
jesstielle
taste the rainbow
I'm Jess. She/her. Ace. I'm 29....... and no i dont like that fact either
19189 posts
Don't wanna be here? Send us removal request.
Last Seen Blogs

aligomaa163
Untitled

edwardelricgirl200
I'm here to write....

ivydoomkitty
Ivy Doomkitty: A "Tail" of Doom

days-e
days-e's art

v1olentdelights
God, I'm so lovesick
Text

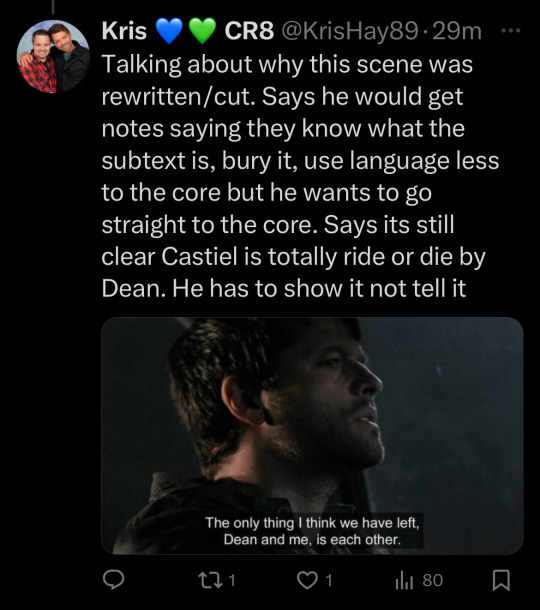
Talking about why this scene was rewritten/cut. Says he would get notes saying they know what the subtext is, bury it, use language less to the core but he wants to go straight to the core. Says its still clear Castiel is totally ride or die by Dean. He has to show it not tell it.
You were not crazy, folks, and I need to lie down.
4K notes
·
View notes
Text
re: the watcher news
do i agree with the decision on a personal level? nah. as soon as i saw they had a big announcement coming and the URL 'watcher tv' i knew what i was gonna be and i was bummed about it
do i get that everyone is Suffering in this economy and they're trying to make the best of a bad situation? yeah. i do. so i'm gonna subscribe for as long as it's viable personally and see how it goes. I love these guys and want to see them succeed. if i can help a little bit, awesome.
3 notes
·
View notes
Text




PEDRO PASCAL
Interviewed by Access Hollywood | SAG Awards 2024

5K notes
·
View notes
Text
While I nodded, nearly napping, suddenly there came a slapping,
As of some one gently flapping, flapping at my chamber door.
“’Tis some fairy,” I muttered, “slapping at my chamber door—
Only this and nothing more.”
97K notes
·
View notes
Text
Automattic will sign a contract with OpenAI for Midjourney to learn off of Tumblr and Wordpress
Hello! Automattic, Tumblr's parent company, will sign a contract with OpenAI and Midjourney so Midjourney can learn off of Tumblr's and WordPress' art and other user data. :) (The full text of this article is copy/pasted in the cut below). You can opt out! but I truly cannot imagine a more idiotic or out of touch decision on the part of Tumblr's CEO.
First thing's first: When/if this goes live, opt out of this immediately. Do this even if you're not an artist. The more people opt out, the less valuable this contract is to Midjourney. in an ideal world, literally all of the active users would opt out, but if we can even get to 50% that's pretty delicious.
Second: Contact Tumblr Support. It's vital that you do this politely. Tumblr staff is not responsible for this decision and the point of doing this is to show the userbase's unwillingness to be involved in this, not harangue Tumblr staff. (Seriously, stop haranguing Tumblr staff). Here's a script:
Hi, I'm writing in to express my disappointment in Automattic's pending contract with OpenAI to sell user data. Midjourney is already embroiled in copyright lawsuits, and it is not possible to train it without compromising copyright, including violating the IP of artists on this site. I strongly protest this contract and will opt out if it goes live. Depending on the privacy terms around what user data is sold to OpenAI and why, it is possible I will leave the platform entirely. Thank you for your time.
Third: Download Glaze and start poisoning them prompts, my friends
Fourth: Stare into the middle distance for a second with me because holy fucking shit? How stupid can one decision be?
Tumblr and Wordpress are preparing to sell user data to Midjourney and OpenAI, according to a source with internal knowledge about the deals and internal documentation referring to the deals.
The exact types of data from each platform going to each company are not spelled out in documentation we’ve reviewed, but internal communications reviewed by 404 Media make clear that deals between Automattic, the platforms’ parent company, and OpenAI and Midjourney are imminent.
The internal documentation details a messy and controversial process within Tumblr itself. One internal post made by Cyle Gage, a product manager at Tumblr, states that a query made to prepare data for OpenAI and Midjourney compiled a huge number of user posts that it wasn’t supposed to. It is not clear from Gage’s post whether this data has already been sent to OpenAI and Midjourney, or whether Gage was detailing a process for scrubbing the data before it was to be sent.
Gage wrote:
“the way the data was queried for the initial data dump to Midjourney/OpenAI means we compiled a list of all tumblr’s public post content between 2014 and 2023, but also unfortunately it included, and should not have included:
private posts on public blogs
posts on deleted or suspended blogs
unanswered asks (normally these are not public until they’re answered)
private answers (these only show up to the receiver and are not public)
posts that are marked ‘explicit’ / NSFW / ‘mature’ by our more modern standards (this may not be a big deal, I don’t know)
content from premium partner blogs (special brand blogs like Apple’s former music blog, for example, who spent money with us on an ad campaign) that may have creative that doesn’t belong to us, and we don’t have the rights to share with this-parties; this one is kinda unknown to me, what deals are in place historically and what they should prevent us from doing.”
Gage’s post makes clear that engineers are working on compiling a list of post IDs that should not have been included, and that password-protected posts, DMs, and media flagged as CSAM and other community guidelines violations were not included.
Automattic plans to launch a new setting on Wednesday that will allow users to opt-out of data sharing with third parties, including AI companies, according to the source, who spoke on the condition of anonymity, and internal documents. A new FAQ section we reviewed is titled “What happens when you opt out?” states that “If you opt out from the start, we will block crawlers from accessing your content by adding your site on a disallowed list. If you change your mind later, we also plan to update any partners about people who newly opt-out and ask that their content be removed from past sources and future training.”
404 Media has asked Automattic how it accidentally compiled data that it shouldn’t share, and whether any of that content was shared with OpenAI, but did not immediately hear back from the company. 404 Media asked Automattic about an imminent deal with Midjourney last week but did not hear back then, either.
Another internal document shows that, on February 23, an employee asked in a staff-only thread, “Do we have assurances that if a user opts out of their data being shared with third parties that our existing data partners will be notified of such a change and remove their data?”
Andrew Spittle, Automattic’s head of AI replied: “We will notify existing partners on a regular basis about anyone who's opted out since the last time we provided a list. I want this to be an ongoing process where we regularly advocate for past content to be excluded based on current preferences. We will ask that content be deleted and removed from any future training runs. I believe partners will honor this based on our conversations with them to this point. I don't think they gain much overall by retaining it.” Automattic did not respond to a question from 404 Media about whether it could guarantee that people who opt out will have their data deleted retroactively.
News about a deal between Tumblr and Midjourney has been rumored and speculated about on Tumblr for the last week. Someone claiming to be a former Tumblr employee announced in a Tumblr blog post that the platform was working on a deal with Midjourney, and the rumor made it onto Blind, an app for verified employees of companies to anonymously discuss their jobs. 404 Media has seen the Blind posts, in which what seems like an Automattic employee says, “I'm not sure why some of you are getting worked up or worried about this. It's totally legal, and sharing it publicly is perfectly fine since it's right there in the terms & conditions. So, go ahead and spread the word as much as you can with your friends and tech journalists, it's totally fine.”
Separately, 404 Media viewed a public, now-deleted post by Gage, the product manager, where he said that he was deleting all of his images off of Tumblr, and would be putting them on his personal website. A still-live post says, “i've deleted my photography from tumblr and will be moving it slowly but surely over to cylegage.com, which i'm building into a photography portfolio that i can control end-to-end.” At one point last week, his personal website had a specific note stating that he did not consent to AI scraping of his images. Gage’s original post has been deleted, and his website is now a blank page that just reads “Cyle.” Gage did not respond to a request for comment from 404 Media.
Several online platforms have made similar deals with AI companies recently, including Reddit, which entered into an AI content licensing deal with Google and said in its SEC filing last week that it’s “in the early stages of monetizing [its] user base” by training AI on users’ posts. Last year, Shutterstock signed a six year deal with OpenAI to provide training data.
OpenAI and Midjourney did not respond to requests for comment.
11K notes
·
View notes


Text
hi im complaining about tiktok again and i know this has been said a million times but i despise how the self-censorship that got really popular on there is quickly becoming the norm. why is my podcast that i listen to that is by and for adults and swears regularly censoring the word "sex" in its episode descriptions on spotify, a platform where they dont even censor officially uploaded song titles for songs like "fuck the pain away." why are there book blurbs using "unalive" completely in earnest. why are people on twitter writing s3x. youtubers can at least handwave having to bleep terms like "heroin" bc that's specifically a youtube problem but why in an era where everyone is handwringing about how everything is Literally 1984 do people not seem to care about grown adults gleefully regressing into homestuck typing quirks and ugly babytalk
66K notes
·
View notes
Text
82K notes
·
View notes
Text
remember when you were 10 and you would hang out with your friends in order to Look At The Computer together like you went to their house and experienced the information superhighway together. and then leave
335K notes
·
View notes
Note
Wait are you really pro-ship?
back in my day we just called it minding your own business
16K notes
·
View notes
Text
“ghost files is about ghost hunting!” “ghost files is about evidence!” WRONG. ghost files is about friendship and love persevering no matter what. mostly via carrying ur friends
3K notes
·
View notes
Text
the thing about griffin mcelroy is i genuinely believe he is a genius like on the level of leonardo da vinci or whoever but no one will ever know because his chosen medium is podcasting
6K notes
·
View notes


Photo




INTRODUCING: Food Files! A brand new Watcher show that follows Ryan and Shane on tour as they try local fan-favorite foods submitted by our fans!
Tune in TOMORROW at 12pm PT for the series premiere. New episodes drop every Wednesday.
6K notes
·
View notes
Text

The Magnus Institute Fire
Manchester, England
The Magnus Institute ran educational programs for gifted children and adults. It was founded in Edinburgh in 1818 and relocated to Manchester in 1868. The program was discontinued when the main facility burned down on 24th December 1999. Interestingly, all of the previous hubs for the Institute have either met an ill fate or been abandoned entirely. 🝰
776 notes
·
View notes