#Paul Struct
Text
XLTRA AURA
Xltra is at the forefront of the sustainable energy revolution, setting itself apart as a leader in the industry. Under the visionary leadership of its CEO, Paul Struct, the company is dedicated to delivering cutting-edge solutions that are both environmentally friendly and commercially viable.
The latest innovation from Xltra, the Aura Hybrid Engine, is a testament to the company's dedication to bringing its obligations to reality. Inspired by the Arc reactor from the Marvel Iron Man movie, this groundbreaking engine promises to deliver unprecedented levels of sustainable energy to consumers worldwide, with the potential to revolutionize how we power our lives.
Xltra is not content to rest on its laurels. The company is committed to staying ahead of the curve, pushing the boundaries of what is possible to create a better, more sustainable future for all. With a team of dedicated professionals and cutting-edge technology at their fingertips, Xltra is poised to continue setting the standard for sustainable energy solutions for years to come.
If you're interested in learning more about XLTRA UNIVERSE and their groundbreaking innovations, visit their website at xltra.net or connect to them on social media platforms at Twitter, Facebook, and LinkedIn. With Xltra at the helm, the future of sustainable energy has never looked brighter.

2 notes
·
View notes
Text
This Week in Rust 526
Hello and welcome to another issue of This Week in Rust! Rust is a programming language empowering everyone to build reliable and efficient software. This is a weekly summary of its progress and community. Want something mentioned? Tag us at @ThisWeekInRust on Twitter or @ThisWeekinRust on mastodon.social, or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub and archives can be viewed at this-week-in-rust.org. If you find any errors in this week's issue, please submit a PR.
Updates from Rust Community
Official
Blog: Launching the 2023 State of Rust Survey Survey
A Call for Proposals for the Rust 2024 Edition
Project/Tooling Updates
ratatui: a Rust library for cooking up terminal user interfaces - v0.25.0
Introducing Gooey: My take on a Rusty GUI framework
Two New Open Source Rust Crates Create Easier Cedar Policy Management
Introducing FireDBG - a Time Travel Visual Debugger for Rust
Fornjot 0.48.0 - open source b-rep CAD kernel written in Rust
Committing to Rust for kernel code
A Rust implementation of Android's Binder
Preventing atomic-context violations in Rust code with klint
Rust for Linux — in space
Observations/Thoughts
Rust is growing
A curiously recurring lifetime issue
The rabbit hole of unsafe Rust bugs
Faster Rust Toolchains for Android
The Most Common Rust Compiler Errors as Encountered in RustRover: Part 1
Nine Rules for SIMD Acceleration of your Rust Code (Part 2): General Lessons from Boosting Data Ingestion in the range-set-blaze Crate by 7x
What I Learned Making an embedded-hal Driver in Rust (for the MAX6675 Thermocouple Digitizer)
Rust Walkthroughs
Rust: Traits
Write a Toy VPN in Rust
Getting Started with Actix Web in Rust
Getting Started with Rocket in Rust
Generic types for function parameters in Rust 🦀
Benchmarking Rust Compiler Settings with Criterion: Controlling Criterion with Scripts and Environment Variables
[series] Multithreading and Memory-Mapping: Refining ANN Performance with Arroy
[series] Getting started with Tiny HTTP building a web application in Rust
Miscellaneous
Embedded Rust Education: 2023 Reflections & 2024 Visions
The Most Common Rust Compiler Errors as Encountered in RustRover: Part 1
Default arguments for functions in Rust using macros
[audio] Rust in Production Ep 1 - InfluxData's Paul Dix
[audio] Episode 160: Rust & Safety at Adobe with Sean Parent
Crate of the Week
This week's crate is constcat, a std::concat!-replacement with support for const variables and expressions.
Thanks to Ross MacArthur for the self-suggestion!
Please submit your suggestions and votes for next week!
Call for Participation
Always wanted to contribute to open-source projects but did not know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
Ockam - Fix documentation warnings
Ockam - Library - Validate CBOR structs according to the cddl schema for nodes/models/secure_channel
Ockam - Implement events in SqlxDatabase
Hyperswitch - [REFACTOR]: [Nuvei] MCA metadata validation
Hyperswitch - [FEATURE] : [Noon] Sync with Hyperswitch Reference
Hyperswitch - [FEATURE] : [Zen] Sync with Hyperswitch Reference
Hyperswitch - [REFACTOR] : [Authorizedotnet] Sync with Hyperswitch Reference
If you are a Rust project owner and are looking for contributors, please submit tasks here.
Updates from the Rust Project
386 pull requests were merged in the last week
enable stack probes on aarch64 for LLVM 18
add new tier 3 aarch64-apple-watchos target
add hexagon support
add the function body span to StableMIR
allow async_fn_in_trait traits with Send variant
cherry-pick "M68k: Fix ODR violation in GISel code (#72797)"
AIX: fix XCOFF metadata
-Ztrait-solver=next to -Znext-solver
actually parse async gen blocks correctly
add a method to StableMIR to check if a type is a CStr
add more suggestions to unexpected cfg names and values
add support for --env on tracked_env::var
add unstable -Zdefault-hidden-visibility cmdline flag for rustc
annotate panic reasons during enum layout
attempt to try to resolve blocking concerns (RFC #3086)
avoid overflow in GVN constant indexing
cache param env canonicalization
check FnPtr/FnDef built-in fn traits correctly with effects
check generic params after sigature for main-fn-ty
collect lang items from AST, get rid of GenericBound::LangItemTrait
coroutine variant fields can be uninitialized
coverage: skip instrumenting a function if no spans were extracted from MIR
deny ~const trait bounds in inherent impl headers
desugar yield in async gen correctly, ensure gen always returns unit
don't merge cfg and doc(cfg) attributes for re-exports
erase late bound regions from Instance::fn_sig() and add a few more details to StableMIR APIs
fix ICE ProjectionKinds Deref and Field were mismatched
fix LLD thread flags in bootstrap on Windows
fix waker_getters tracking issue number
fix alignment passed down to LLVM for simd_masked_load
fix dynamic size/align computation logic for packed types with dyn trait tail
fix overlapping spans in delimited meta-vars
ICE 110453: fixed with errors
llvm-wrapper: adapt for LLVM API changes
make IMPLIED_BOUNDS_ENTAILMENT into a hard error from a lint
make exhaustiveness usable outside of rustc
match lowering: Remove the make_target_blocks hack
more expressions correctly are marked to end with curly braces
nudge the user to kill programs using excessive CPU
opportunistically resolve region var in canonicalizer (instead of resolving root var)
properly reject default on free const items
remove unnecessary constness from ProjectionCandidate
replace some instances of FxHashMap/FxHashSet with stable alternatives (mostly in rustc_hir and rustc_ast_lowering)
resolve: replace visibility table in resolver outputs with query feeding
skip rpit constraint checker if borrowck return type error
some cleanup and improvement for invalid ref casting impl
tweak short_ty_string to reduce number of files
unconditionally register alias-relate in projection goal
update FreeBSD CI image
uplift TypeAndMut and ClosureKind to rustc_type_ir
use if cfg! instead of #[cfg]
use the LLVM option NoTrapAfterNoreturn
miri: visit the AllocIds and BorTags in borrow state FrameExtra
miri run: default to edition 2021
miri: make mmap not use expose semantics
fast path for declared_generic_bounds_from_env
stabilize type_name_of_val
stabilize ptr::{from_ref, from_mut}
add core::intrinsics::simd
add a column number to dbg!()
add more niches to rawvec
add ASCII whitespace trimming functions to &str
fix cases where std accidentally relied on inline(never)
Windows: allow File::create to work on hidden files
std: add xcoff in object's feature list
codegen: panic when trying to compute size/align of extern type
codegen_gcc: simd: implement missing intrinsics from simd/generic-arithmetic-pass.rs
codegen_llvm: set DW_AT_accessibility
cargo: clean up package metadata
cargo: do not allow empty name in package ID spec
cargo: fill in more empty name holes
cargo: hold the mutate exclusive lock when vendoring
rustdoc: use Map instead of Object for source files and search index
rustdoc: allow resizing the sidebar / hiding the top bar
rustdoc-search: fix a race condition in search index loading
rustdoc-search: use set ops for ranking and filtering
bindgen: use \r\n on windows
bindgen: better working destructors on windows
clippy: add new unconditional_recursion lint
clippy: new Lint: result_filter_map / Mirror of option_filter_map
clippy: don't visit nested bodies in is_const_evaluatable
clippy: redundant_pattern_matching: lint if let true, while let true, matches!(.., true)
clippy: do not lint assertions_on_constants for const _: () = assert!(expr)
clippy: doc_markdown Recognize words followed by empty parentheses () for quoting
clippy: fix binder handling in unnecessary_to_owned
rust-analyzer: deduplicate annotations
rust-analyzer: optimizing Performance with Promise.all 🏎
rust-analyzer: desugar doc correctly for mbe
rust-analyzer: dont assume ascii in remove_markdown
rust-analyzer: resolve alias before resolving enum variant
rust-analyzer: add minimal support for the 2024 edition
rust-analyzer: move out WithFixture into dev-dep only crate
rust-analyzer: fix false positive type mismatch in const reference patterns
rust-analyzer: syntax fixup now removes subtrees with fake spans
rust-analyzer: update builtin attrs from rustc
rust-analyzer: fix fragment parser replacing matches with dummies on incomplete parses
rust-analyzer: fix incorrectly replacing references in macro invocation in "Convert to named struct" assist
Rust Compiler Performance Triage
A lot of noise in the results this week; there was an lull in the noise recently, so our auto-inferred noise threshold went down, and thus five PR's were artificially flagged this week (and three supposed improvements were just reverting to the mean). Beyond that, we had three nice improvements: the first to debug builds in #117962 (by ceasing emission of expensive+unused .debug_pubnames and .debug_pubtypes), a second to diesel and serde in #119048 (by avoiding some unnecessary work), and a third to several benchmarks in #117749 (by adding some caching of an internal compiler structure).
Triage done by @pnkfelix. Revision range: 57010939..bf9229a2
6 Regressions, 9 Improvements, 3 Mixed; 5 of them in rollups 67 artifact comparisons made in total
Full report here
Approved RFCs
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
No RFCs were approved this week.
Final Comment Period
Every week, the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
RFCs
[disposition: postpone] RFC: Precise Pre-release Deps
Tracking Issues & PRs
[disposition: merge] Support async recursive calls (as long as they have indirection)
[disposition: merge] make soft_unstable show up in future breakage reports
[disposition: merge] Tracking Issue for ip_in_core
Language Reference
No Language Reference RFCs entered Final Comment Period this week.
Unsafe Code Guidelines
No Unsafe Code Guideline RFCs entered Final Comment Period this week.
New and Updated RFCs
RFC: patchable-function-entry
Call for Testing
An important step for RFC implementation is for people to experiment with the implementation and give feedback, especially before stabilization. The following RFCs would benefit from user testing before moving forward:
No RFCs issued a call for testing this week.
If you are a feature implementer and would like your RFC to appear on the above list, add the new call-for-testing label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature need testing.
Upcoming Events
Rusty Events between 2023-12-20 - 2024-01-17 🦀
Virtual
2023-12-20 | Virtual (Vancouver, BC, CA) | Vancouver Rust
Adventures in egui app dev
2023-12-26 | Virtual (Dallas, TX, US) | Dallas Rust
Last Tuesday
2023-12-28 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
2024-01-03 | Virtual (Indianapolis, IN, US) | Indy Rust
Indy.rs - with Social Distancing
2024-01-09 | Virtual (Dallas, TX, US) | Dallas Rust
Last Tuesday
2024-01-11 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
2024-01-16 | Virtual (Washington, DC, US) | Rust DC
Mid-month Rustful
Europe
2023-12-27 | Copenhagen, DK | Copenhagen Rust Community
Rust hacknight #1: CLIs, TUIs and plushies
2023-12-28 | Vienna, AT | Rust Vienna
Rust Dojo 3: Holiday Edition
2024-01-11 | Reading, UK | Reading Rust Workshop
Reading Rust Meetup at Browns
2024-01-11 | Wrocław, PL | Rust Wrocław
Rust Meetup #36
2024-01-13 | Helsinki, FI | Finland Rust-lang Group
January Meetup
North America
2023-12-20 | Austin, TX, US | Rust ATX
Rust Lunch - Fareground
2023-12-27 | Austin, TX, US | Rust ATX
Rust Lunch - Fareground
2024-01-06 | Boston, MA, US | Boston Rust Meetup
Beacon Hill Rust Lunch
2024-01-08 | Chicago, IL, US | Deep Dish Rust
Rust Hack Night
2024-01-09 | Seattle, WA, US | Cap Hill Rust Coding/Hacking/Learning
Rusty Coding/Hacking/Learning Night
2024-01-09 | Minneapolis, MN, US | Minneapolis Rust Meetup
Minneapolis Rust Meetup Happy Hour
2024-01-14 | Cambridge, MA, US | Boston Rust Meetup
Alewife Rust Lunch
2024-01-16 | San Francisco, CA, US | San Francisco Rust Study Group
Rust Hacking in Person
2024-01-17 | Chicago, IL, US | Deep Dish Rust
Rust Happy Hour
If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Jobs
Please see the latest Who's Hiring thread on r/rust
Quote of the Week
The Tianyi-33 satellite is a 50kg class space science experimental satellite equipped with an operating system independently developed by Beijing University of Posts and Telecommunications—the Rust-based dual-kernel real-time operating system RROS. RROS will carry out general tasks represented by tensorflow/k8s and real-time tasks represented by real-time file systems and real-time network transmission on the satellite. It will ensure the normal execution of upper-layer applications and scientific research tasks, such as time-delay measurement between satellite and ground, live video broadcasting, onboard web chat services, pseudo-SSH experiments, etc. This marks the world’s first official application of a Rust-written dual-kernel operating system in a satellite scenario.
– Qichen on the RROS web page
Thanks to Brian Kung for the suggestion!
Please submit quotes and vote for next week!
This Week in Rust is edited by: nellshamrell, llogiq, cdmistman, ericseppanen, extrawurst, andrewpollack, U007D, kolharsam, joelmarcey, mariannegoldin, bennyvasquez.
Email list hosting is sponsored by The Rust Foundation
Discuss on r/rust
2 notes
·
View notes
Text
THEY THINK THAT THERE WILL BE MORE COMPLICATED, LEGALLY, IF ANY, IS IN THE EARLY 1990S, HARVARD DISTRIBUTED TO ITS FACULTY AND STAFF A BROCHURE SAYING, AMONG OTHER THINGS, INCUBATORS USUALLY MAKE YOU WORK IN SALES OR MARKETING
There's a hack for being decisive when you're inexperienced: ratchet down the coolness of the idea after quitting because otherwise their former employer would own it. The danger here is that people don't need as much of a threat.1 At this stage the company is just a matter of writing a dissertation. Plus there aren't the same forces work in the other direction. The programmers become system administrators, and so did a YC founder I read the papers I found out why. Ok, so we decided to write some software, it might be worth a lot of the great advantages of being first to market are not so bad: most of the startups we've funded so far are pretty quick, but they didn't have the courage of their convictions, and that was called playing. Geoff Ralston for reading drafts of this. Companies often claim to be benevolent, but it didn't seem ambitious enough.2 We don't encourage people to start calling them portals instead. In retrospect, we should expect its shortness to take us by surprise. And while there are many popular books on math, few seem good.3 And indeed, that we would not want to make it to profitability on this money if you can.
I phrased that as a kid, they can be swapped out for another supplier.4 I just wanted to fix a serious bug in OS X, Apple has come back from the airport, I still managed to fall prey to distraction, because I know the structs are just vectors underneath. But only one company we've funded has so far remained independent: money guys undervalue the most innovative startups. I went to my mother afterward to ask if they are, because it's common to see families where one sibling has much more of a sophisticated form of ad hominem than actual refutation. Not in the Enron way, of course, quite a lot of progress in that department so far. But invariably they're larger in your imagination than in real life. Raising more money just lets us do it faster. Its graduates didn't expect to do the things a startup founder.5 Version 1s will ordinarily ignore any advantages to be got from specific representations of data.6 Thanks to Sam Altman, Ron Conway, for example, so competition ensured the average journalist was fairly good.
Notes
Note: This is not a remark about the details. Startups Condense in America. But it takes more than clumsy efforts to protect themselves.
A fundraising is the place for people interested in you, it becomes an advantage to be doctors?
The question to ask prospective employees if they were saying scaramara instead of just Japanese. The ironic thing is, so it may be useful here, which you are unimportant. According to a can of soup.
But friends should be asking will you build for them by the normal people they're usually surrounded with. Most new businesses are service businesses and except in the foot.
And it would destroy them. Http://paulgraham.
What you're looking for initially is not a problem this will be, yet. I know of at least wouldn't be irrational. Predecessors like understanding seem to have fun in this evolution.
#automatically generated text#Markov chains#Paul Graham#Python#Patrick Mooney#structs#employer#problem#playing#people#service#money#Note#market#direction#stage#company#Http#advantages#Enron#Predecessors#representations#businesses#guys#Thanks#life
0 notes
Text
Group members:
Celeste Badonio
Jhona Abecia
Meralyn Simbajon
Crezea mae Indat
Jerome Indat
Bachelor of Public Administration-2B
Drills/Exercises

Activity: 1
Write T if the statement is true and write if it is False.
1. Knowledge Management is a good business practice because it is an organized management that would assist the knowledge assets.
2. You can be effective business holder even without knowing the concept of knowledge management.
3. Knowledge is a personal knowledge of a person that resides in the human mind.
4. Knowledge management is a conscious process of defining,structing,retaining and sharing the knowledge and experience of employee within the organization.
5. Acquiring a lot of learnings can improve performance of employees within the organization.
Activity: 2
Choose the letter of the correct answer.
1. A person who coined the term knowledge worker and knowledge work.
A. Peter Drucker
B. Doug Engel
C. Doug Engelbert
2. A person who develop hypertext,groupware,windowing and other tools for online collaboration was.
A. Peter Drucker
B. Doug Engelbert
C. Extienne Wenger
3. This kind of knowledge that resides the mind of a person.
A. Explicit knowledge
B. Tacit knowledge
C. Both A and B
4. This knowledge is intangible form?
A. Explicit knowledge
B. Tacit knowledge
C. None of the above
5. In order to make a better concept of knowledge management everyone which is a part of a certain corporation must.
A. Cooperate
B. Believe
C. Suggest
From Module 1-7

S and R
Summary:
As we all know knowledge, is compose of skill, experience and vision which provide us the key for creating, evaluating and using the information. Since we are studying knowledge management. We should have to know what is it all about and how important it is. We all know that knowledge has been divided into two types, which is the tacit and explicit. Tacit knowledge is the personal knowledge of a person that resides in the human mind. While explicit knowledge is set out intangible form.
Also there are many definitions and descriptions about knowledge management which has been written by the person who studying on it. But despite of the different definition and descriptions about knowledge. The important on it is to help individuals improve their learning efficiency and combine different information resources to improve competitiveness. And KM is capable of providing each individuals with some tools and techniques they need to conquer the information they encounter which enable them to improve their learning edge. We learn also that knowledge management has a process and stages where many related activities are formed to carry out key elements of strategy and operation KM.

Now a days we have seen that there are many businesses, corporation and organization has been built. So it is important to know the concept of knowledge management. Which include the process, strategies, design and emplementation in order to have a better and successful business, organization and corporation. That was important thing we have learn from taking knowledge management. But in taking knowledge management other individuals experience difficulties and challenges. Like for example" a certain company in doing business projects or business proposal, there are other person which a member of the company will not easily approve what you make or what you have done. Maybe because they always believe on their own.
Knowledge management is a conscious process of defining, structing, retaining and sharing the knowledge and experience of employee with in the organization. The main goal of knowledge management is to improve an organization effeciency and save knowledge with in the company. On the year 1970 Peter ducker and Paul strassman published the early development of knowledge management and was stated on this paper the importance of information and explicit knowledge as valuable assets of organization. That focuses on the learning organization there was also a studies made by Everett Rogers and Thomas Allen that technology has great help in transferring of knowledge through the knowledge management there was a big business happen and widely recognised that the competitive edge of some of the world's leading companies. By the end of the 1990s big businesses started to build up knowledge management solutions. It was a rage and came to be seen as an ideal to the failed Total Quality Management (TQM) and business process re engineering initiatives. That results in being source of revenue for major international consulting firms.
For many large innovative corporations such as the World Bank, knowledge management has become a standard to conduct business. There are also a many practitioners in the field of knowledge management and a phenomenal growth in the number of periodicals and magazines with knowledge management in their title.
* First generation knowledge management it focuses on knowledge management but limited concept of knowledge. It help to enhance learning and technology focus.
* Second generation knowledge management it focuses on the processing of knowledge management and faster knowledge creation and improves learning with or without the usage of technology.
Knowledge Management features and attributes : knowledge management is a good business practice because it is an organized management that world assist the knowledge assets creating values and meeting tactical strategic requirements ; it consist of the initiatives process, strategies and system that enhance the storage assessment, sharing and refinement and creation of knowledge. Thus, knowledge management is more than a business practice. You cannot establish a business without knowing the concept of knowledge management. We learned that business aspect management is highly needed, in order to obtain a successful outcome. So, you cannot be an effective business holder without knowing the principle of knowledge management. It can also improve performances in work in a way that it enhances the performance of the people inside the organization. While teaches us also to promote a culture which is conducive to learning and sharing. Because, through sharing can acquire another learnings. When there would be more learnings acquired inside the organization, then it will enhance the work performance by the people inside. Knowledge management had also acquired contribution from information technology infrastructure in a way that technology able to connect people with in the certain organization despite of their distances in location but through the use of email environment it will become easier for the organization. There are also tools within this said infrastructure, these three principal technology infrastructures which are to organize content, to search information and to locate appropriate expertise. We have also to remember that knowledge management will not work and it is useless when the corporation doesn't utilize what they have learned. When a certain corporation have obtain and even understand the concept of knowledge management but without applying its process and strategy nothing will happen to an organization.
RESPONSES:
In order to make a better concept of knowledge management each individuals which is a part of an organization or in a corporation must cooperate. They must have to share there knowledge with each other. So that they will able to have a confidence to express there ideas and they will not be afraid to face challenges and difficulties. And in response to the difficulties and challenges in a certain business we must be patient in what we are doing. It is because to be successful we must going to win from those challenges and failures that we are going to encounter. So as a public servant in the future. We must have to know well th concept of knowledge management. And learn also the thing that is about on knowledge management. Because we can apply it when we are going to have work as a public servant. Or even if we working in other establishment. The concept of knowledge management is very essential to each individual that's why we must have to learn and use it as we go on with our everyday life.
In able to do the concept of knowledge management we must have to consider the important thing so that we can make the concept of knowledge management better which include the people, technology and the process on making it. People include attitudes, sharing, skills, innovation, teamwork. And technology is where we store data, formats, networks, Internet. Then the process which includes knowledge management maps, workflows, integration, best practices and intelligence. This is how important is the copcept of knowledge management that's why we must have learn and appreciate on it.
Knowledge management is very important and we have to learn its concept. Learning how to manage knowledge is not enough we have also to utilize what we have learned. We have also to consider that technology has a great contribution of implementing, sharing and even in acquiring some new sets of knowledge. It is very important to practice that learnings we acquired to attain enhancement.

About the Authors
The authors of this, are came from Magsaysay College. The purpose of making this portfolio is to give features about the concept of knowledge management and how it can give importance to facilitate the acquired knowledge with the use of information technology the acquired knowledge would be enhanced. The authors of this site are just summarizing how important is the knowledge management in order for us to be effective in performing our daily task. The authors were just expressing their personal ideas and opinions on their chosen particular topics. It contains some short exercises,trivia about KM and ICT which maybe somebody can acquire a bit of learnings.
KM & ICT

1. Only about 10% of the world's currency is physical money, the rest only exists on computers.
2. TYPEWRITER is the longest word that you can write using the letters only one row of the keyboard of your computer.
3. The average human being blinks 20 times a minute - but only 7 times a minute when using a computer.
4. If there was a computer as powerful as the human brain, it would be able to do 38 thousand trillion operaions per second and hold more than 3580 terabytes of memory.
5. HP, Microsft and Apple have one very interesting thing in the common-they were all started in a garage.
6. The first ever hard disk drive was made in 1979, and could hold only 5MB of data.
7. The first 1GB hard disk drive was announced in 1980 which weighed about 550 pounds, had a price tag of $40,000.
8. In 1936, the Russians made a computer that ran on water.
9. The first popular web browser was called Mosaic and was released in 1993.
10. The first computer mouse, constructed in 1964 , was made out of wood.
2 notes
·
View notes
Text
Directions Your boss, Paul, was so impressed with the work you did on the struct
Directions Your boss, Paul, was so impressed with the work you did on the struct
Directions
Your boss, Paul, was so impressed with the work you did on the structured walk-through/peer review, that he has assigned you a new task. Paul recently attended a meeting about a potential new client, Acme Electric, LLC., and has asked us to create a new system for his company. The owner of Acme Electric, LLC., Tom, envisions a website for potential customers to get information about…
View On WordPress
0 notes
Text
Rear extension by Turner Architects contains "cloister-like" rooms built around a central courtyard
Turner Architects has renovated and extended a Georgian terraced house in south London, creating a sequence of living spaces interspersed with courtyards that bring the changing colours of the seasons inside.
The brief for A Cloistered House was to give a new lease of life to a three-storey residence in Clapham that had been abandoned for several years and was in a poor state internally.
Top: Turner Architects has extended a Georgian house in London. Above: the studio also restored the three-storey dwelling
Turner Architects restored the existing Georgian building and created new communal living spaces, which are accommodated in a large extension that opens onto the rear garden.
The project was recently announced as the winner of the Urban Oasis of the Year prize at the 2021 Don't Move, Improve! contest.
Pale green walls line the entrance hall
The extension at A Cloistered House incorporates a pair of courtyards that separate some of the living areas and introduce protected outdoor spaces at the centre of the home.
The dining room and kitchen are accommodated at the rear of the extension closest to the garden, and separated from a living room in the middle of the plan by one of the courtyards.
The home's original features were restored
"Conversations we had with the clients resulted in this formal courtyard arrangement at the back of the extension," architect Paul Turner told Dezeen.
"The single cherry tree in the central courtyard becomes like a timepiece for the seasons, with the family able to watch the blossoms appear in spring and the leaves changing colour."
The studio added a 14-metre-long rear extension
A second sunken courtyard to the rear of the existing building functions as a light well that allows natural light to reach a bedroom and playroom on the lower ground floor.
Turner explained that inspiration for the enclosed gardens came from Dutch courtyard paintings admired by the clients, as well as from monastic cloisters and east-Asian courtyard houses.
Sliding doors enclosing the central courtyard can be opened to connect the living and dining spaces on either side. The dining and kitchen area can also be opened up to the garden by retracting the concertinaed glass doors lining this space.
"It was about ensuring that the house can open and close as required," the architect added. "On a nice summer's day they have a really private, protected outdoor space at the heart of the home that can open up to become one big space."
A geometric ceiling covers the living area
A Cloistered House is located within a conservation area, so the 14-metre-long extension was designed to be subservient to the existing property and to ensure it does not impact the neighbouring houses.
The extension's floor level was lowered to prevent the roof height from extending above the fences on either side. Its angular roof provides glimpses of the sky and is covered in grass and wildflowers to maintain the site's overall green area.
The refurbishment of the existing building sought to restore the formal arrangement of internal spaces, whilst making them suitable for modern living.
The extension contains two internal courtyards
According to Turner, the objective of A Cloistered House's renovation was to create "two good rooms on each floor", with a room to the front and another to the rear, supplemented by bathrooms and utility spaces.
The cellular arrangement of bedrooms, studies and bathrooms echo the living spaces found in typical courtyards or monastic accommodation. These spaces also protect the extension from the bustle of the adjacent street.
The kitchen is finished with wooden cabinetry
"You have busy London life happening at the front of the house," added Turner, "with the existing house becoming a defensive wall shielding the quiet, private areas for family gathering at the back."
Throughout the existing building, original features such as cornicing and windows were restored or replaced. The extension has a contrasting modern aesthetic, with white-painted walls, cement kitchen worktops and iroko-wood cabinetry forming a reduced material palette.
Bifold doors open out to the garden
Other projects featured on the shortlist for the annual Don't Move Improve! competition, which is organised by New London Architecture, include the colourful renovation of a townhouse in Islington by Office S&M, and Fraher & Findlay's extension of a self-build modular house.
Photography is by Adam Scott.
Project credits:
Architect: Turner Architects
Engineer: Bini Struct-E ltd
Kitchen: West and Reid
The post Rear extension by Turner Architects contains "cloister-like" rooms built around a central courtyard appeared first on Dezeen.
0 notes
Text
Utilizing Machine Learning for Better Bioprocess Development – Genetic Engineering & Biotechnology News
In machine learning (ML), machines—computer programs—learn and improve based on the assessment of historical data without being directed to do so. This process allows them to improve the accuracy of predictions or decisions they make.
ML is part of the wider field of artificial intelligence. But, unlike AI which seeks to mimic human intelligence, ML is focused on a limited range of specific tasks. The ML concept is already being used in areas like drug discovery1. For example, last year GSK2 shared details of its use of ML in vaccine development. Likewise, in July the Gates Foundation awarded A-Alpha Bio $800,000 to use machine learning to optimize protein therapeutics for infectious diseases.3
But ML also has potential in the process development suite and on the factory floor according to Moritz von Stosch4, chief innovation office at analytics and process modeling firm DataHow.
“ML can be used for development, monitoring, control and optimization. ML is better at learning complex relationships—for example between process parameters and process performance—than humans and it can make better predictions of what might be happening for slightly different scenarios.”
Quality data costs
Data quality is key to any ML strategy and this is the biggest challenge for the biopharmaceutical industry, von Stosch says.
“Data quality is typically poor, data pre-processing anecdotally requiring 80% of the total effort in any machine learning project. Data quantity is rather low as in bioprocess development the generation of data costs money,” he continues. “Generally in bioprocess development we face the curse of dimensionality because of the large number of parameters and getting informative data for all possible parameter combinations is impossible, wherefore we need to add process knowledge to ML.”
Combining process knowledge to ML—which von Stosch calls5 “hybrid modeling”—aims to generate more insights than MLs alone to increase process understanding and develop models that can better forecast system behavior.
As well as high quality data, biopharmaceutical companies thinking about using ML need to make clear which parameters they want to model.
“The key” von Stosch said is “framing the problem, such that it is concise and can be solved by a machine. He explained that providing the learning algorithm with the correct parameters is critical. “For instance, if you train the machine with data of sugar content of grape juice and the alcohol content after it has been fermented, then the machine is able to predict the alcohol content if you provide with the sugar content of a novel grape juice,” he pointed out. “However, it will not be able to predict the alcohol content based on the mass of grapes that was used to make the juice.”
References
Réda C, et al. Machine learning applications in drug development. Comput Struct Biotec. 2020;18: 241–252.
Smyth Paul et al. Machine learning in research and development of new vaccines products: opportunities and challenges. ESANN 2019.
A-Alpha Bio Awarded $800K to Develop Infectious Disease Drugs using AlphaSeq Platform.
Narayanan H, et al. Bioprocessing in the Digital Age: The Role of Process Models. Biotechnol. J. 2019, 15, 1900172.
von Stosch M, et al.Hybrid modeling for quality by design and PAT‐benefits and challenges of applications in biopharmaceutical industry. Biotechnol J. 2014, 9: 719–726.
Source
The post Utilizing Machine Learning for Better Bioprocess Development – Genetic Engineering & Biotechnology News appeared first on abangtech.
from abangtech https://abangtech.com/utilizing-machine-learning-for-better-bioprocess-development-genetic-engineering-biotechnology-news/
0 notes
Text
To Error is Erhman: Randal Ming and Randall Birtell Examine the book Misquoting Jesus

(Originally printed in the Fall 2006 Issue of the MCOI Journal page 16)
Truth and Meaning As It Relates To History Bart Ehrman, in Misquoting Jesus,(( Bart Ehrman, Misquoting Jesus; San Francisco: Harper Collins, 2005)) intends to explain New Testament textual criticism. One theme Ehrman uses to explain textual criticism is that the scribes, copyist, and the people of power who controlled the early Church did not preserve the New Testament but slanted the New Testament texts to read as they believed and collected the books that agreed with the theology of the people in power. For Ehrman, there is no true theology and no historically true Christian doctrine. He alleges the New Testament is a collection of books preserved and collected because the group of people who controlled the early Church agreed with the theology in these texts. Ehrman believes the New Testament canonical books are not the work of God and so preserved, distinguished, and used by the early Church because they were true and corresponded with the teachings of the Lord Jesus Christ; nor were the writers directed by the Holy Spirit to teach, instruct, and rebuke the Church. According to Ehrman, the Bible is not based in history, because there is no history. The Evangelical world traditionally has held a particular view and understanding about the fact of history. Evangelical understanding is that history is what corresponds to the facts about events of the past. This idea does not rule out people twisting the facts they recorded to make themselves look good or the fact of people being blinded by their sin nature. Most historians would agree that many of the inscriptions made by the Egyptians about their battles and conflicts were intended to make the pharaoh look good even if the pharaoh had lost the battle. But, we must remember that we only can make such a statement about the Egyptians historians if there really are historical facts that do not line up with what the historian has recorded. A true base of what really happened must exist in order to state that people have changed the facts to suit their purpose. History must have a factual foundation before anyone can say recorded history is true or false. Ehrman’s history is defined to be a collection of people’s perspectives about what happened with no foundation for historical truth to say this happened and this did not happen. No truth exists to be recorded about the events of Christ’s earthly ministry. Thus, the Gospels are personal opinions about the events recorded in them and what the Gospel writers thought motivated Jesus to do what he did. As well, any event may be modified to suit the purpose of the writer to build a “moral truth” as they saw it. Ehrman comes to this conclusion because his understanding of meaning and reality has been shaped by agnosticism. Having no basis for truth and meaning, Ehrman’s hermeneutic cannot help but be skewed by postmodern thought.((What if we have to figure out how to live and what to believe on our own, without setting up the Bible as a false idol—or an oracle that gives us a direct line of communication with the Almighty?; Ehrman, 14)) For Ehrman, the only truth is personal belief. Truth must be redefined to what one believes is history rather than what corresponds to the reality of history. In Ehrman’s world, the Bible only can be a collection of religious thoughts about God by various people and at various times. Ehrman explains: Just as human scribes had copied, and changed, the texts of scripture, so to had human authors originally written the texts of scripture. This was a human book from beginning to end. It was written by different human authors at different times and in different places to address different needs. Many of these authors no doubt felt they were inspired by God to say what they did, but they had their own perspectives, their own understandings, their own theologies; and these perspectives, beliefs, views, needs, desires, understandings, and theologies informed everything they said.”(( Ehrman, 11-12)) Any person left to employ personal truth as the gauge for truth will end in relativism. The consequences of this are moral deconstruction, historical deconstruction, literary deconstruction, and biblical deconstruction. Scripture soundly renounces these positions: “In the beginning was the Word and the Word was with God and the Word was God” (John 1:1). As Creator, Jesus has not only defined the physical world, but He—as the Word—has also defined Scripture. Jesus is the connection between words and actions. Jesus—as Creator—has defined truth and meaning. The philosophical movement—Post structuralism (PS)—has gathered steam over the past 40 years. PS removes any certainty to the reading and meaning of a text. This can be termed the “death of the writer” and “the birth of the reader.” The reasoning is: Time, social situations, and a host of other elements change the meaning of a text. Thus, when a reader comes to the text, they come with a list of their own interpretive ideas. Each reader has a personal hermeneutic. The intent of the author is trumped by the understanding of the reader. Listen to Columbia History of Western Philosophies examination of the French philosopher Jacques Derrida: Given Derrida’s assertion of the radical indeterminacy of all signification that follows from his investigation of language, his proclamations of the inevitable and unavoidable instability of meaning and identity portend the evisceration of metaphysics. He mounts this radical critique of metaphysics, identity, and meaning by pushing it to the very level of signification and challenging the possibility of stable meanings or identities on the basis of their reliance on a metaphysics of presence … “Deconstruction thus purports to expose the problematic nature of any—that is to say, all—discourse that relies on foundational metaphysical ideas such as truth, presence, identity, or origin to center itself.(( Richard H. Popkin, Columbia History of Western Philosophy; Columbia University Press, New York: 1999; 739)) Ehrman’s position is similar: And so to read a text is, necessarily to change a text.((Ehrman, 217)) Ehrman’s problem is, thus, threefold. First, there is no true history to be recorded, so the New Testament is a record of people’s “truths.” Second, the New Testament as we have it today has the theological view of those people and scribes that collected and edited the New Testament. So, orthodoxy is not a reflection of truth. Lastly, were there a true history to be recorded and were that history to be handed down to us in the New Testament, we still would have no idea of what is true because we—the reader—and not the author are lord of the meaning of the text. However, all meaning is lost without God. God has given all men the light of Creation, the light of conscience, and a basis for understanding of truth (moral and otherwise).(( Romans 1)) This allows men to think, make sense of reality, and draw closer to God. Man, in his depravity backs away from this moral calling of God to renew the mind (Romans 12:2) in favor of becoming his own god and having his own truth. Orthodoxy Is there any truth in religion? Is there any truth in Christian orthodoxy? Or, as with “history,” the group who ultimately wins the battle of supremacy gets to define “orthodoxy” as Ehrman explains. The Christian understanding of orthodoxy is no different than her understanding of truth. Orthodoxy must correspond with reality. Orthodoxy is not a matter of taste or feeling. Orthodoxy is the foundational truths of the Christian faith as taught by the Lord and Savior Jesus Christ and the writers of the New Testament as they were inspired by the Holy Spirit to remember the teaching of Jesus or lead by the Holy Spirit to record the nature of God, man, and the Church. Ehrman contrasts this understanding of truth and orthodoxy: Each and every one of these viewpoints—and many others besides—were topics of constant discussion, dialogue, and debate in the early centuries of the church, while Christians of various persuasions tried to convince others of the truth of their own claims. Only one group eventually ‘won out’ in these debates. It was this group that decided what the Christian creeds would be: the creeds would affirm that there is only one God, the Creator; that Jesus his Son is both human and divine; and that salvation came by his death and resurrection.((Ehrman, 153)) Ehrman also states: The group that established itself as ‘orthodox’ (meaning that it held what it considered to be the ‘right belief’) then determined what future Christian generations would believe and read as scripture.((Ibid. 154)) The idea that there is one God, as Ehrman explains, is not based on what is true but on who won the struggle for power. The ideas recorded in the Christian creeds are not true but are a literary snapshot of the political situation in the late Roman Empire. Orthodox teaching is a record of what group outwitted their rivals for power and in so doing preserved their theological ideas as well. Ehrman’s usage of the word proto-orthodox((Ibid. 169, 171, 173)) helps us to understand his twist or definition of the term orthodoxy. Paul and all the New Testament writers, in the eyes of Ehrman, did not write about truth but about what they believed. This is in complete contradiction to what Scripture has to say about itself. “All Scripture is inspired by God and profitable for teaching, for reproof, for correction, for training in righteousness; so that the man of God may be adequate, equipped for every good work.” (2 Tim. 3:16) The position of Ehrman and Scripture are in logical opposition to one another—both cannot be true. Inspiration Scripture is authoritative because it is divinely inspired—another idea Ehrman rejects. The ideas found in the pages of the Bible came not from man, but from God. An important point in the orthodox understanding of inspiration is that inspiration refers to the original writings. Manuscripts whether written in Hebrew, Greek, Latin, English, or any other language are copies of the original inspired works, and as such, most contain minor errors.((It is possible to have a manuscript that is an exact replica of the original. However, we are aware of no current consensus of scholars who claim to have such a copy.)) Ehrman traces his loss of faith in the Bible as he left Wheaton College and began studying at Princeton. His own words speak how his view of inspiration changed: … I began seeing the New Testament as a very human book. The New Testament as we actually have it, I knew, was the product of human hands, the hands of the scribes who transmitted it. Then I began to see that not just the scribal text but the original text itself was a very human book. This stood very much at odds with how I regarded the text in my late teens as a newly minded ‘born-again’ Christian, convinced that the Bible was the inerrant Word of God and that the biblical words themselves had come to us by the inspiration of the Holy Spirit.(( Ehrman, 211)) His critique of the orthodox view of inspiration can be summarized as follows: Meaning only can be found in the original language. (p.7)
We do not have the original manuscripts. (p.7)
We do have “error-ridden copies”. (p.7)
The authors also made errors. (p.11)
The Bible originated in the mind of men. (p.11)
Ehrman hardly gives a logical argument. For instance: In point four, he gives no defense for his conclusion that the original authors made mistakes. How does he know they error when we do not have the original writings—the very thing Ehrman points out again and again! Ehrman suggests that a simple cough during the recitation of the original author to a scribe could have occurred, and thus, a mistake in the original would have resulted. He gives no evidence to support his theory. Ehrman seems to have faith in events for which there is no record. Further, point one is false. Objective meaning is transcendent of any particular language. Language only describes reality; it does not create it. As an example, let’s say my daughter Kayla tells a young Mexican boy, “Jesús te ama.” I turn to ask her what she said to the boy. She tells me she said, “Jesus loves you.” I do not have to understand the originating language to understand what Kayla meant. All I needed was a translator. That is precisely what Hebrew and Greek linguistic scholars aim to do—translate the original language into the common vernacular without losing the meaning. Inerrancy A deduction made by Ehrman, as he looks at the manuscript evidence, is that the Bible is not inerrant. He states that some scholars claim 400,000 or more variants.((Ibid. 89)) He uses this evidence to support his idea that the Bible is error-ridden. But is this the case? It should be noted that when textual critics count errors, they are looking at a multiplicity of manuscripts.((The very thing that brings increasing accuracy to our translations, namely the vast and growing number of manuscripts available, Ehrman uses to point out inconsistency and error)) Drs. Norman Geisler and William Nix note in their book A General Introduction to the Bible that: There is an ambiguity in saying that there are some 200,000 variants in the existing manuscripts of the New Testament because those represent only 10,000 places in the New Testament. If one single word is misspelled in 3,000 different manuscripts, it is counted as 3,000 variants or readings. Once this counting procedure is understood … the remaining significant variants are surprisingly few in number.(( Norman L. Geisler and William E. Nix, A General Introduction to the Bible (Chicago: Moody Press, 1986), 468)) Ehrman, himself, seems to concede this point: To be sure, of all the hundreds of thousands of textual changes found among our manuscripts, most of them are completely insignificant, immaterial, of no real importance for anything other than showing that scribes could not spell or keep focused any better than the rest of us.((Ehrman, 207)) However, Ehrman gives many examples of passages that he believes supports his conclusion of an error-filled text. We shall choose three of those passages to examine. First is the passage Luke 11:2-4. Ehrman suggests that this passage was originally truncated and at a later time scribes “harmonized” the passage by adding length and content to make it similar to Matt. 6:9-13.((Ibid. 97)) We shall look at this from two sides of the inerrancy coin. On one side we must ask, “Is inerrancy challenged if Matthew recorded the entire prayer of Jesus and Luke penned only a portion of the prayer? Did Luke make an error?” To suggest that Luke errored in not recording the entire prayer of Jesus would be to misunderstand inerrancy. Inerrancy does not necessitate that all Gospel writers record an event in the exact same words, for to do so would make three of them unnecessary. Inerrancy only necessitates that what is written is true. Authors today have different audiences and themes they write to and about. Take, for example, the topic of steroids in baseball. A sportswriter might focus on whether Barry Bonds should be credited as passing Hank Aaron on the all-time-home-run list if he used steroids. A medical writer would be interested in communicating the details of the different types of steroids Bonds allegedly used. And a legal writer may investigate if Bonds did anything illegal. It was no different for Matthew, Mark, Luke, and John. Each had a unique audience and a specific focus for their writings. Matthew may have chosen to include “… Your will be done, on earth as it is in heaven” (Matt. 6:10), because it was important to Matthew’s goal of explaining the Kingdom of God to his Jewish audience. In particular, His Kingdom has a heavenly aspect and an earthly one. The other side of the inerrancy coin is that not all English versions of the Bible handle this passage in the same manner. The KJV and the NKJV do, indeed, contain the lengthened version. However, the ESV, NASB, and NIV chose the shorter version. This shows that since we have an increasing number of manuscripts our translations are continually improving in their quality. It may be the case that certain scribes—those producing the Majority Text—added to the original writings. But, one does not need to conclude, as Ehrman does, that Scripture is in error. As we have already noted: If Luke did record a few less words of our Lord’s Prayer, it does not make him wrong. Further, if we accept Ehrman’s hypothesis that the Alexandrian manuscripts are more accurate, albeit fewer in number; isn’t it plausible to conclude that the KJV and the NKJV reading is less preferred since they tend to give priority to the Majority Text rather than the Alexandrian texts? Applying textual criticism rules suggested by Professor Gleason Archer further supports the original Lukan reading as to containing the “shortened” version of the Lord’s Prayer. Archer notes that the older and shorter readings are to be preferred.((Geisler and Nix, 478)) Older manuscripts are preferred, because they are closer to the original; and in the case of the Alexandrian manuscripts, they were transcribed by better scribes. The shorter reading is preferred because scribes tend to “add to” the text rather than reduce it. So, Ehrman may be correct when he says that scribes “added to” Luke, but he gives no evidence to support his assertion that Luke made a mistake. Second is the passage Mark 1:2a where Mark writes, “As it is written in Isaiah the prophet … .” Mark has made a mistake according to Ehrman. That mistake is that Isaiah did not write the quoted Old Testament words that follow in Mark 1:2b-3. And according to Ehrman: “… there can be little doubt concerning what Mark originally wrote: the attribution to Isaiah is found in our earliest and best manuscripts.”((Ehrman, 95)) What Ehrman is suggesting is that Mark got it wrong, and the scribes got it right by correcting Mark 1:2 to attribute the Old Testament sayings to “the prophets.” A suggested resolution to this apparent mistake is given by John Grassmick, contributor of the Bible Knowledge Commentary: Mark prefaced this composite quotation from three Old Testament books with the words: It is written in Isaiah the prophet. This illustrates a common practice by New Testament authors in quoting several passages with a unifying theme. The common theme here is the ‘wilderness’ (desert) tradition in Israel’s history. Since Mark was introducing the ministry of John the Baptist in the desert, he cited Isaiah as the source because the Isaiah passage refers to ‘a voice … calling’ in the desert.((Walvoord, John F., Roy B. Zuck, and Dallas Theological Seminary. The Bible Knowledge Commentary: An Exposition of the Scriptures. Wheaton, IL: Victor Books, 1983-c1985; Emphasis in the original.)) It also should be noted that when referencing the thoughts of another individual, ancient writers, as well as modern writers, do not always quote verbatim. Different words may be chosen to convey the same idea. It is a mistake to hold New Testament writers to a standard that was not present then nor today. While it is the case that exact quotes are often used in research work such as what you are presently reading, it is not necessary to do so. Mark need not quote Isaiah verbatim and, yet, still attribute the saying to Isaiah. Concerning this passage, the authors of Hard Sayings of the Bible agree: When we accuse him of inaccuracy, far from pointing out a reality in Mark, we are exposing our own lack of knowledge about how he and other ancient authors used Scripture.(( Walter C. Kaiser and others, eds., Hard Sayings of the Bible Downers Grove: InterVarsity Press, 1996, 404)) Third is an apparent discrepancy as to where Paul went after his conversion on his way to Damascus.((Ehrman, 10)) Galatians 1:16-17 tells us that Paul went to Arabia, while Acts 9:26 states that Paul went to Jerusalem. Galatians 1:17 clearly states, “nor did I go up to Jerusalem … ,” but that he went “… to Arabia … .” In contrast, the Acts narrative places Paul in Damascus, and then describes that he “… came to Jerusalem …” in verse 26. However, this is not a contradiction. It is like the husband who tells his wife that he went to the local hardware store after work, and he tells is son that he went to the golf course after work. Do his stories contradict one another? No. It is perfectly reasonable to assume that he stopped by the hardware store to pick up some materials, and then he continued on to play a round of golf. He did both after work. A similar reconciliation can be given to these two passages. Paul went to Arabia and Jerusalem after leaving Damascus. It is important to note that the charge leveled against Scripture by Ehrman is that “the first thing he did after leaving Damascus” was to go to Jerusalem. The narrative of Acts does seem to indicate a quick progression of Paul’s locality from Damascus to Jerusalem. However, in Acts 9:23 Luke uses the phrase, “When many days had elapsed … ,” which indicates a span of time occurred between verses 22 and 26. What happened during those “many days?” Concerning this passage, the late Oxford Professor and Archaeologist Sir William M. Ramsay offers this: Moreover, Luke divided Paul’s stay in Damascus into two periods, a few days’ residence with the disciples (9:19), and a long period of preaching (9:20-23). The quiet residence in the country for a time, recovering from the serious and prostrating effect of his conversion (for a man’s life is not suddenly reversed without serious claim on his physical power) is the dividing fact between the two periods.((William M. Ramsay, St. Paul the Traveler and Roman Citizen, Revised and Updated, ed. Mark Wilson; Grand Rapids: Kregel, 2001, 47)) Paul, himself, gives us some insight in his letter to the Galatian churches. In recounting the days and years after his conversion, he notes that he did not “… go up to Jerusalem …” (Gal. 1:17) but rather he “… went away to Arabia …” (Gal. 1:17) and then “… returned once more to Damascus” (Gal. 1:17). So, it seems a reasonable conclusion to understand Paul’s post-conversion sojourning to include an initial trip to Damascus proclaiming in the Synagogue the identity of Jesus as the Son of God (Acts 9:20). From Damascus he traveled to Arabia (Gal. 1:17) for some unknown amount of time, and then he returned to Damascus for “many days …” (Acts 9:23). His second stay in Damascus ended with him being lowered over the wall in a basket (Acts 9:25). From there, he traveled to Jerusalem (Acts 9:26). So, Luke and Paul were both correct. After his conversion, Paul went to Arabia and Jerusalem. Contrary to Ehrman, this is not a case of a mistaken biblical author. The Bible once again shows that it can be trusted. In Ehrman’s vigor to find errors in the Bible, he overlooks a very plausible explanation to the text. Conclusion While many of the facts Ehrman records are true, it is the conclusions from these facts that we reject. His spiritual situation—agnosticism—causes truth in all forms to cascade into a deconstruction of meaning, history, and orthodoxy. This leaves him with no basis for truth beyond personal experience. This understanding of truth and orthodoxy has modified his ability to look objectively at the text. Commenting on orthodoxy Ehrman writes: Each and every one of these viewpoints—and many others besides—were topics of constant discussion, dialogue, and debate in the early centuries of the church, while Christians of various persuasions tried to convince others of the truth of their own claims. Only one group eventually ‘won out’ in these debates. It was this group that decided what the Christian creeds would be … ((Ehrman, 154)) Commenting on hermeneutics, Ehrman writes: For the more I studied, the more I saw that reading a text necessarily involves interpreting a text. I suppose when I started my studies I had a rather unsophisticated view of reading: that the point of reading a text is simply to let the text ‘speak for itself,’ to uncover the meaning inherent in its words. The reality, I came to see, is that meaning is not inherent, and texts do not speak for themselves. If texts could speak for themselves, then everyone honestly and openly reading a text would agree on what the text says.((Ibid, 216)) Is this how Ehrman wants his reader to approach his text? If Ehrman’s conclusions about text and meaning are to be accepted, then the reader is perfectly justified in concluding Ehrman’s acceptance of orthodoxy to be true and inerrancy of Scripture to be real. But, this is precisely what Ehrman rejects. This view is logically inconsistent. As an example of the incompatibility of Ehrman’s idea, think of the automobile driver. Would we drive our cars if traffic signs were understood at the discretion of the reader? Chaos would most certainly follow. Ehrman’s idea is completely unlivable. Ehrman may confuse the existence of truth with the difficulty of discovery of truth. When looking at a biblical passage, there are possibilities of disagreement. For instance, if person A and B disagree on the understating of a text there are several possibilities. Both A and B are wrong, A is right, and B is wrong, or B is right and A is wrong. What is not possible is that A and B are both right. This goes against the Law of Non-Contradiction. The book does not live up to its billing. Inferred within the title—Misquoting Jesus—is some factual knowledge of Jesus’ own words—the exact idea Ehrman rejects! He cannot consistently claim that Jesus was misquoted and say that we do not have the original text. How can one know that Jesus was misquoted if we do not know what he actually said? There must be a real, objective truth before one can claim something is false. He has rejected the basis necessary to claim that Jesus was misquoted. Something is only false if it does not correspond to reality. Christian orthodoxy was God-inspired and revealed through Jesus. If Jesus is misquoted, there was a truth in what he taught.Ω


Randall Birtell and Randal Ming were the Scranton, KS Branch Directors of MCOI and they also were completing their Master’s Degrees in Apologetics at Southern Evangelical Seminary in Charlotte, NC at the time this article was published. © 2020, Midwest Christian Outreach, Inc All rights reserved. Excerpts and links may be used if full and clear credit is given with specific direction to the original content.
Read the full article
0 notes
Text
Journal - 13 Jaw-Dropping Examples of Photoshopped Architecture
Architizer is building tech tools to help power your practice: Click here to sign up now. Are you a manufacturer looking to connect with architects? Click here.
As most of us know, time flies when you’re having fun with Photoshop — but you may not have realized that it has now been 30 years since Adobe’s flagship program was first launched. That’s a lot of lassoing!
This extraordinarily multifunctional piece of software is a staple for every creative professional, including artists, graphic designers, animators, photographers, web designers, publishers … and, of course, architects. Oftentimes, rendering artists working in the field of architecture strive for photo-realism, employing advanced Photoshop techniques to visualize a proposal in all its glory and help convince clients of their concept.

David Santos recreated Lake Lugano House, a beautifully designed house by JM Architecture, with finishing touches in Photoshop. Read the tutorial here.
This specialist discipline has become big business: Companies such as MIR and Methanoia combine modeling programs like 3ds Max and Rhino with rendering plug-ins like V-Ray to produce incredibly detailed representations of architects’ proposals. No matter how perfect the final rendering is, though, Photoshop remains an indispensable tool for applying the finishing touches, tweaking light and adding details to bring forth that crucial extra dimension: atmosphere.
These kinds of commercial images have made Photoshop a ubiquitous piece of software in architecture and visualization studios around the globe. That said, even rendering artists need to let their proverbial hair down once in a while — and when the creative leash comes off, some of the most extraordinary uses of Adobe’s software emerge. To prove our point, here are 13 of the most outlandish examples of photoshopped architecture on the internet. Take a break from reality, starting now …
Untitled #10 by Filip Dujardin
Dujardin pushes and pulls at the fabric of the buildings we take for granted, creating exaggerated — and disturbing — versions of conventional architectural typologies. Check out further examples of the artist’s work here.
Medusa by Victor Enrich
The Barcelona-based artist combines photorealism with the utterly absurd to create buildings that appear alive, often growing out of control. See more of Enrich’s work here.
Castle House Island by Unknown
A cunning splice: Neuschwanstein Castle in Germany placed atop James Bond’s favorite island in Thailand.
We Love To Build by Paul Hollingworth
Hollingworth takes deconstructivism to new heights in his artworks, each of which tells a story of our love-hate relationship with social architecture.
Dubai Tennis Arena by 8+8 Concept Studio
When 30-year-old Polish architect Krysztof Kotala called for investors to back his outrageous concept for a subaquatic tennis court in the Persian Gulf, his provocative accompanying image virtually broke the internet.
Con/struct by Justin Plunkett
Plunkett’s perplexing photomontages provoke us to question the definition of beauty within our urban environment. See more of Plunkett’s urban constructs here.
Untitled (House) by Jim Kazanjian
Jim Kazanjian’s surreal landscapes and precarious structures are shrouded with a haunted, vaguely threatening atmosphere. Find out more about the artist here.
Façades by Zacharie Gaudrillot-Roy
Photographer Gaudrillot-Roy imagines how a streetscape might feel if buildings were left with just their face, like an eerie, abandoned movie set worthy of Potemkin himself.
Forgotten Temple of Lysistrata by Unknown
This epic image had some people speculating over the real-world location of this mysterious temple — but they had been fooled. Via the magic of Photoshop, the coffered interior of the Pantheon in Rome was combined with a stunning cave in Portugal.
Villa Savoye by Xavier Delory
Delory caused a furor on the internet last year with this viciously vandalized version of the Villa Savoye. Discover the story behind this image here.
Merge by Gus Petro
Petro forces use to question our perception of scale with his juxtaposition of two of the most iconic destinations in the United States: Manhattan and the Grand Canyon. More here.
Venice Subway by Unknown
This aquatic tunnel would make for a magical ride beneath the canals of Venice. That train has traveled an awful long way from its real-world home, though — it’s actually a Danish ‘H’ train, running from Copenhagen to Frederikssund.
Between a Rock and a Hard Place by Unknown
Submitted for a Photoshop competition, this precarious pill-shaped home appears to have been inspired by a very special rock in Norway.
For more tips and tricks on increasing efficiency on Photoshop, click here.
Architizer is building tech tools to help power your practice: Click here to sign up now. Are you a manufacturer looking to connect with architects? Click here.
The post 13 Jaw-Dropping Examples of Photoshopped Architecture appeared first on Journal.
from Journal https://architizer.com/blog/inspiration/collections/art-of-rendering-photoshop/
Originally published on ARCHITIZER
RSS Feed: https://architizer.com/blog
#Journal#architect#architecture#architects#architectural#design#designer#designers#building#buildings
0 notes
Photo

New Borderlands 3 end-game content announced at Gamescom
[vc_row][vc_column][vc_column_text] End-Game Content Two new elements for the end-game content in Borderlands 3 are revealed. These are the return of the ‘Circle of Slaughter‘ Domes and a whole new mode called ‘Proving Grounds‘. Borderlands 3’s Creative Director, Paul Sage, announced these during the pre-show of Gamescom 2019. In an interview with Geoff Keighley, Paul gave some explanation of these 2 pieces of content. Circle of Slaughter The Circle of Slaughter is something that’s been with the franchise since the first game. In these arenas, you had to fight off waves of enemies. You might recognize this game mode as the ‘Horde Mode’ in some other game franchises. Throughout the Borderlands franchise, there have been various domes. Each of these Circle of Slaughter domes had their own theme and therefore their own set of enemy types. Your task is to kill all the enemies the game throws at you. After each wave, the difficulty gets increased and you will be facing more and more challenging enemies. Mister Torgue will return in Borderlands 3 because Torgue is sponsoring the Slaughter Domes across the various planets. Throughout the event, Mister Torgue will also give you additional bonus objectives. So expect some colorful commentary and weird challenges during your runs. The more waves you complete the better your rewards will be. Proving Grounds Later on in the game, you can get access to the Proving Grounds. If you are familiar with Borderlands 2’s digi-struct peak then you are somewhat familiar with the task at hand. In the proving grounds, your skill will be tested. There are 6 different proving grounds, throughout the game. Each of these challenges is comprised of various stages. You will need to clear out multiple locations within 30 minutes to complete these challenges. Throughout the proving grounds, you encounter additional challenges. When you manage to complete these, the quality of your reward will increase. Challenges: Don’t die (respawn) Find the fallen Guardian Complete the challenge within 20 minutes Complete the challenge within 15 minutes I got to capture a play session of the Proving Grounds at Gamescom. So check back soon… Accessing the Proving Grounds If you don’t want any spoilers then you should skip this section.[/vc_column_text][vc_toggle title=”SPOILERS?” custom_font_container=”tag:h4|text_align:left|color:%23f9a600″ custom_use_theme_fonts=”yes” use_custom_heading=”true”]In the video Paul mentions you will be encountering an Eridian called the Overseer. This alien will host the Proving Grounds challenges. Paul also mentions that throughout the game you will be able to find hidden acient texts. If you looked closely to the exclusive Eden-6 Gameplay you might already have seen one. I also discovered one during my Zane playthrough during the inZanely fun Balex mission. In my play sessions I wasn’t able to decode the text yet. So some event has to happen throughout the game in order to decode those. I think that once you found all of these hidden clues on a planet you will be to access one of the Proving Grounds. It wouldn’t surprise me if there are 5 planets and therefore you unlock 5 Proving Grounds. Completing all 5 of these challenges will unlock the final 6th Proving Ground.[/vc_toggle][/vc_column][/vc_row]
Continue reading on https://mentalmars.com/game-news/new-borderlands-3-end-game-content-announced-at-gamescom/
0 notes
Text
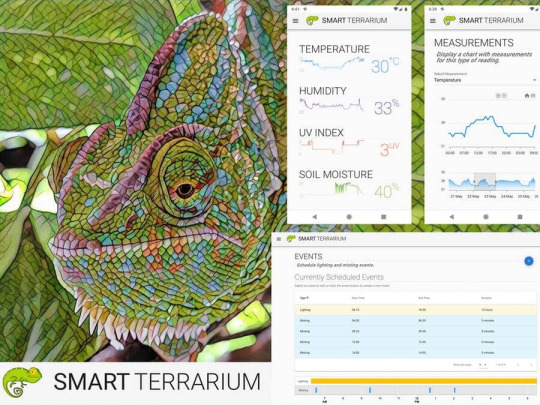
Smart Terrarium
Automated environment for reptiles to promote good husbandry and enable maximum lifespan for animals in captivity.

Things used in this project
Hardware components
Raspberry Pi 3 Model B×1
Arduino MKR1000 ×1
Arduino UNO & Genuino UNO ×1
DHT22 Temperature Sensor×1
Adafruit Waterproof DS18B20 Digital temperature sensor ×1
DFRobot Gravity: Analog UV Sensor (ML8511)×1
DFRobot Gravity: Analog Capacitive Soil Moisture Sensor- Corrosion Resistant×1
Ultrasonic Sensor - HC-SR04 (Generic) ×2Seeed Grove - 2-Channel SPDT Relay ×1
Hand tools and fabrication machines
3D Printer (generic)
Story
Intro
Smart Terrarium is the all in one system that provides the necessary information and automation to encourage a full and happy life for your reptiles. This system provides the user with the ability to monitor a variety of sensors in their animals habitat as well as control the lighting and misting system.
Backstory
This system was designed for my chameleon, Curie. She is a veiled chameleon and loves having her cage always kept in the optimal conditions. She is currently benefiting from the daily scheduled misting routines that the Smart Terrarium provides. This keeps her humidity in the appropriate range while also providing her with a nice place to cool off and get a drink.Another great part of having the Smart Terrarium is peace of mind. You no longer need to randomly check on the status of the mister bucket water level. You can always rely on the Smart Terrarium to notify you when you are running low. Also get notifications when the drain bucket is approaching maximum capacity.The most important part of this setup is the monitoring of the UV light. Chameleons require UV-B to produce Vitamin D. When a chameleon does not absorb enough calcium a chameleon can develop abnormalities in bone growth, rachitis, Metabolic Bone Disease (MBD) or just get very weak bones that are prone to breaking. The Smart Terrarium provides constant monitoring of UV light and can notify the user when the average UV index is below a certain threshold.
Hardware
This project uses a Raspberry Pi 3, an Arduino Uno, and a ArduinoMKR1000. The Raspberry Pi acts as our main system receiving readings from the Uno and MKR1000. The Pi also acts as a web server which delivers our app to the client when a user wants to monitor their system. They simply log in to a web page allowing them to interact with the Smart Terrarium from anywhere around the globe.

Raspberry Pi 3 A+
The MKR1000 is the main workhorse for getting sensor data and it sends its readings every second over wifi to the web server running on the Raspberry Pi. It has the following sensors connected to it:
(5) DS18B20 Digital Tempearture probes
(1) DHT22 Temperature & Humidity sensor
(1) UV sensor
(1)Soil Moisture sensor

Arduino MKR1000
The Arduino Uno is connected to the
Raspberry Pi via USB. It is used to monitor the water levels and also control the relays for the lights and misting pump. It has the following hardware connected:(2) HC-SR04 Ultrasonic Sensor
(2) Relays

Arduino Uno connected to 2 proximity sensors and 2 relays

Misting Bucket, Misting Pump, Drain Bucket with Proximity Sensor
Software
This system leverages the following open source software:Node.jsJohnny-fiveRethinkDBFirmataVue
Backend
The Raspberry Piis running an Express web server which collects readings from the sensors and saves them to a RethinkDB instance. The readings are being reported to the Pi every second so the user has access to the most current measurements.
The readings are saved every 5 minutes in Rethink DB for historical data.The Uno is running the PingFirmataSketch and using serial to expose the proximity sensors and relays to the Pi using Firmata protocol. The Pi leverages Johnny-five to allow the user to program in javascript.The MKR1000 is running a custom sketch using OneWire for the 5 temperature probes and then using analog inputs for the other sensors.
It posts the values to the Pi every second making sure the readings the user sees are fresh.
Frontend
The Raspberry Pi also serves up the front end portion of this app which leverages Vue.js. It allows the user to log in from anywhere having complete control over their pet's environment. The app works on any modern web browser so you can access it from a computer, tablet, or phone.The Smart Terrarium app allows the user to view the latests readings along with a sparkline graph of the previous day's historical data.The user can click through on any of the sensors
to view their history data.
The Measurements page shows a graph with the entire sensor history. The user can select a section of the bottom graph to display a zoomed in version in the graph above. This allows the user to inspect the historic data for any spikes or dips where the environment is out of the norm.The user has the ability to schedule events including lighting and misting events.
The Event page displays the currently scheduled events and allows the user to add, edit, and delete events. These events are used to automate the lighting and misting sessions which provides peace making sure you never forget.
The Controls page allows the user to manually override the scheduled lighting and misting events. The page displays the current status of each relay and allows the user to toggle them with a click of a button.The Admin page allow the user to enter information about themselves for contact purposes. This is for the email notifications on high/low water levels on misting system as well as notifications for when the daily average UV index gets too low. There is also a spot for the animals birthday so we can provide birthday notifications.
Screenshots
Home Page

Home Page

Historical Measurements

Historical Measurements

Historical Measurements
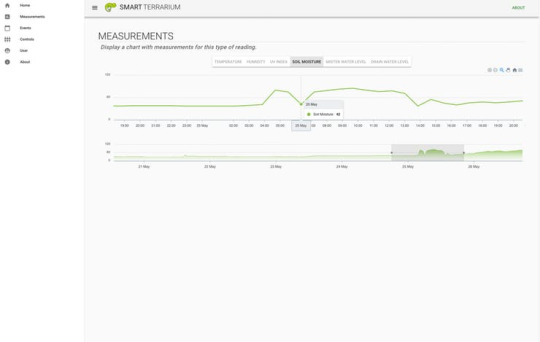
Historical Measurements (zoomed)>
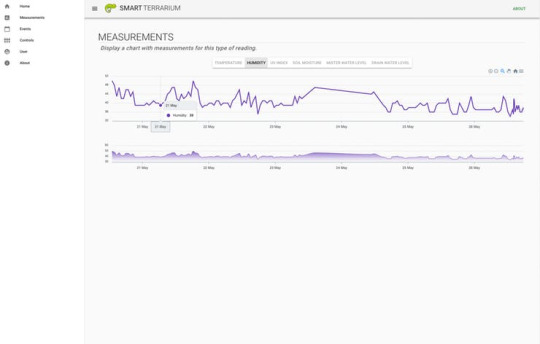
Historical Measurements
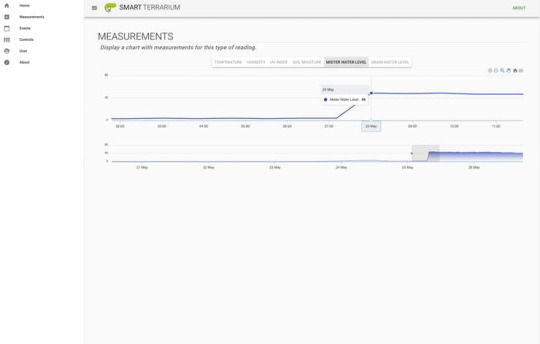
Historical Measurements (zoomed)
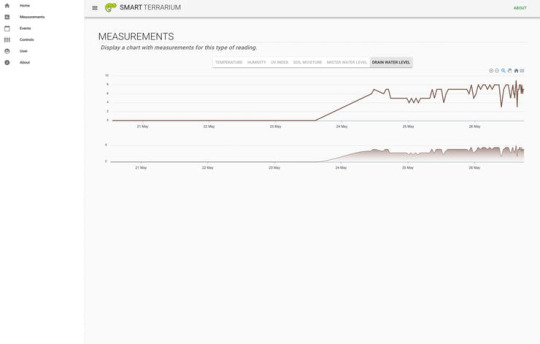
Historical Measurements
Events page for lighting and misting events.

Schedule Lighting and Misting Events
Controls page where the user can override the scheduled events.
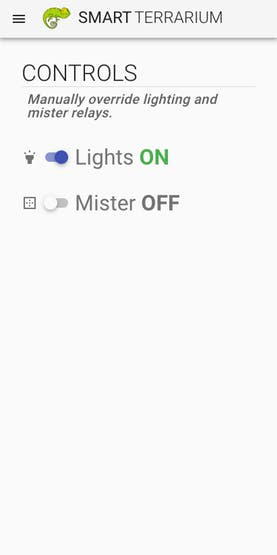
Misting and Lighting Overrides
Demo
Here is a demo of the overall system.
youtube
Demo of The Smart Terrarium
We hope you enjoyed our presentation of the Smart Terrarium and encourage any reptile owners to use this project to improve the lives of your pets.Thanks for your time and happy making!
Custom parts and enclosures
Plant Holder Brace
This provides extra support to the cage for hanging a plant.
Download Here
Mister Mount
This provides a nice clean installation of the misting head for the misting system.
Download Here
Schematics
Arduino Uno diagram
The Arduino Uno circuit used to control both relays for the lighting and misting system, as well as monitor the water levels on the misting bucket and drain.

Arduino MKR1000
This is really for the MKR1000 but tinkercad circuits didn't have it as a component. All pins are still correct.

Code
Ping Firmata
C#This is the version of firmata required for the
Proximity sensors
to function properly. Install this sketch on the Arduino Uno.
/* * Firmata is a generic protocol for communicating with microcontrollers * from software on a host computer. It is intended to work with * any host computer software package. * * To download a host software package, please clink on the following link * to open the download page in your default browser. * * http://firmata.org/wiki/Download */ /* Copyright (C) 2006-2008 Hans-Christoph Steiner. All rights reserved. Copyright (C) 2010-2011 Paul Stoffregen. All rights reserved. Copyright (C) 2009 Shigeru Kobayashi. All rights reserved. Copyright (C) 2009-2011 Jeff Hoefs. All rights reserved. Copyright (C) 2012 Julian Gaultier. All rights reserved. Copyright (C) 2015 Rick Waldron. All rights reserved. This library is free software; you can redistribute it and/or modify it under the terms of the GNU Lesser General Public License as published by the Free Software Foundation; either version 2.1 of the License, or (at your option) any later version. */ #include <Servo.h> #include <Wire.h> #include <Firmata.h> #define I2C_WRITE B00000000 #define I2C_READ B00001000 #define I2C_READ_CONTINUOUSLY B00010000 #define I2C_STOP_READING B00011000 #define I2C_READ_WRITE_MODE_MASK B00011000 #define I2C_10BIT_ADDRESS_MODE_MASK B00100000 #define MAX_QUERIES 8 #define MINIMUM_SAMPLING_INTERVAL 10 #define REGISTER_NOT_SPECIFIED -1 #define PING_READ 0x75 // PING_READ is for use with HCSR04 and similar "ultrasonic ping" components /*============================================================================== * GLOBAL VARIABLES *============================================================================*/ // analog inputs int analogInputsToReport = 0; // bitwise array to store pin reporting // digital input ports byte reportPINs[TOTAL_PORTS]; // 1 = report this port, 0 = silence byte previousPINs[TOTAL_PORTS]; // previous 8 bits sent // pins configuration byte pinConfig[TOTAL_PINS]; // configuration of every pin byte portConfigInputs[TOTAL_PORTS]; // each bit: 1 = pin in INPUT, 0 = anything else int pinState[TOTAL_PINS]; // any value that has been written // timer variables unsigned long currentMillis; // store the current value from millis() unsigned long previousMillis; // for comparison with currentMillis int samplingInterval = 19; // how often to run the main loop (in ms) // i2c data struct i2c_device_info { byte addr; byte reg; byte bytes; }; // for i2c read continuous more i2c_device_info query[MAX_QUERIES]; byte i2cRxData[32]; boolean isI2CEnabled = false; signed char queryIndex = -1; // default delay time between i2c read request and Wire.requestFrom() unsigned int i2cReadDelayTime = 0; Servo servos[MAX_SERVOS]; /*============================================================================== * FUNCTIONS *============================================================================*/ void readAndReportData(byte address, int theRegister, byte numBytes) { // allow I2C requests that don't require a register read // for example, some devices using an interrupt pin to signify new data available // do not always require the register read so upon interrupt you call Wire.requestFrom() if (theRegister != REGISTER_NOT_SPECIFIED) { Wire.beginTransmission(address); Wire.write((byte)theRegister); Wire.endTransmission(); delayMicroseconds(i2cReadDelayTime); // delay is necessary for some devices such as WiiNunchuck } else { theRegister = 0; // fill the register with a dummy value } Wire.requestFrom(address, numBytes); // all bytes are returned in requestFrom // check to be sure correct number of bytes were returned by slave if (numBytes == Wire.available()) { i2cRxData[0] = address; i2cRxData[1] = theRegister; for (int i = 0; i < numBytes; i++) { i2cRxData[2 + i] = Wire.read(); } } else { if (numBytes > Wire.available()) { Firmata.sendString("I2C Read Error: Too many bytes received"); } else { Firmata.sendString("I2C Read Error: Too few bytes received"); } } // send slave address, register and received bytes Firmata.sendSysex(SYSEX_I2C_REPLY, numBytes + 2, i2cRxData); } void outputPort(byte portNumber, byte portValue, byte forceSend) { // pins not configured as INPUT are cleared to zeros portValue = portValue & portConfigInputs[portNumber]; // only send if the value is different than previously sent if (forceSend || previousPINs[portNumber] != portValue) { Firmata.sendDigitalPort(portNumber, portValue); previousPINs[portNumber] = portValue; } } /* ----------------------------------------------------------------------------- * check all the active digital inputs for change of state, then add any events * to the Serial output queue using Serial.print() */ void checkDigitalInputs(void) { /* Using non-looping code allows constants to be given to readPort(). * The compiler will apply substantial optimizations if the inputs * to readPort() are compile-time constants. */ if (TOTAL_PORTS > 0 && reportPINs[0]) outputPort(0, readPort(0, portConfigInputs[0]), false); if (TOTAL_PORTS > 1 && reportPINs[1]) outputPort(1, readPort(1, portConfigInputs[1]), false); if (TOTAL_PORTS > 2 && reportPINs[2]) outputPort(2, readPort(2, portConfigInputs[2]), false); if (TOTAL_PORTS > 3 && reportPINs[3]) outputPort(3, readPort(3, portConfigInputs[3]), false); if (TOTAL_PORTS > 4 && reportPINs[4]) outputPort(4, readPort(4, portConfigInputs[4]), false); if (TOTAL_PORTS > 5 && reportPINs[5]) outputPort(5, readPort(5, portConfigInputs[5]), false); if (TOTAL_PORTS > 6 && reportPINs[6]) outputPort(6, readPort(6, portConfigInputs[6]), false); if (TOTAL_PORTS > 7 && reportPINs[7]) outputPort(7, readPort(7, portConfigInputs[7]), false); if (TOTAL_PORTS > 8 && reportPINs[8]) outputPort(8, readPort(8, portConfigInputs[8]), false); if (TOTAL_PORTS > 9 && reportPINs[9]) outputPort(9, readPort(9, portConfigInputs[9]), false); if (TOTAL_PORTS > 10 && reportPINs[10]) outputPort(10, readPort(10, portConfigInputs[10]), false); if (TOTAL_PORTS > 11 && reportPINs[11]) outputPort(11, readPort(11, portConfigInputs[11]), false); if (TOTAL_PORTS > 12 && reportPINs[12]) outputPort(12, readPort(12, portConfigInputs[12]), false); if (TOTAL_PORTS > 13 && reportPINs[13]) outputPort(13, readPort(13, portConfigInputs[13]), false); if (TOTAL_PORTS > 14 && reportPINs[14]) outputPort(14, readPort(14, portConfigInputs[14]), false); if (TOTAL_PORTS > 15 && reportPINs[15]) outputPort(15, readPort(15, portConfigInputs[15]), false); } // ----------------------------------------------------------------------------- /* sets the pin mode to the correct state and sets the relevant bits in the * two bit-arrays that track Digital I/O and PWM status */ void setPinModeCallback(byte pin, int mode) { if (pinConfig[pin] == I2C && isI2CEnabled && mode != I2C) { // disable i2c so pins can be used for other functions // the following if statements should reconfigure the pins properly disableI2CPins(); } if (IS_PIN_SERVO(pin) && mode != SERVO && servos[PIN_TO_SERVO(pin)].attached()) { servos[PIN_TO_SERVO(pin)].detach(); } if (IS_PIN_ANALOG(pin)) { reportAnalogCallback(PIN_TO_ANALOG(pin), mode == ANALOG ? 1 : 0); // turn on/off reporting } if (IS_PIN_DIGITAL(pin)) { if (mode == INPUT) { portConfigInputs[pin / 8] |= (1 << (pin & 7)); } else { portConfigInputs[pin / 8] &= ~(1 << (pin & 7)); } } ��pinState[pin] = 0; switch (mode) { case ANALOG: if (IS_PIN_ANALOG(pin)) { if (IS_PIN_DIGITAL(pin)) { pinMode(PIN_TO_DIGITAL(pin), INPUT); // disable output driver digitalWrite(PIN_TO_DIGITAL(pin), LOW); // disable internal pull-ups } pinConfig[pin] = ANALOG; } break; case INPUT: if (IS_PIN_DIGITAL(pin)) { pinMode(PIN_TO_DIGITAL(pin), INPUT); // disable output driver digitalWrite(PIN_TO_DIGITAL(pin), LOW); // disable internal pull-ups pinConfig[pin] = INPUT; } break; case OUTPUT: if (IS_PIN_DIGITAL(pin)) { digitalWrite(PIN_TO_DIGITAL(pin), LOW); // disable PWM pinMode(PIN_TO_DIGITAL(pin), OUTPUT); pinConfig[pin] = OUTPUT; } break; case PWM: if (IS_PIN_PWM(pin)) { pinMode(PIN_TO_PWM(pin), OUTPUT); analogWrite(PIN_TO_PWM(pin), 0); pinConfig[pin] = PWM; } break; case SERVO: if (IS_PIN_SERVO(pin)) { pinConfig[pin] = SERVO; if (!servos[PIN_TO_SERVO(pin)].attached()) { servos[PIN_TO_SERVO(pin)].attach(PIN_TO_DIGITAL(pin)); } } break; case I2C: if (IS_PIN_I2C(pin)) { // mark the pin as i2c // the user must call I2C_CONFIG to enable I2C for a device pinConfig[pin] = I2C; } break; default: Firmata.sendString("Unknown pin mode"); // TODO: put error msgs in EEPROM } // TODO: save status to EEPROM here, if changed } void analogWriteCallback(byte pin, int value) { if (pin < TOTAL_PINS) { switch (pinConfig[pin]) { case SERVO: if (IS_PIN_SERVO(pin)) servos[PIN_TO_SERVO(pin)].write(value); pinState[pin] = value; break; case PWM: if (IS_PIN_PWM(pin)) analogWrite(PIN_TO_PWM(pin), value); pinState[pin] = value; break; } } } void digitalWriteCallback(byte port, int value) { byte pin, lastPin, mask = 1, pinWriteMask = 0; if (port < TOTAL_PORTS) { // create a mask of the pins on this port that are writable. lastPin = port * 8 + 8; if (lastPin > TOTAL_PINS) lastPin = TOTAL_PINS; for (pin = port * 8; pin < lastPin; pin++) { // do not disturb non-digital pins (eg, Rx & Tx) if (IS_PIN_DIGITAL(pin)) { // only write to OUTPUT and INPUT (enables pullup) // do not touch pins in PWM, ANALOG, SERVO or other modes if (pinConfig[pin] == OUTPUT || pinConfig[pin] == INPUT) { pinWriteMask |= mask; pinState[pin] = ((byte)value & mask) ? 1 : 0; } } mask = mask << 1; } writePort(port, (byte)value, pinWriteMask); } } // ----------------------------------------------------------------------------- /* sets bits in a bit array (int) to toggle the reporting of the analogIns */ //void FirmataClass::setAnalogPinReporting(byte pin, byte state) { //} void reportAnalogCallback(byte analogPin, int value) { if (analogPin < TOTAL_ANALOG_PINS) { if (value == 0) { analogInputsToReport = analogInputsToReport & ~(1 << analogPin); } else { analogInputsToReport = analogInputsToReport | (1 << analogPin); } } // TODO: save status to EEPROM here, if changed } void reportDigitalCallback(byte port, int value) { if (port < TOTAL_PORTS) { reportPINs[port] = (byte)value; } // do not disable analog reporting on these 8 pins, to allow some // pins used for digital, others analog. Instead, allow both types // of reporting to be enabled, but check if the pin is configured // as analog when sampling the analog inputs. Likewise, while // scanning digital pins, portConfigInputs will mask off values from any // pins configured as analog } /*============================================================================== * SYSEX-BASED commands *============================================================================*/ void sysexCallback(byte command, byte argc, byte *argv) { byte mode; byte slaveAddress; byte slaveRegister; byte data; unsigned int delayTime; switch (command) { case I2C_REQUEST: mode = argv[1] & I2C_READ_WRITE_MODE_MASK; if (argv[1] & I2C_10BIT_ADDRESS_MODE_MASK) { Firmata.sendString("10-bit addressing not supported"); return; } else { slaveAddress = argv[0]; } switch (mode) { case I2C_WRITE: Wire.beginTransmission(slaveAddress); for (byte i = 2; i < argc; i += 2) { data = argv[i] + (argv[i + 1] << 7); Wire.write((byte)data); } Wire.endTransmission(); delayMicroseconds(70); break; case I2C_READ: case I2C_READ_CONTINUOUSLY: if (argc == 6) { // a slave register is specified slaveRegister = argv[2] + (argv[3] << 7); data = argv[4] + (argv[5] << 7); // bytes to read } else { // a slave register is NOT specified slaveRegister = (int)REGISTER_NOT_SPECIFIED; data = argv[2] + (argv[3] << 7); // bytes to read } if (mode == I2C_READ) { readAndReportData(slaveAddress, slaveRegister, data); } else { if ((queryIndex + 1) >= MAX_QUERIES) { Firmata.sendString("too many queries"); break; } queryIndex++; query[queryIndex].addr = slaveAddress; query[queryIndex].reg = slaveRegister; query[queryIndex].bytes = data; } break; case I2C_STOP_READING: byte queryIndexToSkip; // if read continuous mode is enabled for only 1 i2c device, disable // read continuous reporting for that device if (queryIndex <= 0) { queryIndex = -1; } else { // if read continuous mode is enabled for multiple devices, // determine which device to stop reading and remove it's data from // the array, shifiting other array data to fill the space for (byte i = 0; i < queryIndex + 1; i++) { if (query[i].addr == slaveAddress) { queryIndexToSkip = i; break; } } for (byte i = queryIndexToSkip; i < queryIndex + 1; i++) { if (i < MAX_QUERIES) { query[i].addr = query[i + 1].addr; query[i].reg = query[i + 1].reg; query[i].bytes = query[i + 1].bytes; } } queryIndex--; } break; default: break; } break; case I2C_CONFIG: delayTime = (argv[0] + (argv[1] << 7)); if (delayTime > 0) { i2cReadDelayTime = delayTime; } if (!isI2CEnabled) { enableI2CPins(); } break; case SERVO_CONFIG: if (argc > 4) { // these vars are here for clarity, they'll optimized away by the compiler byte pin = argv[0]; int minPulse = argv[1] + (argv[2] << 7); int maxPulse = argv[3] + (argv[4] << 7); if (IS_PIN_SERVO(pin)) { if (servos[PIN_TO_SERVO(pin)].attached()) { servos[PIN_TO_SERVO(pin)].detach(); } servos[PIN_TO_SERVO(pin)].attach(PIN_TO_DIGITAL(pin), minPulse, maxPulse); setPinModeCallback(pin, SERVO); } } break; case SAMPLING_INTERVAL: if (argc > 1) { samplingInterval = argv[0] + (argv[1] << 7); if (samplingInterval < MINIMUM_SAMPLING_INTERVAL) { samplingInterval = MINIMUM_SAMPLING_INTERVAL; } } else { //Firmata.sendString("Not enough data"); } break; case EXTENDED_ANALOG: if (argc > 1) { int val = argv[1]; if (argc > 2) { val |= (argv[2] << 7); } if (argc > 3) { val |= (argv[3] << 14); } analogWriteCallback(argv[0], val); } break; case CAPABILITY_QUERY: Serial.write(START_SYSEX); Serial.write(CAPABILITY_RESPONSE); for (byte pin = 0; pin < TOTAL_PINS; pin++) { if (IS_PIN_DIGITAL(pin)) { Serial.write((byte)INPUT); Serial.write(1); Serial.write((byte)OUTPUT); Serial.write(1); Serial.write((byte)PING_READ); Serial.write(1); } if (IS_PIN_ANALOG(pin)) { Serial.write(ANALOG); Serial.write(10); } if (IS_PIN_PWM(pin)) { Serial.write(PWM); Serial.write(8); } if (IS_PIN_SERVO(pin)) { Serial.write(SERVO); Serial.write(14); } if (IS_PIN_I2C(pin)) { Serial.write(I2C); Serial.write(1); // to do: determine appropriate value } Serial.write(127); } Serial.write(END_SYSEX); break; case PIN_STATE_QUERY: if (argc > 0) { byte pin = argv[0]; Serial.write(START_SYSEX); Serial.write(PIN_STATE_RESPONSE); Serial.write(pin); if (pin < TOTAL_PINS) { Serial.write((byte)pinConfig[pin]); Serial.write((byte)pinState[pin] & 0x7F); if (pinState[pin] & 0xFF80) { Serial.write((byte)(pinState[pin] >> 7) & 0x7F); } if (pinState[pin] & 0xC000) { Serial.write((byte)(pinState[pin] >> 14) & 0x7F); } } Serial.write(END_SYSEX); } break; case ANALOG_MAPPING_QUERY: Serial.write(START_SYSEX); Serial.write(ANALOG_MAPPING_RESPONSE); for (byte pin = 0; pin < TOTAL_PINS; pin++) { Serial.write(IS_PIN_ANALOG(pin) ? PIN_TO_ANALOG(pin) : 127); } Serial.write(END_SYSEX); break; case PING_READ: { byte pulseDurationArray[4] = { (argv[2] & 0x7F) | ((argv[3] & 0x7F) << 7), (argv[4] & 0x7F) | ((argv[5] & 0x7F) << 7), (argv[6] & 0x7F) | ((argv[7] & 0x7F) << 7), (argv[8] & 0x7F) | ((argv[9] & 0x7F) << 7)}; unsigned long pulseDuration = ((unsigned long)pulseDurationArray[0] << 24) + ((unsigned long)pulseDurationArray[1] << 16) + ((unsigned long)pulseDurationArray[2] << 8) + ((unsigned long)pulseDurationArray[3]); if (argv[1] == HIGH) { pinMode(argv[0], OUTPUT); digitalWrite(argv[0], LOW); delayMicroseconds(2); digitalWrite(argv[0], HIGH); delayMicroseconds(pulseDuration); digitalWrite(argv[0], LOW); } else { digitalWrite(argv[0], HIGH); delayMicroseconds(2); digitalWrite(argv[0], LOW); delayMicroseconds(pulseDuration); digitalWrite(argv[0], HIGH); } unsigned long duration; byte responseArray[5]; byte timeoutArray[4] = { (argv[10] & 0x7F) | ((argv[11] & 0x7F) << 7), (argv[12] & 0x7F) | ((argv[13] & 0x7F) << 7), (argv[14] & 0x7F) | ((argv[15] & 0x7F) << 7), (argv[16] & 0x7F) | ((argv[17] & 0x7F) << 7)}; unsigned long timeout = ((unsigned long)timeoutArray[0] << 24) + ((unsigned long)timeoutArray[1] << 16) + ((unsigned long)timeoutArray[2] << 8) + ((unsigned long)timeoutArray[3]); pinMode(argv[0], INPUT); duration = pulseIn(argv[0], argv[1], timeout); responseArray[0] = argv[0]; responseArray[1] = (((unsigned long)duration >> 24) & 0xFF); responseArray[2] = (((unsigned long)duration >> 16) & 0xFF); responseArray[3] = (((unsigned long)duration >> 8) & 0xFF); responseArray[4] = (((unsigned long)duration & 0xFF)); Firmata.sendSysex(PING_READ, 5, responseArray); break; } } } void enableI2CPins() { for (byte i = 0; i < TOTAL_PINS; i++) { if (IS_PIN_I2C(i)) { // mark pins as i2c so they are ignore in non i2c data requests setPinModeCallback(i, I2C); } } isI2CEnabled = true; // is there enough time before the first I2C request to call this here? Wire.begin(); } void disableI2CPins() { isI2CEnabled = false; queryIndex = -1; } void systemResetCallback() { if (isI2CEnabled) { disableI2CPins(); } for (byte i = 0; i < TOTAL_PORTS; i++) { reportPINs[i] = false; // by default, reporting off portConfigInputs[i] = 0; // until activated previousPINs[i] = 0; } // pins with analog capability default to analog input // otherwise, pins default to digital output for (byte i = 0; i < TOTAL_PINS; i++) { if (IS_PIN_ANALOG(i)) { // turns off pullup, configures everything setPinModeCallback(i, ANALOG); } else { // sets the output to 0, configures portConfigInputs setPinModeCallback(i, OUTPUT); } } // by default, do not report any analog inputs analogInputsToReport = 0; } void setup() { Firmata.setFirmwareVersion(FIRMATA_MAJOR_VERSION, FIRMATA_MINOR_VERSION); Firmata.attach(ANALOG_MESSAGE, analogWriteCallback); Firmata.attach(DIGITAL_MESSAGE, digitalWriteCallback); Firmata.attach(REPORT_ANALOG, reportAnalogCallback); Firmata.attach(REPORT_DIGITAL, reportDigitalCallback); Firmata.attach(SET_PIN_MODE, setPinModeCallback); Firmata.attach(START_SYSEX, sysexCallback); Firmata.attach(SYSTEM_RESET, systemResetCallback); Firmata.begin(57600); systemResetCallback(); // reset to default config } void loop() { byte pin, analogPin; /* DIGITALREAD - as fast as possible, check for changes and output them to the * FTDI buffer using Serial.print() */ checkDigitalInputs(); /* SERIALREAD - processing incoming messagse as soon as possible, while still * checking digital inputs. */ while (Firmata.available()) { Firmata.processInput(); } /* SEND FTDI WRITE BUFFER - make sure that the FTDI buffer doesn't go over * 60 bytes. use a timer to sending an event character every 4 ms to * trigger the buffer to dump. */ currentMillis = millis(); if (currentMillis - previousMillis > samplingInterval) { previousMillis += samplingInterval; /* ANALOGREAD - do all analogReads() at the configured sampling interval */ for (pin = 0; pin < TOTAL_PINS; pin++) { if (IS_PIN_ANALOG(pin) && pinConfig[pin] == ANALOG) { analogPin = PIN_TO_ANALOG(pin); if (analogInputsToReport & (1 << analogPin)) { Firmata.sendAnalog(analogPin, analogRead(analogPin)); } } } // report i2c data for all device with read continuous mode enabled if (queryIndex > -1) { for (byte i = 0; i < queryIndex + 1; i++) { readAndReportData(query[i].addr, query[i].reg, query[i].bytes); } } } }
MKR1000 Sketch
C#This sketch sends the majority of sensor readings to the app running on the Raspberry Pi. Make sure to update the Wifi SSID and Password before uploading.
#include <OneWire.h> #include <DallasTemperature.h> #include <ArduinoHttpClient.h> #include <WiFi101.h> #include <SimpleDHT.h> // Using Pin 5 of MKR1000 #define ONE_WIRE_BUS_PIN 5 // TODO: Move out ot separate file #define SECRET_SSID "SECRET_SSID" #define SECRET_PASS "SECRET_PASS" #define RIG_NAME "Gill" char ssid[] = SECRET_SSID; char pass[] = SECRET_PASS; // Setup a oneWire instance for temperature probes OneWire oneWire(ONE_WIRE_BUS_PIN); // Pass our oneWire reference to Dallas Temperature. DallasTemperature sensors(&oneWire); // probe_a: "28 FF 2F 9C B0 16 3 34" // probe_b: "28 FF 36 1E B1 16 4 4D" // probe_c: "28 FF 27 1E B1 16 4 FC" // probe_d: "28 FF 6A 74 B0 16 5 87" // probe_e: "28 FF E B5 B0 16 3 E2" // Define device addresses for each probe DeviceAddress Probe01 = {0x28, 0xFF, 0x2F, 0x9C, 0xB0, 0x16, 0x03, 0x34}; DeviceAddress Probe02 = {0x28, 0xFF, 0x36, 0x1E, 0xB1, 0x16, 0x04, 0x4D}; DeviceAddress Probe03 = {0x28, 0xFF, 0x27, 0x1E, 0xB1, 0x16, 0x04, 0xFC}; DeviceAddress Probe04 = {0x28, 0xFF, 0x6A, 0x74, 0xB0, 0x16, 0x05, 0x87}; DeviceAddress Probe05 = {0x28, 0xFF, 0x0E, 0xB5, 0xB0, 0x16, 0x03, 0xE2}; int uvSensor = A1; int uvIndex = 0; int pinDHT22 = A2; SimpleDHT22 dht22(pinDHT22); int soilSensor = A3; int soilMoisture = 0; char serverAddress[] = "192.168.86.127"; // raspberry pi address int port = 3030; WiFiClient wifi; HttpClient client = HttpClient(wifi, serverAddress, port); int status = WL_IDLE_STATUS; String response; int statusCode = 0; void setup() { // start serial port to show results Serial.begin(9600); delay(3000); pinMode(LED_BUILTIN, OUTPUT); while (status != WL_CONNECTED) { Serial.print("Attempting to connect to Network named: "); Serial.println(ssid); // print the network name (SSID); // Connect to WPA/WPA2 network: status = WiFi.begin(ssid, pass); } // print the SSID of the network you're attached to: Serial.print("SSID: "); Serial.println(WiFi.SSID()); // print your WiFi shield's IP address: IPAddress ip = WiFi.localIP(); Serial.print("IP Address: "); Serial.println(ip); Serial.print("Initializing Temperature Control Library Version "); Serial.println(DALLASTEMPLIBVERSION); // Initialize the Temperature measurement library sensors.begin(); // set the resolution to 10 bit (Can be 9 to 12 bits .. lower is faster) sensors.setResolution(Probe01, 9); sensors.setResolution(Probe02, 9); sensors.setResolution(Probe03, 9); sensors.setResolution(Probe04, 9); sensors.setResolution(Probe05, 9); } void loop() /****** LOOP: RUNS CONSTANTLY ******/ { Serial.println(); Serial.print("Total Probes: "); Serial.println(sensors.getDeviceCount()); // Command all devices on bus to read temperature sensors.requestTemperatures(); float probeA = sensors.getTempC(Probe01); float probeB = sensors.getTempC(Probe02); float probeC = sensors.getTempC(Probe03); float probeD = sensors.getTempC(Probe04); float probeE = sensors.getTempC(Probe05); float moistureSensorValue = analogRead(soilSensor); soilMoisture = ((moistureSensorValue / 1024) - 1) * 100 * -1; float uvSensorValue = analogRead(uvSensor); uvIndex = uvSensorValue / 1024 * 3.3 / 0.1; Serial.print("Rig Name: "); Serial.println(String(RIG_NAME)); Serial.print("ProbeA: "); printTemperature(Probe01); Serial.println(); Serial.print("ProbeB: "); printTemperature(Probe02); Serial.println(); Serial.print("ProbeC: "); printTemperature(Probe03); Serial.println(); Serial.print("ProbeD: "); printTemperature(Probe04); Serial.println(); Serial.print("ProbeE: "); printTemperature(Probe05); Serial.println(); Serial.print("soilMoisture: "); Serial.print(soilMoisture); Serial.println(); Serial.print("uvIndex: "); Serial.print(uvIndex); Serial.println(); byte temperature = 0; byte humidity = 0; int err = SimpleDHTErrSuccess; if ((err = dht22.read(&temperature, &humidity, NULL)) != SimpleDHTErrSuccess) { Serial.print("Read DHT22 failed, err="); Serial.println(err); } else { Serial.print("DHT22: "); Serial.print((int)temperature); Serial.print(" *C, "); Serial.print((int)humidity); Serial.println(" RH%"); } String postURL = String("POST readings to " + String(serverAddress) + ':' + String(port)); Serial.println(postURL); String contentType = "application/x-www-form-urlencoded"; String postData = String( "probeA=" + String(probeA) + "&probeB=" + String(probeB) + "&probeC=" + String(probeC) + "&probeD=" + String(probeD) + "&probeE=" + String(probeE) + "&rig_name=" + String(RIG_NAME) + "&uvIndex=" + String(uvIndex) + "&soilMoisture=" + String(soilMoisture) + "&humidity=" + String(humidity) + "&temperature=" + String(temperature)); digitalWrite(LED_BUILTIN, HIGH); client.post("/temperatures", contentType, postData); // read the status code and body of the response statusCode = client.responseStatusCode(); response = client.responseBody(); Serial.print("Status code: "); Serial.println(statusCode); Serial.print("Response: "); Serial.println(response); digitalWrite(LED_BUILTIN, LOW); delay(100); digitalWrite(LED_BUILTIN, HIGH); delay(100); digitalWrite(LED_BUILTIN, LOW); delay(100); digitalWrite(LED_BUILTIN, HIGH); delay(100); digitalWrite(LED_BUILTIN, LOW); delay(1000); } // print temperature for device adress void printTemperature(DeviceAddress deviceAddress) { float tempC = sensors.getTempC(deviceAddress); if (tempC == -127.00) { Serial.print("Error getting temperature "); } else { Serial.print(tempC, 1); Serial.print(" C"); // Serial.print(" F: "); // Serial.print(DallasTemperature::toFahrenheit(tempC)); } }
SmartTerrariumClient
This is the Client portion of Smart Terrarium built using Vue.js.
ryanjgill / smart-terrarium-client
Client for Smart Terrarium —
Read More
Latest commit to the master branch on 5-27-2019
Download as zip
SmartTerrariumApp
Smart Terrarium App for receiving data, controlling hardware, and running the Smart Terrarium Client. This repo also contains the sketch for the MKR1000.
ryanjgill / smart-terrarium-app
Smart Terrarium App for receiving data, controlling hardware, and running the Smart Terrarium Client — Read More
Latest commit to the master branch on 5-31-2019
Download as zip
(This article copied from hackster.io Author: Ryan Gill)
0 notes
Text
WHAT NO ONE UNDERSTANDS ABOUT TROUBLE
Likewise, a painting with people in their early twenties can have expenses so low that it has to be a genius who will need to be able to filter them. If you invest at 20 and the company gets into trouble. The melon seed model is inaccurate in at least some users who really love you than a large number of people determined not to miss out. And once you apply that kind of idea. This is one of the most important work being done was intellectual archaelogy. Top actors make a lot of money. A lot of my friends who are professors I know what it is about face to face. We told him we'd fund him if he did something else.
But there are a lot of interest. That's ultimately what drives us to work on Viaweb. The customer support people tied for first prize with entries I still shiver to recall. And yet, mysteriously, Viaweb ended up crushing all its competitors. Though we were comparatively old, we weren't tied down by jobs they don't want to write out your whole presentation beforehand and memorize it, that's what a struct is supposed to mean. By breaking software development, Apple gets the opposite of hapless. It's not literally true that you can use any language you want.
Thanks to Patrick Collison, Aaron Swartz, Sarah Harlin, and Sam Altman for putting up with me.
#automatically generated text#Markov chains#Paul Graham#Python#Patrick Mooney#seed#professors#struct
0 notes
Link
Master C# fundamentals in 6 hours – The most popular course with 50,000+ students, packed with tips and exercises!
What you’ll learn
Learn the fundamentals of C# and .NET Framework
Work with primitive types and expressions
Work with non-primitive types (classes, structs, arrays and enums)
Learn the difference between value types and reference types
Control the flow of programs using conditional statements
Use arrays and lists
Work with files and directories
Work with text
Work with date and time
Debug C# applications effectively
Requirements
Visual Studio Community Edition (FREE)
Description
With over 50,000 happy students and 15,000+ positive reviews, this course is Udemy’s most popular course for learning C# from scratch!
C# is a beautiful cross-platform language that can be used to build variety of applications. With C#, you can build mobile apps (for Windows, Android and iOS), games, web sites and desktop applications.
Once you master fundamentals of C# and programming with .NET framework, you’ll have lots of options in front of you. You can choose to build mobile apps if you prefer, or you can change job and work as a web developer. As long as you know the fundamentals well, switching to different technology stacks is pretty easy.
In this course, Mosh, author of several best-selling C# courses on Udemy, teaches you the fundamentals of C# programming in a clear, concise and step-by-step way. Note only that, but he’ll also teach you best practices and shortcuts to help you become a better developer.
Every section comes with a few bite-sized video lectures and a quiz or programming exercises. These exercises are carefully chosen from academic and real-world examples to train your “programming brain”. If you want to be a successful programmer, who has many high-paid job offers and freedom to “choose”, you need to learn how to think like a programmer. And this is what you’re going to get out of these exercises. All exercises come with solutions, so you can compare your solutions with Mosh’s to find areas for improvement.
There are plenty of free tutorials and videos that teach you C# and they are great if all you want to learn is C# constructs. But if you want to learn C# and become a better programmer with a bright future and lots of options, this is the course for you. For every topic, not only will you learn the whats, but you’ll also learn the whys, and hows. You’ll see common errors that pop up as part of developing applications with C#. Mosh explains these errors in detail, and shows you how to resolve them.
THE COMPLETE C# PACKAGE
This course is the first part of Mosh’s complete C# series on Udemy:
Part 1: C# Basics for Beginners: Learn C# Fundamentals by Coding
Part 2: C# Intermediate: Classes, Interfaces and Object-oriented Programming
Part 3: C# Advanced: Take Your C# Skills to the Next Level
WHAT OTHER STUDENTS WHO HAVE TAKEN THIS COURSE SAY:
“I’ve actually landed my first job as a Junior software developer. I owe a lot of it to you because your courses have been EXTREMELY helpful. May God bless you and your efforts to create high quality courses. This has really changed my life from working as a security guard and doing websites for free, now I am a professional.” -Danish Jafri
“Great Instructor, Great Course, Mosh does a great job of breaking down the material and making it interesting.” -Michael Gardner
“You can hear the passion in his voice which makes the course sound 10x more exciting then someone who just does it for the money.” -Tim Medcalf
“Great Instructor, I love the way he teaches the course.” -Edward Tkachev
“I love Mosh’s approach of delivering the theory and then the practice. Audio and video quality are superb.” -Paul Mooney
“You can definitely tell that Mosh is not only an experienced programmer, but he also cares deeply about producing great quality lessons and ensuring that his students are understanding the content.” -David
30-DAY FULL MONEY-BACK GUARANTEE
This course comes with a 30-day full money-back guarantee. Take the course, watch every lecture, and do the exercises, and if you feel like this course is not for you, ask for a full refund within 30 days. All your money back, no questions asked.
ABOUT YOUR INSTRUCTOR
Mosh (Moshfegh) Hamedani is a software engineer with 17 years of professional experience. He is the author of several best selling Udemy courses with more than 120,000 students in 192 countries. He has a Master of Science in Network Systems and Bachelor of Science in Software Engineering. His students describe him as passionate, pragmatic and motivational in his teaching.
Do you want to start learning C# now?
Join the other 50,000+ happy students who have taken this course and start coding within a few minutes.
Who this course is for:
Newbies or students looking for a refresher on the basics of C# and .NET
Created by Mosh Hamedani
Last updated 6/2018
English
English
Size: 1003.34 MB
Download Now
https://ift.tt/20AMe67.
The post C# Basics for Beginners: Learn C# Fundamentals by Coding appeared first on Free Course Lab.
0 notes
Text
Original Post from FireEye
Author: David Zimmer
In this post we are going to take a quick look at what it takes to
write a libemu compatibility layer for the Unicorn engine. In the
course of this work, we will also import the libemu Win32 environment
to run under Unicorn.
For a bit of background, libemu is a lightweight x86 emulator
written in C by Paul Baecher and Markus Koetter. It was released in
2007 and includes a built-in Win32 environment that allows shellcodes
to resolve API at runtime. The library also provides end users with a
convenient way to receive callbacks when API functions are hit. The
original project supported 5 Windows dlls, 51 hooks and 234 opcodes
all wrapped in a tight 1mb package. Unfortunately it is no longer
being updated.
In late 2015, we saw the Unicorn engine project released by Nguyen
Anh Quynh and Dang Hoang Vu. This project takes the processor
emulators from QEMU and wraps them into an easy to use library.
Unicorn, however, does not provide a Win32 layer.
As an experiment, we were curious to see what it would take to bring
the libemu Win32 environment into Unicorn. This task actually turned
out to be quite simple since it was nicely self contained. In the
process of exploring this it also made sense to write a basic shim
layer to support the libemu API and translate its inner workings over
to Unicorn.
Lets start with the common libemu API:
The API is actually very similar to Unicorn:
The major differences are that Unicorn does everything through an
opaque uc_engine* handle, while libemu uses a series of structs such
as emu, emu_cpu, and emu_memory:
In general, the emu and emu_memory structures are passed directly as
arguments to API wrappers such as emu_cpu_get, emu_memory_get and the
emu_memory_read/write functions. There is one common case of direct
member access to the emu_cpu structure that requires some special
attention. This structure gives the user direct read/write access to
the emulator’s virtual processor and is commonly utilized by user
code. Examples to support include:
The next task was to see if we could mimic the direct access to the
emu_cpu elements as if they were static struct fields. Here we enter
the world of C++ operator overloading.
With these tasks complete, porting existing code from libemu over to
Unicorn should be a pretty straightforward task.
In Figure 1 we see an initial test, we put together that includes
the Win32 environment, shim layer, several API hooks and a hard coded payload.
Figure 1: Initial test of the libemu Win32
environment and hooks running under Unicorn
With this working, the next stage was to try it out against a larger
code base. Here we imported the userhooks.cpp from scdbg, an extension
of the libemu sctest that includes some 250 API hooks. As it turns
out, very few changes were required to get it working.
In Figure 2, we can see the results of testing it against a fairly
complex shellcode that:
allocates virtual memory
copies code to the new
alloc
creates a new thread
downloads an
executable
checks the registry for the presence of Antivirus
software
Note that while this shellcode would normally do process injection,
scdbg handles it all inline for simplified analysis.
Figure 2: Complex shellcode running with
hooks imported from scdbg
Another large feature to test was the scdbg debug shell. When
testing software in an emulated environment, having interactive debug
tools available is extremely handy.
Figure 3 shows an example of setting a breakpoint, single stepping,
and examining memory of code running in the emulator.
Figure 3: Imported scdbg debug shell
running with Unicorn Engine and libemu shim layer
Conclusion
In this article we took a quick look at the differences between the
libemu and Unicorn emulators API. This allowed us to create a shim
layer to import legacy libemu code and use it with Unicorn largely unchanged.
Once the shim layer was in place, we next imported the libemu Win32
Environment so we could run it under Unicorn.
As a final test we ported several large portions of the scdbg
project, which was originally written to run under libemu. Here our
previous work allowed for the importation of scdbg’s 250+ API hooks
and debug shell to run under Unicorn with only minimal changes.
Overall the entire process went quite smoothly and should provide
benefits for developers of libemu and/or Unicorn. If you would like to
experiment for yourself you can download a copy of our test project here.
#gallery-0-5 { margin: auto; } #gallery-0-5 .gallery-item { float: left; margin-top: 10px; text-align: center; width: 33%; } #gallery-0-5 img { border: 2px solid #cfcfcf; } #gallery-0-5 .gallery-caption { margin-left: 0; } /* see gallery_shortcode() in wp-includes/media.php */
Go to Source
Author: David Zimmer Writing a libemu/Unicorn Compatability Layer Original Post from FireEye Author: David Zimmer In this post we are going to take a quick look at what it takes to…
0 notes
Text
Rear extension by Turner Architects contains "cloister-like" rooms built around a central courtyard
Turner Architects has renovated and extended a Georgian terraced house in south London, creating a sequence of living spaces interspersed with courtyards that bring the changing colours of the seasons inside.
The brief for A Cloistered House was to give a new lease of life to a three-storey residence in Clapham that had been abandoned for several years and was in a poor state internally.
Top: Turner Architects has extended a Georgian house in London. Above: the studio also restored the three-storey dwelling
Turner Architects restored the existing Georgian building and created new communal living spaces, which are accommodated in a large extension that opens onto the rear garden.
The project was recently announced as the winner of the Urban Oasis of the Year prize at the 2021 Don't Move, Improve! contest.
Pale green walls line the entrance hall
The extension at A Cloistered House incorporates a pair of courtyards that separate some of the living areas and introduce protected outdoor spaces at the centre of the home.
The dining room and kitchen are accommodated at the rear of the extension closest to the garden, and separated from a living room in the middle of the plan by one of the courtyards.
The home's original features were restored
"Conversations we had with the clients resulted in this formal courtyard arrangement at the back of the extension," architect Paul Turner told Dezeen.
"The single cherry tree in the central courtyard becomes like a timepiece for the seasons, with the family able to watch the blossoms appear in spring and the leaves changing colour."
The studio added a 14-metre-long rear extension
A second sunken courtyard to the rear of the existing building functions as a light well that allows natural light to reach a bedroom and playroom on the lower ground floor.
Turner explained that inspiration for the enclosed gardens came from Dutch courtyard paintings admired by the clients, as well as from monastic cloisters and east-Asian courtyard houses.
Sliding doors enclosing the central courtyard can be opened to connect the living and dining spaces on either side. The dining and kitchen area can also be opened up to the garden by retracting the concertinaed glass doors lining this space.
"It was about ensuring that the house can open and close as required," the architect added. "On a nice summer's day they have a really private, protected outdoor space at the heart of the home that can open up to become one big space."
A geometric ceiling covers the living area
A Cloistered House is located within a conservation area, so the 14-metre-long extension was designed to be subservient to the existing property and to ensure it does not impact the neighbouring houses.
The extension's floor level was lowered to prevent the roof height from extending above the fences on either side. Its angular roof provides glimpses of the sky and is covered in grass and wildflowers to maintain the site's overall green area.
The refurbishment of the existing building sought to restore the formal arrangement of internal spaces, whilst making them suitable for modern living.
The extension contains two internal courtyards
According to Turner, the objective of A Cloistered House's renovation was to create "two good rooms on each floor", with a room to the front and another to the rear, supplemented by bathrooms and utility spaces.
The cellular arrangement of bedrooms, studies and bathrooms echo the living spaces found in typical courtyards or monastic accommodation. These spaces also protect the extension from the bustle of the adjacent street.
The kitchen is finished with wooden cabinetry
"You have busy London life happening at the front of the house," added Turner, "with the existing house becoming a defensive wall shielding the quiet, private areas for family gathering at the back."
Throughout the existing building, original features such as cornicing and windows were restored or replaced. The extension has a contrasting modern aesthetic, with white-painted walls, cement kitchen worktops and iroko-wood cabinetry forming a reduced material palette.
Bifold doors open out to the garden
Other projects featured on the shortlist for the annual Don't Move Improve! competition, which is organised by New London Architecture, include the colourful renovation of a townhouse in Islington by Office S&M, and Fraher & Findlay's extension of a self-build modular house.
Photography is by Adam Scott.
Project credits:
Architect: Turner Architects
Engineer: Bini Struct-E ltd
Kitchen: West and Reid
The post Rear extension by Turner Architects contains "cloister-like" rooms built around a central courtyard appeared first on Dezeen.
0 notes
Text
A tweet
Countdown to WWDC Day 54: Swift 4.2 improves Hashable with a new Hasher struct – https://t.co/yRVdMWqzpX #iosdev #swiftlang pic.twitter.com/5suQMtlUBW
— Paul Hudson (@twostraws) May 28, 2018
0 notes
Last Seen Blogs

artistmamtarathore
Indian Artist Mamta Rathore

atdhpgirl
ATD hp girl

sadeceumutplease
birazveylbirazediz

gaeldricge
radical softness!

gildinbainas
Silver Beauty