
cloudemind
cloudemind.com học luyện thi AWS
23193 posts
Don't wanna be here? Send us removal request.
Last Seen Blogs

valentinebitchbaby
21f, Read Pinned!💞

james300300
JB

w3alid
وليد النسيم

gojicream25
Untitled

angeljulie3
Celebrity Leather Outfits
Text
Hướng dẫn cài đặt AWS CDK Python trên MacOS
Có bài viết học luyện thi AWS mới nhất tại https://cloudemind.com/aws-cdk-installation/ - Cloudemind.com
Hướng dẫn cài đặt AWS CDK Python trên MacOS
AWS CDK commands and steps installation
1. Install aws-cli
2. Get AWS credential
3. Install aws-cdk
4. Install Python
5. Install PIP
6. Install IDE
youtube
Have fun!
Xem thêm: https://cloudemind.com/aws-cdk-installation/
0 notes
Text
Cách tính giá của Amazon RDS Postgres và Aurora Postgres
Có bài viết học luyện thi AWS mới nhất tại https://cloudemind.com/amazon-rds-postgres-vs-aurora-postgres-pricing/ - Cloudemind.com
Cách tính giá của Amazon RDS Postgres và Aurora Postgres

Bài này mình cùng tìm hiểu về cách tính giá của RDS và Aurora postgres, từ đó có lựa chọn phù hợp cho các workload chạy trên Postgres nhé.
youtube
Have fun!
Xem thêm: https://cloudemind.com/amazon-rds-postgres-vs-aurora-postgres-pricing/
0 notes
Text
Sự khác nhau giữa AWS RDS PostgreSQL và Aurora PostgreSQL
Có bài viết học luyện thi AWS mới nhất tại https://cloudemind.com/rds-postgres-vs-aurora-postgres/ - Cloudemind.com
Sự khác nhau giữa AWS RDS PostgreSQL và Aurora PostgreSQL

Bài này chúng ta sẽ cùng tìm hiểu sự khác nhau giữa Amazon RDS Postgresql và Aurora Postgresql. Cả hai loại database engine đều được hỗ trợ bởi Amazon RDS, đều là Fully managed services với nhiều tối ưu chạy trên AWS Cloud.
Chúng ta sẽ cùng hiểu về:
Auto scaling on database
Checkpoint duration
Aurora Global Database
Max storage limitations (64TB vs 128TB)
Supported instance classes for RDS Postgres and Aurora Postgres
youtube
Have fun!
Xem thêm: https://cloudemind.com/rds-postgres-vs-aurora-postgres/
0 notes
Text
Sự khác nhau giữa hiệu suất và năng suất
Có bài viết học luyện thi AWS mới nhất tại https://cloudemind.com/su-khac-nhau-giua-hieu-suat-va-nang-suat/ - Cloudemind.com
Sự khác nhau giữa hiệu suất và năng suất

Hiệu suất và năng suất là hai thuật ngữ chỉ 02 góc nhìn khác nhau giữa đầu vào và đầu ra của một sự việc nào đó.
Với Hiệu suất là cố định biến đầu ra nhưng khác nhau biến đấu vào. Ví dụ: Để bạn chạy 50km đi xe Honda thì mất 1 lít xăng, nhưng Yamaha có thể mất 1.1 lít xăng.
Ngược lại năng xuất là cố định biến đầu vào nhưng đầu ra có thể khác nhau. Ví dụ: 1 lít xăng thì Honda chạy đc 50km, nhưng 1 lít xăng Yamaha chỉ chạy đc 45km chẳng hạn.
Xem thêm: https://cloudemind.com/su-khac-nhau-giua-hieu-suat-va-nang-suat/
0 notes
Text
WORM là gì? S3 Object Lock và Glacier Vault Lock
Có bài viết học luyện thi AWS mới nhất tại https://cloudemind.com/worm/ - Cloudemind.com
WORM là gì? S3 Object Lock và Glacier Vault Lock

WORM là một thuật ngữ khá lạ đối với thậm chí cả những người sử dụng AWS lâu năm. Kỹ thuật này không khó nhưng chắc có lẽ do chưa được tận dụng một cách hiệu quả. Hy vọng qua bài này các bạn có ý tưởng về sử dụng WORM cho các giải pháp hệ thống trên Cloud của mình.
WORM viết tắt của chữ WRITE ONCE READ MANY có nghĩa là cho phép viết một lần và đọc nhiều lần. Ngoài ra còn có thể đính kèm một chính sách gọi là policy trong thời gian bao nhiêu lâu đó sẽ không được thay đổi hay xóa object trong S3, gọi là immutable.
S3 Object Lock cho phép cấu hình WORM để block các action xóa sửa trong thời gian cấu hình.
Glacier Vault Lock cũng tương tự thế nhưng xảy ra ở Amazon S3 Glacier storage class cho phép bạn ứng dụng các vault lock policy không cho phép xóa hay sửa dữ liệu trong thời gian giả sử 10 năm.
Việc sử dụng WORM có ý nghĩa trong việc bảo vệ các dữ liệu có tính compliance tuân thủ các chính sách về lưu trữ bảo mật cao.
Use case phổ biến: Dữ liệu lưu vào Glacier cần được để đó 10 năm, trong thời gian này có thể lấy ra đọc hay phân tích lại, nhưng không thể sửa hay xóa dữ liệu đó.
Nếu các bạn có sử dụng WORM trong giải pháp mời các bạn chia sẻ thêm nhé.
Happy Clouding!
Xem thêm: https://cloudemind.com/worm/
0 notes
Text
Đàn ông giống như CPU, Phụ nữ giống như GPU
Có bài viết học luyện thi AWS mới nhất tại https://cloudemind.com/dan-ong-giong-nhu-cpu-phu-nu-giong-nhu-gpu/ - Cloudemind.com
Đàn ông giống như CPU, Phụ nữ giống như GPU

SỰ KHÁC NHAU VỀ SUY NGHĨ GIỮA 👨🦰 & 👩
💪VỀ SỨC CHỊU ĐỰNG
Phụ nữ có khả năng chịu đau (về mặt thể xác) và sức chịu đựng cao hơn đàn ông, cơ thể của họ cũng nhanh lành vết thương hơn đàn ông, do đó sức bền của phụ nữ cũng cao hơn.
Thực tế là giữa 2 người cùng đi làm như nhau, buổi chiều về thì đàn ông có xu hướng là nghỉ ngơi, relax, còn phụ nữ vẫn có thể nội trợ, bếp núc, chăm con. Đàn ông có thể khỏe mạnh hơn, nhưng phụ nữ lại dẻo dai hơn.
🧠VỀ TƯ DUY
Đàn ông có xu hướng tư duy theo hướng logic, còn phụ nữ lại thiên về cảm xúc, vì vậy mà phụ nữ giỏi hơn đàn ông trong việc nhớ ngày tháng (ngày sinh nhật, kỷ niệm ngày yêu nhau, ngày cưới v.v…), trong khi đàn ông giỏi tính toán và suy luận logic hơn.

internet
Ví dụ khi nhìn nhận vấn đề, đàn ông tiếp cận theo hướng tổng quát (General), còn phụ nữ lại chú trọng tới chi tiết (Detail). Điều này thể hiện qua việc khi tiếp cận người khác giới, đàn ông thường bao quát tới 3 điểm là khuôn mặt, ngực và mông (Body), còn phụ nữ thì để ý tới các chi tiết như màu mắt, màu môi, màu da, giày dép, trang phục, phụ kiện của người đối diện.
Chính vì vậy mà phụ nữ có thể nhớ chính xác lỗi lầm bé xíu xiu của bạn dù cả chục năm trôi qua. Câu nói “Ưu điểm là nhớ lâu và nhược điểm là thù dai” không thể chính xác hơn!
Vì không giỏi logic và bị cảm xúc chi phối, phụ nữ được cho là “không phân biệt được phải trái”. Nếu chạy xe ngoài đường, anh em sẽ có đôi lần thấy chị phía trước bật xi-nhan bên trái nhưng lại quẹo phải hoặc ngược lại, vậy nên khi ngồi sau lưng mà hướng dẫn đường đi cho người khác, họ có xu hướng sử dụng tay phải, tay trái thay cho câu nói quẹo trái, quẹo phải. Bù lại, não của phụ nữ ghi nhớ thông tin lâu và chính xác hơn đàn ông. Dù căn phòng có ngăn nắp hay bừa bộn cỡ nào thì họ vẫn có thể nhớ được món đồ cất ở đâu hệt như Sherlock Holmes vậy.
🕐VỀ KHẢ NĂNG ĐA NHIỆM
Bộ não của đàn ông giống Chip xử lý (CPU), chỉ giỏi xử lý đơn nhiệm, tức là việc nào ra việc đó, giải quyết từng việc một. Nhưng bộ não của phụ nữ lại giống như Card đồ họa (GPU), có thể xử lý đa nhiệm nhiều việc cùng lúc. Phụ nữ văn phòng vừa có thể gõ máy tính, vừa nghe điện thoại và ghi chú lại những điều cần thiết một cách chính xác, thậm chí là biết luôn đồng nghiệp đang bàn nhau trưa nay ăn gì :))
Ngược lại, não đàn ông thường tập trung để xử lý từng việc một. Nếu người đàn ông đang cạo râu mà bà vợ cứ hỏi dồn dập bên cạnh thì khả năng anh ta bị phân tâm và làm rách mặt là rất cao. Nhưng nhờ tính đơn nhiệm này mà đàn ông có khả năng tập trung cao độ tốt hơn, trong khi đó phụ nữ dễ bị môi trường xung quanh xao nhãng họ hơn.
Sưu tầm
Xem thêm: https://cloudemind.com/dan-ong-giong-nhu-cpu-phu-nu-giong-nhu-gpu/
0 notes
Text
AWS CLI -
Tạo Amazon EC2 Instance với AWS CLI - Tùy chọn Dry Run là gì?
Có bài viết học luyện thi AWS mới nhất tại https://cloudemind.com/dry-run/ - Cloudemind.com
AWS CLI - Tạo Amazon EC2 Instance với AWS CLI - Tùy chọn Dry Run là gì?
Bình thường các bạn có thể dễ dàng tạo một máy chủ Amazon EC2 thông qua AWS Console. Cách này đơn giản và dễ dàng nhưng thường ở quy mô lớn cần tạo số lượng lớn hay có tính lặp lại các bạn cần tạo các kịch bản hay viết code để tạo nhanh chóng. AWS hỗ trợ 02 phương thức cho nhu cầu này thông qua AWS CLI hoặc AWS SDK.
AWS CLI giúp các bạn thao tác với dịch vụ AWS thông qua chính terminal từ máy tính của các bạn hoặc từ một máy chủ EC2 trên AWS Cloud. Cách này thông thường các bạn làm về Ops sẽ rất thân quen.
AWS SDK ở một hướng khác nhưng cũng cùng mục đích, AWS SDK hỗ trợ các bạn developer thao tác với AWS Services thông qua code của mình. Một số ngôn ngữ phổ biến có thể hỗ trợ là Python, Javascript, C#, Java, Ruby, Go, PHP…
Bài này mình sẽ hướng dẫn các bạn sử dụng aws cli để tạo một ec2 instance đơn giản trong chuỗi về AWS CLI.
2 câu lệnh hữu dụng:
aws ec2 describe-instances – liệt kê tất cả EC2 instances có trong Region đã configure từ trước.
aws ec2 run-instances – tạo một máy chủ ec2
Sau đây là câu lệnh khởi tạo một máy chủ EC2 từ AWS CLI
aws ec2 run-instances --image-id xxx --instance-type t2.micro --subnet-id yyy --security-group-ids zzz
Trong đó:
xxx là AMI Image ID
yyy là là Subnet ID trong VPC
zzz là security group ID
aws cli ec2 command
Do Kevin đang cấu hình output là dạng YAML nên bạn sẽ thấy kết quả trả ra là thông tin một máy chủ EC2 mới với Instance-ID là i-039eb1fb0c0bfcfcd. Giá trị này sinh ra ngẫu nhiên bởi AWS.
Cùng kiểm tra trên AWS Console nào. Các bạn nhìn ở dòng thứ 3 nhé.
aws ec2 console new ec2 instance
Ok, thế là mình đã tạo một máy chủ EC2 đơn giản bằng cách sử dụng aws cli rồi. Có rất nhiều option khác bạn có thể linh hoạt điều chỉnh nữa nhé.
Vậy option dry-run khi chạy lệnh AWS CLI có ý nghĩa gì.
Với tùy chọn thêm tham số –dry-run vào cuối câu lệnh bạn có thể mô phỏng chạy giả lập xem có thành công hay không, chứ ko thực tế tạo ra máy chủ EC2 trong trường hợp này.
aws ec2 run-instances --image-id xxx --instance-type t2.micro --subnet-id yyy --security-group-ids zzz --dry-run
dry run option aws cli command
Hy vọng qua bài này các bạn có thêm chút vui vẻ sử dụng AWS CLI để tạo một máy chủ ec2. Hẹn gặp lại các bạn ở các bài tiếp theo.
Happy Clouding!
Xem thêm: https://cloudemind.com/dry-run/
0 notes
Text
Sự khác nhau giữa CNAME và Alias trong Amazon Route 53
Có bài viết học luyện thi AWS mới nhất tại https://cloudemind.com/cname-vs-alias/ - Cloudemind.com
Sự khác nhau giữa CNAME và Alias trong Amazon Route 53

Khi bạn cấu hình các record trong Hosted Zone của Route 53, bạn có thể sẽ khó hiểu sự khác nhau giữa CNAME và Alias. Bài này giúp bạn vượt qua sự khó hiểu này vì thực sự nó cũng rất dễ thôi.
Trước khi hiểu rõ CNAME và Alias trong hosted zone bạn cần hiểu về khái niệm liên quan đó là các AWS Resources sẽ tạo các đường dẫn URL ví dụ như Load Balancer ELB hay CloudFront. Và thường chúng ta cấu hình Route 53 nói chung hay trong hosted zone nói riêng sẽ thường gặp tình huống này.
Ví dụ về ELB có thể như sau:
DemoALB-813736945.us-east-1.elb.amazonaws.com
Để cấu hình Hosted Zone bạn lưu ý cần trỏ DNS Name của domain bạn quản lý về các mẩu record NS của AWS nhé.
CNAME
Sử dụng để trỏ hostname sang một hostname bất kỳ khác. Ví dụ bạn có domain là cloudemind.com thì CNAME có thể trỏ demo.cloudemind.com sang một hostname khác chẳng hạn demo.anydomain.com
CNAME chỉ hoạt động với Non-root domain. Hay nói cách khác bạn cần tạo sub-domain để cấu hình.
Bạn có thể phát sinh phí khi sử dụng CNAME.
Alias
Alias nhìn thì có vẻ khá giống với CNAME, nhưng Alias để trỏ hostname đến một AWS Resources ví dụ như bên trên có thể là ELB hay CloudFront DNS name.
Alias có thể hoạt động với cả Root domain và non-root domain.
Alias là miễn phí nên Kevin khuyến nghị sử dụng cấu hình nhé.
Ngoài ra Alias có thể hỗ trợ native health check để xem các entity nằm sau có khỏe mạnh hay sẵn sàng hay không.
AWS Exam question
CNAME và Alias cũng là một topic thường xuyên được hỏi trong kỳ thi AWS Certified Associate. Đề thi có thể hỏi các bạn cấu hình cho root domain thì cần phải nhớ đó là sử dụng Alias, còn non-root domain có thể sử dụng cả hai CNAME và Alias.
Happy Clouding!
Kevin
Xem thêm: https://cloudemind.com/cname-vs-alias/
0 notes
Text
Tìm hiểu về Amazon EC2 User Data
Có bài viết học luyện thi AWS mới nhất tại https://cloudemind.com/user-data/ - Cloudemind.com
Tìm hiểu về Amazon EC2 User Data
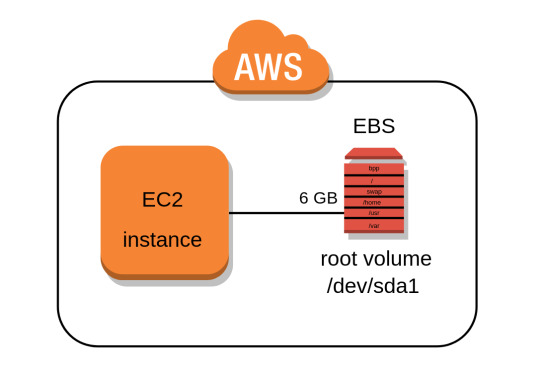
User Data là một kỹ thuật rất hay mà có thể bạn bỏ qua khi sử dụng EC2 Service. User Data giúp bạn tự động cài đặt một số gói (package) trước khi booting máy chủ EC2, quá trình này gọi là bootstrapping.
Quá trình bootstrapping thực tế là yêu cầu Amazon EC2 instance chạy một số lệnh (command) trong khi khởi động với quyền cao nhất là root (sudo su).
Script định nghĩa trong User Data sẽ được chạy một lần duy nhất vào lần khởi động đầu tiên (đảm bảo không bị chạy đi chạy lại nhiều lần). Trong đề thi AWS đây cũng là một topic rất thường xuyên đánh đố hỏi về User Data chạy một lần hay mỗi lần khởi động.
Lưu ý: Script trong User Data chỉ chạy 1 lần vào first start.
Một số công việc mà User Data có thể giúp chúng ta làm như sau:
Installing updates
Installing software
Downloading common files from Internet
Mặc định, những câu lệnh trong User Data sẽ được chạy với đặc quyền cao nhất là root.
Ví dụ về User Data:
#!/bin/bash # install httpd yum update -y yum install -y httpd.x86_64 systemctl start httpd.service systemctl enable httpd.service echo "<h1>Hello AWS from $(hostname -f)</h1>" > /var/www/html/index.html
EC2 User Data là một kỹ thuật quan trọng gặp rất nhiều trong đề thi AWS cũng như thực tiễn làm việc liên quan các workload ảo hóa trên AWS. Hy vọng qua bài này các bạn có thể hiểu được User Data và cách sử dụng.
Tăng thêm một chút khó ta cũng có thể sử dụng User Data script để lấy các thông số liên quan Metadata của EC2.
Code: $(curl -s http://169.254.169.254/latest/meta-data/placement/availability-zone/)
Ghép đoạn trên với User Data ta có được hoàn chỉnh 1 script như sau:
#!/bin/bash # install httpd yum update -y yum install -y httpd.x86_64 systemctl start httpd.service systemctl enable httpd.service EC2_AZ=$(curl -s http://169.254.169.254/latest/meta-data/placement/availability-zone/) echo "<h1>Hello AWS from $(hostname -f) in AZ: $EC2_AZ</h1>" > /var/www/html/index.html
Happy Clouding!
Xem thêm: https://cloudemind.com/user-data/
0 notes
Text
Lịch sử hình thành của kỷ nguyên AWS (Amazon Web Services) - Andy Jassy
Có bài viết học luyện thi AWS mới nhất tại https://cloudemind.com/aws-history/ - Cloudemind.com
Lịch sử hình thành của kỷ nguyên AWS (Amazon Web Services) - Andy Jassy
Ngày nay AWS là cloud provider dẫn đầu thị trường trong việc cung cấp các dịch vụ đám mây với tổng số lượng sản phẩm dịch vụ hơn 175. Để được thành tựu 10 năm liên tiếp được Gartner đánh giá là leader trong thị trường cloud (tiếp theo là Azure và GCP) đòi hỏi một nỗ lực xây dựng không ngừng nghỉ. Nhưng ta hãy xem về ngày ban đầu lịch sử hình thành của AWS như thế nào qua bài này nhé.
Có lần Kevin được thăm văn phòng làm việc AWS ở Singapore, trong khu pantry có một dòng chữ rất to trên tường ghi là “There’s more to build, more to invent. We are still at DAY 1“. Thực sự mình rất ấn tượng và yêu thích AWS từ câu nói này, rất khiêm tốn và ko ngừng vượt trội chính mình.
AWS DAY 1
Thực vậy, theo số liệu của Synergy Research, trong một thập kỷ từ khi AWS thành lập AWS đã phát triển trở thành công ty về hạ tầng cloud thành công nhất hành tinh chiếm hơn 30% thị phần thị trường với khoảng 130 tỉ đô la Mỹ.
Nguồn gốc của ý tưởng thành lập AWS (Amazon Web Services) muốn tìm hiểu ta cần trở về thời gian vào những năm 2000 khi mà Amazon.com là một cty chuyên về thương mại điện tử bán sách đĩa. Đằng sau trang thương mại điện tử này cũng là một hệ thống công nghệ thông tin như là máy chủ, cơ sở dữ liệu, lưu trữ, cân tải, tường lửa… và Amazon.com ngày càng trở nên phổ biến khiến lượng truy cập ngày càng nhiều và kể từ đây Amazon.com gặp rất nhiều bài toán liên quan đến scaling (mở rộng) ứng dụng khi có nhiều user truy cập hơn. Và việc này giống như các doanh nghiệp truyền thống khác là scaling không hề dễ dàng và chậm chạp, mất hàng tháng trời để có phần cứng rồi tiến hành cài đặt, cấu hình…. blah blah.
Chính những vấn đề này khiến Amazon phải xây dựng một hệ thống công nghệ thông tin nội bộ đủ thông minh và linh hoạt (Agility) đối phó với các tình huống tăng tưởng ứng dụng. Và đây chính là nền tảng tạo ra AWS.
AWS CEO Andy Jassy là người bắt đầu xây dựng từ thời kỳ đầu tiên (F0 ^^), theo như ông chia sẻ thì hệ thống lõi của AWS khi xây dựng cần tới 03 năm kể từ năm 2000.
Nào, ta cùng đi sâu vào ý tưởng xây dựng một hệ thống nội bộ như đề cập bên trên để đáp ứng với việc grown chóng mặt của Amazon.com
Vào năm 2000, Amazon muốn launch một dịch vụ thương mại điện tử có tên là Merchant.com để giúp các third-party xây dựng site bán hàng tích hợp với Amazon.com như Target, Marks & Spencer. Và việc này trở nên khó khăn khi thực hiện do team cũng chưa có hoạch định chính xác như rất nhiều startup khác. Lúc này ý tưởng xây dựng các core services với hướng dịch vụ API bắt đầu.
Vào năm 2003 lúc này về mặt thời gian vẫn là 3 năm trước khi thành lập AWS. Đội ngũ của Andy Jassy suy nghĩ về việc launch các dịch vụ nào trước, các dịch vụ cốt lõi và lúc này thành lập cụm từ “the operating system of Internet”. Vào timeframe này có 02 nhân vật rất nổi tiếng đóng vai trò then chốt tạo nên AWS ngày hôm nay là Benjamin Black và Chris Pinkham.
Benjamin Black đóng vai trò là một website engineering manager, ông này có viết một bài về việc tái cấu trúc hạ tầng của Amazon.com theo hướng selling virtual servers as a service.
Ông Benjamin Black viết bài đề xuất với sếp của mình là Chris Pinkham (VP of IT Infra).
Sau khi Benjamin Black và Chris Pinkham viết xong bài đề xuất do Jeff Bezos không sử dụng slide và được ông Bezos thích thú. Khi thực hiện ý tưởng này chính Bezos cũng phải bảo vệ ý tưởng với hội đồng do lúc này Amazon.com vẫn đang là một công ty bán lẻ trực tiếp, liệu rằng việc xây dựng AWS có đúng hay không. Cuối cùng Bezos cũng thực hiện được. Bezos lắng nghe từ nhân viên của mình và nhận ra ý tưởng thông minh từ một nhân viên của mình.
Vào năm 2014 Jeff Bezos approve (phê duyệt) về ý tưởng thực hiện Amazon Infrastructure.
Vào tháng 11/2004 AWS blog được công bố đầu tiên với tập hợp các API và công cụ truy xuất Amazon.com catalog chứ chưa hẳn là một Infrastructure As A Service.
Vào năm 2005, AWS launch privately với một số lượng nhỏ khách hàng. Vào thời điểm này Amazon cũng hoạch định cho việc công bố public launch AWS với một số dịch vụ lõi trước như compute, database, storage.
2006 – A hero is born
19 Mar 2006 – AWS launched Amazon S3
13 Jul 2006 – AWS launched Amazon SQS
25 Aug 2006 – AWS launched Amazon EC2 available for existing AWS customers
22 Aug 2007 – Amazon EC2 public for anybody to use, launched new instance types.
13 Dec 2007 – Amazon SimpleDB is launched. It used a hosted Hadoop framework running on web-scale infrastructure of EC2 and S3
20 Aug 2008 – Launched EBS
18 Nov 2008 – CloudFront
Apr 2009 – Amazon EMR
18 May 2009 – ELB
25 Aug 2009 – VPC
22 Oct 2009 – RDS, start to support MySQL
13 Dec 2009 – announce EC2 Spot instances
Ref:
https://techcrunch.com/2016/07/02/andy-jassys-brief-history-of-the-genesis-of-aws/
https://en.wikipedia.org/wiki/Timeline_of_Amazon_Web_Services
https://aws.amazon.com/about-aws/whats-new/2006/08/24/announcing-amazon-elastic-compute-cloud-amazon-ec2—beta/
https://www.businessinsider.com/benjamin-black-and-amazon-web-services-2014-7
Xem thêm: https://cloudemind.com/aws-history/
0 notes
Text
So sánh AWS Kinesis Data Stream và Kinesis Data Fire Horse
Có bài viết học luyện thi AWS mới nhất tại https://cloudemind.com/kinesis-data-stream-vs-fire-horse/ - Cloudemind.com
So sánh AWS Kinesis Data Stream và Kinesis Data Fire Horse
AWS Kinesis là một dịch vụ rất phổ biến sử dụng trong các kiến trúc về data trên cloud làm nhiệm vụ đưa dữ liệu từ nhiều nguồn đến với AWS Cloud và từ đó có nhiều câu chuyện tiếp theo như Data Platform, Data Lake, Datawarehouse, big data, Data Analytics…
AWS Kinesis cũng là một chủ đề được hỏi rất nhiều trong kỳ thi lấy chứng chỉ AWS không chỉ Solution Architect mà còn ở cả Developer Associate. Do đó bạn cần nắm chắc dịch vụ này không sẽ bị đề thi xoay cho không biết hỏi gì và câu trả lời nào cũng thấy hợp lý.
AWS Kinesis được ví như máng truyền dẫn dữ liệu từ Data Producer và Data Consumer.
Data Producer là những nguồn dữ liệu bất kỳ từ website, từ mạng xã hội, từ mobile app, từ các IoT devices…
Data Consumer là nơi tiêu thụ hay chứa dữ liệu này ví dụ như Apache Hadoop, Apache Storm, Redshift, S3, ElasticSearch…
AWS Kinesis Data Streams – cho phép lập trình viên có thể tùy chỉnh luồng dữ liệu cho những mục đích đặc thù. Kinesis Data Stream là dịch vụ thuộc nhóm unmanaged có nghĩa bạn phải chịu trách nhiệm về việc provision, scaling. Data có thể hiện hữu mặc định 24 giờ, bạn có thể trả thêm phí để kéo dài tới 7 ngày.
AWS Kinesis Data Fire Horse – cho phép load dữ liệu thẳng vào các AWS Services để thực hiện xử lý. Fire horse là dịch vụ thuộc nhóm managed service, có nghĩa là bạn không cần lo lắng về scaling, hay provisioning giải pháp. Fire horse cho phép bạn batching, encrypting, compressing. Firehorse cho phép streaming dữ liệu vào thẳng S3, Redshift, ElasticSearch.
Xem thêm: https://cloudemind.com/kinesis-data-stream-vs-fire-horse/
0 notes
Text
7 CÂU CHUYỆN ĐỂ TA SUY NGẪM
Có bài viết học luyện thi AWS mới nhất tại https://cloudemind.com/7-chuyen-suy-ngam/ - Cloudemind.com
7 CÂU CHUYỆN ĐỂ TA SUY NGẪM

1) CÂU CHUYỆN THỨ NHẤT
Một hôm nọ, thư ký nói với giám đốc:
– Anh à, em có bầu rồi.
Giám đốc vẫn làm việc, cười mỉm rồi nhẹ nhàng nói:
– Anh triệt sản lâu rồi.
Nữ thư ký ngây ra một lúc gượng cười nói:
– Em chỉ nói đùa với anh thôi mà.
Giám đốc nhìn cô một lúc, uống ngụm trà rồi nói:
– Anh cũng thế.
Suy ngẫm:
Sống trong giang hồ, dù gặp việc gì cũng chớ hoang mang, cứ bình tĩnh rồi đâu sẽ có đó.
2) CÂU CHUYỆN THỨ HAI
Ba chàng trai đến nhà cô gái hỏi cưới. Phụ huynh mời tự giới thiệu.
A nói:
– Nhà cháu có vài tỷ đồng.
B nói:
– Nhà cháu có một loạt bất động sản, trị giá vài chục tỷ.
C nói:
– Cháu không có gì cả, ngoài đứa con trong bụng con gái bác.
A, B không nói gì cả, chuồn đi.
Suy ngẫm:
Khi cạnh tranh, chưa hẳn có tiền mới giải quyết được, phải tìm ra điểm mấu chốt dẫn tới việc ra quyết định.
3) CÂU CHUYỆN THỨ BA
Bảy năm trước anh ta bỏ rơi vị hôn thê để đi nước ngoài, giờ đã có thành tựu, nhớ về người xưa, lại được biết cô sống rất vất vả, nên tìm cách đến thăm xem sao.
Anh thấy cô đang cạo vảy cá, bên cạnh là một bé trai rất giống anh, đột nhiên trong lòng rất bối rối.
Cô tự dưng ngẩng đầu nói với qua người đàn ông ngồi dãy hàng đối diện:
– Ông còn không mau mà đi về nấu cơm cho con?
Anh thở dài một hơi, lặng lẽ bỏ đi.
Cô vội vã hướng sang bên người đàn ông phía đối diện nói:
– Chuyện vừa nãy cho tôi xin lỗi nhé.
Suy ngẫm:
Nếu biết mối quan hệ này đã không thể nào quay trở lại, thì thà dứt khoát để khỏi khó lòng áy náy cho nhau.
4) CÂU CHUYỆN THỨ TƯ
Bố đang sửa xe, con trai cầm mảng đá vẽ lên vỏ xe. Bố nhìn thấy, giận quá, văng cái kìm sắt đánh vào tay con. Con phải nhập viện, gãy xương ngón tay. Con nhẹ nhàng nói với bố:
– Bố ơi, sẽ nhanh khỏi thôi, bố đừng lo nhé.
Bố cảm thấy vô cùng ân hận, đùng đùng chạy về nhà định đập nát xe ô tô của mình. Đập vào mắt bố là dòng chữ mà lúc nãy con đang viết dở: Bố ơi, con yêu bố!
Suy ngẫm:
Có rất nhiều việc nếu ta nghĩ kỹ hơn một chút rồi mới quyết định thì sẽ tốt hơn nhiều.
5) CÂU CHUYỆN THỨ NĂM
Trên thảo nguyên có hai mẹ con nhà sư tử. Sư tử con hỏi mẹ:
– Mẹ ơi, hạnh phúc ở đâu?
Mẹ bảo:
– Hạnh phúc ở đuôi con đấy.
Sư tử con ngây ngô cứ gắng sức đuổi theo đuôi mình, mà mãi không thể bắt được.
Sư tử mẹ nhìn con cười hiền hậu nói:
– Ngốc ạ, không cần phải đuổi theo hạnh phúc. Chỉ cần con ngẩng cao đầu hướng về phía trước, thì hạnh phúc sẽ mãi mãi đuổi theo con.
Suy ngẫm:
Nhiều khi ta không phải cố gắng đuổi theo thứ gì đó, cứ an nhiên tự tại với những gì mình có, hạnh phúc tự nhiên sẽ đuổi theo sau.
6) CÂU CHUYỆN THỨ SÁU
Cô gái mù không có gì cả, trên đời này chỉ còn có mỗi người yêu ở bên cạnh. Anh hỏi cô:
– Nếu mắt em khỏi rồi, em có lấy anh không?
Cô gái gật đầu đồng ý.
Rất nhanh sau đó, cô được hiến giác mạc, có thể nhìn thấy bình thường, mới phát hiện người yêu cô cũng bị mù.
Khi chàng trai cầu hôn, cô đã từ chối.
Suy ngẫm:
Đôi khi những khuyết điểm của người bên cạnh (như khiếm khuyết của cha mẹ, vợ chồng, con cái…) là do họ đã âm thầm hy sinh cho ta. Đừng bao giờ phản bội người đã sẵn sàng hy sinh cho bạn.
7) CÂU CHUYỆN THỨ BẢY
Con không nuôi được mẹ già, định cõng mẹ lên núi để mẹ lại đó. Buổi chiều tối, con nói với mẹ sẽ đưa mẹ lên núi dạo chơi. Mẹ phấn khởi trèo lên lưng con. Cả đường con chỉ nghĩ đến việc sẽ trèo lên thật cao rồi bỏ mẹ ở đó. Đến khi phát hiện ra mẹ đang âm thầm rắc hạt đậu xuống đường, con đã rất tức giận quát:
– Mẹ rắc hạt đậu làm gì hả?
Cuối cùng, mẹ đã trả lời một câu khiến đứa con khóc đẫm nước mắt:
– Con ngốc của mẹ, mẹ sợ tý nữa con đi về một mình sẽ bị lạc đường…
—–
Trên đời này có một người, dù bạn có cau có, nói lời khó nghe với họ, mắng chửi quát tháo họ mỗi khi bực bội, thậm chí bị bạn hất hủi bỏ rơi… người đó vẫn luôn yêu thương lo lắng cho bạn mà không cần điều kiện…
Thế nên, khi Người còn bên cạnh, xin đừng nói lời cay đắng.
Bởi sau này khi Người đó không còn, bạn chẳng thể nào tìm ra được người thứ hai trên đời như thế!
Xem thêm: https://cloudemind.com/7-chuyen-suy-ngam/
0 notes
Text
Amazon Elastic File System (EFS) Brain dump
Có bài viết học luyện thi AWS mới nhất tại https://cloudemind.com/efs/ - Cloudemind.com
Amazon Elastic File System (EFS) Brain dump

Amazon EFS
Scalable, elastic, cloud-native NFS file system
Provide simple, scalable, fully managed NFS file system for use with AWS Services and on-premises resources.
Build to scale on-demand to petabytes without interrupting applications. Eliminate to manage provision the storage, it is automatically scale your storage as needed.
EFS has 2 types: EFS standard and EFS Infrequent Access (IA).
EFS has lifecycle management (like S3 lifecycle manage) to help move files into EFS IA automatically.
EFS IA is cheaper file system.
Shared access to thousands of Amazon EC2 instances, enabling high level of aggregate throughput and IOPS with consistent low latencies.
Common use cases: Big data analytics, web serving and content management, application development & testing, database backups, containers storage…
EFS is Regional service storing data within and cross Available Zone for high availability and durability.
Amazon EC2 instances can access cross Available Zone, On-premises resources can access EFS via AWS DX and AWS VPN.
EFS can support over 10GB/s, more than 500,000 IOPS.
Using EFS Lifecycle management can reduce cost up to 92%.
Amazon EFS is compatible with all Linux-based AMIs for Amazon EC2.
You do not need to manage storage procurement and provisioning. EFS will grow and shrink automatically as you add or remove files.
AWS DataSync provides fast and secure way to sync existing file system to Amazon EFS, even from on-premise over any network connection, including AWS Direct Connect or AWS VPN.
Moving files to EFS IA by enabling Lifecycle management and choose age-off policy.
Files smaller than 128KB will remain on EFS standard storage, will not move to EFS IA even it is enabled.
Speed: EFS Standard storage is single-digit latencies, EFS IA storage is double-digit latencies.
Throughput:
50MB/s baseline performance per TB of storage.
100MB/s burst for 1TB
More than 1TB stored, storage can burst 100MB/s per TB.
Can have Amazon EFS Provisioned Throughput to provide higher throughput.
EFS’s objects are redundantly across Available Zone.
You can use AWS Backup to incremental backup your EFS.
Access to EFS:
Amazon EC2 instances inside VPC: access directly
Amazon EC2 Classic instance: via ClassicLink
Amazon EC2 instances in other VPCs: using VPC Peering Connection or VPC Transit Gateway.
EFS can store petabytes of storage. With EFS, you dont need to provision in advance, EFS will automatically grow and shrink as files added or removed from the storage.
Mount EFS via NFS v4
Access Points
EFS Access points to simplify application access to shared datasets on EFS. EFS Access points can work with AWS IAM to enforce an user or group, and a directory for every file system request made through the access point.
You can create multiple access points and provide to some specific applications.
Encryption
EFS support encryption in transit and at rest.
You can configure the encryption at rest when creating EFS via console, api or CLI.
Encrypting your data is minimal effect on I/O latency and throughput.
EFS and On-premise access
To access EFS from on-premise, you have to have AWS DX or AWS VPN.
Standard tools like GNU to allow you copy data from on-premise parallel. It can help faster copy. https://www.gnu.org/software/parallel/
Amazon FSx Windows workload
Window file server for Windows based application such as: CRM, ERP, .NET…
Backed by Native Windows file system.
Build on SSD storage.
Can access by thousands of Amazon EC2 at the same time, also provide connectivity to on-premise data center via AWS VPN or AWS DX.
Support multiple access from VPC, Available Zone, regions using VPC Peering and AWS Transit gateway.
High level throughput & sub-millisecond latency.
Amazon FSx for Windows File Server support: SMB, Windows NFS, Active Directory (AD) Integration, Distributed File System (DFS)
Amazon FSx also can mount to Amazon EC2 Linux based instances.
Amazon FSx for Lustre
Fully managed file system that is optimized for HPC (high performance computing), machine learning, and media processing workloads.
Hundreds of GB per second of throughput at sub-millisecond latencies.
Can be integrated with Amazon S3, so you can join long-term datasets with a high performance system. Data can be automatically copied to and from Amazon S3 to Amazon FSx for Lustre.
Amazon FSx for Lustra is POSIX-compliant, you can use your current Linux-based applications without having to make any changes.
Support read-after-write consistency and support File locking.
Amazon Lustre can also be mounted to an Amazon EC2 instance.
Connect to onpremise via AWS DX, or AWS VPN.
Data Transfer
EFS Data transfers between Region using AWS DataSync
EFS Data transfer within Region using AWS Transfer Family endpoint
Limitations
EFS per Regions: 1,000
Pricing
Pay for storage
Pay for read and write to files (EFS IA)
Xem thêm: https://cloudemind.com/efs/
0 notes
Text
Ghi chú Amazon S3 Glacier Cheat Sheet
Có bài viết học luyện thi AWS mới nhất tại https://cloudemind.com/glacier/ - Cloudemind.com
Ghi chú Amazon S3 Glacier Cheat Sheet

Amazon S3 Glacier
Long term data storage and very low cost storage. Using for archive and backup purposes.
Retrieving data options:
Expedited: 1-5 minutes
Standard: 3-5 hours
Bulk: 5-12 hours.
Durability: 11’s 9.
Availability: need to retrieve first, cannot access directly to object.
Support encryption SSL/TLS in transit, and at rest.
Vault lock is a feature to enforce compliance via lockable policy
Base unit of S3 Glacier storage is archive. An archive is a file such as photo, video, document. Archive will be stored in a Vault.
When you upload an archive, Amazon S3 Glacier will return an Archive ID, Archive ID is unique in a Region in which the archive is restored.
AWS Management console to create and delete Vaults. Other interactions requires by using code or CLI.
Amazon S3 Glacier supports multipart upload. You will be charged in-progress multipart upload at S3 Glacier Staging Storage until upload completed. When completed, 90 days early-delete windows starts.
You should compress your files into a zipped files to lower your storage cost before uploading to Amazon S3 Glacier. Common file format is ZIP, TAR. Base unit of Amazon S3 Glacier is archives. Individual archive has range of size from 1 byte to 40TB.
Largest single upload request is 4GB. For items larger than 100MB, you should you multipart upload.
Archives ar stored in Amazon S3 Glacier is immutable. i.e: archives can be upload, deleted; but cannot edit or overwrite.
Vaults is group of archives. You can manage access to vaults by using AWS IAM.
Vault Lock
Vault lock allows to easily deploy and enforce compliances to your vault via lockable policy (Vault lock policy).
Vault lock policy and vault access policy govern to your vault. However, Vault Lock policy can be made immutable and provide strong enforcements for your compliance controls. In conjunction, you can use the vault access policy to implement access controls that are not compliance related, temporary, and subject to frequent modification
Type of compliance controls with Vault Lock:
Deploy Vault Lock policy by using AWS IAM.
WORM (Write one read many)
Time-based records retention for regulatory archives.
Limitations
Archive size: 1 byte to 40TB
Max vaults: 1,000 vaults per account per region
S3 Glacier has a minimum 90 days of storage. Less than 90 days incur pro-rated charge equal to the storage charge for the remaining days.
One vault access policy per vault.
Pricing
There is no setup fee for using service
Retrieval pricing (depends on expedited, standard or bulk)
Retrieval requests pricing
Provisioned expedited retrieval (100$ per unit)
Upload requests pricing
Data transfer OUT
References
S3 Glacier Pricing
S3 Glacier FAQ
Xem thêm: https://cloudemind.com/glacier/
0 notes
Text
Ghi chú về AWS Snowmobile Cheat Sheet
Có bài viết học luyện thi AWS mới nhất tại https://cloudemind.com/snowmobile/ - Cloudemind.com
Ghi chú về AWS Snowmobile Cheat Sheet
AWS Snowmobile
Help to transfer exabyte-scale data to AWS. Larger capacity than Snowball.
Is a secured data truck with up to 100PB storage capacity. You can scale exabyte-scale data with 10 snowmobile parallel from single location or multiple data centers.
Physical specification: 100PB storage, 45 foot long high cube container, 68K pounds.
Resistant capability: water-resistant, tamper-resistant, temperature controlled, GPS-tracked.
For larger than 10PB data sets, you should use Snowmobile. And smaller 10PB data sets, you should use Snowball Edge.
Snowmobile requires a site requirements such as power (~350KW), network connectivity)
You can connect snowmobile via NFS endpoint
Snowmobile is designed to copy at 1Tbps. Less than 10 days to copy 100PB of data.
How AWS Snowmobile work?
You place inquiry on AWS Console
AWS personel will contact you to clarify the requirements and schedule a job
AWS drives the truck to your site.
AWS connects the snowmobile to your site
Data transfer to snowmobile is completed
Snowmobile will back to designed AWS region
Upload to AWS storage service such as S3 or Glacier.
AWS will work with you to validate the uploaded data.
Pricing
Snowmobile job cost $0.005/GB/month based on amount of storage provisioned capacity.
Xem thêm: https://cloudemind.com/snowmobile/
0 notes
Text
Toàn bộ AWS Snowball Cheat Sheet 2021 Updated
Có bài viết học luyện thi AWS mới nhất tại https://cloudemind.com/snowball/ - Cloudemind.com
Toàn bộ AWS Snowball Cheat Sheet 2021 Updated
AWS SnowBall
Help to transfer data to AWS by using a physical device. Common use case to copy TB to PB of data to AWS.
Snowball has computing and storage capability.
How Snowball Edge (SBE) work:
You start to request one or more snowball edge on AWS Management Console
AWS buckets, data, Amazon EC2 AMIs, Lambda functions to be configured before shipping to you
You receive the devices and setup manual IP or DHCP.
Unlock the device by using codes and Snowball client software. Codes and manifest is uniqued, you cannot use for other device.
Data copied to buckets is encrypted automatically.
All logistic and shipping is done by AWS
You can see the tracking information of the device via messages by Amazon SNS.
AWS Snowball is an AWS Service. Snowball Edge is a device. Originally, AWS Snowball is hardware but now AWS added compute capability to help SnowBall Edge can proceed some calculation at site without networking or connections.
SnowBall Edge types:
SnowBall Edge Compute Optimized: powerful compute, high speed storage for data processing before transferring to AWS. Typical workloads: machine learning, video processing, real-time processing.
52 vCPU, 208 GB RAM, 7.68TB of NVMe SSD, 42TB of HDD, 100 Gbps, nVidia V100.
SnowBall Edge Storage Optimized: General purpose analytics such as IoT data aggregation and transformation.
40 vCPU, 32 GB RAM, 80TB of HDD, 1TB of SATA SSD, 40 Gbps
You CANNOT use SnowBall Edge to migrate data from AWS Region to another AWS Region. In this case, you should consider to use S3 Cross-Region-Replication.
Transfer time estimation: around one week to transfer 80TB of data, including shipping and handling time at site.
SnowBall Edge must return in 360 days. You cannot borrow a device forever ^^
SnowBall Edge supports Clustering to create larger durable storage pool with single S3-compatible end point. Eg: 6 Storage optimized can be clustered to a single durable storage of 400TB. Or standalone performance of a storage optimized is 80TB.
You cannot use mixing of storage optimized and compute optimized for durable cluster.
You cannot use existing EBS for Snowball Edge.
Amazon EC2 on SnowBall Edge supports variety of free OS such as Ubuntu, CentOS. They can be pre-configured load to SBE without any modification. To run other OS, you need to provide licenses.
You can run multiple EC2 instances on the SBE as long as under device capacity.
SBE encrypts data at rest by using AWS KMS.
Using VM Import/Export tool to load AMI into SBE
AWS OpsHub is a member of Snow family that provides graphic user interface to manage SBE easily with no extra cost.
AWS OpsHub runs on a local machine such as your laptop to manage SBE devices.
OpsHub encrypted data while transferring to SBE. All data written to AWS Snow family is encrypted by default.
snowball edge
SBE Block Storage
You can add block storages to SBE
SBE block storage is different with Amazon EBS (only a subset of Amazon EBS).
Data on on the SBE block storage will be deleted when arrived to AWS. If you want to save the data, you should copy it to S3-compatible storage (this data will be copied to AWS S3 bucket when arrived to AWS).
You add SBE block storage after you received device from AWS.
SBE cannot be shipped to another Region. AWS shipped and used in single Region, you cannot use it or ship it to another Region.
Pricing
Data transfer In to AWS or S3 is free.
You will be charged for S3 storage
SBE service fee by use (total days of using). Also depends on type of SBE (compute or storage optimized or compute optimized with GPU)
SBE can support discount up to 62% if you have commitment of using 1 or 3 years. For this type, you have to contact sales team.
Service fee per job (10 days of onsite usage as default)
Shipping fee and service charge
You cannot buy SBE device.
Limitations
10 Block storage volumes per EC2 instance
Max block storage volume is 10TB.
Object file has range from 0 byte to 5TB
References
AWS Snowball Edge Hardware Specification
SBE Pricing
Xem thêm: https://cloudemind.com/snowball/
0 notes
Text
Amazon CloudFront Cheat Sheet
Có bài viết học luyện thi AWS mới nhất tại https://cloudemind.com/cloudfront/ - Cloudemind.com
Amazon CloudFront Cheat Sheet

Amazon CloudFront
Is a Content Delivery Network (CDN) service to help increase performance and experiences for user by speeding up distribution of static and dynamic web content.
Deliver contents via world wide data centers called Edge locations. When the user requests to a content, the request will go to the Edge location first, the location is very near user to have better speed and performance instead of going to Origin.
Benefits is lowest latency and best possible performance.
If the content is not in Edge Location, CloudFront will ask Regional Edge Cache Location. If the content is still not existed in Regional Edge, it will go to Origin to get the data.
How CloudFront work?
Origin servers is your data sources, you need to specific this step and CloudFront will get our files and distribute from CloudFront edge locations over the world.
The files in your Origin servers is called object.
CloudFront Distribution is a configuration to tell CloudFront which is your origin servers when a new request from user to reach. In the meantime, you also can configure the way to cache your content, whether you want CloudFront to log all your requests or whether you want CloudFront to log the requests asap.
Each CloudFront Distribution has a domain name and you can see it from CloudFront Console.
CloudFront supports HTTP protocol and WebSocket protocol
Using lambda@edge can help CloudFront customize the calculation on the content in many ways before delivering.
CloudFront Regional Edge Cache location is new feature of CloudFront allows to cache more content to your users, even the content is not popular to store in Edge Location. This can improve performance for the content instead of going back to Origin and get it.
CloudFront Origin Server types:
Amazon S3 bucket
MediaPackage channel
HTTP Server such as EC2 web server
Objects are cached by 24 hours default. You can invalidate this before expired time.
Support to compress file.
You can use distributions to serve the following content over HTTP or HTTPS:
Static and dynamic content
Video on demand (Apache HTTP Live Streaming HLS and Microsoft Smooth Streaming)
A live event, such as meeting, conference in real time
Values that you can configure for a distribution:
Delivery method: Web or RTMP
Origin settings – information one or more locations where you store your origin contents (up to 25).
Cache behavior setting – caching behavior when given URL path pattern for files on your website.
Custom error page and error caching
Restriction – you can configure the allow to allow some users from countries to access your content, and deny list to deny access from some countries.
CloudFront provides policies to configure the cache behavior. You can use pre-made by AWS or custom by your own. These policies to help you configure the cache TTL settings, cache key contents, and compression settings.
You can choose HTTPS with CloudFront in both ways:
Between viewers and CloudFront
Between CloudFront and Origin
Monitoring
Use AWS Config to see the CloudFront distributions setting changes.
CloudFront can integrate with CloudWatch to monitor websites or application
Capture API requests with CloudTrail. CloudFront is global service, Cloudtrail is Region service. To view CloudFront requests in CloudTrail logs, you must update an existing trail to include global services.
Security
CloudFront, WAF, Shield and Route 53 are working seamlessly and be a good friends to bring higher security to defense multiple attacks including network and application (layer 4 and layer 7) DDoS attacks.
You can deliver your content, APIs or application via SSL/TLS, and advanced SSL features is enabled automatically.
From Geo-restriction capability, you can restrict users from some geographic locations from accessing your content distributed by CloudFront.
Origin Access Identity – restrict access to an Amazon S3 bucket, you can only access from CloudFront. This is make sure you leverage the benefits of CloudFront security and other AWS Services such as: WAF, Shield for higher security.
Field Level Encryption is a feature of CloudFront that allow to secure some sensitive information such as credit card number to your origin servers.
Compliant with PCIDSS, HIPAA, SOC measures.
Pricing
Data transfer out
serving objects from edge locations
submitting data to your origins
Charge for other origin such as S3 storage…
HTTP / HTTPS requests
Charge for requests with field-level-encryption enabled.
Data transfer out from Origin to Edge Location is free of charge.
AWS has a free tier for CloudFront
Limitations
Data transfer rate per distribution: 150 Gbps
Requests per second per distribution: 250K
Files that you can serve per distribution: No quota
Maximum length of request, including header and query string, but not including content: 20,480 bytes
Maximum length of a URL: 8,192 bytes
Web distribution per AWS account: 200
Maximum file size for HTTP GET, PUT, POST request: 20GB
Response timeout per origin: 1-60 seconds
Connection timeout per origin: 1-10 seconds
Connection attempts per origin: 1-3
File size compression: 1K to 10M bytes
Alternate domain names CNAMEs per distribution: 100
Origins per distribution: 25
Origin group per distribution: 10
Origin access identity per account: 100
Cache behavior per distribution: 25
RMTP distributions per account: 100
Request timeout: 30 seconds
References
CloudFront distributions
https://aws.amazon.com/cloudfront/pricing/
Amazon CloudFront quotas
Xem thêm: https://cloudemind.com/cloudfront/
0 notes