#frontmatter yaml
Text
Maybe it's just me, but I find it rather weird/strange that the convention is
have a special "title" field in the frontmatter YAML, and then inject that into the published content as a header
rather than
read the first line of the content, and (optionally: only if it is header markup), use it as a title.
Just seems backwards to me.
I do understand that from a parsing perspective, it can seem cleaner if you're imagining the kind of use-cases where you only need to parse the frontmatter. But that strikes me as missing the forest for the trees. Sure it's cleanly decoupled in isolation, but typical usage isn't going to be decoupled:
If I already run code to parse and convert article content to, say, HTML, it doesn't trouble me to extract the title from the content.
Conversely, if I'm already hand-typing, say, Markdown, I find it cleaner, easier, and more (conventionally/idiomatically) visually representative of what the final result will be (whether visually or just in intent) if the title is the first line of the content using the same representation as I would use for other headings/titles in that content format/markup/language.
It's also not strictly better in composability and decoupling:
on the one hand, your title-extraction composes with any content format without coupling to parsing that content, but
on the other hand, your content authoring is coupled to frontmatter, and content which was written to work without frontmatter (title in the content markup itself) won't compose as nicely with a system which expects a title in the frontmatter.
1 note
·
View note
Note
would you be willing to talk more about how you use dataview to organize data in obsidian? (i am referring to the fact that you kind of mentioned that you do that in this post, but didn't go into any detail about how.) i appreciate your running this blog! 💌💐
hello :) gladly!
i'm still a super beginner with dataview, but i'd be happy to walk through the ways i currently use it with obsidian :)
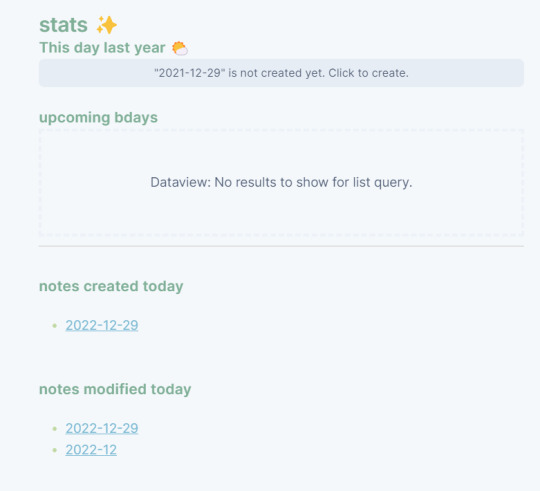
under each daily page, i have a stats section, which is a sort of automatically updating part of my diary.
this day last year: it links me to a diary page from the year previous (i only started using obsidian in the summer so i don't have enough entries for that yet)
upcoming bdays: on pages for my friends / family etc. i have a section on the page's YAML frontmatter for their birthdays - if the birthday is within the month, it'll appear in this section
notes created today: lists all the notes created today
notes modified today: lists all the notes modified today
the only other use of dataview i have atm is that when i create checkboxes like the fofllowing:

i have a page in my vault called 'tasks' that just rounds up all my incomplete tasks in one place so that i can keep all my notes to myself in one spot and to address them later. my rule for this is that these are things / thoughts that i need to process later on, like a short idea for something, or something that needs to be turned into a legit task, etc.
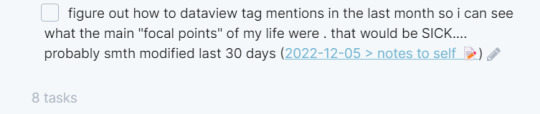
here's a preview of the task page :)
that's honestly it atm - i'd love to incorporate it more into my workflow, but haven't done it yet!
15 notes
·
View notes
Text
Eventually I will have fully automated my process to turn badly-formatted ebooks into tidy little stacks of easily-edited UTF-8 Markdown files with Jekyll-style YAML frontmatter. I will then be forced to face the logical consequence of my choices: the fucking Yama Kings
8 notes
·
View notes
Text
Gridsomeでイチからブログを作る - Markdownファイルで記事を作る
前回、前々回と下準備をしました。それらは準備であって人によっては不必要です。料理で言えば「包丁を研ぐ」のような感ですかね。今回こそは料理をして食べれる形、つまり記事部分を表示させてブログの体にもっていくことを目指そうと思います。
記事を表示させるための準備
記事としてのデータの持ち方はいろいろありますが、今回はMarkdownファイルをベースとして表示できるようにします。なお、他の選択肢としてはWordpressを始めとしたCMSでデータを保持��編集しAPI経由で取得するような方法もあります。
記事部分を扱うプラグインは規約としてsourceという命名規則にのっとるように決められています。従来のGridsome v0.6系まではMarkdownファイルを1記事として扱うためのプラグインとして@gridsome/source-filesystemが提供されていました。 2020年2月現在、Blog-Starterもこれがベースとなっています。
Gridsome v0.7系以降では新たに@gridsome/vue-remarkというプラグインも使うことができます。sourceとついていませんが、内部的に@gridsome/source-filesystemを使っているため、これだけでMarkdownで記事を作っていくことができます。
設定方法が少し異なるものの、遜色なく使えます。なによりMarkdownファイル内でVue.jsのSFCを扱えるのは強力です。記事内に自分で開発したVue.jsのコンポーネントを表現の埋めこむことで自由度が飛躍的にアップします。今回はこのVueRemarkを導入してブログにしていきます。
VueRemakの準備
使いかたはここを見るのが早いです。
が、ちゃんとステップバイステップで追っていきましょう。
まずはインストール。
$ yarn add @gridsome/vue-remark
次にgridsome.config.jsを以下のように追記します。
module.exports = { plugins: [ { use: '@gridsome/vue-remark', options: { typeName: 'Post', // 必須。GraphQL上で扱う型定義 baseDir: './content/posts', // 記事となるmarkdownファイルを置くディレクトリ pathPrefix: '/posts', // URLになるパス。必須ではない。 template: './src/templates/Post.vue' // 記事ページのVueコンポーネントファイルの指定 } } ] }
このオプションは公式にも詳しく書かれています。
{ typeName: 'Post', // 必須。GraphQL上で扱う型定義 baseDir: './content/posts', // 記事となるmarkdownファイルを置くディレクトリ pathPrefix: '/posts', // URLになるパス。必須ではない。 template: './src/templates/Post.vue' // 記事ページのVueコンポーネントファイルの指定 }
この設定を説明すると、 Post型のスキーマを作り、 contents/postsにあるmarkdownファイルに従って記事内容を読みこみ /post/{記事名} ./src/templates/Post.vueのコンポーネントを使って表示する ということをしています。
さっそくcontents/posts/の中にmy-first-article.mdというファイルを作って試してみます。 記事の内容以外はmarkdownの拡張書式であるfrontmatterに従って設定します。今回は最低限として
--- title: 最初の記事 --- これは私の最初の記事です
と書いてみます。
最初の---の行で囲まれた部分がfrontmatterと言い、メタ情報として扱われます。とりあえずタイトルだけでいいでしょう
このmarkdownを実際に表示する部分となる'./src/templates/Post.vue'を書きます。
<template> <article> <h1></h1> <VueRemarkContent /> </article> </template> <page-query> query Post ($id: ID!) { post (id: $id) { title content } } </page-query>
(この例ではHTMLですが、前回導入したPugをtemplateに指定してもOKです)。
<page-query>内に書いたGraphQLにしたがってデータをロードします。ここの内容がそのままVue.jsのコンポーネント内に$pageにはいります。内部にはVue.jsのcomputeとして扱われるのでthis.$pageで扱うことができます。
<VueRemarkContent />の部分には自動的にMarkdownの本文内がpage-queryの中でcontentとして取得した内容をもとにHTMLとして表示されます。
これで記事単体のページはできました。単体ページだけではアクセスしづらいので、indexとなる記事一覧ページも作りましょう。/src/pages/index.vueを作って
<template> <div class="index"> <g-link v-for="post in $page.posts.edges" :key="post.id" :to="post.node.path"> <h2> </g-link> </template> <page-query> query { posts: allPost { edges { node { id title path } } } } </page-query>
と書いてみましょうか。最低限これだけあればOKです。 なお<g-link>はGridsome特有の組み込みコンポーネントで、サイト内リンクを作ります。vue-routerのrouter-link機能とほぼ同一です。サイト内のリンクは<g-link>、サイト外へは通常の<a href>を使います。
ここまでできたら一度表示してみましょうか。 開発中の表示は下記コマンドを打ちます。
$ yarn develop
として、表示されるURL(デフォルトではhttp://localhost:3000)をブラウザで開いてみます。
問題なく表示されていればOKです。記事タイトルと思しきものが1件表示されているので、クリックしたら遷移するでしょうか? なお、VueファイルもMarkdownファイルもHotLoadingが効いているのでファイルを編集して保存すると自動的に反映されます。
タグ対応
記事に分類のためのタグを導入します。要件としては
1記事には複数タグをつけることができる
タグ別に一覧ページを表示できる
でしょうか。 gridsome.config.jsのremark部分に以下のように変更します。
module.exports = { plugins: [ { use: '@gridsome/vue-remark', options: { typeName: 'Post', baseDir: './content/posts', pathPrefix: '/posts', template: './src/templates/Post.vue' }, refs: { tags: { typeName: `Tag`, create: true, } } } ] }
このrefsの指定では、TagというSchemaで参照型が作られ、PostのSchemaに含めています。またcreate: trueとしているため/src/templates/Tag.vueを作ることで、Tagごとの一覧ページのテンプレートを表示させることができます。
まずは記事側に
--- title: 最初の記事 tags: - tag1 - tag2 --- これは私の最初の記事です
のようにfrontmatterにYAML記法の配列でタグ名を適当につけます。
あとはPost.vueで指定しているqueryにtagを足し、templateから扱えばいいので
<template> <article> <h1></h1> <ul> <li v-for="tag in $page.post.tags" :key="tag.id"> <g-link :to="tag.path"> </g-link> </li> </ul> <VueRemarkContent /> </article> </template> <page-query> query Post ($id: ID!) { post (id: $id) { title content tag { id title path } } } </page-query>
とTagを含めるように変更します。
また、Tag.vueを作れば /tags/tag名で呼ばれるファイルを設定できますので、以下のようなコンポーネントも作ってみましょう。
<template> <div class="index"> <div class="info"> <p> </p> </div> <g-link v-for="post in $page.tag.belongsTo.edges" :key="post.id" :to="post.node.path"> <h2> </g-link> </template> <page-query> query { tag: tag(id: $id) { title belongsTo { edges { node { ... on Post { id title path } } } } } } </page-query>
これでタグ機能を追加できました。
ページングを追加する
ページングを追加するにはqueryをまずページング対応に書きかえます。 この時にpage-infoも一緒に出力します。
それではindex.vueを変更してみましょう。
<template> <div class="index"> <g-link v-for="post in $page.posts.edges" :key="post.id" :to="post.node.path"> <h2> </g-link> <Pager :info="$page.posts.pageInfo"/> </template> <page-query> query ($page: Int) { posts: allPost(perPage: 10, page: $page) @paginate { pageInfo { totalPages currentPage } edges { node { id title path } } } } </page-query>
allPost部分に上記のような引数と@paginateを指定します。同時にpageInfoも出力しておきます。 これをGridsome組み込みコンポーネントのPagerに指定れば自動的にページングを表示してくれます。
クラスやスタイルを変更したい場合や、表示件数や前後移動のための表示文字列も変更できるので、詳細はPaginate data - Gridsomeを参照してください。
まとめ
以上で最小限の記事一覧と記事ページ、タグページの実装ができました。 スターターで作るよりまず簡素に自分で書いてみると何がどうなってるか理解できると思います。
これで最低限のブログの体はできました。あとはこれをベースとしてどんどん機能を拡張していくだけです。 次回以降は必要な機能を追加していきましょう。
from Trial and Spiral https://blog.solunita.net/posts/develop-blog-by-gridsome-from-scrach-by-markdown/
1 note
·
View note
Text
MetalsmithJS is Still Really Useful
TLDR; This post highlights a stack of useful plugins to rapidly assemble a static site generator that’s powerful and easy to program... even though the core tool has stopped growing.
I needed to pick a static site framework about two years ago and I chose Metalsmith. It’s a lovely, minimal, open-source tool... however since summer of 2018 there hasn’t been any substantive work. Segment officially handed it off. Scamper to the next shiny thing right!? 🐿
I manage a medium-sized (mostly marketing) website for my day job and rely on Metalsmith along with community plugins and still enjoy it. I’m not held back, it’s simple to adjust, and a huge library of plugins have aligned on sensible norms. 🙌🏻 The architecture makes it very simple to add your own custom plugins and adjust data on it’s way to be rendered.
What Is Metalsmith?
First, here are some useful quick links about the platform and plugins:
Official plugin list
Less official, bigger plugin list
List of resources
Slack channel
Frontmatter explanation
What Do These Plugins Do?
These plugins construct a pipeline to render a site without boilerplate or complexity. Of course, the point of such architecture is to conform to your specific needs... but it never hurts to peek at someone else’s core blueprint.
Most content should be editable in a CMS, pull it from Prismic.
Data from APIs needs to be available to templates/pages/layers.
One-off pages can be hard-coded markdown/YAML.
Essential Plugins
Assemble Components and Pages
metalsmith-layouts - page level templates
metalsmith-discover-partials - expose partials/includes
metalsmith-in-place - use data and partials in markdown
metalsmith-collections - organize grouped pages
Expose Content Beyond Markdown Files
metalsmith-json-to-files - convert JSON into pages
metalsmith-data - expose JSON data to templates
metalsmith-prismic-server - content via Prismic CMS
Handy Utilities
metalsmith-permalinks - easy file named urls
metalsmith-alias - simple HTML aliases
metalsmith-fingerprint - hash filenames for cache busting
metalsmith-i18n - simple internationalization
metalsmith-sitemap - generate a dynamic xml sitemap
Build Tasks
There are Metalsmith plugins for common build tasks like: SASS compile, JS concat/minify, etc. I recommend not using them and doing this stuff with a build tool like: Gulp, Grunt, Webpack, etc. That’s what it’s for. You’ll probably need a build step to download and transform API data and reload the browser when done anyway. Use Metalsmith as a site generator, that’s what it’s for.
I hope this is helpful!
1 note
·
View note
Text
5 Myths About Jamstack
Jamstack isn’t necessarily new. The term was officially coined in 2016, but the technologies and architecture it describes have been around well before that. Jamstack has received a massive dose of attention recently, with articles about it appearing in major sites and publications and new Jamstack-focused events, newsletters, podcasts, and more. As someone who follows it closely, I’ve even seen what seems like a significant uptick in discussion about it on Twitter, often from people who are being newly introduced to the concept.
The buzz has also seemed to bring out the criticism. Some of the criticism is fair, and I’ll get to some of that in a bit, but others appear to be based on common myths about the Jamstack that persist, which is what I want to address first. So let’s look at five common myths about Jamstack I’ve encountered and debunk them. As with many myths, they are often based on a kernel of truth but lead to invalid conclusions.
Myth 1: They are just rebranded static sites
JAMStack is 99.9% branding and .1% substance. 😳😆 https://t.co/nxoEVQ43oE
— Nicole Sullivan – Black Lives Matter (@stubbornella) February 9, 2020
Yes, as I covered previously, the term “Jamstack” was arguably a rebranding of what we previously called “static sites.” This was not a rebranding meant to mislead or sell you something that wasn’t fully formed — quite the opposite. The term “static site” had long since lost its ability to describe what people were building. The sites being built using static site generators (SSG) were frequently filled with all sorts of dynamic content and capabilities.
Static sites were seen as largely about blogs and documentation where the UI was primarily fixed. The extent of interaction was perhaps embedded comments and a contact form. Jamstack sites, on the other hand, have things like user authentication, dynamic content, ecommerce, user generated content.
A listing of sites built using Jamstack on Jamstack.org
Want proof? Some well-known companies and sites built using the Jamstack include Smashing Magazine, Sphero, Postman, Prima, Impossible Foods and TriNet, just to name a few.
Myth 2: Jamstack sites are fragile
A Medium article with no byline: The issues with JAMStack: You might need a backend
Reading the dependency list for Smashing Magazine reads like the service equivalent of node_modules, including Algolia, GoCommerce, GoTrue, GoTell and a variety of Netlify services to name a few. There is a huge amount of value in knowing what to outsource (and when), but it is amusing to note the complexity that has been introduced in an apparent attempt to ‘get back to basics’. This is to say nothing of the potential fragility in relying on so many disparate third-party services.
Yes, to achieve the dynamic capabilities that differentiate the Jamstack from static sites, Jamstack projects generally rely on a variety of services, both first- or third-party. Some have argued that this makes Jamstack sites particularly vulnerable for two reasons. The first, they say, is that if any one piece fails, the whole site functionality collapses. The second is that your infrastructure becomes too dependent on tools and services that you do not own.
Let’s tackle that first argument. The majority of a Jamstack site should be pre-rendered. This means that when a user visits the site, the page and most of its content is delivered as static assets from the CDN. This is what gives Jamstack much of its speed and security. Dynamic functionality — like shopping carts, authentication, user generated content and perhaps search — rely upon a combination of serverless functions and APIs to work.
Broadly speaking, the app will call a serverless function that serves as the back end to connect to the APIs. If, for example, our e-commerce functionality relies on Stripe’s APIs to work and Stripe is down, then, yes, our e-commerce functionality will not work. However, it’s important to note that the site won’t go down. It can handle the issue gracefully by informing the user of the issue. A server-rendered page that relies on the Stripe API for e-commerce would face the identical issue. Assuming the server-rendered page still calls the back end code for payment asynchronously, it would be no more or less fragile than the Jamstack version. On the other hand, if the server-rendering is actually dependent upon the API call, the user may be stuck waiting on a response or receive an error (a situation anyone who uses the web is very familiar with).
As for the second argument, it’s really hard to gauge the degree of dependence on third-parties for a Jamstack web app versus a server-rendered app. Many of today’s server-rendered applications still rely on APIs for a significant amount of functionality because it allows for faster development, takes advantage of the specific area of expertise of the provider, can offload responsibility for legal and other compliance issues, and more. In these cases, once again, the server-rendered version would be no more or less dependent than the Jamstack version. Admittedly, if your app relies mostly on internal or homegrown solutions, then this may be different.
Myth 3: Editing content is difficult
Kev Quirk, on Why I Don’t Use A Static Site Generator:
Having to SSH into a Linux box, then editing a post on Vim just seems like a ridiculously high barrier for entry when it comes to writing on the go. The world is mobile first these days, like it or not, so writing on the go should be easy.
This issue feels like a relic of static sites past. To be clear, you do not need to SSH into a Linux box to edit your site content. There are a wide range of headless CMS options, from completely free and open source to commercial offerings that power content for large enterprises. They offer an array of editing capabilities that rival any traditional CMS (something I’ve talked about before). The point is, there is no reason to be manually editing Markdown, YAML or JSON files, even on your blog side project. Aren’t sure how to hook all these pieces up? We’ve got a solution for that too!
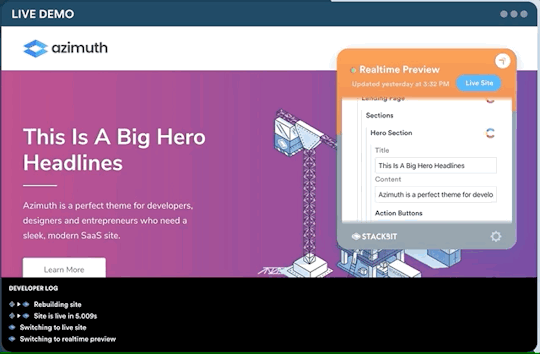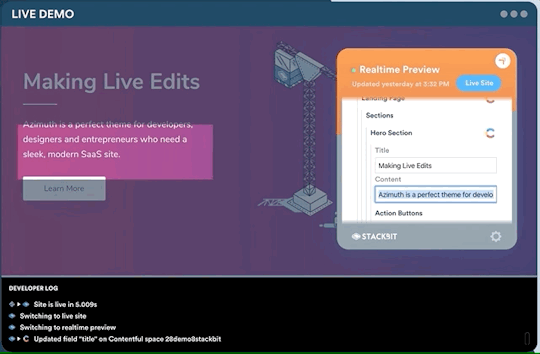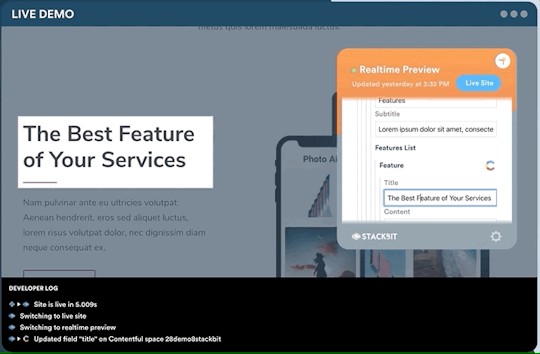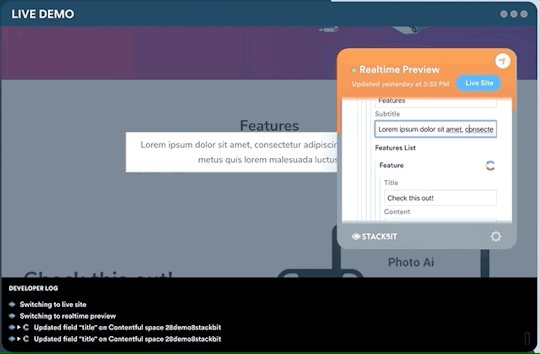
One legitimate criticism has been that the headless CMS and build process can cause a disconnect between the content being edited and the change on the site. It can be difficult to preview exactly what the impact of a change is on the live site until it is published or without some complex build previewing process. This is something that is being addressed by the ecosystem. Companies like Stackbit (who I work for) are building tools that make this process seamless.
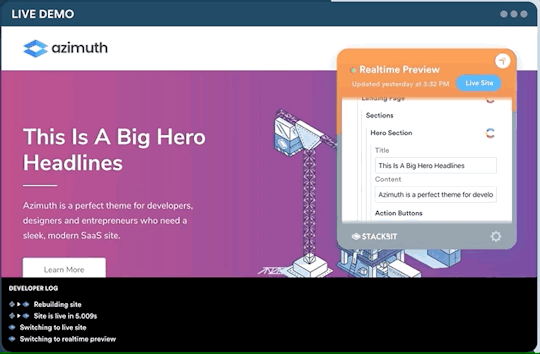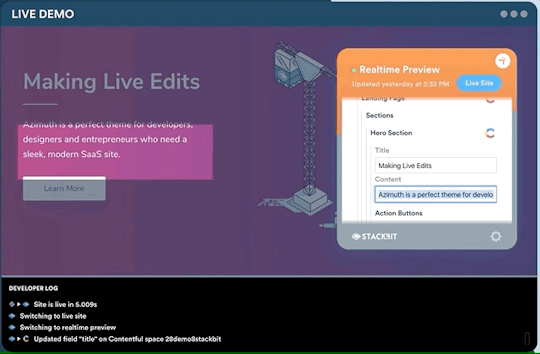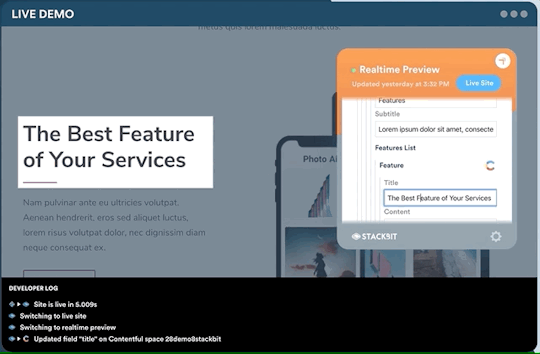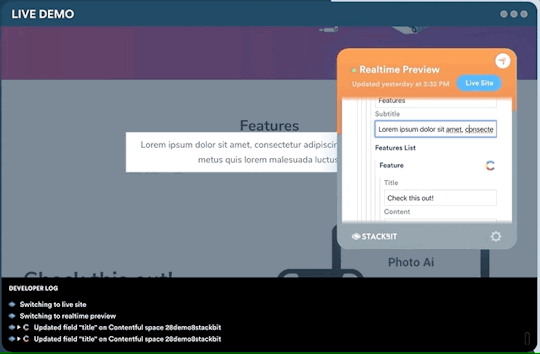
Editing a site using Stackbit
We’re not the only ones working on solving this problem. Other solutions include TinaCMS and Gatsby Preview. I think we are close to it becoming commonplace to have the simplicity of WYSIWYG editing on a tool like Wix running on top of the Jamstack.
Myth 4: SEO is Hard on the Jamstack
Kym Ellis, on What the JAMstack means for marketing:
Ditching the concept of the plugin and opting for a JAMstack site which is “just HTML” doesn’t actually mean you have to give up functionality, or suddenly need to know how to code like a front-end developer to manage a site and its content.
I haven’t seen this one pop up as often in recent years and I think it is mostly legacy criticism of the static site days, where managing SEO-related metadata involved manually editing YAML-based frontmatter. The concern was that doing SEO properly became cumbersome and hard to maintain, particularly if you wanted to inject different metadata for each unique page that was generated or to create structured data like JSON-LD, which can be critical for enhancing your search listing.

The advances in content management for the Jamstack have generally addressed the complexity of maintaining SEO metadata. In addition, because pages are pre-rendered, adding sitemaps and JSON-LD is relatively simple, provided the metadata required exists. While pre-rendering makes it easy to create the resources search engines (read: Google) need to index a site, they also, combined with CDNs, making it easier to achieve the performance benchmarks necessary to improve a site’s ranking.
Basically, Jamstack excels at “technical SEO” while also providing the tools necessary for content editors to supply the keyword and other metadata they require. For a more comprehensive look at Jamstack and SEO, I highly recommend checking out the Jamstack SEO Guide from Bejamas.
Myth 5: Jamstack requires heavy JavaScript frameworks
If you’re trying to sell plain ol’ websites to management who are obsessed with flavour-of-the-month frameworks, a slick website promoting the benefits of “JAMstack” is a really useful thing.
– jdietrich, Hacker News
Lately, it feels as if Jamstack has become synonymous with front-end JavaScript frameworks. It’s true that a lot of the most well-known solutions do depend on a front-end framework, including Gatsby (React), Next.js (React), Nuxt (Vue), VuePress (Vue), Gridsome (Vue) and Scully (Angular). This seems to be compounded by confusion around the “J” in Jamstack. While it stands for JavaScript, this does not mean that Jamstack solutions are all JavaScript-based, nor do they all require npm or JavaScript frameworks.

In fact, many of the most widely used tools are not built in JavaScript, notably Hugo (Go), Jekyll (Ruby), Pelican (Python) and the recently released Bridgetown (Ruby). Meanwhile, tools like Eleventy are built using JavaScript but do not depend on a JavaScript framework. None of these tools prevent the use of a JavaScript framework, but they do not require it.
The point here isn’t to dump on JavaScript frameworks or the tools that use them. These are great tools, used successfully by many developers. JavaScript frameworks can be very powerful tools capable of simplifying some very complex tasks. The point here is simply that the idea that a JavaScript framework is required to use the Jamstack is false — Jamstack comes in 460 flavors!
Where we can improve
So that’s it, right? Jamstack is an ideal world of web development where everything isn’t just perfect, but perfectly easy. Unfortunately, no. There are plenty of legitimate criticisms of Jamstack.
Simplicity
Sebastian De Deyne, with Thoughts (and doubts) after messing around with the JAMstack:
In my experience, the JAMstack (JavaScript, APIs, and Markup) is great until is isn’t. When the day comes that I need to add something dynamic–and that day always comes–I start scratching my head.
Let’s be honest: Getting started with the Jamstack isn’t easy. Sure, diving into building a blog or a simple site using a static site generator may not be terribly difficult. But try building a real site with anything dynamic and things start to get complicated fast.
You are generally presented with a myriad of options for completing the task, making it tough to weigh the pros and cons. One of the best things about Jamstack is that it is not prescriptive, but that can make it seem unapproachable, leaving people with the impression that perhaps it isn’t suited for complex tasks.
Tying services together
Agreed. In yesterday's web you could grab an instrument and begin playing. Today's web development feels like a conductor trying to pull together a massive orchestra into a cohesive song – you have to understand each individual musician's part to have any chance of success.
— Brian Rinaldi (@remotesynth) May 1, 2020
When you actually get to the point of building those dynamic features, your site can wind up being dependent on an array of services and APIs. You may be calling a headless CMS for content, a serverless function that calls an API for payment transactions, a service like Algolia for search, and so on. Bringing all those pieces together can be a very complex task. Add to that the fact that each often comes with its own dashboard and API/SDK updates, things get even more complex.
This is why I think services like Stackbit and tools like RedwoodJS are important, as they bring together disparate pieces of the infrastructure behind a Jamstack site and make those easier to build and manage.
Overusing frameworks
In my opinion, our dependence on JavaScript frameworks for modern front-end development has been getting a much needed skeptical look lately. There are tradeoffs, as this post by Tim Kadlec recently laid out. As I said earlier, you don’t need a JavaScript framework to work in the Jamstack.
However, the impression was created both because so many Jamstack tools rely on JavaScript frameworks and also because much of the way we teach Jamstack has been centered on using frameworks. I understand the reasoning for this — many Jamstack developers are comfortable in JavaScript frameworks and there’s no way to teach every tool, so you pick the one you like. Still, I personally believe the success of Jamstack in the long run depends on its flexibility, which (despite what I said about the simplicity above) means we need to present the diversity of solutions it offers — both with and without JavaScript frameworks.
Where to go from here
Sheesh, you made it! I know I had a lot to say, perhaps more than I even realized when I started writing, so I won’t bore you with a long conclusion other than to say that, obviously, I have presented these myths from the perspective of someone who believes very deeply in the value of the Jamstack, despite it’s flaws!
If you are looking for a good post about when to and when not to choose Jamstack over server-side rendering, check out Chris Coyier’s recent post Static or Not?.
The post 5 Myths About Jamstack appeared first on CSS-Tricks.
5 Myths About Jamstack published first on https://deskbysnafu.tumblr.com/
0 notes
Text
5 Myths About Jamstack
Jamstack isn’t necessarily new. The term was officially coined in 2016, but the technologies and architecture it describes have been around well before that. Jamstack has received a massive dose of attention recently, with articles about it appearing in major sites and publications and new Jamstack-focused events, newsletters, podcasts, and more. As someone who follows it closely, I’ve even seen what seems like a significant uptick in discussion about it on Twitter, often from people who are being newly introduced to the concept.
The buzz has also seemed to bring out the criticism. Some of the criticism is fair, and I’ll get to some of that in a bit, but others appear to be based on common myths about the Jamstack that persist, which is what I want to address first. So let’s look at five common myths about Jamstack I’ve encountered and debunk them. As with many myths, they are often based on a kernel of truth but lead to invalid conclusions.
Myth 1: They are just rebranded static sites
JAMStack is 99.9% branding and .1% substance.


https://t.co/nxoEVQ43oE
— Nicole Sullivan – Black Lives Matter (@stubbornella) February 9, 2020
https://platform.twitter.com/widgets.js
Yes, as I covered previously, the term “Jamstack” was arguably a rebranding of what we previously called “static sites.” This was not a rebranding meant to mislead or sell you something that wasn’t fully formed — quite the opposite. The term “static site” had long since lost its ability to describe what people were building. The sites being built using static site generators (SSG) were frequently filled with all sorts of dynamic content and capabilities.
Static sites were seen as largely about blogs and documentation where the UI was primarily fixed. The extent of interaction was perhaps embedded comments and a contact form. Jamstack sites, on the other hand, have things like user authentication, dynamic content, ecommerce, user generated content.
A listing of sites built using Jamstack on Jamstack.org
Want proof? Some well-known companies and sites built using the Jamstack include Smashing Magazine, Sphero, Postman, Prima, Impossible Foods and TriNet, just to name a few.
Myth 2: Jamstack sites are fragile
A Medium article with no byline: The issues with JAMStack: You might need a backend
Reading the dependency list for Smashing Magazine reads like the service equivalent of node_modules, including Algolia, GoCommerce, GoTrue, GoTell and a variety of Netlify services to name a few. There is a huge amount of value in knowing what to outsource (and when), but it is amusing to note the complexity that has been introduced in an apparent attempt to ‘get back to basics’. This is to say nothing of the potential fragility in relying on so many disparate third-party services.
Yes, to achieve the dynamic capabilities that differentiate the Jamstack from static sites, Jamstack projects generally rely on a variety of services, both first- or third-party. Some have argued that this makes Jamstack sites particularly vulnerable for two reasons. The first, they say, is that if any one piece fails, the whole site functionality collapses. The second is that your infrastructure becomes too dependent on tools and services that you do not own.
Let’s tackle that first argument. The majority of a Jamstack site should be pre-rendered. This means that when a user visits the site, the page and most of its content is delivered as static assets from the CDN. This is what gives Jamstack much of its speed and security. Dynamic functionality — like shopping carts, authentication, user generated content and perhaps search — rely upon a combination of serverless functions and APIs to work.
Broadly speaking, the app will call a serverless function that serves as the back end to connect to the APIs. If, for example, our e-commerce functionality relies on Stripe’s APIs to work and Stripe is down, then, yes, our e-commerce functionality will not work. However, it’s important to note that the site won’t go down. It can handle the issue gracefully by informing the user of the issue. A server-rendered page that relies on the Stripe API for e-commerce would face the identical issue. Assuming the server-rendered page still calls the back end code for payment asynchronously, it would be no more or less fragile than the Jamstack version. On the other hand, if the server-rendering is actually dependent upon the API call, the user may be stuck waiting on a response or receive an error (a situation anyone who uses the web is very familiar with).
As for the second argument, it’s really hard to gauge the degree of dependence on third-parties for a Jamstack web app versus a server-rendered app. Many of today’s server-rendered applications still rely on APIs for a significant amount of functionality because it allows for faster development, takes advantage of the specific area of expertise of the provider, can offload responsibility for legal and other compliance issues, and more. In these cases, once again, the server-rendered version would be no more or less dependent than the Jamstack version. Admittedly, if your app relies mostly on internal or homegrown solutions, then this may be different.
Myth 3: Editing content is difficult
Kev Quirk, on Why I Don’t Use A Static Site Generator:
Having to SSH into a Linux box, then editing a post on Vim just seems like a ridiculously high barrier for entry when it comes to writing on the go. The world is mobile first these days, like it or not, so writing on the go should be easy.
This issue feels like a relic of static sites past. To be clear, you do not need to SSH into a Linux box to edit your site content. There are a wide range of headless CMS options, from completely free and open source to commercial offerings that power content for large enterprises. They offer an array of editing capabilities that rival any traditional CMS (something I’ve talked about before). The point is, there is no reason to be manually editing Markdown, YAML or JSON files, even on your blog side project. Aren’t sure how to hook all these pieces up? We’ve got a solution for that too!
One legitimate criticism has been that the headless CMS and build process can cause a disconnect between the content being edited and the change on the site. It can be difficult to preview exactly what the impact of a change is on the live site until it is published or without some complex build previewing process. This is something that is being addressed by the ecosystem. Companies like Stackbit (who I work for) are building tools that make this process seamless.
Editing a site using Stackbit
We’re not the only ones working on solving this problem. Other solutions include TinaCMS and Gatsby Preview. I think we are close to it becoming commonplace to have the simplicity of WYSIWYG editing on a tool like Wix running on top of the Jamstack.
Myth 4: SEO is Hard on the Jamstack
Kym Ellis, on What the JAMstack means for marketing:
Ditching the concept of the plugin and opting for a JAMstack site which is “just HTML” doesn’t actually mean you have to give up functionality, or suddenly need to know how to code like a front-end developer to manage a site and its content.
I haven’t seen this one pop up as often in recent years and I think it is mostly legacy criticism of the static site days, where managing SEO-related metadata involved manually editing YAML-based frontmatter. The concern was that doing SEO properly became cumbersome and hard to maintain, particularly if you wanted to inject different metadata for each unique page that was generated or to create structured data like JSON-LD, which can be critical for enhancing your search listing.

The advances in content management for the Jamstack have generally addressed the complexity of maintaining SEO metadata. In addition, because pages are pre-rendered, adding sitemaps and JSON-LD is relatively simple, provided the metadata required exists. While pre-rendering makes it easy to create the resources search engines (read: Google) need to index a site, they also, combined with CDNs, making it easier to achieve the performance benchmarks necessary to improve a site’s ranking.
Basically, Jamstack excels at “technical SEO” while also providing the tools necessary for content editors to supply the keyword and other metadata they require. For a more comprehensive look at Jamstack and SEO, I highly recommend checking out the Jamstack SEO Guide from Bejamas.
Myth 5: Jamstack requires heavy JavaScript frameworks
If you’re trying to sell plain ol’ websites to management who are obsessed with flavour-of-the-month frameworks, a slick website promoting the benefits of “JAMstack” is a really useful thing.
– jdietrich, Hacker News
Lately, it feels as if Jamstack has become synonymous with front-end JavaScript frameworks. It’s true that a lot of the most well-known solutions do depend on a front-end framework, including Gatsby (React), Next.js (React), Nuxt (Vue), VuePress (Vue), Gridsome (Vue) and Scully (Angular). This seems to be compounded by confusion around the “J” in Jamstack. While it stands for JavaScript, this does not mean that Jamstack solutions are all JavaScript-based, nor do they all require npm or JavaScript frameworks.

In fact, many of the most widely used tools are not built in JavaScript, notably Hugo (Go), Jekyll (Ruby), Pelican (Python) and the recently released Bridgetown (Ruby). Meanwhile, tools like Eleventy are built using JavaScript but do not depend on a JavaScript framework. None of these tools prevent the use of a JavaScript framework, but they do not require it.
The point here isn’t to dump on JavaScript frameworks or the tools that use them. These are great tools, used successfully by many developers. JavaScript frameworks can be very powerful tools capable of simplifying some very complex tasks. The point here is simply that the idea that a JavaScript framework is required to use the Jamstack is false — Jamstack comes in 460 flavors!
Where we can improve
So that’s it, right? Jamstack is an ideal world of web development where everything isn’t just perfect, but perfectly easy. Unfortunately, no. There are plenty of legitimate criticisms of Jamstack.
Simplicity
Sebastian De Deyne, with Thoughts (and doubts) after messing around with the JAMstack:
In my experience, the JAMstack (JavaScript, APIs, and Markup) is great until is isn’t. When the day comes that I need to add something dynamic–and that day always comes–I start scratching my head.
Let’s be honest: Getting started with the Jamstack isn’t easy. Sure, diving into building a blog or a simple site using a static site generator may not be terribly difficult. But try building a real site with anything dynamic and things start to get complicated fast.
You are generally presented with a myriad of options for completing the task, making it tough to weigh the pros and cons. One of the best things about Jamstack is that it is not prescriptive, but that can make it seem unapproachable, leaving people with the impression that perhaps it isn’t suited for complex tasks.
Tying services together
Agreed. In yesterday's web you could grab an instrument and begin playing. Today's web development feels like a conductor trying to pull together a massive orchestra into a cohesive song – you have to understand each individual musician's part to have any chance of success.
— Brian Rinaldi (@remotesynth) May 1, 2020
https://platform.twitter.com/widgets.js
When you actually get to the point of building those dynamic features, your site can wind up being dependent on an array of services and APIs. You may be calling a headless CMS for content, a serverless function that calls an API for payment transactions, a service like Algolia for search, and so on. Bringing all those pieces together can be a very complex task. Add to that the fact that each often comes with its own dashboard and API/SDK updates, things get even more complex.
This is why I think services like Stackbit and tools like RedwoodJS are important, as they bring together disparate pieces of the infrastructure behind a Jamstack site and make those easier to build and manage.
Overusing frameworks
In my opinion, our dependence on JavaScript frameworks for modern front-end development has been getting a much needed skeptical look lately. There are tradeoffs, as this post by Tim Kadlec recently laid out. As I said earlier, you don’t need a JavaScript framework to work in the Jamstack.
However, the impression was created both because so many Jamstack tools rely on JavaScript frameworks and also because much of the way we teach Jamstack has been centered on using frameworks. I understand the reasoning for this — many Jamstack developers are comfortable in JavaScript frameworks and there’s no way to teach every tool, so you pick the one you like. Still, I personally believe the success of Jamstack in the long run depends on its flexibility, which (despite what I said about the simplicity above) means we need to present the diversity of solutions it offers — both with and without JavaScript frameworks.
Where to go from here
Sheesh, you made it! I know I had a lot to say, perhaps more than I even realized when I started writing, so I won’t bore you with a long conclusion other than to say that, obviously, I have presented these myths from the perspective of someone who believes very deeply in the value of the Jamstack, despite it’s flaws!
If you are looking for a good post about when to and when not to choose Jamstack over server-side rendering, check out Chris Coyier’s recent post Static or Not?.
The post 5 Myths About Jamstack appeared first on CSS-Tricks.
source https://css-tricks.com/5-myths-about-jamstack/
from WordPress https://ift.tt/3f473mj
via IFTTT
0 notes
Text
Taking notes on notetaking
I've been using CherryTree for a couple of years to keep some notes/references to myself. But I've been considering switching to something based on Markdown, mostly because I want my notes to be readable even without the software at hand. (CherryTree stores its notes and attachments in a single XML file)
After trying several open source desktop applications, I'm settling for Zettlr (for now).
Here are some things I like about it
Notes are just Markdown files, and you can use folders to structure your notes however you want
Like Typora or Mark Text, it shows a more or less formatted Markdown code, in a single panel. It's purely a matter of personal taste, but I prefer this to the approach used in many Markdown-base tools to show raw code & formatted preview side by side (it just feels very redundant to me)
You can link between notes with drag & drop
Tags are just #hashtags in your documents
It supports Mermaid for generating flowcharts & diagrams
It supports YAML frontmatter
It has a lot of features to implement a Zettelkasten, which is something I plan to try out
It does a good job as a Markdown editor
It has a small pomodoro timer in the toolbar :)
Last time I tried, there were some annoying inconsistencies in linking to external resources (absolute/relative links).
And as an Electron app, memory usage can get a little high sometimes (especially compared to a PyGTK app like CherryTree)
Some notes on the other app I tried, for reference
QOwnNotes
Like Zettlr, it respects existing files hierarchies. In addition to .md files, it does use Sqlite for metadata (like notes tags).
It has a lot of nice features
A web clipper browser extension
User scripts
Git integration (with commits at regular intervals)
Customisable interface
A small popup to select existing notes when creating a new link
Tight connection with NextCloud/OwnCloud notes & todos
As mentioned above, I'm not a huge fan of editors using 2 panels for Markdown, and this is one of them.
VNote
It also reflects existing directory structure. It adds a json file per folder with metadata, something that can be annoying in some cases (like editing an existing folder).
Editing is done in a single panel that switches between Code or View mode. I might like that better than the redundancy of having 2 panels. But I still prefer the Zettlr approach.
Its search is maybe slightly more advanced than most, but beside that, has nothing special in my opinion.
MindForge
Interestingly very idiosyncratic. I think it definitely reflects its author's own way of working, instead of following standardised UX approaches.
I enjoy the vocabulary used: the File menu is "Mind"; you don't "Save", but "Remember"; "Settings" are "Adapt", etc.
But beside that, it doesn't really work for me. I find the interface way too convoluted, with simple actions taking a lot of clicks.
It has some interesting features, like suggesting related notes, and a concept of Importance/Urgency.
While most apps create a new Markdown file for each not, MindForge gather all notes of a "Notebook" inside a single file, using Markdown headings and metadata in comment tags to separate the notes.
Boostnote
A very polished app that also has a web version (which, as you can imagine, comes with paid plans to expand storage).
It has some coders-friendly features, like reusable snippets, and something similar to Gists - a note that can store a variable number of sources "files".
I'm less a fan of the way notes are structured and stored. You can create different "storages", but from there it's a flat list. While you write notes in Markdown, they are actually stored as CSON files, all in a single folder, with an ID as the filename.
You can switch between a traditional 2-panels mode, or a single panel mode that switches automatically from "Code" to "View" when the focus is out of the text field.
Joplin
Joplin is pleasantly well designed.
Some cool features are
"Todo" notes : notes with little checkbox next to their name in the notes list
Built-in support for file synchronisation (including Webdav and local folder)
E2E encryption
A web clipper browser extension
Sadly, 2 panels again, although it has an "experimental" WYSIWYG mode.
While it uses the Markdown syntax, your notes are actually all stored in a Sqlite database. So not what I was looking for.
But also
I also briefly tried Simplenote, Notable and PileMd, but for some reasons I forgot, it wasn't suiting me.
While writing this, I also found back Standard Notes from my bookmarks. Leaving this here for whoever is interested, but I'll stick to my Zettlr plan for now ;)
#notetaking#zettlr#Zettelkasten#markdown#outliners#PIM#personal knowledge base#desktop wiki#CherryTree#open source
0 notes
Link
So, I’ve been using ikiwiki for my website since 2011. At the time, I was hosting the website on a tiny hosting package included in a DSL contract - nothing dynamic possible, so a static site generator seemed like a good idea. ikiwiki was a good social fit at the time, as it was packaged in Debian and developed by a Debian Developer.
Today, I finished converting it to Hugo.
Why?
I did not really have a huge problem with ikiwiki, but I recently converted my blog from wordpress to hugo and it seemed to make sense to have one technology for both, especially since I don’t update the website very often and forget ikiwiki’s special things.
One thing that was somewhat annoying is that I built a custom ikiwiki plugin for the menu in my template, so I had to clone it’s repository into ~/.ikiwiki every time, rather than having a self-contained website. Well, it was a submodule of my dotfiles repo.
Another thing was that ikiwiki had a lot of git integration, and when you build your site it tries to push things to git repositories and all sorts of weird stuff – Hugo just does one thing: It builds your page.
One thing that Hugo does a lot better than ikiwiki is the built-in server which allows you to run `hugo server´ and get a local http URL you can open in the browser with live-reload as you save files. Super convenient to check changes (and of course, for writing this blog post)!
Also, in general, Hugo feels a lot more modern. ikiwiki is from 2006, Hugo is from 2013. Especially recent Hugo versions added quite a few features for asset management.
Fingerprinting of assets like css (inserting hash into filename) - ikiwiki just contains its style in style.css (and your templates in other statically named files), so if you switch theming details, you could break things because the CSS the browser has cached does not match the CSS the page expects.
Asset minification - Hugo can minimize CSS and JavaScript for you. This means browers have to fetch less data.
Asset concatenation - Hugo can concatenate CSS and JavaScript. This allows you to serve only one file per type, reducing the number of round trips a client has to make.
There’s also proper theming support, so you can easily clone a theme into the themes/ directory, or add it as a submodule like I do for my blog. But I don’t use it for the website yet.
Oh, and Hugo automatically generates sitemap.xml files for your website, teaching search engines which pages exist and when they have been modified.
I also like that it’s written in Go vs in Perl, but I think that’s just another more modern type of thing. Gotta keep up with the world!
Basic conversion
The first part to the conversion was to split the repository of the website: ikiwiki puts templates into a templates/ subdirectory of the repository and mixes all other content. Hugo on the other hand splits things into content/ (where pages go), layouts (page templates), and static/ (other files).
The second part was to inject the frontmatter into the markdown files. See, ikiwiki uses shortcuts like this to set up the title, and gets its dates from git:
[[!meta title="My page title"]]
on the other hand, Hugo uses frontmatter - some YAML at the beginning of the markdown, and specifies the creation date in there:
--- title: "My page title" date: Thu, 18 Oct 2018 21:36:18 +0200 ---
You can also have lastmod in there when modifying it, but I set enableGitInfo = true in config.toml so Hugo picks up the mtime from the git repo.
I wrote a small script to automatize those steps, but it was obviously not perfect (also, it inserted lastmod, which it should not have).
One thing it took me some time to figure out was that index.mdown needs to become _index.md in the content/ directory of Hugo, otherwise no pages below it are rendered - not entirely obvious.
The theme
Converting the template was surprisingly easy, it was just a matter of replacing <TMPL_VAR BASEURL> and friends with { .Site.BaseURL } and friends - the names are basically the same, just sometimes there’s .Site at the front of it.
Then I had to take care of the menu generation loop. I had my bootmenu plugin for ikiwiki which allowed me to generate menus from the configuration file. The template for it looked like this:
<TMPL_LOOP BOOTMENU> <TMPL_IF FIRSTNAV> <li <TMPL_IF ACTIVE>class="active"</TMPL_IF>><a href="<TMPL_VAR URL>"><TMPL_VAR PAGE></a></li> </TMPL_IF> </TMPL_LOOP>
I converted this to:
<li class="active"> <a href=""> <span></span> </a> </li>
this allowed me to configure my menu in config.toml like this:
[menu] [[menu.main]] name = "dh-autoreconf" url = "/projects/dh-autoreconf" weight = -110
I can also specify pre and post parts and a right menu, and I use pre and post in the right menu to render a few icons before and after items, for example:
[[menu.right]] pre = "<i class='fab fa-mastodon'></i>" post = "<i class='fas fa-external-link-alt'></i>" url = "https://mastodon.social/@juliank" name = "Mastodon" weight = -70
Setting class="active" on the menu item does not seem to work yet, though; I think I need to find out the right code for that…
Fixing up the details
Once I was done with that steps, the next stage was to convert ikiwiki shortcodes to something hugo understands. This took 4 parts:
The first part was converting tables. In ikiwiki, tables look like this:
[[!table format=dsv data=""" Status|License|Language|Reference Active|GPL-3+|Java|[github](https://github.com/julian-klode/dns66) """]]
The generated HTML table had the class="table" set, which the bootstrap framework needs to render a nice table. Converting that to a straightforward markdown hugo table did not work: Hugo did not add the class, so I had to convert pages with tables in them to the mmark variant of markdown, which allows classes to be set like this {.table}, so the end result then looked like this:
{.table} Status|License|Language|Reference ------|-------|--------|--------- Active|GPL-3+|Java|[github](https://github.com/julian-klode/dns66)
I’ll be able to get rid of this in the future by using the bootstrap sources and then having table inherit .table properties, but this requires saas or less, and I only have the CSS at the moment, so using mmark was slightly easier.
The second part was converting ikiwiki links like [[MyPage]] and [[my title|MyPage]] to Markdown links. This was quite easy, the first one became [MyPage](MyPage) and the second one [my title](my page).
The third part was converting custom shortcuts: I had [[!lp <number>]] to generate a link LP: #<number> to the corresponding launchpad bug, and [[!Closes <number>]] to generate Closes: #<number> links to the Debian bug tracker. I converted those to normal markdown links, but I could have converted them to Hugo shortcodes. But meh.
The fourth part was about converting some directory indexes I had. For example, [[!map pages="projects/dir2ogg/0.12/* and ! projects/dir2ogg/0.12/*/*"]] generated a list of all files in projects/dir2ogg/0.12. There was a very useful shortcode for that posted on the Hugo documentation, I used a variant of it and then converted pages like this to . As a bonus, the new directory index also generates SHA256 hashes for all files!
Further work
The website is using an old version of bootstrap, and the theme is not split out yet. I’m not sure if I want to keep a bootstrap theme for the website, seeing as the blog theme is Bulma-based - it would be easier to have both use bulma.
I also might want to update both the website and the blog by pushing to GitHub and then using CI to build and push it. That would allow me to write blog posts when I don’t have my laptop with me. But I’m not sure, I might lose control if there’s a breach at travis.
via Planet Debian
0 notes
Text
My Markdown-with-frontmatter-YAML-to-Tumblr-NPF (and then `pytumblr2` to the Tumblr API) code is now wrapped in a very minimal CLI, and I have written Emacs glue for calling that CLI.
I am using `docopt`, which I reach for first when I need a Python CLI MVP, because it reduces boilerplate almost entirely down to just writing the `--help` text string.
(Naturally this post was created and updated through it. Basically ":w" to save changes in my text editor, two keys to switch from this file in my editor to my shell, then rerun the publish command from history to push updates. For the initial posting, I just had to tab-complete the file path and type out my blog name.)
Edit: I have now also added
CLI to get/set my two Tumblr-specific frontmatter fields,
Emacs code to prompt me interactively to pick from one of my blog names (I use Vertico+Orderless for `fzf`-like narrowing/search in all such prompts).
Emacs function to get the target Tumblr blog from the frontmatter (or prompt if it's not in there) and then call the publish CLI.
Emacs function to call the post deleting CLI.
Code within the above two functions to automatically reload the file from the file system if it had no unsaved changes before the publish/delete (to pick up the frontmatter change made by my Tumblr CLI, since that bypasses Emacs and edits the file itself).
(Naturally these latest edits were made by calling that function from within Emacs.)
Final edit: and now, finally, I can publish/update/delete posts with just three key presses (from vi command mode, when on the post's local Markdown file in my Emacs). Naturally, this final triumphant edit was published that way.
4 notes
·
View notes
Text
This post was created and written in Emacs as Markdown (with Frontmatter YAML), and then I used my mostly-finished Python code to post it as NPF using the Tumblr API.
The Python packages I'm using are
`pytumblr2` for interacting with the API using Tumblr's "Neue Post Format",
`python-frontmatter` for reading the frontmatter (but not writing; I hate how it disruptively rearranges and reformats existing YAML),
`mistune` for the Markdown parsing, for now with just the strikethrough extension (`marko` seems like it would be a fine alternative if you prefer strict CommonMark compatibility or have other extension wants).
The workflow I now have looks something like this:
Create a new note in Emacs. I use the Denote package, for many reasons which I'll save for another post.
Denote automatically manages some fields in the frontmatter for the information it owns/manages.
Denote has pretty good code for managing tags (Denote calls them "keywords"). The tags go both in the file name and in the frontmatter. There's some smarts to auto-suggest tags based on tags you already use, etc.
The usual composable benefits apply. Denote uses completing-read to get tags from you when used interactively, so you can get nicer narrowing search UX with Vertico, Orderless, and so on.
So when I create a new "note" (post draft in this case) I get prompted for file name, then tags.
I have my own custom code to make tag adding/removing much nicer than the stock Denote experience (saves manual steps, etc).
Edit the post as any other text file in Emacs. I get all the quality-of-life improvements to text editing particular to my tastes.
If I stop and come back later, I can use any search on the file names or contents, or even search the contents of the note folder dired buffer, to find the post draft in a few seconds.
Every time I save this file, Syncthing spreads it to all my devices. If I want, I can trivially use Emac's feature of auto-saving and keeping a configurable number of old copies for these files.
I have a proper undo tree, if basic undo/redo isn't enough, and in the undo tree UI I can even toggle displaying the diff for each change.
My tools such as viewing unsaved changes with `git diff`, or my partial write and partial revert like `git add -p`, are now options I have within easy reach (and this composes with all enhancements to my Git config, such as using Git Delta or Difftastic).
After a successful new post creation, my Python code adds a "tumblr" field with post ID and blog name to the frontmatter YAML. If I tell it to publish a post that already has that information, it edits the existing post. I can also tell it to delete the post mentioned in that field, and if that succeeds it removes the field from the file too.
The giant leap of me being able to draft/edit/manage my posts outside of Tumblr is... more than halfway complete. The last step to an MVP is exposing the Python functions in a CLI and wrapping it with some Emacs keybinds/UX. Longer-term TODOs:
Links! MVP is to just add links to my Markdown-to-NPF code. Ideal is to use Denote links and have my code translate that to Tumblr links.
Would be nice to use the local "title" of the file as the Tumblr URL slug.
Pictures/videos! I basically never make posts with media, but sometimes I want to, and it would be nice to have this available.
6 notes
·
View notes
Text
Titled Post!
My code now automatically takes the title out of my frontmatter YAML and sticks it in as the first H1 (`#`-prefixed) Markdown paragraph before running it through my Markdown-to-NPF stuff.
Naturally I can also do
`#` as "Biggest" text
and
`##` as "Bigger" text
more generally.
Actually the way I wrote the code it should handle any style of level one and level two headings that `mistune` supports, but I only ever use the `#`-prefixed style when I write Markdown.
1 note
·
View note
Last Seen Blogs




