#facial recognition
Text
So, this is scary as hell, Google's developing tech to scan your face as a form of age identification, and it's yet another reason why we need to stop the various bad internet bills like EARN IT, STOP CSAM, and especially KOSA.
Because, that's why they're doing this, and that sort of invasive face scanning is what everybody's been warning people they're going to do if they pass, so the fact they're running up to push it through should alarm everyone.
And, as of this posting on 12/27/2023, it's been noted that Chuck Schumer wants to try and start pushing these bills through as soon as the new year starts, and some whisperings have been made even of all these bad bills being merged under STOP CSAM into one deadly super-bill.
So, if you live in the US call your senators, and even if you don't please boost this, we need to stop this now.
#censorship#online censorship#internet censorship#surveilance#privacy#facial recognition#signal boost
6K notes
·
View notes
Photo

Hey Apple, there’s a major bug with your latest iOS update! My iPhone’s facial recognition has stopped working!
1K notes
·
View notes
Text
Hypothetical AI election disinformation risks vs real AI harms

I'm on tour with my new novel The Bezzle! Catch me TONIGHT (Feb 27) in Portland at Powell's. Then, onto Phoenix (Changing Hands, Feb 29), Tucson (Mar 9-12), and more!

You can barely turn around these days without encountering a think-piece warning of the impending risk of AI disinformation in the coming elections. But a recent episode of This Machine Kills podcast reminds us that these are hypothetical risks, and there is no shortage of real AI harms:
https://soundcloud.com/thismachinekillspod/311-selling-pickaxes-for-the-ai-gold-rush
The algorithmic decision-making systems that increasingly run the back-ends to our lives are really, truly very bad at doing their jobs, and worse, these systems constitute a form of "empiricism-washing": if the computer says it's true, it must be true. There's no such thing as racist math, you SJW snowflake!
https://slate.com/news-and-politics/2019/02/aoc-algorithms-racist-bias.html
Nearly 1,000 British postmasters were wrongly convicted of fraud by Horizon, the faulty AI fraud-hunting system that Fujitsu provided to the Royal Mail. They had their lives ruined by this faulty AI, many went to prison, and at least four of the AI's victims killed themselves:
https://en.wikipedia.org/wiki/British_Post_Office_scandal
Tenants across America have seen their rents skyrocket thanks to Realpage's landlord price-fixing algorithm, which deployed the time-honored defense: "It's not a crime if we commit it with an app":
https://www.propublica.org/article/doj-backs-tenants-price-fixing-case-big-landlords-real-estate-tech
Housing, you'll recall, is pretty foundational in the human hierarchy of needs. Losing your home – or being forced to choose between paying rent or buying groceries or gas for your car or clothes for your kid – is a non-hypothetical, widespread, urgent problem that can be traced straight to AI.
Then there's predictive policing: cities across America and the world have bought systems that purport to tell the cops where to look for crime. Of course, these systems are trained on policing data from forces that are seeking to correct racial bias in their practices by using an algorithm to create "fairness." You feed this algorithm a data-set of where the police had detected crime in previous years, and it predicts where you'll find crime in the years to come.
But you only find crime where you look for it. If the cops only ever stop-and-frisk Black and brown kids, or pull over Black and brown drivers, then every knife, baggie or gun they find in someone's trunk or pockets will be found in a Black or brown person's trunk or pocket. A predictive policing algorithm will naively ingest this data and confidently assert that future crimes can be foiled by looking for more Black and brown people and searching them and pulling them over.
Obviously, this is bad for Black and brown people in low-income neighborhoods, whose baseline risk of an encounter with a cop turning violent or even lethal. But it's also bad for affluent people in affluent neighborhoods – because they are underpoliced as a result of these algorithmic biases. For example, domestic abuse that occurs in full detached single-family homes is systematically underrepresented in crime data, because the majority of domestic abuse calls originate with neighbors who can hear the abuse take place through a shared wall.
But the majority of algorithmic harms are inflicted on poor, racialized and/or working class people. Even if you escape a predictive policing algorithm, a facial recognition algorithm may wrongly accuse you of a crime, and even if you were far away from the site of the crime, the cops will still arrest you, because computers don't lie:
https://www.cbsnews.com/sacramento/news/texas-macys-sunglass-hut-facial-recognition-software-wrongful-arrest-sacramento-alibi/
Trying to get a low-waged service job? Be prepared for endless, nonsensical AI "personality tests" that make Scientology look like NASA:
https://futurism.com/mandatory-ai-hiring-tests
Service workers' schedules are at the mercy of shift-allocation algorithms that assign them hours that ensure that they fall just short of qualifying for health and other benefits. These algorithms push workers into "clopening" – where you close the store after midnight and then open it again the next morning before 5AM. And if you try to unionize, another algorithm – that spies on you and your fellow workers' social media activity – targets you for reprisals and your store for closure.
If you're driving an Amazon delivery van, algorithm watches your eyeballs and tells your boss that you're a bad driver if it doesn't like what it sees. If you're working in an Amazon warehouse, an algorithm decides if you've taken too many pee-breaks and automatically dings you:
https://pluralistic.net/2022/04/17/revenge-of-the-chickenized-reverse-centaurs/
If this disgusts you and you're hoping to use your ballot to elect lawmakers who will take up your cause, an algorithm stands in your way again. "AI" tools for purging voter rolls are especially harmful to racialized people – for example, they assume that two "Juan Gomez"es with a shared birthday in two different states must be the same person and remove one or both from the voter rolls:
https://www.cbsnews.com/news/eligible-voters-swept-up-conservative-activists-purge-voter-rolls/
Hoping to get a solid education, the sort that will keep you out of AI-supervised, precarious, low-waged work? Sorry, kiddo: the ed-tech system is riddled with algorithms. There's the grifty "remote invigilation" industry that watches you take tests via webcam and accuses you of cheating if your facial expressions fail its high-tech phrenology standards:
https://pluralistic.net/2022/02/16/unauthorized-paper/#cheating-anticheat
All of these are non-hypothetical, real risks from AI. The AI industry has proven itself incredibly adept at deflecting interest from real harms to hypothetical ones, like the "risk" that the spicy autocomplete will become conscious and take over the world in order to convert us all to paperclips:
https://pluralistic.net/2023/11/27/10-types-of-people/#taking-up-a-lot-of-space
Whenever you hear AI bosses talking about how seriously they're taking a hypothetical risk, that's the moment when you should check in on whether they're doing anything about all these longstanding, real risks. And even as AI bosses promise to fight hypothetical election disinformation, they continue to downplay or ignore the non-hypothetical, here-and-now harms of AI.
There's something unseemly – and even perverse – about worrying so much about AI and election disinformation. It plays into the narrative that kicked off in earnest in 2016, that the reason the electorate votes for manifestly unqualified candidates who run on a platform of bald-faced lies is that they are gullible and easily led astray.
But there's another explanation: the reason people accept conspiratorial accounts of how our institutions are run is because the institutions that are supposed to be defending us are corrupt and captured by actual conspiracies:
https://memex.craphound.com/2019/09/21/republic-of-lies-the-rise-of-conspiratorial-thinking-and-the-actual-conspiracies-that-fuel-it/
The party line on conspiratorial accounts is that these institutions are good, actually. Think of the rebuttal offered to anti-vaxxers who claimed that pharma giants were run by murderous sociopath billionaires who were in league with their regulators to kill us for a buck: "no, I think you'll find pharma companies are great and superbly regulated":
https://pluralistic.net/2023/09/05/not-that-naomi/#if-the-naomi-be-klein-youre-doing-just-fine
Institutions are profoundly important to a high-tech society. No one is capable of assessing all the life-or-death choices we make every day, from whether to trust the firmware in your car's anti-lock brakes, the alloys used in the structural members of your home, or the food-safety standards for the meal you're about to eat. We must rely on well-regulated experts to make these calls for us, and when the institutions fail us, we are thrown into a state of epistemological chaos. We must make decisions about whether to trust these technological systems, but we can't make informed choices because the one thing we're sure of is that our institutions aren't trustworthy.
Ironically, the long list of AI harms that we live with every day are the most important contributor to disinformation campaigns. It's these harms that provide the evidence for belief in conspiratorial accounts of the world, because each one is proof that the system can't be trusted. The election disinformation discourse focuses on the lies told – and not why those lies are credible.
That's because the subtext of election disinformation concerns is usually that the electorate is credulous, fools waiting to be suckered in. By refusing to contemplate the institutional failures that sit upstream of conspiracism, we can smugly locate the blame with the peddlers of lies and assume the mantle of paternalistic protectors of the easily gulled electorate.
But the group of people who are demonstrably being tricked by AI is the people who buy the horrifically flawed AI-based algorithmic systems and put them into use despite their manifest failures.
As I've written many times, "we're nowhere near a place where bots can steal your job, but we're certainly at the point where your boss can be suckered into firing you and replacing you with a bot that fails at doing your job"
https://pluralistic.net/2024/01/15/passive-income-brainworms/#four-hour-work-week
The most visible victims of AI disinformation are the people who are putting AI in charge of the life-chances of millions of the rest of us. Tackle that AI disinformation and its harms, and we'll make conspiratorial claims about our institutions being corrupt far less credible.

If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2024/02/27/ai-conspiracies/#epistemological-collapse
Image:
Cryteria (modified)
https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0
https://creativecommons.org/licenses/by/3.0/deed.en
#pluralistic#ai#disinformation#algorithmic bias#elections#election disinformation#conspiratorialism#paternalism#this machine kills#Horizon#the rents too damned high#weaponized shelter#predictive policing#fr#facial recognition#labor#union busting#union avoidance#standardized testing#hiring#employment#remote invigilation
144 notes
·
View notes
Text

A shocking story of wrongful arrest in Detroit has renewed scrutiny of how facial recognition software is being deployed by police departments, despite major flaws in the technology.
Porcha Woodruff was arrested in February when police showed up at her house accusing her of robbery and carjacking. Woodruff, who was eight months pregnant at the time, insisted she had nothing to do with the crime, but police detained her for 11 hours, during which time she had contractions. She was eventually released on a $100,000 bond before prosecutors dropped the case a month later, admitting that her arrest was based in part on a false facial recognition match.
Woodruff is the sixth known person to be falsely accused of a crime because of facial recognition, and all six victims have been Black. “That’s not an accident,” says Dorothy Roberts, director of the University of Pennsylvania Program on Race, Science and Society, who says new technology often reflects societal biases when built atop flawed systems. “Racism gets embedded into the technologies.”
👉🏿 https://www.nytimes.com/2023/08/06/business/facial-recognition-false-arrest.html
👉🏿 https://www.democracynow.org/2023/8/7/facial_recognition_dorothy_roberts
👉🏿 https://www.pbs.org/independentlens/documentaries/coded-bias/
337 notes
·
View notes
Photo


Facial Recognition
7 October 2018
41 notes
·
View notes
Text





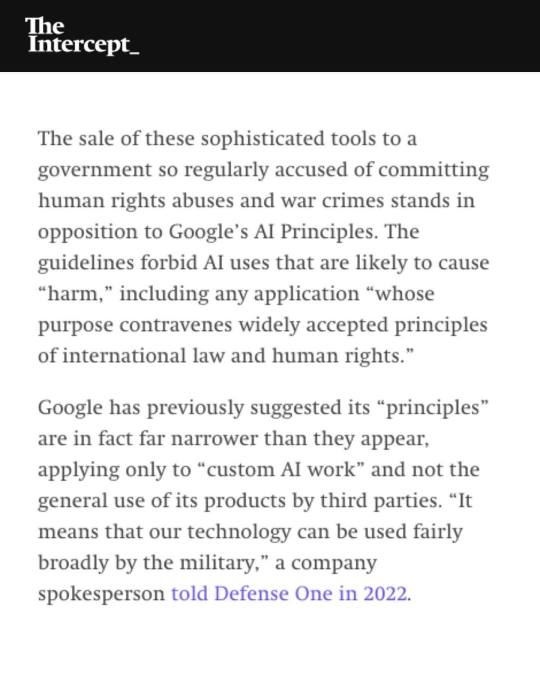

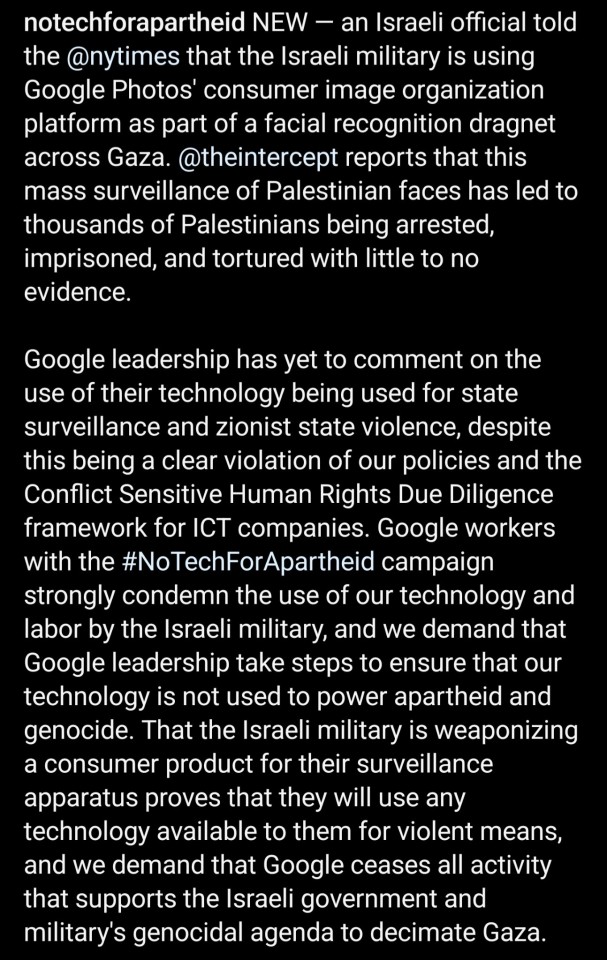


#facial recognition#facial recognition software#boycott israel#boycott google#google software is being used to help target and kill Palestinians#google#apartheid#save palestine#ethnic cleansing#israel is an apartheid state#seek truth#free palestine 🇵🇸#genocide#illegal occupation#israel is committing genocide#israeli war crimes#project nimbus#google photos#israeli hit list#israeli war criminals#israel is a terrorist state#surveillance state#mass surveillance#even AI is racist with facial recognition systems being notoriously unrealiable for people with darker skin tones#no tech for apartheid#human rights violations#conflict sensitive human rights due diligence#seems like that can be bypassed if the money is good enough#dystopian nightmare
17 notes
·
View notes
Text

"Facial recognition was especially bad at recognizing approximately 65% of the US Population"
#incredible#literally went and looked up the 2020 census records for this dont @ me#facial recognition#op
29 notes
·
View notes
Text
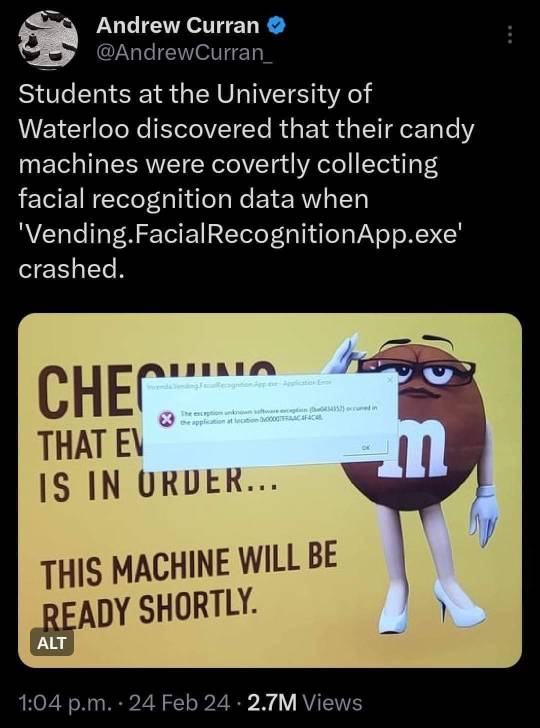

#We're in the bad place#facial recognition#covert facial recognition#university of Waterloo#invasion of privacy#2024
27 notes
·
View notes
Text
MSG’s Facial Recognition at Radio City Gets Girl Scout Mom Kicked Out – NBC New York
A sign says facial recognition is used as a security measure to ensure safety for guests and employees. Conlon says she posed no threat, but the guards still kicked her out with the explanation that they knew she was an attorney.
"They knew my name before I told them. They knew the firm I was associated with before I told them. And they told me I was not allowed to be there," said Conlon.
Conlon is an associate with the New Jersey based law firm, Davis, Saperstein and Solomon, which for years has been involved in personal injury litigation against a restaurant venue now under the umbrella of MSG Entertainment.
"I don’t practice in New York. I’m not an attorney that works on any cases against MSG," said Conlon.
But MSG said she was banned nonetheless — along with fellow attorneys in that firm and others.
155 notes
·
View notes
Text
64 notes
·
View notes
Text
Over 100 artists including Rage Against the Machine co-founders Tom Morello and Zack de la Rocha, along with Boots Riley and Speedy Ortiz, have announced that they are boycotting any concert venue that uses facial recognition technology, citing concerns that the tech infringes on privacy and increases discrimination.
The boycott, organized by the digital rights advocacy group Fight for the Future, calls for the ban of face-scanning technology at all live events. Several smaller independent concert venues across the country, including the House of Yes in Brooklyn, the Lyric Hyperion in Los Angeles, and Black Cat in D.C., also pledged to not use facial recognition tech for their shows. Other artists who said they would boycott include Anti-Flag, Wheatus, Downtown Boys, and over 80 additional artists. The full list of signatories is available here.
“Surveillance tech companies are pitching biometric data tools as ‘innovative’ and helpful for increasing efficiency and security. Not only is this false, it’s morally corrupt,” Leila Nashashibi, campaigner at Fight for the Future, said in a statement. “For starters, this technology is so inaccurate that it actually creates more harm and problems than it solves, through misidentification and other technical faultiness. Even scarier, though, is a world in which all facial recognition technology works 100% perfectly – in other words, a world in which privacy is nonexistent, where we’re identified, watched, and surveilled everywhere we go.”
Facial recognition technology at venues has grown increasingly controversial over the past several months, particularly as Madison Square Garden Entertainment and James Dolan have garnered scrutiny for using the tech to kick out lawyers affiliated with ongoing lawsuits against the company. Several attorneys had been removed last year from events at MSG’s venues including its eponymous arena and Radio City Music Hall. Last October, attorney Barbara Hart was removed from Brandi Carlile’s Madison Square Garden Concert because her law firm was litigating against MSG in a class action lawsuit. (Hart herself wasn’t involved with that suit.)
#Boycotting Venues That Use Face-Scanning Technology#article#rolling stone#surveillance#Facial recognition
33 notes
·
View notes
Text
First Nations man wants apology after being flagged as shoplifter, asked to leave Canadian Tire store. Company will not say if it is using facial recognition technology to identify shoplifters at Grant Park store
“A sign on the front door of the Winnipeg store alerts customers to the fact surveillance cameras are in place. It makes no mention of facial recognition software, which is controversial due to privacy concerns, misidentification and issues with accuracy specifically with non-white skin. "In many cases it doesn't work as well on Black faces. It doesn't work as well on Indigenous faces. It doesn't work as well on faces that are brown or female or young," said Dr. Brenda McPhail, the director of the privacy, technology and surveillance program at the Canadian Civil Liberties Association.”
#submission#facial recognition#Canadian tire#racism#cdnpoli#canada#canadian politics#canadian news#canadian
127 notes
·
View notes
Link
He wasn’t released from jail until nearly a week later. While behind bars, he worried about losing his job and being convicted of felonies that he did not commit. “Not eating, not sleeping. I’m thinking about these charges.
68 notes
·
View notes
Text
Podcasting "How To Think About Scraping"

On September 27, I'll be at Chevalier's Books in Los Angeles with Brian Merchant for a joint launch for my new book The Internet Con and his new book, Blood in the Machine. On October 2, I'll be in Boise to host an event with VE Schwab.

This week on my podcast, I read my recent Medium column, "How To Think About Scraping: In privacy and labor fights, copyright is a clumsy tool at best," which proposes ways to retain the benefits of scraping without the privacy and labor harms that sometimes accompany it:
https://doctorow.medium.com/how-to-think-about-scraping-2db6f69a7e3d?sk=4a1d687171de1a3f3751433bffbb5a96
What are those benefits from scraping? Well, take computational linguistics, a relatively new discipline that is producing the first accounts of how informal language works. Historically, linguists overstudied written language (because it was easy to analyze) and underanalyzed speech (because you had to record speakers and then get grad students to transcribe their dialog).
The thing is, very few of us produce formal, written work, whereas we all engage in casual dialog. But then the internet came along, and for the first time, we had a species of mass-scale, informal dialog that also written, and which was born in machine-readable form.
This ushered in a new era in linguistic study, one that is enthusiastically analyzing and codifying the rules of informal speech, the spread of vernacular, and the regional, racial and class markers of different kinds of speech:
https://memex.craphound.com/2019/07/24/because-internet-the-new-linguistics-of-informal-english/
The people whose speech is scraped and analyzed this way are often unreachable (anonymous or pseudonymous) or impractical to reach (because there's millions of them). The linguists who study this speech will go through institutional review board approvals to make sure that as they produce aggregate accounts of speech, they don't compromise the privacy or integrity of their subjects.
Computational linguistics is an unalloyed good, and while the speakers whose words are scraped to produce the raw material that these scholars study, they probably wouldn't object, either.
But what about entities that explicitly object to being scraped? Sometimes, it's good to scrape them, too.
Since 1996, the Internet Archive has scraped every website it could find, storing snapshots of every page it found in a giant, searchable database called the Wayback Machine. Many of us have used the Wayback Machine to retrieve some long-deleted text, sound, image or video from the internet's memory hole.
For the most part, the Internet Archive limits its scraping to websites that permit it. The robots exclusion protocol (AKA robots.txt) makes it easy for webmasters to tell different kinds of crawlers whether or not they are welcome. If your site has a robots.txt file that tells the Archive's crawler to buzz off, it'll go elsewhere.
Mostly.
Since 2017, the Archive has started ignoring robots.txt files for news services; whether or not the news site wants to be crawled, the Archive crawls it and makes copies of the different versions of the articles the site publishes. That's because news sites – even the so-called "paper of record" – have a nasty habit of making sweeping edits to published material without noting it.
I'm not talking about fixing a typo or a formatting error: I'm talking about making a massive change to a piece, one that completely reverses its meaning, and pretending that it was that way all along:
https://medium.com/@brokenravioli/proof-that-the-new-york-times-isn-t-feeling-the-bern-c74e1109cdf6
This happens all the time, with major news sites from all around the world:
http://newsdiffs.org/examples/
By scraping these sites and retaining the different versions of their article, the Archive both detects and prevents journalistic malpractice. This is canonical fair use, the kind of copying that almost always involves overriding the objections of the site's proprietor. Not all adversarial scraping is good, but this sure is.
There's an argument that scraping the news-sites without permission might piss them off, but it doesn't bring them any real harm. But even when scraping harms the scrapee, it is sometimes legitimate – and necessary.
Austrian technologist Mario Zechner used the API from country's super-concentrated grocery giants to prove that they were colluding to rig prices. By assembling a longitudinal data-set, Zechner exposed the raft of dirty tricks the grocers used to rip off the people of Austria.
From shrinkflation to deceptive price-cycling that disguised price hikes as discounts:
https://mastodon.gamedev.place/@badlogic/111071627182734180
Zechner feared publishing his results at first. The companies whose thefts he'd discovered have enormous power and whole kennelsful of vicious attack-lawyers they can sic on him. But he eventually got the Austrian competition bureaucracy interested in his work, and they published a report that validated his claims and praised his work:
https://mastodon.gamedev.place/@badlogic/111071673594791946
Emboldened, Zechner open-sourced his monitoring tool, and attracted developers from other countries. Soon, they were documenting ripoffs in Germany and Slovenia, too:
https://mastodon.gamedev.place/@badlogic/111071485142332765
Zechner's on a roll, but the grocery cartel could shut him down with a keystroke, simply by blocking his API access. If they do, Zechner could switch to scraping their sites – but only if he can be protected from legal liability for nonconsensually scraping commercially sensitive data in a way that undermines the profits of a powerful corporation.
Zechner's work comes at a crucial time, as grocers around the world turn the screws on both their suppliers and their customers, disguising their greedflation as inflation. In Canada, the grocery cartel – led by the guillotine-friendly hereditary grocery monopolilst Galen Weston – pulled the most Les Mis-ass caper imaginable when they illegally conspired to rig the price of bread:
https://en.wikipedia.org/wiki/Bread_price-fixing_in_Canada
We should scrape all of these looting bastards, even though it will harm their economic interests. We should scrape them because it will harm their economic interests. Scrape 'em and scrape 'em and scrape 'em.
Now, it's one thing to scrape text for scholarly purposes, or for journalistic accountability, or to uncover criminal corporate conspiracies. But what about scraping to train a Large Language Model?
Yes, there are socially beneficial – even vital – uses for LLMs.
Take HRDAG's work on truth and reconciliation in Colombia. The Human Rights Data Analysis Group is a tiny nonprofit that makes an outsized contribution to human rights, by using statistical methods to reveal the full scope of the human rights crimes that take place in the shadows, from East Timor to Serbia, South Africa to the USA:
https://hrdag.org/
HRDAG's latest project is its most ambitious yet. Working with partner org Dejusticia, they've just released the largest data-set in human rights history:
https://hrdag.org/jep-cev-colombia/
What's in that dataset? It's a merger and analysis of more than 100 databases of killings, child soldier recruitments and other crimes during the Colombian civil war. Using a LLM, HRDAG was able to produce an analysis of each killing in each database, estimating the probability that it appeared in more than one database, and the probability that it was carried out by a right-wing militia, by government forces, or by FARC guerrillas.
This work forms the core of ongoing Colombian Truth and Reconciliation proceedings, and has been instrumental in demonstrating that the majority of war crimes were carried out by right-wing militias who operated with the direction and knowledge of the richest, most powerful people in the country. It also showed that the majority of child soldier recruitment was carried out by these CIA-backed, US-funded militias.
This is important work, and it was carried out at a scale and with a precision that would have been impossible without an LLM. As with all of HRDAG's work, this report and the subsequent testimony draw on cutting-edge statistical techniques and skilled science communication to bring technical rigor to some of the most important justice questions in our world.
LLMs need large bodies of text to train them – text that, inevitably, is scraped. Scraping to produce LLMs isn't intrinsically harmful, and neither are LLMs. Admittedly, nonprofits using LLMs to build war crimes databases do not justify even 0.0001% of the valuations that AI hypesters ascribe to the field, but that's their problem.
Scraping is good, sometimes – even when it's done against the wishes of the scraped, even when it harms their interests, and even when it's used to train an LLM.
But.
Scraping to violate peoples' privacy is very bad. Take Clearview AI, the grifty, sleazy facial recognition company that scraped billions of photos in order to train a system that they sell to cops, corporations and authoritarian governments:
https://pluralistic.net/2023/09/20/steal-your-face/#hoan-ton-that
Likewise: scraping to alienate creative workers' labor is very bad. Creators' bosses are ferociously committed to firing us all and replacing us with "generative AI." Like all self-declared "job creators," they constantly fantasize about destroying all of our jobs. Like all capitalists, they hate capitalism, and dream of earning rents from owning things, not from doing things.
The work these AI tools sucks, but that doesn't mean our bosses won't try to fire us and replace us with them. After all, prompting an LLM may produce bad screenplays, but at least the LLM doesn't give you lip when you order to it give you "ET, but the hero is a dog, and there's a love story in the second act and a big shootout in the climax." Studio execs already talk to screenwriters like they're LLMs.
That's true of art directors, newspaper owners, and all the other job-destroyers who can't believe that creative workers want to have a say in the work they do – and worse, get paid for it.
So how do we resolve these conundra? After all, the people who scrape in disgusting, depraved ways insist that we have to take the good with the bad. If you want accountability for newspaper sites, you have to tolerate facial recognition, too.
When critics of these companies repeat these claims, they are doing the companies' work for them. It's not true. There's no reason we couldn't permit scraping for one purpose and ban it for another.
The problem comes when you try to use copyright to manage this nuance. Copyright is a terrible tool for sorting out these uses; the limitations and exceptions to copyright (like fair use) are broad and varied, but so "fact intensive" that it's nearly impossible to say whether a use is or isn't fair before you've gone to court to defend it.
But copyright has become the de facto regulatory default for the internet. When I found someone impersonating me on a dating site and luring people out to dates, the site advised me to make a copyright claim over the profile photo – that was their only tool for dealing with this potentially dangerous behavior.
The reasons that copyright has become our default tool for solving every internet problem are complex and historically contingent, but one important point here is that copyright is alienable, which means you can bargain it away. For that reason, corporations love copyright, because it means that they can force people who have less power than the company to sign away their copyrights.
This is how we got to a place where, after 40 years of expanding copyright (scope, duration, penalties), we have an entertainment sector that's larger and more profitable than ever, even as creative workers' share of the revenues their copyrights generate has fallen, both proportionally and in real terms.
As Rebecca Giblin and I write in our book Chokepoint Capitalism, in a market with five giant publishers, four studios, three labels, two app platforms and one ebook/audiobook company, giving creative workers more copyright is like giving your bullied kid extra lunch money. The more money you give that kid, the more money the bullies will take:
https://chokepointcapitalism.com/
Many creative workers are suing the AI companies for copyright infringement for scraping their data and using it to train a model. If those cases go to trial, it's likely the creators will lose. The questions of whether making temporary copies or subjecting them to mathematical analysis infringe copyright are well-settled:
https://www.eff.org/deeplinks/2023/04/ai-art-generators-and-online-image-market
I'm pretty sure that the lawyers who organized these cases know this, and they're betting that the AI companies did so much sleazy shit while scraping that they'll settle rather than go to court and have it all come out. Which is fine – I relish the thought of hundreds of millions in investor capital being transferred from these giant AI companies to creative workers. But it doesn't actually solve the problem.
Because if we do end up changing copyright law – or the daily practice of the copyright sector – to create exclusive rights over scraping and training, it's not going to get creators paid. If we give individual creators new rights to bargain with, we're just giving them new rights to bargain away. That's already happening: voice actors who record for video games are now required to start their sessions by stating that they assign the rights to use their voice to train a deepfake model:
https://www.vice.com/en/article/5d37za/voice-actors-sign-away-rights-to-artificial-intelligence
But that doesn't mean we have to let the hyperconcentrated entertainment sector alienate creative workers from their labor. As the WGA has shown us, creative workers aren't just LLCs with MFAs, bargaining business-to-business with corporations – they're workers:
https://pluralistic.net/2023/08/20/everything-made-by-an-ai-is-in-the-public-domain/
Workers get a better deal with labor law, not copyright law. Copyright law can augment certain labor disputes, but just as often, it benefits corporations, not workers:
https://locusmag.com/2019/05/cory-doctorow-steering-with-the-windshield-wipers/
Likewise, the problem with Clearview AI isn't that it infringes on photographers' copyrights. If I took a thousand pictures of you and sold them to Clearview AI to train its model, no copyright infringement would take place – and you'd still be screwed. Clearview has a privacy problem, not a copyright problem.
Giving us pseudocopyrights over our faces won't stop Clearview and its competitors from destroying our lives. Creating and enforcing a federal privacy law with a private right action will. It will put Clearview and all of its competitors out of business, instantly and forever:
https://www.eff.org/deeplinks/2019/01/you-should-have-right-sue-companies-violate-your-privacy
AI companies say, "You can't use copyright to fix the problems with AI without creating a lot of collateral damage." They're right. But what they fail to mention is, "You can use labor law to ban certain uses of AI without creating that collateral damage."
Facial recognition companies say, "You can't use copyright to ban scraping without creating a lot of collateral damage." They're right too – but what they don't say is, "On the other hand, a privacy law would put us out of business and leave all the good scraping intact."
Taking entertainment companies and AI vendors and facial recognition creeps at their word is helping them. It's letting them divide and conquer people who value the beneficial elements and those who can't tolerate the harms. We can have the benefits without the harms. We just have to stop thinking about labor and privacy issues as individual matters and treat them as the collective endeavors they really are:
https://pluralistic.net/2023/02/26/united-we-stand/
Here's a link to the podcast:
https://craphound.com/news/2023/09/24/how-to-think-about-scraping/
And here's a direct link to the MP3 (hosting courtesy of the Internet Archive; they'll host your stuff for free, forever):
https://archive.org/download/Cory_Doctorow_Podcast_450/Cory_Doctorow_Podcast_450_-_How_To_Think_About_Scraping.mp3
And here's the RSS feed for my podcast:
http://feeds.feedburner.com/doctorow_podcast
If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2023/09/25/deep-scrape/#steering-with-the-windshield-wipers

Image:
syvwlch (modified)
https://commons.wikimedia.org/wiki/File:Print_Scraper_(5856642549).jpg
CC BY-SA 2.0
https://creativecommons.org/licenses/by/2.0/deed.en
#pluralistic#cory doctorow#podcast#scraping#internet archive#wga strike#sag-aftra strike#wga#sag-aftra#labor#privacy#facial recognition#clearview ai#greedflation#price gouging#fr#austria#computational linguistics#linguistics#ai#ml#artificial intelligence#machine learning#llms#large language models#stochastic parrots#plausible sentence generators#hrdag#colombia#human rights
78 notes
·
View notes
Text

Sen. Ed Markey (D-Mass.) sent a letter Tuesday to the Department of Homeland Security (DHS) urging it to discontinue the use of a smartphone app required by migrants seeking asylum at the southern border to use.
The CBP One app, which was rolled out in 2021, was established to allow migrants to submit applications for asylum before they cross the U.S. border. Markey said in his letter that requiring migrants to submit sensitive information, including biometric and location data, on the app raises “serious privacy concerns,” and demanded that the DHS cease its use of it.
“This expanded use of the CBP One app raises troubling issues of inequitable access to — and impermissible limits on — asylum, and has been plagued by significant technical problems and privacy concerns. DHS should shelve the CBP One app immediately,” Markey said in his letter.
“Rather than mandating use of an app that is inaccessible to many migrants, and violates both their privacy and international law, DHS should instead implement a compassionate, lawful, and human rights centered approach for those seeking asylum in the United States,” he continued.
He said that the use of this technology has also faced technical problems, including with its facial recognition software misidentifying people of color.
“Technology can facilitate asylum processing, but we cannot allow it to create a tiered system that treats asylum seekers differently based on their economic status — including the ability to pay for travel — language, nationality, or race,” he said.
The app has negative ratings on both the Google Play and Apple app stores, with many users criticizing the app for crashing and other technical issues.
(continue reading)
#politics#ed markey#immigration#asylum seekers#joe biden#cbp one app#dhs#privacy rights#surveillance state#facial recognition
54 notes
·
View notes
Photo

machines make images for other machines
#art#collage#digital#painting#overlay#facial recognition#retorufuture#design#probability#possibility
368 notes
·
View notes
Last Seen Blogs

cerkezkoynazli-blog
ÇERKEZKÖY TRAVESTİ NAZLI 0544 414 00 28

ireallylovecats
ಠ_ಠ

r3m-ster
self-proclaimed great poet ⚢

sharkb497
SharkBloody

feral-geges
feral geges