#tumblr is going to sell your blog posts to AI
Text
According to an online report, Automattic/Tumblr plans to sell people's blog posts to AI companies.
OPT OUT!
Be sure to OPT OUT.
OPT OUT
Say hell no. No backstabbing your fellow creatives. Opt out.
The Opt out should start on Wednesday, tomorrow. February 28, 2024.
Also, while you're at it, complain to the FTC.
The FTC has a twitter account.
They've even scraped data they weren't supposed to like dead blogs.
#AI#tumblr is going to sell your blog posts to AI#Opt Out#Scream at them about it#If they are getting PAID for OUR work they need to pay us#Say no
8 notes
·
View notes
Text
Your posts are in an AI model
and then Tumblr decided to sell them to AI models.
Now, don't get me wrong, tumblr selling out the users to AI companies is bad, yes, they shouldn't do that. It sucks.
but don't lets get this confused: your posts were already in there. Tumblr selling them is about tumblr making some money and about the AI models having more exhaustive post collections. It's not about your posts being in an AI model, vs not being in one. That battle has already been lost.
Can you find your post on google? Then it's almost certainly in an AI model already. Think about it: These AI sites showed up before all the sites were making deals to sell their users' content, right? How do you think they built them in the first place?
They scraped the posts. Just like google and bing and such do when they build their search indexes.
It's a fundamental part of how the open web works: you want your posts on tumblr to be visible to users, right? You want them to be readable?* Like, look how much stuff broke when twitter changed their whole read-while-not-logged-in policy, ruining a bunch of thread links/NSFW links. And if it's visible, it's scrapable. That's what the AI models were built on.
I've done website scraping before (not for AI models, of course. I was doing search engines and website archival), this is just how it works. You hire a few relatively smart CS graduates and tell them "build me a scraper that'll give us a bunch of tumblr posts" and they go off for a month or two and come back with a database of a few billion posts, and you stuff that into your AI model. That's how they got all the deviantart and flickr and twitter and pinterest and so on posts. They didn't pay for them: they just took them.
They only ever pay for this shit because either:
they fucked up in such a way that the site might be able to sue them for taking rather than paying
They can buy them cheaper than they can finish taking them. Maybe they'd need to pay the CS grads for an extra month? well, that might be more expensive than just throwing the site a couple hundred thousand bucks.
ANYWAY: my point is, don't treat this "oh no tumblr is selling our posts to AI" like it's a big thing that might happen and it would be bad to happen. Yes, it's bad, tumblr shouldn't do this, this'll let AI models get continual updates of content for far easier than just scraping them would be, tumblr betrayed user trust, and so on...
but realistically, this is not a black and white matter of "if only tumblr didn't do this, then we'd be safe from AI models!"
Nope. We already lost that battle. I'm sorry, and it does suck, but that's just how it is. The avalanche has already started, it's too late for the pebbles to vote.
* I'm assuming here that you don't run a private blog that's set to only followers or something. You'd be safer then, of course, but you're not really my target audience for this rant
14K notes
·
View notes
Text
FYI artists and writers: some info regarding tumblr's new "third-party sharing" (aka selling your content to OpenAI and Midjourney)
You may have already seen the post by @staff regarding third-party sharing and how to opt out. You may have also already seen various news articles discussing the matter.
But here's a little further clarity re some questions I had, and you may too. Caveat: Not all of this is on official tumblr pages, so it's possible things may change.
(1) "I heard they already have access to my data and it doesn't really matter if I opt out"
From the 404 article:
A new FAQ section we reviewed is titled “What happens when you opt out?” states “If you opt out from the start, we will block crawlers from accessing your content by adding your site on a disallowed list. If you change your mind later, we also plan to update any partners about people who newly opt-out and ask that their content be removed from past sources and future training.”
So please, go click that opt-out button.
(2) Some future user: "I've been away from tumblr for months, and I just heard about all this. I didn't opt out before, so does it make a difference anymore?"
Another internal document shows that, on February 23, an employee asked in a staff-only thread, “Do we have assurances that if a user opts out of their data being shared with third parties that our existing data partners will be notified of such a change and remove their data?”
Andrew Spittle, Automattic’s head of AI replied: “We will notify existing partners on a regular basis about anyone who's opted out since the last time we provided a list. I want this to be an ongoing process where we regularly advocate for past content to be excluded based on current preferences. We will ask that content be deleted and removed from any future training runs. I believe partners will honor this based on our conversations with them to this point. I don't think they gain much overall by retaining it.”
It should make a difference! Go click that button.
(3) "I opted out, but my art posts have been reblogged by so many people, and I don't know if they all opted out. What does that mean for my stuff?"
This answer is actually on the support page for the toggle:
This option will prevent your blog's content, even when reblogged, from being shared with our licensed network of content and research partners, including those that train AI models.
And some further clarification by the COO and a product manager:
zingring: A couple people from work have reached out to let me know that yes, it applies to reblogs of "don't scrape" content. If you opt out, your content is opted out, even in reblog form.
cyle: yep, for reblogs, we're taking it so far as "if anybody in the reblog trail has opted out, all of the content in that reblog will be opted out", when a reblog could be scraped/shared.
So not only your reblogged posts, but anyone who contributed in a reblog (such as posts where someone has been inspired to draw fanart of the OP) will presumably be protected by your opt-out. (A good reason to opt out even if you yourself are not a creator.)
Furthermore, if you the OP were offline and didn't know about the opt-out, if someone contributed to a reblog and they are opted out, then your original work is also protected. (Which makes it very tempting to contribute "scrapeable content" now whenever I reblog from an abandoned/disused blog...)
(4) "What about deleted blogs? They can't opt out!"
I was told by someone (not official) that he read "deleted blogs are all opted-out by default". However, he didn't recall the source, and I can't find it, so I can't guarantee that info. If I get more details - like if/when tumblr puts up that FAQ as reported in the 404 article - I will add it here as soon as I can.
Edit, tumblr has updated their help page for the option to opt-out of third-party sharing! It now states:
The content which will not be shared with our licensed network of content and research partners, including those that train AI models, includes:
• Posts and reblogs of posts from blogs who have enabled the "Prevent third-party sharing" option.
• Posts and reblogs of posts from deleted blogs.
• Posts and reblogs of posts from password-protected blogs.
• Posts and reblogs of posts from explicit blogs.
• Posts and reblogs of posts from suspended/deactivated blogs.
• Private posts.
• Drafts.
• Messages.
• Asks and submissions which have not been publicly posted.
• Post+ subscriber-only posts.
• Explicit posts.
So no need to worry about your old deleted blogs that still have reblogs floating around. *\o/*
But for your existing blogs, please use the opt out option. And a reminder of how to opt out, under the cut:
The opt-out toggle is in Blog Settings, and please note you need to do it for each one of your blogs / sideblogs.
On dashboard, the toggle is at https://www.tumblr.com/settings/blog/blogname [replace "blogname" as applicable] down by Visibility:

For mobile, you need the most recent update of the app. (Android version 33.4.1.100, iOs version 33.4.) Then go to your blog tab (the little person icon), and then the gear icon for Settings, then click Visibility.
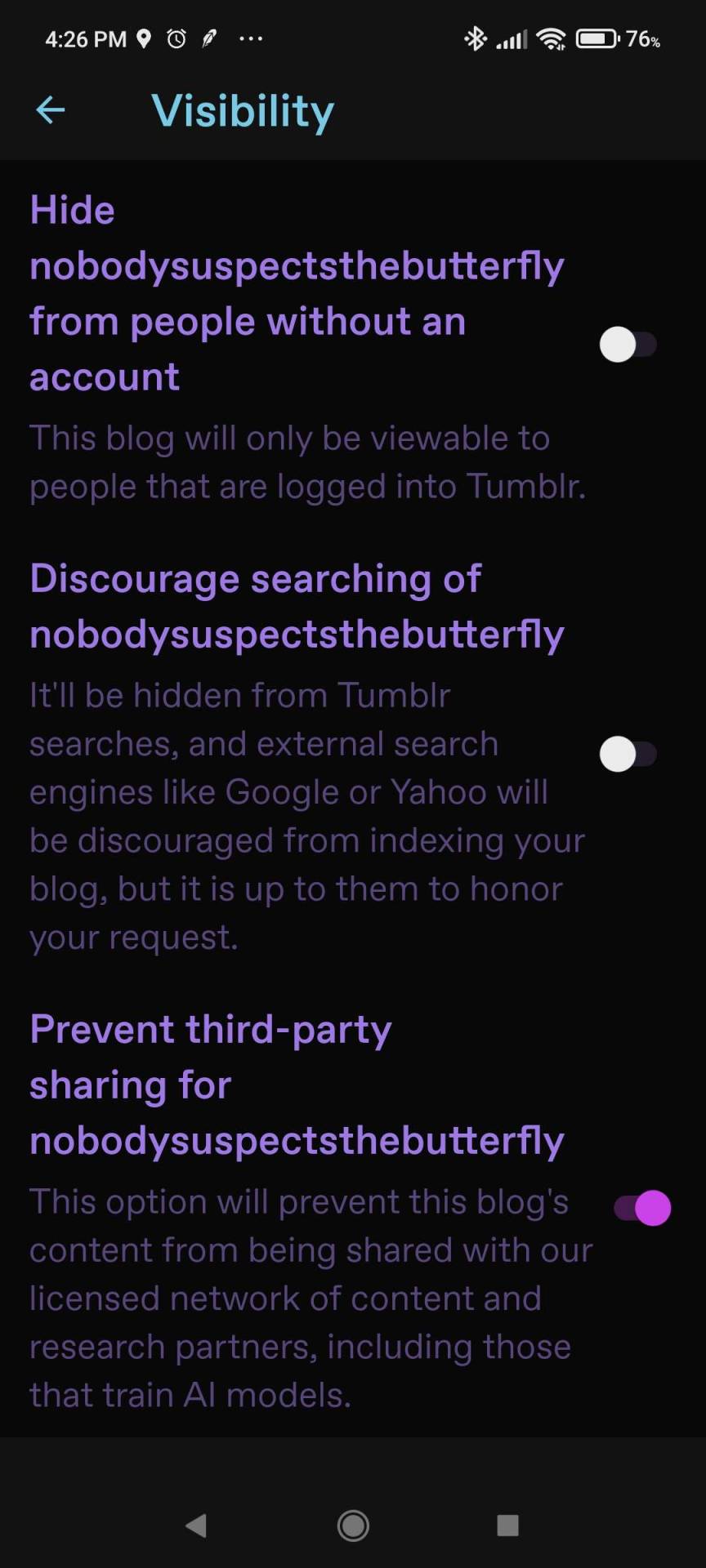
Again, if you have a sideblog, go back to the blog tab, switch to it, and go to settings again. Repeat as necessary.
If you do not have access to the newest version of the app for whatever reason, you can also log into tumblr in your mobile browser. Same URL as per desktop above, same location.
Note you do not need to change settings in both desktop and the app, just one is fine.
I hope this helps!
#tumblr#[tumblr]#third party sharing#openai#midjourney#chatgpt#ai art#ai#fyi#psa#anti-FUD#artists on tumblr#writers on tumblr#illustrators on tumblr#tumblr update#oh tumblr#hellsite (derogatory)#“opt out” no longer looks like a word#but still#opt out my friends#please#also if you want to leave tumblr i don't blame you but please remember to hit that opt-out button before you go
3K notes
·
View notes
Text
AI Sellout
Used an email mask to read the whole article, pasting it below the cut.
Quick important points:
The tweet content is a list of things that are currently included, but were not SUPPOSED TO BE, and engineers are working to scrub it.
Automattic is supposedly going to add an opt out option.
Automattic did not respond to a question from 404 Media about whether it could guarantee that people who opt out will have their data deleted retroactively.
Tumblr and Wordpress are preparing to sell user data to Midjourney and OpenAI, according to a source with internal knowledge about the deals and internal documentation referring to the deals.
The exact types of data from each platform going to each company are not spelled out in documentation we’ve reviewed, but internal communications reviewed by 404 Media make clear that deals between Automattic, the platforms’ parent company, and OpenAI and Midjourney are imminent.
The internal documentation details a messy and controversial process within Tumblr itself. One internal post made by Cyle Gage, a product manager at Tumblr, states that a query made to prepare data for OpenAI and Midjourney compiled a huge number of user posts that it wasn’t supposed to. It is not clear from Gage’s post whether this data has already been sent to OpenAI and Midjourney, or whether Gage was detailing a process for scrubbing the data before it was to be sent.
Gage wrote:
“the way the data was queried for the initial data dump to Midjourney/OpenAI means we compiled a list of all tumblr’s public post content between 2014 and 2023, but also unfortunately it included, and should not have included:
private posts on public blogs
posts on deleted or suspended blogs
unanswered asks (normally these are not public until they’re answered)
private answers (these only show up to the receiver and are not public)
posts that are marked ‘explicit’ / NSFW / ‘mature’ by our more modern standards (this may not be a big deal, I don’t know)
content from premium partner blogs (special brand blogs like Apple’s former music blog, for example, who spent money with us on an ad campaign) that may have creative that doesn’t belong to us, and we don’t have the rights to share with this-parties; this one is kinda unknown to me, what deals are in place historically and what they should prevent us from doing.”
Gage’s post makes clear that engineers are working on compiling a list of post IDs that should not have been included, and that password-protected posts, DMs, and media flagged as CSAM and other community guidelines violations were not included.
Automattic plans to launch a new setting on Wednesday that will allow users to opt-out of data sharing with third parties, including AI companies, according to the source, who spoke on the condition of anonymity, and internal documents. A new FAQ section we reviewed is titled “What happens when you opt out?” states that “If you opt out from the start, we will block crawlers from accessing your content by adding your site on a disallowed list. If you change your mind later, we also plan to update any partners about people who newly opt-out and ask that their content be removed from past sources and future training.”
404 Media has asked Automattic how it accidentally compiled data that it shouldn’t share, and whether any of that content was shared with OpenAI, but did not immediately hear back from the company. 404 Media asked Automattic about an imminent deal with Midjourney last week but did not hear back then, either.
Another internal document shows that, on February 23, an employee asked in a staff-only thread, “Do we have assurances that if a user opts out of their data being shared with third parties that our existing data partners will be notified of such a change and remove their data?”
Andrew Spittle, Automattic’s head of AI replied: “We will notify existing partners on a regular basis about anyone who's opted out since the last time we provided a list. I want this to be an ongoing process where we regularly advocate for past content to be excluded based on current preferences. We will ask that content be deleted and removed from any future training runs. I believe partners will honor this based on our conversations with them to this point. I don't think they gain much overall by retaining it.” Automattic did not respond to a question from 404 Media about whether it could guarantee that people who opt out will have their data deleted retroactively.
News about a deal between Tumblr and Midjourney has been rumored and speculated about on Tumblr for the last week. Someone claiming to be a former Tumblr employee announced in a Tumblr blog post that the platform was working on a deal with Midjourney, and the rumor made it onto Blind, an app for verified employees of companies to anonymously discuss their jobs. 404 Media has seen the Blind posts, in which what seems like an Automattic employee says, “I'm not sure why some of you are getting worked up or worried about this. It's totally legal, and sharing it publicly is perfectly fine since it's right there in the terms & conditions. So, go ahead and spread the word as much as you can with your friends and tech journalists, it's totally fine.”
Separately, 404 Media viewed a public, now-deleted post by Gage, the product manager, where he said that he was deleting all of his images off of Tumblr, and would be putting them on his personal website. A still-live post says, “i've deleted my photography from tumblr and will be moving it slowly but surely over to cylegage.com, which i'm building into a photography portfolio that i can control end-to-end.” At one point last week, his personal website had a specific note stating that he did not consent to AI scraping of his images. Gage’s original post has been deleted, and his website is now a blank page that just reads “Cyle.” Gage did not respond to a request for comment from 404 Media.
Several online platforms have made similar deals with AI companies recently, including Reddit, which entered into an AI content licensing deal with Google and said in its SEC filing last week that it’s “in the early stages of monetizing [its] user base” by training AI on users’ posts. Last year, Shutterstock signed a six year deal with OpenAI to provide training data.
OpenAI and Midjourney did not respond to requests for comment.
985 notes
·
View notes
Text
How to Tell If That Post of Advice Is AI Bullshit
Right, I wasn't going to write more on this, but every time I block an obvious AI-driven blog, five more clutter up the tags. So this is my current (April 2024) advice on how to spot AI posts passing themselves off as useful writing advice.
No Personality - Look up a long-running writing blog, you'll notice most people try to make their posts engaging and coming from a personal perspective. We do this because we're writers and, well, we want to convey a sense of ourselves to our readers. A lot of AI posts are straight-forward - no sense of an actual person writing them, no variation in tone or text.
No Examples - No attempts to show how pieces of advice would work in a story, or cite a work where you could see it in action. An AI post might tell you to describe a person by highlighting two or three features, and that's great, but it's hard to figure out how that works without an example.
Short, Unhelpful Definitions - A lot of what I've seen amount to two or three-sentence listicles. 'When you want to write foreshadowing, include a hint of what you want foreshadowed in an earlier chapter.' Cool beans, could've figured that out myself.
SEO/AI Prompt Language Included - I've seen way too many posts start with "this post is about..." or "now we will discuss..." or "in this post we will..." in every single blog. This language is meant to catch a search engine or is ChatGPT reframing the prompt question. It's not a natural way of writing a post for the average tumblr user.
Oddly Clinical Language - Right, I'm calling out that post that tried to give advice on writing gay characters that called us "homosexuals" the entire time. That's a generative machine trying to stay within certain parameters, not an actual person who knows that's not a word you'd use unless you were trying to be insulting or dunking on your own gay ass in the funniest way possible.
Too Perfect - Most generative AI does not make mistakes (this is how many a student gets caught trying to use it to cheat). You can find ways to make it sound more natural and have it make mistakes, but that takes time and effort, and neither of those are really a factor in these posts. They also tend to have really polished graphics and use the same format every time.
Maximized Tags (That Are Pointless) - Anyone who uses more than 10 one-word tags is a cop. Okay, fine, I'm joking, but there's a minimal amount of tags that are actually useful when promoting a post. More tags are not going to get a post noticed by the algorithm, there is no algorithm. Not everyone has to use their tags to make snarky comments, but if your tags look like a spambot, I'm gonna assume you're a spambot.
No Reblogs From The Rest of Writblr - I'm always finding new Writblr folks who have been around for awhile, but every real person I've seen reblogs posts from other people. We've all got other stuff to do, I'm writing this blog to help others and so are they, the whole point of tumblr is to pass along something you think is great.
While you'll probably see some variation in the future - as people get wise to obviously generated text, they'll try to make it look less generated - but overall, there's still going to be tells to when something is fake.
I don't have any real advice for what to do about this (other than block those blogs, which is what I do). Like most AI bullshit, I suspect most of these blogs are just another grift, attempting to build large follower counts to leverage or sell something to in the future. They may progress past these tattletale features, but I'm still going to block them when I see them. I don't see any value in writing advice compiled from the work of better writers who put the effort in when I can just go find those writers myself.
415 notes
·
View notes
Text
I stopped using Jetpack when they started charging for it. WordPress friends: here's a reason (if you're still using it) to adjust your settings. (tl:dr; turn off "enhanced distribution".)
What this means (or at least suggests) for Wordpress users, whether their blogs are self-hosted (like all the ones in our household) or hosted at Wordpress.org:
Go through your working plugins, from whatever source. Start investigating whether, and/or to whom, they are selling your data for training. This is going to be more small-print-reading than I remember signing up for... but (sighing at the echo of the voice of Abe Lincoln), "The dogmas of the quiet past are inadequate to the stormy present. The occasion is piled high with difficulty, and we must rise with the occasion."
And if you have the time, email your plugin providers and ask for a clear and straightforward answer to the question "Are you using my content to train AI apps?" If they won't give you an answer... dump them.
465 notes
·
View notes
Text
In case anyone else has the same problem I did...
I wanted to opt out of tumblr's new abyssmally tone-deaf and reprehensible scheme to scrape their users' content to sell to their generative AI business partners, but neither app or desktop version showed the toggle, despite updates.
For me, what finally worked was to go to tumblr.com/settings/blog/x (where x is the username of your blog) in a web browser and scroll all the way down.
There I finally found the toggle to opt out.
Please opt out, in solidarity with artists and writers and other creatives, to protect yourself - and to send the higher-up a clear message that we tumblr users aren't "content", and our posts are not for sale.
225 notes
·
View notes
Text
I don't think people responding to the scrambled "uh oh, we got caught" Tumblr AI announcement with "just nightshade and glaze all the art you post guys! it's your own fault if you don't do that small step! It's ok we'll get through this!" are Getting It:
Everything has already been scraped, including the account you haven't been able to access since 2015. Yes even the private, locked sideblogs of all your old art. Did you glaze it? did you nightshade it? in 2015? can you log in and check? no? Opted in.
This also includes any writing, creative or otherwise, posted to Tumblr. Did you nightshade the poetry and fanfiction you posted to Tumblr on your old account in 2018? why not? not a plan-aheader huh? Opted in!
It's opt in by default and by design. People who left Tumblr ages ago will likely not hear about this and won't know to regain account access and opt out. People who have died won't be able to log in and opt out. People who deleted past accounts or sideblogs won't be able to log in and opt out. People whose content is reposted here from Pixiv or other external sources by unrelated third parties won't have any way to say "hey half of that blog is MY stuff. Opt ME out."
Sorry. They just have everything ever put on the site. And you didn't opt out in 2015 when you lost access to your login email, so it's included. This is on purpose because they don't WANT people to be able to opt out, they want people to stay opted in saying "well my art sucks so I'm poisoning the data model 👍" while posting jokes and creative writing, they WANT you to say "well I'm unaffected" and keep posting photos and text and stuff. Midjourney wants that and Tumblr wants to do anything it can to satisfy Midjourney and scrape some cash out of that deal.
I'm sorry because I love this place too, but genuinely the decisions being made here are business decisions being put into place by a company trying to squeeze the last drops of blood out of a stone. Tumblr is not your friend. Staff is not your friend. Automattic is not your friend. The CEO has hopefully PROVEN he is not anyone's friend. This is a business first and a product that they are selling, not to you and me, but to advertisers and partners. Tumblr will ensure that Tumblr users see their ads and supply them data.
Frankly I do not trust this company or this website and I cannot in good faith just believe that they're going to look at my opt out checkbox and say "okay! ^_^ we will remove everything Dama has ever said or done from our AI scrape. we promise to do it!" and then actually do it. They already have the data. They can just claim that whatever is produced through machine learning based in part off of my data is unrelated, came from other sources, etc. I do not have trust in this website. I don't see how anyone could at this point.
I feel like I'm watching a trainwreck from the inside and no one wants to get out of their seats and try hopping off into the safe grassy field. Wait, they say. Let's see if the train just climbs back onto the tracks, they say. The fire and explosions are all part of the process, they say. Eventually people will stop panicking or dying and it'll be a smooth ride, they say. Just look at how bright the horizon is.
211 notes
·
View notes
Text
Since I had to turn this on individually for all my sideblogs, I'm going to post about it on all my sideblogs.
Tumblr is going to be selling data to train AIs. If you don't want your posts used for that purpose, follow these steps:
1, Go into your blog settings. This is separate from your main settings, you have to go through an individual blog.
2, Scroll down to the "Visibility" section. This is near the bottom of your blog settings.
3, Find the toggle that says "Prevent third-party sharing for *blog name*" and turn it on.
4, Repeat for every sideblog you have. You will have to individually turn it on for all of your sideblogs, whether you have two or twenty.
218 notes
·
View notes
Text
Tumblr sold user's posts to AI. You have to opt OUT.
Just putting this up here again, in case you forgot. 100% confirmed by tumblr.
This means your art, etc any contents.
4 notes
·
View notes
Text
Full text of article as follows:
Tumblr and Wordpress are preparing to sell user data to Midjourney and OpenAI, according to a source with internal knowledge about the deals and internal documentation referring to the deals.
The exact types of data from each platform going to each company are not spelled out in documentation we’ve reviewed, but internal communications reviewed by 404 Media make clear that deals between Automattic, the platforms’ parent company, and OpenAI and Midjourney are imminent.
The internal documentation details a messy and controversial process within Tumblr itself. One internal post made by Cyle Gage, a product manager at Tumblr, states that a query made to prepare data for OpenAI and Midjourney compiled a huge number of user posts that it wasn’t supposed to. It is not clear from Gage’s post whether this data has already been sent to OpenAI and Midjourney, or whether Gage was detailing a process for scrubbing the data before it was to be sent.
Gage wrote:
“the way the data was queried for the initial data dump to Midjourney/OpenAI means we compiled a list of all tumblr’s public post content between 2014 and 2023, but also unfortunately it included, and should not have included:
private posts on public blogs
posts on deleted or suspended blogs
unanswered asks (normally these are not public until they’re answered)
private answers (these only show up to the receiver and are not public)
posts that are marked ‘explicit’ / NSFW / ‘mature’ by our more modern standards (this may not be a big deal, I don’t know)
content from premium partner blogs (special brand blogs like Apple’s former music blog, for example, who spent money with us on an ad campaign) that may have creative that doesn’t belong to us, and we don’t have the rights to share with this-parties; this one is kinda unknown to me, what deals are in place historically and what they should prevent us from doing.”
Gage’s post makes clear that engineers are working on compiling a list of post IDs that should not have been included, and that password-protected posts, DMs, and media flagged as CSAM and other community guidelines violations were not included.
Automattic plans to launch a new setting on Wednesday that will allow users to opt-out of data sharing with third parties, including AI companies, according to the source, who spoke on the condition of anonymity, and internal documents. A new FAQ section we reviewed is titled “What happens when you opt out?” states that “If you opt out from the start, we will block crawlers from accessing your content by adding your site on a disallowed list. If you change your mind later, we also plan to update any partners about people who newly opt-out and ask that their content be removed from past sources and future training.”
404 Media has asked Automattic how it accidentally compiled data that it shouldn’t share, and whether any of that content was shared with OpenAI. 404 Media asked Automattic about an imminent deal with Midjourney last week but did not hear back then, either. Instead of answering direct questions about these deals and the compiling of user data, Automattic sent a statement, which it posted publicly after this story was published, titled "Protecting User Choice." In it, Automattic promises that it's blocked AI crawlers from scraping its sites. The statement says, "We are also working directly with select AI companies as long as their plans align with what our community cares about: attribution, opt-outs, and control. Our partnerships will respect all opt-out settings. We also plan to take that a step further and regularly update any partners about people who newly opt out and ask that their content be removed from past sources and future training."
Another internal document shows that, on February 23, an employee asked in a staff-only thread, “Do we have assurances that if a user opts out of their data being shared with third parties that our existing data partners will be notified of such a change and remove their data?”
Andrew Spittle, Automattic’s head of AI replied: “We will notify existing partners on a regular basis about anyone who's opted out since the last time we provided a list. I want this to be an ongoing process where we regularly advocate for past content to be excluded based on current preferences. We will ask that content be deleted and removed from any future training runs. I believepartners will honor this based on our conversations with them to this point. I don't think they gain much overall by retaining it.” Automattic did not respond to a question from 404 Media about whether it could guarantee that people who opt out will have their data deleted retroactively.
News about a deal between Tumblr and Midjourney has been rumored and speculated about on Tumblr for the last week. Someone claiming to be a former Tumblr employee announced in a Tumblr blog post that the platform was working on a deal with Midjourney, and the rumor made it onto Blind, an app for verified employees of companies to anonymously discuss their jobs. 404 Media has seen the Blind posts, in which what seems like an Automattic employee says, “I'm not sure why some of you are getting worked up or worried about this. It's totally legal, and sharing it publicly is perfectly fine since it's right there in the terms & conditions. So, go ahead and spread the word as much as you can with your friends and tech journalists, it's totally fine.”
Separately, 404 Media viewed a public, now-deleted post by Gage, the product manager, where he said that he was deleting all of his images off of Tumblr, and would be putting them on his personal website. A still-live postsays, “i've deleted my photography from tumblr and will be moving it slowly but surely over to cylegage.com, which i'm building into a photography portfolio that i can control end-to-end.” At one point last week, his personal website had a specific note stating that he did not consent to AI scraping of his images. Gage’s original post has been deleted, and his website is now a blank page that just reads “Cyle.” Gage did not respond to a request for comment from 404 Media.
Several online platforms have made similar deals with AI companies recently, including Reddit, which entered into an AI content licensing deal with Google and said in its SEC filing last week that it’s “in the early stages of monetizing [its] user base” by training AI on users’ posts. Last year, Shutterstock signed a six year deal with OpenAI to provide training data.
OpenAI and Midjourney did not respond to requests for comment.
Updated 4:05 p.m. EST with a statement from Automattic.
#It’s amazing how dishonest the staff post was#Original post#Posted for the convenience of users who are not currently subscribed to 404 media#But you absolutely should they’re great#10/10 highly recommended
159 notes
·
View notes
Text
in case you havent seen this post (or just don't want to read it), tumblr might be selling art posted here to midjourney AI. most likely very soon.
i have no idea if this is true, and i'm skeptical to believe something with no proof, but this is a very good reminder to export your blog and be using glaze or nightshade on all future art you post to poison the AI models. if they really are going to give art to AI, deleting your art will do next to nothing unless you can get every person who's ever reblogged your art to delete it, which is just unrealistic. if the deal doesn't go through, poisoning AI models through your art is good practice anyway.
#definite's ted talks#unfortunately this is all that can be done because of the way tumblr works :/#thank you to the person that tagged me in that post!
115 notes
·
View notes
Text
For anyone who has staff blocked or just isn't going to read that whole post. Tumblr is selling out to ai scraping companies officially now.
You can go into account, blog settings, visibility and check "prevent 3rd party sharing" to opt out. (How much this will actually protect your blogs contents, I'm not sure. But it's the only measure offered.)
For most people your account will have opted in automatically, unless you've already been hiding your blog with other visibility settings. (Though I recommend you check anyway.) So make sure you go and opt out.
142 notes
·
View notes
Text
Quick Tumblr PSA
Did you know that Tumblr can sell your blog posts and info to AI research?
Double-check your blog settings and make sure you've turned the blocker on. You'll have to do this for all of your blogs and sideblogs individually. Go to "Blog Settings" then scroll down the page till you see this option about third-party sharing and make sure that blue button is showing.

61 notes
·
View notes
Note
Hello Andy darling~~ I think you must've already heard about the tumblr selling posts to ai business and also about how changing the settings to prevent your blog data from being scraped is not that effective since they did an initial data scrape anyways... I don't wanna pressure or wrangle any answers out of you love but I was wondering what you are planning to do with your blog now?? Are your fics gonna be on ao3 now? No matter what you decide to do or what platform you chose we will always support and love you regardless. It's understandable if you won't post on tumblr anymore so as to not want your lovely fics scrapped by crappy ai. Also I was wondering what it meant for the Shouto collab you were planning to do later this year? I don't write but I was thinking of participating for our angel princess man :<
Ohh mannnn :((( This situation really sucks huh? >:((((
Hello my love!! I plan to stick around and publish fic on here still, at least until we know more!!!
You're correct though; by my understanding, Tumblr has already done a data dump of any public-facing Tumblr posts onto OpenAI, so there's not much we can do about that. Me leaving would not pull my work back out of their LLM, so I don't see a point in leaving for that reason!!
It's also highly probable that before this data dump, all of our fics would have made it into ChatGPT anyway through Common Crawl, which is confirmed to have scraped Tumblr and ao3 in 2022-2023 (and likely prior); Common Crawl is one of datasets OpenAI has said ChatGPT is trained on. I've been peripherally aware of that fact, and it's unfortunately one of the risks of putting anything on the internet these days (even your personal Google Docs content is not safe). That's just another reason I am not especially motivated to boogie out of here just yet; this is already a sort of evil most of us have accepted lol.
Going forward, there is thankfully that "prevent third party sharing option," which, if Tumblr are not being opaque little weenies about it, should stop any future fics being fed into ChatGPT or any of OpenAI's other models. So with that safety mechanism in place, I do plan to keep publishing fic here, at least for the foreseeable future!!
No worries if you'd rather not participate in the Shouto collab given the circumstances, but I will be here thirsting away, and I hope you will join me!!!
44 notes
·
View notes
Text

remember this?
so um it’s not this post sffsg but coming soon >:3
it's like a month and a half later (i think) but it's here! this blog passed a couple milestones in the last few months and i'd like to celebrate at last with a little casual giveaway >:)
i'm still going through a weird art funk, but i'm happy to offer an experimental color portrait of your character, like these for example:

this giveaway entry period will last a month, so until June 18th (11:59 pm GMT-4, to be extra precise <3), after which i'll be drawing 3 winners. to participate, simply like this post! oh and be a follower ig sdfsd
i will contact the winners on tumblr!
and there you have it, simple and unceremonious sdfsf :> i'm really grateful to be able to share my art with you all, it truly means a lot <3 so i encourage everyone to participate! followers old and new, whether you've been here for a day or a year, i'm happy to have you around <3 good luck!
additional technical details:
1 entry per person <3 (1 like = 1 entry)
will paint: your oc, a canon character
won't paint: real people, hateful/bigoted content, anything im not comfortable with
winners will have 72 hours to answer my initial message, after which i'll draw another name
please have a simple description of your character and their vibe + 2-3 refs ready <3
the following rules apply:
• The final portrait you will receive is a digital file, no physical good will be shipped
• I reserve the right to refuse to do a portrait if I'm uncomfortable with a winner's request
• All art is for personal use only
You may, for example:
• use the portrait or a part of it for personal materials (avatar, header, etc)
• make personal prints
• provide it as a character reference
You may not:
• use the portrait for any commercial purposes
• modify the portrait or claim it as your own work
• redistribute or sell copies of the portrait
• make NFTs
• use it to train AI of any sort
• I may display the portrait or part of it on my portfolio website and/or other social media platforms
Don't hesitate to ask if you have any other question <3 <3 <3
150 notes
·
View notes
Last Seen Blogs

moonbeamdagger
they/them causing mayhem

cashmasterfootgodjaycarl-blog
Submit Cashslaves

rosexxgardenxxdreams-blog
Rose Garden Dreams

vijayaggarwaladvocatenews
Untitled

themandollacollective-blog
THE MANDOLLA COLLECTIVE