#Spracherkennung
Text

Verhaltenssteuerung und Manipulation
Analyse bis auf die Einzelperson
Wir kennen es aus dem Marketing, dass das Verhalten von Menschen auf einzelne Gruppen heruntergebrochen wird und die Anreize zum Kaufen für solche Gruppen gesteuert werden. Mit der Möglichkeit noch mehr Daten zu speichern und jederzeit zu tansportieren (5G) werden diese Gruppen immer spezifischer - bis sie irgendwann bis auf die Einzelperson analysiert werden können.
In dem zitierten Interview von Dominik Irtenkauf bei Telepolis mit dem Romanautor Christian J. Meiers geht es um fast reale Science Fiction. Ausgehend von dem Skandal um die Firma Cambridge Analytics bei der Analyse und Steuerung von Wahlkämpfen hat Meiers nun sein 2. Buch "Der Kadidat" veröffentlicht.
Auch wenn das Buch im Jahr 2042 spielen soll, werden die Grundlagen für die darin beschriebene Manipulation der Menschen schon heute gelegt. Die Gefahren der KI-Programme, die er darin beschreibt sind
Wahlmanipulation durch digitale Mittel,
die wahnsinnige Diskrepanz zwischen den Datenmengen in den Händen Weniger und deren unbegrenzte finanzielle Möglichkeiten,
das Verschwimmen von Realität und Fake in Wort und Bild (Deep Fakes),
Social Profiling - Zuckerbrot und Peitsche - Steuerung durch Verhaltensanalyse und Belohnung oder Ausgrenzung
Das Interview ist auf jeden Fall lesenswert ...
Mehr dazu bei https://www.telepolis.de/features/Digitale-Wahlmanipulation-Die-KI-baut-die-Persoenlichkeit-8962579.html?seite=all
Kategorie[21]: Unsere Themen in der Presse Short-Link dieser Seite: a-fsa.de/d/3tA
Link zu dieser Seite: https://www.aktion-freiheitstattangst.org/de/articles/8371-20230417-verhaltenssteuerung-und-manipulation.htm
#Analyse#Marketing#Algorithmen#Steuerung#CambridgeAnalytics#Wahlen#SocialProfiling#Ausgrenzung#Belohnung#ChatGPT#Cyberwar#Wissen#lernfähig#Spracherkennung#kreativ#neuronaleNetze#OpenSource#Menschenrechte#Copyright#KI#AI#KuenstlicheIntelligenz#DataMining
5 notes
·
View notes
Text
22. Juli 2022, aber auch schon vorher
Vom Bassfahren und Busspielen
Ich unterhalte mich mit Molinarius häufiger über unsere gemeinsame Passion: Das Bassspielen. Wenn ich unterwegs bin, oder eh gerade mein Handy in der Hand habe, greife ich gern auf die Diktierfunktion zurück.
Aber beim Bus, äh Bass macht mir das iPhone einen Strich durch die Rechnung. Noch nicht ein einziges Mal ist es mir gelungen, dass das iPhone den Begriff “Bass” schreibt. Stattdessen wird immer “Bus” angezeigt. Und meine Uasspruche ist nicht so schlecht, dass a und u nicht auseinanderzuhalten wären.

Den oben rötlich unterlegten Bass hinter Upright (was das iPhone da krudes verstanden hat, weiß ich schon nicht mehr. “Ab Reit” oder so.) hatte ich von Hand korrigiert, den rot eingekringelten Bus im gerade diktierten Text muss ich noch verbessern.
(Markus Winninghoff)
4 notes
·
View notes
Video
youtube
Nicht nur Nahrung kann man erweitern. Auch seinen Chromebrowser. Hier eine sehr gute Erweiterung, auch die kostenlose Version ist schon sehr gut. https://dictanote.co/voicein/install/?r=708031
0 notes
Text
Perfider Enkeltrick mit durch KI gefälschter Stimme
Der Enkeltrick ist bereits perfide, aber nun nehmen Betrüger eine noch gefährlichere Wendung. Mithilfe von 'Voice Cloning' und künstlicher Intelligenz werden Stimmen von vertrauten Personen imitiert, um Opfer zu betrügen.
Wochenschau KW37-2023
Wie oft ärgere ich mich über die Spracherkennung auf meinem iPhone, wenn ich einen Text diktiere und dabei Unsinn raus kommt? Ziemlich häufig. Fast so häufig wie über die Autokorrektur … Die Funktionalität finde ich sehr komfortabel, wenn es denn funktioniert. So ähnlich verhält es sich auch mit den Befehlen, die ich Siri gebe. Meine Frau versteht mich nicht, Siri aber auch…

View On WordPress
#9vor9#Alexa#Betrug#CyberSecurity#Enkeltrick#GenAI#KI#Siri#Sprachassistenten#Spracherkennung#Wochenschau
0 notes
Text
Siri ist ratlos - iOS 16 bereitet Probleme
Siri ist ratlos. Siri hat Probleme bei der Spracherkennung unter iOS 16. Auch der Apple Support ist ratlos und kann nicht weiterhelfen. Warten auf iOS 16.1.
iPhone 4s mit Siri: Plakat von 2011
Vor 11 Jahren wurde mit dem iPhone 4s auch Siri veröffentlicht. Der digitale Assistent, der auf das Schlüsselwort Hey Siri hört. Seit 11 Jahren versucht uns Siri zu verstehen und uns vernünftige Antworten zu liefern. Und das gelingt ihr manchmal besser. Manchmal schlechter. Und jetzt überhaupt nicht. Siri funktioniert seit iOS 16 nicht mehr auf dem iPhone.…

View On WordPress
0 notes
Link
Die Marktforschungsstudie zu Medizinische Spracherkennung Markt – Globale Branchenanalyse, Marktgröße, Chancen und Prognose, 2022 - 2030, bietet einen detaillierten Einblick in den globalen Medizinische Spracherkennung Markt, der Einblicke in seine verschiedenen Marktsegmente beinhaltet. Marktdynamik mit Treibern, Beschränkungen und Chancen mit ihren Auswirkungen werden im Bericht bereitgestellt. Der Bericht bietet Einblicke in den globalen Medizinische Spracherkennung-Markt, seine Art, Anwendung und wichtigsten geografischen Regionen. Der Bericht behandelt grundlegende Entwicklungsrichtlinien und Layouts von Technologieentwicklungsprozessen.
0 notes
Text
Fernfeldsprache und Spracherkennung-Marktbericht wird eine umfassende Analyse der globalen und regionalen Marktgröße und der Marktgröße auf Länderebene, des Segmentierungsmarktanteils und der Segmentgröße, des Marktwettbewerbs, der Verkaufsanalyse, der Auswirkungen regionaler und globaler Marktteilnehmer sowie der Optimierung der Wertschöpfungskette/Lieferkette umfassen , Handelsgesetze, wichtige Unternehmensstrategien, Analysen von Wachstumschancen, Produkteinführungen, Erweiterung des Gebietsmarktes und technologische Innovationen.
0 notes
Note
Keine Untertitel, keine Folgenbeschreibung, kein Nolin-Happy end. Die Woche ist hart für uns 😂
Wie sollen die Leute, die kein Deutsch können, denn jetzt mit uns mitleiden? Die verpassen jetzt so viele tolle Sachen: Die Trennwand-Szene, Joels Ansage an Noah, Das letzte Gespräch zwischen Colin und Joel.
(Ich würd ja selbst welche erstellen, aber selbst mit Spracherkennung ist so viel Aufwand, die Zeiten anzupassen, da beschränk ich mich lieber aufs übersetzen + untertiteln von on-screen Texten)
12 notes
·
View notes
Link
0 notes
Text
Alles Wissenswerte über das Programm zum Text vorlesen lassen
Ein Programm zum Text vorlesen lassen erlaubt es Nutzern, geschriebene Texte in gesprochene Sprache umzuwandeln und somit eine auditive Wahrnehmung zu genehmigen.
Mehrere Programme Text vorlesen lassen nutzen eine sogenannte Text-to-Speech (TTS) Technologie, um Texte in Sprache umzuwandeln. Diese Technologie basiert auf verzwickten Algorithmen und Modellen, die es gestatten, die menschliche Sprache zu simulieren. Das Programm analysiert den Text, zerlegt ihn in einzelne Wörter und Sätze und generiert dann Sprachausgabe, indem es diese Teile zusammenfügt. Dabei kann die Stimme des Vorlesers individuell angepasst werden, so dass sie sich entweder anhört wie eine männliche oder weibliche Stimme und in verschiedenartigen Sprachen verfügbar ist.
Ein weiteres Verfahren zur Umwandlung von Text in Sprache ist die Nutzung von vorab aufgezeichnetem Audiomaterial. Hierbei werden bestimmte Sätze oder Wörter von einem menschlichen Sprecher aufgenommen und in einer Datenbank gespeichert. Das Programm greift dann auf diese Datenbank zu und spielt die entsprechenden Aufnahmen ab, um den Text vorzulesen. Dieses Verfahren genehmigt eine höhere Qualität und Natürlichkeit der Sprachausgabe, da der menschliche Sprecher über Nuancen und Betonungen verfügt, die ein Computerprogramm nicht immer perfekt reproduzieren kann.
Ferner besteht eine Zusammenstellung von Anwendungsmöglichkeiten für Programme zum Text vorlesen lassen. Ferner können solche Programme auch im Bildungs- und Lernbereich eingesetzt werden, um Schülern und Studenten das Lernen zu erleichtern.
Dadurch können Benutzer den vorgelesenen Text später erneut anhören oder ihn für andere Zwecke benutzen.
Es ist entscheidend zu beachten, dass Programme zum Text vorlesen lassen nicht perfekt sind und manchmal Fehler in der Sprachausgabe auftreten können. Insbesondere bei schweren Texten oder speziellen Fachbegriffen kann es zu Ungenauigkeiten kommen. Dennoch haben sich solche Programme in den letzten Jahren erheblich verbessert und verschaffen eine immer bessere Qualität der Sprachausgabe.
Die wichtigsten Informationen zur Software zum Text vorlesen lassen
Die Entwicklung von Software zum Text vorlesen lassen hat es gewährt, dass Computerbildschirme Texte automatisch in eine natürliche Sprache umwandeln und so Menschen mit Sehbeeinträchtigungen unterstützen können.
Dies ist besonders nützlich für Personen, die nicht in der Lage sind, den Text auf einem Computerbildschirm zu lesen, sei es aufgrund von Sehbehinderungen oder anderen Einschränkungen.
Etliche dieser Programme sind kostenlos, während andere kostenpflichtig sind und zusätzliche Funktionen bieten.
Die meisten Programme zum Text vorlesen lassen verfügen über eine Benutzeroberfläche, die es dem User gewährleistet, den Text auszuwählen, den er vorlesen lassen möchte. Ferner gibt es in der Regel eine Option zur Anpassung der Wiedergabegeschwindigkeit und der Stimme, um den individuellen Vorlieben des Benutzers gerecht zu werden.
Mehrere fortschrittlichere Programme gewährleisten es Usern sogar, den vorgelesenen Text zu bearbeiten, indem sie Markierungen setzen oder bestimmte Abschnitte hervorheben. Dies kann besonders hilfreich sein, wenn der Benutzer beispielsweise prinzipielle Informationen aus einem längeren Text extrahieren möchte.
Die Technologie hinter der Software zum Text vorlesen lassen basiert auf der Spracherkennung und der Text-to-Speech-Techno
1 note
·
View note
Text
Rückblick: Interview mit Heinrich Welter von Genesys - Rolle der Spracherkennung für vernetzten Kundenservice
Photo by Zoran Cindrić on Pexels.com
Im Interview mit Heinrich Welter auf der GForce Kundenkonferenz seines Unternehmens in Wien vor gut zehn Jahren, ging es um Fortschritte und Herausforderungen der Sprachtechnologie. Es zeigt sich, dass ChatGPT nicht vom Himmel gefallen ist, sondern auf der langjährigen Forschungsarbeit von Unternehmen und Wissenschaft beruht. Um was ging es auf der…

View On WordPress
0 notes
Text

KI und neuronale Netze
Wenn Computer sprechen und malen sollen
Der Erfolg bei der Erzeugung von künstlicher Intelligenz wäre das bedeutendste Ereignis in der Geschichte des Menschen. Unglücklicherweise könnte es auch das letzte sein. Stephen Hawking
Gestern hatten wir uns mit den Möglichkeiten und Risiken bei der Benutzung des KI-Programms ChatGPT auseinandergesetzt. Dabei haben wir uns auf die Texterkennung und -generierung fokussiert und dabei vergessen, dass ein wesentlicher Teil auch die Spracherkennung und -genererierung ist. Mit einem "Roboter" oder Programm in der uns gewohnten Sprache kommunizieren zu können ist natürlich viel angenehmer als eine Tastatur zu benutzen.
Deshalb wollen wir heute auf einen Artikel bei Spektrum.de verweisen und ergänzen, dass
ChatGPT inzwischen auch Bilder erkennen und nach unseren Wünschen generieren kann,
maschinelle Spracherkennung schon seit den 1950-iger Jahren ein Ziel der Programmierung ist.
Manon Bischoff schreibt auf Spektrum.de:
Im Januar 1954 war eine IBM-701-Maschine der erste für wissenschaftliche Zwecke entwickelte Rechner, er wog knapp zehn Tonnen und tat etwas Unvorstellbares: Mit russischen Beispielsätzen gefüttert, druckte er eine ins Englische übersetzte Version aus.
Es dauerte noch 60 Jahre bis zum Aufkommen neuronaler Netze in den 2010er und 2020er Jahren, um Algorithmen so leistungsfähig zu machen, dass sie Texte verlässlich von einer Sprache in eine andere übertragen können. Nun kann ChatGPT sogar Witze erfinden - auch wenn diese meist nicht gut sind. Witze sind jedenfalls schwieriger zu erfinden als ein ansprechendes Bild zu malen. Für das Malen reicht ein Verständnis (= eine Tabelle) zu Farben und Beispielbilder von allen möglichen Objekten.
Wie bei der Übersetzung und der Spracherkennung reicht es nicht, so eine Tabelle (= Datenbank) nach einem Stichwort zu durchsuchen, sondern die Verknüpfungen müssen nach der Aufgabenstellung verschieden sein. Dazu benötigt man neuronale Netze, die ChatGPT so erklärt:
Neuronale Netze sind eine Art von Algorithmus für maschinelles Lernen, der von der Struktur und Funktion des menschlichen Gehirns inspiriert ist. Sie bestehen aus miteinander verbundenen Knoten oder »Neuronen«, die Informationen verarbeiten und zwischen den Schichten des Netzes weiterleiten. Jedes Neuron empfängt Eingaben von anderen Neuronen, führt an diesen Eingaben eine einfache mathematische Operation durch und leitet das Ergebnis dann an andere Neuronen in der nächsten Schicht weiter. Auf diese Weise können neuronale Netze lernen, Muster in Daten zu erkennen und auf der Grundlage dieser Daten Vorhersagen zu treffen.
Auf Spektrum.de heißt es dazu: Im Gegensatz zu gewöhnlichen Algorithmen macht der Programmierer in neuronalen Netzen keine eindeutigen Vorgaben (etwa: falls Neuron 2 aus Schicht 3 ein Signal mit Wert 0,77 erhält, dann wandle es in 0,89 um). Stattdessen lässt man das Netz selbst "lernen", welche Einstellungen am geeignetsten sind, um eine Aufgabe zu bewältigen.
Da der Computer schnell ist, kann er seine anfänglichen Fehler mit der Zeit ausbügeln. Allerdings braucht er dazu auch korrekte Rückmeldungen. Bestätigt man ihn in seinen Fehlern, so - kommen wir auf den Artikel von gestern zurück und haben es nun mit einem Rassisten oder anderem Idioten zu tun ...
Welche weiteren Einschränkungen die Computer beim "Lernen" unterworfen sind, erklärt Manon Bischoff auf Spektrum.de sehr gut und beschreibt auch die Fortschritte in den ChatGPT Versionen der letzten Jahre. Der Aufbau der neuronalen Netze kann - auch wegen der immer noch mangelhaften Rechenleistung - nur auf kurze Distanzen (der Begriffe in der Matrix) verlässlich sein. Deshalb ist bei aller Arbeit, die nun ein Computer erledigen kann, wichtig zu bedenken, dass er dies nur kann, weil Menschen ihn vorher bei den Bewertungen der Zusammenhänge richtig trainiert haben. D.h. natürlich auch, dass er nur das gut kann, wozu er trainiert worden ist.
Mehr dazu bei https://www.spektrum.de/news/wie-funktionieren-sprachmodelle-wie-chatgpt/2115924#Echobox=1678347819
und der Artikel von gestern https://www.aktion-freiheitstattangst.org/de/articles/8339-20230318-was-bietet-chatgpt.htm
Kategorie[21]: Unsere Themen in der Presse Short-Link dieser Seite: a-fsa.de/d/3t4
Link zu dieser Seite: https://www.aktion-freiheitstattangst.org/de/articles/8340-20230319-ki-und-neuronale-netze-.htm
#Algorithmen#ChatGPT#Cyberwar#Wissen#lernfähig#Spracherkennung#malen#kreativ#neuronaleNetze#OpenSource#Menschenrechte#Copyright#KI#AI#KuenstlicheIntelligenz#Tay#Twitter#Microsoft#Tesla#Musk#Rassist#DataMining
2 notes
·
View notes
Text
30. September und andauernd, noch
-ieux oder -eille, ich werde es bestimmt noch verstehen
Der Sohn erzählt mir, dass er nun wieder Spanisch lernt. Mit einer App. Er hat die Möglichkeit, mit einer Organisation in ein paar Monaten nach Peru zu fahren. In der Schule hat er bis vor ungefähr einem Jahr Spanisch gelernt, das will er dafür wieder auffrischen.
Von Freunden und aus den Berichten im Techniktagebuch kenne ich Duolingo und nehme an, dass er Spanisch also damit lernt. Aber er sagt, dass er da eine andere App habe, Busuu. Und die sei ganz gut. Er erzählt mir, dass es eine Funktion gibt, mit der man Lösungen und Aufnahmen von sich an Muttersprachler senden könne, und die würden das dann korrigieren, und gleichzeitig bekomme man Lösungen und Aufnahmen von anderen, die gerade deutsch lernen, und würde die im Gegenzug korrigieren. Das finde ich einen spannenden Communitygedanken und möchte mir das gerne angucken.
Mit Sprachen hab ich es nicht so. Englisch habe ich beruflich mal sehr intensiv gesprochen, in den letzten Jahren ist das aber ziemlich eingerostet, seit ich es nur noch als Fachsprache und nicht mehr als Umgangssprache benutze. Und meine französischen Sprachkenntnisse... naja. Die waren immer äußerst bescheiden. Mein Französisch als “eingerostet” zu beschreiben wäre sehr euphemistisch.
Während mein Wortschatz im Französischen durch meine Lateinkenntnisse und auch, weil ich mal eine Zeit lang häufiger in Paris war, vielleicht gar nicht so schlecht ist, sind Grammatik und Rechtschreibung des Französischen mir immer ein Rätsel. Diese französische Eigenschaft, die letzten Buchstaben des Wortes einfach wegzulassen und man muss dann halt wissen, ob da noch ein t, ein s, ein e oder sonst was für ein Buchstabe kommt, und wie die Striche auf und unter den Buchstaben zu verteilen sind, hat nicht so richtig zu meiner Freundschaft mit dem Französischen beigetragen.
Ich überlege kurz: Welche Sprache könnte ich mir also mit Busuu angucken? Englisch wieder vertiefen, Französisch endlich mal "richtig" lernen, oder eine ganz andere? Dänisch, das ich ein ganz klein wenig kann und das ich gerne vertiefen würde, ist auf Busuu leider nicht verfügbar.
Ich registriere mich und wähle aus, dass ich ca. 10 Minuten am Tag Französisch lernen möchte, nur mal ein paar Tage lang, um mir das anzugucken.
Aber sofort bin ich in den Fängen der Gamification. Es ist toll, ich bin in einer Liga, und wenn ich fleißig lerne, steige ich in eine höhere Liga auf! Und nun aber dran bleiben, sonst rutsche ich wieder ab! Und, tatsächlich, ich soll Sätze schreiben und nachsprechen, und dann bekomme ich von Muttersprachler:innen Korrekturen und ermutigende Kommentare. Das ist wirklich sehr nett, manche verteilen sehr großzügig Kommentare, dass meine fehlerhaften Antworten “Parfait” seien, aber andere geben sich richtig Mühe, mich zu korrigieren:
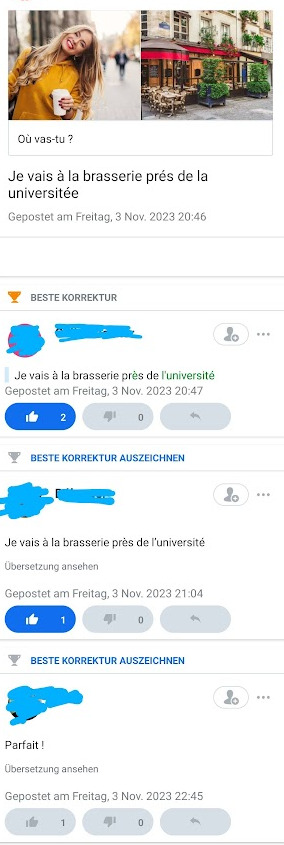
Screenshot aus Busuu, natürlich mit schönen Bildern
Ich kann mich dann wiederum bedanken, indem ich Daumen hoch für die Antworten verteile oder eine Antwort als “Beste Antwort” auszeichne - das gibt dann wieder Punkte für die Antwortenden, um in der Liga aufzusteigen.
Ich spreche auch Sätze nach, meine Aussprache wird von einer Spracherkennung beurteilt, und nehme eigene Antwortsätze auf, die dann wiederum in die Community gehen, die die Sätze und meine Aussprache korrigiert. Und andersherum revanchiere ich mich natürlich, indem ich Deutschlernende ermutige und korrigiere.
Wer bis hierhin gelesen hat, wird den Gedanken verstanden haben und so neu ist der ja wahrscheinlich auch gar nicht, aber ich finde das irgendwie toll: Fast jede:r ist ja irgendwie mehr oder weniger Expert:in in der Muttersprache, und ich bekomme ermutigendes Feedback, dass Muttersprachler:innen meine holprigen Sprachbemühungen verstehen können!
Jetzt muss ich nur dran bleiben. An vielen Tagen schaffe ich nur das absolute Minimum, eine Minilektion, aber auch das ist wichtig, damit mein Streak nicht abreißt:
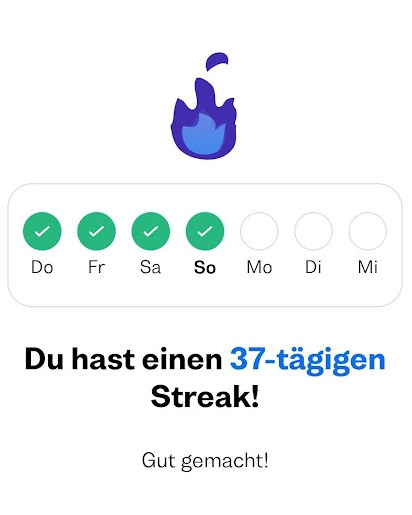
Screenshot aus Busuu: 37 Tage schon täglich eine kleine Französisch-Lektion, "Gut gemacht!", finde ich auch
(Molinarius)
7 notes
·
View notes
Text
Neue Gründe Sexpuppen zu kaufen

Sexpuppenliebhaber können in Foren kommunizieren: Laut einer Umfrage einer Unterhaltungs-Dating-Seite nutzen 54 % der Menschen TPE-Puppen als Sexspielzeug, 46 % geben als Begründung „Ready to Try“ an. Ein Blick auf die internationale „Doll „Forum“, in dem Puppenliebhaber virtuell kommunizieren können, bestätigt die Erkenntnisse. Den meisten Nutzern geht es nur um Reinheit plus Korrekturlinsen, denn wenn es um Perfektion geht, kommt es bei Puppen natürlich auf einiges an: „Warum sollte ich mit einer normalen Frau schlafen?“ ob ich auch eine Supermodel-Puppe habe?
Auch Industriewissenschaftler haben nachgewiesen, dass der Narzissmus zunimmt. Wir umgeben uns immer mehr und gehen Risiken und Konflikten aus dem Weg, bis wir Störungen fürchten und gemeinsam glücklicher sein wollen. Sind unbelebte Sexualpartner ein Vorbild für die Zukunft? Weil sie sich mit dem anderen Geschlecht nicht vertragen, oder eben nicht Ich fühle mich beim Dating nicht wohl.
echtes Puppenbordell
Die meisten Sex puppe Kunden mit großen Brüsten begleiten sie für eine Stunde, etwa 80 Euro. Dann trafen wir die einzige männliche Puppe im Flur des Bordells, namens Mr. Diego. Der Manager erklärte, dass es dort „echte Puppen“ für Frauen gäbe Auf dem freien Markt stehen 2.000 verschiedene Modelle zur Auswahl, während es derzeit nur etwa 50 „echte Puppen“ für Männer gibt. Werfen wir einen Blick auf die Technologietrends: Es gibt bereits Sexroboter mit eingebauter künstlicher Intelligenz.
Sie können Ihre Augen und Ihren Mund bewegen und verfügen über eine Spracherkennungs-App, die der auf Ihrem Smartphone ähnelt. Die Demo war beeindruckend, eine Funktion, die die Schnittstelle zwischen europäischer Liebespuppe und Menschen menschlicher und austauschbarer machte. Die Zukunft der Interaktion mit intelligenten Robotern ist so hell, dass wir menschliche Intimität manchmal völlig verachten, so eine Studie von Zukunftsforschern des Australian National Sexy.
#sexpuppen#silikonpuppe#liebespuppe#lebensechte sexpuppe#silikonpuppen#liebespuppen#sexpuppe#real doll
0 notes
Text
Die Fortschritte im Bereich der künstlichen Intelligenz (KI) haben in den letzten Jahren zu einem erheblichen Anstieg des Interesses und der Anwendung von Deep Learning geführt. Deep Learning bezieht sich auf eine Unterdisziplin des maschinellen Lernens, die auf neuronalen Netzwerken basiert und große Datenmengen verwenden kann, um komplexe Probleme zu lösen. Es hat Anwendungen in verschiedenen Bereichen wie Spracherkennung, Bild- und Videoverarbeitung, medizinischer Diagnose und automatisiertem Fahren gefunden.
Deep Learning-Modelle sind inspiriert von biologischen neuronalen Netzwerken im Gehirn. Sie bestehen aus mehreren Schichten von Neuronen, die Informationen verarbeiten und weitergeben. Jede Schicht lernt, bestimmte Merkmale oder Muster aus den Eingabedaten zu extrahieren und an die nächste Schicht weiterzugeben. Durch die Kombination mehrerer Schichten können Deep-Learning-Modelle komplexe Konzepte und Probleme erkennen und verstehen.
Ein Schlüsselelement des Deep Learning ist das Training dieser neuronalen Netzwerke. Dies geschieht durch die Bereitstellung einer großen Menge an markierten Trainingsdaten, die als Beispiele für das gewünschte Verhalten dienen. Die Netzwerke passen ihre internen Gewichtungen und Parameter an, um die Trainingsdaten möglichst genau abzubilden. Dieser Prozess wird als "Backpropagation" bezeichnet und beruht auf dem Gradientenabstieg-Verfahren, bei dem die Fehler zwischen den Vorhersagen des Netzwerks und den tatsächlichen Werten minimiert werden.
Die Vorteile von Deep Learning liegen in seiner Fähigkeit, große Datenmengen zu verarbeiten und komplexe Muster zu erkennen. Im Vergleich zu herkömmlichen Machine-Learning-Methoden können Deep-Learning-Modelle oft eine höhere Genauigkeit bei der Lösung schwieriger Probleme erreichen. Sie können auch auf unstrukturierte Daten wie Bilder, Audiosignale und Texte angewendet werden, wodurch ihre Anwendungsbereiche erheblich erweitert werden.
Trotz dieser Vorteile gibt es auch Grenzen für Deep Learning. Ein Problem ist die Notwendigkeit einer großen Menge an Trainingsdaten. Deep-Learning-Modelle benötigen oft eine riesige Datenmenge, um gute Leistung zu erzielen. Dies kann in Situationen, in denen nur begrenzte Daten verfügbar sind, zu Herausforderungen führen.
Ein weiteres Problem ist die Interpretierbarkeit von Deep-Learning-Modellen. Aufgrund ihrer komplexen Struktur und der großen Anzahl von Parametern kann es schwierig sein, zu verstehen, wie ein bestimmtes Ergebnis oder eine Vorhersage erzielt wurde. Dies kann zu Vertrauensproblemen führen und die Anwendungsbereiche von Deep Learning einschränken, insbesondere in Bereichen wie der Medizin, wo klare Erklärungen von entscheidender Bedeutung sind.
Darüber hinaus sind Deep-Learning-Modelle anfällig für sogenannte "Adversarial Attacks". Dabei werden speziell gestaltete Eingabedaten verwendet, um die Modelle absichtlich dazu zu bringen, falsche Vorhersagen zu treffen. Dieses Phänomen hat Bedenken hinsichtlich der Sicherheit und Zuverlässigkeit von Deep-Learning-Systemen aufkommen lassen.
Ein weiteres Problem ist der Energieverbrauch von Deep-Learning-Modellen. Die Trainings- und Inferenzprozesse erfordern viel Rechenleistung und können große Mengen an Energie verbrauchen. Angesichts des zunehmenden Einsatzes von Deep Learning in verschiedenen Anwendungen kann dieser Energieverbrauch zu erheblichen Umweltauswirkungen führen.
Insgesamt bietet Deep Learning große Potenziale und hat zu bedeutenden Fortschritten in verschiedenen Bereichen geführt. Es ermöglicht die Lösung komplexer Probleme und die Verarbeitung großer Datenmengen. Gleichzeitig gibt es aber auch Herausforderungen und Grenzen, die berücksichtigt werden müssen. Die Verbesserung der Interpretierbarkeit, die Sicherheit gegen Adversarial Attacks und die Verringerung des Energieverbrauchs sind wichtige Forschungsbereiche, um die Anwendbarkeit und Effektivität von Deep Learning weiter zu optimieren.
Grundlagen des Deep Learning
Deep Learning
ist ein Zweig des maschinellen Lernens, der sich mit dem Training von neuronalen Netzwerken befasst, um komplexe Muster und Zusammenhänge in großen Datenmengen zu erkennen und zu verstehen. Es handelt sich um eine Form des künstlichen Lernens, bei der das Netzwerk hierarchisch strukturiert ist und aus vielen Schichten von Neuronen besteht. In diesem Abschnitt werden die grundlegenden Konzepte, Strukturen und Prozesse des Deep Learning detailliert behandelt.
Neuronale Netzwerke
Ein neuronales Netzwerk ist ein künstliches System, das biologische neuronale Netzwerke imitiert. Es besteht aus künstlichen Neuronen, die miteinander verbunden sind und Informationen verarbeiten. Diese künstlichen Neuronen haben Eingänge, Gewichte, eine Aktivierungsfunktion und einen Ausgang. Die Informationen fließen durch das Netzwerk, indem die eingehenden Signale mit den Gewichten multipliziert und dann durch die Aktivierungsfunktion transformiert werden. Der resultierende Ausgang jedes Neurons wird dann an die nächsten Neuronen weitergegeben.
Tiefe neuronale Netzwerke
Ein tiefes neuronales Netzwerk besteht aus vielen Schichten von Neuronen, die nacheinander angeordnet sind. Jede Schicht nimmt die Ausgabe der vorherigen Schicht als Eingabe an und gibt ihre eigene Ausgabe an die nächste Schicht weiter. Die erste Schicht wird als Eingangsschicht bezeichnet und die letzte Schicht als Ausgangsschicht. Die zwischenliegenden Schichten werden als versteckte Schichten bezeichnet.
Ein tiefes neuronales Netzwerk hat den Vorteil, dass es komplexe Funktionen und Beziehungen zwischen den Eingabe- und Ausgabedaten erlernen kann. Jede Schicht des Netzwerks lernt unterschiedliche Merkmale oder Abstraktionen der Daten. Die tiefe Struktur ermöglicht es dem Netzwerk, immer abstraktere Repräsentationen der Daten zu erstellen, je weiter es in den Netzwerkstapel vordringt.
Trainieren von Deep Learning-Modellen
Das Training eines Deep Learning-Modells besteht darin, die Gewichte und Parameter des Netzwerks so anzupassen, dass es die gewünschten Aufgaben oder Vorhersagen erfüllt. Dies wird durch die Minimierung einer Kostenfunktion erreicht, die den Unterschied zwischen den tatsächlichen und den vorhergesagten Ergebnissen quantifiziert.
Um ein tiefes neuronales Netzwerk zu trainieren, werden zunächst zufällige Gewichte verwendet. Die Eingabedaten werden dem Netzwerk vorgelegt und die Ausgaben des Netzwerks werden mit den tatsächlichen Ausgaben verglichen. Der Unterschied zwischen den beiden Ausgaben wird durch die Kostenfunktion gemessen. Anschließend werden die Gewichte so angepasst, dass die Kostenfunktion minimiert wird. Dieser Prozess wird iterativ durchgeführt, indem die Gewichte nach und nach angepasst werden, bis das Netzwerk die gewünschte Genauigkeit erreicht oder keine Verbesserungen mehr erzielt werden können.
Backpropagation
Die Backpropagation ist ein grundlegender Algorithmus zur Gewichtsanpassung beim Training von neuronalen Netzwerken. Es verwendet die Kettenregel der Ableitung, um den Beitrag jedes Gewichts zur Fehlerfunktion zu berechnen. Der Fehler wird dann rückwärts durch das Netzwerk propagiert, um die Gewichte entsprechend anzupassen.
Der Algoritmus besteht aus zwei Hauptphasen: der Vorwärtspropagation und der Rückwärtspropagation. Bei der Vorwärtspropagation fließen die Daten durch das Netzwerk, die Gewichte werden aktualisiert und die Ausgaben der Schichten werden berechnet. Bei der Rückwärtspropagation wird der Fehler berechnet, indem der Gradient der Kostenfunktion mit den Gewichten multipliziert wird. Anhand der Ableitung wird schließlich der Beitrag jedes Gewichts zum Fehler berechnet und die Gewichte angepasst.
Convolutional Neural Networks (CNNs)
Convolutional Neural Networks, kurz CNNs, sind eine spezielle Art von neuronalen Netzwerken, die besonders gut für die Verarbeitung und Klassifizierung von Bildern geeignet sind. Sie ahmen die Funktionsweise des visuellen Kortex nach und sind in der Lage, lokale Muster in bilddaten zu erkennen.
CNNs verwenden spezielle Schichten, um räumliche Invarianz zu erreichen. Die Convolutional-Schicht verwendet Filter, die über das Eingangsbild gefaltet werden, um bestimmte Merkmale zu erkennen. Die Pooling-Schicht reduziert die räumliche Dimension der Merkmale, während die Aktivierungsschicht die letzten Ergebnisse zusammenfasst. Dieser Prozess wird wiederholt, um Merkmale auf höherer Abstraktionsebene zu lernen.
CNNs haben in Bereichen wie Bilderkennung, Objekterkennung und Gesichtserkennung große Erfolge erzielt und wurden in vielen Anwendungen eingesetzt.
Recurrent Neural Networks (RNNs)
Recurrent Neural Networks, kurz RNNs, sind eine andere Art von neuronalen Netzwerken, die die Fähigkeit haben, Sequenzen von Daten zu verarbeiten und zu lernen. Im Gegensatz zu CNNs verfügen RNNs über eine Rückkopplungsschleife, die es ihnen ermöglicht, Informationen über vergangene Zustände beizubehalten.
Ein RNN besteht aus einer Schicht von Neuronen, die miteinander verbunden sind und über eine Rückkopplungsschleife verfügen. Diese Schleife ermöglicht es dem Netzwerk, frühere Ausgaben als Eingabe für zukünftige Schritte zu verwenden. Dadurch können RNNs in der Lage sein, Kontextinformationen in den Daten zu erfassen und auf zeitliche Aspekte zu reagieren.
RNNs haben in Bereichen wie maschineller Übersetzung, Spracherkennung, Texterkennung und Textgenerierung große Erfolge erzielt.
Merke
Das Training von Deep-Learning-Modellen erfordert umfassendes Wissen über neuronale Netzwerke, ihre Strukturen und Trainingsmethoden. Die Grundlagen des Deep Learnings sind von entscheidender Bedeutung für das Verständnis der Funktionsweise und Grenzen dieser Technik. Durch den Einsatz von tiefen neuronalen Netzwerken, wie den Convolutional und Recurrent Neural Networks, können komplexe Muster in verschiedenen Datentypen erkannt und interpretiert werden. Die weitere Erforschung und Entwicklung von Deep Learning hat das Potenzial, viele Bereiche der Künstlichen Intelligenz zu revolutionieren.
Wissenschaftliche Theorien im Bereich Deep Learning
Das Feld des Deep Learning hat in den letzten Jahren große Aufmerksamkeit auf sich gezogen und ist zu einem zentralen Thema in der künstlichen Intelligenz (KI) geworden. Es gibt eine Vielzahl von wissenschaftlichen Theorien, die sich mit den Grundlagen und Grenzen von Deep Learning beschäftigen. Diese Theorien reichen von mathematischen Modellen bis hin zu neurowissenschaftlichen Ansätzen und spielen eine entscheidende Rolle bei der Entwicklung und Weiterentwicklung von Deep-Learning-Algorithmen.
Neuronale Netzwerke
Eine der grundlegendsten Theorien im Deep Learning ist das Konzept der künstlichen neuronalen Netzwerke. Diese Theorie basiert auf der Annahme, dass das menschliche Gehirn aus einer großen Anzahl von Neuronen besteht, die über synaptische Verbindungen miteinander kommunizieren. Die Idee hinter neuronalen Netzwerken ist es, dieses biologische Prinzip auf maschineller Ebene nachzuahmen. Ein neuronales Netzwerk besteht aus verschiedenen Schichten von künstlichen Neuronen, die über gewichtete Verbindungen miteinander verbunden sind. Durch das Lernen von Gewichten können neuronale Netzwerke komplexe Funktionen erlernen und Muster in den Daten erkennen.
Feedforward- und Rückkopplungsnetzwerke
Im Bereich des Deep Learning gibt es zwei grundlegende Arten von neuronalen Netzwerken: feedforward- und rückkopplungsnetzwerke. Feedforward-Netzwerke sind die am häufigsten verwendeten Modelle im Deep Learning und zeichnen sich dadurch aus, dass die Information nur in eine Richtung durch das Netzwerk fließt, von der Eingabeschicht zur Ausgabeschicht. Diese Art von Netzwerken eignet sich besonders gut für Aufgaben wie Klassifizierung und Regression.
Rückkopplungsnetzwerke hingegen ermöglichen die Rückkopplung von Informationen aus den Ausgabeschichten zu den Eingabeschichten. Dadurch können diese Netzwerke dynamische Prozesse modellieren und zum Beispiel für die Vorhersage von Zeitreihen eingesetzt werden.
Die Theorie hinter diesen Netzwerken stellt eine Erweiterung der feedforward-Netzwerke dar und ermöglicht eine größere Flexibilität bei der Modellierung von komplexen Zusammenhängen.
Convolutional Neural Networks (CNN)
Eine weitere wichtige Theorie im Bereich Deep Learning sind Convolutional Neural Networks (CNN). Diese Art von neuronalen Netzwerken ist speziell darauf ausgerichtet, mit Daten umzugehen, die eine räumliche Struktur aufweisen, wie beispielsweise Bilder. CNNs verwenden spezielle Schichten, die als Faltungsschichten bezeichnet werden und lokale Muster in den Daten erkennen können. Durch die Verwendung von faltenden Schichten können CNNs Bilder automatisch segmentieren, Objekte erkennen und Klassifizierungsaufgaben durchführen.
Die Theorie hinter CNNs basiert auf der Tatsache, dass viele visuelle Aufgaben hierarchische Strukturen aufweisen. Die ersten Schichten eines CNN erkennen einfache Kanten und Texturmerkmale, während spätere Schichten immer komplexere Merkmale erkennen können. Diese Hierarchie ermöglicht es dem Netzwerk, abstrakte Konzepte wie Gesichter oder Objekte zu verstehen.
Generative Adversarial Networks (GAN)
Generative Adversarial Networks (GANs) sind eine weitere Theorie im Bereich des Deep Learning. GANs bestehen aus zwei neuralen Netzwerken, einem Generator und einem Diskriminator, die miteinander konkurrieren. Der Generator generiert neue Beispiele, während der Diskriminator versucht, echte Beispiele von den künstlich generierten zu unterscheiden.
Die Idee hinter GANs ist es, einen Generator zu trainieren, der realistische Daten erzeugen kann, indem er die zugrunde liegende Verteilung der Daten erlernt. GANs haben zahlreiche Anwendungen, wie zum Beispiel das Generieren von Bildern oder das Erzeugen von Texten. Die Theorie hinter GANs ist komplex und erfordert mathematische Kenntnisse aus den Bereichen Wahrscheinlichkeitstheorie und Spieltheorie.
Limitierungen und Grenzen
Obwohl Deep Learning in vielen Bereichen erfolgreich eingesetzt wird, gibt es auch Grenzen und Limitierungen dieser Technologie. Eine der Hauptlimitierungen sind die Datenanforderungen. Deep Learning-Modelle benötigen oft große Mengen an annotierten Trainingsdaten, um effektiv zu funktionieren. Das Einsammeln und Annotieren solcher Daten kann zeitaufwendig und kostspielig sein.
Ein weiteres Problem ist die sogenannte Overfitting-Problematik. Deep-Learning-Modelle können zu gut an die Trainingsdaten angepasst werden und schlecht auf neuen Daten generalisieren. Dieses Problem kann durch Techniken wie Regularisierung oder den Einsatz von unbeschrifteten Daten bekämpft werden, ist jedoch immer noch eine Herausforderung.
Darüber hinaus sind Deep Learning-Modelle oft als sogenannte "Black Box" bekannt, da es schwierig ist, ihre internen Entscheidungsprozesse zu verstehen. Dies ist insbesondere in sicherheitskritischen Anwendungen wie der Medizin oder der Autonomie von Fahrzeugen ein Problem.
Merke
Die wissenschaftlichen Theorien, die Deep Learning zugrunde liegen, reichen von neuronalen Netzwerken über Convolutional Neural Networks bis hin zu Generative Adversarial Networks. Diese Theorien haben zu großen Fortschritten bei der Mustererkennung und dem maschinellen Lernen geführt. Dennoch gibt es auch Grenzen und Limitierungen, die weiter untersucht werden müssen, um die Anwendbarkeit von Deep Learning in verschiedenen Bereichen zu verbessern. Es ist wichtig, weiterhin die Theorien und Konzepte des Deep Learning zu erforschen, um das volle Potenzial dieser aufstrebenden Technologie auszuschöpfen.
Vorteile von Deep Learning
Deep Learning ist ein Teilbereich des maschinellen Lernens, der auf künstlichen neuronalen Netzwerken basiert. Es hat in den letzten Jahren große Aufmerksamkeit erhalten und ist zu einem wichtigen Werkzeug für die Datenanalyse und das Lösen komplexer Probleme geworden. Deep Learning bietet eine Reihe von Vorteilen, sowohl in Bezug auf die Leistungsfähigkeit als auch in Bezug auf die Anwendbarkeit auf verschiedene Aufgaben und Branchen.
In diesem Abschnitt werden die Vorteile von Deep Learning ausführlich diskutiert.
1. Bessere Leistung bei großen Datenmengen
Deep Learning-Modelle sind bekannt für ihre Fähigkeit, große Datenmengen effizient zu verarbeiten. Im Gegensatz zu herkömmlichen statistischen Modellen, die auf begrenzten Datensätzen basieren, können Deep Learning-Modelle mit Millionen oder sogar Milliarden von Datenpunkten arbeiten. Dies ermöglicht eine genauere und zuverlässigere Analyse, da sie auf einer breiten Datenbasis basiert.
Ein Beispiel dafür ist die Bilderkennung. Mit Deep Learning können neuronale Netzwerke trainiert werden, um Tausende von Bildern zu analysieren und Muster und Merkmale zu erkennen. Dies hat zu beeindruckenden Fortschritten bei der automatisierten Bilderkennung und -klassifizierung geführt, die in verschiedenen Branchen wie Medizin, Sicherheit und Transport eingesetzt werden.
2. Automatisierte Merkmalsextraktion
Ein weiterer großer Vorteil von Deep Learning ist die Fähigkeit, automatisch Merkmale aus den Daten zu extrahieren. In traditionellen Verfahren muss der Mensch die relevanten Merkmale manuell definieren und extrahieren, was zeitaufwändig und subjektiv sein kann. Mit Deep Learning können neuronale Netzwerke automatisch relevante Merkmale aus den Daten extrahieren, wodurch der Analyseprozess beschleunigt und die Genauigkeit verbessert wird.
Dies ist besonders nützlich bei unstrukturierten Daten wie Bildern, Texten und Tonaufnahmen. Zum Beispiel kann ein Deep Learning-Modell verwendet werden, um aus Röntgenbildern Merkmale zu extrahieren und automatisch Krankheiten wie Krebs zu erkennen. Dieser automatisierte Prozess kann die Erkennungszeit erheblich verkürzen und die Genauigkeit im Vergleich zu herkömmlichen Verfahren verbessern.
3. Flexibilität und Anpassungsfähigkeit
Deep Learning-Modelle sind äußerst flexibel und anpassungsfähig. Sie können auf verschiedene Aufgaben und Branchen angewendet werden, von der Sprachübersetzung bis zur Robotik. Durch das Training auf spezifische Datensätze können Deep Learning-Modelle spezialisiert und optimiert werden, um bestimmte Probleme zu lösen.
Ein Beispiel dafür ist der Einsatz von Deep Learning in der automatischen Spracherkennung. Indem neuronale Netzwerke auf große Sprachkorpora trainiert werden, können sie menschliche Sprache verstehen und in Text umwandeln. Dies hat zu Fortschritten bei der Entwicklung von Sprachassistenten wie Siri und Alexa geführt, die in verschiedenen Geräten und Anwendungen zur Verfügung stehen.
4. Kontinuierliche Verbesserung
Deep Learning-Modelle können kontinuierlich verbessert werden, indem sie mit neuen Daten aktualisiert und erweitert werden. Dies ermöglicht es den Modellen, sich an verändernde Muster, Trends und Bedingungen anzupassen, ohne dass ein umfangreicher Neutraining erforderlich ist.
Durch diese Fähigkeit zur kontinuierlichen Verbesserung kann Deep Learning in Echtzeitanwendungen eingesetzt werden, bei denen Modelle ständig mit neuen Daten arbeiten müssen. Ein Beispiel dafür ist der Einsatz von Deep Learning in selbstfahrenden Autos. Durch die kontinuierliche Aktualisierung der Trainingsdaten können sich die Modelle an veränderte Verkehrsbedingungen anpassen und die Fahrsicherheit verbessern.
5. Entdeckung von komplexen Zusammenhängen
Deep Learning kann dazu beitragen, komplexe Zusammenhänge in den Daten zu entdecken, die mit traditionellen statistischen Modellen schwer zu erfassen wären. Durch die Verwendung mehrerer Schichten von Neuronen können Deep Learning-Modelle hierarchische und nichtlineare Merkmale erkennen, die in den Daten vorhanden sind.
Ein Beispiel hierfür ist die Analyse von medizinischen Bildern. Durch die Verwendung von Deep Learning können neuronale Netzwerke Tausende von Merkmalen in den Bildern identifizieren und Muster erkennen, die mit menschlichem Auge schwer zu erkennen wären. Dies ermöglicht es Ärzten, bessere Diagnosen zu stellen und Behandlungen zu planen.
6. Skalierbarkeit und Effizienz
Deep
Learning-Modelle sind äußerst skalierbar und können auf großen Rechenressourcen wie Grafikprozessoren (GPUs) parallelisiert werden. Dies ermöglicht eine schnelle und effiziente Verarbeitung großer Datenmengen.
Die Skalierbarkeit von Deep Learning ist besonders wichtig in Bereichen wie Big Data Analyse und Cloud Computing. Durch die Verwendung von Deep Learning können Unternehmen große Datenmengen analysieren und aussagekräftige Erkenntnisse gewinnen, um fundierte Entscheidungen zu treffen und Geschäftsprozesse zu verbessern.
7. Geringer Bereichsbedarf für Expertenwissen
Im Gegensatz zu herkömmlichen statistischen Modellen erfordern Deep Learning-Modelle weniger Expertenwissen in Bezug auf die Merkmalsextraktion und Modellierung der Daten. Mit Deep Learning können die Modelle durch das Training mit Beispieldaten lernen, relevante Merkmale zu identifizieren und Vorhersagen zu treffen.
Dies erleichtert die Anwendung von Deep Learning in Bereichen, in denen Expertenwissen schwer zu erlangen ist oder teuer ist. Ein Beispiel dafür ist die automatisierte Spracherkennung, bei der Deep Learning-Modelle ohne vordefinierte Regeln auf große Sprachdatensätze trainiert werden können.
Merke
Insgesamt bietet Deep Learning eine Vielzahl von Vorteilen, die es zu einer leistungsstarken und vielseitigen Methode der Datenanalyse machen. Durch die Fähigkeit, große Datenmengen effizient zu verarbeiten und automatisch relevante Merkmale zu extrahieren, ermöglicht Deep Learning neue Erkenntnisse und Fortschritte in verschiedenen Branchen und Anwendungen. Mit der kontinuierlichen Verbesserung, Skalierbarkeit und Effizienz von Deep Learning-Modellen wird diese Methode weiterhin dazu beitragen, komplexe Probleme zu lösen und innovative Lösungen bereitzustellen.
Nachteile oder Risiken des Deep Learning
Deep Learning, eine Unterkategorie des maschinellen Lernens, hat in den letzten Jahren zunehmend an Popularität gewonnen und wird in vielen Anwendungen erfolgreich eingesetzt. Es ist eine Technologie, die auf neuronalen Netzwerken basiert und es Computern ermöglicht, komplexe Aufgaben zu erlernen und auszuführen, die normalerweise menschliches Wissen und Intelligenz erfordern würden. Trotz der vielen Vorteile und Möglichkeiten, die das Deep Learning bietet, gibt es jedoch auch Nachteile und Risiken, die bei der Anwendung dieser Technologie berücksichtigt werden müssen. In diesem Abschnitt werden diese Nachteile und Risiken ausführlich und wissenschaftlich behandelt.
Mangelnde Transparenz
Eine der größten Herausforderungen beim Einsatz von Deep Learning ist die mangelnde Transparenz der Entscheidungsfindung. Während traditionelle Programmierung auf Regeln und logischen Schritten basiert, die von Menschen entwickelt werden, um bestimmte Ergebnisse zu erzielen, funktioniert Deep Learning aufgrund der Komplexität der neuronalen Netzwerke anders. Es ist schwierig nachzuvollziehen, wie ein Deep-Learning-Modell zu einer bestimmten Vorhersage oder Entscheidung gekommen ist. Dieser Mangel an Transparenz kann zu einem Vertrauensverlust führen, da Benutzer und Stakeholder möglicherweise nicht verstehen, warum bestimmte Entscheidungen getroffen wurden oder wie das Modell tatsächlich funktioniert.
Um dieses Problem anzugehen, werden verschiedene Techniken entwickelt, um die Transparenz von Deep-Learning-Modellen zu verbessern. Insbesondere die Erklärbarkeit von Entscheidungen wird erforscht, um den Benutzern und Stakeholdern Einblick in die Funktionsweise des Modells zu geben.
Mangelnde Robustheit gegenüber Störungen
Eine weitere Herausforderung des Deep Learning ist die mangelnde Robustheit gegenüber Störungen. Deep-Learning-Modelle können anfällig für sogenannte "Adversarial Attacks" sein, bei denen kleine, absichtlich eingeführte Störungen in den Eingabedaten dazu führen können, dass das Modell falsche Vorhersagen trifft oder fehlerhaft funktioniert. Diese Störungen sind für Menschen oft nicht wahrnehmbar, aber das Modell reagiert dennoch stark darauf.
Dieses Problem ist besonders besorgniserregend, wenn Deep Learning in sicherheitskritischen Anwendungen eingesetzt wird, wie beispielsweise in der Medizin oder im autonomen Fahren. Ein fehlerhaftes Modell, das manipulierte Eingabedaten nicht richtig verarbeitet, kann schwerwiegende Folgen haben. Forscher arbeiten an Techniken, um Deep-Learning-Modelle robuster gegenüber solchen Störungen zu machen, aber es bleibt eine Herausforderung, die noch nicht vollständig gelöst ist.
Datenvoraussetzungen und Datenschutzbedenken
Ein weiterer Nachteil von Deep Learning ist die hohe Abhängigkeit von großen Mengen an qualitativ hochwertigen Trainingsdaten. Um ein effektives Modell zu erstellen, müssen Deep-Learning-Algorithmen mit ausreichend Daten trainiert werden, damit sie Muster erkennen und Vorhersagen generieren können. Dies kann zu Schwierigkeiten führen, wenn nicht genügend Daten vorhanden sind oder die verfügbaren Daten von schlechter Qualität sind.
Darüber hinaus können Datenschutzbedenken bei der Verwendung von Deep Learning auftreten. Da Deep-Learning-Modelle sehr viele Daten analysieren und verarbeiten, besteht das Risiko, dass sensible Informationen oder personenbezogene Daten versehentlich offengelegt werden. Dies kann zu erheblichen rechtlichen und ethischen Konsequenzen führen. Um diese Risiken zu minimieren, sind Datenschutztechniken und -richtlinien erforderlich, um sicherzustellen, dass die Privatsphäre von Individuen geschützt wird.
Ressourcenintensivität
Deep Learning ist bekannt dafür, rechen- und ressourcenintensiv zu sein. Das Training eines Deep-Learning-Modells erfordert erhebliche Rechenleistung und Speicherplatz. Insbesondere große Modelle mit vielen Schichten und Neuronen erfordern leistungsstarke Hardware und Ressourcen, um effizient trainiert zu werden. Dies kann zu hohen Kosten führen, insbesondere für kleine Unternehmen oder Organisationen mit begrenztem Budget.
Die Bereitstellung von Deep-Learning-Modellen für den Einsatz in der Produktion erfordert ebenfalls erhebliche Ressourcen. Die Modelle müssen auf Servern oder Cloud-Plattformen gehostet und gewartet werden, was zusätzliche Kosten verursachen kann. Die Ressourcenintensität von Deep Learning kann ein Hindernis für die breite Anwendung und Verbreitung dieser Technologie darstellen.
Verzerrung und Vorurteile
Deep-Learning-Modelle sind nur so gut wie die Daten, mit denen sie trainiert werden. Wenn die Trainingsdaten Vorurteile oder Verzerrungen aufweisen, wird sich dies auch in den Vorhersagen und Entscheidungen des Modells widerspiegeln. Dies kann zu Fehlern und Ungerechtigkeiten führen, insbesondere in Anwendungen wie der Kreditvergabe, der Bewerbungsauswahl oder der Kriminalitätsvorhersage.
Die Verzerrung und Vorurteile von Deep-Learning-Modellen sind ein ernstes Problem, das angegangen werden muss. Eine Möglichkeit, dieses Problem anzugehen, besteht darin, sicherzustellen, dass die Trainingsdaten divers und repräsentativ sind. Unterschiedliche Bevölkerungsgruppen sollten angemessen in den Trainingsdaten vertreten sein, um Vorurteile und Verzerrungen zu reduzieren.
Skalierbarkeit und Komplexität
Die Größe und Komplexität von Deep-Learning-Modellen kann auch zu Herausforderungen bei der Skalierbarkeit führen. Während kleinere Modelle möglicherweise noch effizient auf handelsüblichen Computern trainiert werden können, werden größere Modelle mit mehreren Schichten und Neuronen mehr Rechenleistung und Speicherplatz erfordern. Dies kann die Skalierung von Deep Learning auf komplexe Aufgaben und Anwendungen einschränken.
Darüber hinaus erfordert die Entwicklung und Implementierung von Deep-Learning-Modellen spezialisierte Kenntnisse und Fähigkeiten. Es erfordert Fachwissen in den Bereichen Mathematik, Statistik, Computerwissenschaften und maschinelles Lernen. Dies kann dazu führen, dass Deep Learning für viele Menschen, insbesondere für diejenigen ohne Zugang zu entsprechenden Ressourcen oder Bildung, unzugänglich wird.
Zusammenfassung
Deep Learning
bietet viele Möglichkeiten und Vorteile, aber es ist wichtig, auch die potenziellen Nachteile und Risiken dieser Technologie zu berücksichtigen. Die mangelnde Transparenz, die Robustheit gegenüber Störungen, die Abhängigkeit von qualitativ hochwertigen Trainingsdaten, Datenschutzbedenken, die Ressourcenintensität, die Verzerrung und Vorurteile sowie die Skalierbarkeit und Komplexität sind Herausforderungen, die bei der Anwendung von Deep Learning adressiert werden müssen. Durch weitere Forschung und Entwicklung von Techniken zur Verbesserung dieser Aspekte kann Deep Learning sein Potenzial besser ausschöpfen und zu einer effektiven und verantwortungsbewussten Technologie werden.
Anwendungsbeispiele und Fallstudien im Bereich Deep Learning
Deep Learning, eine Teilmenge des maschinellen Lernens, hat in den letzten Jahren erstaunliche Fortschritte gemacht und wird heute in einer Vielzahl von Anwendungen eingesetzt. Diese Technik hat sich als äußerst leistungsfähig erwiesen und ermöglicht es Computersystemen, komplexe Aufgaben zu lösen, die für herkömmliche algorithmische Ansätze schwierig oder unmöglich sind. In diesem Abschnitt werden einige wichtige Anwendungsbeispiele und Fallstudien im Bereich Deep Learning vorgestellt.
Bilderkennung und Objekterkennung
Eines der bekanntesten Anwendungsgebiete von Deep Learning ist die Bilderkennung. Deep-Learning-Modelle können trainiert werden, um Objekte, Muster oder Gesichter in Bildern zu erkennen. Beispielsweise hat das Modell "DeepFace" von Facebook die Fähigkeit, Gesichter auf Fotos extrem genau zu erkennen und zu identifizieren. Diese Fähigkeit hat Anwendungen in der Sicherheit, der sozialen Medien und sogar in der medizinischen Bildgebung.
Ein weiteres Beispiel ist das "Convolutional Neural Network" (CNN), das speziell für die Objekterkennung entwickelt wurde. Diese Modelle können komplexe Szenen analysieren und Objekte in Bildern identifizieren. Im Jahr 2012 gewann ein CNN-Basiertes Modell namens "AlexNet" den ImageNet-Wettbewerb, bei dem es darum geht, Objekte in 1,2 Millionen Bildern zu erkennen. Dieser Erfolg war ein Wendepunkt für Deep Learning und hat das Interesse an der Technologie stark erhöht.
Spracherkennung und natürlich-sprachliche Verarbeitung (NLP)
Deep Learning hat auch zu erheblichen Fortschritten in der Spracherkennung und natürlich-sprachlichen Verarbeitung geführt. Durch den Einsatz von rekurrenten neurnalen Netzwerken (RNN) können Modelle trainiert werden, um gesprochene Sprache in Text umzuwandeln. Beispielsweise verwendet die Spracherkennungssoftware "Siri" von Apple Deep-Learning-Techniken, um Benutzeranweisungen zu verstehen und darauf zu reagieren.
Darüber hinaus kann Deep Learning in der natürlichen Sprachverarbeitung eingesetzt werden, um den Kontext und die Bedeutung von Text zu verstehen. In der Literaturanalyse und Sentiment-Analyse haben Deep-Learning-Modelle gezeigt, dass sie menschliche Schreibstile und Emotionen erkennen können. Dies ermöglicht es Unternehmen, das Kundenfeedback besser zu verstehen und ihre Produkte und Dienstleistungen entsprechend anzupassen.
Medizinische Bildgebung und Diagnose
Deep Learning hat auch das Potenzial, die medizinische Bildgebung und Diagnose zu revolutionieren. Durch die Trainierung von neuronalen Netzwerken mit großen Mengen an medizinischen Bildern können Modelle entwickelt werden, die in der Lage sind, Krebsgewebe, Anomalien oder andere medizinische Zustände zu erkennen. In einer Studie wurde ein CNN-basiertes Modell entwickelt, das eine vergleichbare Genauigkeit bei der Diagnose von Hautkrebs zeigte wie erfahrene Dermatologen. Dieses Beispiel zeigt das enorme Potenzial von Deep-Learning-Modellen in der medizinischen Diagnose.
Autonome Fahrzeuge
Ein weiteres Anwendungsgebiet, in dem Deep Learning große Fortschritte gemacht hat, ist die Entwicklung autonomer Fahrzeuge. Durch den Einsatz von KI-Modellen können Fahrzeuge lernen, Verkehrszeichen zu erkennen, Hindernisse zu umgehen und sich in verschiedenen Verkehrssituationen sicher zu bewegen.
Unternehmen wie Tesla, Google und Uber setzen bereits Deep-Learning-Techniken ein, um ihre autonomen Fahrzeuge zu verbessern. Obwohl diese Technologie noch in den Kinderschuhen steckt, hat sie das Potenzial, die Art und Weise, wie wir uns fortbewegen, grundlegend zu verändern.
Musikgenerierung und künstlerische Kreativität
Deep Learning kann auch dazu verwendet werden, Musik zu generieren und künstlerische Kreativität zu fördern. Durch das Training von neuronalen Netzwerken mit großen Mengen an musikalischen Daten können Modelle entwickelt werden, die in der Lage sind, Musikstücke zu komponieren oder vorhandene Melodien in neuen Stilen umzuwandeln. Dieses Gebiet wird als "Deep Music" bezeichnet und hat bereits zu interessanten Ergebnissen geführt. Beispielsweise kann ein Modell trainiert werden, um Musik im Stil eines bestimmten Komponisten zu erstellen oder ein vorhandenes Stück in einen anderen Musikstil zu übertragen.
Zusammenfassung
Deep Learning hat in den letzten Jahren erhebliche Fortschritte gemacht und wird in einer Vielzahl von Anwendungen eingesetzt. Die Bilderkennung, Spracherkennung, medizinische Bildgebung, autonomes Fahren, Musikgenerierung und viele andere Bereiche haben von den leistungsstarken Fähigkeiten des Deep Learning profitiert. Die Beispiele und Fallstudien, die in diesem Abschnitt vorgestellt wurden, sind nur ein kleiner Ausschnitt der Anwendungen und zeigen das enorme Potenzial dieser Technologie. Es bleibt spannend zu beobachten, wie sich Deep Learning in Zukunft weiterentwickeln und neue Möglichkeiten für die Gesellschaft eröffnen wird.
Häufig gestellte Fragen
Was ist Deep Learning?
Deep Learning ist ein Teilbereich des maschinellen Lernens, der auf künstlichen neuronalen Netzwerken (KNN) basiert. Es handelt sich um eine Methode, bei der Algorithmen verwendet werden, um große Mengen an Daten zu analysieren und Muster zu erkennen. Diese Algorithmen sind in der Lage, komplexe Zusammenhänge zu lernen und Entscheidungen zu treffen, ohne dass sie explizit programmiert werden müssen. Deep Learning ist durch seine Fähigkeit zur automatischen Extraktion von Merkmalen aus Daten und zur Handhabung von unstrukturierten und hochdimensionalen Daten besonders leistungsfähig.
Wie funktioniert Deep Learning?
Deep Learning verwendet tiefe neuronale Netzwerke, die aus mehreren Schichten von Neuronen bestehen. Diese Netzwerke sind in der Lage, Daten zu interpretieren und zu verstehen. Das Training der neuronalen Netzwerke im Deep Learning erfolgt durch die Optimierung der Gewichte und Bias-Werte, um eine gewünschte Ausgabe für eine gegebene Eingabe zu generieren.
Der Prozess des Trainings eines Deep-Learning-Modells erfolgt in der Regel in zwei Schritten. Im ersten Schritt wird das Modell mit einer großen Menge an Trainingsdaten gefüttert. Während des Trainings passt das Modell kontinuierlich die Gewichte und Bias-Werte an, um die Vorhersagen des Modells zu verbessern. Im zweiten Schritt wird das trainierte Modell auf neuen Daten getestet, um die Genauigkeit der Vorhersagen zu bewerten.
Wo wird Deep Learning eingesetzt?
Deep Learning wird in vielen unterschiedlichen Bereichen eingesetzt. Eine der bekanntesten Anwendungen ist die Bilderkennung, bei der Deep-Learning-Modelle in der Lage sind, Objekte in Bildern zu erkennen und zu klassifizieren. Darüber hinaus wird Deep Learning auch in der Spracherkennung, der automatischen Übersetzung, der Textanalyse, der Autonomie von Fahrzeugen und der medizinischen Diagnose eingesetzt.
Was sind die Grenzen des Deep Learning?
Obwohl Deep Learning sehr leistungsstark ist, hat es auch seine Grenzen. Eines der Hauptprobleme ist die Notwendigkeit einer großen Menge an Trainingsdaten, um genaue Vorhersagen zu treffen. Wenn die Datenmenge begrenzt ist, kann es schwierig sein, ein zuverlässiges Modell zu trainieren.
Ein weiteres Problem ist die Interpretierbarkeit der Ergebnisse. Deep-Learning-Modelle sind oft als sogenannte "Black-Boxen" bekannt, da sie komplexe Beziehungen
lernen können, aber es schwierig sein kann, die zugrunde liegenden Muster oder Gründe für bestimmte Vorhersagen zu verstehen.
Auch die Rechenleistung und Ressourcenanforderungen können eine Herausforderung sein. Deep-Learning-Modelle sind sehr rechenintensiv und erfordern leistungsstarke Hardware oder spezielle Prozessoren wie GPUs.
Wie kann man Deep-Learning-Modelle verbessern?
Es gibt verschiedene Ansätze, um Deep-Learning-Modelle zu verbessern. Eine Möglichkeit besteht darin, mehr Trainingsdaten zu sammeln, um die Vorhersagegenauigkeit zu verbessern. Eine größere Datenmenge ermöglicht es dem Modell, eine größere Vielfalt an Mustern und Beziehungen zu erlernen.
Eine weitere Möglichkeit besteht darin, die Architektur des neuronalen Netzwerks zu optimieren. Durch die Verwendung von komplexeren Netzwerkstrukturen wie Convolutional Neural Networks (CNNs) oder Recurrent Neural Networks (RNNs) können bessere Ergebnisse erzielt werden.
Darüber hinaus können Techniken wie Data Augmentation, die das Erzeugen künstlicher Daten durch Veränderung der vorhandenen Daten beinhalten, und Regularisierungstechniken wie Dropout verwendet werden, um Overfitting zu verhindern und die Leistung des Modells zu verbessern.
Welche Rolle spielt Deep Learning in der Entwicklung künstlicher Intelligenz?
Deep Learning spielt eine wichtige Rolle in der Entwicklung von künstlicher Intelligenz (KI). Es ermöglicht Computern, komplexe Aufgaben zu erlernen und menschenähnliche Fähigkeiten in Bereichen wie Bild- und Spracherkennung zu entwickeln.
Durch die Kombination von Deep Learning mit anderen Techniken wie Reinforcement Learning und Natural Language Processing können KI-Systeme entwickelt werden, die intelligente Entscheidungen treffen und komplexe Probleme lösen können.
Gibt es ethische Bedenken im Zusammenhang mit Deep Learning?
Ja, es gibt ethische Bedenken im Zusammenhang mit Deep Learning. Ein Hauptanliegen ist die Privatsphäre und der Datenschutz. Da Deep Learning auf großen Mengen an Daten beruht, besteht die Gefahr, dass persönliche Informationen und sensible Daten in unsichere Hände geraten oder für unerwünschte Zwecke verwendet werden können.
Ein weiteres Problem sind die Vorurteile und Vorurteile, die in den Daten vorhanden sein können. Wenn die Trainingsdaten eine Verzerrung aufweisen oder nicht repräsentativ für die tatsächliche Bevölkerung sind, können die Vorhersagen und Entscheidungen des Modells ebenfalls verzerrt sein.
Darüber hinaus besteht auch die Gefahr von Arbeitsplatzverlusten durch die Automatisierung von Aufgaben, die zuvor von Menschen durchgeführt wurden. Dies könnte zu sozialen und wirtschaftlichen Ungleichgewichten führen.
Wie sieht die Zukunft von Deep Learning aus?
Die Zukunft von Deep Learning ist vielversprechend. Da immer größere Datenmengen verfügbar sind und die Rechenleistung weiterhin zunimmt, wird Deep Learning wahrscheinlich noch leistungsfähiger und vielseitiger werden.
Eine Entwicklung in Richtung effizienterer Modelle und Algorithmen wird erwartet, um den Rechenaufwand zu reduzieren und Deep Learning für eine breitere Anwendungsbasis zugänglich zu machen.
Darüber hinaus wird erwartet, dass Deep Learning in Verbindung mit anderen Techniken wie Reinforcement Learning und generativen Modellen zur Entwicklung noch intelligenterer KI-Systeme führen wird.
Gibt es Alternativen zu Deep Learning?
Ja, es gibt alternative Ansätze zum Deep Learning. Eine solche Alternative ist das symbolische maschinelle Lernen, bei dem Modelle auf Basis der expliziten Darstellung von Regeln und Symbolen arbeiten. Symbolisches maschinelles Lernen ist in der Lage, transparentere und interpretierbarere Modelle zu erstellen, da die zugrunde liegende Logik und das Regelwerk explizit dargelegt werden.
Eine weitere Alternative ist das bayessche maschinelle Lernen, bei dem die Unsicherheit in den Modellen berücksichtigt und probabilistische Inferenzmethoden verwendet werden.
Schließlich gibt es auch Ansätze wie das evolutionäre
maschinelle Lernen, bei dem Populationen von Modellen durch evolutionäre Prozesse optimiert werden.
Diese alternativen Ansätze haben jeweils ihre eigenen Vor- und Nachteile und können je nach Anwendungsfall unterschiedliche Vorteile bieten.
Kritik am Deep Learning
Das Deep Learning hat in den letzten Jahren große Aufmerksamkeit erregt und gilt als eine der vielversprechendsten Technologien im Bereich des maschinellen Lernens. Dennoch ist das Deep Learning nicht frei von Kritik. In diesem Abschnitt werden einige der Hauptkritikpunkte an dieser Technologie beleuchtet und diskutiert.
Begrenzte Datenmenge
Ein häufig genannter Kritikpunkt am Deep Learning ist, dass es eine große Menge an annotierten Trainingsdaten benötigt, um gute Ergebnisse zu erzielen. Insbesondere bei komplexen Aufgaben wie Bild- oder Spracherkennung sind große Datensätze erforderlich, um die Fülle der verschiedenen Merkmale und Muster abzudecken. Dies kann zu Herausforderungen führen, da nicht immer ausreichend viele annotierte Daten zur Verfügung stehen.
Ein weiteres Problem ist, dass sich die Anforderungen an die Datenqualität mit zunehmender Tiefe des Netzes erhöhen. Das heißt, dass selbst kleine Fehler in den Trainingsdaten zu schlechten Ergebnissen führen können. Dies macht die Sammlung und Annotierung großer Datenmengen noch schwieriger und zeitintensiver.
Black Box-Natur
Ein weiterer Kritikpunkt am Deep Learning ist seine Black Box-Natur. Das heißt, dass die Entscheidungen, die von einem tiefen neuronalen Netzwerk getroffen werden, oft schwer nachvollziehbar sind. Traditionelle maschinelle Lernalgorithmen ermöglichen es den Anwendern, die Entscheidungsfindung zu verstehen und zu erklären. Im Deep Learning hingegen ist der Prozess der Entscheidungsfindung ein komplexes Zusammenspiel von Millionen von Neuronen und Gewichten, das nur schwer zu durchdringen ist.
Diese Black Box-Natur des Deep Learning kann zu Vertrauensproblemen führen, vor allem in sicherheitskritischen Anwendungen wie dem autonomen Fahren oder der Medizin. Es ist schwierig zu sagen, warum ein tiefes neuronales Netzwerk eine bestimmte Entscheidung getroffen hat, und dies kann Vertrauen in die Technologie beeinträchtigen.
Hoher Ressourcenbedarf
Deep Learning-Modelle sind bekannt für ihren hohen Ressourcenbedarf, insbesondere in Bezug auf Rechenleistung und Speicherplatz. Um komplexe Modelle zu trainieren, sind oft große Mengen an Rechenleistung und spezieller Hardware, wie Grafikprozessoren (GPUs), erforderlich. Dies schränkt den Zugang zu dieser Technologie ein und begrenzt ihre Anwendung auf Organisationen oder Einzelpersonen mit ausreichend Ressourcen.
Der hohe Ressourcenbedarf des Deep Learning hat auch Umweltauswirkungen. Der Einsatz von Hochleistungsrechnern und GPUs führt zu einem erhöhten Energieverbrauch, der zu einer höheren CO2-Emission beiträgt. Dies ist besonders besorgniserregend, da das Deep Learning aufgrund seiner Popularität und Anwendungsvielfalt zunehmend eingesetzt wird.
Datenschutzbedenken
Da das Deep Learning große Mengen an Daten benötigt, um gute Ergebnisse zu erzielen, stellt sich die Frage nach dem Datenschutz. Viele Organisationen und Unternehmen sammeln und nutzen personenbezogene Daten, um Trainingsdatensätze zu erstellen. Dies kann zu Datenschutzbedenken führen, insbesondere wenn die Daten unsicher gespeichert oder für andere Zwecke verwendet werden.
Darüber hinaus können tiefgehende neuronale Netzwerke auch selbst Datenschutzprobleme aufwerfen. Diese Modelle haben die Fähigkeit, komplexe Merkmale aus den Trainingsdaten zu lernen, was bedeutet, dass sie Informationen über die Daten selbst erlangen. Dies kann zu unbefugtem Zugriff oder Missbrauch führen, wenn die Modelle nicht angemessen geschützt werden.
Robustheit gegenüber Angriffen
Ein weiteres Problem mit dem Deep Learning ist seine mangelnde Robustheit gegenüber Angriffen. Tiefgehende neuronale Netzwerke sind anfällig für verschiedene Arten von Angriffen, wie beispielsweise das Hinzufügen von Störungen zu den Eingabedaten (bekannt als adversariale Angriffe).
Diese Störungen können für Menschen kaum erkennbar sein, können aber das Verhalten des Modells drastisch verändern und zu falschen oder unzuverlässigen Vorhersagen führen.
Diese Sicherheitslücken im Deep Learning können weitreichende Folgen haben, vor allem in sicherheitskritischen Anwendungen wie der Bilderkennung in selbstfahrenden Autos oder der biometrischen Identifikation. Es ist wichtig, dass diese Angriffe erkannt und abgewehrt werden, um die Zuverlässigkeit und Sicherheit von Deep Learning-Systemen zu gewährleisten.
Merke
Trotz der Kritikpunkte bietet das Deep Learning immer noch enorme Potenziale und ist in vielen Anwendungsbereichen äußerst erfolgreich. Durch die Berücksichtigung der genannten Kritikpunkte und die Weiterentwicklung von robusten und transparenten Deep Learning-Modellen können viele der aufgeworfenen Probleme gelöst werden.
Es ist jedoch wichtig, dass sowohl Forscher als auch Praktizierende diese Kritikpunkte ernst nehmen und sich bewusst mit ihnen auseinandersetzen. Nur so können Fortschritte erzielt und das volle Potenzial des Deep Learning ausgeschöpft werden.
Aktueller Forschungsstand
In den letzten Jahren hat das Thema Deep Learning massive Fortschritte und Innovationen erlebt. Da es sich um einen schnell wachsenden Bereich handelt, haben Wissenschaftler auf der ganzen Welt intensiv daran gearbeitet, die Funktionsweise und die Grenzen des Deep Learning besser zu verstehen. In diesem Abschnitt werden einige der aktuellen Forschungsarbeiten und Erkenntnisse im Bereich des Deep Learning vorgestellt.
Verbesserte Modelle und Architekturen
Eine der Schlüsselkomponenten des Deep Learning ist die Architektur des neuronalen Netzwerks. Wissenschaftler haben viele neue Modelle und Architekturen entwickelt, um die Leistungsfähigkeit von Deep Learning zu verbessern. Ein Beispiel hierfür ist das Convolutional Neural Network (CNN), das speziell für die Verarbeitung von Bildern entwickelt wurde. CNNs haben sich als äußerst effektiv bei der Objekterkennung, Klassifizierung und Segmentierung erwiesen. Die Erforschung neuer CNN-Architekturen, wie zum Beispiel ResNet, DenseNet und MobileNet, hat zu bedeutenden Leistungssteigerungen geführt.
Ein weiteres vielversprechendes Modell ist das sogenannte GAN (Generative Adversarial Network). GANs bestehen aus zwei Netzwerken, dem Generator und dem Diskriminator, die miteinander konkurrieren. Der Generator erzeugt neue Daten, während der Diskriminator versucht, echte von generierten Daten zu unterscheiden. Durch diese Konkurrenz können GANs realistisch aussehende Bilder, Texte und sogar Audio erzeugen. Die Weiterentwicklung von GANs hat zu bemerkenswerten Ergebnissen in den Bereichen Bildsynthese, Bildübersetzung und Textgenerierung geführt.
Überwindung von Datenbeschränkungen
Das Training eines tiefen neuronalen Netzwerks erfordert normalerweise große Mengen an annotierten Daten. Ein derzeitiges Forschungsgebiet besteht darin, Methoden zu entwickeln, um die Abhängigkeit von einer großen Datenmenge zu verringern. Ein vielversprechender Ansatz ist das sogenannte transfer learning, bei dem ein Netzwerk zunächst auf großen allgemeinen Datensätzen vortrainiert wird und anschließend auf spezifische Aufgaben feinabgestimmt wird. Diese Technik ermöglicht es, Modelle mit begrenzten Datenressourcen effektiv zu trainieren und Leistungsverbesserungen zu erzielen.
Ein weiterer Ansatz, um die Datenbeschränkung zu überwinden, ist die Verwendung von generativen Modellen. Generative Modelle wie Variational Autoencoder (VAE) und Generative Adversarial Networks (GANs) sind in der Lage, neue Daten zu erzeugen, ohne dass umfangreiche annotierte Daten erforderlich sind. Dies ermöglicht es, den Datensatz zu erweitern und die Leistung des Modells zu verbessern. Die Erforschung und Weiterentwicklung solcher generativer Modelle hat das Potenzial, die Datenabhängigkeit des Deep Learning signifikant zu reduzieren.
Robustheit und Interpretierbarkeit von Deep Learning Modellen
Ein wichtiger
Forschungsbereich im Deep Learning ist die Verbesserung der Robustheit und Interpretierbarkeit von Modellen. Deep Learning Modelle sind bekanntermaßen anfällig für Angriffe und können in bestimmten Situationen unzuverlässig sein. Forscher arbeiten daran, die Fähigkeit von Deep Learning Modellen zur Erkennung von Angriffen zu verbessern und gleichzeitig ihre Leistung auf normalen Daten beizubehalten. Techniken wie Adversarial Training, bei dem das Modell mit speziell generierten adversarialen Beispielen trainiert wird, haben vielversprechende Ergebnisse gezeigt.
Ein weiteres Problem im Deep Learning ist die Black-Box-Natur der Modelle. Diese Tatsache macht es schwierig, die Entscheidungen und den internen Prozess der Modelle zu verstehen. Wissenschaftler arbeiten an Methoden zur Erklärbarkeit von Deep Learning Modellen, um zu verstehen, warum und wie ein Modell bestimmte Vorhersagen trifft. Durch die Verbesserung der Interpretierbarkeit kann das Vertrauen in die Modelle gestärkt und ihr Einsatz in sicherheitskritischen Bereichen erleichtert werden.
Verbesserte Hardware und effizientes Training
Um die wachsenden Anforderungen des Deep Learning zu bewältigen, sind leistungsstarke und effiziente Hardwarelösungen erforderlich. GPUs (Graphics Processing Units) haben sich als hilfreich erwiesen, um die Berechnungsintensität von Deep Learning Modellen zu bewältigen. In letzter Zeit wurde auch der Einsatz von spezialisierten Chiparchitekturen wie TPUs (Tensor Processing Units) und FPGAs (Field-Programmable Gate Arrays) erforscht, um die Rechenleistung weiter zu steigern.
Die Effizienz des Trainings ist ein weiterer kritischer Faktor. Das Training großer Deep Learning Modelle kann sehr zeitaufwendig und rechenintensiv sein. Forscher versuchen, effizientere Trainingsmethoden zu entwickeln, wie zum Beispiel das One-Shot Learning und das Few-Shot Learning, bei denen ein Modell mit nur wenigen Trainingsbeispielen gute Leistung erzielen kann. Diese Techniken könnten den Trainingsprozess beschleunigen und den Ressourcenbedarf reduzieren.
Anwendungsbereiche und Grenzen
Deep Learning hat eine Vielzahl von Anwendungsbereichen revolutioniert, einschließlich Bilderkennung, Sprachverarbeitung, autonome Fahrzeuge und medizinische Diagnose. Die Fortschritte im Deep Learning haben zu erheblichen Leistungssteigerungen in diesen Bereichen geführt und neue Möglichkeiten eröffnet. Dennoch gibt es auch Grenzen und Herausforderungen, die noch angegangen werden müssen.
Eine der Hauptgrenzen des Deep Learning ist seine Abhängigkeit von großen Datenmengen. Das Training eines tiefen neuralen Netzwerks erfordert normalerweise eine massive Anzahl von annotierten Beispielen. Dies kann in einigen Anwendungsbereichen, insbesondere in Nischenbereichen oder in Situationen, in denen nur begrenzte Daten verfügbar sind, problematisch sein. Die Entwicklung neuer Techniken zur effizienten Nutzung von begrenzten Datenressourcen ist daher von entscheidender Bedeutung.
Ein weiteres Problem ist die Erklärbarkeit von Deep Learning Modellen. Der aktuelle Stand der Technik ermöglicht es oft nicht, die Entscheidungen von Deep Learning Modellen vollständig zu verstehen und zu erklären. Dies kann zu einer mangelnden Vertrauenswürdigkeit führen, insbesondere in sicherheitskritischen Anwendungen. Eine Verbesserung der Erklärbarkeit und Transparenz von Deep Learning Modellen ist daher wünschenswert.
Zusammenfassend lässt sich sagen, dass der aktuelle Forschungsstand im Bereich des Deep Learning durch bemerkenswerte Fortschritte und Innovationen gekennzeichnet ist. Die Entwicklung verbesserter Modelle und Architekturen, die Überwindung von Datenbeschränkungen, die Verbesserung der Robustheit und Interpretierbarkeit, sowie die Verbesserung der Hardware- und Trainingsmethoden haben zu bedeutenden Fortschritten geführt. Dennoch gibt es noch Herausforderungen und Grenzen, die weiter erforscht werden müssen, um das volle Potenzial des Deep Learning auszuschöpfen.
Praktische Tipps für den Umgang mit Deep Learning
Deep Learning, auch bekannt als tiefes Lernen oder hierarchisches Lernen, ist ein Teilbereich des maschinellen Lernens, der auf neuronalen Netzwerken basiert. Diese Technik hat in den letzten Jahren erhebliche Fortschritte gemacht und hat zahlreiche Anwendungen in verschiedenen Bereichen wie Bild- und Spracherkennung, Natural Language Processing, robotischen Systemen und sogar selbstfahrenden Autos gefunden.
Da Deep Learning jedoch ein komplexes und anspruchsvolles Feld ist, gibt es bestimmte praktische Tipps, die bei der Verwendung und Implementierung dieser Technik hilfreich sein können. In diesem Abschnitt werden solche hilfreichen Tipps ausführlich behandeln und verschiedene Aspekte des Umgangs mit Deep Learning beleuchten.
Daten vorbereiten und vorverarbeiten
Die Qualität und Reinheit der Daten spielen eine entscheidende Rolle für die Leistungsfähigkeit von Deep Learning Modellen. Um optimale Ergebnisse zu erzielen, ist es wichtig, die Daten vor der Verwendung sorgfältig vorzubereiten und zu verarbeiten. Dazu gehören Schritte wie Datenaufbereitung, Datencodierung, Normalisierung und Datenaugmentation.
Die Datenaufbereitung beinhaltet die Bereinigung von Fehlwerten, die Entfernung von Ausreißern und die Anpassung fehlender Werte. Dies stellt sicher, dass die Daten eine hohe Qualität und Konsistenz aufweisen. Darüber hinaus kann die Kodierung von kategorialen Variablen in numerische Werte die Leistung des Modells verbessern. Die Normalisierung der Daten ist ebenfalls wichtig, um sicherzustellen, dass alle Daten auf eine vergleichbare Skala gebracht werden.
Die Datenaugmentation ist ein weiterer wesentlicher Schritt für Deep Learning Modelle, insbesondere wenn die verfügbaren Daten begrenzt sind. Durch die künstliche Erweiterung des Datensatzes kann die Modellleistung verbessert werden, indem Verzerrungen, Rotationen oder andere Transformationen auf die bereits vorhandenen Daten angewendet werden.
Auswahl des geeigneten Modells und der Hyperparameter
Bei der Implementierung von Deep Learning Modellen ist die Auswahl des geeigneten Modells und der Hyperparameter entscheidend für die Leistung und den Erfolg des Modells. Es gibt eine Vielzahl von verschiedenen Deep Learning Modellen wie Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs) und Deep Belief Networks (DBNs), die je nach Art der Daten und des Problems gewählt werden können.
Zusätzlich zur Auswahl des Modells sind die Hyperparameter, wie die Lernrate, die Anzahl der Schichten und Neuronen, die Dropout-Rate und der Regularisierungsparameter, von entscheidender Bedeutung. Diese Hyperparameter können experimentell optimiert werden, um die beste Leistung des Modells zu erzielen. Hierbei können Techniken wie das Grid-Search-Verfahren oder Bayes'sche Optimierung eingesetzt werden.
Zusätzliche Schritte zur Modellverbesserung
Um die Leistung eines Deep Learning Modells weiter zu verbessern, gibt es verschiedene zusätzliche Schritte, die unternommen werden können. Eine Möglichkeit besteht darin, das Modell durch Transferlernen zu initialisieren. Dies beinhaltet die Verwendung eines bereits trainierten Modells als Ausgangspunkt und das Anpassen an die spezifische Aufgabe oder den spezifischen Datensatz.
Ein weiterer Ansatz zur Leistungssteigerung besteht darin, Ensembles von Modellen zu verwenden. Indem mehrere Modelle kombiniert werden, können mögliche Fehler und Schwächen verringert und die Gesamtleistung erhöht werden. Dies kann durch verschiedene Techniken wie Bootstrap-Aggregierung (Bagging) oder Vorhersageaggregation (Stacking) erreicht werden.
Überwachung der Modellleistung und Fehleranalyse
Es ist wichtig, die Leistung des Deep Learning Modells während des Trainings und der Evaluation zu überwachen. Dies kann durch die Beobachtung von Metriken wie Genauigkeit, Precision, Recall und F1-Score erfolgen. Die Überwachung dieser Metriken gibt Aufschluss darüber, wie gut das Modell auf bestimmte Klassen oder Probleme reagiert.
Darüber hinaus ist die Fehleranalyse ein wichtiger Schritt bei der Verbesserung eines Deep Learning Modells.
Durch die Analyse der Fehler kann festgestellt werden, welche Arten von Fehlern das Modell macht und welche Muster oder Merkmale zu diesen Fehlern führen. Dies ermöglicht es, das Modell gezielt zu optimieren und die spezifischen Schwachstellen anzusprechen.
Ressourcenoptimierung und Hardwarebeschränkungen
Deep Learning Modelle sind computationally intensive und erfordern in der Regel leistungsstarke Hardware wie GPUs (Graphics Processing Units). Um den Ressourcenbedarf zu reduzieren und die Trainingszeit zu verkürzen, kann die Modellgröße durch Techniken wie Gewichtsquantisierung oder Modellkomprimierung reduziert werden.
Darüber hinaus kann die Verwendung von Cloud-basierten Diensten wie Amazon Web Services (AWS) oder Google Cloud Platform (GCP) eine effiziente Möglichkeit sein, die Skalierbarkeit und Flexibilität von Deep Learning Modellen zu gewährleisten. Diese Ressourcen können gegen eine Gebühr gemietet werden, was eine kosteneffiziente Lösung sein kann, insbesondere für kleine Unternehmen oder Organisationen mit begrenztem Budget.
Berücksichtigung von Ethik und Datenschutz
Bei der Verwendung von Deep Learning Modellen ist es wichtig, ethische Aspekte und den Schutz der Privatsphäre zu berücksichtigen. Es ist wichtig sicherzustellen, dass die verwendeten Daten fair und repräsentativ sind und keine diskriminierenden oder voreingenommenen Muster enthalten.
Darüber hinaus sollten Maßnahmen ergriffen werden, um den Schutz der Privatsphäre der Personen zu gewährleisten, deren Daten verwendet werden. Dies kann die Anonymisierung von Daten, die Einholung von Zustimmungen und die Verwendung von Sicherheitsmaßnahmen zur Verhinderung von Datenlecks umfassen.
Zusammenfassung
Deep Learning hat das Potenzial, die Art und Weise zu revolutionieren, wie Probleme des maschinellen Lernens gelöst werden. Indem man die praktischen Tipps, die in diesem Artikel behandelt wurden, berücksichtigt, kann man die Chancen auf erfolgreiche Anwendungen von Deep Learning Modellen erhöhen.
Die Daten sollten vor der Verwendung sorgfältig vorbereitet und verarbeitet werden, um eine hohe Datenqualität sicherzustellen. Die Auswahl des geeigneten Modells und der Hyperparameter ist ebenfalls entscheidend und kann die Leistung des Modells maßgeblich beeinflussen. Zusätzliche Schritte zur Modellverbesserung, Überwachung der Modellleistung und Fehleranalyse, Ressourcenoptimierung und Berücksichtigung ethischer Aspekte sind ebenfalls wichtig, um optimale Ergebnisse zu erzielen.
Es ist wichtig, sich immer bewusst zu sein, dass Deep Learning ein sich ständig weiterentwickelndes Feld ist und dass eine kontinuierliche Weiterbildung und Anpassung unerlässlich sind. Durch die Anwendung dieser praktischen Tipps können die Grenzen des Deep Learning nach und nach erweitert werden.
Zukunftsaussichten von Deep Learning
Deep Learning ist ein Bereich des maschinellen Lernens, der in den letzten Jahren erhebliche Fortschritte gemacht hat. Es hat sich gezeigt, dass Deep Learning-Modelle in der Lage sind, komplexe Aufgaben zu lösen und dabei menschenähnliche Leistungen zu erbringen. Die Zukunftsaussichten für Deep Learning sind vielversprechend und werden hier ausführlich diskutiert.
Fortschritte in der Hardware
Ein entscheidender Faktor für die Weiterentwicklung von Deep Learning ist die Verbesserung der Hardware. Aktuelle Fortschritte in der Chip-Technologie haben zu leistungsfähigeren Grafikverarbeitungseinheiten (GPUs) und spezialisierten Deep Learning-Prozessoren geführt. Diese Hardware ermöglicht es, anspruchsvolle Deep Learning-Algorithmen schneller und effizienter auszuführen.
Diese Entwicklung wird voraussichtlich weitergehen, da Unternehmen wie IBM, Google und Nvidia weiterhin in die Entwicklung von maßgeschneiderter Hardware für Deep Learning investieren. Zukünftige Innovationen könnten die Leistungsfähigkeit von Deep Learning weiter verbessern und es ermöglichen, noch komplexere Probleme zu lösen.
Fortschritte im Training großer Modelle
Deep Learning-Modelle sind bekannt für ihre Fähigkeit, aus großen Mengen an Daten zu lernen.
In der Vergangenheit war es jedoch oft eine Herausforderung, diese Modelle effizient zu trainieren. Das Training eines Deep Learning-Modells erfordert in der Regel große Rechenressourcen und lange Trainingszeiten.
In Zukunft könnte jedoch die Entwicklung neuer und verbesserte Algorithmen, parallele und verteilte Verarbeitungstechniken sowie Fortschritte in der Hardware die Effizienz des Trainingsprozesses erheblich steigern. Dies würde es Forschern und Entwicklern ermöglichen, schneller bessere Modelle zu trainieren und neue Anwendungen für Deep Learning zu explorieren.
Anwendungsbereiche
Deep Learning hat bereits in einer Vielzahl von Anwendungsbereichen beeindruckende Ergebnisse erzielt, darunter Bilderkennung, Sprachverarbeitung und autonomes Fahren. Die Zukunftsaussichten für Deep Learning sind vielversprechend, da es weiterhin in immer mehr Branchen und Disziplinen eingesetzt wird.
Ein vielversprechender Anwendungsbereich ist die Medizin. Deep Learning kann dazu beitragen, medizinische Diagnosen zu verbessern, indem es große Mengen an Patientendaten analysiert und Muster erkennt, die für menschliche Ärzte schwer zu erkennen sind. Es könnte auch bei der personalisierten Medizin und der Entwicklung neuer Medikamente helfen, indem es die Suche nach potenziellen Wirkstoffen beschleunigt.
Auch in der Robotik und der Automatisierung gibt es viel Potenzial für Deep Learning. Durch den Einsatz von Deep Learning-Modellen können Roboter komplexe Aufgaben erlernen und autonom durchführen. Dies könnte zu Fortschritten in der Industrieautomation und der Entwicklung von autonomen Fahrzeugen führen.
Ethische und soziale Implikationen
Die Zukunft von Deep Learning wirft auch Fragen nach ethischen und sozialen Implikationen auf. Die Verwendung von Deep Learning erfordert den Zugriff auf große Mengen an Daten, was Datenschutz- und ethische Bedenken hervorruft. Darüber hinaus besteht die Gefahr von automatisierter Diskriminierung, wenn Deep Learning-Modelle auf unfaire Weise vorgehen oder Vorurteile abbilden.
Es ist daher wichtig, dass Forscher, Entwickler und Regulierungsbehörden diese Fragen angehen und sich für eine verantwortungsvolle Entwicklung und Anwendung von Deep Learning einsetzen. Durch die Sensibilisierung für diese Probleme und die Einführung von ethischen Richtlinien kann Deep Learning zu einer positiven und ausgewogenen Gesellschaft beitragen.
Zusammenfassung
Insgesamt sind die Zukunftsaussichten für Deep Learning vielversprechend. Fortschritte in der Hardware, Trainingstechniken und Anwendungsbereichen ermöglichen es Deep Learning-Modellen, immer komplexere Aufgaben zu bewältigen und menschenähnliche Leistungen zu erbringen. Es ist jedoch wichtig, die ethischen und sozialen Implikationen zu berücksichtigen und sicherzustellen, dass Deep Learning verantwortungsvoll eingesetzt wird. Durch die fortlaufende Forschung und den Dialog zwischen Industrie, Akademie und Regierung können wir das volle Potenzial von Deep Learning ausschöpfen und neue innovative Lösungen für eine Vielzahl von Herausforderungen finden.
Zusammenfassung
Deep Learning ist ein Teilgebiet des maschinellen Lernens, das darauf abzielt, neuronale Netzwerke aufzubauen und zu trainieren, um komplexe Aufgaben zu lösen. Es verwendet einen hierarchischen Ansatz, bei dem verschiedene Schichten von Neuronen verwendet werden, um relevante Merkmale in den Eingabedaten zu extrahieren. Diese hierarchische Struktur ermöglicht es Deep-Learning-Modellen, hochkomplexe Funktionen zu erlernen und zu generalisieren.
Die Funktionsweise von Deep Learning basiert auf der Verwendung von sogenannten künstlichen neuronalen Netzwerken (KNN). Ein KNN besteht aus verschiedenen Schichten von Neuronen, die miteinander verbunden sind. Jedes Neuron in einer Schicht erhält Eingabesignale von Neuronen in der vorherigen Schicht und produziert eine Ausgabe, die an Neuronen in der nächsten Schicht weitergegeben wird. Auf diese Weise wird der Informationsfluss durch das Netzwerk ermöglicht.
Die Struktur eines KNN variiert je nach Anwendung und kann eine unterschiedliche Anzahl von Schichten und Neuronen pro Schicht aufweisen. In der Regel besteht ein KNN aus einer Eingabeschicht, einer oder mehreren verdeckten Schichten und einer Ausgabeschicht. Beim Training künstlicher neuronaler Netzwerke wird eine große Menge an Eingabedaten verwendet, um die Gewichte der Neuronen zu optimieren und das Netzwerk an die Aufgabe anzupassen.
Der Trainingsprozess von Deep-Learning-Modellen erfolgt in der Regel durch das sogenannte Backpropagation-Verfahren. Hierbei wird in einem ersten Schritt eine Vorwärtsberechnung durch das Netzwerk durchgeführt, wobei die Ausgaben des Netzwerks für eine bestimmte Eingabe berechnet werden. Anschließend wird der Fehler zwischen den Ausgaben des Netzwerks und den tatsächlichen Ausgabewerten berechnet. Verwendet man beispielsweise das Quadrat des Fehlers als Kostenfunktion, so kann dieser durch Optimierungsverfahren wie dem Gradientenabstiegsverfahren minimiert werden.
Deep Learning hat in den letzten Jahren bemerkenswerte Erfolge in einer Vielzahl von Anwendungen erzielt, darunter Bilderkennung, Spracherkennung, maschinelle Übersetzung und autonomes Fahren. In der Bilderkennung konnten Deep-Learning-Modelle menschenähnliche Genauigkeit bei der Erkennung und Klassifizierung von Objekten in Bildern erreichen. In der Spracherkennung haben Deep-Learning-Modelle herkömmliche Ansätze übertroffen und sind heute in vielen Sprachassistenz-Systemen wie Siri und Google Assistant integriert.
Trotz dieser Erfolge gibt es jedoch auch Grenzen für Deep Learning. Eine der Hauptprobleme ist die hohe Anzahl an Trainingsdaten, die für die erfolgreiche Anpassung eines tiefen neuronalen Netzwerks erforderlich sind. Insbesondere bei komplexen Aufgaben können die benötigten Trainingsdaten sehr groß sein, was die Anwendung von Deep Learning auf bestimmte Anwendungen einschränken kann.
Eine weitere Herausforderung ist die Interpretierbarkeit von tiefen neuronalen Netzwerken. Aufgrund ihrer komplexen Struktur und des Trainingsprozesses können Deep-Learning-Modelle schwierig zu verstehen und zu interpretieren sein. Dies kann ein Problem in Situationen sein, in denen Erklärungen oder begründete Entscheidungen erforderlich sind.
Ein weiteres Limitation von Deep Learning ist die Notwendigkeit von leistungsstarken Computerressourcen. Aufgrund der hohen Anzahl von Neuronen und Schichten können tiefe neuronale Netzwerke viel Rechenleistung erfordern, um effizient zu operieren. Dies kann die Anwendung von Deep Learning in ressourcenbeschränkten Umgebungen einschränken.
In Anbetracht dieser Herausforderungen laufen jedoch umfangreiche Forschungsstudien, die darauf abzielen, die Grenzen von Deep Learning zu überwinden und die Leistungsfähigkeit und Anwendungsbereiche von Deep-Learning-Modellen zu erweitern. Es werden neue Architekturen und Strategien entwickelt, um die Anforderungen an Trainingsdaten zu reduzieren, die Interpretierbarkeit zu verbessern und die Rechenressourcen zu optimieren.
Zusammenfassend lässt sich sagen, dass Deep Learning ein leistungsstarkes Werkzeug ist, um komplexe Aufgaben in verschiedenen Anwendungsgebieten zu lösen. Es basiert auf der Verwendung von künstlichen neuronalen Netzwerken und ermöglicht es, hochkomplexe Funktionen zu erlernen. Allerdings gibt es auch Grenzen für Deep Learning, darunter die Anforderungen an Trainingsdaten, die Interpretierbarkeit und die Rechenressourcen. Dennoch wird intensiv an der Überwindung dieser Grenzen geforscht, um die Leistungsfähigkeit und Anwendungsbereiche von Deep-Learning-Modellen weiter zu verbessern.
0 notes
Text
Die Magie zum Leben erwecken: Erstellung interaktiver AR-Inhalte
Die Magie zum Leben erwecken: Erstellung interaktiver AR-Inhalte
Die Erstellung interaktiver Augmented Reality (AR)-Inhalte ermöglicht es Entwicklern, die Magie der AR zum Leben zu erwecken und beeindruckende digitale Erlebnisse zu schaffen. In diesem Artikel erfahren Sie, wie Sie interaktive AR-Inhalte erstellen können, die Ihre Benutzer faszinieren und begeistern.
1. Auswahl der richtigen AR-Entwicklungsumgebung
Um interaktive AR-Inhalte zu erstellen, benötigen Sie eine geeignete AR-Entwicklungsumgebung. Es gibt verschiedene Tools und Plattformen wie Unity, Unreal Engine, ARKit, ARCore und Vuforia, die Ihnen dabei helfen, hochwertige AR-Erlebnisse zu entwickeln. Wählen Sie diejenige aus, die Ihren Anforderungen am besten entspricht und Ihnen die erforderlichen Funktionen bietet.
2. Erstellung von 3D-Modellen und Animationen
Um AR-Inhalte interaktiv zu gestalten, müssen Sie 3D-Modelle und Animationen erstellen. Verwenden Sie 3D-Modellierungssoftware wie Blender, Maya oder 3ds Max, um Objekte, Charaktere und Szenen zu erstellen. Anschließend können Sie diese Modelle in Ihre AR-Entwicklungsumgebung importieren und mit Animationen versehen, um interaktive Aktionen und Bewegungen zu ermöglichen.
3. Implementierung von Benutzerinteraktionen
Interaktive AR-Inhalte erfordern Benutzerinteraktionen. Sie können verschiedene Interaktionsmöglichkeiten wie Touch-Gesten, Bewegungserkennung, Spracherkennung oder Objekterkennung implementieren. Nutzen Sie die Funktionen Ihrer AR-Entwicklungsumgebung, um diese Interaktionen zu programmieren und den Benutzern ein immersives AR-Erlebnis zu bieten.
4. Integration von Multimedia-Inhalten
Um die AR-Inhalte noch interaktiver zu gestalten, können Sie Multimedia-Inhalte integrieren. Dies umfasst Soundeffekte, Hintergrundmusik, Sprachausgabe oder visuelle Effekte. Nutzen Sie die Möglichkeiten Ihrer AR-Entwicklungsumgebung, um diese Inhalte nahtlos in Ihre AR-Anwendung einzubinden und die immersive Erfahrung zu verstärken.
5. Testen und Optimieren
Nach der Erstellung interaktiver AR-Inhalte ist es wichtig, diese gründlich zu testen und zu optimieren. Stellen Sie sicher, dass alle Interaktionen reibungslos funktionieren und die AR-Elemente korrekt platziert werden. Nehmen Sie gegebenenfalls Anpassungen vor, um ein reibungsloses und beeindruckendes Benutzererlebnis sicherzustellen.
6. Bereitstellung der AR-Inhalte
Sobald Ihre interaktiven AR-Inhalte fertiggestellt sind, können Sie sie auf verschiedenen Plattformen bereitstellen. Dies umfasst mobile Geräte wie Smartphones und Tablets, AR-Brillen und Headsets oder sogar Web-AR-Anwendungen. Wählen Sie die Plattformen aus, die Ihre Zielgruppe am besten erreichen und implementieren Sie die erforderlichen Bereitstellungsschritte für eine reibungslose Erfahrung.
Haben Sie Fragen zur Erstellung interaktiver AR-Inhalte? Hinterlassen Sie einen Kommentar und lassen Sie es uns wissen! Wir helfen Ihnen gerne weiter. Wenn Ihnen dieser Artikel gefallen hat, teilen Sie ihn bitte mit anderen, die Interesse an der Erstellung faszinierender AR-Inhalte haben.
Tags and categories: Entwickler
via MRT Media GmbH https://bit.ly/3MIzqZC
June 01, 2023 at 11:53AM
0 notes
Last Seen Blogs

supermonicalove
princess piper

xwoaini
Deportation Asylum Criminal Conviction Naturalization Lawyer

duplicitywrites
the people's prince ass: tom's ass

wickedweebachu
The_brokenangel

sandyhopesstuff
hope's rambles