#power bi jujuy
Text
[PowerBi] Catálgo de diseños para reportes
Hace tiempo he escrito un artículo para tener presente que la UI puede manipularse y mejorarse por herramientas terceras. Ciertamente, no es algo para tomar a la ligera, lleva su tiempo aporta un enorme valor para el usuario final.
En este artículo reflejé una, de muchas formas, que podemos usar para construir fondos para nuestros informes de PowerBi. Usando PowerPoint, podemos delimitar colores, sombras, espacios, alineamientos, etc. Las prestaciones de manipulación de formas y colores es mayor que lo que PowerBi nos represente. Sin duda, podemos hacer mucho en el canva de PowerBi, pero... ¿a que precio.? Tal vez generar un buen fondo nos tome el agregado de 15 formas. No es lo mismo que el fondo sea una imagen a que PowerBi renderice 15 elementos antes de siquiera pensar en sus números.
Como regalo para este mes de mi cumpleaños, quise entregar una nueva sección de LaDataWeb inspirada en Temas, Plantillas, Themes, Templates o como quieran llamarle.
Me alegra mucho presentarles este nuevo espacio "Temas". En él encontraran un pequeño catálogo de ejemplos UIUX para tableros que nos ayudaría a inspirar nuevas ideas.

Así mismo incorporé la posibilidad de descargarlo en máximo detalle, puesto que el .zip incluye:
Archivo.pbix
Imagen vácio de fondo
Imagen de Dashboard ejemplo de como desarrollar encima del fondo
Tema.json
Con esto serán capaces de llevar más comodamente los tableros que quieran hacer igual o guiarse a partir de uno de los ejemplos.
Hay también un enlace a GitHub en caso que quieran aportar algunos ustedes como contribuyentes de este catálogo.
Link al sitio: https://www.ladataweb.com.ar/templates.html
¡Espero que lo disfruten y traiga nuevas ideas para sus proyectos!
#storytelling#dataviz#datavisual#uxui#powerbi#power bi#ladataweb#power bi cordoba#power bi jujuy#power bi argentina
1 note
·
View note
Text
[PowerBi][PowerAutomate] Enviar notificación de una DAX Query
Las alertas en Power Bi son una herramienta que nos permite hacer envío de un correo o notificación de celular en caso de que un número realice una condición. Son muy útiles, pero se quedan cortas.
Si quisieramos conocer más que un número que llega con una regla, sino fijamente estar informado de uno o más números y porque no una pequeña tabla de valores, solo podríamos hacerlo con una suscripción. Muchas opciones que no llegan a algo tan simple como prender la PC y ver por Teams como van X valores bajo diversas condiciones.
En este artículo veremos como configurar envio de correo o mensaje de Teams del resultado de una consulta DAX en Power Automate.
Para poder consultar un modelo semántico de datos de Power Bi Service necesitamos tener acceso al dataset. Podemos realizarlo de diversas maneras puesto que en realidad es un request que nos probee la Power Bi Rest API.
https://learn.microsoft.com/en-us/rest/api/power-bi/datasets/execute-queries-in-group
Si bien nosotros vamos a realizarlo por Power Automate, tranquilamente podría ser una Azure Function u otro servicio que nos permita realizar tiros a la API.
Lo primero que vamos a hacer es probar que nuestra consulta devuelva el dato esperado. Para ello podemos utilizar DAX Studio que nos permite ejecutar consulta contra modelos semánticos tabulares. Si tenemos nuestro dataset en capacidad dedicada, podríamos conectarlo directamente. Si estamos usando PRO, podemos abrir PowerBi Desktop de nuestro modelo original (pbix) y conectarlo a DAX Studio.
En mi caso estoy buscando que todas las mañanas se me informe como van las ventas de este año actual. Entonces veo a ejecutar una medida que traiga una sola fila y una sola columna según un filtro en el formato deseado. La consulta DAX se vería algo así:
EVALUATE
SUMMARIZE(
FILTER('Orders',
RELATED('Tablecalendar'[Year])= YEAR(NOW()))
, "Venta", FORMAT( SUM(Orders[Sales]), "#,0.00")
)
Voy a sumar las ventas de mi tabla de hecho y filtrarlas por la columna de la tabla calendario relacionada contra el año de la fecha actual, especificando el formato de separador de miles y dos decimales.
Conociendo mi valor, puedo abrir Power Automate y crear un flujo que sea calendarizado/recurrente.
Vamos a buscar la acción "Run a query against a dataset". Este cumple la misma función del enlace de API antes mencionado. Para interpretar su resultado de tabla vamos a realizar una acción que crea un csv a partir de una tabla. Así tendremos una tabla y su salida para delimitar que queremos enviar en notificación.
El paso de consulta a PowerBi nos permite ver las áreas de trabajo, sus datasets y un espacio para pegar la consulta. Para la creación de la tabla solo pedirle la primera fila porque espero un único valor
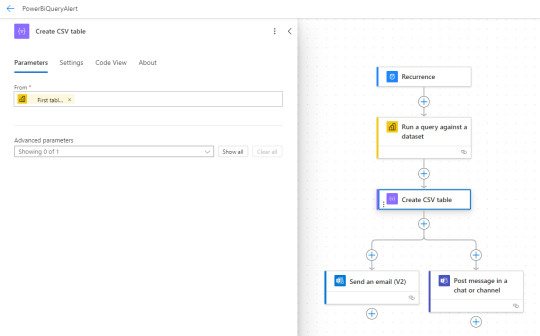
NOTA: En caso de querer construir una tabla más compleja, puede asesorarse en la doc o el foro de Power Automate.
Finalmente, podemos enviar por correo o en un mensaje de Teams a un grupo o canal de manera que informemos a quienes pertine sobre las ventas. Solo debemos agregar al cuerpo el "Output" que sería la salida dinámica de Create CSV table.
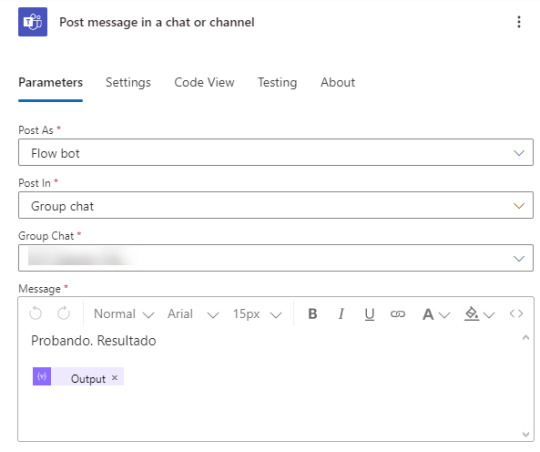
De este modo podemos alertarnos o notificarnos cualquier resultado de un modelo de datos a partir de una consulta DAX.
NOTA: todos los componentes usados en power automate NO son premium. Podemos construirlos con la versión free de office 365.
Espero que esto les sea de utilidad para informarse por el medio deseado los números deseados sin depender del correo o de la notificación de la app.
#power bi#powerbi#power automate#powerautomate#power platform#power bi alerts#Power bi tips#power bi tutorial#power bi training#power bi argentina#power bi cordoba#Power bi jujuy#power bi latam
0 notes
Text
Seteo PowerBi Rest API por primera vez
En múltiples oportunidades me encuentro con problemas que se solucionarían sencillamente con la Power Bi Rest API. Siempre la suelo recomendar pero cada vez me encuentro más con usuarios que quedan un poco asustados de la interacción con la API.
Éste artículo nos va a acompañar a setear las configuraciones necesarias para poder autenticar y comenzar a utilizar la Power Bi Rest API con Python usando SimplePBI pero recordando que el seteo es independiente del lenguaje de programación. Cualquier lenguaje podría usarse una vez listas las credenciales.
¿Qué es una API?
Como quien repasa, las API son mecanismos que permiten a dos componentes de software comunicarse entre sí mediante un conjunto de definiciones y protocolo. Dicho de otro modo, queremos escribir un código que se comunique con Power Bi Service. La API es el puente que nos permite establecer esta comunicación. Ahora bien, el punte esta vigilado por protocolos de seguridad. Por esta razón, necesitamos una credencial de acceso para que nuestra vía de comunicación pueda funcionar.
Toda API tiene una documentación sobre los requests y categorias para utilizarla. A continuación el enlace de la Power Bi Rest API Doc con sus categorías según permisos:
https://learn.microsoft.com/en-us/rest/api/power-bi/
Service Principal vs Usuario profesional
Las credenciales pueden ser de dos tipos. Por un lado, puede estar bajo el nombre de una Cuenta Profesional de Microsoft. Un modo que permite delimtiar el usuario específico que accedió pero con la desventaja que queda atado al usuario y si el usuario deja la institución, otra persona no puede usar su credencial a menos que sea modificada. Por otro lado, puede estar bajo el acceso de una gran Clave/Key que de acceso. Esta credencial permite a cualquier usuario que la porte pueda usar la vía de comunicación. Suele ser la opción más elegida para establecer desarrollos puesto que son independientes de una persona (Service Principal).
IMPORTANTE: Tengamos presente que si queremos usar Service Principal, los permisos en Power Bi Service quedan atados a la aplicación. Esto significa que cuando quiera "Ver mis Áreas de Trabajo", solo veremos las áreas que tengan a la Aplicación registrada como miembro.
Registrar una App en Azure
Las aplicaciones de Azure son las credenciales que nos permiten cruzar determinados puentes o mejor dicho comunicarnos con distintos servicios dentro de la nube Microsoft. Para registrar una nueva App vamos a ingresar al Portal de Azure (https://www.portal.azure.com)
Dentro del servicio Entra ID (antes llamado Active Directory) podemos encontrar un menú de Aplicaciones Registradas donde podremos poner "Nuevo Registro"

El proceso para usar la API es muy simple, solo escribiendo el nombre bastará. Si bien, hay más opciones de configuración, no serán necesarias para hacer consultas con la Power Bi Rest API
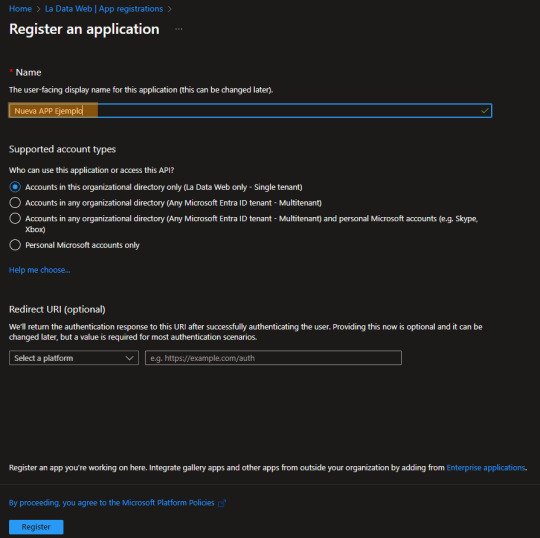
Ya creada, veamos algunos valores importantes para usarlar:

TenantID o ID de Organización: Primero e indispensable puesto que sería única por institución. Esto significa que cualquier puente de comunicación a cualquier servicio necesita especificar el mismo ID.
App o Client ID: este es el identificatorio de la credencial. También pensado o usado como Usuario de una aplicación.
Paso siguiente podemos configurar un poco más de detalle. Ya tendríamos la credencial para atravesar el puente, ahora tenemos que delimitar a que tenemos acceso de dicho lado del puente. Con esto me refiero a ¿Puedo ver los datasets?, ¿Puedo configuar un refresh?, ¿Puedo ver mis areas de trabajo?, etc.
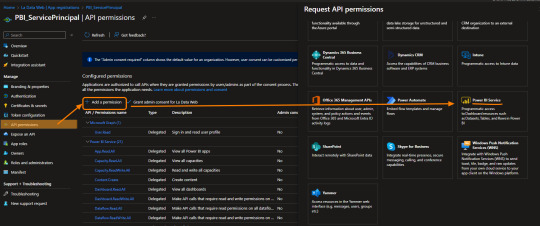
Vamos a nutrirnos de los permisos delegados que nos permiten elegir lo que queremos ver.
NOTA: Los permisos de aplicación son los que permiten embeber Power Bi

En este ejemplo le damos permiso a leer y escribir sobre Paneles/Dashboards. Esto significa que podríamos comunicarnos con toda la sección de Paneles de la API que esta en su documentación.
Creada y con permisos, la credencial pertenece a un Usuario Owner para utilizarla. Si quisieramos cambiar esto y usarla con Clave (Service Principal) solo bastaría generarla.

Tengamos presente que las claves tienen fecha de expiración por seguridad y que solo nos muestra su valor una vez para ser copiadas. Cuando salgamos del sitio no podremos volver a ver jamás la clave. La nomenclatura con la que nos podemos referir a la clave es "Secreto".
A partir de ese momento nuestra clave puede funcionar como contraseña de nuestros accesos y tendremos todo listo para que nuestro código hable con el de Power Bi Service.
Autenticación con Python y SimplePBI
Para autenticar contra la Power Bi Rest API necesitamos la dirección de logueo y algunos varios argumentos que pongan a prueba la validez de la credencial que enviamos. Si todo esta correcto obtendremos un Bearer Token de la respuesta que será como un pulcera VIP de pase libre a algunos requests. SimplePBI, la librería de Python para usar la Power Bi Rest API, nos ayudará que ese proceso sea muy sencillo.
from simplepbi import token
obj_tok = token.Token(tenant_id, app_client_id, username=None, password=None, app_secret_key, use_service_principal=True)
Dependiendo si seteamos en False o True el último argumento, autenticaríamos con Service Principal o una Cuenta Profesional de Microsoft. El ejemplo está seteado con Service Principal. Simplemente importando el objeto Token y enviando los parámetros que explicamos antes como Tenant, App Id y Secret nos bastaría para comunicarnos.
Para conocer como continuar interactuando con cada una de las categorías que vimos en la documentación de la API puede leer más sobre la librería SimplePBI en su documentación pública https://github.com/ladataweb/SimplePBI/tree/main/
#power bi#powerbi#power bi argentina#power bi cordoba#power bi jujuy#power bi tutorial#power bi training#power bi tips#ladataweb#Power bi service#power bi rest api#simplepbi#python power bi rest api#power bi python
0 notes
Text
Origen web para evitar gateway PowerBi y Azure Functions
Existen diversos escenarios donde PowerBi nos va a exigir un gateway para actualizar nuestra información. A veces es muy necesario y tiene sentido, pero otras veces no y resulta hasta molesto.
Puede que haya muchos escenarios más que los que voy a mencionar pero normalmente al escrapear un sitio web (funcion Web.Pages de power query) se exige un gateway. Tal vez tenes alguna operación tan compleja que se te ocurre usar Python para resolverla porque esta dentro de Power Bi, pero con eso también te exige Gateway.
Este artículo mostrará como podemos usar Azure Functions para realizar una operación simple con Python para luego leerlo desde PowerBi como un simple Get Request de API.
Primero que nada un poco de teoría. Existen escenarios web los cuales requeiren de Gateway para su tratamiento. Aun si estamos en power query online (dataflows) necesitaremos uno. Hay tres funciones cláscias que son de interés y funcionan distinto. WebContent, WebPages y WebContentBrowser. Si quieren conocer la diferencia y entender cual pide gateway y cual no, pueden leer la siguiente doc: https://learn.microsoft.com/en-us/power-query/connectors/web/web-troubleshoot
Me gustaría comenzar aclarando que no voy a hacer una introducción a Azure Functions. No voy a explicar que es, cómo funciona y cómo setear el entorno. Para eso ya hay excelentes videos en internet o podemos leer más en la siguiente doc de microsoft:
https://learn.microsoft.com/es-es/azure/azure-functions/create-first-function-vs-code-python?pivots=python-mode-configuration
Para este post necesitamos conocimientos previos en Python básico y Visual Studio Code. Asumiendo que ya tenemos el entorno seteado con las extensiones de Visual Studio code, vamos a comenzar con un ejemplo sencillo conectando a una API. Ya logueados en el apartado de Azure y con visibilidad a nuestra suscripción, vamos a crear una Function App. Podemos pensarlo como el servidor de procesamiento de muchas Azure Functions. En ese espacio podemos tener muchas functions, pensemos a cada una como un request.
Al momento de crearla tenemos 4 pasos
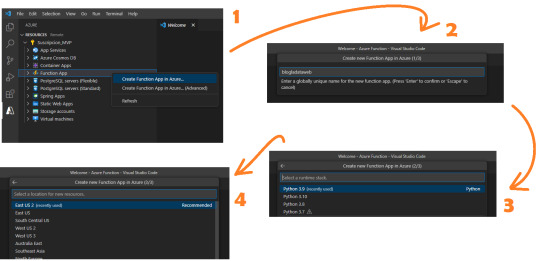
Ese nombre será participe de la URL de la API que estamos generando.
Ahora podremos crear la función. Se almacenará en la carpeta que tengamos apuntando el Visual Studio Code. Clickeamos el rayito para crear una función dentro de la Function App

La aplicación creada se verá así:
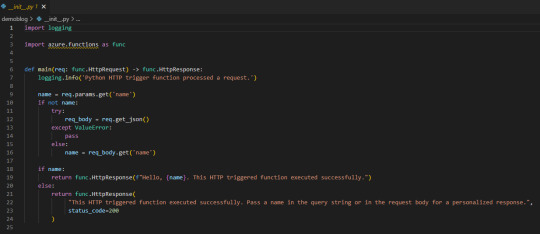
Lo que necesitamos saber es que tenemos una función main donde se ejecutará el código principal. Luego depende si llamamos a la función con get o post si podemos capturar items de parametros de url o body. Eso nos ayudaría a incrementar la seguridad puesto que sin los parametros correctos o autenticación no podríamos obtener la respuesta. A modo de ejemplo vamos a hacer una simple lógica para que la url retorne el resultado cada vez que sea llamada sin necesidad de nada más puesto que considero que no es sensible la data del nombre de los workspaces en mi tenant de demo.
Veamos que simple es escribir código dentro de main devolviendo un dict o json en el return bajo el status_code deseado. Podemos aprovecharnos de los mensajes para ser claros en fallas para recibirlas en Power Bi.

Usando SimplePBI para obtener grupos, pueden ver que simplemente generamos token, creamos objeto de grupo (workspaces) y llamamos a los workspaces que nuestro Service Principal puede ver.
Luego agregue al return una aclaración adicional para cuando lo que queremos devolver no es un “texto” literal sino un dict o json que es el “mimetype”.
NOTA: Si no sabes que es SimplePBI podes pasar por aqui.
IMPORTANTE: aclaro que tenemos un secret expuesto en este código, lo mejor para una azure function así sería usar un Azure KeyVault a nuestras contraseñas y secretos para que no queden expuestos.
Si vamos a usar una librería importada tendremos que buscar el archivo requirements.txt en el panel de recursos y agregarla. Yo lo hice para SimplePBI.
Si necesitamos utilizar pandas para tomar datos de un origen estructurado, podemos utilizar “ DataFrame.to_dict(orient="records") ” en el json.dumps del return para convertir nuestro frame al formato de mimetype json.
Get data
Mucho sobre python y funciones, vamos a PowerBi Desktop a conectarnos. Usaremos el conector web para traer la información con credenciales anónimas.
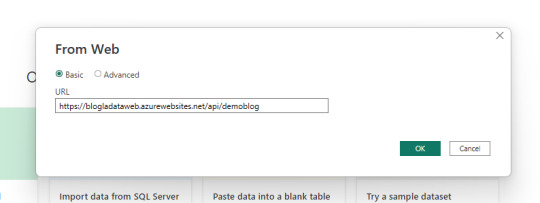
Dependiendo como orientamos nuestro json devuelto en la API que nos generamos en Azure Functions vamos a tener que efectuar transformaciones en power query. En este caso la devuelta por SimplePBI es muy uniforme y el motor practicamente lo resuelve solo.
Veamos como queda:
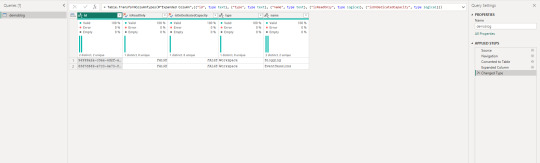
Ahora tenemos nuestra data cargada en Power Bi usando python sin necesidad de un gateway personal. Ya podemos publicar nuestro informe al servicio de power bi y configurar las credenciales como anónimas.
ACLARACIÓN: las Azure Functions tiene un límte de uso (timeout) en 5 minutos. Nuestra ejecución no puede durar más de eso o fallaría y nuestro propósito quedaría perdido.
Conclusión
Esta metodología puede ayudarnos a dar más velocidad a pequeños desarrollos, scrappings u origenes cloud complicados que PowerBi no tenga connector sin driver (ejemplo: oracle o mysql). Con una Azure Function construir rápido y fácilmente una API que responda. Para aumentar la seguridad es necesario utilizar Azure KeyVaults en nuestro código y en caso de necesitar disponibilizar data más sensible, lo mejor sería pedir un parámetro o body con alguna clase de key (que puede ser inventada por nosotros) para que no todo quede sobre una URL pública. Espero que este ejemplo les despierte nuevas ideas.
#powerbi#power bi#power bi desktop#power bi python#python power bi#azure functions#Azure functions python#power bi tips#power bi argentina#power bi jujuy#power bi cordoba#power bi tutorial#power bi training#azure functions power bi#ladataweb
0 notes
Text
Nueva Suscripción a LaDataWeb
Muchos sitios y blogs contienen una gran opción para estar al día con lo que sucede en su red. La nuestra se lo debía a la comunidad y hoy se cumple esa feature.
Nos emociona mucho contarles que en el lanzamiento de mejoras estéticas de sitio web hemos incluido una nueva opción, una para "Suscribirse" a LaDataWeb.
Lee más para conocer como hacerlo y que incluye.
Suscripción
Nuestra suscripción no es un login sino más bien un newsletter mensual. Una oportunidad para estar al día con los lanzamientos de la comunidad de LaDataWeb y, tal vez en un futuro, la comunidad en español.
¿Como suscribirse?
Si estas navegando nuestro Blog, entonces podes encontrar botones más pequeños con flecha o abajo con el texto

El nuevo sitio cuenta con un gran botón arriba a la derecha que te pedirá un correo. Tan simple como eso.

Una vez que nos suscribamos recibiremos un correo de bienvenida para corroborar que todo salió correctamente.
¿Qué encontrare en el newsletter mensual?
Nuestro correo se encargará de transmitir las siguientes novedades:
Últimos dos artículos del blog
Un artículo antiguo random
Release notes de la última actualización de SimplePBI
Descripción del último Storytelling de nuestro sitio
Esperamos que encuentre el correo sencillo y fácil de leer. Si bien el texto general de las secciones y saludos están en ingles, recuerden que nuestro contenido siempre es en español ;)
#ladataweb#storytelling#power bi storytelling#simplepbi#power bi rest api python#power bi rest api#power bi español#power bi argentina#power bi cordoba#power bi jujuy
0 notes
Text
[PowerBi] Integración con AzureDevOps Git Repos
El lanzamiento de Power Bi Developer Mode durante el evento Microsoft Build está causando gran revuelo no solo por su posibilidad resguardar un proyecto de PowerBi sino también porque por primera vez tendríamos la posibilidad de que dos o más usuarios trabajen en un mismo proyecto. Esto no es trabajo concurrente instantáneo como Word Online sino más bien cada quien modificando los mismos archivos de un repositorio y logrando integrarlos al final del día.
La deuda de versionado y trabajo en equipo finalmente estaría cumplida. Según uno de los personajes más importantes del equipo, Rui Romano, aún hay mucho por hacer. Veamos que nos depara esta característica por el momento.
Vamos a iniciar asumiendo que el lector tiene un conocimiento básico de repositorios. Entienden que en un repositorio se almacenan versiones de archivos. Se pueden crear ramas/branches por persona que permita modificar archivos y luego se puedan integrar/merge para dejar una versión completa y definitiva.
Todo esto es posible gracias a la nueva característica de Power Bi Desktop que nos permite guardar como proyecto. Esto dividirá nuestro pbix en dos carpetas y un archivo:
Carpeta de <nombre del archivo>.Dataset: Una colección de archivos y carpetas que representan un conjunto de datos de Power BI. Contiene algunos de los archivos más importantes en los que es probable que trabajes, como model.bim.
Carpeta de <nombre del archivo>.Report: Una colección de archivos y carpetas que representan un informe de Power BI. El archivo más importante es "report.json", aunque durante la vista previa no se admiten modificaciones externas en este archivo.
Archivo <nombre del archivo>.pbip: El archivo PBIP contiene un enlace a una carpeta de informe. Al abrir un archivo PBIP, se abre el informe en Power Bi Desktop y el modelo correspondiente.
Entorno
Lo primero es configurar y determinar nuestro entorno para poder vincular las herramientas. Necesitamos una cuenta en Azure DevOps y un workspace con capacidad en Power Bi Service. Para que la integración sea permitida necesitamos asegurarnos que nuestra capacidad y la de la Organización de Azure DevOps estén en la misma región.
La región de una organización de Azure DevOps puede ser elegida al crearla, al igual que podemos elegir la región de una capacidad cuando creamos una premium, embedded o fabric.
En caso de utilizar capacidad PowerBi Premium Per User o Fabric Trial, no podríamos elegir la región. Sin embargo, podríamos revisar la región de nuestro PowerBi para elegir la misma en Azure DevOps
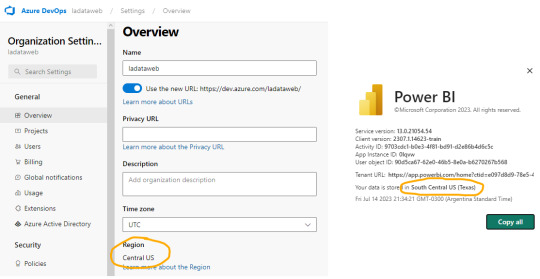
En ese caso creamos la organización de DevOps igual que nuestro PowerBi porque haremos el ejemplo con un workspace PPU.
Seteo
Dentro de Power Bi Service y el Área de trabajo con capacidad que queremos versionar iremos a la configuración. Con la misma cuenta de ambos entornos completaremos los valores de organización, proyecto, repositorio, rama y carpeta (opcional).
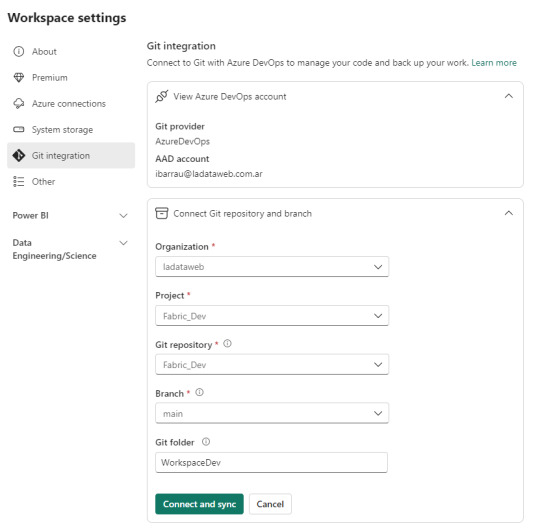
Como nuestro repositorio esta vacío, lo primero que sucederá cuando conectemos será una sincronización de todos los items del área de trabajo en el repositorio. Ahora bien, si teníamos reportes en el repositorio y en el area, tendremos un paso más para coordinar la operación deseada si pisar o integrar.
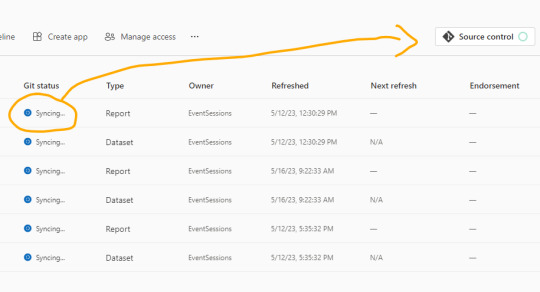
Una vez que todo tenga tilde verde y esté sincronizado, podremos ver como queda el repositorio.
En caso que ya tuvieramos informes cuando inicio el proceso, se crearán carpetas pero no el archivo .pbip que nos permitiría abrirlo con Power Bi Desktop.
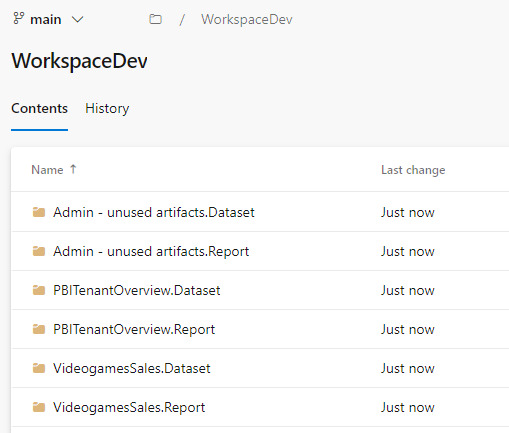
Si crearamos el informe con Power Bi Desktop y eligieramos “Guardar como proyecto” si se crearía. Entonces podríamos hacer un commit al repositorio y automáticamente se publicaría en nuestra área de trabajo.
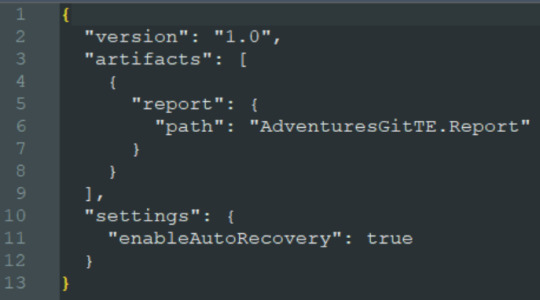
El archivo pbip es un archivo de texto. Podemos abrirlo con un bloc de notas para conocer como se constituye para generarlo en caso que necesitemos abrir con Desktop uno de los informes que sincronizamos antes. Ejemplo del archivo:
Al tener sincronizado el repositorio con el workspace podemos usar un entorno local. Si está en el repositorio en la rama principal, entonces estará publicado en el área de trabajo. Veamos como sería el proceso.

Esta sincronización también nos favorece en el proceso de Integración y Deploy continuo puesto que varios desarrolladores podrían tener una rama modificada y al integrarlo con la principal delimitada en el área de trabajo tendríamos automáticamente todo deployado.
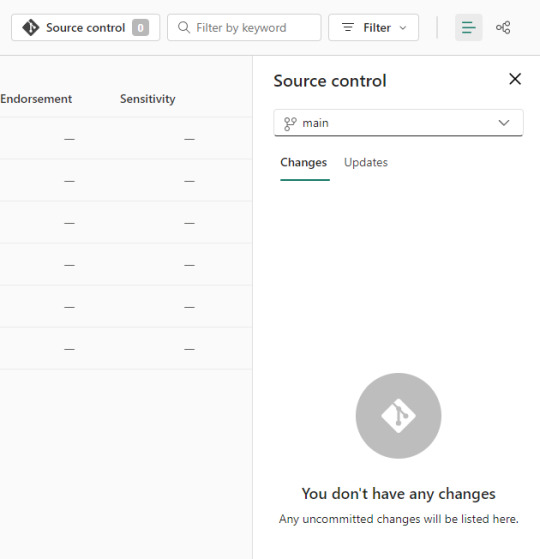
Si algo no se encuentra en su última versión o hacemos modificaciones en línea, podemos acceder al menú de source control que nos ayudaría a mantener ordenadas las versiones.
Alternativa Pro
Con las nuevas actualizaciones de Fabric en agosto 2023, podremos por primera vez, trabajar en equipo en PowerBi sin licencia por capacidad o premium. Guardar como proyecto es una característica de PowerBi Desktop. Por lo tanto, podemos usarla contra un repositorio Git en cualquier tecnología. Al termino del desarrollo, una persona encargada debería abrir el PBIP y publicarlo al área pertinente. Ahora podemos publicar desde Desktop los informes guardados como proyectos. Esto nos permite que los casos de puras licencias pro puedan aprovechar las características de histórico y control de versiones. Quedará pendiente la automatización para deploy e integración que aún no podría resolverse solo con PRO.
Conclusión
Esta nueva característica nos trae una práctica indispensable para el desarrollo. Algo que era necesario hace tiempo. Sería muy prudente usarlo aún en proyectos que no modifiquen un informe al mismo tiempo puesto que ganamos una gran capacidad en lo que refiere a control de versiones.
Si no tenemos capacidad dedicada, deberíamos trabajar como vimos en post anteriores sobre metodología de integración continua de repositorio https://blog.ladataweb.com.ar/post/717491367944781824/simplepbicd-auto-deploy-informes-de-powerbi
Esperemos que pronto tengamos una opción para importar por API estos proyectos al PowerBi Service para poder idear nuestros propios procesos sin usar las integraciones por defecto sino una personalizada a nuestro gusto.
#powerbi#power bi#power bi desktop#power bi git#azure devops#azure repos#power bi tutorial#power bi tips#power bi training#power bi argentina#power bi jujuy#power bi cordoba#ladataweb#power bi developer mode
0 notes
Text
[DAX] Descripciones en medidas con Azure Open AI
Hace un tiempo lanzamos un post sobre documentar descripciones de medidas automaticamente usando la external tool Tabular Editor y la API de ChatGPT. Lo cierto es que la API ahora tiene un límite trial de tres meses o una cantidad determinada de requests.
Al momento de decidir si pagar o no, yo consideraría que el servicio que presta Open AI dentro de Azure tiene una diferencia interesante. Microsoft garantiza que tus datos son tus datos. Qué lo que uses con la AI será solo para vos. Para mi eso es suficiente para elegir pagar ChatGPT por Open AI o por Azure.
Este artículo nos mostrará como hacer lo que ya vimos antes pero deployando un ChatGPT 3.5 y cambiando el script de C# para utilizar ese servicio en Azure.
Para poder realizar esta práctica necesitamos contar con un recurso de Azure Open AI. Este recurso se encuentra limitado al público y solo podremos acceder llenando una encuesta. Fijense al momento de crear el recurso debajo de donde seleccionaríamos el precio.

La respuesta de Microsoft para permitirnos usar el recurso puede demorar unos días. Una vez liberado nos permitirá usar un Tier S0. Este recurso es un espacio que nos permite explorar, desarrollar, deployar modelos. En nuestro caso queremos deployar uno ya existente. Al crear el recurso veremos lo siguiente y antes de ingresar a Deploy, copiaremos valores de interes.
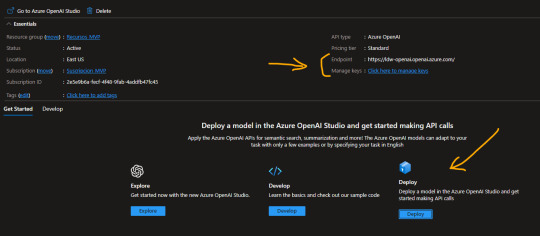
Para nuestro script vamos a necesitar el “Endpoint” y una de las “Keys” generadas. Luego podemos dar click en “Deploy”.
Al abrir Azure AI Studio vamos a “Deployments” para generar uno nuevo y seguimos esta configuración:
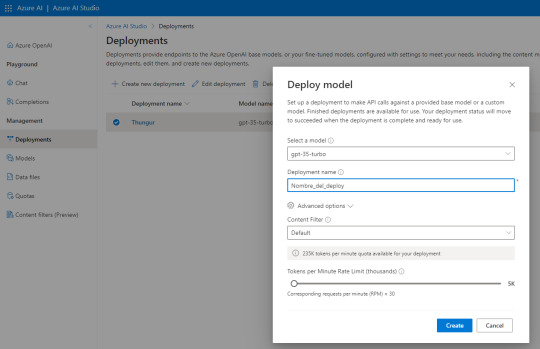
El nombre del deploy es importante puesto que será parte de la URL que usamos como request. Seleccionen esa versión de modelo que se usa para Chat especificamente de manera que repliquemos el comportamiento deseado de ChatGPT.
Atención a las opciones avanzadas puesto que nos permiten definir la cuota de tokens por minuto y el rate limiting de requests por minuto. Para mantenerlo similar a la API gratuita de Open AI lo puse en 30. Son 10 más que la anterior.
NOTA: ¿Por qué lo hice? si ya intentaron usar la API Trial de GPT verán que les permite ver sus gastos y consumos. Creo que manteniendo ese rate limiting tuve un costo bastante razonable que me ayudó a que no se extienda demasiado puesto que no solo lo uso para descripciones DAX. Uds pueden cambiar el valor
Con esto sería suficiente para tener nuestro propio deploy del modelo. Si quieren probarlo pueden ir a “Chat” y escribirle. Nos permite ver requests, json y modificarle parámetros:

Con esto ya creado y lo valores antes copiados podemos proceder a lo que ya conocemos. Abrimos PowerBi Desktop del modelo a documentar. Luego abrimos Tabular Editor y usaremos el siguiente Script para agregar descripciones a todas las medidas que no tengan descripción previa. Tiene un pausador al llegar a 30 porque es el rate limiting que yo definí en mi modelo. Eso pueden cambiarlo
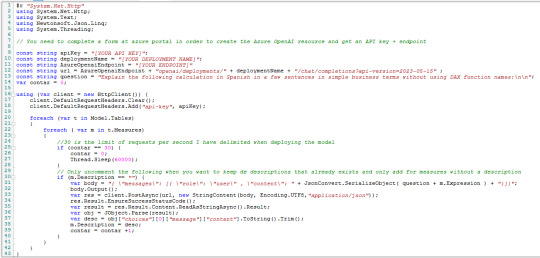
Las primeras variables son los valores que copiamos y el nombre del deployment. Completando esos tres el resto debería funcionar. El script lo pueden copiar de mi Github.
Con esto obtendrán las descripciones de las medidas automaticamente en sus modelos utilizando el servicio de Azure Open AI, espero que les sirva.
#powerbi#power bi#power bi desktop#azure openai service#azure ai#power bi argentina#power bi jujuy#power bi cordoba#power bi tips#power bi training#power bi tutorial#ladataweb#fabric
0 notes
Text
[PowerQuery] Transformar columnas con condición personalizada
No hay nada más molesto para hacer informes o análisis que datos sumamente sucios. Con esto me refiero a malos ingresos de datos, normalmente proveniente de encuestas u hojas de cálculo.
Power Query es una buena herramienta de ETL pero es importante usarla bien para no reventar de pasos insostenibles en nuestro script. Para eso ya escribimos un post que nos ayude a reducir pasos. Lo que veremos en este artículo esta enfocado en simular lo que podemos hacer dentro de “Agregar Columna Personalizada” pero transformando la columna que necestamos limpiar sin crear otra columna con el código personalizado deseado.
En el proceso iremos agregando codiciones varias para ver el poder que tenemos.
Antes de iniciar me gustaría aclarar que este artículo mostrará técnicas avanzadas de power query para usarse como ETL en respuesta a procesamiento de datos. Eso no quita que haya mejores prácticas. Nada superará a hacer el procesamiento en un único origen de verdad como warehouse o lakehouse que sería la mejor de las prácticas.
¿Cuántes veces tuvieron que crear una columna personalizada en power query porque no existía un modo en la interfaz para reemplazar valores con un sencillo if?
Me quedó media larga la pregunta pero ciertamente ocurre que a veces necesitamos limpiar un conjunto de datos con una columna numérica mal escriba y caemos en hacer muchisimas operaciones de “Reemplazar Valores”. Lo cierto es que reemplazar valores solo cambia una cadena de texto por otra. Eso esta bien para cosas pequeñas como errores de tipeo tradicionales. Sin embargo, con una condición más complicado, digamos, si queremos que salga un determinado texto tras encontrar una determinada cadena sin reemplazarla, entonces se complicaría. Ejemplo, cada vez que encontremos el texto “hombr” debería salír “Varón”. Si aparece homb, hombre, hombrrrre, hombre pues, hombrecito, hombreton o algo similar, lo reconocería como hombre y le pondríamos “Varón”.
Vamos a ver tres ejemplos de reemplazo y limpiezas.
Supongamos que enviamos una encuesta de sueldos a un grupo de personas que trabajan remoto. Tenemos una tabla con salarios y una descripción que no todos llenan sobre el pago en dólares.
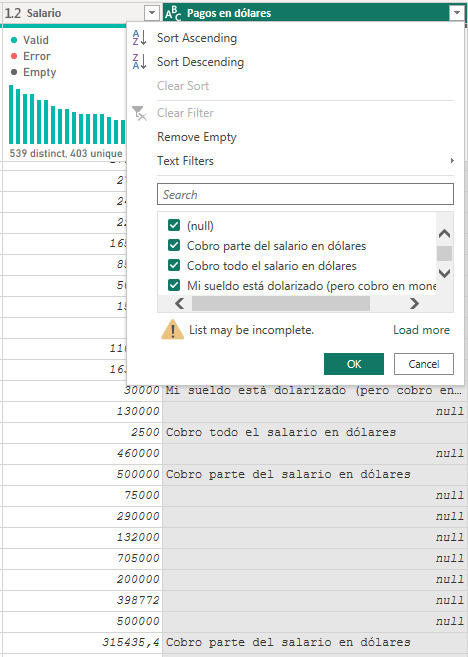
Lo primero que podríamos pensar es agregar otra columna más limpia, pero podríamos limpiar esta. ¿Qué tal si reemplazamos “USD” cuando encuentra la palabra “dólares” y “ARS” cuando no lo hace?
Veamos el proceso. Cuando queremos reemplazar bajo condición en una columna necesitamos usar la función ReplaceValues de tabla. Veamos la teoría:
Table.ReplaceValue(table as table, oldValue as any, newValue as any, replacer as function, columnsToSearch as list) as table
Esta función nos deja reemplazar una cadena oldValue (en este caso el mismo valor de la columna porque queremos reemplazar cada aparición sin importar su valor) con un newValue (resultado de una condición que armemos) en una clásica condición de reemplazo Replacer y la columna columnsToSearch en la cual buscará el oldValue para cambiar por el newValue. Basados en la tabla anterior nos quedaría algo así:
= Table.ReplaceValue(
#"Paso Anterior",
each [#"Pagos en dólares"] ,
each if Text.Contains([#"Pagos en dólares"], "dólares")
then "ARS"
else "USD",
Replacer.ReplaceValue,{"Pagos en dólares"}
)
De este modo en cada aparición del valor propio de la columna hace un reemplazo de lo que tenga por la condición elegida. Dejandonos con un pobre pero inicial resultado:
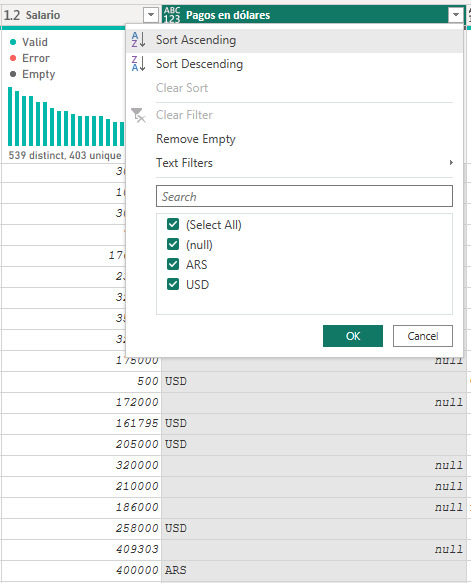
La lógica se cumplió y aprendimos a hacer un reemplazo en la columna. Sin embargo, la limpieza fue medio pobre y no hemos contemplado los escenarios correctamente. Recordemos que tenemos muchos null y también hay casos que tienen “Parte del salario en dolares”, lo cual no quedaría contemplado con ARS y USD.
Para mejorar nuestro limpieza sobre la columna vamos a realizar una condición entre las dos columnas. Por vivir en este páis tengo claro que no existe un Salario menos a 15000 ARS en la industria remota de tiempo completo (FullTime) y sería también dificil que una persona tenga un salario de 15000 USD mensuales.. Entonces voy a usar ese conocimiento para limpiar con una condición numérica la primera elección y luego preguntar por la palabra “parte” cuando recibie en ambas monedas el salario.
Veamos el caso
= Table.ReplaceValue(
#"Renamed Columns",
each [#"Pagos en dólares"],
each if [Salario]< 15000
then "USD"
else if Text.Contains([#"Pagos en dólares"], "parte") and [#"Pagos en dólares"] <> null
then "Híbrido"
else "ARS",
Replacer.ReplaceValue,
{"Pagos en dólares"}
)
Hacemos la primera condición coladores si el número es menor a 15000 entonces USD. Para la segunda condición en el if vamos a ir por "parte” y sumamos que no sea nulo porque sino Text.Contains ignora preguntar a los nulos y esas filas quedarían nulas aunque existiera el else.
De este modo el reemplazo quedaría más completo dejando nuestra columna con todas las opciones posibles:
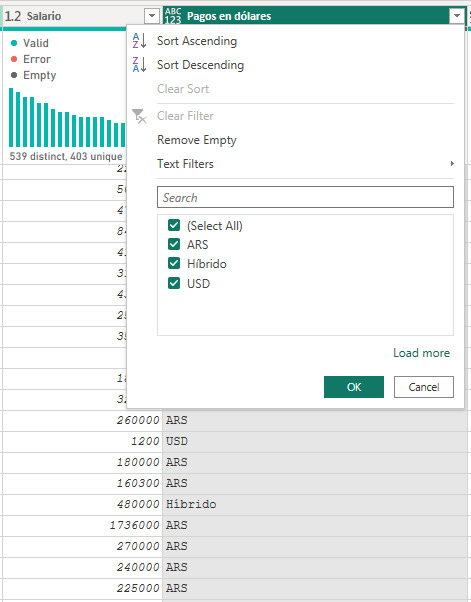
Condición IN SQL en Power Query
Los casos anteriores suelen ser un clásico, pero que ocurre cuando tenemos algo más complejo. Cuando necesitamos una serie de reemplazos masivos del estilo “IN” de SQL. Por ejemplo, veamos la siguiente imagen y digamos que necesitamos reemplazar todos las apariciones de cadenas de texto que conlleven a Hombre, Varón, Macho y Masculino. Algo tipo hombr, var, mach, masc. Si encontramos algo con eso, entonces reemplacemos por “Varón”.
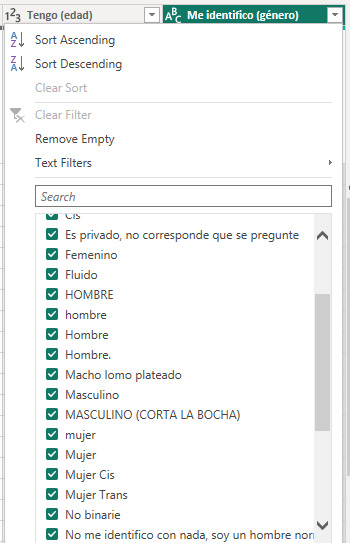
La condición semejante a IN en SQL se construye con List.Contains. Veamos la teoría:
List.Contains(list as list, value as any, optional equationCriteria as any) as logical
La función necesita una lista de valores bajo los cuales comparar y el valor a recibir. Dicho de otro modo si algun string de la lista coincide con value entonces true.
Para poder realizar esta compleja tarea necesitamos dos operaciones. Por un lado construir la lista de valores a reemplazar en cada valor de nuestra columna puesto que los comparadores masivos hacen comparación de valores exactos. Dicho de otro modo el reemplazo ejecutado se vería tipo:
List.Contains({”hombre”, “Hombre”, “Hombre.”, “Macho lomo plateado”, “Masculino”, “[entre otros....]”} , [#”Me identifico (Género)”])
Necesitamos construir esa lista de manera tal que por cada coincidencia podamos reemplazarlo por “Varón”.
En nuestro editor de consulta vamos a crear una variable. Una variable no es más que un paso más que no está relacionado con el “Paso anterior” y vive en nuestro script para usarlo. La generación de la lista sería filtrar la tabla por valores únicos cuando el texto contenga lo deseado y convertirlo a lista. Veamos:
Lista_de_varones = Table.ToList(
Table.SelectRows(
Table.Distinct(#"Paso Origen"[[#"Me identifico (género)"]]),
each (Text.Contains(Text.Lower([#"Me identifico (género)"]), "hombr")
or Text.Contains(Text.Lower([#"Me identifico (género)"]), "var")
or Text.Contains(Text.Lower([#"Me identifico (género)"]), "mach")
or Text.Contains(Text.Lower([#"Me identifico (género)"]), "masc")
) and (not Text.Contains(Text.Lower([#"Me identifico (género)"]), "trans")
)
)
)
Fijense que si bien hace referencia a un paso anterior, no lo vamos a usar en el siguiente. A la tabla de una única columna género distintiva le filtramos las filas cuando contenga lo antes acordado “hombr”, “var”, “mach”, “masc” y le agregue que no contenga “trans” puesto que sería otro género. Así obtenemos una lista con todos los resultados para nuestro IN de SQL. Son más de 50 resultados, pero solo mostraré algunos porque esto se descontroló

Con esa variable en lista que llamaremos al paso reemplazador que veníamos construyendo para aplicarlo sobre nuestra columna:
= Table.ReplaceValue(
#"Paso Origen",
each [#"Me identifico (género)"],
each if List.Contains( Lista_de_varones, [#"Me identifico (género)"] )
then "Varón"
else [#"Me identifico (género)"],
Replacer.ReplaceText,
{"Me identifico (género)"}
)
Fijense como se acortó la lista. Pasamos de casi 150 valores distintos de género a tener casi 80.
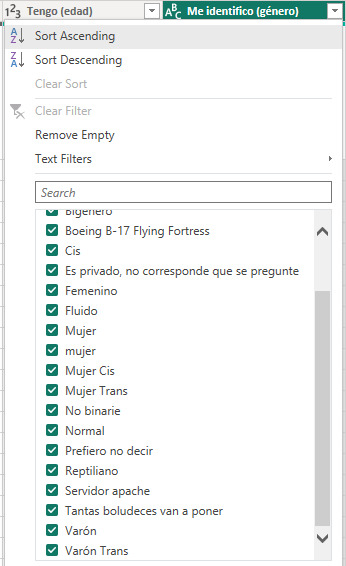
De este modo podríamos repetirlo con apariciones para Mujer, No Binario, Mujer Trans, Varón Trans y dejar al resto en Otro.
Antes de concluir me gustaría hacer incapie en que este es un proceso muy pesado. Recorrer el conjunto para obtener la lista que luego usamos de reemplazo puede tardar mucho si la lista demora en generarse. El reemplazo es rápido pero la lista no. Por ello recomiendo fuertemente hardcodear la lista si el origen de datos es una encuesta cerrada como este caso. Hacemos la ejecución para conocer los valores y ya conociendolos los registramos en otro origen:

Pueden copiar a notepadd++ y generar un macro que ponga comiilas y comas en menos de un minuto.
Ahora si llegamos al final del post y hemos aprendido a reemplazar valores de una columna según condiciones personalizadas en cualquier otra columna de la misma fila inclusive con múltiples reemplazos de porciones de cadenas de texto. Ojalá les sirva para limpiar esos datos sucios que nos llegan.
#power bi#powerbi#power bi tips#power bi tutorial#power bi training#power query#powerquery#power query tips#power query tutorial#power query training#ladataweb#power bi cordoba#power bi jujuy#power bi argentina
0 notes
Text
youtube
Luego del gran evento de Power Bi en español de inicio de año, me alegra compartirles la sesión que expuse durante el evento "Intro Scripting C# en Power Bi con Tabular Editor".
En la misma vamos a conocer como hacer scripts desde 0 sin conocimientos previos en C# o Tabular Editor, contra un modelo de Power Bi Desktop.
#power bi#power bi argentina#powerbi#power bi cordoba#power bi jujuy#power bi tutorial#power bi training#power bi tips#power bi desktop#ladataweb#Tabular Editor#power bi external tools#Youtube
0 notes
Text
[PowerBi] Measure Killer - external tool para limpiar el modelo
Vamos a tomarnos un momento para charlar de una Power Bi external tool. Hace tiempo hay varias muy conocidas que cada día usamos más para acompañar nuestros desarrollos en Power Bi Desktop y más. Ésta particularmente esta aumentando la popularidad para “limpieza” de modelo pero la podemos usar para otras cosas.
Éste artículo presenta la tool Measure Killer para que podamos conocer sus principales características gratuitas y analizar si queremos que nos acompañe como tantas otras.
Si hay algo hermoso al rededor de la comunidad de PowerBi es como se ayudan las personas para lograr objetivos comunes. Así es como surjen estas herramientas. La herramienta se llama Measure Killer y fue creada por Gregor Brunner. Pueden conseguirla en el siguiente enlace: https://en.brunner.bi/measurekiller
Se puede instalar como msi, por tienda o portable. Naturalmente voy a usar el msi para integración en el menú de external tools. En el sitio web tambien podrán sacarse dudas de que se puede y no puede hacer.
Algunas características que aportan la herramienta pasan por el análisis de un modelo tanto en medidas, columnas y tablas de dax como así también Power Query. Esto nos ayuda a limpiar el modelo.
En este artículo vamos a ver su característica más popular. Encontrar medidas no usadas y generar un script de C# para eliminarlas en un paso. Si no estan familiarizados con C# pueden ver este antiguo post del blog.
Ni bien la abrimos tendremos un pre menú para seleccionar el dataset. Vamos por Single report/dataset:

Pronto veremos el menú principal y la misma breve documentación del sitio para darnos a concoer como funciona en más detalle.
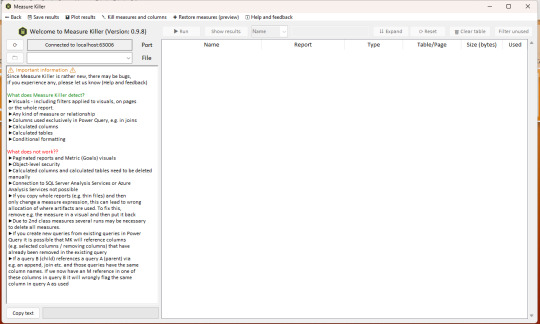
En primer lugar, en este menú buscaremos el archivo que tenemos abierto para que haga un correcto mapeo entre archivo y servidor local, o por lo menos eso imagino que hace. En segundo lugar damos “Run” y en tercero “Show results”. Terminaremos con una pantalla semejante a la siguiente:

En blanco veremos columnas y medidas usadas y en rojo las no usados. Aquí podemos explorar, buscar por nombre, table, filtrar por usados, etc. Cuando estemos decididos en nuestro accionar vamos al menú de Kill measures and columnas y veremos opciones masivas para ejecutar.
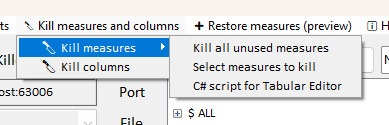
Recomiendo no usar el “Kill all...” para tener una doble revisión de nuestro proceso. Si usamos la opción de las seleccionadas podremos ver una lista previa que nos ayude a tener otro pantallazo. Mi favorita es la del script de C# porque no solo me da el mismo pantallazo de hacer una re validación antes de borrar sino también porque podría guardar ese script dentro de carpetas de documentación del modelo para conocer en que fecha, quien, limpió que elementos. Teniendo así un mejor entendimiento del proceso del modelo.
Si bien la herramienta nos permite exportar información a modo de documentación, no considero que las columnas propuestas aporten más que otras herramientas que ya hemos visto como “Model Document”. Un simple ejemplo es que entre las columnas exportadas no esta la descripción de la medida. La documentación apunta más que nada a responde ¿dónde está siendo usada la medida y cual es su expresión?. Sin embargo, considero importante ejecutar la acción junto con el script de limpieza. De es aforma si necesitamos recrear una medida compleja que fuera de repente si necesitaríamos usar, podemos rastrear si existío y cuando se borró en el script para luego buscar su expresión en el excel exportado que tengan fechas similares. Seguramente necesitarían una buena regla de nombrado esos archivos.
Así terminamos de ver una sencilla herramienta que esta pisando grandes terrenos de popularidad por su sencillez y potencial.
#measure killer#powerbi#power bi#power bi desktop#power bi external tool#power bi tutorial#power bi training#power bi tips#power bi argentina#power bi jujuy#power bi cordoba#ladataweb
0 notes
Text
[SimplePBI][CD] Auto Deploy informes de PowerBi con Azure Devops Pipelines
CI/CD, DataOps, Devops y muchos otros nombres han recorrido las redes para referirse al proceso más continuo y automático de deploy. Hoy luego de tanto tiempo de dos herramientas como Azure Devops y PowerBi existen muchos posts y artículos que nos hablan de esto.
¿Qué diferencia este artículo de otro? que haremos el deploy continuo con SimplePBI (librería de python para usar la PowerBi Rest API) dentro de Azure Devops. Solo prácticas de CD. Luego compartiré pensamientos sobre CI. Para esto nos acompañaremos de un repositorio Git en Azure Devops.
No se si llamarle algo “Ops” o simplemente CD PowerBi. Asique sin más charla que dar seguí leyendo si te interesa este mix de temas.
Si hay algo de lo que estoy seguro sobre todo esto de Ops, CI o CD es que tiene un origen y base en software que consiste en facilitar la experiencia del desarrollador. Con ese objetivo vamos a mantener la metodología de un post anterior. El desarrollador no necesita saber más nada. Todo lo siguiente lo configuraría un admin o persona que se dedique a “Ops”.
NOTA: Antes de iniciar aclaro que para que funcione la metodología anterior vamos a quitar el “tracking” del archivo y mantener unicamente el lock. Debemos quitarlo puesto que modifica la metadata guardada en gitattributes y le impide a la API de PowerBi importar el informe. Código:
git lfs untrack "Folder/File_name.pbix"
Proceso
Intentando simular metodologías de desarrollo de software es que vamos a plantear este artículo. Cabe aclarar que funcionaría en tradicionales esquemas que siguen el hilo de “Origenes -> Power Bi Desktop -> Power Bi Service”. Nuestro enfoque aquí esta centrado en que los desarrolladores no tengan contacto con Power Bi Service. Su herramienta de desarrollo Desktop y Git serían la diaria. De este modo solo deben preocuparse por tomar la última versión desarrollada, efectuar modificaciones bloqueando el archivo y devolverlo al repositorio modificado y desbloqueado.
La responsabilidad del profesional Ops será la de asegurar que esos desarrollos publicados se disponibilicen en el servicio de PowerBi con flujos automáticos. Con este propósito, y aprovechando nuestro repositorio, vamos a utilizar la herramienta de Azure Devops Pipelines. Para tener acceso a los procesamientos paralelos que nos permiten ejecutar el pipeline, será necesario llenar una encuesta especificada en la documentación de Microsoft como nueva política. Forms y doc para más info en el siguiente link:
https://learn.microsoft.com/en-us/azure/devops/pipelines/licensing/concurrent-jobs?view=azure-devops&tabs=ms-hosted
Si bien existen muchas formas y procesos de generar deploys automáticos, la que vamos a generar es la siguiente:
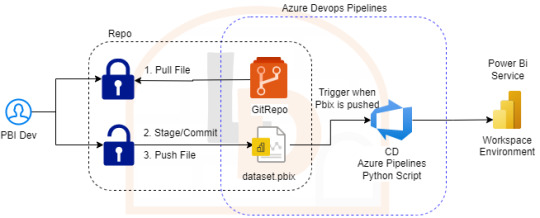
Nos vamos a concentar en importar archivos de PowerBi Desktop ni bien hayan sido pusheados al repositorio. Nuestro enfoque consiste en tener un Pipeline por Área de Trabajo, lo que llevaría a un archivo .yml por area de trabajo. Para mejorar la consistencia de nuestros desarrollos les recomiendo ordenar las carpetas para que coincidan con las areas de trabajo, datasets/reportes o ambientes. Por ejemplo:
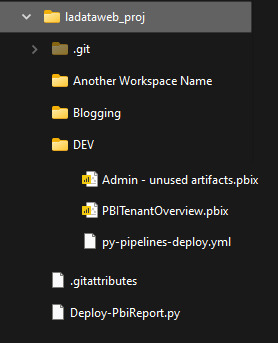
De ese modo podríamos controlar ambientes, shared datasets o simplemente informes con el dataset. Cada quien conoce sus desarrollos para aplicar la complejidad deseada. Vamos a ver el ejemplo con un solo ambiente que tiene informes en areas de trabajo sin separación de shared datasets.
Configuración
Para iniciarnos en este camino abrimos dev.azure.com y creamos un proyecto. El proyecto trae muchos componentes. De momento a nosotros nos interesan dos. Repos y Pipelines. Asumiendo que saben de lo que hablo y ya tienen un repositorio en esta tecnología o Github, procedemos a crear el pipeline eligiendo el repo:
Luego nos preguntará si tenemos una acción concreta de creación incial para nuestro archivo yaml (archivos de configuración de pipelines que orientan el proceso). Podemos elegir iniciar en blanco e ir completando o descarguen el código que veremos en el artículo, ponganlo en el repositorio y creen el pipeline a partir de un archivo existente
Ahora si tendremos nuestro archivo yml en el repositorio listo para modificarlo. Veamos como hacemos la configuración.
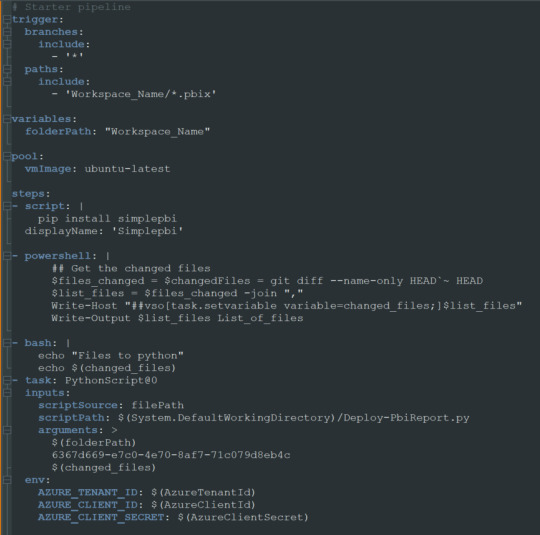
Enlace de github del archivo.
Nuestro pequeño pipeline cuenta con una serie de pasos.
Trigger
Variables
Pool
Steps
NOTA: Estos son un mínimo viable para correr una automatización. Si desean leer más y conocer mayor profundidad puede adentrarse en la documentación de microsoft: https://learn.microsoft.com/es-es/azure/devops/pipelines/yaml-schema/?view=azure-pipelines
Trigger nos mencionará en que parte del repositorio y sobre que branch tiene que prestar atención. En nuestro caso dijimos cualquier branch del path con carpeta “Workspace_Name” y al modificar cualquier archivo PBIX de dicha carpeta. Eso significa que al realizar un commit y push de un archivo de Power Bi Desktop dentro de esa carpeta, se ejecutará el pipeline.
Variables nos permite definir un texto que podremos reutilizar más adelante. En este caso el path de la carpeta. Si bien es una sola carpeta, la práctica de la variable puede ser útil si queremos usar paths más largos. IMPORTANTE: los nombres de carpetas en la variable path no pueden contener espacios dado que la captura de python posterior los reconoce como argumentos separados. Recomiendo usar “_” en lugar de espacios.
Pool viene por defecto y es el trasfondo que correrá el pipeline. Recomiendo dejarlo en ubuntu-latest.
Steps aquí estan los pasos ejecutables de nuestro pipeline. La plataforma nos permite ayudarnos a escribir esta parte cuando elegimos basarnos de la ayuda del wizard. En este caso podemos basarnos en lo que proveemos en ladataweb. Hablemos más de estos pasos.
Detalle de Steps
Primero haremos la instalación de la librería de Python que nos permite utilizar la Power Bi Rest API de manera sencilla en el paso Script.
El paso powershell puesto que nos permite jugar con una consola directa sobre el repositorio. Aqui aprovecharemos para ejecutar un comando git que nos informe cuales fueron los últimos archivos afectados entre el commit anteriores y el actual. Tengamos en cuenta que para poder realizar esta comparación necesitamos cambiar el shallow fetch de nuestro repositorio. Esto significa la memoria de cambio reciente que normalmente viene resguardando 1 commit “más reciente”. Para realizar este cambio necesitamos guardar el pipeline. Luego lo editamos nuevamente y nos dirigimos a triggers:

Una vez allí en la pestaña Yaml podremos encontrar la siguiente opción que igualaremos a 3 como el mínimo necesario para la comparativa.
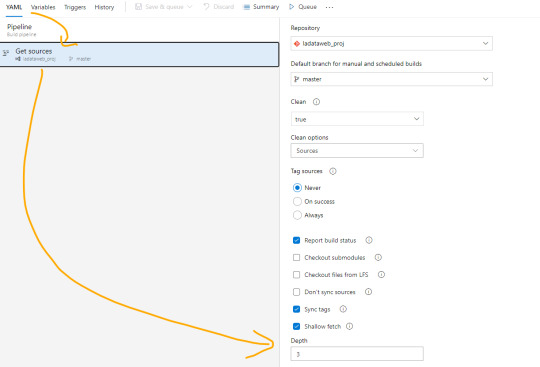
Esta operación también se puede realizar con un Bach de Git local, pero este modo me parece más simple y visual. Para más información pueden leer aqui: https://learn.microsoft.com/es-es/azure/devops/pipelines/repos/azure-repos-git?view=azure-devops&tabs=yaml#shallow-fetch
El paso bash es simplemente para mostrarnos en la consola los archivos que reconoció el script y estan listos para pasar entre pasos.
El paso crítico es Task que llamará a un python script. Para ser más ordenado vamos a llamar a un archivo en el repositorio que nos permita leer un código que cambie con unos parámetros que envía el pipeline para no estar reescribiendolo en cada pipeline de cada workspace/carpeta. Aqui completamos que en script source del file path definido podemos encontrar el script path hasta el archivo puntual que usuará los siguientes tres argumentos. La lista de argumentos refiere al path de los archivos pbix, el id del workspace en donde publicaremos y los archivos que se modificaron según el último commit. Cierra definiendo unas variables de entorno para garantizar la seguridad del script evitando la exposición de la autenticación de la API. En el menú superior derecho veremos la posibilidad de agregar variables:

Sugiero mantener oculto el secret del cliente y visible el id del cliente. Visible este segundo para reconocer con que App Registrada de Azure AD nos estamos conectado a usar la Power Bi Rest API.
Ya definido nuestro Pipeline creemos el script de python que hará la operación de publicar el archivo. En nuestro script lo dejé en la Raíz del repositorio $(System.DefaultWorkingDirectory)/Deploy-PbiReport.py para reutilizarlo en los pipelines de las carpetas/workspaces. Veamos el script

Enlace de github del archivo.
Primero importaremos simplepbi y otras dos librerías. OS para reconocer las variables del entorno y SYS para recibir argumentos.
Iniciarmos recibiendo los argumentos de pipeline con sys.argv en el orden correspondiente. Como la recepción de python lee los argumentos separados por espacios como distintos, vamos a asumir que el parámetro 3 o más se unan separados por espacios (puesto que llegaron como argumentos separados. Luego tomamos la lista de archivos en cadena de texto para construir una lista de python que nos permita recorrerla. En este proceso aprovecharemos para quitar archivos modificados en el commit que no pertenezcan a la carpeta/workspace deseada y sean de extensión “.pbix”. Leemos las variables de entorno para loguear nuestro Power Bi Rest API y todo lo siguiente es mágia de SimplePBI. Pedimos el token para nuestra operaciones, hacemos un for de archivos a importar y realizamos la importación con cuidados de capturas de excepciones y condiciones. Todos los prints nos ayudarán a ver los mensajes al termino de la ejecución para reconocer alguna eventualidad. Esto apunta a no cortar si uno de los archivos falla en publicar no corte al resto. Sino que seguirá y al finalizar podremos lanzar la excepción para que falle el pipeline general a pesar que tal vez corrieran 4/5. Por supuesto que esta decisión podría cambiarse a que si uno falla ninguno continue, o que siga pero al final lanzar una excepción
NOTA: Claro que si es la primera vez que colocamos el archivo.pbix en el repositorio no bastará solo con la importación automática. Será necesario ir a ingresar las credenciales para las actualizaciones manualmente. De momento eso no es posible hacerlo automáticamente.
Para ejecutar la prueba solo bastaría con modificar un archivo .pbix dentro de la carpeta del repo, commit y push. Ese debería ejecutar la acción y publicar el archivo.
De ese modo el desarrollador solo se enfoca en desarrollar con Power Bi Desktop de manera apropiada contra un repositorio y nada más. Un profesional Ops y Administrador serían quienes tendrían licencias PRO que administren el entorno de Áreas de trabajo, apps y distribución de audiencias y permisos.
Demo final commiteando con visual studio code:
Conclusión
Estas posibilidades llevan no solo a buenas prácticas en desarrollo sino también a mantener una linea de desarrolladores que no necesitarían licencias pro a menos que querramos que tengan más responsabilidades en el servicio.
Todo este ejemplo puede expandirse mucho más. Podríamos desarrollar los informes con Parametros para apuntar a distintas bases de datos y tener ambientes de desarrollo. Los desarrolladores no cambiarían más que agregar parametros y tal vez tener otro branch o repositorio. Los profesionales Ops podrían incorporar en el script de importación el cambio del parámetro en service. Incluso podrían efectuarse prácticas de CI moviendo automáticamente versiones estables de un repo a otro. Hablar de CI no me gusta porque no podemos hacer build ni correr tests, pero dejen volar su imaginación. Cada día las prácticas de desarrollo son más posibles y cercanas en proyectos de datos.
En ese archivo python podríamos usar todo el poder de SimplePBI para ajustar nuestro escenario a la práctica Ops deseada.
#powerbi#power bi#power bi devops#power bi cicd#azure devops#azure devops pipelines#power bi tips#power bi tutorial#power bi training#power bi versioning#simplepbi#ladataweb#power bi jujuy#power bi argentina#power bi cordoba#power bi rest api
0 notes
Text
[GIT] Versionando PowerBi trabajando en equipo - previa para CI/CD
Estoy seguro que una de las dudas más grandes de las soluciones de Power Bi actualmente se están preguntando ¿Como persistir/versionar PowerBi?
Naturalmente, cuando los desarrollos son realizados por una única persona no suele haber tantos problemas porque bastaría con una herramienta de estilo Sharepoint para guardar los archivos una vez finalizados. Sin embargo, si trabajamos en equipo sobre un dataset en constante crecimiento la cuestión se complica.
Luego de varios años trabajando en distintos proyectos y métodos voy a compartir mi forma rutinaria de trabajar en equipo persistiendo nuestros archivos. Este artículo aprovechara las tecnologías de versionado de Git con desarrollos de Power Bi Desktop usando Azure DevOps.
Primero me gustaría aclarar que este post asume que ya tenemos conocimientos básicos sobre Repositorio y Versionado Git.
Cuando trabajamos solos sobre un report o dataset no suele haber problemas en el desarrollo. La triste realidad por el momento es que trabajar en simultáneo sobre un mismo archivo Power Bi Desktop es imposible. Por esta razón, necesitamos organizarnos más que nunca al momento de trabajar en equipo sobre un mismo archivo. Junto con ello es indispensable aplicar prácticas de desarrollo de software sobre los archivos para recuperar versiones anteriores históricas con posibilidades de integración y deploy continuo.
La primera solución
Ésta idea nace trabajando en un proyecto con Sharepoint. Un equipo de 10 personas sobre un mismo dataset. La solución que pensamos rápidamente fue crear un chat todos juntos donde avisaríamos si estábamos usando el archivo original para que NADIE más lo modifique. Decíamos algo tipo “Pulling Dataset Nombre”. Al terminar de subirlo volver a avisar con un “Pushing Dataset Nombre”. De ese modo nuestro sharepoint versionaba el desarrollo y persistíamos nuestras versiones. El problema con esta solución era tener que bajar el archivo, publicarlo y luego subirlo a sharepoint por cada cambio que quisiéramos hacer. Si sincronizaban sharepoint para evitar el problema anterior ocurráa que no se siguía la regla al pie de la letra pensando que hacían un cambio rápido y luego ir a avisar al chat. En ese interín chocaba con otra persona editando y comenzaban los conflictos. Ésta puede ser una gran posibilidad en un único ambiente de desarrollo sin automatizaciones ni metodologías de proyectos puesto que aunque sea tenemos versiones de respaldo de los desarrollos.
Solución Definitiva
Si quisiéramos llevarlo al siguiente nivel necesitaríamos una estructura más robusta. Entonces me pregunté como podíamos mejorar esto y ahí nacieron las ideas. Me di cuenta que si se hacía bien podíamos tener versionado, evitar el chat, cumplir con ambientes y usar CD/CI que alinearía una estructura agile.
Llevando este escenario a las mejores prácticas vamos a utilizar Azure DevOps (que cuenta con limitada cantidad de licencias free). Vamos por esta herramienta porque no solamente cuenta con las últimas versiones de la tecnología GIT sino también con Pipelines que nos ayudarían a construir CI/CD con Power Bi. Tuvimos en cuenta una las problemáticas que sucede en ambas soluciones (sharepoint y git repo) para evitarlas en esta metodología. El mayor temor al momento de trabajar con Sharepoint es pisarse versiones y el mayor miedo de trabajar con GIT es que un archivo de power bi no puede pasar por una acción “Merge”.
NOTA: Para aquellos interesados en CI/CD pueden encontrarlo por google o en este post de la comunidad de Power Bi.
En un principio lo que voy a mostrar suena obvio y hasta repetitivo porque consisten en usar un repositorio Git con Azure DevOps, pero hay un punto de quiebre que resultó ser el quiebre de optimización.
Al igual que la solución inicial de Sharepoint tenemos que descargar la última versión del repositorio para comenzar a trabajar (pull) y luego devolverla al repositorio al terminar de modificar (commit and push). Esos dos conceptos son los principales de los cuales no podemos escapar, pero SI podemos hacerlo de todo lo demás que lo rodea. Podemos:
Evitar el chat y merge bloqueando el archivo cuando alguien lo toma automáticamente
Programar una integración continua al devolver y hasta deployarlo en el ambiente adecuado según el momento del sprint.
Muchos se preguntarán ¿Por qué bloquear el archivo?. Normalmente, cuando trabajamos con repositorios, hacemos pull request modificamos algunas cosas y la devolvemos a main. Veamos la imagen considerando que el violeta y verde son usuarios que toman el archivo celeste pbix en tiempos distintos.
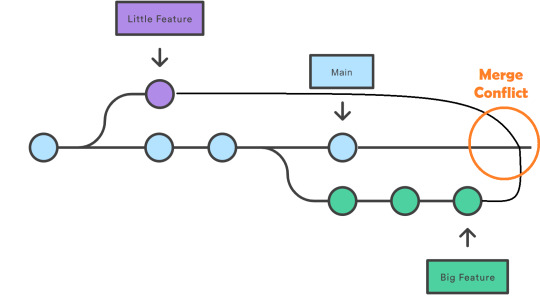
Como dos tomaron en el archivo al momento de subirlo se generará un conflicto. Como es un archivo unico y cerrado no podemos mergear su código. Para evitar el conflicto la lógica de sharepoint funcionaba no por el chat, sino porque se esperaba a que termine un cambio para comenzar otro. Algo así:
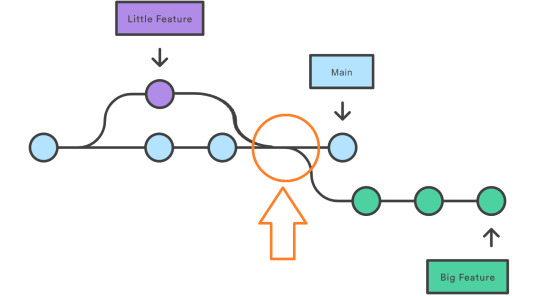
Al termino del violeta comienza el verde tomando la versión modificada de violeta. Entonces nos preguntamos ¿Cómo forzar al usuario verde que el violeta termine su cambio antes de comenzar el suyo? bloqueando el archivo. Cuando el usuario haga pull request nos avise que no puede porque el Usuario X lo esta modificando.
De ese modo reduciríamos nuestra práctica colaborativa de un archivo a cuatro acciones. Bloquear, pull, push y desbloquear. Bloquear, descargar, subir y desbloquear. Aclaro que por supuesto stage y commit se siguen haciendo por prácticas de repositorio. Veamos una imagen para entender mejor como fluiría todo el repo y un spoiler de integración continua.
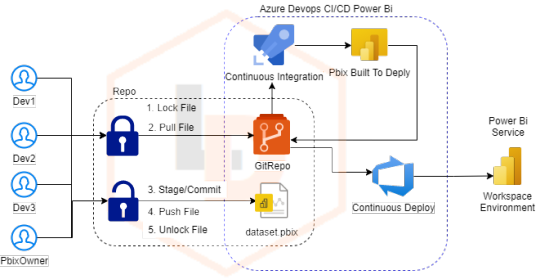
Una vez implementado los números de la imagen serían las acciones rutinarias de los desarrolladores. Para configurar esto necesitaremos un usuario dueño de la arquitectura quien hará el seteo inicial y podrá desbloquear el archivo aún cuando esté bloqueado en casos excepcionales.
Todo inicia etiquetando al archivo requerido como “Lockable”, es decir bloqueable. Esto lo convierte en un archivo de solo lectura a menos que seamos nosotros quien lo bloqueemos. Para ello el usuario Owner podrá ejecutar un código semejante al siguiente
git lfs track ".\dataset.pbix" --lockable
A partir de ese momento estará listo el seteo inicial para que la diaria de los desarrolladores sea la mencionada en nuestro diagrama iniciando por el lock.
git lfs lock “.\dataset.pbix”
Al momento de ejecutar el lock sabremos si esta disponible o si otra persona lo tiene. Si alguien hizo lock y todavía no lo desbloqueó veremos un aviso de que no podemos bloquearlo porque persona@compañia.com.ar lo tiene en su poder. En caso que este disponible nos permitiría bloquearlo. Esta es una de las razones por la cual decidí usar la función lock de GIT porque no solo podemos realizar la acción sino ver quien lo tiene así en caso de emergencias.
Asumo que los pasos intermedios ya son familiares. Hablo hacer pull de un archivo, realizar un cambio, stage y commit changes finalizando con un push.
No todo termina aquí. Ahora que terminamos nuestro trabajo es momento de disponibilizar el archivo para que otro usuario pueda usarlo. Entonces ejecutaremos
git lfs unlock ".\dataset.pbix”
Este comando liberará el archivo para que otra persona pueda editarlo. El comando solo sirve cuando nosotros fuimos quien dimos “lock” al archivo. Si intentamos hacerlo contra un archivo que no hemos bloqueado fallaría.
Así hemos terminado con los pasos necesario para el desarrollo conjunto en equipo de un archivo versionado. Cada vez que algún miembro necesita el archivo ejecutaría esos paso.
No todo termina aquí. Seguramente pueden ocurrir problemas. Por ejemplo un desarrollador dio push de sus cambios pero nunca hizo el unlock y ahora salió de vacaciones. Por esta razón es indispensable tener un “responsable” al que llamé owner. Para una mejor organización solo esa persona debería conocer que es posible desbloquear lo que nosotros mismos no hemos bloqueado. El comando es similar pero lleva un argumento adicional para estos casos extremos.
git lfs unlock <filename> --force
Con el agregado del final podríamos desbloquear el archivo en caso que la persona que lo tiene se haya olvidado de hacerlo, no podamos contactarnos para que lo desbloquee.
Así concluimos con una metodología de trabajo con Azure DevOps sobre Git versionando Power Bi en equipo. También ahora sabemos que va más allá de la edición puesto que podríamos generar Build y Deploys configurables según las necesidades del equipo para automatizar y evolucionar el modo de trabajo. Un claro ejemplo sería tener automatizaciones que publiquen el archivo pbix del repositorio a un determinado Workspace de PowerBi Service. De momento la mayoría de las personas utilizar PowerBi Desktop y por eso opto por esta metodología, pero no quiero terminar sin antes mencionar que la tecnología no para de crecer y para los desarrolladores más pro código seguro veremos mejores prácticas con el lanzamiento de TMDL.
#powerbi#power bi#power bi training#power bi tips#power bi tutorial#power bi git#power bi versioning#power bi devops#power bi cordoba#power bi jujuy#power bi argentina#ladataweb#power bi cicd
0 notes
Text
[StoryTelling] This is Roger Federer
Hace tiempo que tenía esta idea de tablero para cuando llegara el día del retiro de su majestad. Lamentablemente demoré más de la cuenta, pero lo importante es conocer más sobre este brutal deportista.
En este artículo vamos a comentar sobre el desarrollo del storytelling del tenista que me hizo gustar este deporte, Roger Federer.
Les doy la bienvenida al Storytelling que se titula “This is Roger Federer”.
Historia
Para contar esta historia he creado un menú lateral izquierdo y dividí la secuencia en tres principales capítulos.
Datos y resumen de su carrera
Torneos
Vs Rivales
El en transcurso de la historia podemos iniciar contemplando sus datos personales. Para que no todo quedase en eso continuamos con historia de ganados y perdidos, puntos y ranking.

Continua dividiendo su camino en torneos usando un árbol de decomposición en los torneos ganados y la proporción de los mismos según la superficie.
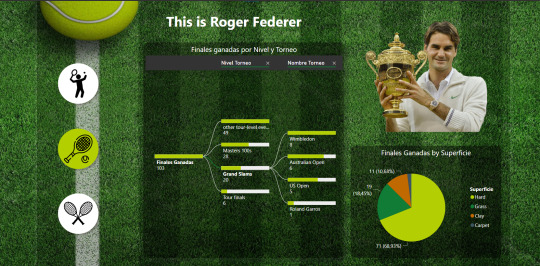
Cierra la historia pudiendo comparar partido a partido o estadísticas generales de algún torneo, año o rival especifico. Podremos conocer no solo una racha con un rival sino sus rivalidades por superficies y mucho más.

Template
Para construir esto utilicé una dinámica de Dark Them con un fondo oscurecido. La cancha de tenis tiene un cuadrado negro con transparencia que ayude a visualizar mejor las letras blancas. Cada visualización tambien tiene el mismo efecto pero con mayor concentración.Vean los cuadrados 1, 2 y 3 como se va oscureciendo.

El tooltip sobre la foto del tenista se construyó con la tercera forma de documentación que menciona un antiguo post de documentación.

Para mejorar la navegación se usaron bookmark navigators en la página principal y la de rivales cambiando gráficos, como así también navegación entre páginas con los iconos redondos que se pintan del color de la pelota de tenis. Los colores de gráficos también combinan con la pelota de tenis.
Bookmark Navigator por grupo

Navegación de página

Colores

Así termina nuestro paso por un nuevo storytelling en LaDataWeb. Esperemos que les haya gustado y ojalá volvamos a ver tenis como el de Roger en un futuro.
#storytelling#power bi#powerbi#power bi desktop#power bi storytelling#roger federer#power bi roger federer#power bi jujuy#power bi cordoba#power bi argentina#ladataweb
0 notes
Text
[TabularEditor] Documentar automaticamente descripciones de Medidas
ChatGPT esta causando un impacto enorme en el mundo de IA. Hay muchos ejemplos que muestran como puede ejecutar código. Sin embargo, el mejor que vi hasta el momento para por documentación.
La cuestión con la documentación es que no solo los desarrolladores detestan hacerla, sino también que se olviden o ni intentan. Entonces tener una forma de que se genere automáticamente es una feature que estoy seguro se usaría mucho más.
Desde el inicio del post voy a comenzar aclarando que ninguna inteligencia artificial será capas de dar una mejor descripción que el desarrollador del código DAX. Por ello se recomienda leer lo que genera la IA para controlar que esté todo en orden. Sería como validar documentación generado por alguien más.
Para poder trabajar con esta solución vamos a necesitar dos cosas
Tabular Editor 2 o 3
Cuenta en https://platform.openai.com/
Para construir esto vamos a usar un Script en C# que correrá sobre Tabular Editor. Ese script llamará a la API de OpenAI preguntandole a la inteligencia artificial por una descripción breve del cálculo de la medida en DAX.
Empecemos generando una KEY para poder usar la API de OpenAI. Vamos al menú de arriba a la derecha y clickeamos en View API Keys:

En la pantalla que se abre tocamos el botón “Create new secret key”. Eso abrirá una ventana emergente con una clave enorme. Este es el momento de copiarla porque no va a mostrarla de nuevo. Si no la copian ahi, se perderá y tendrán que generar otra.
Con esa key vamos a poder continuar con el script que podrán encontrarlo en mi Github. El script fue creado por Darren Gosbell y publicado en este artículo. Sin embargo, subí una copia modificada con dos cambios:
Posibilidad de correr en más de 20 medidas
Generación de la descripción en español
Tengan en cuenta que la API tiene una limitación que solo permite 20 requests por minuto. Eso significa que el tiempo estimado de ejecución será de 1 minuto cada 20 medidas. Luego se incorporó un “in Spanish” al pedido del bot para que nos genere en español el contenido, pero si quieren que siga en ingles, pueden borrarlo.
Abrímos nuestro PowerBi Desktop. Vamos a External Tools y abrimos Tabular Editor. Nos dirigimos a la pestaña (tab) “C# Scripts” donde se ingresa el código que vamos a copiar, pero antes de pegarlo ejecutamos la siguiente línea:
Model.AllMeasures.Count().Output();
Esta sentencia devuelve el total de medidas en nuestro modelo. Si dividimos ese número en 20 tendremos el tiempo estimado en minutos que tardará en correr nuestro script. Muy importante tenerlo en cuenta porque al ejecutar, y demorar, siempre da la sensación que se congeló todo cuando en realidad sigue corriendo.
Luego de tener una idea del tiempo promedio pegamos nuestro código:

Reemplazamos la constante apiKey por la key generada para nuestro usuario de OpenAI y le damos play para ejecutarlo. Consideren que el script, por defecto, va a generar descripción para todas las medidas sin importar si ya tenían algo escrito. Va a pisar cualquier descripción existente.
Sino queremos que esto ocurra fijense que tiene un condicional comentado que pregunta por vacío. Si descomentamos la linea del if y el cierre de su llave correspondiente, entonces solo agregará descripción a medidas que no tengan esa propiedad manteniendo las que ya tenían.
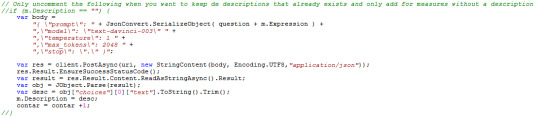
Un ejemplo de descripción generada:
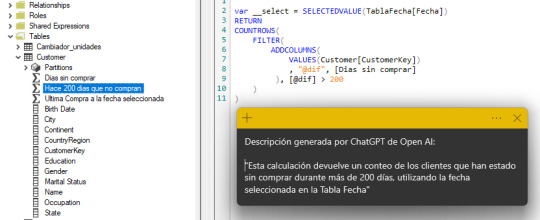
Antes de pensar que todo ha terminado vamos a guardar esto en nuestro modelo tabular de Power Bi Desktop y controlar que las descripciones tengan sentido. No podemos dejar de revisarlo. Tal como si lo hubiera hecho otro desarrollador y nosotros fueramos responsables del modelo, debemos revisar la documentación generada.
Para facilitar ese proceso podemos usar otra external tool llamada Model Documenter tal como lo indiqué en un antiguo post.
Espero que esto ayude a seguir documentando y teniendo el ejercicio de tener una descripción para las medidas.
#powerbi#power bi#power bi desktop#power bi tips#power bi tutorial#power bi training#power bi documentation#tabular editor#power bi argentina#power bi jujuy#power bi cordoba
0 notes
Text
[TabularEditor] Analizador de buenas prácticas de modelado
¿Sabían que existe un analizador de buenas prácticas en una external tool llamada tabular editor? tal vez ya sabían puesto que no es algo nuevo y lo anunció PowerBi oficial en su momento. Lo que es una novedad es que ahora existe una posibilidad de correrlo y que las descripciones estén en Español, italiano y japonés.
Éste artículo nos ayudará a hacer el chequeo de buenas prácticas con la tool y a utilizar las descripciones en español.
Lo primero que necesitamos para realizar esta práctica es la external tool tabular editor. Podemos conseguir la version gratuita en el siguiente enlace: https://github.com/TabularEditor/TabularEditor/releases
A partir de ese momento la tendremos disponible para hacer muchas cosas contra nuestro modelo, pero en este post solo veremos el tema del análisis de buenas prácticas.
Para proceder a chequear nuestro modelo, simplemente vamos a la tab de External Tools y abrimos Tabular Editor.
Nota: Puede que aparezca un mensaje que las ediciones del modelo que hagamos aquí corren por nuestra propia responsabilidad. Pueden tener la tranquilidad que el producto lleva años de estabilidad y testing sin fallas críticas.
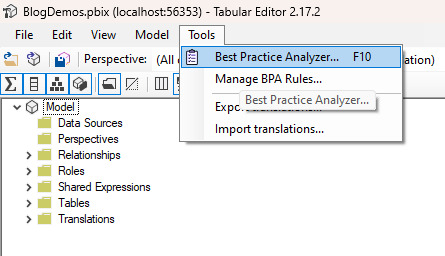
En el menú de herramientas o tools veremos el analizador que también puede ser accedido con F10
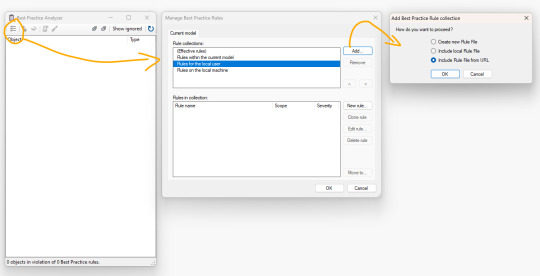
Una vez abierto el menú administraremos las reglas agregando por URL las del GitHub de la plataforma https://github.com/microsoft/Analysis-Services/tree/master/BestPracticeRules
NOTA: Recordemos usar la información cruda en modo RAW ingresando al archivo BPARules y dando click en raw para obtener la URL
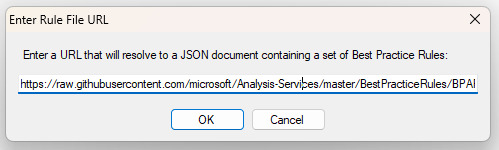
En el menú que se incorpora ingresamos la URL antes mencionada
Esto incorporará un item a la administración de reglas. Al seleccionarla podemos ver cada detalle de reglas que analizará por si queremos desactivar alguna.

Del mismo modo podemos incorporar las reglas en español. Si vemos bien el Github de reglas hay una carpeta spanish. Entonces repetimos el proceso con la URL de la RAW data del archivo BPARules.json y obtendremos el análisis en español:

De este modo podremos analizar más detalladamente que las mejores prácticas de modelado estén aplicadas en nuestro modelo y aquellas advertencias o errores por no completarlos, sean expresados en español. Al dar “Ok”, podremos apreciar las reglas que se expanden como una matriz con +/- para reflejar la columna, tabla o item que rompe la regla.
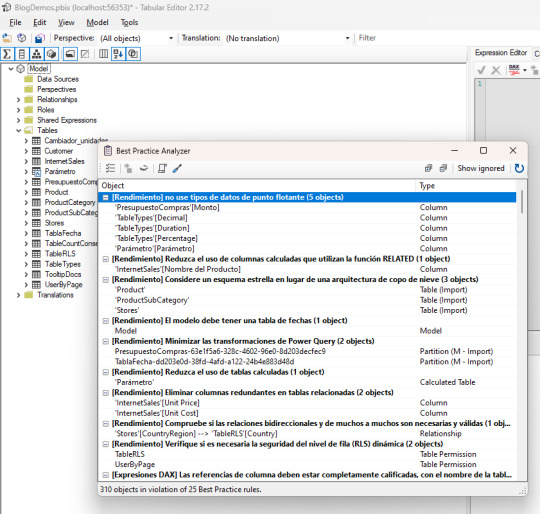
A partir de ese punto queda en cada persona leer el informe y tomar decisiones sobre la modificación de cada hallazgo encontrado por el analizador.
Asi termina este tip para analizar la implementación de buenas prácticas en nuestros modelos. Espero que les sea de utilidad para llevar los modelos a su máximo nivel.
#powerbi#power bi#tabular editor#tabular model#power bi tips#power bi training#power bi tutorial#power bi argentina#power bi cordoba#power bi jujuy#power bi desktop#ladataweb#power bi external tool
0 notes
Text
[DAX] Time Intelligence vs WINDOW vs OFFSET
El mundo de DAX esta que arde con el lanzamiento de las funciones nuevas a fines del año 2022. Muchos posts en distintos blogs han aparecido mostrando muchos escenarios explicando las funciones nuevas.
La mayoría de los artículos intenta explicar las funciones. Este artículo va a pasar eso por alto y va a intentar comparar como responden las funciones de time intelligence con el código tradicional respecto a las nuevas funciones de DAX para resolver esos clásicos escenarios de fecha.
Antes de dar inicio al artículo vamos a dejar un enlace a la documentación de Microsoft de las nuevas funciones DAX 2022. De ésta forma podes interiorizarte con OFFSET y WINDOW antes de iniciar.
https://learn.microsoft.com/es-es/dax/new-dax-functions
El análisis aplicado será realizado sobre un Adventure works en modo importado. Lo primero que vamos a hacer es aprender a construir algunos escenarios clásicos de Time Intelligence con las nuevas funciones. Veamos ejemplos para LY (Año Anterior), LM (Mes Anterior) y YTD (Año total meses acumulados).
Año Anterior (LY)
Normalmente para construir esta función podemos usar DATEADD o SAMEPERIODLASTYEAR. Veamos un ejemplo para una medida de [Net Price AC]
Net Price LY =
CALCULATE(
[Net Price AC]
, SAMEPERIODLASTYEAR(TablaFecha[Fecha])
)
Ahora veamos la traducción a las nuevas medidas.
OFFSET
Net Price LY OFF =
CALCULATE(
[Net Price AC],
OFFSET(
-1,
ALL(TablaFecha[Año])
)
)
WINDOW
Net Price LY WIN =
CALCULATE(
[Net Price AC],
WINDOW(
-1,REL,-1,REL,
ALL(TablaFecha[Año])
)
)
De forma predeterminada cuando no especificamos valores de ORDERBY y PARTITIONBY, tomaría lo expresado en la tabla de relación. En este caso los valores distintivos de Año.
En un rápido chequeo podemos apreciar todo acorde:

Mes Anterior (LM)
En estos casos podemos usar tanto DATEADD como PREVIOUSMONTH, sigamos nuestro ejemplo con Net Price AC
Net Price LM =
CALCULATE(
[Net Price AC]
, PREVIOUSMONTH(TablaFecha[Fecha])
)
Ahora veamos la traducción a las nuevas medidas.
OFFSET
Net Price LM OFF =
CALCULATE(
[Net Price AC]
, OFFSET(
-1
, ALL(TablaFecha[Año], TablaFecha[IdMes], TablaFecha[Mes], TablaFecha[Periodo])
, ORDERBY(TablaFecha[Periodo])
)
)
WINDOW
Net Price LM WIN =
CALCULATE(
[Net Price AC],
WINDOW(
-1,REL,-1,REL,
ALL(TablaFecha[Año], TablaFecha[IdMes], TablaFecha[Mes], TablaFecha[Periodo]),
ORDERBY(TablaFecha[Periodo])
)
)
La traducción esta vez es un poco más compleja. Requerimos más que solo año para poder hacerle entender al motor lo querepresenta un mes. Podemos usar el par Mes y IdMes o podemos usar Periodo. Yo expresé ambos para tener la libertad de que la medida funcione para ambas columnas llegado el caso de una visualización. El IdMes es el número de mes que da orden al nombre de mes. Por esa última razón es necesario incluirlo en la tabla relativa que vamos a explorar.
Vistazo validando valores:

Año total meses acumulados (YTD)
Para este escenario vamos a usar la medida Quantity AC
Quantity YTD =
CALCULATE(
[Quantity AC]
, DATESYTD(TablaFecha[Fecha])
)
OFFSET. De momento no disponemos de una medida con esta función porque la función realiza un desplazamiento determinado para recuperar el valor de una fila y no para agregar o acumular un conjunto de filas. Puede que existan formas de ejecutar la acción pero seguramente requerirían acciones adicionales que hagan más compleja la resolución. Como estamos buscando la mejor forma para resolver esto, dudo que esta opción aplique.
Ahora veamos la traducción a la nueva medida
WINDOW
Quantity YTD WIN =
CALCULATE(
[Quantity AC],
WINDOW(
1,ABS,0,REL,
ALL(TablaFecha[Año], TablaFecha[IdMes], TablaFecha[Mes], TablaFecha[Periodo]),
ORDERBY(TablaFecha[Periodo]),
PARTITIONBY(TablaFecha[Año])
)
)
La clave en esta oportunidad es que el acumulado comience al primer índice absoluto y termine en el actual relativo particionado por año. De este modo acumula valores desde el inicio de la partición hasta el último.
Validamos la solución:
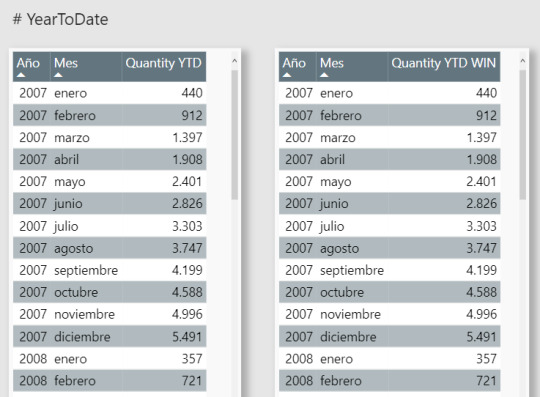
Ahora que todo se dispone de la mejor manera vamos a mediar la performance de nuestras medidas como sugiere SQLBI. Una página en blanco donde inicia nuestro PowerBi Desktop para tener todas las memorias cache limpias y recien prenderíamos el Performance Analyzer para ver los números de las visualizaciones en limpio.
LY
Dentro del tiempo de cada visualización para LY podemos apreciar que no hay mucha diferencia en cuanto a performance, si bien demoró menos OFFSET en la totalización el detalle nos indica que DAX Query demora exactamente lo mismo para cada medida.
LM

Para lo que es el Mes ya tenemos una diferencia que se presenta más que nada por el abarcar columnas de Mes, IdMes y Periodo. Cuando hice la prueba con simplemente periodo los tres números estaban más cerca y menores a 30 en DAX Query. Seguía ganando TI (TimeIntelligence) por poco.
YTD

Finalmente acumulando tampoco hemos encontrado grandes diferencias.
Conclusión
Las nuevas funciones tienen un gran poder para recorrer y traer valores de un contexto. Pueden buscar por indice o cantidad en un cierto orden. Son muy poderosas para escenarios de búsqueda bajo índices numéricos o de texto. Sin embargo, las nuevas funciones no son mejores ni funcionan mejor para escenarios tradicionales de fecha con un conjunto de datos importado. Las nuevas funciones NO reemplazarían a las de Time Intelligence tradicionales que venimos usando hace ya bastante tiempo.
Tengan cuidado en escenarios de Direct Query puesto que allí si se ha notado diferencia y Chris Webb lo demostró en un artículo de su blog.
Como siempre pueden encontrar el archivo de PowerBi Desktop de prueba en mi github. Espero que les haya sido útil el análisis.
#powerbi#power bi#power bi tutorial#power bi tips#power bi training#power bi desktop#dax#dax tips#dax tutorial#dax training#power bi argentina#power bi jujuy#power bi cordoba#ladataweb
0 notes
Last Seen Blogs

arumidden
You teach me and I'll teach you

i-think-i-luv-ya
I Just Wanted To Know Their Names!!!

chaoticcollectorzombie
end the ice Ba beer

thetidemice
lila

quintisqueen-blog
Serious is overated