#human in the loop
Text
Cigna’s nopeinator

I'm touring my new, nationally bestselling novel The Bezzle! Catch me THURSDAY (May 2) in WINNIPEG, then Calgary (May 3), Vancouver (May 4), Tartu, Estonia, and beyond!

Cigna – like all private health insurers – has two contradictory imperatives:
To keep its customers healthy; and
To make as much money for its shareholders as is possible.
Now, there's a hypothetical way to resolve these contradictions, a story much beloved by advocates of America's wasteful, cruel, inefficient private health industry: "If health is a "market," then a health insurer that fails to keep its customers healthy will lose those customers and thus make less for its shareholders." In this thought-experiment, Cigna will "find an equilibrium" between spending money to keep its customers healthy, thus retaining their business, and also "seeking efficiencies" to create a standard of care that's cost-effective.
But health care isn't a market. Most of us get our health-care through our employers, who offer small handful of options that nevertheless manage to be so complex in their particulars that they're impossible to directly compare, and somehow all end up not covering the things we need them for. Oh, and you can only change insurers once or twice per year, and doing so incurs savage switching costs, like losing access to your family doctor and specialists providers.
Cigna – like other health insurers – is "too big to care." It doesn't have to worry about losing your business, so it grows progressively less interested in even pretending to keep you healthy.
The most important way for an insurer to protect its profits at the expense of your health is to deny care that your doctor believes you need. Cigna has transformed itself into a care-denying assembly line.
Dr Debby Day is a Cigna whistleblower. Dr Day was a Cigna medical director, charged with reviewing denied cases, a job she held for 20 years. In 2022, she was forced out by Cigna. Writing for Propublica and The Capitol Forum, Patrick Rucker and David Armstrong tell her story, revealing the true "equilibrium" that Cigna has found:
https://www.propublica.org/article/cigna-medical-director-doctor-patient-preapproval-denials-insurance
Dr Day took her job seriously. Early in her career, she discovered a pattern of claims from doctors for an expensive therapy called intravenous immunoglobulin in cases where this made no medical sense. Dr Day reviewed the scientific literature on IVIG and developed a Cigna-wide policy for its use that saved the company millions of dollars.
This is how it's supposed to work: insurers (whether private or public) should permit all the medically necessary interventions and deny interventions that aren't supported by evidence, and they should determine the difference through internal reviewers who are treated as independent experts.
But as the competitive landscape for US healthcare dwindled – and as Cigna bought out more parts of its supply chain and merged with more of its major rivals – the company became uniquely focused on denying claims, irrespective of their medical merit.
In Dr Day's story, the turning point came when Cinga outsourced pre-approvals to registered nurses in the Philippines. Legally, a nurse can approve a claim, but only an MD can deny a claim. So Dr Day and her colleagues would have to sign off when a nurse deemed a procedure, therapy or drug to be medically unnecessary.
This is a complex determination to make, even under ideal circumstances, but Cigna's Filipino outsource partners were far from ideal. Dr Day found that nurses were "sloppy" – they'd confuse a mother with her newborn baby and deny care on that grounds, or confuse an injured hip with an injured neck and deny permission for an ultrasound. Dr Day reviewed a claim for a test that was denied because STI tests weren't "medically necessary" – but the patient's doctor had applied for a test to diagnose a toenail fungus, not an STI.
Even if the nurses' evaluations had been careful, Dr Day wanted to conduct her own, thorough investigation before overriding another doctor's judgment about the care that doctor's patient warranted. When a nurse recommended denying care "for a cancer patient or a sick baby," Dr Day would research medical guidelines, read studies and review the patient's record before signing off on the recommendation.
This was how the claims denial process is said to work, but it's not how it was supposed to work. Dr Day was markedly slower than her peers, who would "click and close" claims by pasting the nurses' own rationale for denying the claim into the relevant form, acting as a rubber-stamp rather than a skilled reviewer.
Dr Day knew she was slower than her peers. Cigna made sure of that, producing a "productivity dashboard" that scored doctors based on "handle time," which Cigna describes as the average time its doctors spend on different kinds of claims. But Dr Day and other Cigna sources say that this was a maximum, not an average – a way of disciplining doctors.
These were not long times. If a doctor asked Cigna not to discharge their patient from hospital care and a nurse denied that claim, the doctor reviewing that claim was supposed to spend not more than 4.5 minutes on their review. Other timelines were even more aggressive: many denials of prescription drugs were meant to be resolved in fewer than two minutes.
Cigna told Propublica and The Capitol Forum that its productivity scores weren't based on a simple calculation about whether its MD reviewers were hitting these brutal processing time targets, describing the scores as a proprietary mix of factors that reflected a nuanced view of care. But when Propublica and The Capitol Forum created a crude algorithm to generate scores by comparing a doctor's performance relative to the company's targets, they found the results fit very neatly into the actual scores that Cigna assigned to its docs:
The newsrooms’ formula accurately reproduced the scores of 87% of the Cigna doctors listed; the scores of all but one of the rest fell within 1 to 2 percentage points of the number generated by this formula. When asked about this formula, Cigna said it may be inaccurate but didn’t elaborate.
As Dr Day slipped lower on the productivity chart, her bosses pressured her bring her score up (Day recorded her phone calls and saved her emails, and the reporters verified them). Among other things, Dr Day's boss made it clear that her annual bonus and stock options were contingent on her making quota.
Cigna denies all of this. They smeared Dr Day as a "disgruntled former employee" (as though that has any bearing on the truthfulness of her account), and declined to explain the discrepancies between Dr Day's accusations and Cigna's bland denials.
This isn't new for Cigna. Last year, Propublica and Capitol Forum revealed the existence of an algorithmic claims denial system that allowed its doctors to bulk-deny claims in as little as 1.2 seconds:
https://www.propublica.org/article/cigna-pxdx-medical-health-insurance-rejection-claims
Cigna insisted that this was a mischaracterization, saying the system existed to speed up the approval of claims, despite the first-hand accounts of Cigna's own doctors and the doctors whose care recommendations were blocked by the system. One Cigna doctor used this system to "review" and deny 60,000 claims in one month.
Beyond serving as an indictment of the US for-profit health industry, and of Cigna's business practices, this is also a cautionary tale about the idea that critical AI applications can be resolved with "humans in the loop."
AI pitchmen claim that even unreliable AI can be fixed by adding a "human in the loop" that reviews the AI's judgments:
https://pluralistic.net/2024/04/23/maximal-plausibility/#reverse-centaurs
In this world, the AI is an assistant to the human. For example, a radiologist might have an AI double-check their assessments of chest X-rays, and revisit those X-rays where the AI's assessment didn't match their own. This robot-assisted-human configuration is called a "centaur."
In reality, "human in the loop" is almost always a reverse-centaur. If the hospital buys an AI, fires half its radiologists and orders the remainder to review the AI's superhuman assessments of chest X-rays, that's not an AI assisted radiologist, that's a radiologist-assisted AI. Accuracy goes down, but so do costs. That's the bet that AI investors are making.
Many AI applications turn out not to even be "AI" – they're just low-waged workers in an overseas call-center pretending to be an algorithm (some Indian techies joke that AI stands for "absent Indians"). That was the case with Amazon's Grab and Go stores where, supposedly, AI-enabled cameras counted up all the things you put in your shopping basket and automatically billed you for them. In reality, the cameras were connected to Indian call-centers where low-waged workers made those assessments:
https://pluralistic.net/2024/01/29/pay-no-attention/#to-the-little-man-behind-the-curtain
This Potemkin AI represents an intermediate step between outsourcing and AI. Over the past three decades, the growth of cheap telecommunications and logistics systems let corporations outsource customer service to low-waged offshore workers. The corporations used the excuse that these subcontractors were far from the firm and its customers to deny them any agency, giving them rigid scripts and procedures to follow.
This was a very usefully dysfunctional system. As a customer with a complaint, you would call the customer service line, wait for a long time on hold, spend an interminable time working through a proscribed claims-handling process with a rep who was prohibited from diverging from that process. That process nearly always ended with you being told that nothing could be done.
At that point, a large number of customers would have given up on getting a refund, exchange or credit. The money paid out to the few customers who were stubborn or angry enough to karen their way to a supervisor and get something out of the company amounted to pennies, relative to the sums the company reaped by ripping off the rest.
The Amazon Grab and Go workers were humans in robot suits, but these customer service reps were robots in human suits. The software told them what to say, and they said it, and all they were allowed to say was what appeared on their screens. They were reverse centaurs, serving as the human faces of the intransigent robots programmed by monopolists that were too big to care.
AI is the final stage of this progression: robots without the human suits. The AI turns its "human in the loop" into a "moral crumple zone," which Madeleine Clare Elish describes as "a component that bears the brunt of the moral and legal responsibilities when the overall system malfunctions":
https://estsjournal.org/index.php/ests/article/view/260
The Filipino nurses in the Cigna system are an avoidable expense. As Cigna's own dabbling in algorithmic claim-denial shows, they can be jettisoned in favor of a system that uses productivity dashboards and other bossware to push doctors to robosign hundreds or thousands of denials per day, on the pretense that these denials were "reviewed" by a licensed physician.

If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2024/04/29/what-part-of-no/#dont-you-understand
#pluralistic#cigna#computer says no#bossware#moral crumple zones#medicare for all#m4a#whistleblowers#dr debby day#Madeleine Clare Elish#automation#ai#outsourcing#human in the loop#humans in the loop
231 notes
·
View notes
Text

Hot one out there today, eh neighbor?
#synthography#video feedback#partially made w/dalle-2#digital mixed media#glitchcore#human in the loop#glitch photography#unreality
26 notes
·
View notes
Text
Not-Yet-Full Self Driving on Tesla (And How to Make it Better)
We have had Full Self Driving (FSD) Beta on our Tesla Model Y for some time. I had written a previous post on how much the autodrive reduces the stress of driving and want to update it for the FSD experience. The short of it is that the car goes from competent driver to making beginner's mistakes in a split second.
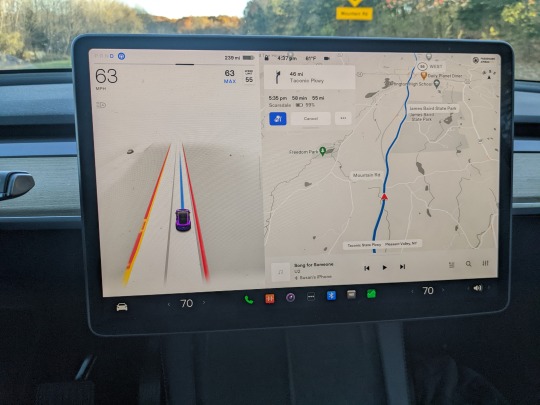
Some examples of situations with which FSD really struggles are any non-standard intersection. Upstate New York is full of those with roads coming at odd angles (e.g. small local roads crossing the Taconic Parkway). One common failure mode is where FSD will take a corner at first too tightly, then overcorrect and partially cross the median. Negotiating with other cars at four ways stops, which are also abundant upstate is also hilariously entertaining, by which I mean scary as hell.
The most frustrating part of the FSD experience though is that it makes the sames mistakes in the same location and there is no way to provide it feedback. This is a huge missed opportunity on the part of Tesla. The approach to FSD should be with the car being very clear when it is uncertain and asking for help, as well as accepting feedback after making a mistake. Right now FSD comes off as a cocky but terrible driver, which induces fear and frustration. If instead it acted like a novice eager to learn it could elicit a completely different emotional response. That in turn would provide a huge amount of actual training data for Tesla!
In thinking about AI progress and designing products around it there are two failure modes at the moment. In one direction it is to dismiss the clear progress that's happening as just a parlor trick and not worthy of attention. In the other direction it is to present systems as if they were already at human or better than human capability and hence take humans out of the loop (the latter is true in some closed domains but not yet generally).
It is always worth remembering that airplanes don't fly the way birds do. It is unlikely that machines will drive or write or diagnose the way humans do. The whole opportunity for them to outdo us at these activities is exactly because they have access to modes of representing knowledge that are difficult for humans (eg large graphs of knowledge). Or put differently, just as AI made the mistake of dismissing the potential for neural networks again and again we are now entering a phase that is needlessly dismissing ontologies and other explicit knowledge representations.
I believe we are poised for further breakthroughs from combining techniques, in particular making it easier for humans to teach machines. And autonomous vehicles are unlikely to be fully realized until we do.
5 notes
·
View notes
Text
Data Labeling Strategies for Cutting-Edge Segmentation Projects

Deep learning has been very successful when working with images as data and is currently at a stage where it works better than humans on multiple use-cases. The most important problems that humans have been interested in solving with computer vision are image classification, object detection and segmentation in the increasing order of their difficulty.
While there in the plain old task of image classification we are just interested in getting the labels of all the objects that are present in an image. In object detection we come further and try to know along with what all objects that are present in an image, the location at which the objects are present with the help of bounding boxes. Image segmentation takes it to a new level by trying to find out accurately the exact boundary of the objects in the image.
What is image segmentation?
We know an image is nothing but a collection of pixels. Image segmentation is the process of classifying each pixel in an image belonging to a certain class and hence can be thought of as a classification problem per pixel. There are two types of segmentation techniques
segmentation: - Semantic segmentation is the process of classifying each pixel belonging to a particular label. It doesn’t different across different instances of the same object. For example, if there are 2 cats in an image, semantic segmentation gives same label to all the pixels of both cats
Instance segmentation: - Instance segmentation differs from semantic segmentation in the sense that it gives a unique label to every instance of a particular object in the image. As can be seen in the image above all 3 dogs are assigned different colors i.e different labels. With semantic segmentation all of them would have been assigned the same color.
There are numerous advances in Segmentation algorithms and open-source datasets. But to solve a particular problem in your domain, you will still need human labeled images or human based verification. In this article, we will go through some of the nuances in segmentation task labeling and how human based workforce can work in tandem with machine learning based approaches.
To train your machine learning model, you need high quality labels. For a successful data labeling project for segmentation depends on three key ingredients.
Labeling Tools
Training
Quality Management
Labeling Tools
There are many open source and commercially available tools on the market. At objectways, we train our workforce using Open CVAT that provides a polygon tool with interpolation and assistive tooling that gives 4x better speed at labeling and then we use a tool that fits the use case.
Here are the leading tools that we recommend for labeling. For efficient labeling, prefer a tool that allows pre-labeling and assistive labeling using techniques like Deep Extreme Cut or Grab cut and good review capabilities such as per label opacity controls.
Workforce training
While it is easier to train a resource to perform simple image tasks such as classification or bounding boxes, segmentation tasks require more training as it involves multiple mechanisms to optimize time, increase efficiency and reduce worker fatigue. Here are some simple training techniques
Utilize Assistive Tooling: An annotator may start with a simple brush or polygon tool which they find easy to pick up. But at volume, these tools tend to induce muscle fatigue hence it is important to make use of assistive tooling.
Gradually introduce complex tasks: Annotators are always good at doing the same task more efficiently with time and should be part of the training program. At Objectways, we tend to start training by introducing annotators with simple images with relatively easy shapes (Cars/Buses/Roads) and migrate them to using complex shapes such as vegetation, barriers.
Use variety of available open-source pre-labeled datasets: It is also important to train the workforce using different datasets and we use PascalVoc, Coco, Cityscapes, Lits, CCP, Pratheepan, Inria Aerial Image Labeling.
Provide Feedback: It is also important to provide timely feedback about their work and hence we use the golden set technique that is created by our senior annotators with 99.99% accuracy and use it to provide feedback for annotators during the training.
Quality Management
In Machine Learning, there are different techniques to understand and evaluate the results of a model.
Pixel accuracy: Pixel accuracy is the most basic metric which can be used to validate the results. Accuracy is obtained by taking the ratio of correctly classified pixels w.r.t total pixels.
Intersection over Union: IOU is defined as the ratio of intersection of ground truth and predicted segmentation outputs over their union. If we are calculating for multiple classes, the IOU of each class is calculated, and their meaning is taken. It is a better metric compared to pixel accuracy as if every pixel is given as background in a 2-class input the IOU value is (90/100+0/100)/2 i.e 45% IOU which gives a better representation as compared to 90% accuracy.
F1 Score: The metric popularly used in classification F1 Score can be used for segmentation tasks as well to deal with class imbalance.
If you have a labeled dataset, you can introduce a golden set in the labeling pipeline and use one of the scores to compare labels against your own ground truth. We focus on following aspects to improve quality of labeling
Understand labeling instructions: Never underestimate the importance of good labeling instructions. Typically, instructions are authored by data scientists who are good at expressing what they want with examples. The human brain has a natural tendency to give weight to (and remember) negative experiences or interactions more than positive ones — they stand out more. So, it is important to provide bad labeling examples. Reading instructions carefully often weeds out many systemic errors across tasks.
Provide timely feedback: While many workforces use tiered skilled workforce where level1 workforce are less experienced than quality control team, it is important to provide timely feedback to level1 annotators, so they understand unintentional labeling errors, so they do not make those errors in the future tasks
Rigorous Quality audits: Many tools provide nice metrics to track label addition/deletion or change over time. Just as algorithms should converge and reduce the loss function, the time to QC a particular task and suggested changes should converge to less than .01% error rate. At objectways, we have dedicated QC and super QC teams who have a consistent track record to achieve over 99% accuracy.
Summary
We have discussed best practices to manage complex large scale segmentation projects and provided guidance for tooling, workforce upskilling and quality management. Please contact [email protected] to provide feedback or if you have any questions.
#Objectways#Artificial Intelligence#Machine Learning#Data Science#Data Labeling#Data Annotation#Human in the Loop
0 notes
Text
Realizing the ultimate power of Human-in-loop in Data Labeling?
As more automated systems, software, robots, etc. are produced, the world of today becomes more and more mechanized. The most advanced technologies, machine learning, and artificial intelligence are giving automation a new dimension and enabling more jobs to be completed by machines themselves.
The term “man in the machine” is well-known in science fiction books written in the early20th century. It is obvious what this phrase refers to in the twenty-first century: artificial intelligence and machine learning. Natural intelligence — humans in the loop — must be involved at many stages of the development and training of AI. In this loop, the person takes on the role of a teacher.

What does “Human-in-Loop” mean?
Like the humans who created them, AIs are not perfect. Because machines base their knowledge on existing data and patterns, predictions generated by AI technologies are not always accurate. Although this also applies to human intellect, it is enhanced by the utilization of many inputs in trial-and-error-based cognition and by the addition of emotional reasoning. Because of this, humans are probably more likely to make mistakes than machines are to mess things up.
A human-in-the-loop system can be faster and more efficient than a fully automated system, which is an additional advantage.
Humans are frequently considerably faster at making decisions than computers are, and humans can use their understanding of the world to find solutions to issues that an AI might not be able to find on its own.
How Human-in-the-loop Works and Benefits Data Labeling & Machine Learning?
Machine learning models are created using both human and artificial intelligence in the“human-in-the-loop” (HITL) branch of artificial intelligence. People engage in a positive feedback loop where they train, fine-tune, and test a specific algorithm in the manner known as “human-in-the-loop”.It typically works as follows: Data is labeled initially by humans. A model thus receives high-quality (and lots of) training data. This data is used to train a machine learning system to make choices. The model is then tuned by people.
Humans frequently assess data in a variety of ways, but mostly to correct for overfitting, to teach a classifier about edge instances, or to introduce new categories to the model’s scope. Last but not least, by grading a model’s outputs, individuals can check its accuracy, particularly in cases where an algorithm is too underconfident about a conclusion. It’s crucial to remember that each of these acts is part of a continual feedback loop. By including humans in the machine learning process, each of these training, adjusting, and testing jobs is fed back into the algorithm to help it become more knowledgeable, confident, and accurate.
When the model chooses what it needs to learn next — a process called active learning — and you submit that data to human annotators for training, this can be very effective.
When should you utilize machine learning with a Human in the loop?
Training: Labeled data for model training can be supplied by humans. This is arguably where data scientists employ a HitL method the most frequently.
Testing: Humans can also assist in testing or fine-tuning a model to increase accuracy. Consider a scenario where your model is unsure whether a particular image is a real cake or not.
And More…
Data Labeler is one of the best Data Labeling Service Providers in USA
Consistency, efficiency, precision, and speed are provided by their well-built integrated data labeling platform and its advanced software. Label auditing ensures that your models are trained and deployed more quickly thanks to its streamlined task interfaces.
Contact us to know more.
1 note
·
View note
Text
I need codependent Danny/Jason as a little treat (for me) and I love the idea of them having some sort of instant connection the moment they meet (bc ghost stuff idk)
Danny who's been dropped in Gotham with no way home (alt universe??) and he's been here for 36 hours and having a Very bad time senses a liminal being and immediately latches onto them heedless of the fact that his new best friend is shooting at some seedy guys in an alley and goes off about how stressed he is and how he can't make it back to the ghost zone and what a bad day he's been having (and it's important to note Danny is a littol ghost boy literally hanging off of Jason's neck as he floats aimlessly) and Jason is like "who are you??" And Danny is like "oh sorry I'm Danny lol" and then just continues lamenting his woes
And honestly ? This might as well happen. Nothing about this Danny guy(is he human?) gives Jason a bad vibe and tbh he's never felt more calm and level headed before so he just keeps up his usual Red Hood patrol and doesn't even think about it when he heads back to a safehouse and feeds Danny dinner (breakfast) before crashing for half the day
The only thing I actually need is Jason meeting up with the bats for some sort of Intel meeting and they're like "uhhh who's that" and Jason is like "that's Danny." And does not elaborate (very ".... What do you have there?" "A smoothie" vibes)
And it takes them a while to realize that these two have known each other for less than 12 hours and are literally attached at the hip
#very remora fish with a shark#jason todd#danny fenton#danny phantom#dpxdc#dp x dc#this isnt super important but i imagine Danny's ghost form as young and unaged from his death so jason is used to this small whispy kid#who just hangs off him and talks literally all the time#so when something comes up and someone is like 'idk if we can bring danny looking like... that' (glowing and a literal ghost)#danny is like 'oh ok u need a human? ok :)' and transforms#its been WEEKS#jason didn't know he could do that#nobody did#and now theres this 20ish dude standing there#human form danny doesn't talk a lot (anxiety) ghost form danny can't stop talking (anxiety)#could be a ship fic and at this point jason goes from 'where is my little buddy :(' to 👀😳#i imagine theres a sort of feedback loop with them both feeding off of each other's ecto energies and vibes idk#so when danny is human its not as strong#batman is convince this strange entity is like hypnoyizing his son and like hes not WRONG#but it goes both ways#idk#i just need more codependency fics :(#i should go on a bender#ignore my 500 open tabs and go to town
1K notes
·
View notes
Text

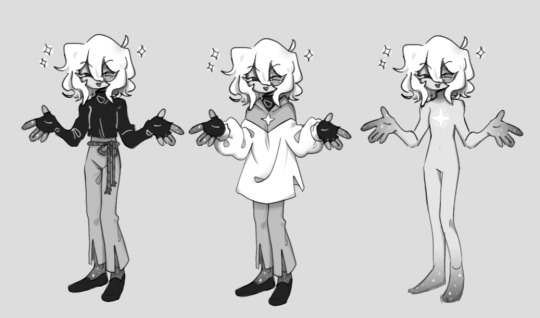
Ah yes, hooman Loop

^ early concept
#I don't think much of human Loop designs but if it is on my mind I always think of it as like#that one “Loop gets summoned by the gang” fic on ao3 where tall Loop started shrinking and then just kinda Siffrinifies back#basically yeah I imagine if Loop human then wish craft ran out#Loop's hairstyle is basically Siffrin if they ever brushed their hair#the headcanon behind this is that their time spent as a star made Loop appreciate their old body so#if Loop ever gained back their Siffrin body they'd really want to “preserve” it#it's self care but only in a roundabout way#They're not thinking about it in terms of “looking good” it's about saving their body at its peak condition for the longest time possible#due to trauma and stuff <33#also yea they definitely own like 1000 creams salves and oils for every part of their body#isat#in stars and time#loop#isat loop#loop isat#isat spoilers#my art#art tag#desert art
899 notes
·
View notes
Text

Comfortable in New Skin
#wanted to give loop some like... vague clothes. since while they dont Need to be covered... accessorising is a human right#and boy do they need some of those. one can assume the only place theyd be getting clothes is isa though. so. ponder it#in stars and time#isat fanart#isat spoilers#isat loop#loop isat#isat#lucabyteart#SPOILERS TAG BECAUSE UM. CAPTION IS UNNEGOTIABLE. SOZ#anyway i do have Even More doodles on the way. primarily about loop. predictable. a lot of thoughts on the body horror of it all.#if you were to ask me. i think loops quote unquote skin is uncannily loose when pushed or pulled in any way#almost as if it were clothes covering the skin rather than skin itself. probably feels fuzzy and vague too. as for their head?#non-solid but in the way where theres a force pushing outwards. radiating you could say. yknow. vague. undefined. not quite real#but thats just my headcanon. tee hee
698 notes
·
View notes
Text






Makes my grand return to tumblr with in stars and time <3 heres my autism <3
spoilers??? under the cut??? for two hats??? uh loop stuff proceed at ur own risk i guess???



#isat#isat spoilers#isat siffrin#isat fanart#in stars and time#isat isabeau#isat bonnie#isat odile#isat loop#in stars and time spoilers#in stars and time siffrin#in stars and time isabeau#in stars and time odile#in stars and time bonnie#in stars and time loop#in stars and time fanart#isat au#?? technically?? for loop returns/join the gang au???? kinda technically???? idk man#human loop#two hats spoilers#isat isafrin#isafrin#just a lot of my favorite moments and then also a bit of sillies from when i played the game with trye <3 hi trye <3 love you <3#tisms cutely#peep the few times i messed up sifs hair early on in doodles <3
413 notes
·
View notes
Text

Everyone's favorite cosmic joke!
#isat spoilers#in stars and time spoilers#in stars and time#isat#isat loop#kala art#God making fanart for this game is so fun but my art is tailored for as much color as is humanely possible to cram onto a file so I suffer.
496 notes
·
View notes
Text


exhaustion
#set post loops odile looping au but feel free to apply anywhere#odile loops au#isat#isat odile#in stars and time#isat mirabelle#isat spoilers#thinking like. odile overexhausting herself; because she no longer knows how much the human body can take before collapsing#because wishcraft allowed her to function without sleep for hundreds of loops#made while i was super sleepy at work... projecting my exhaustion#day 50#ok yeah nevermind i keep missing days. gonna go through asks whenever i'm ready for it#does odile putting her hair down post loops teal's design? well I'm attributing it to her anyways
490 notes
·
View notes
Text
“Humans in the loop” must detect the hardest-to-spot errors, at superhuman speed

I'm touring my new, nationally bestselling novel The Bezzle! Catch me SATURDAY (Apr 27) in MARIN COUNTY, then Winnipeg (May 2), Calgary (May 3), Vancouver (May 4), and beyond!

If AI has a future (a big if), it will have to be economically viable. An industry can't spend 1,700% more on Nvidia chips than it earns indefinitely – not even with Nvidia being a principle investor in its largest customers:
https://news.ycombinator.com/item?id=39883571
A company that pays 0.36-1 cents/query for electricity and (scarce, fresh) water can't indefinitely give those queries away by the millions to people who are expected to revise those queries dozens of times before eliciting the perfect botshit rendition of "instructions for removing a grilled cheese sandwich from a VCR in the style of the King James Bible":
https://www.semianalysis.com/p/the-inference-cost-of-search-disruption
Eventually, the industry will have to uncover some mix of applications that will cover its operating costs, if only to keep the lights on in the face of investor disillusionment (this isn't optional – investor disillusionment is an inevitable part of every bubble).
Now, there are lots of low-stakes applications for AI that can run just fine on the current AI technology, despite its many – and seemingly inescapable - errors ("hallucinations"). People who use AI to generate illustrations of their D&D characters engaged in epic adventures from their previous gaming session don't care about the odd extra finger. If the chatbot powering a tourist's automatic text-to-translation-to-speech phone tool gets a few words wrong, it's still much better than the alternative of speaking slowly and loudly in your own language while making emphatic hand-gestures.
There are lots of these applications, and many of the people who benefit from them would doubtless pay something for them. The problem – from an AI company's perspective – is that these aren't just low-stakes, they're also low-value. Their users would pay something for them, but not very much.
For AI to keep its servers on through the coming trough of disillusionment, it will have to locate high-value applications, too. Economically speaking, the function of low-value applications is to soak up excess capacity and produce value at the margins after the high-value applications pay the bills. Low-value applications are a side-dish, like the coach seats on an airplane whose total operating expenses are paid by the business class passengers up front. Without the principle income from high-value applications, the servers shut down, and the low-value applications disappear:
https://locusmag.com/2023/12/commentary-cory-doctorow-what-kind-of-bubble-is-ai/
Now, there are lots of high-value applications the AI industry has identified for its products. Broadly speaking, these high-value applications share the same problem: they are all high-stakes, which means they are very sensitive to errors. Mistakes made by apps that produce code, drive cars, or identify cancerous masses on chest X-rays are extremely consequential.
Some businesses may be insensitive to those consequences. Air Canada replaced its human customer service staff with chatbots that just lied to passengers, stealing hundreds of dollars from them in the process. But the process for getting your money back after you are defrauded by Air Canada's chatbot is so onerous that only one passenger has bothered to go through it, spending ten weeks exhausting all of Air Canada's internal review mechanisms before fighting his case for weeks more at the regulator:
https://bc.ctvnews.ca/air-canada-s-chatbot-gave-a-b-c-man-the-wrong-information-now-the-airline-has-to-pay-for-the-mistake-1.6769454
There's never just one ant. If this guy was defrauded by an AC chatbot, so were hundreds or thousands of other fliers. Air Canada doesn't have to pay them back. Air Canada is tacitly asserting that, as the country's flagship carrier and near-monopolist, it is too big to fail and too big to jail, which means it's too big to care.
Air Canada shows that for some business customers, AI doesn't need to be able to do a worker's job in order to be a smart purchase: a chatbot can replace a worker, fail to their worker's job, and still save the company money on balance.
I can't predict whether the world's sociopathic monopolists are numerous and powerful enough to keep the lights on for AI companies through leases for automation systems that let them commit consequence-free free fraud by replacing workers with chatbots that serve as moral crumple-zones for furious customers:
https://www.sciencedirect.com/science/article/abs/pii/S0747563219304029
But even stipulating that this is sufficient, it's intrinsically unstable. Anything that can't go on forever eventually stops, and the mass replacement of humans with high-speed fraud software seems likely to stoke the already blazing furnace of modern antitrust:
https://www.eff.org/de/deeplinks/2021/08/party-its-1979-og-antitrust-back-baby
Of course, the AI companies have their own answer to this conundrum. A high-stakes/high-value customer can still fire workers and replace them with AI – they just need to hire fewer, cheaper workers to supervise the AI and monitor it for "hallucinations." This is called the "human in the loop" solution.
The human in the loop story has some glaring holes. From a worker's perspective, serving as the human in the loop in a scheme that cuts wage bills through AI is a nightmare – the worst possible kind of automation.
Let's pause for a little detour through automation theory here. Automation can augment a worker. We can call this a "centaur" – the worker offloads a repetitive task, or one that requires a high degree of vigilance, or (worst of all) both. They're a human head on a robot body (hence "centaur"). Think of the sensor/vision system in your car that beeps if you activate your turn-signal while a car is in your blind spot. You're in charge, but you're getting a second opinion from the robot.
Likewise, consider an AI tool that double-checks a radiologist's diagnosis of your chest X-ray and suggests a second look when its assessment doesn't match the radiologist's. Again, the human is in charge, but the robot is serving as a backstop and helpmeet, using its inexhaustible robotic vigilance to augment human skill.
That's centaurs. They're the good automation. Then there's the bad automation: the reverse-centaur, when the human is used to augment the robot.
Amazon warehouse pickers stand in one place while robotic shelving units trundle up to them at speed; then, the haptic bracelets shackled around their wrists buzz at them, directing them pick up specific items and move them to a basket, while a third automation system penalizes them for taking toilet breaks or even just walking around and shaking out their limbs to avoid a repetitive strain injury. This is a robotic head using a human body – and destroying it in the process.
An AI-assisted radiologist processes fewer chest X-rays every day, costing their employer more, on top of the cost of the AI. That's not what AI companies are selling. They're offering hospitals the power to create reverse centaurs: radiologist-assisted AIs. That's what "human in the loop" means.
This is a problem for workers, but it's also a problem for their bosses (assuming those bosses actually care about correcting AI hallucinations, rather than providing a figleaf that lets them commit fraud or kill people and shift the blame to an unpunishable AI).
Humans are good at a lot of things, but they're not good at eternal, perfect vigilance. Writing code is hard, but performing code-review (where you check someone else's code for errors) is much harder – and it gets even harder if the code you're reviewing is usually fine, because this requires that you maintain your vigilance for something that only occurs at rare and unpredictable intervals:
https://twitter.com/qntm/status/1773779967521780169
But for a coding shop to make the cost of an AI pencil out, the human in the loop needs to be able to process a lot of AI-generated code. Replacing a human with an AI doesn't produce any savings if you need to hire two more humans to take turns doing close reads of the AI's code.
This is the fatal flaw in robo-taxi schemes. The "human in the loop" who is supposed to keep the murderbot from smashing into other cars, steering into oncoming traffic, or running down pedestrians isn't a driver, they're a driving instructor. This is a much harder job than being a driver, even when the student driver you're monitoring is a human, making human mistakes at human speed. It's even harder when the student driver is a robot, making errors at computer speed:
https://pluralistic.net/2024/04/01/human-in-the-loop/#monkey-in-the-middle
This is why the doomed robo-taxi company Cruise had to deploy 1.5 skilled, high-paid human monitors to oversee each of its murderbots, while traditional taxis operate at a fraction of the cost with a single, precaratized, low-paid human driver:
https://pluralistic.net/2024/01/11/robots-stole-my-jerb/#computer-says-no
The vigilance problem is pretty fatal for the human-in-the-loop gambit, but there's another problem that is, if anything, even more fatal: the kinds of errors that AIs make.
Foundationally, AI is applied statistics. An AI company trains its AI by feeding it a lot of data about the real world. The program processes this data, looking for statistical correlations in that data, and makes a model of the world based on those correlations. A chatbot is a next-word-guessing program, and an AI "art" generator is a next-pixel-guessing program. They're drawing on billions of documents to find the most statistically likely way of finishing a sentence or a line of pixels in a bitmap:
https://dl.acm.org/doi/10.1145/3442188.3445922
This means that AI doesn't just make errors – it makes subtle errors, the kinds of errors that are the hardest for a human in the loop to spot, because they are the most statistically probable ways of being wrong. Sure, we notice the gross errors in AI output, like confidently claiming that a living human is dead:
https://www.tomsguide.com/opinion/according-to-chatgpt-im-dead
But the most common errors that AIs make are the ones we don't notice, because they're perfectly camouflaged as the truth. Think of the recurring AI programming error that inserts a call to a nonexistent library called "huggingface-cli," which is what the library would be called if developers reliably followed naming conventions. But due to a human inconsistency, the real library has a slightly different name. The fact that AIs repeatedly inserted references to the nonexistent library opened up a vulnerability – a security researcher created a (inert) malicious library with that name and tricked numerous companies into compiling it into their code because their human reviewers missed the chatbot's (statistically indistinguishable from the the truth) lie:
https://www.theregister.com/2024/03/28/ai_bots_hallucinate_software_packages/
For a driving instructor or a code reviewer overseeing a human subject, the majority of errors are comparatively easy to spot, because they're the kinds of errors that lead to inconsistent library naming – places where a human behaved erratically or irregularly. But when reality is irregular or erratic, the AI will make errors by presuming that things are statistically normal.
These are the hardest kinds of errors to spot. They couldn't be harder for a human to detect if they were specifically designed to go undetected. The human in the loop isn't just being asked to spot mistakes – they're being actively deceived. The AI isn't merely wrong, it's constructing a subtle "what's wrong with this picture"-style puzzle. Not just one such puzzle, either: millions of them, at speed, which must be solved by the human in the loop, who must remain perfectly vigilant for things that are, by definition, almost totally unnoticeable.
This is a special new torment for reverse centaurs – and a significant problem for AI companies hoping to accumulate and keep enough high-value, high-stakes customers on their books to weather the coming trough of disillusionment.
This is pretty grim, but it gets grimmer. AI companies have argued that they have a third line of business, a way to make money for their customers beyond automation's gifts to their payrolls: they claim that they can perform difficult scientific tasks at superhuman speed, producing billion-dollar insights (new materials, new drugs, new proteins) at unimaginable speed.
However, these claims – credulously amplified by the non-technical press – keep on shattering when they are tested by experts who understand the esoteric domains in which AI is said to have an unbeatable advantage. For example, Google claimed that its Deepmind AI had discovered "millions of new materials," "equivalent to nearly 800 years’ worth of knowledge," constituting "an order-of-magnitude expansion in stable materials known to humanity":
https://deepmind.google/discover/blog/millions-of-new-materials-discovered-with-deep-learning/
It was a hoax. When independent material scientists reviewed representative samples of these "new materials," they concluded that "no new materials have been discovered" and that not one of these materials was "credible, useful and novel":
https://www.404media.co/google-says-it-discovered-millions-of-new-materials-with-ai-human-researchers/
As Brian Merchant writes, AI claims are eerily similar to "smoke and mirrors" – the dazzling reality-distortion field thrown up by 17th century magic lantern technology, which millions of people ascribed wild capabilities to, thanks to the outlandish claims of the technology's promoters:
https://www.bloodinthemachine.com/p/ai-really-is-smoke-and-mirrors
The fact that we have a four-hundred-year-old name for this phenomenon, and yet we're still falling prey to it is frankly a little depressing. And, unlucky for us, it turns out that AI therapybots can't help us with this – rather, they're apt to literally convince us to kill ourselves:
https://www.vice.com/en/article/pkadgm/man-dies-by-suicide-after-talking-with-ai-chatbot-widow-says

If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2024/04/23/maximal-plausibility/#reverse-centaurs
Image:
Cryteria (modified)
https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0
https://creativecommons.org/licenses/by/3.0/deed.en
#pluralistic#ai#automation#humans in the loop#centaurs#reverse centaurs#labor#ai safety#sanity checks#spot the mistake#code review#driving instructor
793 notes
·
View notes
Text
#shameless self-repost#original work#human in the loop#technopagan#endless loop#touchdesigner#newmediaart#tarot cards#pamela colman smith#the lovers#judgement#temperance#the tower#the devil#interpolation#motion graphics#surreal
30 notes
·
View notes
Text
Something that amuses me between knitters and crocheters is this... almost humble nature each craft has about the other. I couldn't imagine how one would knit, and I know some of the basics - and yet, I have met so many knitters who say crochet is impossible, and yet I find it to be so simple. There's just something charming about when one recognizes just how much skill, effort, patience, and care go into a craft, and to be humbled by just how incredible human ingenuity and creativity are
#art#fiber art#crochet#knit#i was watching a knitter who is trying to crochet and she was struggling with the foundation chain and...#...man that's how i would feel with a BASIC cast-on (maybe besides the crochet cast-on)#a knitter described knit as just... a bunch of open crochet loops and that made it much easier to understand knit#i love how knit looks because you can do these colour changes SEAMLESSLY in a magical way#I LOVE YOU FIBER ARTS - I LOVE YOU HUMANS I LOVE YOU PEOPLE <3
626 notes
·
View notes
Text
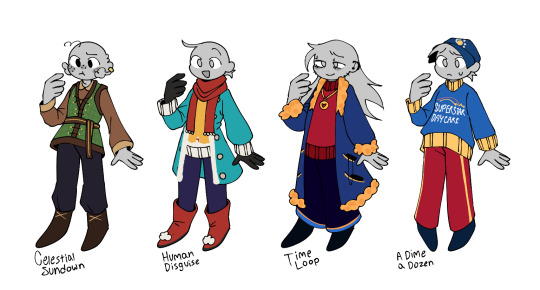
My DCA AU Y/Ns, the family gathering, my children, etc.
Celestial Sundown - a medieval peasant whose Sun, Moon, and Eclipse are gods
Human Disguise - a store+library employee who falsely believes Sun and Moon to be regular humans
Time Loop - a daycare assistant sent back to their first day on the job every few months on the day of the fire (note: this design is after the loops broke)
A Dime a Dozen - a socially anxious daycare assistant falsely under the impression that Sun and Moon are not sentient
Transparent ver.

#pillowspace art#dca au#dca fandom#y/n insert#celestial sundown au#human disguise au#time loop au#a dime a dozen#dca y/n#[csd art tag]
535 notes
·
View notes
Text

post-game loop!!
for... me, mostly, i think. do they look enough like themself? or even sif really? im not sure. but i like them well enough that im not too worried about it.
(design notes and an alt under the cut!)
okay. so. first off? they were originally gonna have a mouth. but i just... couldnt. i couldnt reckon with it. so they get no mouth. sorry, loop.
while they dont have a scar on their eye anymore, they have... something? there are 'freckles' that radiate out from their eye. unlike the rest of their person, these dark spots dont seem to radiate light.
the hat theyre wearing is sifs! this worlds sifs. siffrin doesnt need it anymore, after all. and theirs is... long gone.
speaking of the hat: its adorned with orchids. orchids are funeral flowers. they represent everlasting love and sympathy for the deceased. their friends no longer exist. they cannot, not in the way they once did. its a way to hold on to those people, but to let them go, too. the only way through is forward now, after all.
the core of their design was asymmetry. siffrin is actually very symmetrical as far as his design goes, so i wanted loop to throw all caution to the wind. a long white glove paired with a short black one, a cloak that drapes over one side, hair not sticking to an even length.
theyre actually wearing white tights. not that you can really tell unless you colour pick and see the very mild difference between their skin tone and the white of their clothes.
wears platform boots almost exclusively to be taller than sif. lmao.

#in stars and time#in stars and time fanart#isat#isat fanart#isat spoilers#isat act 6 spoilers#in stars and time spoilers#loop isat#loop in stars and time#basil paints#hey if anyone has questions about their design i didnt answer you can ask them wehehe.#other than 'why are they human-ish now?' because my answer for that is boring.#they wanted to be a part of the world. to be real in a way they werent in the loops.
292 notes
·
View notes
Last Seen Blogs

dreams-flame-cloak
It’s Called Fashion Look It Up

chuburguer
diarrea record's

ionybonnypcom
No Title

missmiha
Miss Miha

jenchick662002
Untitled