#ArrayDeque
Text
Коллекции?
Если коротко, то
Существует несколько типов коллекций (интерфейсов):
List - упорядоченный список. Элементы хранятся в порядке добавления, проиндексированы.
Queue - очередь. Первый пришёл - первый ушёл, то есть элементы добавляются в конец, а удаляются из начала.
Set - неупорядоченное множество. Элементы могут храниться в рандомном порядке.
Map - пара ключ-значение. Пары хранятся неупорядоченно.
У них есть реализации.
Реализации List
ArrayList - самый обычный массив. Расширяется автоматически. Может содержать элементы разных классов.
LinkedList - элементы имеют ссылки на рядом стоящие элементы. Быстрое удаление за счёт того, что элементы никуда не сдвигаются, заполняя образовавшийся пробел, как в ArrayList.
Реализации Queue
LinkedList - рассказано выше. Да, оно также реализует интерфейс Queue.
ArrayDeque - двунаправленная очередь, где элементы могут добавляться как в начало так и в конец. Также и с удалением.
PriorityQueue - элементы добавляются в сортированном порядке (по возрастанию или по алфавиту или так, как захочет разработчик)
Реализации Set
HashSet - элементы хранятся в хэш-таблице, в бакетах. Бакет каждого элемента определяется по его хэш-коду. Добавление, удаление и поиск происходят за фиксированное количество времени.
LinkedHashSet - как HashSet, но сохраняет порядок добавления элементов.
TreeSet - используется в том случает, когда элементы надо упорядочить. По умолчанию используется естественный порядок, организованный красно-чёрным деревом. (Нет, я не буду это здесь объяснять, не заставите)
LinkedList - рассказано выше. Да, оно также реализует интерфейс Queue.
ArrayDeque
Реализации Map
HashMap - то же самое что и HashSet. Использует хэш-таблицу для хранения.
TreeMap - тоже использует красно-чёрное дерево. Как и TreeSet, это достаточно медленно работающая структура для малого количества данных.
LinkedHashMap. Честно? Тяжеловато найти информацию про различия с LinkedHashSet, кроме того, что один - это Set, а второй - Map. Мда :/
А связи всего этого выглядят так
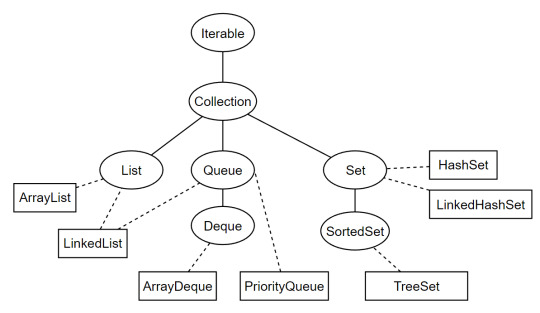
Овалы - интерфейсы;
Прямоугольники - классы;
Здесь видно, что начало начал - интерфейс Iterable, ну а общий для всех интерфейс - Collection (Не путать с фреймворком Collections)
А где Map? а вот он
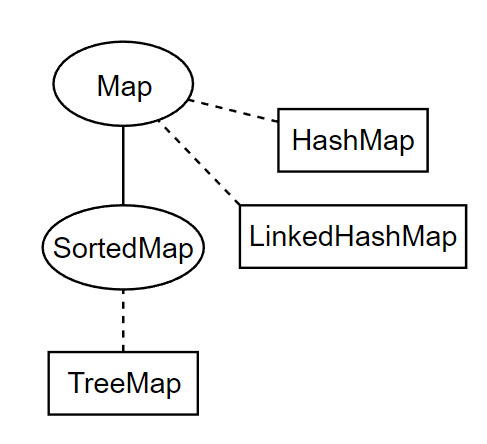
Map не наследуется от Collection - он сам по себе.
К этой теме также можно много чего добавить: устройство красно-черного дерева, работа HashSet'ов и HashMap'ов под капотом, сложность коллекций. Но это всё темы для следующих постов.
Ну, а пока надеюсь, что понятно.
#студент бормочет#List#Set#Queue#Map#ArrayList#LinkedList#ArrayDeque#PriorityOueue#HashMap#HashSet#LinkedHashMap#LinkedHashSet#TreeMap#TreeSet#как же много тегов#Коллекции
0 notes
Text
the utter plebeians who write critically acclaimed LeetCode solutions with reputation in the 4-5K's: [use arrays no matter what operations of list, stack, queue, deque etc. they are actually leveraging]
me, a patrician who cares not for such pedestrian concerns as "memory usage", wishing only to signal intent and flex my knowledge of the Java collections API: new ArrayDeque<Integer>(). new HashMap<Character, Integer>(). new TreeMap<Integer, ArrayDeque<Integer>>(). none of you shall be free from my repeated invocations of Deque::peekFirst()
3 notes
·
View notes
Text
The Collection Framework in Java

What is a Collection in Java?
Java collection is a single unit of objects. Before the Collections Framework, it had been hard for programmers to write down algorithms that worked for different collections. Java came with many Collection classes and Interfaces, like Vector, Stack, Hashtable, and Array.
In JDK 1.2, Java developers introduced theCollections Framework, an essential framework to help you achieve your data operations.
Why Do We Need Them?
Reduces programming effort & effort to study and use new APIs
Increases program speed and quality
Allows interoperability among unrelated APIs
Reduces effort to design new APIs
Fosters software reuse
Methods Present in the Collection Interface
NoMethodDescription1Public boolean add(E e)To insert an object in this collection.2Public boolean remove(Object element)To delete an element from the collection.3Default boolean removeIf(Predicate filter)For deleting all the elements of the collection that satisfy the specified predicate.4Public boolean retainAll(Collection c)For deleting all the elements of invoking collection except the specified collection.5Public int size()This return the total number of elements.6Publicvoid clear()This removes the total number of elements.7Publicboolean contains(Object element)It is used to search an element.8PublicIterator iterator()It returns an iterator.9PublicObject[] toArray()It converts collection into array.
Collection Framework Hierarchy
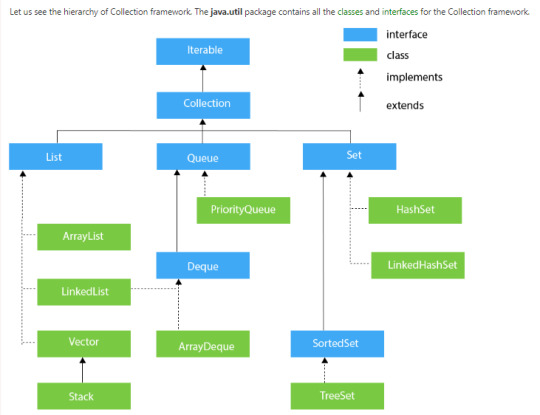
List Interface
This is the child interface of the collectioninterface. It is purely for lists of data, so we can store the ordered lists of the objects. It also allows duplicates to be stored. Many classes implement this list interface, including ArrayList, Vector, Stack, and others.
Array List
It is a class present in java. util package.
It uses a dynamic array for storing the element.
It is an array that has no size limit.
We can add or remove elements easily.
Linked List
The LinkedList class uses a doubly LinkedList to store elements. i.e., the user can add data at the initial position as well as the last position.
It allows Null insertion.
If we’d wish to perform an Insertion /Deletion operation LinkedList is preferred.
Used to implement Stacks and Queues.
Vector
Every method is synchronized.
The vector object is Thread safe.
At a time, one thread can operate on the Vector object.
Performance is low because Threads need to wait.
Stack
It is the child class of Vector.
It is based on LIFO (Last In First Out) i.e., the Element inserted in last will come first.
Queue
A queue interface, as its name suggests, upholds the FIFO (First In First Out) order much like a conventional queue line. All of the elements where the order of the elements matters will be stored in this interface. For instance, the tickets are always offered on a first-come, first-serve basis whenever we attempt to book one. As a result, the ticket is awarded to the requester who enters the queue first. There are many classes, including ArrayDeque, PriorityQueue, and others. Any of these subclasses can be used to create a queue object because they all implement the queue.
Dequeue
The queue data structure has only a very tiny modification in this case. The data structure deque, commonly referred to as a double-ended queue, allows us to add and delete pieces from both ends of the queue. ArrayDeque, which implements this interface. We can create a deque object using this class because it implements the Deque interface.
Set Interface
A set is an unordered collection of objects where it is impossible to hold duplicate values. When we want to keep unique objects and prevent object duplication, we utilize this collection. Numerous classes, including HashSet, TreeSet, LinkedHashSet, etc. implement this set interface. We can instantiate a set object with any of these subclasses because they all implement the set.
LinkedHashSet
The LinkedHashSet class extends the HashSet class.
Insertion order is preserved.
Duplicates aren’t allowed.
LinkedHashSet is non synchronized.
LinkedHashSet is the same as the HashSet except the above two differences are present.
HashSet
HashSet stores the elements by using the mechanism of Hashing.
It contains unique elements only.
This HashSet allows null values.
It doesn’t maintain insertion order. It inserted elements according to their hashcode.
It is the best approach for the search operation.
Sorted Set
The set interface and this interface are extremely similar. The only distinction is that this interface provides additional methods for maintaining the elements' order. The interface for handling data that needs to be sorted, which extends the set interface, is called the sorted set interface. TreeSet is the class that complies with this interface. This class can be used to create a SortedSet object because it implements the SortedSet interface.
TreeSet
Java TreeSet class implements the Set interface it uses a tree structure to store elements.
It contains Unique Elements.
TreeSet class access and retrieval time are quick.
It doesn’t allow null elements.
It maintains Ascending Order.
Map Interface
It is a part of the collection framework but does not implement a collection interface. A map stores the values based on the key and value Pair. Because one key cannot have numerous mappings, this interface does not support duplicate keys. In short, The key must be unique while duplicated values are allowed. The map interface is implemented by using HashMap, LinkedHashMap, and HashTable.
HashMap
Map Interface is implemented by HashMap.
HashMap stores the elements using a mechanism called Hashing.
It contains the values based on the key-value pair.
It has a unique key.
It can store a Null key and Multiple null values.
Insertion order isn’t maintained and it is based on the hash code of the keys.
HashMap is Non-Synchronized.
How to create HashMap.
LinkedHashMap
The basic data structure of LinkedHashMap is a combination of LinkedList and Hashtable.
LinkedHashMap is the same as HashMap except above difference.
HashTable
A Hashtable is an array of lists. Each list is familiar as a bucket.
A hashtable contains values based on key-value pairs.
It contains unique elements only.
The hashtable class doesn’t allow a null key as well as a value otherwise it will throw NullPointerException.
Every method is synchronized. i.e At a time one thread is allowed and the other threads are on a wait.
Performance is poor as compared to HashMap.
This blog illustrates the interfaces and classes of the java collection framework. Which is useful for java developers while writing efficient codes. This blog is intended to help you understand the concept better.
At Sanesquare Technologies, we provide end-to-end solutions for Development Services. If you have any doubts regarding java concepts and other technical topics, feel free to contact us.
0 notes
Link
ArrayDeque (читається як аррейдек) – це клас який забезпечує двосторонню чергу. Іншими словами - це автоматично зростаючий масив, що дозволяє нам додавати або видаляти елементи з обох боків черги. ArrayDeque може бути використано як стек (LIFO, останній ввійшов - перший вийшов) або ж як черга (FIFO, перший ввійшов - перший вийшов).
0 notes
Text
The Breadth-First Search Algorithm
Graphs can be traversed in a depth-first or breadth-first manner. The first one is particularly useful when your data is a DAG (directed, acyclical graph), but both can be applied to any given kind of graph, including trees.
Consider this example:
This is a graph with 9 nodes, which I have key colored to show the depth of every layer of nodes. Hopefully this clears out the topology a bit. This graph can be represented as a 9 x 9 adjacency matrix as shown above (if you have N nodes, necessarily you need N x N size in your matrix).
The key to traversing the graph in a breadth-first manner is the implementation of two auxiliary data structures:
An N-sized array to keep track of what nodes you have already visited in your traversal, to avoid cycles when going down the graph by layers.
A queue of nodes of dynamic size, which will shift the nodes in order as you visit them, and unshift them as you traverse down.
So in this example, you would do this, if you wished to traverse the tree starting from node 0:
Enqueue 0
Dequeue 0
Enqueue all its children, 1, 2, 3 (queue = 1, 2, 3)
Add 0 to output
Mark 0 as visited
Dequeue 1
If not visited yet, enqueue all its children, 4 and 5 (queue = 2, 3, 4, 5)
Add 1 to output
Mark 1 as visited
Dequeue 2
If not visited yet, enqueue all its children, 3 and 6 (queue = 3, 4, 5, 6) ... REPEAT UNTIL THE QUEUE IS EMPTY and all nodes have been visited
This is a sample implementation:
public class Main { public static int N = 9; public static void main(String[] args) { int[][] graph = new int[N][N]; graph[0][1] = 1; graph[0][2] = 1; graph[0][3] = 1; graph[1][4] = 1; graph[1][5] = 1; graph[2][3] = 1; graph[2][6] = 1; graph[3][7] = 1; graph[3][8] = 1; System.out.println(bfs(graph, 0).toString()); } private static List bfs(int[][] graph, int startNode) { Queue<Integer> queue = new ArrayDeque(); List<Integer> output = new ArrayList<>(); //visited array of N elements to avoid cycles boolean[] visited = new boolean[N]; int current = startNode; queue.add(current); while(!queue.isEmpty()) { if(!visited[current]){ for (int j = 0; j < N; j++) { if (graph[current][j] != 0) { queue.add(j); } } output.add(current); visited[current] = true; } current = queue.remove(); } //catch last element to get shifted from queue output.add(current); return output; } }
0 notes
Text
[100% OFF] Master Java Collection Framework
[100% OFF] Master Java Collection Framework
What you Will learn ?
Collection Interfaces
Types of Data Structures
ArrayList Class
LinkedList Class
Iterator, ListIterator and Spliterator
Queue and Stack
ArrayDeque Class
PriorityQueue Class
Map Classes
How Hashing Works
HashMap Class
LinkedHashMap Class
TreeMap Class
EnumMap, WeakHashMap and IdentityHashMap Classes
HashSet Class
LinkedHashSet Class
TreeSet Class
Collection…

View On WordPress
0 notes
Text
7 | Linked-lists
Linked-lists
The key difference between an ArrayDeque and a Doubly Linked List is that null elements can be added in the Doubly Linked List but not in the ArrayDeque. Doubly Linked List can store null elements, thus, it consumes more space. Doubly Linked List is said to be more efficient in removing elements for iteration.
We use DLList when:
> can be used in navigation systems where both front and back navigation is required
> implementing undo and redo functionality
> removing the current element in the iteration
> using null elements in a list or sequence
and use ArrayDeque when:
> saving up space

0 notes
Text



haven’t posted more / sooner since, honestly, my notes around these exercises have been a mess 🙈
these are 2 related problems on implementing the method ‘rotate’, for raw arrays & for ArrayDeque / DualArrayDeque respectively. the technique I adopted for the array rotation actually just sort of came to me while I was playing with examples in my mind. it occurred to me that, separate from the details around storing array values temporarily as we overwrite the indices they originally belonged to, taking the greatest common denominator of r the rotation length & n the array size could help organize the operation into several “subrotations.” but actually sitting down to prove this became nontrivial (I was rusty on the basics of modular arithmetic.) in the end, I just sketched a proof and moved on.
actually implementing ‘rotate’ in a way that was perfectly generic to all Java AbstractLists, while being able to override with more efficient implementation for certain subclasses, turned out to be a handy introduction to the “wrapper” idiom! (in all fairness I did lean on ChatGPT to show me the basics, maybe there’s other better language features for this.) I think nowadays Scala has traits for this, but it’s still nice any time I can learn new ways of fending for myself in a Java codebase
0 notes
Text



This analysis has to do with DualArrayDeque, a structure which has performance characteristics that are essentially the same as ArrayDeque, but illustrating the use of combining multiple smaller data structures to implement a larger one.
Just like ArrayDeque, its add / remove operations run roughly in O(min{i, n-i}) time, where i and n are the index of the operation and the size of the collection respectively. As well, the "maintenance" operation (which in this case is called balance, since its primary role is to rebalance the number of items in the front vs. the back stack) has an amortized cost of O(1) per add / remove operation performed since the empty DualArrayDeque was initialized.
The middle section gave me a bit of trouble! Here is what the text has to say about analyzing the 'add' running time, when the index is "in the middle" (i.e. n/4 < i <= 3n/4):
When n/4 ≤ i < 3n/4, we cannot be sure whether the operation affects front or back, but in either case, the operation takes O(n) = O(i) = O(n−i) time, since i ≥ n/4 and n−i > n/4. [...] Thus, the running time of add(i,x), if we ignore the cost of the call to balance(), is O(1 + min{i,n−i}).
Ignore the constant-time piece "O(1)" and focus on the "min{i, n-i}" piece. The first thing to know when it comes to big-O notation for analyzing running times in comp sci is that people write "f(n) = O(g(n))" to say, basically:
Eventually (for large enough n), f(n) is always bounded above by some factor of g(n) i.e. c * g(n).
The use of the equals sign tends to obscure (for beginners, anyway) that this is really describing a membership claim (i.e. that f(n) belongs to the class of functions that are thus bounded above.) It's weird to get used to, but it's tradition and you basically see it everywhere in the literature.
With that in mind, what the analysis for n/4 ≤ i < 3n/4 really says is more like the following (if we unpack it a bit and add missing details):
Whether the 'add' operation affects front (in which case the number of items displaced is i < 3n/4) or back (in which case the number of items displaced is (n−i) ≤ 3n/4), then in any case the running time is bounded above by a multiple of n: specifically, c := 3/4. (This is because all the real work of the 'add' operation lies precisely in displacing the elements.) So the running time is O(n). But! The quantities i and (n−i) themselves are both ≥ n/4 in this scenario under consideration (precisely because i comes from the middle of the sequence.) So, up to the appropriate factor, they both bound n from above. Since their minimum bounds n thus if both of them do, then we may as well write that n is O(min{i, n−i}) in this case, which means the actual running time for 'add' is as well.
That's a lot of transforming and chaining inequalities, some of which is swept under the rug a bit by the big-O notation. As weird as it was to deal with, I did find (eventually) that unpacking the original statement was a good exercise in figuring out how to use it.
0 notes
Text
6 | Array-Based Lists
Array-Based Lists
The lab exercise wants us to implement an ArrayDeque then it also wants us to incorporate a List interface. To be honest, I always get nervous in doing a lab exercise since I always think that its gonna be hard. [Yes I overthink so much even before doing the task HAHA]
"input.dat"— this got me crying in difficulty since its first appearance in lab exercise one. It took me a while before finding out that it was actually an input (for real) and should be read by the code that I'm about to write. I spent long hours searching the web on how to import it and I really find it difficult since I have no knowledge about Python. Python is still so foreign to me. [even c++ and c — I still need to study these languages a lot, like a lot.] Good thing that I have block mates who helped through the process and got me out of my misery in this lab exercise.
0 notes
Last Seen Blogs

rusizudice
rusizudice

skywalkergeek
𝓗𝓪𝓹𝓹𝓲𝓵𝔂 𝓮𝓿𝓮𝓻 𝓪𝓯𝓽𝓮

ameliarachmadani1432
Untitled

goblin--brain
18+

gendermonkey
Cheeky Gender Monkey