#filter dataframe by multiple conditions
Text
DataFrame in Pandas: Guide to Creating Awesome DataFrames
Explore how to create a dataframe in Pandas, including data input methods, customization options, and practical examples.
Data analysis used to be a daunting task, reserved for statisticians and mathematicians. But with the rise of powerful tools like Python and its fantastic library, Pandas, anyone can become a data whiz! Pandas, in particular, shines with its DataFrames, these nifty tables that organize and manipulate data like magic. But where do you start? Fear not, fellow data enthusiast, for this guide will…
View On WordPress
#advanced dataframe features#aggregating data in pandas#create dataframe from dictionary in pandas#create dataframe from list in pandas#create dataframe in pandas#data manipulation in pandas#dataframe indexing#filter dataframe by condition#filter dataframe by multiple conditions#filtering data in pandas#grouping data in pandas#how to make a dataframe in pandas#manipulating data in pandas#merging dataframes#pandas data structures#pandas dataframe tutorial#python dataframe basics#rename columns in pandas dataframe#replace values in pandas dataframe#select columns in pandas dataframe#select rows in pandas dataframe#set column names in pandas dataframe#set row names in pandas dataframe
0 notes
Text
Python Libraries Pandas: Your Gateway to Data Science Mastery - Skillslash Pune
1. Introduction
In the world of data science, mastering Python's Pandas library is essential to unlock the full potential of data analysis. Whether you're a seasoned data professional or just beginning your journey in Data Science, Pandas can be your best ally. If you're looking to enhance your skills further, consider enrolling in a comprehensive "Data Science Course in Pune'' at Skillslash, where you can delve deeper into Pandas and other essential data science tools.

2. What is Pandas?
Pandas is an open-source Python library that provides high-performance data structures and data analysis tools. Developed by Wes McKinney, Pandas is widely used in the data science community for its flexibility and ease of use. Its core revolves around two fundamental data structures: Series and DataFrame, making it effortless to work with labeled and relational data.
3. Installing Pandas
Before you embark on your data science journey with Pandas, make sure you have it installed on your system. Don't worry; the process is simple. Just use the following pip command to get Pandas up and running:

4. Creating and Manipulating DataFrames
DataFrames form the backbone of Pandas, enabling you to organize and analyze data efficiently. Whether you're dealing with CSV files or SQL databases, Pandas provides a seamless interface to create and manipulate DataFrames. This knowledge will be invaluable in your "Data Science Course in Pune'' at Skillslash, as you dive into real-world data projects.
5. Data Cleaning with Pandas
Raw data is often messy, with missing values and inconsistencies. With Pandas, you'll have a comprehensive toolkit for data cleaning and preprocessing. Skillslash's "Data Science Course in Pune" will guide you through hands-on exercises to tackle real-world data challenges and enhance your data cleaning skills.
6. Data Selection and Filtering
To extract meaningful insights from vast datasets, you must master the art of data selection and filtering. Pandas offers powerful methods to slice and dice data based on specific conditions. Through Skillslash's "Data Science Course in Pune," you'll gain practical experience in data wrangling, equipping you with the skills to handle complex data sets efficiently.
7. Handling Missing Data
Dealing with missing data is a crucial aspect of data analysis. Pandas provides various techniques to identify and handle missing values. Understanding these methods will enhance the accuracy and reliability of your data-driven insights, which you'll explore in the "Data Science Course in Pune'' at Skillslash.
8. Grouping and Aggregating Data
Grouping data based on certain criteria and performing aggregate functions is a common data analysis task. Pandas simplifies this process with its intuitive syntax, allowing you to gain deeper insights into your data. Skillslash's "Data Science Course in Pune" will take you through advanced data aggregation techniques to make you a proficient data analyst.
9. Merging and Joining DataFrames
Data often resides in multiple sources, and combining them is vital for comprehensive analysis. Pandas offers seamless ways to merge and join DataFrames, making it easier for you to handle complex data relationships. Mastering these techniques will be a valuable addition to your data manipulation arsenal during the "Data Science Course in Pune'' at Skillslash.
10. Time Series Analysis with Pandas
Time series data requires specialized handling, and Pandas excels at it. You'll learn how to work with time-based data, handle date/time operations, and perform time-based aggregations in Skillslash's "Data Science Course in Pune." These skills are particularly crucial when dealing with financial data, sensor data, and many other real-world applications.
11. Pandas for Data Visualization
Data visualization is a powerful tool for communicating insights effectively. Pandas integrates seamlessly with other Python libraries like Matplotlib and Seaborn, empowering you to create visually stunning plots and charts. Through Skillslash's "Data Science Course in Pune," you'll learn how to present your data-driven stories in a visually compelling manner.
12. Case Study: Analyzing Sales Data
Nothing solidifies your understanding of a tool like Pandas more than applying it to a real-world case study. Skillslash's "Data Science Course in Pune" includes practical case studies, such as analyzing sales data using Pandas. This hands-on experience will give you the confidence to tackle data challenges in various domains.
13. Tips and Tricks for Efficient Data Analysis
As you dive deeper into data analysis with Pandas, you'll encounter various tips and tricks to enhance your productivity. Skillslash's experienced instructors will share their insights and best practices, empowering you to optimize your data workflows.
14. Advantages and Limitations of Pandas
Understanding the strengths and limitations of any tool is vital for making informed decisions. In Skillslash's "Data Science Course in Pune," you'll gain a comprehensive understanding of Pandas' advantages and where it may not be the best fit. This knowledge will guide you in choosing the right tools for different data science projects.
15. Conclusion
In conclusion, Python's Pandas library opens the doors to a world of data science possibilities. Whether you're a data enthusiast or a professional, Pandas is an invaluable addition to your skill set. To elevate your data science journey further, consider enrolling in Skillslash's "Data Science Course in Pune," where you'll learn Pandas and various other data science tools under the guidance of industry experts.
16. FAQs
Q1: Is the "Data Science Course in Pune" suitable for beginners?
Absolutely! Skillslash's "Data Science Course in Pune" caters to all skill levels, from beginners to experienced professionals. The course is structured to accommodate learners with varying degrees of expertise.
Q2: Can I access course materials at my own pace?
Yes, Skillslash offers flexible learning options, allowing you to access course materials at your own pace. Learn at a speed that suits your schedule and commitments.
Q3: Are there any prerequisites for the "Data Science Course in Pune"?
While some familiarity with Python and basic data concepts is beneficial, the course is designed to be beginner-friendly. With dedication and enthusiasm, anyone can excel in this course.
Q4: What sets Skillslash's "Data Science Course in Pune" apart from others?
Skillslash's "Data Science Course in Pune" is curated by industry professionals, offering practical insights and real-world applications. You'll gain hands-on experience, ensuring you're well-prepared for the challenges of the data science field.
Q5: How can I enroll in the "Data Science Course in Pune" at Skillslash?
Enrolling is easy! Simply visit https://skillslash.com/data-science-course-in-pune to get access to Skillslash's "Data Science Course in Pune" and take the first step towards becoming a proficient data scientist.
0 notes
Text
pandas: multiple conditions while indexing data frame - unexpected behavior
I am filtering rows in a dataframe by values in two columns.
For some reason the OR operator behaves like I would expect AND operator to behave and vice versa.
My test code:
import pandas as pddf = pd.DataFrame({'a': range(5), 'b': range(5) })# let's insert some -1 valuesdf['a'][1] = -1df['b'][1] = -1df['a'][3] = -1df['b'][4] = -1df1 = df[(df.a != -1) & (df.b != -1)]df2 = df[(df.a != -1) | (df.b != -1)]print pd.concat([df, df1, df2], axis=1, keys = [ 'original df', 'using AND (&)', 'using OR (|)',])
And the result:
original df using AND (&) using OR (|) a b a b a b0 0 0 0 0 0 01 -1 -1 NaN NaN NaN NaN2 2 2 2 2 2 23 -1 3 NaN NaN -1 34 4 -1 NaN NaN 4 -1[5 rows x 6 columns]
As you can see, the AND operator drops every row in which at least one value equals -1. On the other hand, the OR operator requires both values to be equal to -1 to drop them. I would expect exactly the opposite result. Could anyone explain this behavior, please?
I am using pandas 0.13.1.
https://codehunter.cc/a/python/pandas-multiple-conditions-while-indexing-data-frame-unexpected-behavior
0 notes
Text
Five methods for Filtering data with multiple conditions in Python
https://kanoki.org/2020/01/21/pandas-dataframe-filter-with-multiple-conditions/
Comments
1 note
·
View note
Text
Pandas Filter Rows by Condition(s)
Pandas Filter Rows by Condition(s)
You can select the Rows from Pandas DataFrame based on column values or based on multiple conditions either using DataFrame.loc[] attribute, DataFrame.query() or DataFrame.apply() method to use lambda function. In this article, I will explain how to select rows based on single or multiple column values (values from the list) and also how to select rows that have no None or Nan…
View On WordPress
0 notes
Text
Pandas Merge Between Dates

Pandas.Series.between to Select DataFrame Rows Between Two Dates We can also use pandas.Series.between to filter DataFrame based on date.The method returns a boolean vector representing whether series element lies in the specified range or not. We pass thus obtained the boolean vector to loc method to extract DataFrame. On A.cusipB.ncusip and A.fdate is between B.namedt and B.nameenddt. In SQL this would be trivial, but the only way I can see how to do this in pandas is to first merge unconditionally on the identifier, and then filter on the date condition. Merge is a function in the pandas namespace, and it is also available as a DataFrame instance method merge , with the calling DataFrame being implicitly considered the left object in the join. The related join method, uses merge internally for the index-on-index (by default) and column (s)-on-index join. Sep 01, 2020 df. Sortvalues (by=' date ', ascending= False) sales customers date 0 4 2 2020-01-25 2 13 9 2020-01-22 3 9 7 2020-01-21 1 11 6 2020-01-18 Example 2: Sort by Multiple Date Columns Suppose we have the following pandas DataFrame.
Pandas Merge Between Dates In Google Sheets
Pandas Merge Between Dates Formula
Pandas Days Between Two Dates
In this article we will discuss how to merge dataframes on given columns or index as Join keys. Tor browser official.
First let’s get a little intro about Dataframe.merge() again,
Dataframe.merge()
In Python’s Pandas Library Dataframe class provides a function to merge Dataframes i.e.
It accepts a hell lot of arguments. Let’s discuss some of them,
Imp Arguments :
right : A dataframe or series to be merged with calling dataframe
how : Merge type, values are : left, right, outer, inner. Default is ‘inner’. If both dataframes has some different columns, then based on this value, it will be decided which columns will be in the merged dataframe.
on : Column name on which merge will be done. If not provided then merged on indexes.
left_on : Specific column names in left dataframe, on which merge will be done.
right_on : Specific column names in right dataframe, on which merge will be done.
left_index : bool (default False)
If True will choose index from left dataframe as join key.
right_index : bool (default False)
If True will choose index from right dataframe as join key.
suffixes : tuple of (str, str), default (‘_x’, ‘_y’)
Suffex to be applied on overlapping columns in left & right dataframes respectively.
In our previous article our focus was on merging using ‘how’ argument i.e. basically merging Dataframes by default on common columns using different join types. But in this article we will mainly focus on other arguments like what if don’t want to join an all common columns ? What if we want to join on some selected columns only? Let’s see some examples to understand this,
First of all, let’s create two dataframes to be merged.
Tor Browser aims to make all users look the same, making it difficult for you to be fingerprinted based on your browser and device information. MULTI-LAYERED ENCRYPTION. Your traffic is relayed and encrypted three times as it passes over the Tor network. The network is comprised of thousands of volunteer-run servers known as Tor relays. Original tor browser. 41 Best Tor Sites - deep web/dark web have millions of onion sites those are runs on private servers, here I have selected 33 onion sites and all are related to popular categories, all these mention tor websites millions or users use every day. If you want to get these deep web sites links info then visit this post. Tor Browser will block browser plugins such as Flash, RealPlayer, QuickTime, and others: they can be manipulated into revealing your IP address. We do not recommend installing additional add-ons or plugins into Tor Browser. Tor Browser is free and open source software developed the Tor Project, a nonprofit organization. You can help keep Tor strong, secure, and independent by making a donation. Give before the end of.
Pandas Merge Between Dates In Google Sheets
Dataframe 1:
This dataframe contains the details of the employees like, ID, name, city, experience & Age i.e.
Contents of the first dataframe created are,
Dataframe 2:
This dataframe contains the details of the employees like, ID, salary, bonus and experience i.e.
Contents of the second dataframe created are,
Merging Dataframe on a given column name as join key
In both the above dataframes two column names are common i.e. ID & Experience. But contents of Experience column in both the dataframes are of different types, one is int and other is string. There is no point in merging based on that column. By default if we don’t pass the on argument then Dataframe.merge() will merge it on both the columns ID & Experience as we saw in previous post i.e.
https://thispointer.com/pandas-how-to-merge-dataframes-using-dataframe-merge-in-python-part-1/
Which will not work here. Therefore, here we need to merge these two dataframes on a single column i.e. ID. To do that pass the ‘on’ argument in the Datfarame.merge() with column name on which we want to join / merge these 2 dataframes i.e.
Contents of the merged dataframe,
It merged both the above two dataframes on ‘ID’ column. As both the dataframes had a columns with name ‘Experience’, so both the columns were added with default suffix to differentiate between them i.e. Experience_x for column from Left Dataframe and Experience_y for column from Right Dataframe.
In you want to join on multiple columns instead of a single column, then you can pass a list of column names to Dataframe.merge() instead of single column name. Also, as we didn’t specified the value of ‘how’ argument, therefore by default Dataframe.merge() uses inner join. You can also specify the join type using ‘how’ argument as explained in previous article i.e.
Merging Dataframe on a given column with suffix for similar column names
If there are some similar column names in both the dataframes which are not in join key then by default x & y is added as suffix to them.
Like in previous example merged dataframe contains Experience_x & Experience_y. Instead of default suffix, we can pass our custom suffix too i.e.
Contents of the merged dataframe,
We passed a tuple (‘_In_Years’, ‘_Levels’) in suffixes argument and ‘_In_Years’ is added to column from left dataframe and ‘_Levels’ is added to columns from right dataframe.
Merging Dataframe different columns
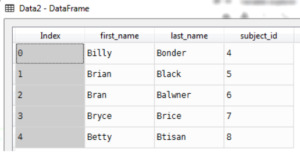
What if both the dataframes was completely different column names. For example let’s rename column ‘ID’ in dataframe 2 i.e.
Now out second dataframe salaryDFObj contents are,
Now let’s see how to merge these two dataframes on ‘ID‘ column from Dataframe 1 and ‘EmpID‘ column from dataframe 2 i.e.
Contents of the merged dataframe,
Till now we have seen merging on columns either by default on specifically given columns. But what if we want to merge in index of both the dataframe ?
We will discuss that in next article. Azure teams.
Pandas Merge Between Dates Formula
Complete example is as follows,
Output:
Pandas Days Between Two Dates
Related Posts:
0 notes
Text
What’s going on on PyPI
Scanning all new published packages on PyPI I know that the quality is often quite bad. I try to filter out the worst ones and list here the ones which might be worth a look, being followed or inspire you in some way.
• starline
Unofficial python library for StarLine API
• adafdr
A fast and covariate-adaptive method for multiple hypothesis testing. Software accompanying the paper ‘AdaFDR: a Fast, Powerful and Covariate-Adaptive Approach to Multiple Hypothesis Testing’, 2018.
• Alexa-Payloads
A Python Library to interface with Alexa
• antspyx
Advanced Normalization Tools in Python
• deepevent
Deep Learning to identify gait events. We propose a new application (_DeepEvent_) of long short term memory recurrent neural network to the automatic detection of gait events. The 3D position and velocity of the markers on the heel, toe and lateral malleolus were used by the network to determine Foot Strike (FS) and Foot Off (FO). The method was developed from 10526 FS and 9375 FO from 226 children. _DeepEvent_ predicted **FS** within **5.5 ms** and **FO** within **10.7 ms** of the gold standard (automatic determination using force platform data) and was more accurate than common heuristic marker trajectory-based methods proposed in the literature and another deep learning method.
• GoogleActions
A Python Library to interface with Alexa
• gsclight
A simplified package for Google Search Console API. A simplified, object-oriented helper library for the (https://…/search-console-api-original ). This package only covers basic API calls and was mainly created for practice purposes. To get the full Google Search Console API experience see Josh Carty’s (https://…/google-searchconsole ).
• numba-scipy
numba-scipy extends Numba to make it aware of SciPy. numba-scipy extends Numba to make it aware of SciPy. Numba is an open source, NumPy-aware optimizing compiler for Python sponsored by Anaconda, Inc. It uses the LLVM compiler project to generate machine code from Python syntax.
• pyus
GPU-accelerated Python package for ultrasound imaging.
• sparkle_test
A small and simple base class for fast and clean PySpark unit tests. Unit testing in Spark is made easier with sparkle-test, the settings are tuned for performance and your unit tests don’t leave any files in your workspace. There is one convenience method for asserting dataframe equality.
• Swarmrob
An Orchestration Tool for Container-based Robot Applications. Because of the very heterogeneous composition of software and hardware in robotics, the reproduction of experiments is a common problem. SwarmRob is a python framework that uses container technologies and orchestration to enable the simple sharing of experimental artifacts and improve the reproducibility in robotics research.
• Swarmrob-Worker
An Orchestration Tool for Container-based Robot Applications. Because of the very heterogeneous composition of software and hardware in robotics, the reproduction of experiments is a common problem. SwarmRob is a python framework that uses container technologies and orchestration to enable the simple sharing of experimental artifacts and improve the reproducibility in robotics research.
• trvae
trVAE – Regularized Conditional Variational Autoencoders
• airtunnel
Airtunnel – tame your Airflow
• deepposekit
A toolkit for pose estimation using deep learning. DeepPoseKit is a software toolkit with a high-level API for 2D pose estimation of user-defined keypoints using deep learning – written in Python and built using [Tensorflow](https://…/tensorflow ) and [Keras](https://…/keras ). Use DeepPoseKit if you need:
• tools for annotating images or video frames with user-defined keypoints
• a straightforward but flexible data augmentation pipeline using the [imgaug package](https://…/imgaug )
• a Keras-based interface for initializing, training, and evaluating pose estimation models
• easy-to-use methods for saving and loading models and making predictions on new data http://bit.ly/2ucff20
0 notes
Text
Course: Berlin.PythonDataVisualization.10-14Dec
Course: Data Manipulation and Visualization with Python Berlin, 10th-14th December 2018 ( http://bit.ly/2r2vtVV ) INSTRUCTOR: DR. Martin Jones (founder, Python for biologists: ( https://bit.ly/2ycQ25u ) ) This course focusses on using Python's scientific software libraries to manipulate and visualise large datasets. It's intended for researchers with a basic knowledge of Python who need to explore large datasets and quickly visualise patterns and relationships. This course is aimed at researchers and technical workers with a background in biology and a basic knowledge of Python (if you've taken the Introductory Python course then you have the Python knowledge; if you're not sure whether you know enough Python to benefit from this course then just drop us an email). Students should have enough biological/bioinformatics background to appreciate the example datasets. They should also have some basic Python experience (the Introduction to Python course will fulfill these requirements). Students should be familiar with the use of lists, loops, functions and conditions in Python and have written at least a few small programs from scratch. Students will require the scientific Python stack to be installed on their laptops before attending; instructions for this will be sent out prior to the course. Detailed syllabus 1. Introduction and datasets Jupyter (formerly iPython) is a programming environment that is rapidly becoming the de facto standard for scientific data analysis. In this session we'll learn why Jupyter is so useful, covering its ability to mix notes and code, to render inline plots, charts and tables, to use custom styles and to create polished web pages. We'll also take a look at the datasets that we'll be investigating during the course and discuss the different types of data we encounter in bioinformatics work. 2. Introduction to pandas In this session we introduce the first part of the scientific Python stack: the pandas data manipulation package. We'll learn about Dataframes X the core data structure that much of the rest of the course will rely on X and how they allow us to quickly select, sort, filter and summarize large datasets. We'll also see how to extend existing Dataframes by writing functions to create new columns, as well as how to deal with common problems like missing or inconsistent values in datasets. We'll get our first look at data visualisation by using pandas' built in plotting ability to investigate basic properties of our datasets. 3. Grouping and pivoting with pandas This session continues our look at pandas with advanced uses of Dataframes that allow us to answer more complicated questions. We'll look two very powerful tools: grouping, which allows us to aggregate information in datasets, and pivoting/stacking, which allows us to flexibly rearrange data (a key step in preparing datasets for visualisation). In this session we'll also go into more detail about pandas indexing system. 4. Advanced manipulation with pandas In this final session on the pandas library we'll look at a few common types of data manipulation X binning data (very useful for working with time series), carrying out principal component analysis, and creating networks. We'll also cover some features of pandas designed for working with specific types of data like timestamps and ordered categories. 5. Introduction to seaborn This session introduces the seaborn charting library by showing how we can use it to investigate relationships between different variables in our datasets. Initially we concentrate on showing distributions with histograms, scatter plots and regressions, as well as a few more exotic chart types like hexbins and KDE plots. We also cover heatmaps, in particular looking at how they lend themselves to displaying the type of aggregate data that we can generate with pandas. 6. Categories in seaborn This session is devoted to seaborn's primary use case: visualising relationships across multiple categories in complex datasets. We see how we can use colour and shape to distinguish categories in single plots, and how these features work together with the pandas tools we have already seen to allow us to very quickly explore a dataset. We continue by using seaborn to build small multiple or facet plots, separating categories by rows and columns. Finally, we look at chart types that are designed to show distributions across categories: box and violin plots, and the more exotic swarm and strip plots. 7. Customisation with seaborn For the final session on seaborn, we go over some common types of customisation that can be tricky. To achieve very fine control over the style and layout of our plots, we'll learn how to work directly with axes and chart objects to implement things like custom heatmap labels, log axis scales, and sorted categories. 8. Matplotlib In the final teaching session, we look at the library that both pandas and seaborn rely on for their charting tools: matplotlib. We'll see how by using matplotlib directly we can do things that would be impossible in pandas or seaborn, such as adding custom annotations to our charts. We'll also look at using matplotlib to build completely new, custom visualisation by combining primitive shapes. 9. / 10. Data workshop The two sessions on the final day are set aside for a data workshop. Students can practice applying the tools they've learned to their own datasets with the help of an instructor, or continue to work on exercises from the previous day. There may also be time for some demonstrations of topics of particular interest, such as interactive visualisation tools and animations. Here is the full list of our courses and Workshops: ( http://bit.ly/2u3eUMV ) Best regards, Carlo Carlo Pecoraro, Ph.D Physalia-courses DIRECTOR [email protected] http://bit.ly/2a6XcQr Twitter: @physacourses mobile: +49 15771084054 http://bit.ly/2AwM0HR "[email protected]"
via Gmail
0 notes
Text
What’s going on on PyPI
Scanning all new published packages on PyPI I know that the quality is often quite bad. I try to filter out the worst ones and list here the ones which might be worth a look, being followed or inspire you in some way.
• starline
Unofficial python library for StarLine API
• adafdr
A fast and covariate-adaptive method for multiple hypothesis testing. Software accompanying the paper ‘AdaFDR: a Fast, Powerful and Covariate-Adaptive Approach to Multiple Hypothesis Testing’, 2018.
• Alexa-Payloads
A Python Library to interface with Alexa
• antspyx
Advanced Normalization Tools in Python
• deepevent
Deep Learning to identify gait events. We propose a new application (_DeepEvent_) of long short term memory recurrent neural network to the automatic detection of gait events. The 3D position and velocity of the markers on the heel, toe and lateral malleolus were used by the network to determine Foot Strike (FS) and Foot Off (FO). The method was developed from 10526 FS and 9375 FO from 226 children. _DeepEvent_ predicted **FS** within **5.5 ms** and **FO** within **10.7 ms** of the gold standard (automatic determination using force platform data) and was more accurate than common heuristic marker trajectory-based methods proposed in the literature and another deep learning method.
• GoogleActions
A Python Library to interface with Alexa
• gsclight
A simplified package for Google Search Console API. A simplified, object-oriented helper library for the (https://…/search-console-api-original ). This package only covers basic API calls and was mainly created for practice purposes. To get the full Google Search Console API experience see Josh Carty’s (https://…/google-searchconsole ).
• numba-scipy
numba-scipy extends Numba to make it aware of SciPy. numba-scipy extends Numba to make it aware of SciPy. Numba is an open source, NumPy-aware optimizing compiler for Python sponsored by Anaconda, Inc. It uses the LLVM compiler project to generate machine code from Python syntax.
• pyus
GPU-accelerated Python package for ultrasound imaging.
• sparkle_test
A small and simple base class for fast and clean PySpark unit tests. Unit testing in Spark is made easier with sparkle-test, the settings are tuned for performance and your unit tests don’t leave any files in your workspace. There is one convenience method for asserting dataframe equality.
• Swarmrob
An Orchestration Tool for Container-based Robot Applications. Because of the very heterogeneous composition of software and hardware in robotics, the reproduction of experiments is a common problem. SwarmRob is a python framework that uses container technologies and orchestration to enable the simple sharing of experimental artifacts and improve the reproducibility in robotics research.
• Swarmrob-Worker
An Orchestration Tool for Container-based Robot Applications. Because of the very heterogeneous composition of software and hardware in robotics, the reproduction of experiments is a common problem. SwarmRob is a python framework that uses container technologies and orchestration to enable the simple sharing of experimental artifacts and improve the reproducibility in robotics research.
• trvae
trVAE – Regularized Conditional Variational Autoencoders
• airtunnel
Airtunnel – tame your Airflow
• deepposekit
A toolkit for pose estimation using deep learning. DeepPoseKit is a software toolkit with a high-level API for 2D pose estimation of user-defined keypoints using deep learning – written in Python and built using [Tensorflow](https://…/tensorflow ) and [Keras](https://…/keras ). Use DeepPoseKit if you need:
• tools for annotating images or video frames with user-defined keypoints
• a straightforward but flexible data augmentation pipeline using the [imgaug package](https://…/imgaug )
• a Keras-based interface for initializing, training, and evaluating pose estimation models
• easy-to-use methods for saving and loading models and making predictions on new data http://bit.ly/2Sykp0z
0 notes
Link
Article URL: https://kanoki.org/2020/01/21/pandas-dataframe-filter-with-multiple-conditions/
Comments URL: https://news.ycombinator.com/item?id=22106575
Points: 5
# Comments: 1
0 notes
Text
Python Libraries Pandas: Your Gateway to Data Science Mastery
1. Introduction
In the world of data science, mastering Python's Pandas library is essential to unlock the full potential of data analysis. Whether you're a seasoned data professional or just beginning your journey in Data Science, Pandas can be your best ally. If you're looking to enhance your skills further, consider enrolling in a comprehensive "Data Science Course'' at Skillslash, where you can delve deeper into Pandas and other essential data science tools.

2. What is Pandas?
Pandas is an open-source Python library that provides high-performance data structures and data analysis tools. Developed by Wes McKinney, Pandas is widely used in the data science community for its flexibility and ease of use. Its core revolves around two fundamental data structures: Series and DataFrame, making it effortless to work with labeled and relational data.
3. Installing Pandas
Before you embark on your data science journey with Pandas, make sure you have it installed on your system. Don't worry; the process is simple. Just use the following pip command to get Pandas up and running:

4. Creating and Manipulating DataFrames
DataFrames form the backbone of Pandas, enabling you to organize and analyze data efficiently. Whether you're dealing with CSV files or SQL databases, Pandas provides a seamless interface to create and manipulate DataFrames. This knowledge will be invaluable in your "Data Science Course'' at Skillslash, as you dive into real-world data projects.
5. Data Cleaning with Pandas
Raw data is often messy, with missing values and inconsistencies. With Pandas, you'll have a comprehensive toolkit for data cleaning and preprocessing. Skillslash's "Data Science Course" will guide you through hands-on exercises to tackle real-world data challenges and enhance your data cleaning skills.
6. Data Selection and Filtering
To extract meaningful insights from vast datasets, you must master the art of data selection and filtering. Pandas offers powerful methods to slice and dice data based on specific conditions. Through Skillslash's "Data Science Course," you'll gain practical experience in data wrangling, equipping you with the skills to handle complex data sets efficiently.
7. Handling Missing Data
Dealing with missing data is a crucial aspect of data analysis. Pandas provides various techniques to identify and handle missing values. Understanding these methods will enhance the accuracy and reliability of your data-driven insights, which you'll explore in the "Data Science Course'' at Skillslash.
8. Grouping and Aggregating Data
Grouping data based on certain criteria and performing aggregate functions is a common data analysis task. Pandas simplifies this process with its intuitive syntax, allowing you to gain deeper insights into your data. Skillslash's "Data Science Course" will take you through advanced data aggregation techniques to make you a proficient data analyst.
9. Merging and Joining DataFrames
Data often resides in multiple sources, and combining them is vital for comprehensive analysis. Pandas offers seamless ways to merge and join DataFrames, making it easier for you to handle complex data relationships. Mastering these techniques will be a valuable addition to your data manipulation arsenal during the "Data Science Course'' at Skillslash.
10. Time Series Analysis with Pandas
Time series data requires specialized handling, and Pandas excels at it. You'll learn how to work with time-based data, handle date/time operations, and perform time-based aggregations in Skillslash's "Data Science Course." These skills are particularly crucial when dealing with financial data, sensor data, and many other real-world applications.
11. Pandas for Data Visualization
Data visualization is a powerful tool for communicating insights effectively. Pandas integrates seamlessly with other Python libraries like Matplotlib and Seaborn, empowering you to create visually stunning plots and charts. Through Skillslash's "Data Science Course," you'll learn how to present your data-driven stories in a visually compelling manner.
12. Case Study: Analyzing Sales Data
Nothing solidifies your understanding of a tool like Pandas more than applying it to a real-world case study. Skillslash's "Data Science Course" includes practical case studies, such as analyzing sales data using Pandas. This hands-on experience will give you the confidence to tackle data challenges in various domains.
13. Tips and Tricks for Efficient Data Analysis
As you dive deeper into data analysis with Pandas, you'll encounter various tips and tricks to enhance your productivity. Skillslash's experienced instructors will share their insights and best practices, empowering you to optimize your data workflows.
14. Advantages and Limitations of Pandas
Understanding the strengths and limitations of any tool is vital for making informed decisions. In Skillslash's "Data Science Course," you'll gain a comprehensive understanding of Pandas' advantages and where it may not be the best fit. This knowledge will guide you in choosing the right tools for different data science projects.
15. Conclusion
In conclusion, Python's Pandas library opens the doors to a world of data science possibilities. Whether you're a data enthusiast or a professional, Pandas is an invaluable addition to your skill set. To elevate your data science journey further, consider enrolling in Skillslash's "Data Science Course," where you'll learn Pandas and various other data science tools under the guidance of industry experts.
16. FAQs
Q1: Is the "Data Science Course" suitable for beginners?
Absolutely! Skillslash's "Data Science Course" caters to all skill levels, from beginners to experienced professionals. The course is structured to accommodate learners with varying degrees of expertise.
Q2: Can I access course materials at my own pace?
Yes, Skillslash offers flexible learning options, allowing you to access course materials at your own pace. Learn at a speed that suits your schedule and commitments.
Q3: Are there any prerequisites for the "Data Science Course"?
While some familiarity with Python and basic data concepts is beneficial, the course is designed to be beginner-friendly. With dedication and enthusiasm, anyone can excel in this course.
Q4: What sets Skillslash's "Data Science Course" apart from others?
Skillslash's "Data Science Course" is curated by industry professionals, offering practical insights and real-world applications. You'll gain hands-on experience, ensuring you're well-prepared for the challenges of the data science field.
Q5: How can I enroll in the "Data Science Course" at Skillslash?
Enrolling is easy! Simply visit https://skillslash.com/data-science-course to get access to Skillslash's "Data Science Course" and take the first step towards becoming a proficient data scientist.
0 notes
Text
Select rows in pandas MultiIndex DataFrame
What are the most common pandas ways to select/filter rows of a dataframe whose index is a MultiIndex?
Slicing based on a single value/label
Slicing based on multiple labels from one or more levels
Filtering on boolean conditions and expressions
Which methods are applicable in what circumstances
Assumptions for simplicity:
input dataframe does not have duplicate index keys
input dataframe below only has two levels. (Most solutions shown here generalize to N levels)
Example input:
mux = pd.MultiIndex.from_arrays([ list('aaaabbbbbccddddd'), list('tuvwtuvwtuvwtuvw')], names=['one', 'two'])df = pd.DataFrame({'col': np.arange(len(mux))}, mux) colone two a t 0 u 1 v 2 w 3b t 4 u 5 v 6 w 7 t 8c u 9 v 10d w 11 t 12 u 13 v 14 w 15
Question 1: Selecting a Single Item
How do I select rows having "a" in level "one"?
colone two a t 0 u 1 v 2 w 3
Additionally, how would I be able to drop level "one" in the output?
coltwo t 0u 1v 2w 3
Question 1b
How do I slice all rows with value "t" on level "two"?
colone two a t 0b t 4 t 8d t 12
Question 2: Selecting Multiple Values in a Level
How can I select rows corresponding to items "b" and "d" in level "one"?
colone two b t 4 u 5 v 6 w 7 t 8d w 11 t 12 u 13 v 14 w 15
Question 2b
How would I get all values corresponding to "t" and "w" in level "two"?
colone two a t 0 w 3b t 4 w 7 t 8d w 11 t 12 w 15
Question 3: Slicing a Single Cross Section (x, y)
How do I retrieve a cross section, i.e., a single row having a specific values for the index from df? Specifically, how do I retrieve the cross section of ('c', 'u'), given by
colone two c u 9
Question 4: Slicing Multiple Cross Sections [(a, b), (c, d), ...]
How do I select the two rows corresponding to ('c', 'u'), and ('a', 'w')?
colone two c u 9a w 3
Question 5: One Item Sliced per Level
How can I retrieve all rows corresponding to "a" in level "one" or "t" in level "two"?
colone two a t 0 u 1 v 2 w 3b t 4 t 8d t 12
Question 6: Arbitrary Slicing
How can I slice specific cross sections? For "a" and "b", I would like to select all rows with sub-levels "u" and "v", and for "d", I would like to select rows with sub-level "w".
colone two a u 1 v 2b u 5 v 6d w 11 w 15
Question 7 will use a unique setup consisting of a numeric level:
np.random.seed(0)mux2 = pd.MultiIndex.from_arrays([ list('aaaabbbbbccddddd'), np.random.choice(10, size=16)], names=['one', 'two'])df2 = pd.DataFrame({'col': np.arange(len(mux2))}, mux2) colone two a 5 0 0 1 3 2 3 3b 7 4 9 5 3 6 5 7 2 8c 4 9 7 10d 6 11 8 12 8 13 1 14 6 15
Question 7: Filtering by numeric inequality on individual levels of the multiindex
How do I get all rows where values in level "two" are greater than 5?
colone two b 7 4 9 5c 7 10d 6 11 8 12 8 13 6 15
Note: This post will not go through how to create MultiIndexes, how to perform assignment operations on them, or any performance related discussions (these are separate topics for another time).
https://codehunter.cc/a/python/select-rows-in-pandas-multiindex-dataframe
0 notes
Text
Pandas Filter by Column Value
Pandas Filter by Column Value
pandas support several ways to filter rows by column value, DataFrame.query() method is used to filter the rows based on the expression (single or multiple column conditions) provided and returns a new DataFrame after applying the column filter. In case you wanted to update the existing or referring DataFrame use inplace=True argument.
In this article, I will explain the syntax of the Pandas…
View On WordPress
0 notes
Text
Spark DataFrame Where() to filter rows
Spark DataFrame Where() to filter rows
Spark where() function is used to filter the rows from DataFrame or Dataset based on the given condition or SQL expression, In this tutorial, you will learn how to apply single and multiple conditions on DataFrame columns using where() function with Scala examples.
Spark DataFrame where() Syntaxes
1) where(condition: Column): Dataset[T] 2) where(conditionExpr: String): Dataset[T] //using…
View On WordPress
0 notes
Last Seen Blogs

engineering-1234
Untitled

upside-blue
[deep breath] [sigh] [empty stare]

mobanjaree
all things must pass away

dai-dark
大ダーク

spencernikes
Spencer nikes