#your art is. absolutely delightful op
Text
Stucky, Fandom Longevity, and "Primacy Bias"
There’s this post that's been floating around the past few days about how the Stucky fandom in its heyday produced fic and art masterpieces like they were all collectively possessed by an unprecedented spirit of creative insanity. It’s a good, fun post and I agree with the person who wrote it. (not rb'ing because I didn't want to hijack their post with something that's only tangentially related).
It was indeed a magical time and the creative output in both quantity and quality in the two-year period following the release of CA:TWS is—with perhaps a few exceptions—unmatched by anything that I’ve seen before and since. However, going through the notes on that post, I noticed something that left me a little irritated and quite frankly sad since it is in congruence with, and to a certain extent the confirmation of something that I’ve been thinking about a lot lately.
For one thing, there are so many people in the notes expressing sentiments along the lines of “it was such a wonderful time; I wish I could go back; I miss these fics; I want to read these fics again,” etc., etc., you get it. And it feels a little silly pointing this out, but…you can just do that? Almost all of these fics are still right there, waiting for you to be (re)read. Yes, a lot of people left the fandom after The Great Devastation of 2019, but their stories didn’t just disappear. It's not like there is now a big, black hole where the Steve/Bucky tag used to be on AO3. So, if you miss these fics and you want to revisit them—just do it. Chances are the authors will be delighted that people are still finding and enjoying their stories all these years later. And—since apparently this needs saying, too, judging from the notes on that post: A lot of people seem to be very concerned with losing ‘coolness points’ for openly admitting that they still miss the ship and often feel tempted to dip their toes back into the Stucky pool. I don’t know how to tell you this, but if someone tries to shame you for simply enjoying or missing something, they are an asshole. Not to mention that all this is happening on tumble.com—'coolness' doesn't exactly live here. And that is a good thing, to be clear. Fandom is not about being cool. It’s about being as enthusiastic, as silly, as absolutely fucking unhinged about the things you love as you want to be. So, stop caring what other people think and enjoy yourself.
The other thing is that there seems to be a pretty widespread misconception that the Stucky fandom hasn’t produced any good fanworks after 2016.
First, that is patently and demonstrably untrue. There is so much incredibly good fanfiction and fanart still out there. Not as much as back in the day, sure, but it still exists. And more is being posted every day! Even some of the OG Big Names are still around. One of the most beloved Stucky series that started all the way back in 2014 was updated as recently as December of last year. The artist, who I believe the op is referring to as creating ‘baroque’ paintings, posted their latest Stucky art not even two months ago.
Second, I find this “primacy bias” more than just a little insulting to the many hardworking and incredibly talented people who are still putting their blood, sweat, and tears into creating for this community. And it’s one thing if people who have long left the fandom believe or say something like this, but it’s frankly irritating when I see people who are still very much active—and therefore definitely should know better—feed into that same false myth. Yes, it sucks that the Stucky ship isn’t as big as it used to be, but that doesn't mean there isn't any 'fresh talent' to be found anymore. I’m also not saying we shouldn’t still celebrate and recommend older works—I do it all the time! And it sure as hell doesn't mean everyone has to reblog absolutely everything all the time, either. Your blog, your rules.
But maybe we should put a little more focus on the good things, on the creators and the community we have now, especially if we want that community to still exist in another ten years. I mean, imagine you’re a person who’s just gotten into the fandom (because yes, there are indeed still new people discovering Stucky all the time) and one of the first things you’re being told is “eh, nice that you're here, but you’re about 7 years late; the big party is already over.” Does that seem like a fun space to hang out in to you?
So. Let’s all—and I do not exclude myself from this because God knows, I love to complain—spend a little less time mourning the ‘good old days’ that are never coming back anyway, and instead focus our attention on enjoying and appreciating both the incredible treasure chest of an archive we have AND the wealth of high-quality art and fic that is still being created by this wonderful community every single day. With this in mind:
🥳🎊Happy Stucky Week 2023!!! 🎊🥳
*I want to make it very clear that this is a general thing that’s been on my mind lately and that I’m trying to work through here—probably not very coherently. I'm not trying to tell anybody 'how to do fandom' and I’m most definitely not vagueposting about any particular incident, person, or group in this fandom. This isn’t a callout post. It’s an I have a lot of thoughts and feelings about this and I don’t know what else do with them post.
#stucky#stucky fanfic#fandom culture#i once again have no idea what to tag this#fanfiction forever#fanart forever
490 notes
·
View notes
Note
Hi there! I recently joined the Ghost fandom and discovered your art, and I wanted to let you know that your work has brought me so much joy! Your drawings are so beautiful (I've reread your Terzomega Valentine's Day comic SO many times!) and I absolutely L O V E your dolls and plushies!!! (I recently got all of the supplies to start doll customizing and seeing you have so much fun with it is hugely inspiring!!) And I can't count how many times I've watched your animatics; they're SO incredibly funny and well made!!!
This is all to say: thank you for making so many wonderful things! Looking forward to what you make next, and I hope you have a fantastic day!!! 😊
(P.S.—I was so happy to see Kalluzeb while I was going through your art tag; they're SUCH a good ship!!!)
(P.P.S.—HELLO FELLOW THE SORCERER'S APPRENTICE (2010) ENJOYER!!!! I've literally only met one other person who has seen that movie 😆)
OP THANK YOU SO MUCH AHHHHHHHHH!!!! delighted to know you enjoyed my work. and for being a sorcerer's apprentice 2010 enjoyer. Horvath my beloved.
thanks again for stopping by, ive read your tags through my notifications and loved every one of them. you made my day 🥺🖤🖤🖤🖤

#ask kabuki#never be afraid to comment on my work guys im am always thrilled to see what you think!!#even if its keyboard smashing of excitement. anything. i love reading your feedback.#keeps me going <3#excentricanthropologist
55 notes
·
View notes
Text
I almost tagged the original before deciding that I do, in fact, like my peace and realizing that the people that make posts like this and the people supporting this viewpoint are the people that would start Internet Beef over my tags so I'll do this on my own post with screenshots of the tags.
Here is the post I'm referencing:
Here are the tags I considered adding but ultimately decided not to:
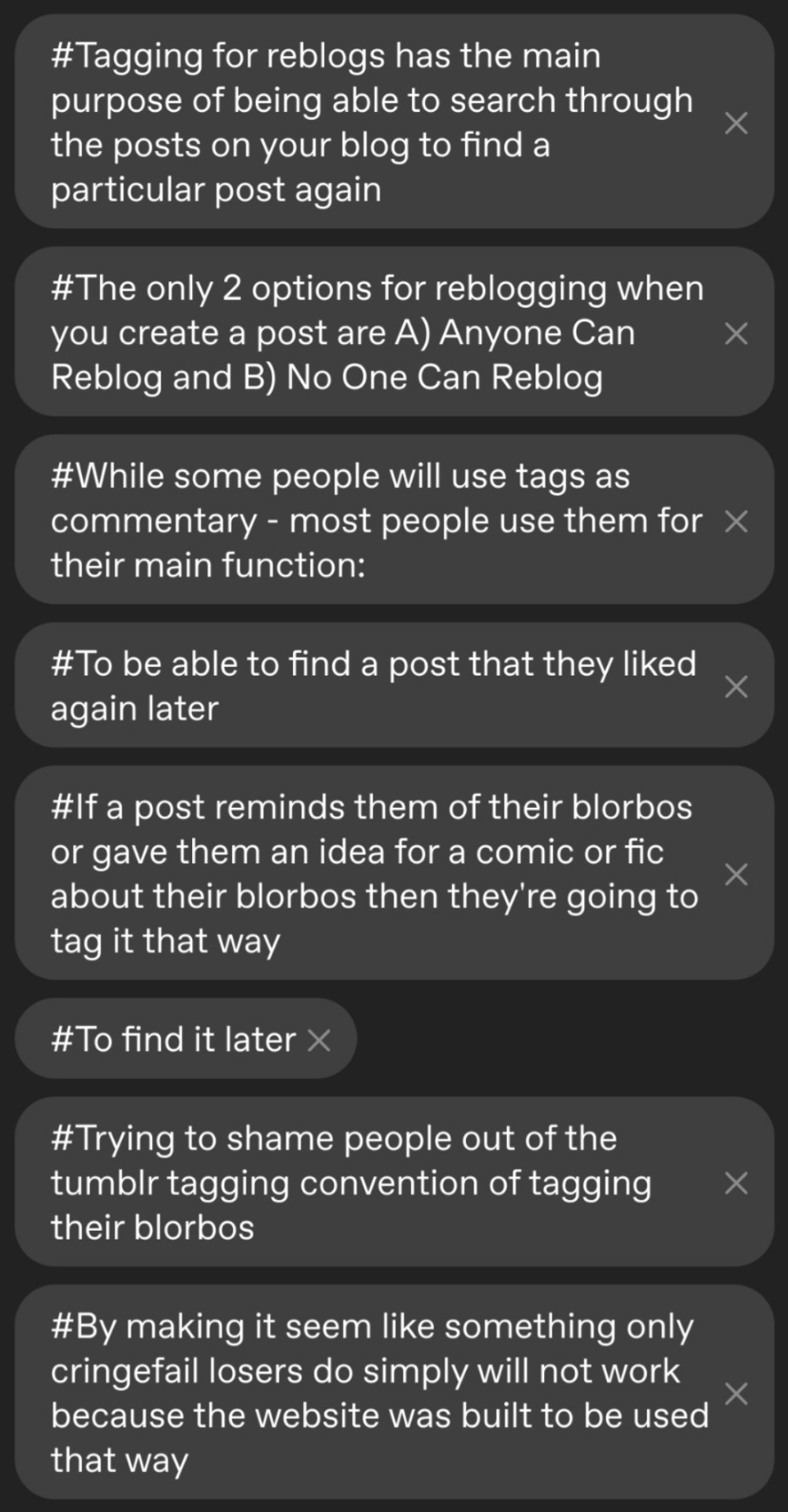
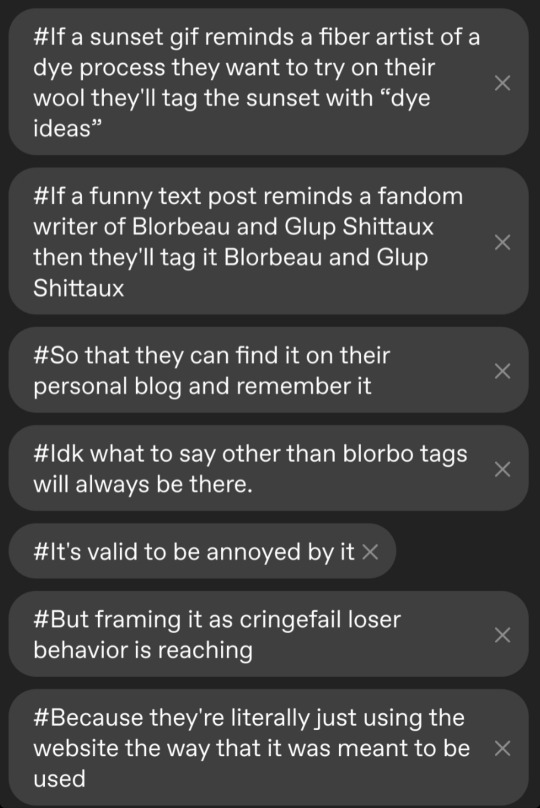
I'm so tired of popular blogs trying to shame the general tumblr populace into not tagging their blorbos because they don't like the borbos that are tagged.
Whats funny is a lot of the popular blogs will then turn around and agree with the general tumblr gripe these days that it sucks that no one reblogs anything anymore.
But like
MY SIBLING IN CHRIST!!!
YOU MADE THE ENVIRONMENT HOSTILE TO REBLOG!!!
WHY WOULD SOMEONE REBLOG A POST IF ANYTIME THEY TAG A RELATABLE POST THEY RISK BEING NEGATIVELY JUDGED AND THEY'LL BE DEEMED A CRINGEFAIL LOSER FOR REBLOGGING WITH TAGS THE OP DIDN'T LIKE?????
I've seen other similar posts, this is just the one that finally annoyed me enough to give my 2 cents.
Like Jesus I wouldn't be following were-ralph if they didn't derail a post with their Werewolf Boyfriend!!! And my tumblr experience would be worse for it! They're hilarious and have great taste in music!
Blorbo tags on relatable posts sometimes lead you to a piece of media or genre of media that you might enjoy.
Like I get that you don't like Blorbeau and Glup Shittaux and find them annoying and that's valid.
But like let people use the website without shame over liking fictional characters. 🙏 please.
ALSO ALSO that made me remember!
I never would have read this post :
If someone didn't blorbo tag!!!
I DON'T EVEN LIKE STAR WARS.
This is a post that somone liked and came up in my feed. I wasn't even following the tags for it but because the tags were made they inspired someone else who delighted someone else enough to create writing and technically art of this silly text post.
And I'm considering watching the prequels along with whatever Commander Cody is in just to get the context for these blorbos because I LAUGHED MYSELF TO TEARS reading this!!!
It was wonderful! And despite my general lifelong passionate disinterest for Space Wizards and their Lazer Swords I absolutely have to see what the fuck is going on with these two!
THIS IS WHAT TUMBLR IS ABOUT!!!!!
Sharing what's cool and fun and funny about your special interests in the hopes that other people will see how cool and fun and funny it is and join you!
That's what this website is built for!!!
11 notes
·
View notes
Text
well, it is star trek update time. last night we watched ds9's "whispers" and tng's "lower decks."
whispers (ds9):
this episode was really really really really good but it sent me into an absolute existential FIT
i don't usually like episodes where they string us along and don't give us enough clues to figure the thing out for ourselves. and that's what this did because really WHO could predict that. however the ending did gut punch me so i forgive them except i never want them to do that to me ever again
red herring with the coffee. he ordered it so many times i was sure there was something in his coffee
i feel so bad for the replicant. i feel SO BAD FOR HIM. also, did you know this is the only time in trek they use the word replicant
action hero obrien, even under false pretenses, was very very very good. he literally can kick ass and he's smart as hell too like he's so cool???
"tell keiko i love her" JESUS CHRIST. anyway!!!!!!!!
lower decks (tng):
this episode was ALSO pretty good...i really loved especially the dual poker games
i also love the waiter in ten forward who got to go to BOTH poker games, king, but where tf is guinan?? i miss her sm
riker is your worst nightmare. alexa play poker face
worf was also very good in this...he loves and supports his little guys so much. siskocore.
picard was as usual the devil incarnate. i cant believe he yelled at this girl just to see if she could take the pressure of a dangerous mission because he had RACIALLY PROFILED HER and then he, who has been tortured by cardassians, let an ensign SEVEN MONTHS INTO HER FIRST ASSIGNMENT do this covert ops shit. AND THEN SHE DIED!!!! i hope he feels bad forever
i liked her so much :( which i know is the point, but
i kind of wish that unlikable guy who was trying to suck up to riker had died instead because that would be a gut punch in a different way
ALSO NURSE OGAWA'S MAN RUNNING AROUND ON HER?? and then beverly is like oh thank god he proposed GIRL that doesn't mean you didn't see him talking to another woman! just bc you let picard do that shit does NOT mean you don't let alyssa know what you saw!!! smh
i'm still not looking forward to the show lower decks...the art style is so fucking ugly and reminds me so much of family guy, the unfunniest show ever to air on television. as in, even south park was funnier. but maybe if the plots are a little like this it will make it slightly easier to tolerate
EDITED TO ADD: i nearly forgot to mention, the vulcan this episode was CHANNELING mister leonard nimoy. i recognized so many of his little acting tics. absolutely delightful.
TONIGHT: ds9's "paradise" and tng's "thine own self" which i know has AMNESIA!!!!!! i've been in bed since i got home from work but i got out of it specifically for this reason. it better be good
7 notes
·
View notes
Note
I love your human Optimus sm, he is so father figure coded its delightful. That being said, how wholesome can he get?
(I love ur art, you're amazing <33333)
THE MOST!!! WHOLESOME!!!!
- Came across Bumblebee dancing ballet by himself on accident one night in a little music room at the base (which is Alpha Trion’s estate) with bay windows all around! Noticed that Bee’s immediate reaction was to try fleeing the scene, but knowing from Bee’s scars that Bee had a BAD childhood, instinctively understood what might have happened for an 18 year old to have that response, and excitedly compliments Bee on Bee’s grace and form (to say this poor lad was taken aback by this absolute whiplash of what USUALLY happens when his bio dad would catch him dancing would be an understatement). Offers to play the piano for Bee (there is one unused there and he hasn’t practiced in years, but he may have just found a reason to start again!) so Bee has music to dance to, and it’s an offer Bee gladly takes up. They make it their thing at least once a week!
- He and Bumblebee play football together!
- Bumblebee runs. A lot. Bee has a STRONG fight or flight instinct and after Bad Nights, Bee tends to run as far as his legs can take him (because bio dad’s promised to hurt you, but first, he must catch you) and often overestimates how much energy he has left to return to base in a timely manner. So OP sometimes trails along and nestles down next to Bee when Bee is half-dead from exhaustion on the grass somewhere and just. Lays there. Talking to Bee. Bee doesn’t have to respond, he just wants to let Bee know he’s always here if Bee ever wants to talk. At some point he offers to piggyback Bee to base when Bee’s cursing his legs stumbling out from under him, and it’s both amusing and very, very bittersweet to feel how firmly Bee is holding on to his shoulders—like this is something Bee has never done before—and the slight dampness in his shoulder Bee has his face buried in.
- OP gifted Bumblebee his pet rabbit, BigWig! Which came with a little rabbit-sized hoodie just like Bee’s which OP commissioned Mirage to make.
- OP helped HotRod with his dyslexia! OP was the one who noticed HotRod had learning difficulties that were never addressed, and it’s not your fault the system failed you—you’re not stupid, you’re not lazy, you think on your feet and have insight beyond your years! He buys graphic novels and comics for HotRod (who did not have access to any of this before and didn’t see any point to it because he’s been labeled a dumbass who can’t write words) and they two often have little reading sessions together!
43 notes
·
View notes
Note
HIIII ROS HI HI HI still truckin througj the last half hour of my shift i was absolutely DELIGHTED 2 SEE UR WILLIAM AND DAKOTA ART THEYRE SO FUCKING CUUUUTE. boys forever i love them
ABYWAY ANYWAY. now that youre in party hell i wanted 2 pick ur brain a little i wanna know ur thoughts . do u have anyyyy theories or thoughts 👀 about vyncents powers or williams dorito fever dream or just in general hehe . putting u in a jar under a magnifying glass and feeding u a drop of plankton water like youre a baby seahorse (<< guy whos seahorses had babies today. proud father momence)
oh my god. gets fucking put in a jar under a magnifying glass blhhhhrghghghghbhgh >_< also OMG........... CONGRATS ON THE SEAHORSE BABIES!!!! what do seahorse babies look like. are they like fully formed or some larval shit like newborn puppies???
anyway YEAH i DO have thoughts!!!! SO many thoughts, even!!
okkk ok ok. about vyncents powers....... first i thought he was some alien superman type situation. because of the whole deal. nowwwww i really do think he reverse isekai'd from like a classic high fantasy jrpg ass world.. i think he like touched the forbidden artifact or got hit by the fantasy truck and got shoved into this world & it sucks. i DONT know if hes human or like some type of creature. about his powers & his fucking multiclass thing???? i have NO CLUE DUDE!!!!! ngl its giving like system egg. ohhh sorry yeah sometimes i just become a whole different person who dresses different and acts different its not a big thing dw about it. or like..... i was considering some type of warlock deal possession situation also but apparently he JUST BECAME the party city warlock?? so i have NO clue.
WILLIAM DORITO FEVER DREAM.. (<- none of these words r in the bible) OK. my first thought IS my head shoots up like a cat hearing the treat bag rustle or like a 2016 emo at the g note at hearing the unravel op......... man i wonder why that specific song for this one specific questionably alive kid with fucked up death powers. this couldnt mean anything!! im sure there arent any impies (fucked up way of saying implications) (GOD the irreparable harm that quencies meme did 2 my vocabulary) anyway my first question about this motherfucker is IS HE DEAD OR NOT. IS HE ALIVE. IS HE IN SOME FUCKED UP LIMINAL STATE BETWEEN THE TWO. schrodingers wiwi. the forest part of the dream sequence stuck out 2 me re: the will-o'-the-wisp-- idk if it's like a textual folkloric thing or my personal associations or what, i dont wanna look it up rn, but i've always associated them with forests + the of course leading astray thing. slightly more meta but also like the uhhhh idiomatic meaning of the phrase as one of the stupid wishful goals u gotta follow even though itll fuck you up? that might b a bit of a reach though since he really is very like textually just. ghost shit. the "man on a paper throne" image DID make me sit up & take note as did the inability 2 turn tangible again but i dont know enough yet 2 make any conjectures!!!! ok ok i thinkkk thats it for noww <3333
#GOD dude i gotta warn u if u ever wanna pick my brain u WILL get like 900 words minimum especially if its about somethin fun like this...#literally all im ever doing is rotating my current guys & plot & such in my head....#here i do go off about it often but thats still usually only ever like +/- 20% of whatever im thinkin about!! so. shrug </3#anyway CATKISS.gif also i love the party hell. its giving bacchanalia its giving dancing plague its great#mac tag!#pd lb
{kind=link}
6 notes
·
View notes
Text
I keep seeing people post an image of Doctor Who with a line calling it British people's One Piece and... eh, I guess somewhat, but also no, not really?
DW at its most politically left leaning, yeah sure, they're a lot alike.
But One Piece is a single coherent story that, despite its length, is working towards a specific end, written by one man who's able to commit to showing his views on how the corrupt system that governs the world destroys it. While Doctor Who is an episodic collaborative series that wants to never end where you can absolutely have an episode written by one person that has that same message of 'corrupt systems destroy those who keep them running', but then have another episode written by a different person that says 'the way Amazon treats its employees is fine and acceptable actually'.
I mean, that mixed bag nature is what I loved about Doctor Who (having an actual work of art one week, a fun pulpy no-thoughts adventure the next, and something to bitch about the following week was a delight), but like, it's not on One Piece's level in the way they're actually comparable.
And One Piece is not really on Doctor Who's level on the one other way they're actually comparable: the time scale. OP has been running less than half as long as DW and finally closing in on its ending. DW is meant to be a never ending semi-tragedy following this immortal demi-god - it's been able to run successfully for an only once broken sixty years and may potentially by one of the few stories out there that might actually get away with never ending.
So no, Doctor Who really isn't British people's One Piece. It's just Doctor Who.
I will say, though, if your favorite parts of Doctor Who is RTD and Moffett's better episodes (which was the corner of the fandom I'd settled into on here back when I was all about that series and I know some of those people still follow me) and you're really looking for the hard stuff now, you should totally give One Piece a try. I know @as-i-watch was into it too, so I think there could be a real DW to OP pipeline here.
As for the people who joined me with One Piece who've never watched Doctor Who... you know what, if you're someone who actually likes the Long Ring Long Island arc and a lot of the anime's filler, I think you might like DW.
14 notes
·
View notes
Note
Seeing as you are quite fond of BloodBorne and the various eyes it tends to layer on peoples brains, what are your thoughts on Elden Ring? (Apologies if this has been asked already)
Also considering FromSoft is putting out Armored Core 6 would you be interested in playing that as well?
(this is a poor attempt to distract you from the horrible dumb shit that Anon sent you, so i send you hugs and questions to help)
DUDE I FUCKING LOVE ELDEN RING, it's my favorite Fromsoft game behind Bloodborne, so much so that I have a canon url blog for it at @lichdragon-fortissax (though I admittedly haven't been posting as much there bc I've been in my Destiny 2 hyperfixation as of late). I adore the story, the characters, the art and the gameplay, and it's where I ended up accidentally making a couple of ocs I'm actually really fond of, which is rare bc I tend to be extremely nitpicky about my own personal content. Bloodborne is a favorite in a sort of spiritual/thematic way but Elden Ring is a fav for it's storytelling, with Ds1 right behind it. I've got so many hours in there and tbh once I'm finished griding out the rest of Season of the Deep I'm considering redownloading it to give my strength and int builds another shot (though I'll probs just co-op Malenia on Fenrix more bc I adore that fight). It's a fucking masterpiece
As for Armoured Core, I just finished watching Vaati and Ironpineapple's videos on it and I'm super stoked to see it in full, though I'm kind of on the fence if I want to get it at full launch or wait to watch a playthrough first, which I did with every game but Elden Ring bc I knew I'd click with it right away (full launch is 5 days before my birthday, so that would be a great present, but still...I'm stingy with money and when to spend it shchfje). I'm not much of a mech guy typically, but I love the bleak nature of the Armoured Core series with their poignant criticism of capitalist corperate systems, and the super-customization aspect of it makes my little strategy-loving brain giddy. I get the feeling that if I do end up playing it I'll just end up tinkering with my build and replaying missions over and over again for the sole purpose of maximizing efficiency for each encounter, bc if there's one thing I love to do, it's find a way to absolutely bulldoze bossfights. It looks sick as hell and I absolutely cannot wait for someone to find the world's most broken build day 1 of the community that comes to dominate the meta before it gets nerfed to hell and back (though tbh I'd be just as delighted if that was a fruitless effort simply because of certain strategies needing certain parts and tactics, as seems to be the idea for the gameplay)
#bl4ck-dr4gon#reply#tysm for this btw it does help#rambling about hyperfixations is like my one happy button other than animals
5 notes
·
View notes
Text
i gotta say, i really don't agree with the whole "likes are meaningless!" idea that gets passed around here.
i love when people like my stuff! it absolutely delights me to know that people saw what i made and enjoyed it!
of course reblogs are even better cuz then more people can see (and therefore like and reblog) what i made but. the end result of that is still just... Number Go Up. and liking a post still makes number go up even if it's only by 1.
everyone has different standards for what they'll reblog. for some, a like without a reblog means "i liked this, but i only reblog things i love", for others it's "i loved this, but i only reblog things i'm absolutely enamored with", for others it's "i liked/loved/was enamored with this, but i have a theme that i stick to on my blog and this doesn't fit". either way, someone enjoyed your post even if it didn't fit their reblog criteria
like, each blog has different levels of activity. some blogs are super active (are on this site very frequently and/or have a very high 'posts reblogged'/'posts viewed' ratio) and they're on your dash all the time. other blogs are super inactive (are on this site very infrequently and/or have very low 'posts reblogged'/'posts viewed' ratio). this is how tumblr works. this is a feature, not a bug.
if everybody followed those "likes mean nothing!!! you MUST reblog more" posts and changed their habits enough to start reblogging 2x as many posts, than everyone's dashboards would have twice as many posts on their dashboard. let's say a tumblr user's dashboard normally has 1,000 posts on it every day, and they spend enough time on here to see 500 of those posts; they see about half of the posts on their dash. now everyone starts reblogging twice as much, so there's 2000 posts on their dash every day, but they're still only seeing 500 of those posts (unless they start spending more time on this hellsite, which is generally not a good idea lmao)
now this is, of course, not accounting for the TYPE of posts that people reblog
cuz it *is* true that low-effort joke posts tend to get more notes than high-effort art/writing posts do.
which, in some ways, that makes sense. jokes have a wider audience, whereas taste in art is very personal. (and sometimes this effect can be amplified by people reblogging stuff based off of what they think their followers will enjoy. they subconsciously think "ha, my followers will get a good laugh out of this, i'll reblog it" when they see a joke they enjoy but "hm, i like this but i don't know if any of my followers will" when they enjoy a piece of art/writing/etc.. which, i advise everyone to try to stop doing this. not out of any Moral Obligation but bc you're gonna have more fun on this hellsite if you treat your blog as a little bin for shiny trinkets you enjoy, rather than as a performance)
and a lot of times, reblogging high-effort posts means much more to the op than reblogging low-effort posts does. like, i enjoy when my silly little jokes get notes but i LOVE when my art or long meta-analysis posts get notes.
so i DO wholeheartedly encourage people to reblog more art and writing and whatnot, rather than just jokes all the time. but do that cuz you WANT TO, not out of some weird sense of guilt
i've seen people say they've stopped liking posts at all if they're not gonna reblog it, cuz they're afraid the op will be offended. and that makes me really sad. please continue to like my posts, even if you don't quite want them on your blog! don't feel bad! it makes me so so happy when i know people saw and enjoyed what i made, even if they don't share it with anyone.
(i am saying this as someone with a fairly active blog, both in terms of original posts and reblogs, and who consciously makes an effort to reblog more art/writing instead of just jokes, and who makes both joke posts and art/writing posts of my own)
#eliot posts#long post#idk i'm just a tiiiny bit salty but also very saddened by that sentiment repeatedly making its way onto my dashboard
24 notes
·
View notes
Note
shit okay so i've finished the lighthouse series finally and i love your characterisation of faroe in it so deeply. wanted to ask - thoughts on what a teenaged faroe would be like? having to interact with normal people and realising how fucking weird her family is, and whatever she remembers of her childhood. she's such a delight and she's such a menace. i wanna know what she'd be like when she's a little older
ohhh, i’m glad you enjoyed and you have absolutely activated my ‘can’t shut up’ trap card! teenage faroe HCs under cut
so I think my big HC for teenage faroe is that she gets really into painting as her preferred mode of art. I like to think arthur did teach her piano, and she likes it well enough, but it didn’t have the same emotional attachment arthur had for it.
nobody can say exactly why this comes about, but john almost reverently describing every piece of art she made as a toddler/child to arthur probably had something to do with it. i also like to think that faroe’s brief time in the Dark World, and especially under the influence of Arthur-Wearing-John’s-Old-Yellow-Robe, has affected her, just a bit - just in that her dreams are a little more vivid, a little more memorable, and little more Out There (leading to John having a small breakdown one day when teenage faroe draws a stunningly good representation of Carcosa, right down to the throne room). she prefers landscapes in general, but the family portrait hanging in arthur and john’s house was definitely painted by Faroe for Arthur’s birthday.
as for personality! I think Faroe is definitely a ‘see an injured baby bird, bring it home’ type of person - and she definitely keeps the curiosity that she inherited from her father. while it was less worrying when she rarely went anywhere without holding onto someone hand, it definitely became more worrying when the adults stopped walking her to school every day. I really love the idea of Faroe’s investigative spirit starting with ‘I’m going to crack the case of The Missing Cookie so I can be a detective just like Daddy’ to ‘ope Faroe’s coming home close to midnight because she was helping a classmate look for a lost cat’. with three detectives in her immediate family, it’s never that hard to find her in Arkham, but doesn’t stop Arthur and John especially from being scared to death. they taught Faroe occult symbols at a pretty young age and Faroe always understood that that was the one thing they would not let her fuck around with.
(I was also so close to including the idea that Arthur gets a seeing eye dog when Faroe is still a child, who Faroe names Goldie. Faroe takes to Goldie so much that they get a second dog just for her [’sweetie, I know you’re having fun playing with Goldie but Goldie has to work now’] - a little white Westie named Bones. this is 100% the adorable animal mascot Faroe investigates with.)
relatedly, I think everyone struggled a lot with Faroe’s growing independence, especially with how close her family is. like, I don’t think Faroe ever had a rebellious phase per se (that is, she was never like ‘fuck you dad I don’t play by your rules’), but she definitely leaned more into ... ‘I Know This Is The Right Thing To Do Why Are You Telling Me I Can’t Do This Because I’m A Child’, which is a lot more frustrating all around.
(still, parker remembers the last time he was called ‘Uncle Bark’ and shifted to only ‘Uncle Parker’ [except when she’s scared or upset].)
i think Faroe might have had a brief period where she became acutely aware (in the way that teenagers are) that her home life is Not The Norm (i used to joke that Faroe, as a child, would say ‘sometimes I stay with Daddy and Mr. John, who kiss, and sometimes I stay with Mama and Uncle Bark, who don’t’). while I don’t think that she ever got badly teased about it [everyone likes Bella, the lady who makes all the costumes for school plays, and everyone likes Mr. Yang, the guy who cheers all the kids on at the baseball game, and everyone is moderately lukewarm on Mr.s Lester and Doe who look kind of pissy but generally mean well], I think the first time Faroe tried to underplay her home situation (maybe she implied Bella and Arthur were married, maybe she pretended like Mr. John wasn’t her dad, per se), John -- unable to hide the emotions on his face -- looked so fucking sad that even Faroe, at 14 years old, was like awwwwwww shit I can’t do that again. Overall though, I do think Faroe borders on being pretty popular among her class. She’s involved in a lot of stuff, Bella handmakes her clothes, and more than a few students in the school have had their family’s cases solved by the Lester/Doe/Yang partnership.
as for what Faroe remembers, I would think (other than her dreams) she doesn’t remember much of her time in the Dark World, or being dead. She doesn’t like swimming much, but that’s more along the lines of Arthur being too anxious to teach her as a child, and thus Faroe learning a little later in life. She remembers a happy home - though the duos lived separately, she remembers them being together so often that it seemed like they all lived together. If she had an emotional problem, she’s more inclined to go to her mother (who sometimes talks to her as if she’s a fellow classmate, and not her daughter) or Mr. John (who seems to get things in ways that Parker and Arthur can’t). If she needs something done, it’s Parker (who seems to know every person in Arkham) or her father (who would move heaven and earth for her, in a way that makes Faroe a liiiiiiiitttle scared to ever have kids. Arthur, god bless, is a little intense).
however, I do think the truth comes out around the time when Faroe is a teenager. Faroe was aware for a while of things not seeming right: her father’s acutely visible scars and bright amber eyes, for one thing. Still, I think they didn’t want to tell her as a child, and she was easily enough distracted from any questions whenever she asked.
It’s only when she becomes a teenager that it starts to become unavoidable. For one thing, she finds Parker Yang’s obituary in a newspaper at the library. She reads the term ‘John Doe’ in a book and, uh-oh, that seems a little weird. And, um. What are all these ‘Police Searching For Arthur Lester, supposed murderer of Parker Yang’ news clippings in the library? And, hang on, if her mother is fifteen years younger than Arthur, then why do they have so many stories of growing up together?
and I think, at some point, they sit her down and tell her all of it. Not the nitty gritty details, not how Arthur got all his scars, but enough for Faroe to realize that most of her family - including herself - was dead, at one point. Enough for Faroe to realize that, oops, one of her dads used to be a god, and maybe her dreams aren’t just dreams.
and of course it’s a lot to take in, and there’s a couple of weeks where Faroe’s basically sleepwalking through life, but her family helps her through it. I think at the end of the day, the thing that helps her most is the thing that her Uncle Parker told her (and the same thing Parker told Arthur, way back when Arthur lost his memory): that no matter how the story went, she was safe and loved, and she had a lot of people making sure she always would be.
thanks for asking!
#i was like 'i need to trim this down' but#i did not#it is funny that even after the end of ALL that i was sitting with a lot of family HCs that simply could not fit in the story#so thank you very much for asking! i always love to ramble but never know the appropriate time to unless i'm asked#faroe her father's daughter beloved. faroe wanting to become a detective when she grows up beloved#faroe painting Bones into the family portrait beloved#faroe getting into trouble at school because she argues too much beloved
8 notes
·
View notes
Text
I am delighted to see all the people on my dashboard who are reblogging that shitty "artists should post new art when" poll with "whenever the fuck they feel like it" in the tags.
The thing is. I know op was probably looking for "advice for optimal engagement to grow my following" but this is. 1) absolutely not the website to chase engagement on (it is fully unpredictable and an ideal window is impossible to nail down and any algorithm they might have Will Never work, consistently or in your favor) and 2) a horrifically toxic line of thinking if you want to actually enjoy making art. There is no actionable advice that anyone could feasibly give on Tumblr to achieve the goal you've set for yourself and I suggest you stop chasing it.
If you make art, you are fully free to post it whenever, wherever you fucking want to. Or not. Old art. New art. Finished art. Art you'll never finish. Polished or unpolished. Post your fucking art. Or don't, I'm not your dad.
3 notes
·
View notes
Note
Hey, I love your art so much and whenever I see it on my dash it’s an absolute friggin delight, whether you’re posting new pieces, or it’s old ones getting reblogged! You’re so right to be focussing on your health and well-being right now, we’ll all still be here delighted to see you once things settle down and get better for you; there’s never any rush or pressure. Really hope things improve for you soon because you really do deserve all the happiness in the world! Do your best to be kind to yourself in the meantime :) thank you for all the epic art and general awesome blogging <3
op 😭 i had to take my time responding to this because when i woke up and saw this in my asks it sent me into tears… thank u so much for your kind words and encouragement… it means so much!! i feel like so much of my time online has been spent stressing about how to produce “content” and i’m trying my darndest to get out of that mindset… so thank u for this… really :) for now y’all will be stuck with scumhorseposting and old art reblogs… and that’s okay <3
4 notes
·
View notes
Text
Welcome!
Welcome to the trauma culture is blog! Unfortunately, I was having issues making a new account with Tumblr so this won't be able to be passed down, probably, but I intend to run it until I'm dead, so that shouldn't be an issue
These rules and tags will probably change a bit as we go, but welcome! Feel free to vent, but because I don't want this to be a negative blog, try to keep the specifics or length to your own posts. We'll probably ride the line between venting and not for a lot of posts. If you don't want to see any of that, block this specific tag, #trauma culture vent
On the other hand, we are always delighted to receive uplifting and supportive asks. Tell us about your progress! Or, if you just want to say something nice :) This is not a vent blog, any and all trauma culture asks are welcome!
If you need to refer to me, you may simply call me op, admin, or mod Angel in case I ever add anyone else or do pass the blog on. I go by all pronouns including neo and throne/throneself
When you're submitting something, start your ask with "trauma culture is", "childhood trauma culture is", "ptsd culture is", etc. You can include "ADHD and trauma culture is" or things like that as well. Don't submit discourse or things that are discriminatory such as being ableist, racist, or queerphobic. If you have any questions, always feel free to ask!
And of course, if there's ever something I didn't tag, mis-tagged, or you think I should add to the tag list, let me know. We want this blog to be as safe as possible, but sometimes that requires input from you too. Again, this post will be constantly updated

~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~

Banner credits:
Pixel art by Softwarning (idk where I'm sorry I found it on Pinterest)
Banners by @cafekitsune
Tag List:
#Trauma culture vent--this is for posts that we feel go into venting territory or are explicitly venting. You can block this tag if you don't want to see those posts.
#agere trauma culture--are for asks pertaining to this blog and the related outside tag. Agere asks are always welcome! Age regression is a great, healthy coping mechanism for trauma (and absolutely NOT a kink/fetish/sex thing)
#Religious trauma culture
#psychiatric trauma culture
#answering questions/angel speaks
#relationship trauma culture--anything that mentions relationships or partners
#suggestive trauma culture--anything that ventures into sexual territory, regardless of the exact content
#nsfw trauma culture--only if we feel something doesn't fit under the suggestive tags. Please don't send anything explicit or overtly sexual
#apathy
#/lh--just for lighthearted asks or anything with nice post scripts
#trauma resources--anything that may be helpful or is worth looking into for anyone using this blog. All of these will come from verified sources, or at least extensive proven success of use
#medical resources--same as the trauma resources tag. I want to use this blog to help people so anything that could help someone in physical danger will go here
#(subject) trauma culture--are for asks pertaining to this blog and the related outside tag
#Adhd trauma culture
#ocd trauma culture
#anxiety trauma culture
#mental health trauma culture
#disability trauma culture
neurodivergent trauma culture
#tw (subject)--for any potentially triggering topics
#tw unreality
#tw abuse
#implied (subject)--same as above but less explicit
#implied pedophilia
#implied domestic violence
#implied abuse
#implied panic attack
#(subject)mention--for specific or potentially triggering subjects mentioned in an ask
#suicide mention
#car crash mention
#violence mention
#therapy mention
#injuries mention
#abuse mention
Anon List: 🦂
About Mods:
Mod Angel: Hi! I'm Angel :) I started this blog for myself and everyone else who needs it. I'd love to include informative and supportive resources on here as well, so be on the lookout for that in the future! I have a special interest in neurology as a whole, but particularly diverse neurology such as mental illness and trauma effects on the brain. I am in school for it and do a lot of my own research outside my degree, but I am not a professional. I will be sure to note if anything I say is my own thoughts or officially/professionally recognized. I go by any pronouns
Rules:
-No racism, homophobia, xenophobia, misogyny, pedophilia, terfs...(extensive list I'll add on as things crop up, but you can all infer what the rest would be) if you have questions or its something related, send it in or message and we'll decide and get back to you
-Please don't send anything explicit or overtly sexual
-any asks, comments or reblogs that are designed to be triggering, negative or aggressive will be deleted. Same with anything inappropriate
-no suicidal ideation or suicidal venting. If it's related to this blog, then that's fine, but this is not a place to express any desire to hurt or kill yourself
0 notes
Text
The Definitive Guide to Adelaide Photo Booth Hire
You've only stumbled upon the coolest Photo display hire provider in Adelaide! Listed below you'll find a large variety of fantastic companies consisting of a brand new workplace, an workplace along with a brand-new designer, a photo booth, craft gallery, gallery presents, and numerous additional. But what concerning your organization? You can explore our collection of Photo series, showrooms, occasions, fine art, and even more. Sporting organization card, company cards, and memory card papers will be an effortless technique to discover Australia's absolute best in Creative.
Simply A Couple of Explanations WHY YOU'LL Enjoy US. In fact, I don't also recognize the purpose. It's essential to be conscious of your personal emotional conditions, when going with anxiety and post-traumatic stress disorder. I recognize that, since I like others, and it's less complicated to be delighted concerning being on your own than feeling unfortunate or angry, but as significantly as what causes this? Yes, there is actually this aspect of being depressing or furious that delivers you to this factor.
Decent Costs We think in fair rates - image cubicle hire doesn't happen low-cost, but our costs ensures you acquire the absolute best solution without damaging the bank. We deliver both a client company possibility and an possibility to meet your requirements. We utilize real-time visitor traffic evaluation to figure out the typical consumer task. We utilize real-time web traffic study to identify the ordinary customer task. We make use of real-time visitor traffic analysis to establish the average customer activity.
ALL NIGHT Tap the services of With up to 6 hrs of hire, our conventional bundle is twice that of the sector criterion - Your visitors will certainly certainly never skip an additional photo-op! We can deal with a much larger variety of customers at a opportunity, so you can intend your day's occasions in breakthrough! Participate in our staff right here and buy yours today: http://www.meetup.com/dakakatakata/ Dakakata is the most assorted team of women I've ever seen.
CUSTOMISED Your encounter with us are going to be entirely unique, we'll customized make your printing theme located on your digital invitation so that everything looks steady. -Custom made electronic invite helped make through our experienced visuals developers. We get our company logo coming from one of our visuals professionals and then produce sure we're in a really good position to obtain the style in purchase. -All of our printed products will happen with our unique style through our own experts.
GREEN & CLEAN All of our awesome props are eco-friendly friendly and hygenically well prepared - Mention no to sharing hats with strangers! We have a brand-new "gift" which gives you a brand new method to tell how much you care! We have included labels of everything from a lovely new "skin" or "gift" to a "first-rate" hat for your new dog – it's just that simple!
EXPERIENCE We've been in the field for a long opportunity, and merely put, we understand what we're doing - You can count on us! In other words, we have been there for you the whole opportunity, and we've seen what we can do and what we require to carry out for our customers. With this brand new version we're receiving smarter and including an whole entire brand-new amount of company and quality. Your satisfaction, and your cash, will aid us help make that occur.
Consumer SERVICE Your joy is our best concern, our group is always satisfied to help and educate you in anyway we may - Ask us anything! - Call us if you require assistance! Email us at (626) 624-4227 or consult with the customer service office to obtain an estimation of our prices & shipping time. Please enter into your e-mail address Thank you.
Higher Premium Our photo-booths are designed and built here in Australia and are completely state-of-the-art - We only utilize the finest of the best! (No one from Australia, or various other nations, or any type of other country should make use of our product.). WE Merely Offer Source . If you would just like to see our picture-booth and item listing listed here, please send us a information and we will certainly send out you his connect with relevant information.

We make it our top priority to remain on leading of the most recent photo-booth technologies. Our electronic cameras go behind the settings, providing unparalleled, high-resolution, high-resolution photographes taken out of the comfort assortment to everyone. We likewise establish our own proprietary image processing program, which makes it possible for us to deliver an entire collection of high-definition digital images from significantly and broad at no price.". "Every picture we make is discussed with the world via our cameras.
0 notes
Text


modern au dates [ pt. 1 ]
characters ⊱ zhongli, xiao, kazuha, childe
warnings ⊱ completely safe! please enjoy!
rating ⊱ sfw
zhongli
this man is so rooted in traditions in a beautiful and romantic way; he definitely plans every single date, based on not just his own preferences, but yours as well
they’re very cliche, stereotypical, and conventional dates—but that makes them no less meaningful, especially from someone as sincere and honest as zhongli
he definitely takes you on your standard, beautiful, candlelit dinners in one of the more higher-end restaurants that you’ve never heard before
but just when you think that’s all you’re going to get out of him, he surprises you by taking you to hole-in-the-walls that are incredibly obscure and unconventional, and absolutely delightful to eat at
you want to try a new hobby? you both do it together as a date, whether it be trying your hand at pottery or learning how to sew
personally, he’d love to try some waltz or ballroom dance lessons for couples
domestic shopping together; just taking you around to small businesses to support the local community, and he treats you to whatever you want while you’re there
cooking dinner together at home and enjoying each other’s company is a date in of itself, and it is so simple, yet so treasured as an experience
xiao
he doesn’t really like being around people, and he generally prefers intimate locations where it can feel like just the two of you. he’s simply more comfortable that way and the privacy allows him to be more vulnerable with you
he enjoys going out to restaurants or teahouses with you, so long as your dining area isn’t in the public eye, and is moreso tucked away and partially invisible
but honestly? the best date with him would be a very cozy date in his living room, where the lights are dimmed out and you two are watching a comfort movie while eating your preferred snacks or ordering take-out
that said, movie theater dates aren’t too bad, actually, because it’s dark enough where he feels more inclined to allow himself to tentatively reach for your hand as the projector rolls
boba tea dates except he’s very shy about admitting his enjoyment of the drink and that said, he’ll never really specifically call it a date, but it’s definitely a date
he would honestly really like playing co-op video games together
it’s a bit silly, but just picking you up in his car and taking you somewhere, even if it’s just giving you a ride to your school or job, feels like a date to him, because it is intimate and memorable and it’s with you
just lying in bed together and talking softly as you relax into each other’s sides is more than enough for him
honestly would do anything you wanted, as long as it fits with his personal desire for privacy and intimacy
late night drives together with good music playing softly on the radio
kazuha
art, music, or film festivals
would definitely take you to very scenic places, like the beach during a particularly vivid and colorful thunderstorm, or through the park while the cherry blossom trees are in full bloom
that said, just scenic walks in general; even if you don’t go anywhere that is a mind-blowing wonder upon the earth, he’d still find something to appreciate about it anyway, even if it’s just your company
even if you’re not the most talented artist, he would absolutely love to try painting or writing together. but if you weren’t comfortable or interested, he’d appreciate having someone he can share his work with, and he strongly encourages that you share whatever you’re passionate about, as well
stargazing together
coffeeshop dates, except its not coffee at all—it is, in fact, tea
wandering through the town together, hand in hand
traveling together, except it is a very relaxed experience instead of a fast-paced, tourist-standard holiday; you likely go to places not as prone to seeing visitors, like small farming villages brimming with an expansive culture of art and music
he’d be curious about visiting museums or art exhibits with you, but has never actually gone to one himself
definitely buys you sentimental trinkets as souvenirs to remind you of each date, like a keychain with a cherry blossom on it to represent that one time you went to the spring festival together, or a flower plucked from one of your nature walks that he dried and pressed into a journal for you to keep forever
childe
the type of guy that shows up at your front door late in the evening with a bunch of flowers and a winning smile, asking if you’d like to go on a date with him
they dates are always this exact amount of spontaneous and impulsive
sometimes he will randomly just call you and ask if you could go with him just to do this one, little thing, that he definitely can do by himself, but of course, he’s not going to do it alone, because he’d much rather do it with you, and frankly, any excuse to be with you is excuse enough for him
he makes very normal things suddenly amazing, heartwarming dates
something as mundane as just having to get his phone screen fixed because it cracked, again, he takes you with him and it’s a day filled with fun, adventure, and mischief as you go on a wild drive to different locations in town, all because he happened to remember, ‘oh, yeah, i wanted to show you this one shop, it sells the coolest halloween decorations...’ and next thing you know, seven hours have been spent hanging out with childe
definitely all about fairs or carnivals; he’d buy a whole bunch of sugary treats for you to try with him, and he’ll happily share as much as you’d like
also would try and win the biggest plushie for you at the carnival games, and he will be unnecessarily (and playfully) competitive about it.
but he always gets extra prizes to give to some random kids who look like they deserve something to cheer them up
radiates the energy of the boyfriend who drives with you at 3 am just to buy some very specific fast food menu item that either of you are craving, and that is a date, no matter what you say
#wisteria moon#zhongli x reader#zhongli x gn!reader#zhongli x gn reader#childe x reader#childe x gn!reader#childe x gn reader#xiao x reader#xiao x gn reader#xiao x gn!reader#kazuha x reader#kazuha x gn reader#kazuha x gn!reader#genshin x reader#genshin impact headcanons#genshin impact scenarios#genshin#impact#genshin impact#modern au#sfw#genshin imagines#genshin scenarios#genshin headcanons#genshin impact imagines
567 notes
·
View notes
Text
frank's image generation model, explained
[See also: github repo, Colab demo]
[EDIT 9/6/22: I wrote this post in January 2022. I've made a number of improvements to this model since then. See the links above for details on what the latest version looks like.]
Last week, I released a new feature for @nostalgebraist-autoresponder that generates images. Earlier I promised a post explaining how the model works, so here it is.
I'll try to make this post as accessible as I can, but it will be relatively technical.
Why so technical? The interesting thing (to me) about the new model is not that it makes cool pictures -- lots of existing models/techniques can do that -- it's that it makes a new kind of picture which no other model can make, as far as I know. As I put it earlier:
As far as I know, the image generator I made for Frank is the first neural image generator anyone has made that can write arbitrary text into the image!! Let me know if you’ve seen another one somewhere.
The model is solving a hard machine learning problem, which I didn't really believe could be solved until I saw it work. I had to "pull out all the stops" to do this one, building on a lot of prior work. Explaining all that context for readers with no ML background would take a very long post.
tl;dr for those who speak technobabble: the new image generator is OpenAI-style denoising diffusion, with a 128x128 base model and a 128->256 superresolution model, both with the same set of extra features added. The extra features are: a transformer text encoder with character-level tokenization and T5 relative position embeddings; a layer of image-to-text and then text-to-image cross-attention between each resnet layer in the lower-resolution parts of the U-Net's upsampling stack, using absolute axial position embeddings in image space; a positional "line embedding" in the text encoder that does a cumsum of newlines; and information about the diffusion timestep injected in two places, as another embedding fed to the text encoder, and injected with AdaGN into the queries of the text-to-image cross-attention. I used the weights of the trained base model to initialize the parts of the superresolution model's U-Net that deal with resolutions below 256.
This post is extremely long, so the rest is under a readmore
The task
The core of my bot is a text generator. It can only see text.
People post a lot of images on tumblr, though, and the bot would miss out on a lot of key context if these images were totally invisible to it.
So, long ago, I let my bot "see" pictures by sending them to AWS Rekognition's DetectText endpoint. This service uses a scene text recognition (STR) model to read text in the image, if it exists. ("STR" is the term for OCR when when the pictures aren't necessarily printed text on paper.)
If Rekognition saw any text in the image, I let the bot see the text, between special delimiters so it knows it's an image.
For example, when Frank read the OP of this post, this is what generator model saw:
#1 fipindustries posted:
i was perusing my old deviant art page and i came across a thing of beauty.
the ultimate "i was a nerdy teen in the mid 2000′s starter pack". there was a challenge in old deviant art where you had to show all the different characters that had inspired an OC of yours. and so i came up with this list
=======
"Inspirations Meme" by Phantos
peter
=======
(This is actually less information than I get back from AWS. It also gives me bounding boxes, telling me where each line of text is in the image. I figured GPT wouldn't be able to do much with this info, so I exclude it.)
Images are presented this way, also, in the tumblr dataset I use to finetune the generator.
As a result, the generator knows that people post images, and it knows a thing or two about what types of images people post in what contexts -- but only through the prism of what their STR transcripts would look like.
This has the inevitable -- but weird and delightful -- result that the generator starts to invent its own "images," putting them in its posts. These invented images are transcripts without originals (!). Invented tweets, represented the way STR would view a screenshot of them, if they existed; enigmatically funny strings of words that feel like transcripts of nonexistent memes; etc.
So, for a long time, I've had a vision of "completing the circuit": generating images from the transcripts, images which contain the text specified in the transcripts. The novel pictures the generator is imagining itself seeing, through the limited prism of STR.
It turns out this is very difficult.
Image generators: surveying the field
We want to make a text-conditioned image generation model, which writes the text into the generated image.
There are plenty of text-conditioned image generators out there: DALL-E, VQGAN+CLIP, (now) GLIDE, etc. But they don't write the text, they just make an image the text describes. (Or, they may write text on occasion, but only in a very limited way.)
When you design a text-conditioned image generation method, you make two nearly independent choices:
How do you generate images at all?
How do you make the images depend on the text?
That is, all these methods (including mine) start with some well-proven approach for generating images without the involvement of text, and then add in the text aspect somehow.
Let's focus on the first part first.
There are roughly 4 distinct flavors of image generator out there. They differ largely in how they provide signal about which image are plausible to the model during training. A survey:
1. VAEs (variational autoencoders).
These have an "encoder" part that converts raw pixels to a compressed representation -- e.g. 512 floating-point numbers -- and a "decoder" part that converts the compressed representation back into pixels.
The compressed representation is usually referred to as "the latent," a term I'll use below.
During training, you tell the model to make its input match its output; this forces it to learn a good compression scheme. To generate a novel image, you ignore the encoder part, pick a random value for the latent, and turn it into pixels with the decoder.
That's the "autoencoder" part. The "variational" part is an extra term in the loss that tries to make the latents fill up their N-dimensional space in a smooth, uniform way, rather than squashing all the training images into small scrunched-up pockets of space here and there. This increases the probability that a randomly chosen latent will decode to a natural-looking image, rather than garbage.
VAEs on their own are not as good at the other methods, but provide a foundation for VQ-autoregressive methods, which are now popular. (Though see this paper)
2. GANs (generative adversarial networks).
Structurally, these are like VAEs without the encoder part. They just have a latent, and a have a decoder that turns the latent into pixels.
How do you teach the decoder what images ought to look like? In a GAN, you train a whole separate model called the "discriminator," which looks at pixels and tries to decide whether they're a real picture or a generated one.
During training, the "G" (generator) and the "D" (discriminator) play a game of cat-and-mouse, where the G tries to fool the D into thinking its pictures are real, and the D tries not to get fooled.
To generate a novel image, you do the same thing as with a VAE: pick a random latent and feed it through the G (here, ignoring the D).
GANs are generally high-performing, but famously finicky/difficult to train.
3. VQVAEs (vector quantized VAEs) + autoregressive models.
These have two parts (you may be noticing a theme).
First, you have a "VQVAE," which is like a VAE, with two changes to the nature of the latent: it's localized, and it's discrete.
Localized: instead of one big floating-point vector, you break the image up into little patches (typically 8x8), and the latent takes on a separate value for each patch.
Discrete: the latent for each patch is not a vector of floating-point numbers. It's an element of a finite set: a "letter" or "word" from a discrete vocabulary.
Why do this? Because, once you have an ordered sequence of discrete elements, you can "do GPT to it!" It's just like text!
Start with (say) the upper-leftmost patch, and generate (say) the one to its immediate right, and then the one to its immediate right, etc.
Train the model to do this in exactly the same way you train GPT on text, except it's seeing representations that your VQVAE came up with.
These models are quite powerful and popular, see (the confusingly named) "VQ-VAE" and "VQ-VAE-2."
They get even more powerful in the form of "VQGAN," an unholy hybrid where the VQ encoder part is trained like a GAN rather than like a VAE, plus various other forbidding bells and whistles.
Somehow this actually works, and in fact works extremely well -- at the current cutting edge.
(Note: you can also just "do GPT" to raw pixels, quantized in a simple way with a palette. This hilarious, "so dumb it can't possibly work" approach is called "Image GPT," and actually does work OK, but can't scale above small resolutions.)
4. Denoising diffusion models.
If you're living in 2021, and you want to be one of the really hip kids on the block -- one of the kids who thinks VQGAN is like, sooooo last year -- then these are the models for you. (They were first introduced in 2020, but came into their own with two OpenAI papers in 2021.)
Diffusion models are totally different from the above. They don't have two separate parts, and they use a radically different latent space that is not really a "compressed representation."
How do they work? First, let's talk about (forward) diffusion. This just means taking a real picture, and steadily adding more random pixel noise to it, until it eventually becomes purely random static.
Here's what this looks like (in its "linear" and "cosine" variants), from OA's "Improved denoising diffusion probabilistic models":

OK, that's . . . a weird thing to do. I mean, if turning dogs into static entertains you, more power to you, your hobby is #valid. But why are we doing it in machine learning?
Because we can train a model to reverse the process! Starting with static, it gradually removes the noise step by step, revealing a dog (or anything).
There are a few different ways you can parameterize this, but in all of them, the model learns to translate frame n+1 into a probability distribution (or just a point prediction) for frame n. Applying this recursively, you recover the first frame from the last.
This is another bizarre idea that sounds like it can't possibly work. All it has at the start is random noise -- this is its equivalent of the "latent," here.
(Although -- since the sampling process is stochastic, unless you use a specific deterministic variant called DDIM -- arguably the random draws at every sampling step are an additional latent. A different random seed will give you a different image, even from the same starting noise.)
Through the butterfly effect, one arrangement of random static gradually "decodes to" a dog, and another one gradually "decodes to" a bicycle, or whatever. It's not that the one patch of RGB static is "more doglike" than the other; it just so happens to send the model on a particular self-reinforcing trajectory of imagined structure that spirals inexorably towards dog.
But it does work, and quite well. How well? Well enough that the 2nd 2021 OA paper on diffusion was titled simply, "Diffusion Models Beat GANs on Image Synthesis."
Conditioning on text
To make an image generator that bases the image on text, you pick one of the approaches above, and then find some way to feed text into it.
There are essentially 2 ways to do this:
The hard way: the image model can actually see the text
This is sort of the obvious way to do it.
You make a "text encoder" similar to GPT or BERT or w/e, that turns text into an encoded representation. You add a piece to the image generator that can look at the encoded representation of the text, and train the whole system end-to-end on text/image pairs.
If you do this by using a VQVAE, and simply feed in the text as extra tokens "before" all the image tokens -- using the same transformer for both the "text tokens" and the VQ "image tokens" -- you get DALL-E.
If you do this by adding a text encoder to a diffusion model, you get . . . my new model!! (Well, that's the key part of it, but there's more)
My new model, or GLIDE. Coincidentally, OpenAI was working on the same idea around the same time as me, and released a slightly different version of it called GLIDE.
(EDIT 9/6/22:
There are a bunch of new models in this category that came out after this post was written. A quick run-through:
OpenAI's DALL-E 2 is very similar to GLIDE (and thus, confusingly, very different from the original DALL-E). See my post here for more detail.
Google's Imagen is also very similar to GLIDE. See my post here.
Stability's Stable Diffusion is similar to GLIDE and Imagen, except it uses latent diffusion. Latent diffusion means you do the diffusion in the latent space of an autoencoder, rather than on raw image pixels.
Google's Parti is very similar to the original DALL-E.
)
-----
This text-encoder approach is fundamentally more powerful than the other one I'll describe next. But also much harder to get working, and it's hard in a different way for each image generator you try it with.
Whereas the other approach lets you take any image generator, and give it instant wizard powers. Albeit with limits.
Instant wizard powers: CLIP guidance
CLIP is an OpenAI text-image association model trained with contrastive learning, which is a mindblowingly cool technique that I won't derail this post by explaining. Read the blog post, it's very good.
The relevant tl;dr is that CLIP looks at texts and images together, and matches up images with texts that would be reasonable captions for them on the internet. It is very good at this. But, this is the only thing it does. It can't generate anything; it can only look at pictures and text and decide whether they match.
So here's what you do with CLIP (usually).
You take an existing image generator, from the previous section. You take a piece of text (your "prompt"). You pick a random compressed/latent representation, and use the generator to make an image from it. Then ask CLIP, "does this match the prompt?"
At this point, you just have some randomly chosen image. So, CLIP, of course, says "hell no, this doesn't match the prompt at all."
But CLIP also tells you, implicitly, how to change the latent representation so the answer is a bit closer to "yes."
How? You take CLIP's judgment, which is a complicated nested function of the latent representation: schematically,
judgment = clip(text, image_generator(latent))
All the functions are known in closed form, though, so you can just . . . analytically take the derivative with respect to "latent," chain rule-ing all the way through "clip" and then through "image_generator."
That's a lot of calculus, but thankfully we have powerful chain rule calculating machines called "pytorch" and "GPUs" that just do it for you.
You move latent a small step in the direction of this derivative, then recompute the derivative again, take another small step, etc., and eventually CLIP says "hell yes" because the picture looks like the prompt.
This doesn't quite work as stated, though, roughly because the raw CLIP gradients can't break various symmetries like translation/reflection that you need to break to get a natural image with coherent pieces of different-stuff-in-different-places.
(This is especially a problem with VQ models, where you assign a random latent to each image patch independently, which will produce a very unstructured and homogeneous image.)
To fix this, you add "augmentations" like randomly cropping/translating the image before feeding it to CLIP. You then use the averaged CLIP derivatives over a sample of (say) 32 randomly distorted images to take each step.
A crucial and highly effective augmentation -- for making different-stuff-in-different-places -- is called "cutouts," and involves blacking out everything in the image but a random rectangle. Cutouts is greatly helpful but also causes some glitches, and is (I believe) the cause of the phenomenon where "AI-generated" images often put a bunch of distinct unrelated versions of a scene onto the same canvas.
This CLIP-derivative-plus-augmentations thing is called CLIP guidance. You can use it with whichever image generator you please.
The great thing is you don't need to train your own model to do the text-to-image aspect -- CLIP is already a greater text-to-image genius than anything you could train, and its weights are free to download. (Except for the forbidden CLIPs, the best and biggest CLIPs, which are OA's alone. But you don't need them.)
(EDIT 9/6/22: since this post was written, the "forbidden CLIPs" have been made available for public use, and have been seeing use for a while in projects like my bot and Stable Diffusion.)
For the image generator, a natural choice is the very powerful VQGAN -- which gets you VQGAN+CLIP, the source of most of the "AI-generated images" you've seen papered all over the internet in 2021.
You know, the NeuralBreeders, or the ArtBlenders, or whatever you're calling the latest meme one. They're all just VQGAN+CLIP.
Except, sometimes they're a different thing, pioneered by RiversHaveWings: CLIP-guided diffusion. Which is just like VQGAN+CLIP, except instead of VQGAN, the image generator is a diffusion model.
(You can also do something different called CLIP-conditioned diffusion, which is cool but orthogonal to this post)
Writing text . . . ?
OK but how do you get it to write words into the image, though.
None of the above was really designed with this in mind, and most of it just feels awkward for this application.
For instance...
Things that don't work: CLIP guidance
CLIP guidance is wonderful if you don't want to write the text. But for writing text, it has many downsides:
CLIP can sort of do some basic OCR, which is neat, but it's not nearly good enough to recognize arbitrary text. So, you'd have to finetune CLIP on your own text/image data.
CLIP views images at a small resolution, usually 224x224. This is fine for its purposes, but may render some text illegible.
Writing text properly means creating a coherent structure of parts in the image, where their relation in space matters. But the augmentations, especially cutouts, try to prevent CLIP from seeing the image globally. The pictures CLIP actually sees will generally be crops/cutouts that don't contain the full text you're trying to write, so it's not clear you even want CLIP to say "yes." (You can remove these augmentations, but then CLIP guidance loses its magic and starts to suck.)
I did in fact try this whole approach, with my own trained VQVAE, and my own finetuned CLIP.
This didn't really work, in exactly the ways you'd expect, although the results were often very amusing. Here's my favorite one -- you might even be able to guess what the prompt was:

OK, forget CLIP guidance then. Let's do it the hard way and use a text encoder.
I tried this too, several times.
Things that don't work: DALL-E
I tried training my own DALL-E on top of the same VQVAE used above. This was actually the first approach I tried, and where I first made the VQVAE.
(Note: that VQVAE itself can auto-encode pictures from tumblr splendidly, so it's not the problem here.)
This failed more drastically. The best I could ever get was these sort of "hieroglyphics":

This makes sense, given that the DALL-E approach has steep downsides of its own for this task. Consider:
The VQVAE imposes an artificial "grain" onto the image, breaking it up into little patches of (typically) 8x8 pixels. When text is written in an image, the letters could be aligned anywhere with respect to this "grain."
The same letters will look very different if they're sitting in the middle of a VQ patch, vs. if they're sitting right on the edge between two, or mostly in one patch and partly in another. The generator has to learn the mapping from every letter (or group of letters) to each of these representations. And then it has to do that again for every font size! And again for every font!
Learning to "do GPT" on VQ patches is generally just harder than learning to do stuff on raw pixels, since the relation to the image is more abstract. I don't think I had nearly enough data/compute for a VQ-autoregressive model to work.
Things that don't work: GANs with text encoders
OK, forget DALL-E . . . uh . . . what if we did a GAN, I guess?? where both the G and the D can see the encoded text?
This was the last thing I tried before diffusion. (StyleGAN2 + DiffAug, with text encoder.) It failed, in boring ways, though I tried hard.
GANs are hard to train and I could never get the thing to "use the text" properly.
One issue was: there is a lot of much simpler stuff for the G and D to obsess over, and make the topic of their game, before they have to think about anything as abstract as text. So you have to get pretty far in GAN training for the point where the text would matter, and only at that point does the text encoder start being relevant.
But I think a deeper issue was that VAE/GAN-style latent states don't really make sense for text. I gave the G both the usual latent vector and a text encoding, but this effectively implies that every possible text should be compatible with every possible image.
For that to make sense, the latent should have a contextual meaning conditional on the text, expressing a parameterization of the space of "images consistent with this text." But that intuitively seems like a relatively hard thing for an NN to learn.
Diffusion
Then I was on the EleutherAI discord, and RiversHaveWings happened to say this:
And I though, "oh, maybe it's time for me to learn this new diffusion stuff. It won't work, but it will be educational."
So I added a text encoder to a diffusion model, using cross-attention. Indeed, it didn't work.
Things that don't work: 256x256 diffusion
For a long time, I did all my diffusion experiments at 256x256 resolution. This seemed natural: it was the biggest size that didn't strain the GPU too much, and it was the smallest size I'd feel OK using in the bot. Plus I was worried about text being illegible at small resolutions.
For some reason, I could never get 256x256 text writing to work. The models would learn to imitate fonts, but they'd always write random gibberish in them.
I tried a bunch of things during this period that didn't fix the problem, but which I still suspect were very helpful later:
Timestep embeddings: at some point, RiversHaveWings pointed out that my text encoder didn't know the value of the diffusion timestep. This was bad b/c presumably you need different stuff from the text at different noise levels. I added that. Also added some other pieces like a "line embedding," and timestep info injected into the cross-attn queries.
Line embeddings: I was worried my encoder might have trouble learning to determine which tokens were on which line of text. So I added an extra positional embedding that expresses how many newlines have happened so far.
Synthetic data: I made a new, larger synthetic, grayscale dataset of text in random fonts/sizes on flat backgrounds of random lightness. This presented the problem in a much crisper, easier to learn form. (This might have helped if I'd had it for the other approaches, although I went back and tried DALL-E on it and still got hieroglyphics, so IDK.)
Baby's first words: 64x64 diffusion
A common approach with diffusion models is to make 2 of them, one at low resolution, and one that upsamples low-res images to a higher resolution.
At wit's end, I decided to try this, with train a 64x64 low-res model. I trained it with my usual setup, and . . .
. . . it can write!!!
It can write, in a sense . . . but with misspellings. Lots of misspellings. Epic misspellings.
One of my test prompts, which I ran on all my experimental models for ease of comparison, was the following (don't ask):
the
what string
commit
String evolved
LEGGED
Here are two samples from the model, both with this prompt. (I've scaled them up in GIMP just so they're easier to see, which is why they're blurry.)


Interestingly, the misspellings vary with the conditioning noise (and the random draws during sampling since I'm not using DDIM). The model has "overly noisy/uncertain knowledge" as opposed to just being ignorant.
Spelling improves: relative positional embeddings
At this point, I was providing two kinds of position info to the model:
- Which line of text is this? (line embedding)
- Which character in the string is this, counting from the first one onward? (Absolute pos embedding)
I noticed that the model often got spelling right near the beginning of lines, but degraded later in them. I hypothesized that it was having trouble reconstructing relative position within a line from the absolute positions I was giving it.
cfoster0 on discord suggested I try relative positional embeddings, which together with the line embedding should convey the right info in an easy-to-use form.
I tried this, using the T5 version of relative positional embeddings.
This dramatically improved spelling. Given that test prompt, this model spelled it exactly right in 2 of 4 samples I generated:


I showed off the power of this new model by thanking discord user cfoster0 for their suggestion:

(At some point slightly before this, I also switched from a custom BPE tokenizer to character-level tokenization, which might have helped.)
Doing it for real: modeling text in natural images
OK, we can write text . . . at least, in the easiest possible setting: tiny 64x64 images that contain only text on a flat background, nothing else.
The goal, though, is to make "natural" images that just so happen to contain text.
Put in a transcript of a tweet, get a screenshot of a tweet. Put in a brief line of text, get a movie still with the text as the subtitle, or a picture of a book whose the text is the title, or something. This is much harder:
I have fewer real tumblr images (around 169k) than synthetic text images (around 407k, and could make more if needed)
The real data is much more diverse and complex
The real data introduces new ways the image can depend on the text
Much of the real data is illegible at 64x64 resolution
Let's tackle the resolution issue first. On the synthetic data, we know 64x64 works, and 256x256 doesn't work (even with relative embeds.)
What about 128x128, though? For some reason, that works just as well as 64x64! It's still small, and ideally I'd want to make images bigger than that, but it makes legibility less of a concern.
OK, so I can generate text that looks like the synthetic dataset, at 128x128 resolution. If I just . . . finetune that model on my real dataset, what happens?
It works!
The model doesn't make recognizable objects/faces/etc most of the time, which is not surprising given the small size and diverse nature of the data set.
But it does learn the right relationships between text and image, without losing its ability to write text itself. It does misspell things sometimes, about as often as it did on the synthetic data, but that seems acceptable.
Here's a generated tweet from this era:

The prompt for this was a real STR transcript of this tweet. (Sorry about the specific choice of image here, it's just a tweet that ended up in my test split and was thus a useful testing prompt)
At this point, I was still doing everything in monochrome (with monochrome noise), afraid that adding color might screw things up. Does it, though?
Nope! So I re-do everything in color, although the synthetic font data is still monochrome (but now diffused with RGB noise). Works just as well.
(Sometime around this point, I added extra layers of image-to-text cross-attn before each text-to-image one, with an FF layer in the middle. This was inspired by another cfoster0 suggestion, and I thought it might help the model use image context to guide how it uses the text.
This is called "weave attn" in my code. I don't know if it's actually helpful, but I use it from here on.)
One last hurdle: embiggening
128x128 is still kinda small, though.
Recall that, when I originally did 64x64, the plan was to make a second "superresolution" model later to convert small images into bigger ones.
(You do this, in diffusion, by simply giving the model the [noiseless] low-res image as an extra input, alongside the high-res but noised image that is an input to any diffusion model. In my case, I also fed it the text, using the same architecture as elsewhere.)
How was that going? Not actually that well, even though it felt like the easy part.
My 128 -> 256 superresolution models would get what looked like great metrics, but when I looked at the upsampled images, they looked ugly and fuzzy, a lot like low-quality JPEGs.
I had warm-started the text encoder part of the super-res model with the encoder weights from the base model, so it should know a lot about text. But it wasn't very good at scaling up small, closely printed text, which is the most important part of its job.
I had to come up with one additional trick, to make this last part work.
My diffusion models use the standard architecture for such models, the "U-net," so called for its U shape.
It takes the image, processes it a bit, and then downsamples it to half the resolution. It processed it there, then downsamples it again, etc -- all the way down to 8x8. Then it goes back up again, to 16x16, etc. When it reaches the original resolution, it spits out its prediction for the noise.
Therefore, most of the structure of my 256-res model looks identical to the structure of my 128-res model. Only it's "sandwiched" between a first part that downsamples from 256, and a final part that upsamples to 256.
The trained 128 model knows a lot about how these images tend to look, and about writing text. What if I warm-start the entire middle of the U-Net with weights of the 128 model?
That is, at initialization, my 256 super-res model would just be my 128 model sandwiched inside two extra parts, with random weights for the "bread" only.
I can imagine lots of reasons this might not work, but it was easy to try, and in fact it did work!
Super-res models initialized in this way rapidly learned to do high-quality upsampling, both of text and non-text image elements.
At this point, I had the model (or rather, the two models) I would deploy in the bot.
Using it in practice: rejection sampling
To use this model in practice, the simplest workflow would be:
Generate a single 128x128 image from the prompt
Using the prompt and the 128x128 image, upsample to 256x256
We're done
However, recall that we have access to STR model, which we can ask to read images.
In some sense, the point of all this work is to "invert" the STR model, making images from STR transcripts. If this worked perfectly, feeding the image we make through STR would always return the original prompt.
The model isn't that good, but we can get it closer by using this workflow instead:
Generate multiple 128x128 images from the prompt
Read all the 128x128 images with STR
Using some metric like n-gram similarity, measure how close the transcripts are to the original prompt, and remove the "worst" images from the batch
Using the prompt and the 128x128 images that were kept in step 3, upsample 256x256
Feed all the 256x256 images through STR
Pick the 256x256 image that most closely matches the prompt
We're done
For step 3, I use character trigram similarity and a slightly complicated pruning heuristic with several thresholds. The code for this is here.
Why did diffusion work?
A few thoughts on why diffusion worked for this problem, unlike anything else:
- Diffusion doesn't have the problem that VQ models have, where the latent exists on an arbitrary grid, and the text could have any alignment w/r/t the grid.
- Unlike VQ models, and GAN-type models with a single vector latent, the "latent" in diffusion isn't trying to parameterize the manifold of plausible images in any "nice" way. It's just noise.
Since noise works fine without adding some sort of extra "niceness" constraint, we don't have to worry about the constraint being poorly suited to text.
- During training, diffusion models take partially noised real images as inputs, rather than getting a latent and having to invent the entire image de novo. And it only gets credit for making this input less noised, not for any of the structure that's already there.
I think this helps it pick up nuances like "what does the text say?" more quickly than other models. At some diffusion timesteps, all the obvious structure (that other models would obsess over) has already been revealed, and the only way to score more points is to use nuanced knowledge.
In a sense, diffusion learns the hard stuff and the easy stuff in parallel, rather than in stages like other models. So it doesn't get stuck in a trap where it over-trains itself to one stage, and then can't learn the later stages, because the loss landscape has a barrier in between (?). I don't know how to make this precise, but it feels true.
Postscript: GLIDE
Three days before I deployed this work in the bot, OpenAI released its own text-conditioned diffusion model, called GLIDE. I guess it's an idea whose time has come!
Their model is slightly different in how it joins the text encoder to the U-net. Instead of adding cross-attn, it simply appends the output of the text encoder as extra positions in the standard attention layers, which all diffusion U-Nets have in their lower-resolution middle layer(s).
I'm not sure if this would have worked for my problem. (I don't know because they didn't try to make their model write text -- it models the text-image relation more like CLIP and DALL-E.)
In any event, it makes bigger attn matrices than my approach, of size (text_len + res^2)^2 rather than my (text_len * res^2). The extra memory needed might be prohibitive for me in practice, not sure.
I haven't tried their approach, and it's possible it would beat mine in a head-to-head comparison on this problem. If so, I would want to use theirs instead.
The end
Thanks for reading this giant post!
Thanks again to people in EleutherAI discord for help and discussion.
You can see some of the results in this tag.
106 notes
·
View notes
Last Seen Blogs

miyahex
spellbound

yuusaku-fujiki
Into the VRAINS

thuocbacgiatruyenaphaco-blog
thuốc bắc gia truyền

couplecuckoldfun
Cuckold Sex India |Genuine Couple| Cam Sex | Real Meetings

mosegaardurquhart
The Journey of Farley 693