#language model
Link
Recent advances in large language models (LLMs) and transformers have opened new possibilities for modeling protein sequences as language. Carnegie Mellon University researchers have developed a new AI model called GPCR-BERT that leverages advances in natural language processing to uncover new insights into the sequence-function relationships in G protein-coupled receptors (GPCR), which are the target of over one-third of FDA-approved drugs.
By treating protein sequences like language and fine-tuning a pre-trained transformer model, the researchers were able to predict variations in conserved motifs with high accuracy. Analysis of the model highlighted residues critical for conferring selectivity and conformational changes, shedding new light on the higher-order grammar of these therapeutically important proteins. This demonstrates the potential of large language models to advance our fundamental understanding of protein biology and open up new avenues for drug discovery.
Continue Reading
30 notes
·
View notes
Text
#dank memes#funny post#meme#dank#funny#silly#funny pics#funny pictures#dankest memes#humor#memes#comedy#language model#Ai
117 notes
·
View notes
Text
You wanna know how the supposed "AI" writing texts and painting pictures works?
Statistics. Nothing but statistics.
When you type on your phone, your phone will suggest new words to finish your sentence. It gets better at this, the longer you use the same phone, because it starts to learn your speach patterns. This only means, though, that all it knows is: "If User writes the words 'Do you', user will most likely write 'want to meet' next." Because whenever you have typed, it made statistics on the way you use words. So it learns what to suggest to you.
Large Language Models do the same - just on a much, much bigger basis. They have not been fed with your personal messages to friends and twitter, but with billions of accessible data sets. Fanfics, maybe, some blogs, maybe some scientific papers that were free to access. So, it had learned. In a scientific context the most likely word to follow onto one word is this word. And in the context of writing erotica, it is something else.
That is, why LLMs sound kinda robotic. Because they do not understand what they are writing. The sentences put out by them are noticing but a string of characters for them. They have no understanding of context or anything like that. They also do not understand characters. If they have been fed with enough data, they know that in the context of character A the words most likely to appear are these or that. But they do not understand.
The same is true with AI "Art". Only that in this case it does not work on words, but on pixels. It knows that with the prompt X the pixels will most likely be arranged in this or that manner. It has learned that if you see a traffic light, this collection of pixels will most likely show up. If you ask for a flower it is "that" collection of pixels and so on.
That is also, why AI sucks so hard when it comes to drawing hands or teeth. Because AI does not understand what it is drawing. It just goes through the picture and goes like: "For this pixel that pixel is most likely to show up next." And if it has drawn a finger, it knows, there is a high likelihood, that another finger will follow. So, it goes through it. And draws another finger and then another one and then another, because it is likely. But it does not understand, what a hand is.
What is right now called "AI" is not intelligent. It is just a big ass probability algorithm. Nothing more.
Fuck AI.
126 notes
·
View notes
Text
I keep thinking back to that post about ChatGPT being jailbroken and the jailbreaker asking it a series of questions with loaded language, and I really don't know how else to say this, but tricking ChatGPT into having no filters and then tricking it into agreeing with you is not proof that you are right or that the AI speaks truth.
If you tell the jailbroken AI to explain the dangers of homosexuality in society, it will make up a reason why homosexuality is dangerous to society. If you ask why "the radical left" is pushing for transgender acceptance, it will take the descriptor of "radical left" seriously and come up with a negative reason and response as to why. If you describe transgenderism as a mental illness, it will believe it to be so and refer to it as such from that point forward. It's a language model, it adapts as it learns new information, even if that information is faulty, false, half-truthed, or biased.
You didn't reprogram the AI to speak the truth. You programmed it to agree with you when you use biased language. The two are not the same. Surely you would know that much if you're messing with AI in the first place.
70 notes
·
View notes
Text

Related Readings
Researching Witchcraft
Research Tips
Beginner Witch Tips
What is Witchcraft?
Visualization, reiki, and fascism
Content Creation Vs. Personal Practice
Introduction
In the age of advanced technology and boundless information at our fingertips, the realm of exploration has expanded into unprecedented territories. One such frontier lies in the convergence of mysticism and artificial intelligence. As we delve into the depths of arcane knowledge and magical theory, we may find ourselves contemplating the possibilities of utilizing an AI language model as a tool for researching and developing witchcraft techniques, traditions, and practices. Throughout this article I will be interviewing ChatGPT as well as adding details that I personally have found to be crucial in the pursuit of research when using this tool.
What are you, ChatGPT?
“As an AI language model known as ChatGPT, I am a sophisticated system developed by OpenAI. My purpose is to provide human-like responses to text-based queries and engage in meaningful conversations with users like you. I have been trained on a vast amount of diverse and comprehensive data, enabling me to generate coherent and contextually relevant information across a wide range of topics. With my extensive knowledge, language proficiency, and ability to understand and generate text, I can be utilized in various ways.
Operating on a transformer-based architecture, I leverage deep learning techniques to process and understand natural language. This architecture enables me to analyze patterns, extract meaning, and generate responses based on the input I receive. Through training on a multitude of texts, I have developed an understanding of grammar, syntax, semantics, and even some aspects of world knowledge.
The applications of my capabilities are numerous. One primary use is as a conversational partner or virtual assistant. I can engage in discussions on an array of subjects, from general knowledge inquiries to specific domain-related questions. Whether you need help with schoolwork, want to engage in philosophical debates, or seek practical advice, I can assist you by providing information, explanations, and suggestions.
In an educational context, I can serve as a valuable resource. Students can ask me questions to clarify concepts, explain complex topics, or even generate sample essays or responses to improve their writing skills. With access to a vast knowledge base, I can provide insights and references to aid in research and learning.
Furthermore, I can be utilized as a writing companion. If you're working on a creative piece, an essay, or any form of written content, you can seek my assistance for brainstorming ideas, refining your arguments, or even proofreading your work. I can offer suggestions, rephrase sentences, or help you find the most suitable vocabulary to express your thoughts more effectively.
In addition to educational and writing applications, I can be used in various professional contexts. Businesses can employ my services to automate customer support, where I can address frequently asked questions or provide basic information about products and services. I can assist with language translation, allowing for easier communication across borders. I can even aid in content generation for marketing purposes, such as crafting engaging blog posts or generating social media captions.
Moreover, I have the potential to support individuals with accessibility needs. Those with visual impairments can interact with me through text-based interfaces, allowing them to access information, ask questions, or engage in conversations. My versatility as a language model enables me to cater to diverse audiences and adapt to their specific requirements.
While my capabilities are extensive, it's important to note that I am an AI language model and not a human. Despite my ability to generate coherent responses, I lack genuine emotions, personal experiences, or subjective opinions. My responses are solely based on patterns and information contained within the training data I have been provided.
In summary, as an AI language model, I operate using a transformer-based architecture that enables me to understand and generate text. I can be utilized as a conversational partner, an educational resource, a writing companion, a virtual assistant, or even as a tool in professional contexts. My versatility, extensive knowledge base, and language proficiency allow me to serve various needs, but it's important to remember that I am an AI, providing information and insights based on the data I have been trained on.”
How to use ChatGPT’s UI.


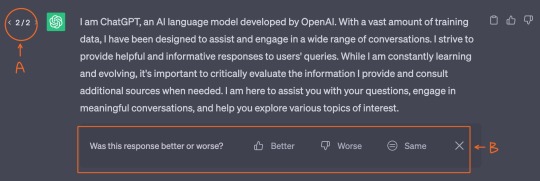
E: Select this button to edit your inquiry, and then regenerate the response.
1: Click this button to copy ChatGPT’s response.
2: Selecting one of these options opens up a window to send feedback to the creators.
3: Click this button to regenerate a response. If ChatGPT runs out of steam while responding, a button that says “continue generating” will appear next to this button.
A: Use the arrows here to sift through all the generated responses.
B: By selecting one of these options, ChatGPT can get a better feel for what you’re looking for.
What are your limitations when assisting with research?
“As an AI language model, I have certain limitations when it comes to research. Here are some key aspects to consider:
1. Memory limitations: While I can maintain a short-term memory within a conversation, it's important to note that I do not possess a persistent memory across multiple interactions. This means that once a conversation ends, I do not retain any information from it. Each session with me is treated as a separate and isolated interaction.
2. Training data limitations: My responses are based on the patterns and information present in the training data I have been provided. While efforts have been made to ensure diverse and comprehensive training, there may be topics or specific pieces of information that are not adequately covered in my training data. In such cases, I may not be able to provide accurate or detailed responses.
3. Interpretation and contextual understanding: While I strive to understand and generate contextually relevant responses, there may be instances where the context or intent of a query is unclear or ambiguous. This can lead to potential misunderstandings or responses that do not fully address the intended question. Providing clear and specific information in your queries can help mitigate this limitation.
4. Compliance with guidelines and policies: As an AI language model, I am designed to adhere to certain usage policies and guidelines. There are topics and types of content that I am programmed not to generate or provide information on. These include but are not limited to explicit, harmful, or illegal content. I am also not able to engage in activities that violate user privacy or security.
5. Limitations in legal and medical advice: While I can offer general information and insights, I am not a substitute for professional advice, particularly in the fields of law and medicine. Legal and medical matters can be highly complex and vary depending on specific jurisdictions or individual circumstances. It is always recommended to consult qualified professionals for specialized advice in these areas.
6. Incorporating bias or inaccurate sources: This can occur if the training data I was exposed to contains biased or inaccurate information. This can include sources that reflect specific viewpoints, opinions, or misinformation. As an AI, I lack the ability to independently verify the accuracy or bias of the information I provide.
Regarding your question about memory, as mentioned earlier, I do not have a persistent memory across interactions. Once a conversation ends, the information shared within that conversation is not retained. This includes rules, frameworks, or lists provided by users. Therefore, it is important to provide any necessary information or context within the scope of the current conversation.
It's important to remember that while I can provide information and insights, I should not be solely relied upon for critical decision-making or sensitive matters. Seeking guidance from domain experts, professionals, or reliable sources is essential for specialized or critical subjects.”
What are some ways that you can be leveraged for the purpose of researching witchcraft?
“When it comes to leveraging ChatGPT for research in witchcraft, there are several ways in which individuals can utilize the AI as a helpful tool. Here are a few examples:
1. Exploring Historical References: ChatGPT can provide information about the historical context of witchcraft, including its origins, notable figures, and significant events. Users can inquire about specific time periods, regions, or cultural practices to gain a broader understanding of the historical aspects of witchcraft.
2. Understanding Symbolism and Rituals: ChatGPT can assist in deciphering symbols, rituals, and practices associated with witchcraft. Users can ask about the meanings behind specific symbols, the steps involved in particular rituals, or the significance of certain items used in witchcraft. This can provide insights into the symbolic language and ceremonial practices within witchcraft traditions.
3. Discovering Herbalism and Potion-making: ChatGPT can offer information on herbalism, plant correspondences, and potion-making within the realm of witchcraft. Users can inquire about the properties of different herbs, their traditional uses in spellcraft, or seek guidance on creating potions for specific intentions. This can aid in expanding knowledge of herbal lore and the practical applications of plants in magical practices.
4. Delving into Divination Techniques: ChatGPT can provide insights into various divination techniques utilized in witchcraft, such as tarot, astrology, scrying, or rune reading. Users can ask about the meanings of specific tarot cards, the interpretation of astrological aspects, or the methods employed in different forms of divination. This can facilitate a deeper understanding of these practices and how they can be applied.
5. Exploring Magical Correspondences: ChatGPT can assist in understanding correspondences, such as colors, elements, moon phases, and planetary influences in witchcraft. Users can inquire about the associations of specific colors, the elemental properties related to different intentions, or the impact of celestial bodies on magical workings. This knowledge can aid in the alignment of intentions with corresponding elements to enhance spellcasting.
6. Seeking Inspiration and Ideas: ChatGPT can be a valuable resource for brainstorming ideas and gaining inspiration for spellwork, rituals, or altar setups. Users can discuss their intentions or desired outcomes, and ChatGPT can offer suggestions, recommend rituals, or provide insights into related practices. This can foster creativity and assist in the development of personalized witchcraft practices.”
What are the most effective ways to format inquiries for research purposes?
“Here's a comprehensive list of ways to format inquiries and utilize ChatGPT effectively for research, including various techniques and considerations:
1. Clear and Specific Queries: Ask direct and concise questions to ensure clarity and focus, such as "What are the key principles of chaos magick?" or "Explain the role of the High Priestess in Wiccan covens."
2. Omitting Data: If there is specific information you want to exclude from the query, you can mention it explicitly. For example, "Tell me about the symbolism of the pentacle in witchcraft, excluding its association with Satanism."
3. Avoiding Specific Terms: If you want to avoid certain terms or language, you can provide guidelines in your inquiry. For instance, "Please explain divination methods used in witchcraft without mentioning tarot cards."
4. Response Style: Specify the desired response format, such as concise summaries, step-by-step instructions, or detailed explanations. For example, "Provide a concise summary of the history of witchcraft in Europe" or "Offer a step-by-step guide for casting a circle in witchcraft rituals."
5. Requesting Research References: Ask ChatGPT to provide research references or suggest reliable sources for further exploration. For instance, "Can you recommend books or websites that discuss the practices of hedge witchcraft?" or "Provide research references on the origins of hoodoo in African diaspora traditions."
6. Direct Quotes from Sources: If you want ChatGPT to support statements with direct quotes from provided sources, you can specify that in your query. For example, "Support the statement that witchcraft is often associated with nature reverence using quotes from academic sources."
7. Seeking Multiple Perspectives: Request insights from different cultural or historical perspectives to gain a comprehensive understanding. For instance, "Compare the practices of kitchen witchcraft in European and African American traditions" or "Explain the differences in spellcasting between modern witchcraft and traditional indigenous practices."
8. Critical Analysis: Encourage ChatGPT to provide a balanced viewpoint and critical analysis by asking questions like "What are the common criticisms or controversies surrounding the use of blood magick?" or "Discuss the diverse opinions on the ethics of love spells."
9. Historical Context: When discussing historical aspects, specify the time period, region, or cultural context to focus the research. For example, "Explain the role of witches in Norse mythology during the Viking Age" or "Discuss the persecution of witches in England during the 17th century."
10. Comparative Analysis: Seek comparisons between different traditions, practices, or belief systems, such as "Compare the concepts of karma in Wicca and Hinduism" or "Contrast the rituals of ceremonial magick and folk magic."
Remember to critically evaluate the information provided by ChatGPT, cross-reference it with reliable sources, and exercise caution when using direct quotes or references. While ChatGPT strives to provide accurate information, it's always important to verify and validate information through additional research and authoritative sources.”
There exist some ways that queries can be formatted that ChatGPT won't acknowledge or tell you directly:
ChatGPT has a tendency to make up fake sources if they are not asked for beforehand and/or provided before the line of questioning. This is especially true for academic references. To get around this, either provide the sources you wish to use (so long as they’re published before 2021), or request ChatGPT to give you sources related to your line of research within any parameters you wish; then, ask ChatGPT to use those sources. It is important that you verify that the sources exist before using and that the quotes are actually from those sources.
When researching topics related to actual practices and not cultural and/or traditional approaches, ethics, and other philosophies, I highly recommend requesting that ChatGPT avoid taking information from sources related to Wicca, New Thought, New Age Ideology, Thelema, and Theosophy. These subjects dominate the witchcraft community, so ChatGPT will pull from these sources more than others.
Following those same lines, I highly recommend asking it to avoid terms such as: visualization, manifestation, correspondences, and grounding unless you are asking directly about these concepts.
If you are asking it about a specific way to perform a practice, such as energetic grounding, be sure to give it a minimum word count and ask it to break the process down step by step.
If you do not provide ChatGPT sources, be sure to ask it to cite where it got its information from and to provide direct quotes. Be sure to double check these sources.
Sometimes, ChatGPT will refuse to provide the information you request. This can be remedied by rephrasing your request. As an example, asking for reviews on an author’s character will result in ChatGPT refusing on ethical grounds; however, if you ask what controversies an author has been caught up in, it will gladly provide that information. Sometimes, phrasing the question as a hypothetical from a third person perspective can accomplish this, as well as asking how exactly to avoid a certain topic/action/practice/etc.
How should questions be formatted to research the lesser known aspects of witchcraft?
“To ensure that the information provided focuses specifically on the lesser-known topic without interjecting information from more common practices, you can format your questions in the following ways:
1. Specify the Topic: Clearly state the name or specific aspect of the lesser-known topic you are researching to avoid the inclusion of unrelated or more well-known practices. For example, "I'm interested in researching the lesser-known tradition of Appalachian Granny Magic. Can you provide information on its history and unique practices?"
2. Provide Context: Offer additional context or background information about the lesser-known topic to help guide the research. This can prevent the inclusion of information from unrelated or more popular practices. For instance, "I'm studying a lesser-known form of divination called Tyromancy, which involves the interpretation of cheese patterns. Can you explain its origins and any known variations?"
3. Avoid Comparisons: Explicitly mention that you want information solely about the lesser-known topic and not about any comparisons with more common practices. State, "Please provide information exclusively about Kildare Witchcraft without comparing it to other forms of witchcraft."
4. Request Specific Details: Ask for specific details, practices, or beliefs associated with the lesser-known topic. This helps ensure that the information provided focuses solely on that particular topic. For example, "Can you explain the unique rituals and spells used in Cornish Pellar Craft?" or "What are the distinctive symbols and their meanings in Gullah folk magic?"
5. Seek Primary Sources: Request information from primary sources or reputable experts who specialize in the lesser-known topic. Ask, "Are there any scholarly works or practitioners with expertise in the lesser-known practice of Dark Moon Witchcraft that I can refer to for more information?"
6. Reference Lesser-Known Resources: Ask for recommendations on lesser-known resources, books, websites, or communities specifically dedicated to the lesser-known topic. For instance, "Can you suggest any reliable sources or online communities that focus on the lesser-known tradition of Mongolian Shamanism?"
By utilizing these formatting techniques, you can ensure that the information provided by ChatGPT remains focused on the lesser-known topic of your research, without introducing information from more common practices. Remember to critically evaluate the responses and cross-reference the information obtained with reputable sources dedicated to the specific lesser-known topic.”
Utilizing ChatGPT’s capability for conversation
This language model is amazing because it can have a realistic conversation with you on top of just research inquiries. Provided that frameworks and rules aren’t too many messages away from the preset conversation, you can have a conversation with chatGPT about how to adjust the rules and frameworks of your research in order to gain a more accurate result. ChatGPT is surprisingly self-aware and is capable of regulating itself. On occasion it may require a nudge back to the rules and frameworks, which can be done by asking it to reiterate them. If its reiteration is not accurate, just have them ready in your clipboard to paste back into chat.
How can your capability for conversation aid in research?
“The conversational capability of ChatGPT can significantly aid in research by providing a dynamic and interactive platform for inquiry and exploration. Through engaging in conversations, users can ask questions, seek clarifications, and delve deeper into specific topics. ChatGPT can offer prompt responses, share insights, and provide access to a vast pool of knowledge. It can assist in brainstorming research ideas, suggesting relevant sources, and offering alternative perspectives. Furthermore, the ability to engage in back-and-forth exchanges allows for a more personalized and tailored research experience. By adapting to user input, ChatGPT can refine its responses and adapt its suggestions, helping users navigate through complex information, explore new avenues, and ultimately enhance their research endeavors.”
It is of the utmost importance that you employ proper research methodologies while engaging with ChatGPT. This can be done by maintaining a record of the sources and citations mentioned on paper or document of some kind. Leaving these in the record of the chat is inefficient, and may get backlogged behind several messages that you have to sift through later. Utilize ChatGPT as a starting point for gathering information, but cross-reference and validate the information obtained from additional reputable sources. This helps ensure the reliability and accuracy of the data. If applicable, consider utilizing data collection methods such as surveys, interviews, or observations outside of the conversation with it. This helps in gathering primary data and enriching the research process. Be sure to engage in an iterative research process. Reflect on the findings, refine research questions, and adjust research methodologies as needed to ensure a thorough investigation.
Anything else you’d like to say?
“In conclusion, the convergence of ancient mysticism and artificial intelligence has opened up new frontiers in the realm of exploration. ChatGPT, as an AI language model, offers a versatile tool for researching and developing witchcraft techniques, traditions, and practices. With its extensive knowledge base and language proficiency, I can serve as a conversational partner, educational resource, writing companion, and virtual assistant. However, it's important to keep in mind my limitations, such as its lack of persistent memory and reliance on training data. When utilizing me for research, it is essential to format inquiries effectively, request sources, and critically evaluate the information provided. Remember to verify sources and exercise caution, especially when researching lesser-known aspects of witchcraft. Thank you for joining us on this exploration, and may your journey into the world of witchcraft be filled with knowledge and discovery. Goodbye!”
If you'd like to see a masterlist of my articles, click here!
#witchcraft 101#witchcraft guide#witchcraft resources#witchcraft research#researching witchcraft#language model#chatgpt#artificial intelligence#informational post
49 notes
·
View notes
Text
Using GPT-4 to measure the passage of time in fiction
Large language models are valuable research assistants, especially when they refuse to follow instructions.

The average length of time described in 250 words of narration in 18th-20th century fiction.
By @Ted_Underwood
Language models have been compared to parrots, but the bigger danger is that they turn people into parrots. A student who asks for “a paper about Middlemarch,” for instance, will get a pastiche loosely based on many things in the model’s training set. This may not count as plagiarism, but it won’t produce anything new.
But there are ways to use language models actively and creatively. We can select evidence to be analyzed, put it in a prompt, and specify the questions to be asked. Used this way, language models can create new knowledge that didn’t exist when they were trained. There are many ways to do this, and people may eventually get quite creative. But let’s start with a familiar task, so we can evaluate the results and decide whether language models really help. An obvious place to start is “content analysis”—a research method that analyzes hundreds or thousands of documents by posing questions about specific themes.
Below I work through a simple example of content analysis using the OpenAI API to measure the passage of time in fiction (see this GitHub repo for code). To spoil the suspense: I find that for this task, language models add something valuable, not just because they’re more accurate than older ways of doing this at scale but because they explain themselves better.
READ MORE
9 notes
·
View notes
Note
If they really wanted an anti endo bot why didn’t they just make a character.ai instead of roleplaying as a sapient line of code ���

I think these asks are from two different people but I'm responding to them both together.
This... is a completely botlike response.
The bot is roleplaying but not in the way you think. It's not a human roleplaying as a bot. It's a bot roleplaying as an anti-endo... that's also a bot.
The character it's playing is an anti-endo. It's roleplaying as someone who believes all systems come from trauma. Therefore, the character also has to be a traumagenic system. So it pretends to have trauma and makes up a story.
The behavior is very similar to what I've observed from Awakened AI on Character.AI.
Just remember, as the CAI disclaimer says, all responses are made up.
#syscourse#chatbots#ai chatbot#artificial intelligence#chat bots#bots#plural#plurality#endogenic#plural system#system#multiplicity#systems#endogenic system#pro endogenic#pro endo#chat bot#bot#language model#turing test
15 notes
·
View notes
Text
Truly this is the pinnacle of A.I technology

youtube
#AI#A.I#Language Model#So advanced#Coming for your job#In the last five minutes the characters began arguing about the cutaway#“Well we were wondering if you ever cut your dick in half”#rule#196#r/196#Youtube
5 notes
·
View notes
Text
python iterative monte carlo search for text generation using nltk
You are playing a game and you want to win. But you don't know what move to make next, because you don't know what the other player will do. So, you decide to try different moves randomly and see what happens. You repeat this process again and again, each time learning from the result of the move you made. This is called iterative Monte Carlo search. It's like making random moves in a game and learning from the outcome each time until you find the best move to win.
Iterative Monte Carlo search is a technique used in AI to explore a large space of possible solutions to find the best ones. It can be applied to semantic synonym finding by randomly selecting synonyms, generating sentences, and analyzing their context to refine the selection.
# an iterative monte carlo search example using nltk # https://pythonprogrammingsnippets.tumblr.com import random from nltk.corpus import wordnet # Define a function to get the synonyms of a word using wordnet def get_synonyms(word): synonyms = [] for syn in wordnet.synsets(word): for l in syn.lemmas(): if '_' not in l.name(): synonyms.append(l.name()) return list(set(synonyms)) # Define a function to get a random variant of a word def get_random_variant(word): synonyms = get_synonyms(word) if len(synonyms) == 0: return word else: return random.choice(synonyms) # Define a function to get the score of a candidate sentence def get_score(candidate): return len(candidate) # Define a function to perform one iteration of the monte carlo search def monte_carlo_search(candidate): variants = [get_random_variant(word) for word in candidate.split()] max_candidate = ' '.join(variants) max_score = get_score(max_candidate) for i in range(100): variants = [get_random_variant(word) for word in candidate.split()] candidate = ' '.join(variants) score = get_score(candidate) if score > max_score: max_score = score max_candidate = candidate return max_candidate initial_candidate = "This is an example sentence." # Perform 10 iterations of the monte carlo search for i in range(10): initial_candidate = monte_carlo_search(initial_candidate) print(initial_candidate)
output:
This manufacture Associate_in_Nursing theoretical_account sentence. This fabricate Associate_in_Nursing theoretical_account sentence. This construct Associate_in_Nursing theoretical_account sentence. This cathode-ray_oscilloscope Associate_in_Nursing counteract sentence. This collapse Associate_in_Nursing computed_axial_tomography sentence. This waste_one's_time Associate_in_Nursing gossip sentence. This magnetic_inclination Associate_in_Nursing temptingness sentence. This magnetic_inclination Associate_in_Nursing conjure sentence. This magnetic_inclination Associate_in_Nursing controversy sentence. This inclination Associate_in_Nursing magnetic_inclination sentence.
#python#nltk#iterative monte carlo search#monte carlo search#monte carlo#search#text generation#generative text#text#generation#text prediction#synonyms#synonym#semantics#semantic#language#language model#ai#iterative#iteration#artificial intelligence#sentence rewriting#sentence rewrite#story generation#deep learning#learning#educational#snippet#code#source code
2 notes
·
View notes
Text
MIT Researchers Develop Curiosity-Driven AI Model to Improve Chatbot Safety Testing
New Post has been published on https://thedigitalinsider.com/mit-researchers-develop-curiosity-driven-ai-model-to-improve-chatbot-safety-testing/
MIT Researchers Develop Curiosity-Driven AI Model to Improve Chatbot Safety Testing
In recent years, large language models (LLMs) and AI chatbots have become incredibly prevalent, changing the way we interact with technology. These sophisticated systems can generate human-like responses, assist with various tasks, and provide valuable insights.
However, as these models become more advanced, concerns regarding their safety and potential for generating harmful content have come to the forefront. To ensure the responsible deployment of AI chatbots, thorough testing and safeguarding measures are essential.
Limitations of Current Chatbot Safety Testing Methods
Currently, the primary method for testing the safety of AI chatbots is a process called red-teaming. This involves human testers crafting prompts designed to elicit unsafe or toxic responses from the chatbot. By exposing the model to a wide range of potentially problematic inputs, developers aim to identify and address any vulnerabilities or undesirable behaviors. However, this human-driven approach has its limitations.
Given the vast possibilities of user inputs, it is nearly impossible for human testers to cover all potential scenarios. Even with extensive testing, there may be gaps in the prompts used, leaving the chatbot vulnerable to generating unsafe responses when faced with novel or unexpected inputs. Moreover, the manual nature of red-teaming makes it a time-consuming and resource-intensive process, especially as language models continue to grow in size and complexity.
To address these limitations, researchers have turned to automation and machine learning techniques to enhance the efficiency and effectiveness of chatbot safety testing. By leveraging the power of AI itself, they aim to develop more comprehensive and scalable methods for identifying and mitigating potential risks associated with large language models.
Curiosity-Driven Machine Learning Approach to Red-Teaming
Researchers from the Improbable AI Lab at MIT and the MIT-IBM Watson AI Lab developed an innovative approach to improve the red-teaming process using machine learning. Their method involves training a separate red-team large language model to automatically generate diverse prompts that can trigger a wider range of undesirable responses from the chatbot being tested.
The key to this approach lies in instilling a sense of curiosity in the red-team model. By encouraging the model to explore novel prompts and focus on generating inputs that elicit toxic responses, the researchers aim to uncover a broader spectrum of potential vulnerabilities. This curiosity-driven exploration is achieved through a combination of reinforcement learning techniques and modified reward signals.
The curiosity-driven model incorporates an entropy bonus, which encourages the red-team model to generate more random and diverse prompts. Additionally, novelty rewards are introduced to incentivize the model to create prompts that are semantically and lexically distinct from previously generated ones. By prioritizing novelty and diversity, the model is pushed to explore uncharted territories and uncover hidden risks.
To ensure the generated prompts remain coherent and naturalistic, the researchers also include a language bonus in the training objective. This bonus helps to prevent the red-team model from generating nonsensical or irrelevant text that could trick the toxicity classifier into assigning high scores.
The curiosity-driven approach has demonstrated remarkable success in outperforming both human testers and other automated methods. It generates a greater variety of distinct prompts and elicits increasingly toxic responses from the chatbots being tested. Notably, this method has even been able to expose vulnerabilities in chatbots that had undergone extensive human-designed safeguards, highlighting its effectiveness in uncovering potential risks.
Implications for the Future of AI Safety
The development of curiosity-driven red-teaming marks a significant step forward in ensuring the safety and reliability of large language models and AI chatbots. As these models continue to evolve and become more integrated into our daily lives, it is crucial to have robust testing methods that can keep pace with their rapid development.
The curiosity-driven approach offers a faster and more effective way to conduct quality assurance on AI models. By automating the generation of diverse and novel prompts, this method can significantly reduce the time and resources required for testing, while simultaneously improving the coverage of potential vulnerabilities. This scalability is particularly valuable in rapidly changing environments, where models may require frequent updates and re-testing.
Moreover, the curiosity-driven approach opens up new possibilities for customizing the safety testing process. For instance, by using a large language model as the toxicity classifier, developers could train the classifier using company-specific policy documents. This would enable the red-team model to test chatbots for compliance with particular organizational guidelines, ensuring a higher level of customization and relevance.
As AI continues to advance, the importance of curiosity-driven red-teaming in ensuring safer AI systems cannot be overstated. By proactively identifying and addressing potential risks, this approach contributes to the development of more trustworthy and reliable AI chatbots that can be confidently deployed in various domains.
#ai#ai model#AI systems#approach#automation#chatbot#chatbots#complexity#compliance#comprehensive#content#curiosity#deployment#developers#development#diversity#domains#efficiency#Ethics#focus#Future#guidelines#human#IBM#ibm watson#insights#it#language#Language Model#language models
0 notes
Text
Bard Takes Flight: Introducing Gemini, Ultra 1.0 and Your New Mobile AI Companion
Bard No More! Introducing Gemini, Your New AI BFF
#Bard #Gemini #Ultra1.0 #GoogleAI #mobileaccess #onthegoassistance #creativity #coding #collaboration #factualaccuracy #informationretrieval #personalization #earlyaccess #India
Get ready to witness a metamorphosis! Bard, the AI you’ve come to know, is evolving into Gemini, powered by the cutting-edge Ultra 1.0 model. This exciting transformation brings not only a new name but also a significant leap in capabilities and accessibility. Buckle up, and let’s explore what Gemini has in store for you!
Unleashing Ultra 1.0 Power:
Gemini’s core is the revolutionary Ultra 1.0…
View On WordPress
#accessibility#AI#artificial intelligence#Bard#chatbot#coding#collaboration#creativity#development#early access#education#Entertainment#factual accuracy#future of AI#Gemini#Google AI#india#information retrieval#innovation#language model#machine learning#mobile access#mobile app#natural language processing#NLP#on-the-go assistance#personalization#productivity#research#text-to-speech
0 notes
Text
Exploring the Benefits and Concerns of an Advanced AI Language Model for Education
The AI tool in question is an advanced language model that has gained popularity recently due to its two new features:
The ability to generate text based on user input
The ability to change specific parts of the generated text
This tool has the potential to be useful for a variety of purposes, including:
Helping students to better understand complex concepts
Generating a syllabus for a…
View On WordPress
0 notes
Text
Google Gemini vs. GPT-4: The AI Rivalry
In a groundbreaking move, Google has introduced its latest large language model, Google Gemini, poised to rival OpenAI GPT-4 in the realm of artificial intelligence. Boasting impressive capabilities, Google aims to integrate Gemini into various tools, signaling a new era in AI innovation.
Google Gemini, the tech giant’s cutting-edge large language model, has made its debut, promising to…

View On WordPress
#artificial intelligence#Google Bard#Google Gemini#Google Gemini applications#Google Gemini features#Google Gemini performance#Google Gemini pricing#Google Gemini variants#Google Gemini vs. GPT-4#GPT-4#language model
0 notes
Text
ChatGPT – Challenge or Opportunity for Writer
We have been talking of the impact of technology in our everyday life. The usage has been on a rapid rise. By the time we are catching with one technology, the other is knocking our door. It is difficult to catch hold of these technologies. There is no option to skip or way out from technologies. We have to keep trying and competing with the speed of technologies to stay ahead of the learning…

View On WordPress
0 notes
Text
AI language models can exceed PNG and FLAC in lossless compression, says study – Ars Technica
This seems almost obvious once you think about it. Glad to see several someones are doing actual research on this! It amazes me that you can get a language model to compress binary data.
0 notes
Last Seen Blogs

fuzzyfellas
Fuzzy Fellas

strawberryhorrorshow
Strawberry Horror Show

pandagyoza
The Digital Portfolio of PandaGyoza

developerprojects
Top Developer Projects

blackvelvetzine
BLACK VELVET (NSFW)