#open ai
Text


this reply kills me 😭 article link
69K notes
·
View notes
Text
Also did you know that the reason NYT can sue openAI with the expectation of success is that the AI cites its sources about as well as James Somerton.
It regurgitates long sections of paywalled NYT articles verbatim, and then cites it wrong, if at all. It's not just a matter of stealing traffic and clicks etc, but also illegal redistribution and damaging the NYT's brand regarding journalistic integrity by misquoting or citing incorrectly.
OpenAI cannot claim fair use under these circumstances lmao.
#current events#open ai#openai#capitalism#lawsuits#nyt#new york times#the new york times#Phoenix Talks#copyright#copyright law#james somerton
3K notes
·
View notes
Text

I'M SOBBING
28K notes
·
View notes
Text
this sucks and I hate it

#birds#swearing#bird#illustration#nature#comics#comic#funny#vulgarity#art#midjourney#open ai#fuck that shit#i hate it#capitalist hellscape
929 notes
·
View notes
Text
Please DO NOT use AI to generate fanfic
Not reblogging because I don't want to bash, but a day after hearing that OpenAI has scraped AO3 to train their writing AI, I've just seen a Tumblr post with AI-generated 'fanfic'.
The billions of hours of labour that millions of fanfic writers have given, hoping for nothing in return but comments and kudos, has been taken and used to train a for profit AI owned by Elon Musk. [So many people have nit-picked this, I'm editing to add: while Elon does not outright own this, as I believed at time of writing, based on the info linked, he did INVEST HEAVILY in it. This does not constitute deliberate misinformation and is honestly not that a significant difference FFS.]
This is bad, guys.
It's bad because it's fundamentally wrong, because it endangers fan works, and because it's illegal.
Not illegal in the way that fanfiction is legally questionable but now broadly defensible by highly trained OTW lawyers. Illegal in the way that copyrighted works and characters have been used for profit to create works with Open AI.
It's wrong not just because the works are created without consent from the labour of authors who won't see a penny, but because the aim of AIs like Open AI is to replace the work of professional writers.
You may use Open AI to make a silly fanfic and have a good laugh, but that's not what Elon wants it for.
If you hate what's happened to Twitter, you should be really, really scared about this.
It endangers fanworks because it awakens the power and might of brands like Disney, who have mostly stopped trying to sue fancreators (although they really, really did used to, and not that long ago) for using their IP and especially for writing LGBTQ+ fic. They're mostly willing to turn a blind eye because we aren't making any money.
But that's not what Elon wants to do. And they might start caring again if they see Open AI writing Stucky (follow the link, it writes Stucky omegaverse fic at the merest mention of Steve) and it obviously does so because it used AO3 as its source material.
You and I know it's not any fic writer's fault, but I don't think Disney cares, and it's cheaper to battle AO3 than Elon.
I should stress: AO3 admins are aware. It's been reported. do not clog up their inboxes reporting it again.
The above reasons and more are all arsenal in the armoury of OTW's lawyers. But that's still a battle to fight.
In the meantime, the very least you can do is NOT USE OPEN AI.
Not for a laugh. Not for anything.
And please: spread the word.
4K notes
·
View notes
Note
got anything good, boss?
Sure do!
-
"Weeks after The New York Times updated its terms of service (TOS) to prohibit AI companies from scraping its articles and images to train AI models, it appears that the Times may be preparing to sue OpenAI. The result, experts speculate, could be devastating to OpenAI, including the destruction of ChatGPT's dataset and fines up to $150,000 per infringing piece of content.
NPR spoke to two people "with direct knowledge" who confirmed that the Times' lawyers were mulling whether a lawsuit might be necessary "to protect the intellectual property rights" of the Times' reporting.
Neither OpenAI nor the Times immediately responded to Ars' request to comment.
If the Times were to follow through and sue ChatGPT-maker OpenAI, NPR suggested that the lawsuit could become "the most high-profile" legal battle yet over copyright protection since ChatGPT's explosively popular launch. This speculation comes a month after Sarah Silverman joined other popular authors suing OpenAI over similar concerns, seeking to protect the copyright of their books.
Of course, ChatGPT isn't the only generative AI tool drawing legal challenges over copyright claims. In April, experts told Ars that image-generator Stable Diffusion could be a "legal earthquake" due to copyright concerns.
But OpenAI seems to be a prime target for early lawsuits, and NPR reported that OpenAI risks a federal judge ordering ChatGPT's entire data set to be completely rebuilt—if the Times successfully proves the company copied its content illegally and the court restricts OpenAI training models to only include explicitly authorized data. OpenAI could face huge fines for each piece of infringing content, dealing OpenAI a massive financial blow just months after The Washington Post reported that ChatGPT has begun shedding users, "shaking faith in AI revolution." Beyond that, a legal victory could trigger an avalanche of similar claims from other rights holders.
Unlike authors who appear most concerned about retaining the option to remove their books from OpenAI's training models, the Times has other concerns about AI tools like ChatGPT. NPR reported that a "top concern" is that ChatGPT could use The Times' content to become a "competitor" by "creating text that answers questions based on the original reporting and writing of the paper's staff."
As of this month, the Times' TOS prohibits any use of its content for "the development of any software program, including, but not limited to, training a machine learning or artificial intelligence (AI) system.""
-via Ars Technica, August 17, 2023
#Anonymous#ask#me#open ai#chatgpt#anti ai#ai writing#lawsuit#united states#copyright law#new york times#good news#hope
741 notes
·
View notes
Text
- Tumblr/Wordpress está se preparando para começar a vender nossos dados de usuários para Midjourney e OpenAI. (como ativar a configuração que impede isso)
oi gente! esse tumblr eu geralmente só posto minhas capas, mas eu vi uma notícia recente importante sobre o tumblr e achei importante compartilhar aqui, já que pelo o que eu notei está sendo mais falado na gringa. eu vi isso hoje nesse post > aqui <, então créditos a pessoa @8pxl pelo tutorial. (thank you for sharing this news! 🌼). vou resumir o que tá acontecendo e mostrar como ativar uma configuração que já está disponível, para que seus blogs não sejam afetados por isso.
- o que é OpenAi e Midjourney?
a OpenAi é um laboratório de pesquisa de inteligência artificial estadunidense, tem produtos como o ChatGPT e Dall-E.
o Midjourney é um serviço de inteligência artificial que gera imagens a partir de descrições em linguagem natural, chamadas de prompts.
- o que está acontecendo?
pelo o que eu entendi, recentemente estavam tendo uns rumores de que o Tumblr estaria negociando com a OpenAi e com Midjourney para vender dados de publicações de usuários para treinamento de IA. (de acordo com a > fonte <)
na quarta-feira saiu uma configuração para que os usuários optem por NÃO compartilhar os dados com terceiros, incluindo empresas de IA. e eu vou mostrar aqui como ativar essa configuração.
(vocês podem ler mais sobre aqui: 1 (em português), 2 (em inglês))
- como ativar a configuração?
para ativar a configuração é bem simples, antes de tudo lembrem de ativar em TODOS os blogs vinculados na sua conta, um por um.
1 - entre na sua conta do tumblr pelo navegador (pelo que eu verifiquei, a configuração ainda não está disponível pelo app);
2 - clique nos três tracinhos > vá em conta > clique em configurações do blog:

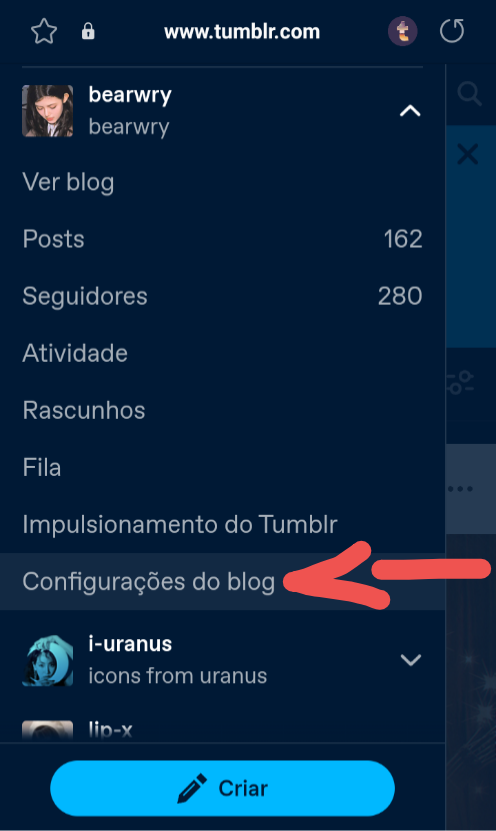
3 - desça até visibilidade > a última opção vai ser essa configuração, "Impedir o compartilhamento de [blog] com terceiros"
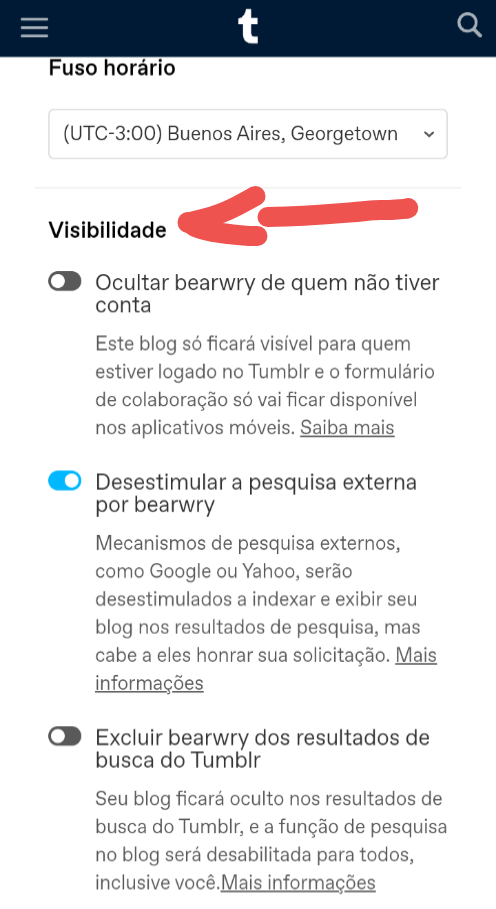
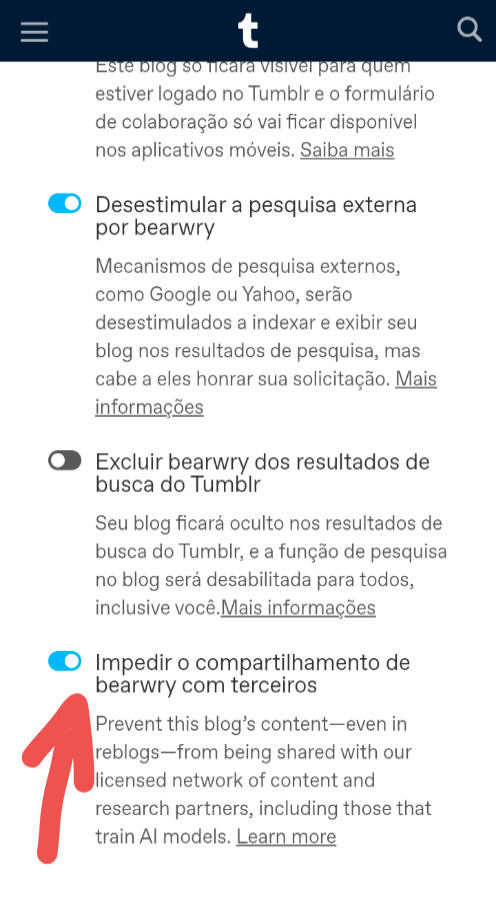
a configuração diz: Evite que o conteúdo deste blog, mesmo em reblogs, seja compartilhado com nossa rede licenciada de conteúdo e parceiros de pesquisa, incluindo aqueles que treinam modelos de IA.
pronto, está ativada! LEMBRANDO: tem que ativar a configuração em cada blog que você tem vinculado na sua conta, ou seja, faça esse processo em todos os blogs que você tem caso não queira ter seus dados de publicações compartilhados.
127 notes
·
View notes
Text
"Open" "AI" isn’t

Tomorrow (19 Aug), I'm appearing at the San Diego Union-Tribune Festival of Books. I'm on a 2:30PM panel called "Return From Retirement," followed by a signing:
https://www.sandiegouniontribune.com/festivalofbooks

The crybabies who freak out about The Communist Manifesto appearing on university curriculum clearly never read it – chapter one is basically a long hymn to capitalism's flexibility and inventiveness, its ability to change form and adapt itself to everything the world throws at it and come out on top:
https://www.marxists.org/archive/marx/works/1848/communist-manifesto/ch01.htm#007
Today, leftists signal this protean capacity of capital with the -washing suffix: greenwashing, genderwashing, queerwashing, wokewashing – all the ways capital cloaks itself in liberatory, progressive values, while still serving as a force for extraction, exploitation, and political corruption.
A smart capitalist is someone who, sensing the outrage at a world run by 150 old white guys in boardrooms, proposes replacing half of them with women, queers, and people of color. This is a superficial maneuver, sure, but it's an incredibly effective one.
In "Open (For Business): Big Tech, Concentrated Power, and the Political Economy of Open AI," a new working paper, Meredith Whittaker, David Gray Widder and Sarah B Myers document a new kind of -washing: openwashing:
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4543807
Openwashing is the trick that large "AI" companies use to evade regulation and neutralizing critics, by casting themselves as forces of ethical capitalism, committed to the virtue of openness. No one should be surprised to learn that the products of the "open" wing of an industry whose products are neither "artificial," nor "intelligent," are also not "open." Every word AI huxters say is a lie; including "and," and "the."
So what work does the "open" in "open AI" do? "Open" here is supposed to invoke the "open" in "open source," a movement that emphasizes a software development methodology that promotes code transparency, reusability and extensibility, which are three important virtues.
But "open source" itself is an offshoot of a more foundational movement, the Free Software movement, whose goal is to promote freedom, and whose method is openness. The point of software freedom was technological self-determination, the right of technology users to decide not just what their technology does, but who it does it to and who it does it for:
https://locusmag.com/2022/01/cory-doctorow-science-fiction-is-a-luddite-literature/
The open source split from free software was ostensibly driven by the need to reassure investors and businesspeople so they would join the movement. The "free" in free software is (deliberately) ambiguous, a bit of wordplay that sometimes misleads people into thinking it means "Free as in Beer" when really it means "Free as in Speech" (in Romance languages, these distinctions are captured by translating "free" as "libre" rather than "gratis").
The idea behind open source was to rebrand free software in a less ambiguous – and more instrumental – package that stressed cost-savings and software quality, as well as "ecosystem benefits" from a co-operative form of development that recruited tinkerers, independents, and rivals to contribute to a robust infrastructural commons.
But "open" doesn't merely resolve the linguistic ambiguity of libre vs gratis – it does so by removing the "liberty" from "libre," the "freedom" from "free." "Open" changes the pole-star that movement participants follow as they set their course. Rather than asking "Which course of action makes us more free?" they ask, "Which course of action makes our software better?"
Thus, by dribs and drabs, the freedom leeches out of openness. Today's tech giants have mobilized "open" to create a two-tier system: the largest tech firms enjoy broad freedom themselves – they alone get to decide how their software stack is configured. But for all of us who rely on that (increasingly unavoidable) software stack, all we have is "open": the ability to peer inside that software and see how it works, and perhaps suggest improvements to it:
https://www.youtube.com/watch?v=vBknF2yUZZ8
In the Big Tech internet, it's freedom for them, openness for us. "Openness" – transparency, reusability and extensibility – is valuable, but it shouldn't be mistaken for technological self-determination. As the tech sector becomes ever-more concentrated, the limits of openness become more apparent.
But even by those standards, the openness of "open AI" is thin gruel indeed (that goes triple for the company that calls itself "OpenAI," which is a particularly egregious openwasher).
The paper's authors start by suggesting that the "open" in "open AI" is meant to imply that an "open AI" can be scratch-built by competitors (or even hobbyists), but that this isn't true. Not only is the material that "open AI" companies publish insufficient for reproducing their products, even if those gaps were plugged, the resource burden required to do so is so intense that only the largest companies could do so.
Beyond this, the "open" parts of "open AI" are insufficient for achieving the other claimed benefits of "open AI": they don't promote auditing, or safety, or competition. Indeed, they often cut against these goals.
"Open AI" is a wordgame that exploits the malleability of "open," but also the ambiguity of the term "AI": "a grab bag of approaches, not… a technical term of art, but more … marketing and a signifier of aspirations." Hitching this vague term to "open" creates all kinds of bait-and-switch opportunities.
That's how you get Meta claiming that LLaMa2 is "open source," despite being licensed in a way that is absolutely incompatible with any widely accepted definition of the term:
https://blog.opensource.org/metas-llama-2-license-is-not-open-source/
LLaMa-2 is a particularly egregious openwashing example, but there are plenty of other ways that "open" is misleadingly applied to AI: sometimes it means you can see the source code, sometimes that you can see the training data, and sometimes that you can tune a model, all to different degrees, alone and in combination.
But even the most "open" systems can't be independently replicated, due to raw computing requirements. This isn't the fault of the AI industry – the computational intensity is a fact, not a choice – but when the AI industry claims that "open" will "democratize" AI, they are hiding the ball. People who hear these "democratization" claims (especially policymakers) are thinking about entrepreneurial kids in garages, but unless these kids have access to multi-billion-dollar data centers, they can't be "disruptors" who topple tech giants with cool new ideas. At best, they can hope to pay rent to those giants for access to their compute grids, in order to create products and services at the margin that rely on existing products, rather than displacing them.
The "open" story, with its claims of democratization, is an especially important one in the context of regulation. In Europe, where a variety of AI regulations have been proposed, the AI industry has co-opted the open source movement's hard-won narrative battles about the harms of ill-considered regulation.
For open source (and free software) advocates, many tech regulations aimed at taming large, abusive companies – such as requirements to surveil and control users to extinguish toxic behavior – wreak collateral damage on the free, open, user-centric systems that we see as superior alternatives to Big Tech. This leads to the paradoxical effect of passing regulation to "punish" Big Tech that end up simply shaving an infinitesimal percentage off the giants' profits, while destroying the small co-ops, nonprofits and startups before they can grow to be a viable alternative.
The years-long fight to get regulators to understand this risk has been waged by principled actors working for subsistence nonprofit wages or for free, and now the AI industry is capitalizing on lawmakers' hard-won consideration for collateral damage by claiming to be "open AI" and thus vulnerable to overbroad regulation.
But the "open" projects that lawmakers have been coached to value are precious because they deliver a level playing field, competition, innovation and democratization – all things that "open AI" fails to deliver. The regulations the AI industry is fighting also don't necessarily implicate the speech implications that are core to protecting free software:
https://www.eff.org/deeplinks/2015/04/remembering-case-established-code-speech
Just think about LLaMa-2. You can download it for free, along with the model weights it relies on – but not detailed specs for the data that was used in its training. And the source-code is licensed under a homebrewed license cooked up by Meta's lawyers, a license that only glancingly resembles anything from the Open Source Definition:
https://opensource.org/osd/
Core to Big Tech companies' "open AI" offerings are tools, like Meta's PyTorch and Google's TensorFlow. These tools are indeed "open source," licensed under real OSS terms. But they are designed and maintained by the companies that sponsor them, and optimize for the proprietary back-ends each company offers in its own cloud. When programmers train themselves to develop in these environments, they are gaining expertise in adding value to a monopolist's ecosystem, locking themselves in with their own expertise. This a classic example of software freedom for tech giants and open source for the rest of us.
One way to understand how "open" can produce a lock-in that "free" might prevent is to think of Android: Android is an open platform in the sense that its sourcecode is freely licensed, but the existence of Android doesn't make it any easier to challenge the mobile OS duopoly with a new mobile OS; nor does it make it easier to switch from Android to iOS and vice versa.
Another example: MongoDB, a free/open database tool that was adopted by Amazon, which subsequently forked the codebase and tuning it to work on their proprietary cloud infrastructure.
The value of open tooling as a stickytrap for creating a pool of developers who end up as sharecroppers who are glued to a specific company's closed infrastructure is well-understood and openly acknowledged by "open AI" companies. Zuckerberg boasts about how PyTorch ropes developers into Meta's stack, "when there are opportunities to make integrations with products, [so] it’s much easier to make sure that developers and other folks are compatible with the things that we need in the way that our systems work."
Tooling is a relatively obscure issue, primarily debated by developers. A much broader debate has raged over training data – how it is acquired, labeled, sorted and used. Many of the biggest "open AI" companies are totally opaque when it comes to training data. Google and OpenAI won't even say how many pieces of data went into their models' training – let alone which data they used.
Other "open AI" companies use publicly available datasets like the Pile and CommonCrawl. But you can't replicate their models by shoveling these datasets into an algorithm. Each one has to be groomed – labeled, sorted, de-duplicated, and otherwise filtered. Many "open" models merge these datasets with other, proprietary sets, in varying (and secret) proportions.
Quality filtering and labeling for training data is incredibly expensive and labor-intensive, and involves some of the most exploitative and traumatizing clickwork in the world, as poorly paid workers in the Global South make pennies for reviewing data that includes graphic violence, rape, and gore.
Not only is the product of this "data pipeline" kept a secret by "open" companies, the very nature of the pipeline is likewise cloaked in mystery, in order to obscure the exploitative labor relations it embodies (the joke that "AI" stands for "absent Indians" comes out of the South Asian clickwork industry).
The most common "open" in "open AI" is a model that arrives built and trained, which is "open" in the sense that end-users can "fine-tune" it – usually while running it on the manufacturer's own proprietary cloud hardware, under that company's supervision and surveillance. These tunable models are undocumented blobs, not the rigorously peer-reviewed transparent tools celebrated by the open source movement.
If "open" was a way to transform "free software" from an ethical proposition to an efficient methodology for developing high-quality software; then "open AI" is a way to transform "open source" into a rent-extracting black box.
Some "open AI" has slipped out of the corporate silo. Meta's LLaMa was leaked by early testers, republished on 4chan, and is now in the wild. Some exciting stuff has emerged from this, but despite this work happening outside of Meta's control, it is not without benefits to Meta. As an infamous leaked Google memo explains:
Paradoxically, the one clear winner in all of this is Meta. Because the leaked model was theirs, they have effectively garnered an entire planet's worth of free labor. Since most open source innovation is happening on top of their architecture, there is nothing stopping them from directly incorporating it into their products.
https://www.searchenginejournal.com/leaked-google-memo-admits-defeat-by-open-source-ai/486290/
Thus, "open AI" is best understood as "as free product development" for large, well-capitalized AI companies, conducted by tinkerers who will not be able to escape these giants' proprietary compute silos and opaque training corpuses, and whose work product is guaranteed to be compatible with the giants' own systems.
The instrumental story about the virtues of "open" often invoke auditability: the fact that anyone can look at the source code makes it easier for bugs to be identified. But as open source projects have learned the hard way, the fact that anyone can audit your widely used, high-stakes code doesn't mean that anyone will.
The Heartbleed vulnerability in OpenSSL was a wake-up call for the open source movement – a bug that endangered every secure webserver connection in the world, which had hidden in plain sight for years. The result was an admirable and successful effort to build institutions whose job it is to actually make use of open source transparency to conduct regular, deep, systemic audits.
In other words, "open" is a necessary, but insufficient, precondition for auditing. But when the "open AI" movement touts its "safety" thanks to its "auditability," it fails to describe any steps it is taking to replicate these auditing institutions – how they'll be constituted, funded and directed. The story starts and ends with "transparency" and then makes the unjustifiable leap to "safety," without any intermediate steps about how the one will turn into the other.
It's a Magic Underpants Gnome story, in other words:
Step One: Transparency
Step Two: ??
Step Three: Safety
https://www.youtube.com/watch?v=a5ih_TQWqCA
Meanwhile, OpenAI itself has gone on record as objecting to "burdensome mechanisms like licenses or audits" as an impediment to "innovation" – all the while arguing that these "burdensome mechanisms" should be mandatory for rival offerings that are more advanced than its own. To call this a "transparent ruse" is to do violence to good, hardworking transparent ruses all the world over:
https://openai.com/blog/governance-of-superintelligence
Some "open AI" is much more open than the industry dominating offerings. There's EleutherAI, a donor-supported nonprofit whose model comes with documentation and code, licensed Apache 2.0. There are also some smaller academic offerings: Vicuna (UCSD/CMU/Berkeley); Koala (Berkeley) and Alpaca (Stanford).
These are indeed more open (though Alpaca – which ran on a laptop – had to be withdrawn because it "hallucinated" so profusely). But to the extent that the "open AI" movement invokes (or cares about) these projects, it is in order to brandish them before hostile policymakers and say, "Won't someone please think of the academics?" These are the poster children for proposals like exempting AI from antitrust enforcement, but they're not significant players in the "open AI" industry, nor are they likely to be for so long as the largest companies are running the show:
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4493900

I'm kickstarting the audiobook for "The Internet Con: How To Seize the Means of Computation," a Big Tech disassembly manual to disenshittify the web and make a new, good internet to succeed the old, good internet. It's a DRM-free book, which means Audible won't carry it, so this crowdfunder is essential. Back now to get the audio, Verso hardcover and ebook:
http://seizethemeansofcomputation.org
If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2023/08/18/openwashing/#you-keep-using-that-word-i-do-not-think-it-means-what-you-think-it-means
Image:
Cryteria (modified)
https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0
https://creativecommons.org/licenses/by/3.0/deed.en
#pluralistic#llama-2#meta#openwashing#floss#free software#open ai#open source#osi#open source initiative#osd#open source definition#code is speech
250 notes
·
View notes
Text
These are statements that can co-exist:
Data scraping methods used to train AI text and image generators should be regulated by governments.
Researchers, journalists, and archivists use the same data scraping for their work, and AI text and image generators also have legitimate ethical uses.
Data scraping is legal in many places and it's not easy for websites with publicly available data to prevent it.
Some people have had/will have their income negatively impacted by AI-generated content. That sucks and they have my sympathy.
It's unethical to fire employees or contractors (or pay them less, etc.) only to replace their work with content from AI text or image generators.
It's shitty that tech bros are making fun of many people's concerns about AI-generated content.
It's shitty that a lot of people are throwing around blanket statements like, "Anyone who uses AI-anything is a thief."
It's likely that most individuals will never be harmed by AI-generated content because such generators do not 'steal' or copy specific works of literature or visual art—it's more like they're taking averages from huge amounts of scraped public data.
I'm concerned about both the data collection methods used to train AI content generators and how much information they have already used for training.
AI text and image generation is not inherently evil, nor are people who use it. It's a technology with many applications and can be used for both ethical and unethical purposes.
Capitalism is unethical.
+++
(no, I don't check my notes, so if you want to call me names for pointing out that this is a complex and nuanced issue, have fun with that)
#ai-generated images#chatgpt#open ai#ai-generated content#capitalism#i'm so very tired of the childishly simplistic takes about this issue i see all over tumblr#like i literally have variations of ai___ filtered so i see less of them#i'm begging you to form your own opinions and stop getting them from the people who yell the loudest#actually go read about how this works and ways that artists and writers use it sparingly in their processes just like other tools
212 notes
·
View notes
Text

The Gays be takin over the AI. Ya hear!! Arrrrg!!!!
#spandex muscle#guys in spandex#hot guys in lycra#gaipirates#gay pirates#gay ai#gay hot#gay bulge#evil gays#gay ai art#ai bulge#gayhunk#the gays#the gay agenda#the gayest#just gay things#man bulge#men in tights#guys in tights#tights bulge#poolside#arrrrrgh#open shirt#open ai#gay fantasy#gay fashion#queer eye#queer artwork#queer pride#gay tights
44 notes
·
View notes
Text

Apparently, if you opt out right now, chances are high that tumblr won't sell your info, but if you decide to do so later, you have to trust big AI companies to honour your request, there isn't a guarantee or regulation for it in place
#frown pouts#ai#open ai#tumblr#automattic#third-party sharing#third party sharing#anti ai#staff#privacy#data privacy#policies#opt out#features
42 notes
·
View notes
Text
I'm getting so sick of seeing AI generated everything online. Bland and boring ChatGPT generated text blurbs. Cringey and unintentionally terrifying AI art made by people who can only draw stick figures that steals from real artists. AI generated influencers run by some a team of insufferable tech bros out in a super gentrified neighborhood in SF that have 100k followers on Instagram. Terrible AI generated music that's only good as a meme (ex. Spongebob Squarepants sings "Billie Jean" by Michael Jackson). AI being infused into everything. New smartphones with AI generative pre-trained transformers. GROK being added to Twitter/X. Search engines being enhanced by AI.
To quote Wikipedia's definition of the Dead Internet Theory
Timothy Shoup of the Copenhagen Institute for Futures Studies stated that, "in the scenario where GPT-3 'gets loose', the internet would be completely unrecognizable."[14] He predicted that in such a scenario, 99% to 99.9% of content online might be AI generated by 2025 to 2030.[14] These predictions have been used as evidence for the dead internet theory.[10]
Looks like Mr. Shoup might have a very good point. I just didn't think it would happen so fast.
#dead internet theory#ai#i hate ai#anti ai#ai is ruining the internet#artificial intelligence#chat gpt#Open AI#Grok#It all sucks
26 notes
·
View notes
Text
What is the function of AI art/writing? I've been asking myself that lately, while thinking of writer strikes, AI scraping of fanfic websites, and ChatGPT being used for school essays. What do its creators and users want out of it? Why, if it is human-curated (programmed), does it feel so inauthentic?
As a writer of both fiction (fanfic) and nonfiction (academia), the work that I produce is a reflection of the world around me, my experiences, and observations of others. The stories I write, and even persuasive academic works, try to grasp what is important to me or what I find is needed, even if it already exists in another form. We don't understand the entire human condition of sadness by reading one sad story - each story, each account, reveals a different dimension of it and invites us to reflect on it.
I'd argue that when we create, whether fiction, nonfiction, art, etc., we invite others to reflect with us, explore with us, and enter into a space we haven't seen before, if only because we cannot enter each others' minds and experience how we experience in each moment. It's an invitation to enter a part of the world that is, by necessity, new to us, even if we re-read, re-see, re-experience it repeatedly because we are ever-changing.
AI can't do this. AI can't invite us to experience, to laugh, cry, get angry, get sad, or explore a dimension of human experience. AI can learn by algorithm and programming, but it cannot and does not feel. It can only regurgitate an amalgam of human experience out of whatever it's given. It's not authentic because it's not human. AI can't experience the joy of brushing your fingers through a cat's fur, or the painful injustice of human suffering, or the absurdity of human follies. It can't experience for itself, so when it "creates" it isn't authentic or satisfying.
Perhaps one day AI will feel more authentic, but there's a fundamental disconnect, in my view, between what feels authentic and what is authentic. I don't even have to understand authenticity in order to recognize or affirm it (contemporary art falls into this category, for me). But AI won't ever be able to say, with the joy of a five year old, the pride of a twentysomething, or learnedness of anyone, at any age, "I made this. Look at it, read it, let me share a part of myself, my spirit, my life with you." AI has no life, no self-reflection, no human authenticity.
The function may be to assist human living, enrich us in some way, but it should only enrich us to the same level as tools might; they are in service to us. We are not in service to it, and we shouldn't try to replace authentic human experience with it, or else I fear we will lose some of the richness that can only be given through the sharing of one person's life with another.
#ai#chatgpt#open ai#machine learning#humanity#on humanity#authenticity#artificial intelligence#writers strike#artists#writers#writing#creativity#ai generated images#ai generated
78 notes
·
View notes
Text

"sometimes ai feel like erisch klapptone"
40 notes
·
View notes
Text
I guess Chat GPT is trying to troll me

For real (╯°□°)╯︵ ┻━┻
Whats that? T^T
#memes#chatgpt#ai#open ai#chat gpt#artificial intelligence#technology#troll#trolls#ai is trolling me
20 notes
·
View notes
Text
Was talking to a teen about ai art yesterday and she said that ai would be able to make ‘better’ art. So I asked, what exactly is ‘better’ art and how would that work? To which she had an answer: ‘if we manage to understand and replicate the mechanism of human creativity, ai will be able to perfect it’. Which is, I think, what lies at the center of this discourse between businessmen and IT specialists (people generally very far away from creating art) and artists. They think that it is, like anything else, a mechanism. A system, like that of a computer. Instead of, you know (and every artist knows), a completely mysterious and unexplored source of passion and inspiration turning itself into something that has never existed before. Instead of a piece of the divine in the human soul. Instead of the equivalency of a dam being opened and your grief and love spilling out onto paper. They think creativity works like mathematics when creativity actually works like prayer. And AI can’t really pray, can it.
#she also said that ai is unlimited but the human mind is limited#so my question was ‘how can a limited mind create something unlimited’#how can man create god#and she never really answered#ai art#ai#anti ai art#anti ai#ai theft#open ai#artificial intelligence#technology#tech#art#creativity#writing#creative writing#filmmaking
20 notes
·
View notes
Last Seen Blogs

ch0ke-m3-lik3-y0u-h8-m3
ch0ke.strngl3.

thearchress
The Archress

junebeats
Lorenzotproductions

katherineofdawn
Princess Katherine of Dawn

phuwportraits
Phuw Portraits