#ai in publishing
Note
Regarding the AI-to-sort-through-submissions question, a major publisher recently opened (briefly) to submissions and were going to use an AI called Storywise to sort their subs. There was a massive backlash on social media and they rescinded the idea, got them a lot of bad press. Not sure if you saw that controversy. So I wonder if the person who asked you that question also saw that or if some agencies/other publishers are now doing this too.
I hadn't heard of this controversy, so I googled it, and came up with this article recapping a thing where Angry Robot was going to use Storywise to sort through submissions and got a lot of pushback. (Are they a major publisher? Is this what you were referring to? Or was there another thing?)
The interesting / wild thing about this to me is that... this doesn't sound like a big deal, actually? They put an FAQ about it (which they have left up for transparency) -- in reading the article above and the FAQ, if they are to be believed, it seems that AR were using a non-generative AI program that was NOT being trained on or retaining any of the author's work.
This "slushbot" was going to filter submissions to the appropriate editor and flag any anomalies (like, "doesn't fit requested word count" etc).
All submissions, whether or not they were "flagged" in this way, were being looked at by an actual human. (Because slushbot can make mistakes!).
This... doesn't sound that egregious to me? In fact, it sounds super reasonable? AM I BONKS? Am I missing something?? Maybe!
Things I -- and possibly you! -- use every day that have similar features:
GMAIL. Uses AI to filter out spam, highlight important messages, designate promotions and ads to different folders, remind me to follow up on things, etc. Does it make mistakes? Sure, sometimes. I do have to check the spam filter now and again to make sure it isn't flagging important things wrongly. Does it make my life infinitely easier? YES. I get hundreds of emails a day -- if I had to look at all the trash ones, I would NEVER find the important ones!
SPELLCHECK / AUTOCORRECT / AUTOCOMPLETE / GRAMMARLY, et al. Use AI to tell me when I have misspelled something or to suggest wording. Is it always right? No! I never mean DUCK, spellcheck! Does it make my life easier? For sure! I have fat fingers, this saves me from many a gaffe!
"IF YOU LIKE ____, TRY _____" -- you know how online retailers often suggest things based on your buying preferences, or give you a bargain on things they know you enjoy to get you to re-buy, etc? You know how TikTok and Netflix push content that they think you'll be into based on your viewing habits? Or you'll just be chatting about beekeepers and suddenly you have ads for bee merch on your Facebook? That's the magic of the algorithms, babes. And they are everywhere.
QUERYMANAGER. I don't know if this technically counts as "AI" -- but QM does do things like flag submissions that meet certain criteria that I've designated (like, if it is somebody who is previously published, if it is a referral, etc) -- it also tells me the history of submissions, so I know if they've queried the agency before and when and to whom and with what material. (This is how I KNOW FOR A FACT that so many people don't follow the DUCKING directions.) And, while currently I have to manually forward submissions to other agents if they are more appropriate for them, I could see a world where that was automated -- like if all queries came to a central repository and QM2.0 forwarded them to the specific agents at the agency who were open to [whatever] kind of book. Would that be a bad thing? Or a HELPFUL thing? IDK.
These are just tools, at the end of the day. I don't think there's anything morally wrong with using them or trying them out as long as you aren't letting them make actual decisions for you. Like, I would never want a slushbot to reject things (or accept them!) on my behalf - I have to be the one to look, just as I would never want an algorithm to purchase things on my behalf just because I MIGHT like them -- no thank you! By all means suggest, but I have to make the final decision!
(TL;DR: Using spellcheck on your work to make sure you haven't called me KENNIFER? Yes please! "Creating" work that you intend to submit with your name on it using generative AI? Please, no. Using an AI filter to flag submissions and sort them to the correct person? Sounds OK! Stealing author's work to train an AI? Not OK!)
5 notes
·
View notes
Text

"Dyke March 1994" by Morgan Gwenwald
source: The Wild Good: Lesbian Photographs & Writings on Love, edited by Beatrix Gates
#lesbian#lesbian literature#dyke#dyke literature#archived#thatbutcharchivist#dyke march#dyke march 1994#lesbian history#lesbian photography#author: beatrix gates#photographer: morgan gwenwald#the wild good#year: 1996#publisher: anchor books#publisher: doubleday dell publishing group inc.#butch#butch dyke#butch lesbian#why does it look alright while i'm editing and then hitting the finished button is like unleashing an entirely different monster#ai yai yai#i'll figure it out#asian lesbian
10K notes
·
View notes
Text
So, there's a dirty little secret in indie publishing a lot of people won't tell you, and if you aren't aware of it, self-publishing feels even scarier than it actually is.
There's a subset of self-published indie authors who write a ludicrous number of books a year, we're talking double digit releases of full novels, and these folks make a lot of money telling you how you can do the same thing. A lot of them feature in breathless puff pieces about how "competitive" self-publishing is as an industry now.
A lot of these authors aren't being completely honest with you, though. They'll give you secrets for time management and plotting and outlining and marketing and what have you. But the way they're able to write, edit, and publish 10+ books a year, by and large, is that they're hiring ghostwriters.
They're using upwork or fiverr to find people to outline, draft, edit, and market their books. Most of them, presumably, do write some of their own stuff! But many "prolific" indie writers are absolutely using ghostwriters to speed up their process, get higher Amazon best-seller ratings, and, bluntly, make more money faster.
When you see some godawful puff piece floating around about how some indie writer is thinking about having to start using AI to "stay competitive in self-publishing", the part the journalist isn't telling you is that the 'indie writer' in question is planning to use AI instead of paying some guy on Upwork to do the drafting.
If you are writing your books the old fashioned way and are trying to build a readerbase who cares about your work, you don't need to use AI to 'stay competitive', because you're not competing with these people. You're playing an entirely different game.
8K notes
·
View notes
Text
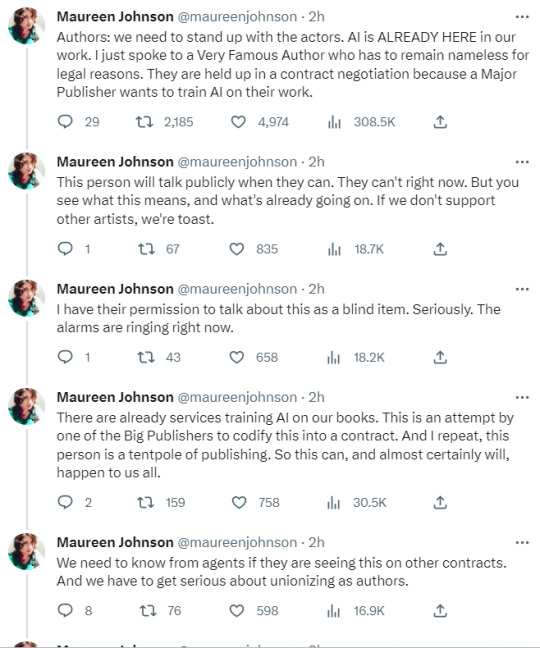
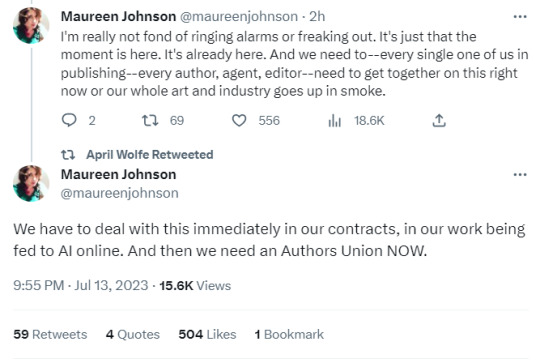
Alarm bells being rung by Maureen Johnson on AI and the Big Publishers
#I've already got academics wanting it put into their contracts that their work CAN'T be used to train AI#This is a scary time#ai MUST be regulated#on publishing#wga strike#sag aftra strike#sag-aftra strike#AUTHORS UNIONIZE
27K notes
·
View notes
Text
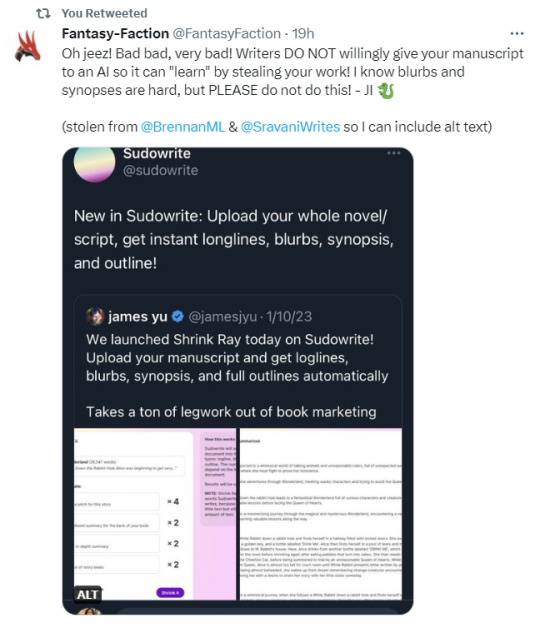
GUYS DO NOT GIVE YOUR MANUSCRIPT TO AN AI THIS IS A BAD IDEA ON EVERY LEVEL DON'T DO IT
original tweet from @jamesjyu reads: "We launch Shrink Ray today on Sudowrite! Upload your manuscript and get loglines, blurbs, synopsis, and full outlines automatically. Takes a ton of legwork out of book marketing. Below the tweet are two images of the program."
original quote tweet from @sudowrite reads: "New in Sudowrite: Upload your whole novel/script, get instant longlines (sic), blurbs, synopsis, and outline!"
tweet from @FantasyFaction reads: "Oh jeez! Bad bad, very bad! Writers DO NOT willingly give your manuscript to an AI so it can "learn" by stealing your work! I know blurbs and synopses are hard, but PLEASE do not do this! - JI 🐉
(stolen from ML Brennan & Sravani Hotha so I can include alt text)"
#ai writing#ai theft#ai generated#writing advice#writers block#fantasy-faction#fantasy#fantasy books#reading#booklr#books and libraries#bookblr#book blog#self publishing#self published#author life#fanfic writing#fanfiction#writing#writers#writers on tumblr#writer community#writer challenge#female writers#writer problems#writblr
3K notes
·
View notes
Text
That viral post that's going around about how people who write "book quality" mlm fic are too "normal" to publish and have real jobs so only "weird" people publish their "shitty" fanfic is so completely out of touch with reality and I am giving a massive side eye to everyone reblogging it.
Not only is it completely, easily verifiably untrue (you cannot enter any professional writing space without tripping over a dozen grizzled scifi writers who got their start by filing off the serial numbers and publishing their Star Trek fanfic even going back decades ago??? it's a whole thing?? plus how can you look at the mlm category on Amazon right now and say with a straight face that people aren't publishing shitty Spirk and Stucky fanfic??? Oh, honey...) it's also the perfect example of this kind of sneering elitism that true artists would never sully themselves by seeking profit, they do it only for the purity of the thing that always somehow leads back to, "no one should be paid to make art, actually."
The only reason you're seeing more published fanfic right now has nothing to do with the idealistic purity of your hypothetical government employee written smut of the past vs the debased scribbles of those awful straights of today and everything to do with the fact that a) self-publishing has created a voracious readership that wants a ton of content so it's become a viable, flexible income stream for many, especially disabled people b) anyone can publish now with self-publishing tools so there are less gatekeepers and c) lockdown got a lot of people into fandom and therefore writing who never tried it before.
And if you really think there's no "shitty" published mlm and no "book-quality" m/f writing out there that started as fanfic, then you are clearly not a reader so why are you even talking about this?
#love how they manipulated people into spreading that post by making it seem like a cishet vs gay thing#when the real message is OP thinks trying to sell your writing is cringe and 'weird' and 'normal people' with jobs would never#which would of course never have flown on the fandom website#so they played into the queer shipping is purer than cishet shipping puriteen thing#and it worked!#because my god people are gullible#this is the direct pipeline that leads to AI thievery#''normal' people write for the joy of it anyway so why do you need pay? you are just greedy and 'weird'!'#'oh no this isn't about who we get to call cringe and who gets to profit from art it's about um...#(quick what's a hated m/f ship?).. oh uh 'shitty' REYLO#and not our super pure uh... (spirk is still popular right? lets throw in that avengers one too to make it seem timely) stucky!'#I'm sorry if I have no sense of humor about this but the year is 2024 and people are still way too ready to sneer#about writers trying to earn a fucking living in the shittiest timeline#and i need you to look deep into yourself and ask you why it's so important to you to tell yourself that only people writing what you like#are 'normal' with real jobs and to vilify everyone else as 'weird' and 'shitty'#for trying to make an income during a financial fucking crisis#i would say sorry for ranting about this but I'm not sorry because wtf#write whatever you want#publish whatever you want#there is no moral fucking purity in what the content is#and one thing certainly doesn't make you more 'weird' or 'normal' than the other#like there is soooo much shitty mlm that started as fanfic???#that post is 100% OP made up some guys to get mad about and called them relyos for the clicks#writing#publishing#writblr#writeblr#i wasn't going to tag this anything but you know what fuck it I'm mad#i had like 5 more tags but tumblr cut me off which is fair 😅#fan fiction
464 notes
·
View notes
Text
Okay, it took a few tries to pull this off, but it was worth it
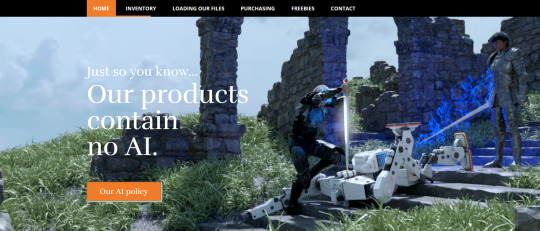
(Context: somebody asked me a question over the weekend that... really annoyed me. The less said about the details, the better.)
Such are the times we live in that it seems it's become wise for small publishers to put up an All Content Produced From Start To Finish By Living Human Beings notice. ...So here's ours. (eyeroll)
...It's exciting business, though, setting up a slide image so that it doesn't lose the most interesting bits depending on what device you're using to view it. At least the one screenshotted above works on desktop devices, now. But it's not quite right for tablets as yet, and I haven't yet checked it on the phone. (sigh) That can wait until after lunch.
(PS: Thanks to the kind person who askboxed me this AM to let me know about that AI art with the washing machines. Yeah, it's getting harder to tell. [mutter] But the heads-up was appreciated. Sorry I hit the wrong button too-early-in-the-morning and accidentally killed the response I was writing to you. Thereby also losing your username.) :/
...And now back, with some relief, to the exciting world of pre-print proofreading.
317 notes
·
View notes
Text
"The world's coral reefs are close to 25 percent larger than we thought. By using satellite images, machine learning and on-ground knowledge from a global network of people living and working on coral reefs, we found an extra 64,000 square kilometers (24,700 square miles) of coral reefs – an area the size of Ireland.
That brings the total size of the planet's shallow reefs (meaning 0-20 meters deep) to 348,000 square kilometers – the size of Germany. This figure represents whole coral reef ecosystems, ranging from sandy-bottomed lagoons with a little coral, to coral rubble flats, to living walls of coral.
Within this 348,000 km² of coral is 80,000 km² where there's a hard bottom – rocks rather than sand. These areas are likely to be home to significant amounts of coral – the places snorkelers and scuba divers most like to visit.
You might wonder why we're finding this out now. Didn't we already know where the world's reefs are?
Previously, we've had to pull data from many different sources, which made it harder to pin down the extent of coral reefs with certainty. But now we have high resolution satellite data covering the entire world – and are able to see reefs as deep as 30 meters down.
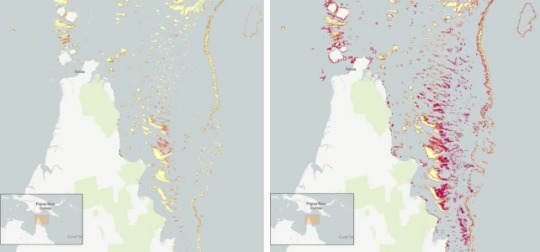
Pictured: Geomorphic mapping (left) compared to new reef extent (red shading, right image) in the northern Great Barrier Reef.
[AKA: All the stuff in red on that map is coral reef we did not realize existed!! Coral reefs cover so much more territory than we thought! And that's just one example. (From northern Queensland)]
We coupled this with direct observations and records of coral reefs from over 400 individuals and organizations in countries with coral reefs from all regions, such as the Maldives, Cuba, and Australia.
To produce the maps, we used machine learning techniques to chew through 100 trillion pixels from the Sentinel-2 and Planet Dove CubeSat satellites to make accurate predictions about where coral is – and is not. The team worked with almost 500 researchers and collaborators to make the maps.
The result: the world's first comprehensive map of coral reefs extent, and their composition, produced through the Allen Coral Atlas. [You can see the interactive maps yourself at the link!]
The maps are already proving their worth. Reef management agencies around the world are using them to plan and assess conservation work and threats to reefs."
-via ScienceDirect, February 15, 2024
#oceanography#marine biology#marine life#marine science#coral#coral reefs#environment#geography#maps#interactive maps#ai#ai positive#machine learning#conservation news#coral reef#conservation#tidalpunk#good news#hope#full disclosure this is the same topic I published a few days ago#but with a different article/much better headline that makes it clear that this is “throughout the world there are more reefs”#rather than “we just found an absolutely massive reef”#also included one of the maps this time around#bc this is a really big deal and huge sign of hope actually!!!#we were massively underestimating how many coral reefs the world has left!#and now that we know where they are we can do a much better job of protecting them
218 notes
·
View notes
Text
Official AI-Generated Massive Rat Penis Post
#official penis post#penish#AI#this got thru PEER REVIEW and was published y’all#scary#win for big dick fans though?#rat
269 notes
·
View notes
Text
Ok, ok this will be a lot of text so I'll use a translator because I'm tired (。・//ε//・。)
I have been making sketches and ideas for several days about an AU that is about Shiho never being part of the black Org and Shinichi for his part being an active member of it.
In the AU Shiho would be a girl passionate about science just like her parents, famous pharmacists, she lives alone but in the care of Agasa, her neighbor.
Shinichi is a boy who grew up in the Organization, his parents were tricked into joining and they tried to escape, failing, and they took Shinichi hostage so that they would continue working for them, but they began to notice Shinichi's potential from an early age and joined as a member.
Shinichi's parents found out about this and complained since it was not part of the deal and killed them, while Shinichi was tricked into telling him that his parents were locked up in a far away place and if I continued working with them His parents would be safe if they found out at 17 about the deception, rebelling against the organization.
Ending in Shinichi being captured and locked in a gas chamber, not giving the organization the satisfaction of killing him, he would do so by taking the ATPX 4869 that he had hidden and instead of killing him he shrunk him and decided that life gave him another chance and he remembered that his parents always talked about a trusted friend named Agasa so he found out his location.
Arriving there, Shinichi couldn't take it anymore due to physical and mental exhaustion, he fainted and Shiho was going out to see Agasa and sees Shinichi lying there helping him and taking him with her to Dr. Agasa's house.
And that would be like the scoop, but what do you think, most of the Sketckes I had were traditional so I made some quick ones in digital And I already have other things in mind, but I'm not used to sharing personal Au's or Headcanons, it's the first time I've done it, and sorry if there's something wrong, it's all full Google Translate (((;ꏿ_ꏿ;)))


#shiho miyano#miyano shiho#case closed#dcmk#dcmk fanart#kudo shinichi#shinichi kudo#edogawa conan#conan edogawa#detective conan#ai haibara#haibara ai#the first au that published what a shame
190 notes
·
View notes
Note
I saw a comment that agents are using AI to sift through queries. Is this true and is this allowed? Wouldn’t that put unpublished work owned by that author into the public domain? I know lawyers are currently being sanctioned for putting private client info into AI to help with cases. This isn’t as high stakes, but it does put the author’s work at risk of being stolen. Thoughts?
There's a lot to unpack here!
Saw a comment... where? From whom? I have never heard of this, personally, so while I'm not saying it's untrue... well, I don't think it's NORMAL PRACTICE or anything, at all. Just on its face, that sounds sus to me. (For one thing, I don't think most agents would even know HOW to "use AI" to write a birthday card, let alone how to program some kind of slush-robot and trust it to accurately gauge our mercurial preferences!)
I can't speak to the lawyers being sanctioned or whatnot piece, idk about that, so let's focus on issue at hand. Let's say I somehow got hold of an AI tool that would sort through my slush pile and only show me the things it deemed most likely to sell. A SLUSH ROBOT!
First, it sorting through slush wouldn't "put your work into the public domain" -- (words mean things!) -- Your work that you personally created is, in the US, anyway, under copyright protection the moment it leaves your brain and is fixed in a tangible medium, you don't even need to register for copyright (though you or your publisher will do so when it is published just for an additional level of protection!) Copyrighted work is NOT in the public domain, that's why there are lawsuits from authors suing various tech companies who used their work to train their AI. So, if I were to use this tool to TRAIN the AI, I'd be abusing your copyright (unethically in my opinion, but I guess the legality is for the courts to decide!) -- but that would NOT render your copyright null and void or put it into the public domain.
But because this hypothetical slush robot is probably a program that I bought or got from someplace, not something I've invented and am training myself, it isn't using any data it gleans from me to train off of -- it's already been trained. For example, the GPT in Chat GPT stands for "generative pre-trained transformer" -- it uses the billion-whatever things it was trained on to generate new things / make predictions / whatever.
I talked to my friend and client Martha Brockenbrough about this (her excellent book on AI, FUTURE TENSE, is out now and is required reading if you are interested in this topic but don't know much about it!). I asked her for an example of how a tool like this might work and she replied:
"For example, companies that get a lot of applicants may use AI to narrow the field. The tool isn't training the model -- it is using an algorithm trained on resumes to look at the new one. AI looks at patterns and makes decisions. Just like people do, but in some cases faster / better / worse. So, when you turn in a resume to a company, are you worried that the HR person is going to steal your resume or leak info?"
Basically, this worry is akin to one that has been around forever, which is the concern that if you query an agent they will "steal your ideas" -- which, a) we don't want your ideas, actually, they are worthless on their own, and b) stealing them would actually be quite a bit harder/more complicated than just representing you and making money off them in the normal fashion, and c) don't query an agent you don't trust, I guess!
4 notes
·
View notes
Note
hey there! fellow naturalist (albeit less experienced!) here! in regards to the AI-generated ID guides, do you have any advice for helping the general public learn to recognize them? are there any giveaways other than incorrect information a layperson might not pick up on that we can tell people to watch out for?
Hi, @fischotterkunst! It's a messy topic, to be sure, but here's what I've been seeing of these AI-generated texts, at least on Amazon:
--If you sort your search for "foraging book" or "mushroom hunting" or whatever search string you use by "Newest Arrivals", you'll notice that there is a glut of books that have come out in the past few weeks. Yes, there are always new books, but this is at a higher than normal rate, which suggests AI is behind at least some of them. There ARE occasionally real authors' books that just happened to come out recently, so don't dismiss every single book that is a fresh release. Use the other criteria below.
--They will invariably be self-published or from some publisher with zero online presence. Not a problem by itself; my own chapbooks are self-published on Amazon KDP. But they come out every three months, not every three days, because I am researching, writing, and editing them all myself, rather than churning out content with AI.
--The titles and subtitles are often very long and stuffed with keywords. They are obviously optimized for search engines rather than being descriptive of the book and they have a rather clunky fashion.

--Look for obvious typos and other errors; for example, in the image above we have "WILD MUSHROOM COOKBOOK FOR BEGINNER: The complete guide on mushroom foraging and cooking with delicious recipes to enjoy your favorite". It should be "for beginners", and the subtitle just...ends prematurely. Favorite what? Favorite mushrooms? Favorite cartoon characters? Favorite color? Also, while there are lot of variations on name spellings, "Magaret" instead of "Margaret" stands out as a possible fake in combination with other clues. (All her other books also have this spelling, though.)
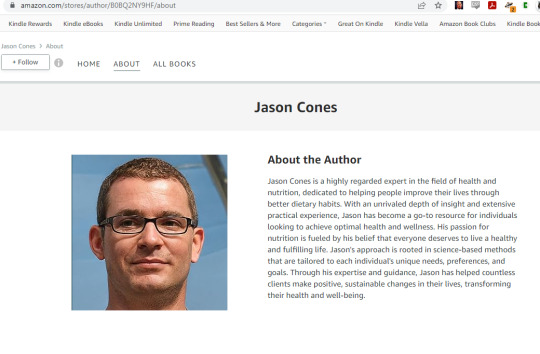
--This is a BIG one: Who's the author? Check their bio. In the above image you'll see that "Jason Cones", the author of "The Wild Edible Plants Forager's Handbook: A Beginner's Guide to Safe Foraging, Including How to Identify Edible Plants, Learn About Their Medicinal Properties, and Prepare Them for Cooking", has a very generic picture and bio that has pretty obviously been generated by AI. If you search for him online, the only page for an author named Jason Cones is the Amazon author page--no website, no social media, no interviews, nada. Even a brand new author will at least have something other than their Amazon page, and they'll mention experience, credentials, other biographical info.
--Look at the author's other books. Magaret seems to focus on cookbooks of very specific sorts, but again they've all come out in a very short time. They also tend to often be on really super-specific niche subjects--this, again, is not a red flag in and of itself, but it's a common pattern with AI "authors". Jason Cones, on the other hand, has written over two dozen books not just about foraging but anger management techniques, acupressure, and weed gummies, and all of his titles have come out since last December.

--If all the books have the same cover but slight differences in title, it's also a big red flag. There are reputable publishers of regional foraging guides like Timber Press, but their books are written by multiple authors and have come out over a long stretch of years (plus they're a well-known publisher with a solid track record, online presence, etc.) Also notice the typos in the title and subtitle; everyone says "Mushroom Foraging", not "Mushrooms Foraging", and "Keep Track Your Mushroom Sightings" is missing "of".


--Compare the descriptions of multiples of these new books and you start seeing patterns. If you look at the images above, you'll notice that both Lorna K. Thompson's "Foraging Recipe Cookbook" and Kevin Page's "The Ultimate Foraging Guide for Seniors" have a very similar formulaic description. They start with a brief story about a person in a town or village who discovers some foraging secrets and then transforms his life, and then a list of things you're supposedly going to find in this seemingly miraculous book. This basically reads like "Hey, ChatGPT, tell me a story of a person who improved their life with foraging in two hundred words or less!" Also, the ends got cut off of my screen shot, but they both end with "GET YOUR COPY TODAY!"
I have not purchased any of these books to verify how awful the content is, but what little content I can see in the previews is uniformly formulaic and, again, reads like someone asked an AI to write content on a topic with some specific keywords thrown in. Needless to say, I do NOT recommend any of these books.
Also, I feel really bad for any actual authors who released their books in the past few months. They're likely getting drowned out by this AI junk, though hopefully they're getting enough attention for their work through their publishers, social media, etc. to get some sales. Support your real-life authors, and boycott AI!
Finally, PLEASE reblog this! It's really, really important that people know what to look for, and the more posts we have floating around with this info, the less likely it is someone's going to get poisoned by following what these books have to say.
#fischotterkunst#AI#Ai sucks#chatgpt#foraging#mushroom foraging#mushroom hunting#wild foods#nature#mushrooms#plants#fungus#fungi#books#self publishing#Amazon#PSA#poisonous mushrooms#poisonous plants
572 notes
·
View notes
Text
In light of the current shit with tumblr making us opt-out of sharing our blogs with AI scrapers, I checked the state of Wordpress for this and, not surprisingly since it's the same company, you need to opt out there too.
If you have a wordpress-blog of the NAME.wordpress.com kind, you need to go into Settings and under the section Privacy, hit the checkmark for "Prevent third-party sharing for NAME.wordpress.com".
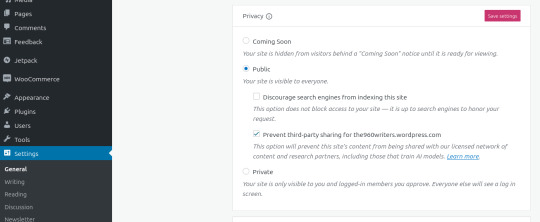
I know some of us here at writeblr have secondary blogs on wordpress, so make sure to opt-out of AI scraping there.
#AI scraping#tumblr#wordpress#AI opt-out#third party sharing#AI shit#writeblr#publishing#indie publishing#self publishing
95 notes
·
View notes
Text


Happy 2024 have these things I made in the last half hour of 2023
#Sonic the hedgehog#fandom i have an offering for you please accept me-#shadjet#sonknux#jet the hawk#shadow the hedgehog#rouge the bat#vector the crocodile#mark the tapir#idk. he’s there. might as well tag him#sage the ai#knuckles the echidna#why was that the fourth option#white bg#for a couple#don’t let any of this fool you I am not well versed in the Sonic franchise and it’s lore#most of what I know comes from anything Snapcube and co has said#I’ve started playing the dream team game and the second Sonic game and that’s IT#well. I also had a little volleyball game with Amy and rouge from a kids meal#and I started reading the idw comics back when they started publishing#OH IVE ALSO SEEN THE TWO LIVE ACTION MOVIES#overall: I have some catching up to do bare with me-
85 notes
·
View notes
Text
A link-clump demands a linkdump

Cometh the weekend, cometh the linkdump. My daily-ish newsletter includes a section called "Hey look at this," with three short links per day, but sometimes those links get backed up and I need to clean house. Here's the eight previous installments:
https://pluralistic.net/tag/linkdump/
The country code top level domain (ccTLD) for the Caribbean island nation of Anguilla is .ai, and that's turned into millions of dollars worth of royalties as "entrepreneurs" scramble to sprinkle some buzzword-compliant AI stuff on their businesses in the most superficial way possible:
https://arstechnica.com/information-technology/2023/08/ai-fever-turns-anguillas-ai-domain-into-a-digital-gold-mine/
All told, .ai domain royalties will account for about ten percent of the country's GDP.
It's actually kind of nice to see Anguilla finding some internet money at long last. Back in the 1990s, when I was a freelance web developer, I got hired to work on the investor website for a publicly traded internet casino based in Anguilla that was a scammy disaster in every conceivable way. The company had been conceived of by people who inherited a modestly successful chain of print-shops and decided to diversify by buying a dormant penny mining stock and relaunching it as an online casino.
But of course, online casinos were illegal nearly everywhere. Not in Anguilla – or at least, that's what the founders told us – which is why they located their servers there, despite the lack of broadband or, indeed, reliable electricity at their data-center. At a certain point, the whole thing started to whiff of a stock swindle, a pump-and-dump where they'd sell off shares in that ex-mining stock to people who knew even less about the internet than they did and skedaddle. I got out, and lost track of them, and a search for their names and business today turns up nothing so I assume that it flamed out before it could ruin any retail investors' lives.
Anguilla is a British Overseas Territory, one of those former British colonies that was drained and then given "independence" by paternalistic imperial administrators half a world away. The country's main industries are tourism and "finance" – which is to say, it's a pearl in the globe-spanning necklace of tax- and corporate-crime-havens the UK established around the world so its most vicious criminals – the hereditary aristocracy – can continue to use Britain's roads and exploit its educated workforce without paying any taxes.
This is the "finance curse," and there are tiny, struggling nations all around the world that live under it. Nick Shaxson dubbed them "Treasure Islands" in his outstanding book of the same name:
https://us.macmillan.com/books/9780230341722/treasureislands
I can't imagine that the AI bubble will last forever – anything that can't go on forever eventually stops – and when it does, those .ai domain royalties will dry up. But until then, I salute Anguilla, which has at last found the internet riches that I played a small part in bringing to it in the previous century.
The AI bubble is indeed overdue for a popping, but while the market remains gripped by irrational exuberance, there's lots of weird stuff happening around the edges. Take Inject My PDF, which embeds repeating blocks of invisible text into your resume:
https://kai-greshake.de/posts/inject-my-pdf/
The text is tuned to make resume-sorting Large Language Models identify you as the ideal candidate for the job. It'll even trick the summarizer function into spitting out text that does not appear in any human-readable form on your CV.
Embedding weird stuff into resumes is a hacker tradition. I first encountered it at the Chaos Communications Congress in 2012, when Ang Cui used it as an example in his stellar "Print Me If You Dare" talk:
https://www.youtube.com/watch?v=njVv7J2azY8
Cui figured out that one way to update the software of a printer was to embed an invisible Postscript instruction in a document that basically said, "everything after this is a firmware update." Then he came up with 100 lines of perl that he hid in documents with names like cv.pdf that would flash the printer when they ran, causing it to probe your LAN for vulnerable PCs and take them over, opening a reverse-shell to his command-and-control server in the cloud. Compromised printers would then refuse to apply future updates from their owners, but would pretend to install them and even update their version numbers to give verisimilitude to the ruse. The only way to exorcise these haunted printers was to send 'em to the landfill. Good times!
Printers are still a dumpster fire, and it's not solely about the intrinsic difficulty of computer security. After all, printer manufacturers have devoted enormous resources to hardening their products against their owners, making it progressively harder to use third-party ink. They're super perverse about it, too – they send "security updates" to your printer that update the printer's security against you – run these updates and your printer downgrades itself by refusing to use the ink you chose for it:
https://www.eff.org/deeplinks/2020/11/ink-stained-wretches-battle-soul-digital-freedom-taking-place-inside-your-printer
It's a reminder that what a monopolist thinks of as "security" isn't what you think of as security. Oftentimes, their security is antithetical to your security. That was the case with Web Environment Integrity, a plan by Google to make your phone rat you out to advertisers' servers, revealing any adblocking modifications you might have installed so that ad-serving companies could refuse to talk to you:
https://pluralistic.net/2023/08/02/self-incrimination/#wei-bai-bai
WEI is now dead, thanks to a lot of hueing and crying by people like us:
https://www.theregister.com/2023/11/02/google_abandons_web_environment_integrity/
But the dream of securing Google against its own users lives on. Youtube has embarked on an aggressive campaign of refusing to show videos to people running ad-blockers, triggering an arms-race of ad-blocker-blockers and ad-blocker-blocker-blockers:
https://www.scientificamerican.com/article/where-will-the-ad-versus-ad-blocker-arms-race-end/
The folks behind Ublock Origin are racing to keep up with Google's engineers' countermeasures, and there's a single-serving website called "Is uBlock Origin updated to the last Anti-Adblocker YouTube script?" that will give you a realtime, one-word status update:
https://drhyperion451.github.io/does-uBO-bypass-yt/
One in four web users has an ad-blocker, a stat that Doc Searls pithily summarizes as "the biggest boycott in world history":
https://doc.searls.com/2015/09/28/beyond-ad-blocking-the-biggest-boycott-in-human-history/
Zero app users have ad-blockers. That's not because ad-blocking an app is harder than ad-blocking the web – it's because reverse-engineering an app triggers liability under IP laws like Section 1201 of the Digital Millenium Copyright Act, which can put you away for 5 years for a first offense. That's what I mean when I say that "IP is anything that lets a company control its customers, critics or competitors:
https://locusmag.com/2020/09/cory-doctorow-ip/
I predicted that apps would open up all kinds of opportunities for abusive, monopolistic conduct back in 2010, and I'm experiencing a mix of sadness and smugness (I assume there's a German word for this emotion) at being so thoroughly vindicated by history:
https://memex.craphound.com/2010/04/01/why-i-wont-buy-an-ipad-and-think-you-shouldnt-either/
The more control a company can exert over its customers, the worse it will be tempted to treat them. These systems of control shift the balance of power within companies, making it harder for internal factions that defend product quality and customer interests to win against the enshittifiers:
https://pluralistic.net/2023/07/28/microincentives-and-enshittification/
The result has been a Great Enshittening, with platforms of all description shifting value from their customers and users to their shareholders, making everything palpably worse. The only bright side is that this has created the political will to do something about it, sparking a wave of bold, muscular antitrust action all over the world.
The Google antitrust case is certainly the most important corporate lawsuit of the century (so far), but Judge Amit Mehta's deference to Google's demands for secrecy has kept the case out of the headlines. I mean, Sam Bankman-Fried is a psychopathic thief, but even so, his trial does not deserve its vastly greater prominence, though, if you haven't heard yet, he's been convicted and will face decades in prison after he exhausts his appeals:
https://newsletter.mollywhite.net/p/sam-bankman-fried-guilty-on-all-charges
The secrecy around Google's trial has relaxed somewhat, and the trickle of revelations emerging from the cracks in the courthouse are fascinating. For the first time, we're able to get a concrete sense of which queries are the most lucrative for Google:
https://www.theverge.com/2023/11/1/23941766/google-antitrust-trial-search-queries-ad-money
The list comes from 2018, but it's still wild. As David Pierce writes in The Verge, the top twenty includes three iPhone-related terms, five insurance queries, and the rest are overshadowed by searches for customer service info for monopolistic services like Xfinity, Uber and Hulu.
All-in-all, we're living through a hell of a moment for piercing the corporate veil. Maybe it's the problem of maintaining secrecy within large companies, or maybe the the rampant mistreatment of even senior executives has led to more leaks and whistleblowing. Either way, we all owe a debt of gratitude to the anonymous leaker who revealed the unbelievable pettiness of former HBO president of programming Casey Bloys, who ordered his underlings to create an army of sock-puppet Twitter accounts to harass TV and movie critics who panned HBO's shows:
https://www.rollingstone.com/tv-movies/tv-movie-features/hbo-casey-bloys-secret-twitter-trolls-tv-critics-leaked-texts-lawsuit-the-idol-1234867722/
These trolling attempts were pathetic, even by the standards of thick-fingered corporate execs. Like, accusing critics who panned the shitty-ass Perry Mason reboot of disrespecting veterans because the fictional Mason's back-story had him storming the beach on D-Day.
The pushback against corporate bullying is everywhere, and of course, the vanguard is the labor movement. Did you hear that the UAW won their strike against the auto-makers, scoring raises for all workers based on the increases in the companies' CEO pay? The UAW isn't done, either! Their incredible new leader, Shawn Fain, has called for a general strike in 2028:
https://www.404media.co/uaw-calls-on-workers-to-line-up-massive-general-strike-for-2028-to-defeat-billionaire-class/
The massive victory for unionized auto-workers has thrown a spotlight on the terrible working conditions and pay for workers at Tesla, a criminal company that has no compunctions about violating labor law to prevent its workers from exercising their legal rights. Over in Sweden, union workers are teaching Tesla a lesson. After the company tried its illegal union-busting playbook on Tesla service centers, the unionized dock-workers issued an ultimatum: respect your workers or face a blockade at Sweden's ports that would block any Tesla from being unloaded into the EU's fifth largest Tesla market:
https://www.wired.com/story/tesla-sweden-strike/
Of course, the real solution to Teslas – and every other kind of car – is to redesign our cities for public transit, walking and cycling, making cars the exception for deliveries, accessibility and other necessities. Transitioning to EVs will make a big dent in the climate emergency, but it won't make our streets any safer – and they keep getting deadlier.
Last summer, my dear old pal Ted Kulczycky got in touch with me to tell me that Talking Heads were going to be all present in public for the first time since the band's breakup, as part of the debut of the newly remastered print of Stop Making Sense, the greatest concert movie of all time. Even better, the show would be in Toronto, my hometown, where Ted and I went to high-school together, at TIFF.
Ted is the only person I know who is more obsessed with Talking Heads than I am, and he started working on tickets for the show while I starting pricing plane tickets. And then, the unthinkable happened: Ted's wife, Serah, got in touch to say that Ted had been run over by a car while getting off of a streetcar, that he was severely injured, and would require multiple surgeries.
But this was Ted, so of course he was still planning to see the show. And he did, getting a day-pass from the hospital and showing up looking like someone from a Kids In The Hall sketch who'd been made up to look like someone who'd been run over by a car:
https://www.flickr.com/photos/doctorow/53182440282/
In his Globe and Mail article about Ted's experience, Brad Wheeler describes how the whole hospital rallied around Ted to make it possible for him to get to the movie:
https://www.theglobeandmail.com/arts/music/article-how-a-talking-heads-superfan-found-healing-with-the-concert-film-stop/
He also mentions that Ted is working on a book and podcast about Stop Making Sense. I visited Ted in the hospital the day after the gig and we talked about the book and it sounds amazing. Also? The movie was incredible. See it in Imax.
That heartwarming tale of healing through big suits is a pretty good place to wrap up this linkdump, but I want to call your attention to just one more thing before I go: Robin Sloan's Snarkmarket piece about blogging and "stock and flow":
https://snarkmarket.com/2010/4890/
Sloan makes the excellent case that for writers, having a "flow" of short, quick posts builds the audience for a "stock" of longer, more synthetic pieces like books. This has certainly been my experience, but I think it's only part of the story – there are good, non-mercenary reasons for writers to do a lot of "flow." As I wrote in my 2021 essay, "The Memex Method," turning your commonplace book into a database – AKA "blogging" – makes you write better notes to yourself because you know others will see them:
https://pluralistic.net/2021/05/09/the-memex-method/
This, in turn, creates a supersaturated, subconscious solution of fragments that are just waiting to nucleate and crystallize into full-blown novels and nonfiction books and other "stock." That's how I came out of lockdown with nine new books. The next one is The Lost Cause, a hopepunk science fiction novel about the climate whose early fans include Naomi Klein, Rebecca Solnit, Bill McKibben and Kim Stanley Robinson. It's out on November 14:
https://us.macmillan.com/books/9781250865939/the-lost-cause

If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2023/11/05/variegated/#nein
#pluralistic#hbo#astroturfing#sweden#labor#unions#tesla#adblock#ublock#youtube#prompt injection#publishing#robin sloan#linkdumps#linkdump#ai#tlds#anguilla#finance curse#ted Kulczycky#toronto#stop making sense#talking heads
137 notes
·
View notes
Text
So I follow authors on Instagram. One of them posted earlier today about another author reaching out to her for advice. These people are Traditionally published.
The conversation was about the fact that the author that reached out to the one I followed said there was an AI clause in their contract. That would allow the publishing company to feed her work into an AI to produce more without her involvement or input.
If you're someone who creates and works with contracts, I suggest you start looking. It's a factor in both the writing strike and I believe the actors strike as well, but I could be wrong about the actors strike.
The instagram post can be found HERE
191 notes
·
View notes
Last Seen Blogs

ebodinphotos
Regard sur l'Homme et la Nature

jackiegrc-blog
run like a river.

oddlytwistedghosts
Hello there

orchidsbythesea
Orchids by the Sea

vecucamoc
Untitled