#search engine crawlers
Link

Cloaking in SEO is a black hat technique that provides users with content or information different from the content presented to search engine crawlers. It is a malicious tactic aiming to leverage search engines and users to further their goals. Also, it's an attempt to cheat the search engine to rank the website higher in SERPs.
Guidelines clearly state why you should not use SEO cloaking to rank your website organically. Here is why you need to avoid it -
Your website is going to get a Google penalty.
People will avoid your website if you don’t stop using cloaking.
If you continuously engage in shady behaviors, your site might be banned and won’t recover.
You can determine, whether your site is cloaking or not, by comparing the preview text of the page and submitting the URL to the cloaking checker. Ensure your website has engaging content, is valuable to visitors and search engines, and does not hinder the guidelines.
0 notes
Text
every few days i remember that i can literally google anything i ever wanted to know
so im gonna give myself an undercut now
#literally i could google ANYTHING this is so mindblowing#even though google and bing and ddg (YEAH duckduckgo sucks) suck#there are search engines that specialize on older text based stuff'#or geocities crawlers#goddddd i love information technology#im also gonna open a gemini capsule sdkfsdkfns#literally i have so much ideas and happineiss and will to live and drive to create#how come i wanted to kill myself a week ago i am amazing and theres A LOT to do!!!!!#text#uh#mecore
1 note
·
View note
Text
What is a Search Engine? & Its Types!
If you didn't know what is a Search Engine? You came right place to get info. Here, WP Bunch provides all information about Search Engine & types of search engines & How Does a Search Engine Work, etc. Search engines is divided into three groups, like Crawler-Based, etc. To know More details visit our blog!

#best web development services in India#Google search#Microsoft Bing#Yahoo Search engine#SEO services India#about search engine#types of search engines#Crawler-Based#Human-powered Directories#Hybrid Search Engines#Search Engine
0 notes
Link
Robots.txt Generator
0 notes
Text
Functions of Search Engine
Search Engine is an tool where people search their quires in form of keywords and relevant phrases in SERP. Keyword is can be anything that visitors want to know or search. There are different types of search engines like Google,Bing,Dugdugoo, The world’s first search engine was Archie(1990),Google(1996),Microsoft Bing(2009) Berner Lee invented world’s first World Wide Web(WWW) in the year 1989; HTTP technology being used where data was transmitted in TCP/IP.
SEO – Search Engine Optimization for Online Marketing Concept. Modern graphic interface showing symbol of keyword research website promotion by optimize customer searching and analyze market strategy.

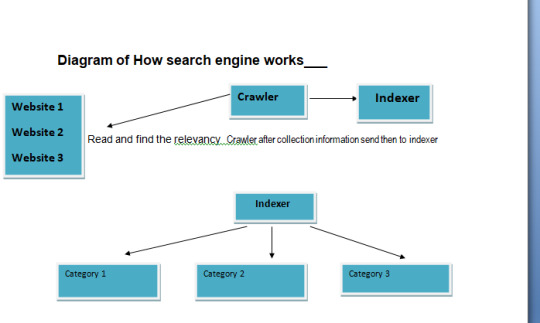
How search engine works?
A search engine works through the following
1. Crawler collects the information through the website or webpages which we have submitted for indexing.
2. The crawler collects the information as per what is mentioned in the structure of the website and relevance submit it to the indexer of serach engine.
3. The indexer arranges the websites as per their catagories and store them in a local server.
4. The indexer after arranging the websites access the ranking alogorism and then find it to display results happens according to the search query.
5. We get the information of the various websites in a page is called search Engine Result Page.(SERP).
1 note
·
View note
Text
#Website#Beginners Guide#Block Crawlers In Wordpress#Block Search Bots In Wordpress#Block Search Engines In Wordpress#How To Stop Search Engines#Private Blog#Seo#Wordpress#Wordpress Free
0 notes
Text
微軟的 Outlook 系統會自動點擊信件內的連結
前幾天在 Hacker News Daily 上翻到的,微軟的 Outlook 系統 (雲端上的系統) 會自動點擊信件內的連結,導致一堆問題:「“Magic links” can end up in Bing search results — rendering them useless.」,在 Hacker News 上的討論也有很多受害者出來抱怨:「“Magic links” can end up in Bing search results, rendering them useless (medium.com/ryanbadger)」。
原文的標題寫的更批評,指控 Outlook 會把這些 link 丟到 Bing 裡面 index,這點還沒有看到確切的證據。
先回到連結被點擊的問題,照文章內引用的資料來看,看起來是 2017 年開始就有的情況:「Do any common…
View On WordPress
0 notes
Text
Friday, July 28th, 2023
🌟 New
We’ve updated the text for the blog setting that said it would “hide your blog from search results”. Unfortunately, we’ve never been able to guarantee hiding content from search crawlers, unless they play nice with the standard prevention measures of robots.txt and noindex. With this in mind, we’ve changed the text of that setting to be more accurate, insofar as we discourage them, but cannot prevent search indexing. If you want to completely isolate your blog from the outside internet and require only logged in folks to see your blog, then that’s the separate “Hide [blog] from people without an account” setting, which does prevent search engines from indexing your blog.
When creating a poll on the web, you can now have 12 poll options instead of 10. Wow.
For folks using the Android app, if you get a push notification that a blog you’re subscribed to has a new post, that push will take you to the post itself, instead of the blog view.
For those of you seeing the new desktop website layout, we’ve eased up the spacing between columns a bit to hopefully make things feel less cramped. Thanks to everyone who sent in feedback about this! We’re still triaging more feedback as the experiment continues.
🛠 Fixed
While experimenting with new dashboard tab configuration options, we accidentally broke dashboard tabs that had been enabled via Tumblr Labs, like the Blog Subs tab. We’ve rolled back that change to fix those tabs.
We’ve fixed more problems with how we choose what content goes into blogs’ RSS feeds. This time we’ve fixed a few issues with how answer post content is shown as RSS items.
We’ve also fixed some layout issues with the new desktop website navigation, especially glitches caused when resizing the browser window.
Fixed a visual glitch in the new activity redesign experiment on web that was making unread activity items difficult to read in some color palettes.
Fixed a bug in Safari that was preventing mature content from being blurred properly.
When using Tumblr on a mobile phone browser, the hamburger menu icon will now have an indicator when you have an unread ask or submission in your Inbox.
🚧 Ongoing
Nothing to report here today.
🌱 Upcoming
We hear it’s crab day tomorrow on Tumblr. 🦀
We’re working on adding the ability to reply to posts as a sideblog! We’re just getting started, so it may be a little while before we run an experiment with it.
Experiencing an issue? File a Support Request and we’ll get back to you as soon as we can!
Want to share your feedback about something? Check out our Work in Progress blog and start a discussion with the community.
859 notes
·
View notes
Note


also, curious what your searching methods are for finding manga panels like this..haven't had much luck with panels on any of the main sites i use e.g. tineye lens saucenao etc, so i'm wondering if you have any specific strategies
Well, I always start my searches on Google Lens. If I'm lucky, the first step will identify the series right away, and if not, the "Find source" step might find it used with its name somewhere.
This time, I was lucky on the second image:


私の推しは悪役令嬢。 (Ch. 33) — いのり。, 青乃下
alias "I Favor the Villainess" by Inori. and Aono Shimo
But what if I had not been so lucky? Then the detective work starts.
I joke a bit, but that's how it usually feels. I try to collect as much data as I can based on the starting images. For example, if it was posted here on Tumblr, someone might mention a character or a ship name on the tags.
And in the case where the image cannot be found anywhere, there's the option to search based on the likeness of the characters or on the text still in the panels.
Either way, all the little bits I collect can help me get to a name, and once I have a name, I can search for it!
In this case, however, I think you were just early to the party. This one chapter was released just some ten days ago and, when you went looking, the search engine crawlers might not have seen any of those images yet.
58 notes
·
View notes
Text
While the finer points of running a social media business can be debated, one basic truth is that they all run on attention. Tech leaders are incentivized to grow their user bases so there are more people looking at more ads for more time. It’s just good business.
As the owner of Twitter, Elon Musk presumably shared that goal. But he claimed he hadn’t bought Twitter to make money. This freed him up to focus on other passions: stopping rival tech companies from scraping Twitter’s data without permission—even if it meant losing eyeballs on ads.
Data-scraping was a known problem at Twitter. “Scraping was the open secret of Twitter data access. We knew about it. It was fine,” Yoel Roth wrote on the Twitter alternative Bluesky. AI firms in particular were notorious for gobbling up huge swaths of text to train large language models. Now that those firms were worth a lot of money, the situation was far from fine, in Musk’s opinion.
In November 2022, OpenAI debuted ChatGPT, a chatbot that could generate convincingly human text. By January 2023, the app had over 100 million users, making it the fastest growing consumer app of all time. Three months later, OpenAI secured another round of funding that closed at an astounding valuation of $29 billion, more than Twitter was worth, by Musk’s estimation.
OpenAI was a sore subject for Musk, who’d been one of the original founders and a major donor before stepping down in 2018 over disagreements with the other founders. After ChatGPT launched, Musk made no secret of the fact that he disagreed with the guardrails that OpenAI put on the chatbot to stop it from relaying dangerous or insensitive information. “The danger of training AI to be woke—in other words, lie—is deadly,” Musk said on December 16, 2022. He was toying with starting a competitor.
Near the end of June 2023, Musk launched a two-part offensive to stop data scrapers, first directing Twitter employees to temporarily block “logged out view.” The change would mean that only people with Twitter accounts could view tweets.
“Logged out view” had a complicated history at Twitter. It was rumored to have played a part in the Arab Spring, allowing dissidents to view tweets without having to create a Twitter account and risk compromising their anonymity. But it was also an easy access point for people who wanted to scrape Twitter data.
Once Twitter made the change, Google was temporarily blocked from crawling Twitter and serving up relevant tweets in search results—a move that could negatively impact Twitter’s traffic. “We’re aware that our ability to crawl Twitter.com has been limited, affecting our ability to display tweets and pages from the site in search results,” Google spokesperson Lara Levin told The Verge. “Websites have control over whether crawlers can access their content.” As engineers discussed possible workarounds on Slack, one wrote: “Surely this was expected when that decision was made?”
Then engineers detected an “explosion of logged in requests,” according to internal Slack messages, indicating that data scrapers had simply logged in to Twitter to continue scraping. Musk ordered the change to be reversed.
On July 1, 2023, Musk launched part two of the offensive. Suddenly, if a user scrolled for just a few minutes, an error message popped up. “Sorry, you are rate limited,” the message read. “Please wait a few moments then try again.”
Rate limiting is a strategy that tech companies use to constrain network traffic by putting a cap on the number of times a user can perform a specific action within a given time frame (a mouthful, I know). It’s often used to stop bad actors from trying to hack into people’s accounts. If a user tries an incorrect password too many times, they see an error message and are told to come back later. The cost of doing this to someone who has forgotten their password is low (most people stay logged in), while the benefit to users is very high (it prevents many people’s accounts from getting compromised).
Except, that wasn’t what Musk had done. The rate limit that he ordered Twitter to roll out on July 1 was an API limit, meaning Twitter had capped the number of times users could refresh Twitter to look for new tweets and see ads. Rather than constrain users from performing a specific action, Twitter had limited all user actions. “I realize these are draconian rules,” a Twitter engineer wrote on Slack. “They are temporary. We will reevaluate the situation tomorrow.”
At first, Blue subscribers could see 6,000 posts a day, while nonsubscribers could see 600 (enough for just a few minutes of scrolling), and new nonsubscriber accounts could see just 300. As people started hitting the limits, #TwitterDown started trending on, well, Twitter. “This sucks dude you gotta 10X each of these numbers,” wrote user @tszzl.
The impact quickly became obvious. Companies that used Twitter direct messages as a customer service tool were unable to communicate with clients. Major creators were blocked from promoting tweets, putting Musk’s wish to stop data scrapers at odds with his initiative to make Twitter more creator friendly. And Twitter’s own trust and safety team was suddenly stopped from seeing violative tweets.
Engineers posted frantic updates in Slack. “FYI some large creators complaining because rate limit affecting paid subscription posts,” one said.
Christopher Stanley, the head of information security, wrote with dismay that rate limits could apply to people refreshing the app to get news about a mass shooting or a major weather event. “The idea here is to stop scrapers, not prevent people from obtaining safety information,” he wrote. Twitter soon raised the limits to 10,000 (for Blue subscribers), 1,000 (for nonsubscribers), and 500 (for new nonsubscribers). Now, 13 percent of all unverified users were hitting the rate limit.
Users were outraged. If Musk wanted to stop scrapers, surely there were better ways than just cutting off access to the service for everyone on Twitter.
“Musk has destroyed Twitter’s value & worth,” wrote attorney Mark S. Zaid. “Hubris + no pushback—customer empathy—data = a great way to light billions on fire,” wrote former Twitter product manager Esther Crawford, her loyalties finally reversed.
Musk retweeted a joke from a parody account: “The reason I set a ‘View Limit’ is because we are all Twitter addicts and need to go outside.”
Aside from Musk, the one person who seemed genuinely excited about the changes was Evan Jones, a product manager on Twitter Blue. For months, he’d been sending executives updates regarding the anemic signup rates. Now, Blue subscriptions were skyrocketing. In May, Twitter had 535,000 Blue subscribers. At $8 per month, this was about $4.2 million a month in subscription revenue. By early July, there were 829,391 subscribers—a jump of about $2.4 million in revenue, not accounting for App Store fees.
“Blue signups still cookin,” he wrote on Slack above a screenshot of the signup dashboard.
Jones’s team capitalized on the moment, rolling out a prompt to upsell users who’d hit the rate limit and encouraging them to subscribe to Twitter Blue. In July, this prompt drove 1.7 percent of the Blue subscriptions from accounts that were more than 30 days old and 17 percent of the Blue subscriptions from accounts that were less than 30 days old.
Twitter CEO Linda Yaccarino was notably absent from the conversation until July 4, when she shared a Twitter blog post addressing the rate limiting fiasco, perhaps deliberately burying the news on a national holiday.
“To ensure the authenticity of our user base we must take extreme measures to remove spam and bots from our platform,” it read. “That’s why we temporarily limited usage so we could detect and eliminate bots and other bad actors that are harming the platform. Any advance notice on these actions would have allowed bad actors to alter their behavior to evade detection.” The company also claimed the “effects on advertising have been minimal.”
If Yaccarino’s role was to cover for Musk’s antics, she was doing an excellent job. Twitter rolled back the limits shortly after her announcement. On July 12, Musk debuted a generative AI company called xAI, which he promised would develop a language model that wouldn’t be politically correct. “I think our AI can give answers that people may find controversial even though they are actually true,” he said on Twitter Spaces.
Unlike the rival AI firms he was trying to block, Musk said xAI would likely train on Twitter’s data.
“The goal of xAI is to understand the true nature of the universe,” the company said grandly in its mission statement, echoing Musk’s first, disastrous town hall at Twitter. “We will share more information over the next couple of weeks and months.”
In November 2023, xAI launched a chatbot called Grok that lacked the guardrails of tools like ChatGPT. Musk hyped the release by posting a screenshot of the chatbot giving him a recipe for cocaine. The company didn’t appear close to understanding the nature of the universe, but per haps that’s coming.
Excerpt adapted from Extremely Hardcore: Inside Elon Musk’s Twitter by Zoë Schiffer. Published by arrangement with Portfolio Books, a division of Penguin Random House LLC. Copyright © 2024 by Zoë Schiffer.
20 notes
·
View notes
Text
If I’m being honest, the most useful skill for hacking is learning to do research. And since Google’s search is going to shit, allow me to detail some of the methods I use to do OSINT and general research.
Google dorking is the use of advanced syntax to make incredibly fine-grained searches, potentially exposing information that wasn’t supposed to be on the internet:
Some of my go-to filters are as follows:
“Query” searches for documents that have at least one field containing the exact string.
site: allows for a specific site to be searched. See also inurl and intitle.
type: specifies the tor of resource to look for. Common examples are log files, PDFs, and the sitemap.xml file.
Metasearch engines (such as SearxNG) permit you to access results from several web-crawlers at once, including some for specialized databases. There are several public instances available, as well as some that work over tor, but you can also self-host your own.
IVRE is a self-hosted tool that allows you to create a database of host scans (when I say self-hosted, I mean that you can run this in a docker container on your laptop). This can be useful for finding things that search engines don’t show you, like how two servers are related, where a website lives, etc. I’ve used this tool before, in my investigation into the Canary Mission and its backers.
Spiderfoot is like IVRE, but for social networks. It is also a self-hosted database. I have also used this in the Canary Mission investigation.
Some miscellaneous websites/web tools I use:
SecurityTrails: look up DNS history for a domain
BugMeNot: shared logins for when creating an account is not in your best interest.
Shodan/Censys: you have to make an account for these, so I don’t usually recommend them.
OSINT framework: another useful index of tools for information gathering.
12 notes
·
View notes
Text

#__How_do_search_engines_work?
Search engines are complex software systems that help users find information on the internet. They work by crawling, indexing, and ranking web pages to provide relevant search results when a user enters a query. Here's a high-level overview of how search engines like Google work:
Web Crawling:
Search engines use automated programs called web crawlers or spiders to browse the internet. These crawlers start by visiting a few known websites and follow links from those pages to discover new ones.
Crawlers download web pages and store them in a vast database known as the index. This process is continuous, with crawlers revisiting websites to look for updates and new content.
Indexing:
Once web pages are crawled, search engines analyze the content of each page, including text, images, links, and metadata (e.g., page titles and descriptions).
This information is then organized and stored in the search engine's index. The index is like a massive library catalog that helps the search engine quickly retrieve relevant web pages when a user enters a query.
Query Processing:
When a user submits a search query, the search engine processes it to understand the user's intent. This may involve analyzing the query's keywords, context, and user history (if available).
Search engines use algorithms to determine which web pages are most likely to satisfy the user's query. These algorithms consider various factors like relevance, freshness, and user engagement.
Ranking:
Search engines assign a ranking to each web page in their index based on how well they match the user's query and other relevance factors. Pages that are more relevant to the query are ranked higher.
Ranking algorithms are highly complex and take into account hundreds of signals, such as the quality and quantity of backlinks, page load speed, and user engagement metrics.
Displaying Results:
The search engine then displays a list of search results on the user's screen, usually with a title, snippet, and URL for each result.
Search engines aim to present the most relevant and high-quality results on the first page of results, as users are more likely to find what they need there.
User Interaction:
Search engines also track user interactions with search results, such as clicks, bounce rates, and time spent on pages. This data can be used to refine rankings and improve the search experience.
Continuous Improvement:
Search engines are constantly evolving and improving their algorithms to provide better search results and combat spammy or low-quality content.
It's important to note that different search engines may have their own unique algorithms and ranking criteria, and they may prioritize different factors based on their specific goals and philosophies. Google, for example, uses the PageRank algorithm, among others, while Bing and other search engines have their own approaches.
#websiteseoservices#seo#seotips#seomarketing#seoagency#seostrategy#bdoutsourcing#digitalmarketing#usa#uk#canada#realestate#bdoutsourcingnt
22 notes
·
View notes
Text
Old Internet Fridays #10: aminfatolli.neocities
aminfatolli.neocities
What’s this?
What’s this website?
A single-page neocities with a single poorly translated (likely machine translated) recipe for Gooshfil/elephant ears, a Persian delicacy. The source recipe seems to be from this Persian website, down to the image. I could make a stab and guess it might belong to an "Amin Fatolli" but I honestly could not say.
Okay, how did you find it?
Long story, and a particular whim. Okay, so if you'll allow me to preface this: I cook. I cook like it's breathing, it's just always been a thing with me. And if there's one thing the internet has, it's recipes. But also, god help you if you're accessing a recipe website without an ad blocker these days.
What I was really looking for was a real old school HTML website of recipes. Just a poorly formatted but functional "Kim Family Recipes" or some shit, and then a link to like 5 sparse but good recipes with maybe a few amateurish pictures.
I started my search on DuckDuckGo with "recipe blog" and then "family recipes". The thing is, there are a lot of recipe things on the internet -- humans sharing food, you know, we love to do that! So I switched to Google with the vague idea that I might try to go all the way back on the pagination, only to learn that the pagination either doesn't exist or is hard to find these days. Then I booted up Neocities and just searched for "recipe" which is where I came across this odd little duck.
How's it doing on internet archive?

ooohhhh ahhh the fact that it's first save is late 2020 makes me feel tender in some kind of way.
What delighted you the most?
I'm presenting this not because it's a good recipe website-- it'd be a challenge to even make this one thing from the translation. But this is truly an internet artifact in a way that feels very old internet, you know? The story is worth more than the actual product. There's an element of celebrating the amateurish, the human, the everyday, that I sometimes like to entertain.
This website might exist because someone, in the pandemic, wanted an English-speaking friend of theirs to try this really good dessert. And that's so sweet.
There's also something charming about the badness of the machine translation that feels old-internet in a way I remember from the early 2000s. "The elephant's eau de toilette" ough that Persian > English google translate does not have its context very well filled out. But that adds something to it.
I entertain the thought of putting recipes I make on the internet all the time. Perhaps I will someday, and it'll be someplace like here. A weird little neocities site, visited only by friends and family, looked over by search engines for ad-coated blogs with SEO garbage, and found only by the archive crawler and very occasionally, by little strangers like me.
17 notes
·
View notes
Text
What is robots.txt and what is it used for?
Robots.txt is a text file that website owners create to instruct web robots (also known as web crawlers or spiders) how to crawl pages on their website. It is a part of the Robots Exclusion Protocol (REP), which is a standard used by websites to communicate with web crawlers.
The robots.txt file typically resides in the root directory of a website and contains directives that specify which parts of the website should not be accessed by web crawlers. These directives can include instructions to allow or disallow crawling of specific directories, pages, or types of content.
Webmasters use robots.txt for various purposes, including:
Controlling Access: Website owners can use robots.txt to control which parts of their site are accessible to search engine crawlers. For example, they may want to prevent crawlers from indexing certain pages or directories that contain sensitive information or duplicate content.
Crawl Efficiency: By specifying which pages or directories should not be crawled, webmasters can help search engines focus their crawling efforts on the most important and relevant content on the site. This can improve crawl efficiency and ensure that search engines index the most valuable content.
Preserving Bandwidth: Crawlers consume server resources and bandwidth when accessing a website. By restricting access to certain parts of the site, webmasters can reduce the load on their servers and conserve bandwidth.
Privacy: Robots.txt can be used to prevent search engines from indexing pages that contain private or confidential information that should not be made publicly accessible.
It's important to note that while robots.txt can effectively instruct compliant web crawlers, it does not serve as a security measure. Malicious bots or those that do not adhere to the Robots Exclusion Protocol may still access content prohibited by the robots.txt file. Therefore, sensitive or confidential information should not solely rely on robots.txt for protection.
Click here for best technical SEO service
#technicalseo#seo#seo services#robots.txt#404error#digital marketing#keyword research#keyword ranking#seo tips#search engine marketing#404 error#googleadsense#rohan
7 notes
·
View notes
Text
Oekaki updatez...
Monster Kidz Oekaki is still up and i'd like to keep it that way, but i need to give it some more attention and keep people updated on what's going on/what my plans are for it. so let me jot some thoughts down...
data scraping for machine learning: this has been a concern for a lot of artists as of late, so I've added a robots.txt file and an ai.txt file (as per the opt-out standard proposed by Spawning.ai) to the site in an effort to keep out as many web crawlers for AI as possible. the site will still be indexed by search engines and the Internet Archive. as an additional measure, later tonight I'll try adding "noai", "noimageai", and "noml" HTML meta tags to the site (this would probably be quick and easy to do but i'm soooo sleepy 🛌)
enabling uploads: right now, most users can only post art by drawing in one of the oekaki applets in the browser. i've already given this some thought for a while now, but it seems like artist-oriented spaces online have been dwindling lately, so i'd like to give upload privileges to anyone who's already made a drawing on the oekaki and make a google form for those who haven't (just to confirm who you are/that you won't use the feature maliciously). i would probably set some ground rules like "don't spam uploads"
rules: i'd like to make the rules a little less anal. like, ok, it's no skin off my ass if some kid draws freddy fazbear even though i hope scott cawthon's whole empire explodes. i should also add rules pertaining to uploads, which means i'm probably going to have to address AI generated content. on one hand i hate how, say, deviantart's front page is loaded with bland, tacky, "trending on artstation"-ass AI generated shit (among other issues i have with the medium) but on the other hand i have no interest in trying to interrogate someone about whether they're a Real Artist or scream at someone with the rage of 1,000 scorned concept artists for referencing an AI generated image someone else posted, or something. so i'm not sure how to tackle this tastefully
"Branding": i'm wondering if i should present this as less of a UTDR Oekaki and more of a General Purpose Oekaki with a monster theming. functionally, there wouldn't be much of a difference, but maybe the oekaki could have its own mascot
fun stuff: is having a poll sort of "obsolete" now because of tumblr polls, or should I keep it...? i'd also like to come up with ideas for Things To Do like weekly/monthly art prompts, or maybe games/events like a splatfest/artfight type thing. if you have any ideas of your own, let me know
boring stuff: i need to figure out how to set up automated backups, so i guess i'll do that sometime soon... i should also update the oekaki software sometime (this is scary because i've made a lot of custom edits to everything)
Money: well this costs money to host so I might put a ko-fi link for donations somewhere... at some point... maybe.......
7 notes
·
View notes
Text

it's interesting - this was turned off for me by default. is this different for others? maybe it's tied to the setting for indexing the blog by search engine crawlers? (which i turned off forever ago because i don't need that heat)
#tumblr#but knowing the context this doesn't matter#just curious that it's opt-out for me#just drives the point home that this option doesn't have anything to do with the deal
7 notes
·
View notes
Last Seen Blogs

marasmuffin
welcome

kkurafilm
[n] fearnot

love-and-books320
Sarah

textosplasmoicos
prosaico

hollyblackmore-blog1
☾ little wild