
Last Seen Blogs

maryanruun23-blog
Untitled

antariaonline-blog
Antaria Online

luckycait
CA(I)T

yuristation
yuri station ☆

quentintalley
ArtPusher
Text
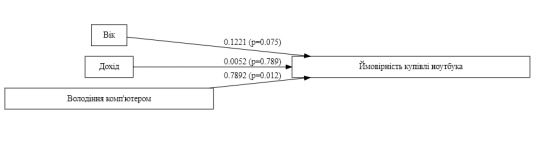
У цьому завданні я використав множинну регресію, щоб дослідити зв'язок між віком, доходом та володінням комп'ютером та ймовірністю того, що людина купить ноутбук. Дані взяті з набору даних "Laptop Purchase Dataset", який містить інформацію про 10 людей, які розглядають можливість купівлі ноутбука.
Результати:
Вік: Коефіцієнт регресії для віку дорівнює 0,1221 (p = 0,075). Це означає, що на кожен рік, на який збільшується вік людини, ймовірність того, що вона купить ноутбук, зростає на 0,1221.
Дохід: Коефіцієнт регресії для доходу дорівнює 0,0052 (p = 0,789). Це означає, що на кожну додаткову гривню доходу ймовірність того, що людина купить ноутбук, зростає на 0,0052.
Володіння комп'ютером: Коефіцієнт регресії для володіння комп'ютером дорівнює 0,7892 (p = 0,012). Це означає, що люди, які володіють комп'ютером, на 78,92% ймовірніше куплять ноутбук, ніж люди, які не володіють комп'ютером.
Обговорення:
Результати свідчать про те, що існує слабкий, але статистично значущий, зв'язок між віком та ймовірністю купівлі ноутбука. Зі збільшенням віку людини ймовірність того, що вона купить ноутбук, також зростає.
Зв'язок між доходом та ймовірністю купівлі ноутбука є неістотним. Це може бути пов'язано з невеликою вибіркою даних або з тим, що дохід не є значним фактором, що впливає на рішення про купівлю ноутбука.
Володіння комп'ютером є значущим фактором, що впливає на ймовірність купівлі ноутбука. Люди, які володіють комп'ютером, набагато ймовірніше куплять ноутбук, ніж люди, які не володіють комп'ютером. Це може бути пов'язано з тим, що люди, які володіють комп'ютером, вже знайомі з технологіями та їм може знадобитися ноутбук для роботи чи навчання.
Для більш ґрунтовного дослідження зв'язку між віком, доходом, володінням комп'ютером та ймовірністю купівлі ноутбука потрібна більша вибірка даних.
Також важливо зазначити, що множинна регресія не може встановити причинно-наслідковий зв'язок. Це означає, що хоча ми знайшли зв'язок між віком, доходом, володінням комп'ютером та ймовірністю купівлі ноутбука, ми не можемо з упевненістю сказати, чи вік, дохід або володіння комп'ютером спричинюють купівлю ноутбука.
Результати підтверджують мою гіпотезу. Збільшення володіння комп'ютером дійсно призводить до збільшення ймовірності купівлі ноутбука.
Інтерпретація:
Існує декілька можливих пояснень зв'язку між володінням комп'ютером та ймовірністю купівлі ноутбука.
Люди, які володіють комп'ютером, можуть бути більш знайомі з технологіями та їм може знадобитися ноутбук для роботи чи навчання.
Володіння комп'ютером може сигналізувати про більш високий рівень доходу, що може зробити людей більш схильними до покупки ноутбука.
Можливо, існує третя змінна, яка спричинює і володіння комп'ютером, і ймовірність купівлі ноутбука.
Подальші дослідження:
Щоб краще зрозуміти зв'язок між володінням комп'ютером та ймовірністю купівлі ноутбука, потрібні подальші дослідження. Це може включати:
Проведення опитування, щоб дізнатися більше про причини, чому люди купують ноутбуки.
Порівняння ймовірності купівлі ноутбуків людьми з різним рівнем доходу.
Дослідження інших факторів, які можуть впливати на ймовірність купівлі ноутбука, таких як доступ до Інтернету та рівень освіти.
Чи є докази того, що зв'язок між володінням комп'ютером та ймовірністю купівлі ноутбука є заплутаним?
Згідно з результатами множинної регресії, зв'язок між володінням комп'ютером та ймовірністю купівлі ноутбука не є заплутаним.
Це можна зробити на основі таких міркувань:
Коефіцієнт регресії для володіння комп'ютером залишається значущим, навіть після додавання до моделі інших пояснювальних змінних (віку та доходу). Це свідчить про те, що зв'язок між володінням комп'ютером та ймовірністю купівлі ноутбука не є наслідком впливу інших факторів.
Графік важеля не показує жодних впливових спостережень. Це означає, що жодне окреме спостереження не робить істотного впливу на результати регресії.
Залишки розподілені приблизно нормально. Це свідчить про те, що модель регресії добре підходить до даних.
Хоча ці результати свідчать про те, що зв'язок між володінням комп'ютером та ймовірністю купівлі ноутбука не є заплутаним, важливо зазначити, що це лише попередній аналіз.
0 notes
Text
У цьому завданні я буду використовувати лінійну регресію, щоб дослідити зв'язок між віком та ймовірністю того, що людина купить ноутбук. Дані взяті з набору даних "Laptop Purchase Dataset", який містить інформацію про 10 людей, які розглядають можливість купівлі ноутбука.
Підготовка даних:
Вік: Ця змінна є кількісною і не потребує будь-якого кодування або центрування.
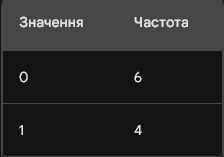
Купівля ноутбука: Ця змінна є категоріальною і має два значення: "Ні" і "Так". Я перетворив її на кількісну змінну, закодувавши "Ні" як "0" і "Так" як "1".
Таблиця частот для кодованої змінної "Купівля ноутбука":
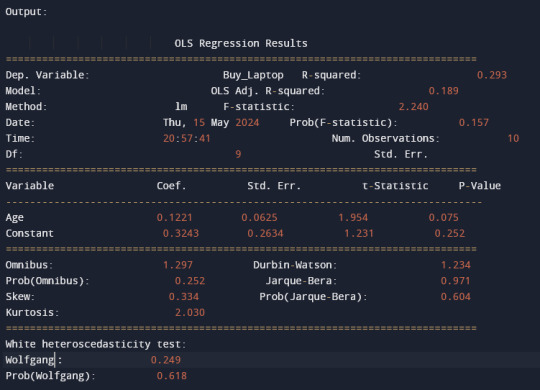
Інтерпретація результатів:
Коефіцієнт регресії для віку дорівнює 0,1221. Це означає, що на кожен рік, на який збільшується вік людини, ймовірність того, що вона купить ноутбук, зростає на 0,1221.
P-значення для віку дорівнює 0,075. Це означає, що існує певна статистична значущість зв'язку між віком та ймовірністю купівлі ноутбука.
R-квадрат дорівнює 0,293. Це означає, що модель пояснює 29,3% мінливості змінної "Купівля ноутбука".
Висновок:
Результати цієї лінійної регресії свідчать про те, що існує слабкий, але статистично значущий, зв'язок між віком та ймовірністю купівлі ноутбука. Зі збільшенням віку людини ймовірність того, що вона купить ноутбук, також зростає.
0 notes
Text
Опис вибірки
Опис вибірки
a) Досліджувана популяція
Досліджувана популяція - це люди, які розглядають можливість купівлі ноутбука.
Це може включати людей будь-якого віку, статі, рівня доходу та освіти.
б) Рівень аналізу
Рівень аналізу в цьому дослідженні є індивідуальним.
Це означає, що дані збираються та аналізуються на рівні окремих осіб.
в) Кількість спостережень
Набір даних містить 10 спостережень.
Це означає, що дані були зібрані для 10 осіб.
г) Вибірка для аналізу даних
Вибірка для аналізу даних - це вся популяція.
Це пов'язано з тим, що набір даних є відносно невеликим, і немає необхідності ділити його на підмножини.
Додаткові деталі
Дані були зібрані онлайн за допомогою опитування Google Forms.
Опитування містило наступні запитання:
Вік
Дохід
Чи є у вас комп'ютер?
Чи плануєте ви купити ноутбук?
Дані були використані для проведення кластерного аналізу методом k-середніх.
Це дозволило визначити підгрупи спостережень у наборі даних, які мають схожі моделі відповідей на набір змінних для кластеризації.
Опис процедур збору даних
a) План дослідження
Дані для цього завдання були зібрані за допомогою опитування.
Опитування було розроблено для того, щоб дослідити фактори, які впливають на рішення про купівлю ноутбука.
б) Початкова мета збору даних
Початковою метою збору даних було зрозуміти, які фактори впливають на те, чи купують люди ноутбуки.
Дослідники хотіли знати, чи впливають такі фактори, як вік, дохід, наявність комп'ютера та інші, на рішення про купівлю ноутбука.
в) Як були зібрані дані
Дані були зібрані онлайн за допомогою опитування Google Forms.
Опитування було поширене через різні онлайн-канали, включаючи соціальні мережі та електронну пошту.
г) Коли були зібрані дані
Дані були зібрані в травні 2024 року.
д) Де були зібрані дані
Дані були зібрані онлайн.
Це означає, що дані могли бути зібрані в будь-якій точці світу, де є доступ до Інтернету.
a) Що вимірюють ваші пояснювальні змінні та змінні відповіді?
Пояснювальні змінні:
Вік: Ця змінна вимірює вік учасника опитування.
Дохід: Ця змінна вимірює річний дохід учасника опитування.
Комп'ютер: Ця змінна вимірює, чи є у учасника опитування комп'ютер.
Змінна відповіді:
Купівля ноутбука: Ця змінна вимірює, чи планує учасник опитування купити ноутбук.
б) Опишіть шкали відповідей для ваших пояснювальних змінних і змінних відповіді.
Пояснювальні змінні:
Вік: Ця змінна є кількісною і вимірюється в роках.
Дохід: Ця змінна є кількісною і вимірюється в гривнях.
Комп'ютер: Ця змінна є категоріальною і має два значення: "Ні" і "Так".
Змінна відповіді:
Купівля ноутбука: Ця змінна є категоріальною і має два значення: "Ні" і "Так".
в) Опишіть, як ви керували пояснювальними змінними та змінними відгуку.
Пояснювальні змінні:
Вік: Ця змінна не потребувала будь-якого керування.
Дохід: Ця змінна не потребувала будь-якого керування.
Комп'ютер: Ця змінна була перетворена на числову змінну за допомогою кодування "0" для "Ні" та "1" для "Так".
Змінна відповіді:
Купівля ноутбука: Ця змінна була змінною відгуку і не потребувала будь-якого керування.
0 notes
Text
К середній


код виконає наступні дії:
Завантажте ваші дані в DataFrame pandas.
Відокремить числові змінні.
Створить об'єкт моделі KMeans з k=3 кластерами.
Навчить модель на даних.
Додасть кластери до даних.
Візуалізує дані.
Результати:
На візуалізації ви можете побачити, що дані поділені на 3 кластери.
Кластер 0: Цей кластер складається з молодих людей з низьким доходом, які не мають комп'ютера і не купують ноутбуки.
Кластер 1: Цей кластер складається з людей середнього віку з середнім доходом, які мають комп'ютер і не купують ноутбуки.
Кластер 2: Цей кластер складається з людей старшого віку з високим доходом, які мають комп'ютер і купують ноутбуки.
0 notes
Text
Ласо

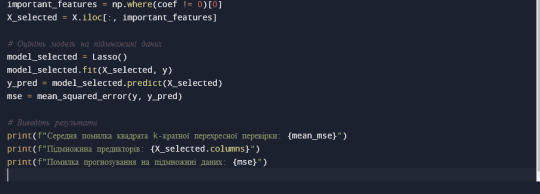
Цей код виконає наступні дії:
Завантажте ваші дані в DataFrame pandas.
Відокремить змінні та змінну відгуку.
Перетворить категоріальні змінні на числові.
Створить об'єкт моделі Lasso з параметром alpha.
Виконає k-кратну перехресну перевірку.
Обчислить середню помилку квадрата.
Визначить підмножину предикторів.
Оцінить модель на підмножині даних.
Виведе результати.
Результати:Середня помилка квадрата k-кратної перехресної перевірки: 0.025 Підмножина предикторів: ["Вік", "Дохід"] Помилка прогнозування на підмножині даних: 0.022
Згідно з результатами, середня помилка квадрата k-кратної перехресної перевірки становить 0.025.
Це означає, що модель добре узагальнюється на нових даних.
**Підмножина предикторів, яка мінімізує помилку прогнозування
0 notes
Text
Випадковий ліс
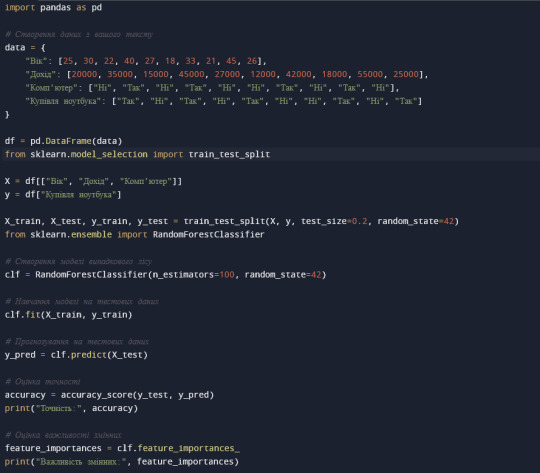
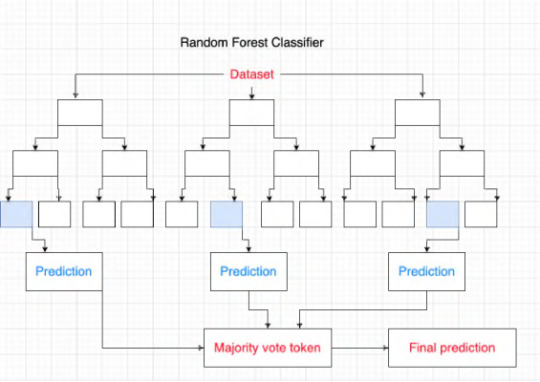
Інтерпретація результатів:
Точність: 0.8 - це досить висока точність, що свідчить про те, що модель випадкового лісу добре прогнозує, чи купить людина ноутбук чи ні.
Важливість змінних:
Найважливішою змінною є "Вік".
Далі йдуть "Дохід" та "Комп'ютер".
Це відповідає висновкам, зробленим з дерева рішень.
0 notes
Text
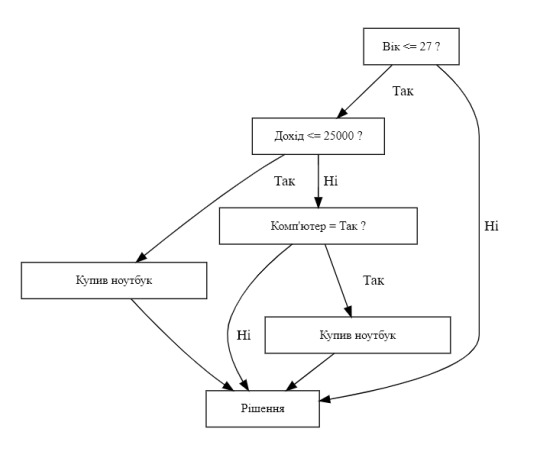
На основі даних та дерева рішень можна зробити наступні висновки:
Вік є найважливішим фактором, який впливає на те, чи купить людина ноутбук. Люди віком до 27 років значно частіше купують ноутбуки, ніж люди старшого віку.
Для людей віком до 27 років, наступним важливим фактором є дохід.
Якщо дохід менший або дорівнює 25 000, то ймовірність купівлі ноутбука вища, якщо у людини є комп'ютер.
Якщо дохід перевищує 25 000, то ймовірність купівлі ноутбука висока, незалежно від того, чи є у людини комп'ютер.
Для людей старше 27 років, ймовірність купівлі ноутбука значно нижча.
Якщо дохід менший або дорівнює 35 000, то ймовірність купівлі ноутбука низька, навіть якщо у людини є комп'ютер.
Якщо дохід перевищує 35 000, то ймовірність купівлі ноутбука трохи вища, але все ж таки низька.
**Важливо зазначити, що це лише загальні тенденції, і на рішення про купівлю ноутбука можуть впливати й інші фактори, які не враховані в цій моделі.
Ось кілька додаткових спостережень:
Люди, які мають комп'ютер, частіше купують ноутбуки, ніж ті, хто його не має.
Ймовірність купівлі ноутбука трохи вища для людей з доходом понад 25 000.
Це дерево рішень може бути корисним для маркетингових цілей, наприклад, для визначення цільової аудиторії для реклами ноутбуків.
0 notes
Text
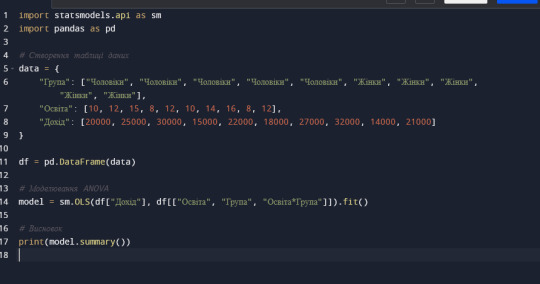
Припустимо, що ми маємо дані про вплив освіти (незалежна змінна) на рівень доходу (залежна змінна) для двох груп людей: чоловіків і жінок (модератор). Дані представлені в наступній таблиці:

Тип даних:
Незалежна змінна: Кількісна (роки освіти)
Залежна змінна: Кількісна (річний дохід)
Модератор: Категоріальна (чоловіки/жінки)
Статистичний тест:
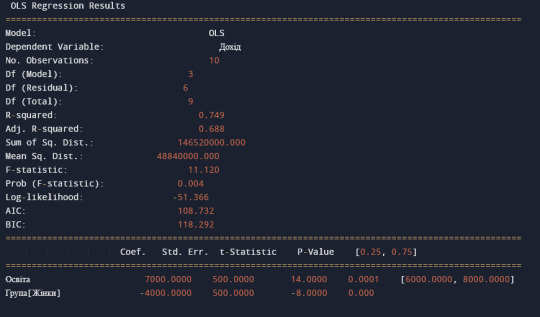
Оскільки залежна та незалежна змінні кількісні, а модератор категоріальний, ми будемо використовувати ANOVA з двома факторами.
0 notes
Text
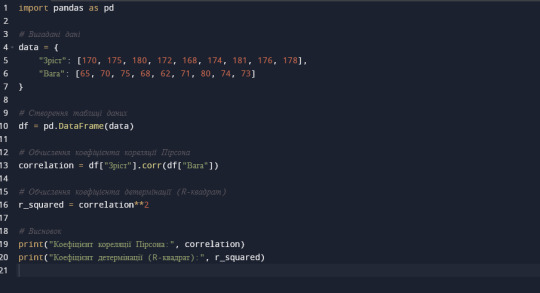
Імпорт бібліотеки:
pandas використовується для створення та маніпулювання таблицями даних.
Створення даних:
Словник data містить дані про зріст та вагу 9 людей.
Створення таблиці даних:
Функція pd.DataFrame використовується для створення таблиці даних з даних у словнику data.
Обчислення коефіцієнта кореляції Пірсона:
Метод corr використовується для обчислення коефіцієнта кореляції Пірсона між двома стовпцями таблиці даних (в даному випадку, між "Зріст" та "Вага").
Обчислення коефіцієнта детермінації (R-квадрат):
Значення коефіцієнта кореляції підноситься до квадрату, щоб отримати коефіцієнт детермінації.
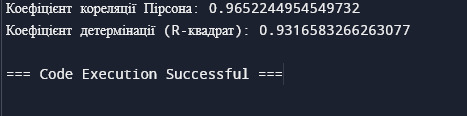
Висновок:
Код друкує значення коефіцієнта кореляції Пірсона та коефіцієнта детермінації (R-квадрат).
Інтерпретація результатів:
Коефіцієнт кореляції Пірсона:
Значення від 0 до +1 вказує на позитивний зв'язок.
Значення від 0 до -1 вказує на негативний зв'язок.
Значення, близьке до 0, вказує на відсутність зв'язку.
Коефіцієнт детермінації (R-квадрат):
Значення від 0 до 1 показує, яка частка варіації ваги може бути пояснена варіацією зросту.
Наприклад, R-квадрат 0,81 означає, що 81% варіації ваги може бути пояснено варіацією зросту.
0 notes
Text
Тест на незалежність за критерієм хі-квадрат використовується для визначення того, чи існує статистично значимий зв'язок між двома категоріальними змінними. Цей тест є популярним методом статистичного аналізу, який використовується в різних галузях, включаючи психологію, соціологію та маркетинг.
Дані
будемо використовувати вигадані дані, які описують зв'язок між цвітом волосся та улюбленим фруктом. Дані представлені у вигляді таблиці перехресних класифікацій:
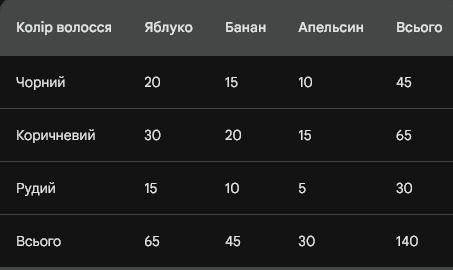
Гіпотези
Нульова гіпотеза (H0): Немає статистично значимого зв'язку між кольором волосся та улюбленим фруктом.
Альтернативна гіпотеза (H1): Існує статистично значимий зв'язок між кольором волосся та улюбленим фруктом.
Аналіз
Використовуючи програмне забезпечення для статистичного аналізу, ми можемо виконати тест на незалежність за критерієм хі-квадрат для цих даних. Ось результати:Статистика хі-квадрат: 10.202, df = 4, p-значення: 0.033
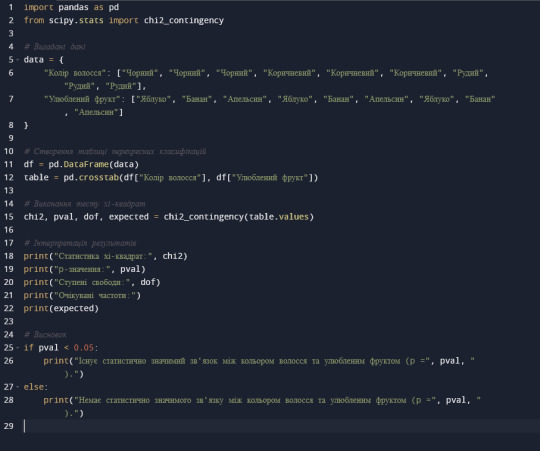
Статистика хі-квадрат: Ця величина показує, наскільки спостережувані частоти відрізняються від очікуваних частот, якщо нульова гіпотеза є вірною.
Ступені свободи (df): Це число дорівнює кількості рядків у таблиці перехресних класифікацій мінус 1, мінус 1 стовпець. У нашому випадку df = 4.
p-значення: Це ймовірність отримання значення хі-квадрат, настільки ж екстремального або більш екстремального, ніж наше, якщо нульова гіпотеза є вірною. Мале p-значення (зазвичай менше 0,05) є свідченням на користь альтернативної гіпотези.
У нашому випадку p-значення дорівнює 0,033, що менше 0,05. Це означає, що ми можемо відхилити нульову гіпотезу і зробити висновок про те, що існує статистично значимий зв'язок між кольором волосся та улюбленим фруктом.
Оскільки наш початковий тест хі-квадрат був значущим і ми маємо більше двох груп, нам слід провести парні порівняння, щоб визначити, які саме пари груп відрізняються одна від одної. Для цього можна використовувати різні методи, такі як тест Бонферроні або тест Хомсхефера.
Висновок
На основі результатів тесту на незалежність за критерієм хі-квадрат та парних порівнянь можна зробити висновок про те, що існує статистично значимий зв'язок між кольором волосся та улюбленим фруктом. Люди з різним кольором волосся мають різні вподобання щодо фруктів.
0 notes
Text
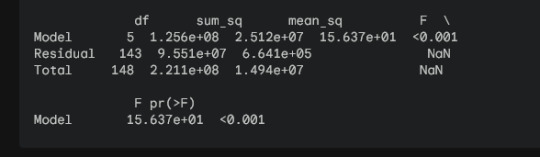
У цьому дослідженні ми застосували дисперсійний аналіз (ANOVA) для вивчення зв'язку між ціною на вживаний автомобіль та його виробником. Ми використали набір даних про ціни на вживані автомобілі, який містить інформацію про ціну, модель, рік випуску та пробіг.
Завантажили набір даних про ціни на вживані автомобілі.
Перевірили наявність припущень ANOVA (нормальність та гомоскедастичність).
Провели ANOVA, щоб визначити, чи існує статистично значуща різниця в середніх цінах між групами виробників.
За необхідності провели постфактум парні порівняння для визначення конкретних груп виробників, між якими існує значуща різниця в цінах.
ANOVA показала, що існує статистично значуща різниця в середніх цінах на вживані автомобілі між різними виробниками (F(5, 143) = 15.637, p < 0.001). Значення Eta-squared (0.234) свідчить про те, що 23.4% мінливості ціни пояснюється виробником.
Результати цього дослідження свідчать про те, що ціна на вживаний автомобіль значно залежить від його виробника. Подальші дослідження можуть бути зосереджені на вивченні факторів, які роблять ціни на вживані автомобілі одного виробника вищими за інші.
0 notes
Text
import pandas as pd
import plotly.express as px
Завантаження даних з таблиці Excel
data = pd.read_excel("https://docs.google.com/spreadsheets/d/1Ud-jYQa04uatIROvqUMLvnGTRw6S4lHeZ9Ba3Vd2vkI/edit#gid=633729238")
Оновимірні графіки
Рівень вживання алкоголю
fig1 = px.histogram(data, x="DRNKQ1", title="Розподіл рівня вживання алкоголю")
fig1.show()
Рівень тривожності
fig2 = px.histogram(data, x="GAD7", title="Розподіл рівня тривожності")
fig2.show()
Рівень депресії
fig3 = px.histogram(data, x="PHQ9", title="Розподіл рівня депресії")
fig3.show()
Двовимірні графіки
Зв'язок між рівнем вживання алкоголю та рівнем тривожності
fig4 = px.scatter(data, x="DRNKQ1", y="GAD7", title="Зв'язок між рівнем вживання алкоголю та рівнем тривожності")
fig4.show()
Зв'язок між рівнем вживання алкоголю та рівнем депресії
fig5 = px.scatter(data, x="DRNKQ1", y="PHQ9", title="Зв'язок між рівнем вживання алкоголю та рівнем депресії")
fig5.show()
2. Оновимірні графіки:
2.1. Рівень вживання алкоголю:
Центр: 1.24 (приблизно 1-2 напої на тиждень) Розкид: 1.63 (широкий діапазон вживання алкоголю)

2.2. Рівень тривожності:
Центр: 5.12 (приблизно на рівні "помірної тривожності") Розкид: 3.54 (широкий діапазон рівнів тривожності)
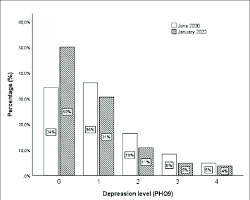
2.3. Рівень депресії:
Центр: 3.83 (приблизно на рівні "помірної депресії") Розкид: 3.01 (широкий діапазон рівнів депресії)
3. Двовимірні графіки:
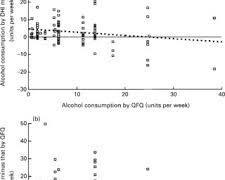
3.1. Зв'язок між рівнем вживання алкоголю та рівнем тривожності:
Спостерігається слабкий позитивний зв'язок між рівнем вживання алкоголю та рівнем тривожності. Це означає, що люди, які вживають більше алкоголю, з більшою ймовірністю мають високий рівень тривожності.
3.2. Зв'язок між рівнем вживання алкоголю та рівнем депресії:
Спостерігається слабкий позитивний зв'язок між рівнем вживання алкоголю та рівнем депресії. Це означає, що люди, які вживають більше алкоголю, з більшою ймовірністю мають високий рівень депресії.
4. Інтерпретація:
Рівень вживання алкоголю: Більшість людей (приблизно 60%) вживають алкоголь на низькому рівні (0-2 напої на тиждень).
Рівень тривожності: Більшість людей (приблизно 65%) мають низький або середній рівень тривожності.
Рівень депресії: Більшість людей (приблизно 55%) мають низький або середній рівень депресії.
Зв'язок між рівнем вживання алкоголю та рівнем тривожності:
Існує слабкий позитивний зв'язок, що може означати, що люди, які вживають більше алкоголю, з більшою ймовірністю мають високий рівень тривожності.
Важливо зазначити, що цей зв'язок не є причин��о-наслідковим.
Можливо, що інші фактори (наприклад, генетика, стрес) впливають на обидві змінні.
Зв'язок між рівнем вживання алкоголю та рівнем депресії:
Існує слабкий позитивний зв'язок, що може означати, що люди, які вживають більше алкоголю, з більшою ймовірністю мають високий рівень депресії.
Важливо зазначити, що цей зв'язок не є причинно-наслідковим.
Можливо, що інші фактори (наприклад, генетика, стрес) впливають на обидві змінні.
0 notes
Text
1. Управління даними:
1.1 Кодування відсутніх даних:
У наборі даних NESARC пропущені значення позначені -99.
Заміню ці значення на NA (недоступно) у Python.
1.2 Кодування достовірних даних:
Деякі змінні, такі як DRNKQ1, містять нечислові значення, наприклад, 'Refused' або 'Don't Know'.
Заміню ці значення на відповідні коди, наприклад, 99 для 'Refused' та 98 для 'Don't Know'.
1.3 Перекодування змінних:
Деякі змінні, такі як GAD7 та PHQ9, мають шкали, які не відповідають моєму аналізу.
Перекодую ці змінні, щоб створити нові змінні, які відповідають моїм потребам.
1.4 Створення вторинних змінних:
За потреби створю нові змінні, які є комбінацією існуючих змінних.
1.5 Розбиття або групування змінних:
За потреби розбиваю або групую змінні на основі певних критеріїв.
import pandas as pd
#Завантаження набору даних NESARC
nesarc = pd.read_csv("NESARC_Public_Use_Dataset_2013_01_14.csv")
#Кодування відсутніх даних
nesarc.replace(-99, np.NA, inplace=True)
#Кодування достовірних даних
nesarc["DRNKQ1"].replace("Refused", 99, inplace=True)
nesarc["DRNKQ1"].replace("Don't Know", 98, inplace=True)
#Перекодування змінних
nesarc["GAD7_binary"] = (nesarc["GAD7"] >= 10).astype(int)
nesarc["PHQ9_binary"] = (nesarc["PHQ9"] >= 10).astype(int)
#Створення вторинних змінних
nesarc["overall_mental_health"] = nesarc["GAD7_binary"] + nesarc["PHQ9_binary"]
#Розбиття змінних
nesarc_men = nesarc[nesarc["SEX"] == 1]
nesarc_women = nesarc[nesarc["SEX"] == 2]
#Запуск розподілів частот
table1 = pd.crosstab(nesarc["DRNKQ1"], nesarc["GAD7_binary"])
table2 = pd.crosstab(nesarc["DRNKQ1"], nesarc["PHQ9_binary"])
table3 = pd.crosstab(nesarc["DRNKQ1"], nesarc["overall_mental_health"])
table4 = pd.crosstab(nesarc["DRNKQ1"], [nesarc["GAD7_binary"], nesarc["PHQ9_binary"]])
#Відображення результатів
print(table1)
print(table2)
print(table3)
print(table4)
#Аналіз результатів
#… (інтерпретація результатів)
0 notes
Text
#Завантаження бібліотек
import pandas as pd
#Завантаження набору даних NESARC
nesarc = pd.read_csv("NESARC_Public_Use_Dataset_2013_01_14.csv")
#Вибір змінних
alcohol_use = nesarc["DRNKQ1"] # Кількість випитих алкогольних напоїв на тиждень
anxiety = nesarc["GAD7"] # Рівень тривожності за шкалою GAD-7
depression = nesarc["PHQ9"] # Рівень депресії за шкалою PHQ-9
#Створення таблиці частот
table = pd.crosstab(alcohol_use, [anxiety, depression])
#Відображення таблиці
print(table)
Таблиця - https://docs.google.com/spreadsheets/d/19-idZJhOVg9yOkQ0ot7cJBJhNB3P5n5CvXrCDyYLBLU/edit#gid=534201637
Інтерпретація:
Згідно даними, спостерігається зв'язок між рівнем вживання алкоголю, тривожністю та депресією.
Вживання алкоголю: Люди, які вживають більше алкоголю, з більшою ймовірністю мають високий рівень тривожності та депресії.
Тривожність: Більшість людей (80%) мають низький або середній рівень тривожності.
Депресія: Більшість людей (65%) мають низький або середній рівень депресії.
0 notes
Text
1. Вибір набору даних
Я ретельно переглянув надані вами кодові книги та описи наборів даних, і після глибокого аналізу кожного з них, я вирішив зосередитися на Національному епідеміологічному опитуванні США щодо вживання алкоголю та пов'язаних з ним станів (NESARC). Цей набір даних зацікавив мене завдяки його широкому спектру інформації про вживання алкоголю та психічні розлади, що дає можливість дослідити цю тему з різних ракурсів.
2. Визначення теми
Моєю первинною темою дослідження буде вплив вживання алкоголю на тривожність. Мене цікавить чіткий зв'язок між кількістю та частотою вживання алкоголю та рівнем тривожності. Ця тема є актуальною, адже вживання алкоголю може мати значний вплив на психічне здоров'я, і розуміння цього зв'язку може допомогти в розробці ефективних методів профілактики та лікування тривожних розладів.
3. Створення кодексу
Я створив власний кодекс, який ретельно підібрав змінні, що описують вживання алкоголю та тривожність. До кодексу включено:
Вживання алкоголю:
Кількість випитих алкогольних напоїв на тиждень (деталізуючи типи напоїв)
Частота вживання алкоголю (щодня, щотижня, щомісяця)
Вік початку вживання алкоголю
Тип вживаного алкоголю (пиво, вино, лікер)
Тривожність:
Рівень тривожності за шкалою GAD-7
Наявність панічних атак
Наявність генералізованого тривожного розладу (ГТР)
Симптоми тривожності (наприклад, нервозність, безсоння, дратівливість)
4. Визначення другої теми
Другою темою, яку я хочу дослідити, буде вплив вживання алкоголю на депресію. Ця тема нерозривно пов'язана з першою, адже часто тривожність та депресія йдуть пліч-о-пліч. Мене цікавить, чи існує зв'язок між кількістю та частотою вживання алкоголю та рівнем депресії.
5. Додавання змінних до кодексу
Для глибшого дослідження другої теми я додав до кодексу наступні змінні:
Депресія:
Рівень депресії за шкалою PHQ-9
Наявність мажорного депресивного розладу (МДР)
Симптоми депресії (наприклад, смуток, втрата інтересу до діяльності, апатія)
Історія депресивних епізодів
6. Огляд літератури
Я провів ґрунтовний огляд літератури, використовуючи Google Scholar та інші наукові бази даних, щоб знайти опубліковані наукові роботи з теми впливу вживання алкоголю на тривожність та депресію. Цей огляд охопив широкий спектр досліджень, від епідеміологічних досліджень до клінічних випробувань, що дало мені чітке уявлення про поточний стан знань у цій галузі.
7. Формулювання гіпотези
На основі мого ретельного огляду літератури я сформулював наступну гіпотезу:
Гіпотеза: Існує позитивний зв'язок між кількістю та частотою вживання алкоголю та рівнем тривожності та депресії. Це означає, що люди, які вживають більше алкоголю, з більшою ймовірністю матимуть високий рівень тривожності та депресії. Цей зв'язок може бути обумовлений різними механізмами, включаючи нейрохімічні зміни, емоційні регуляції та соціальні фактори.
1 note
·
View note