#xpu
Photo

Monthly
#A#render#houdini#animated#simulated#karma#cpu#xpu#liquid#flow#path#particles#water#motion graphics#black#ritch#loop
87 notes
·
View notes
Text
youtube
XPUS-INTO THE SPHERE OF MADNESS
1 note
·
View note
Text
Descubra as paradisíacas praias da Riviera Maya
Descubra as paradisíacas praias da Riviera Maya
Conheça as principais praias da Riviera Maya, o complexo litorâneo do México de 120 km de visuais paradisíacos, ótimos hotéis e passeios fantásticos.
Com 120 km de litoral localizada no estado de Quintana Roo, no México, a Riviera Maya abriga algumas das praias mais lindas do mundo. Além das praias, a região conta com hotéis de luxo e passeios em sítios arqueológicos incríveis.
Escolher a época…

View On WordPress
#Cozumel#Hotel Grand Palladium Kantenah#Kantenah#México#Playa del Carmen#Quintana Roo#Riviera Maya#Tulum#Xcacel#Xpu-ha
1 note
·
View note
Text

!!Taking Emergency art commissions!!
TLDR: car kicked the bucket, would love to make art for you in exchange for money so I can get a new-used car and get myself back up to college in time
Hey all! I’m in a bit of an emergency situation in that my car died. I go to college somewhere where the public transport is basically non existent a car is a necessity. The cost to fix my current car is $10,000, which I very much don’t have. Instead I’m trying to get a used car for under that, so I can make it back to college in time for the semester.
I want to offer my artistic services in the form of art commissions, in hopes to be able to scrape enough money together to get a vehicle.
The type of art I do: I most often do character art, such as D&D/TTRPG characters, pets, people’s OC’s, fanart of anime/video game/cartoon characters, furries, etc. See examples for better comprehension of my style!
What you’ll get: a digital file .png of what you’ve had me draw. It can be used as a background for phones/tablets/desktop, as a pfp, etc. Although I’d love to do physical art, I just currently don’t have the materials or time to do so! I also unfortunately can’t afford the time to make pins/clothes/stickers/prints at the moment
Refined sketches are between 20-40 USD
Clean lineart is 40-60 USD
Rendered is between 65-80 USD
Illustrations are between 90-110 USD
Backgrounds/landscapes vary piece to piece, but would generally be between 80-100 USD
My Terms of Service for the commissioners: https://docs.google.com/document/d/1X0SG2nQcl-Xpu-RSxI4V4BgHWghhlwxT-fbm-iK20NM/edit
Donations are also welcomed but of course never expected
Venmo: @Icarus-Farnham
Cashapp: $gaybotanist
Zelle & PayPal: ask!






#alright time for a fuck ton of tags for reach#furries#art#furry art#furry#anthro#furry sfw#anthro art#commission#commissionsopen#commission art#art commission#lgbtq community#dnd#dnd art#dnd character#dnd oc#dungeons and dragons#dnd5e#ttrpg#d&d#d&d 5e#d&d art#d&d character#d&d oc#fantasy#pathfinder
53 notes
·
View notes
Photo

Intel HPC Roadmap: 800W Rialto Bridge GPU, Falcon Shores XPU, Ponte Vecchio with HBM Benchmarks https://ift.tt/PgyHQvz
3 notes
·
View notes
Link
Juntamente com as atualizações de CPU do servidor EPYC, porquê segmento do evento AMD Data Center de hoje, a empresa também está oferecendo uma atualização sobre o status de sua família de aceleradores AMD Instinct MI300 quase finalizada. Os processadores de classe HPC de próxima geração da empresa, que usam núcleos de CPU Zen 4 e núcleos de GPU CDNA 3 em um único pacote, agora se tornaram uma família multi-SKU de XPUs. Juntando-se ao APU MI300 de 128 GB anunciado anteriormente, que agora está sendo chamado de MI300A, a AMD também está produzindo uma peça de GPU pura usando o mesmo design. Nascente chip, chamado de MI300X, usa exclusivamente blocos de GPU CDNA 3 em vez de uma mistura de blocos de CPU e GPU no MI300A, tornando-o uma GPU pura de cimo desempenho que é emparelhada com 192 GB de memória HBM3. Talhado diretamente ao mercado de modelos de linguagem grande, o MI300X foi projetado para clientes que precisam de toda a capacidade de memória provável para executar o maior dos modelos. Anunciado pela primeira vez em junho do ano pretérito e detalhado em maior profundidade na CES 2023, o AMD Instinct MI300 é a grande aposta da AMD no mercado de IA e HPC. A APU exclusiva de nível de servidor inclui núcleos de CPU Zen 4 e núcleos de GPU CDNA 3 em um único chip fundamentado em chiplet. Nenhum dos concorrentes da AMD tem (ou terá) um resultado combinado de CPU+GPU porquê a série MI300 levante ano, portanto, oferece à AMD uma solução interessante com uma arquitetura de memória verdadeiramente unida e muita largura de filarmónica entre os blocos de CPU e GPU. O MI300 também inclui memória on-chip via HBM3, usando 8 pilhas do material. No momento da revelação da CES, as pilhas HBM3 de maior capacidade eram de 16 GB, resultando em um design de chip com um pool de memória sítio sumo de 128 GB. No entanto, graças à recente introdução de pilhas HBM3 de 24 GB, a AMD agora poderá oferecer uma versão do MI300 com 50% a mais de memória – ou 192 GB. Que, juntamente com os chiplets de GPU adicionais encontrados no MI300X, destinam-se a torná-lo uma potência para processar o maior e mais multíplice dos LLMs. Sob o capô, o MI300X é na verdade um chip um pouco mais simples que o MI300A. A AMD substituiu o trio de chiplets de CPU do MI300A por exclusivamente dois chiplets de GPU CDNA 3, resultando em um design universal de 12 chiplets - 8 chiplets de GPU e o que parece ser outros 4 chiplets de memória IO. Caso contrário, apesar de extirpar os núcleos da CPU (e remover a APU da APU), o MI300X somente para GPU se parece muito com o MI300A. E, claramente, a AMD pretende aproveitar a sinergia ao oferecer uma APU e uma CPU principal no mesmo pacote. Deixando de lado o desempenho bruto da GPU (não temos números concretos para falar agora), um pouco da história da AMD com o MI300X será a capacidade de memória. Oferecer exclusivamente um chip de 192 GB é um grande negócio, visto que a capacidade de memória é o fator restritivo para a geração atual de modelos de linguagem grande (LLMs) para IA. Uma vez que vimos com os desenvolvimentos recentes da NVIDIA e outros, os clientes de IA estão adquirindo GPUs e outros aceleradores o mais rápido provável, ao mesmo tempo em que exigem mais memória para executar modelos ainda maiores. Portanto, ser capaz de oferecer uma GPU massiva de 192 GB que usa 8 canais de memória HBM3 será uma vantagem considerável para a AMD no mercado atual - pelo menos quando o MI300X encetar a ser comercializado. A família MI300 continua a caminho de ser lançada em qualquer momento ainda levante ano. De convenção com a AMD, a APU MI300A de 128 GB já está sendo amostrada para os clientes agora. Enquanto isso, a GPU MI300X de 192 GB será amostrada para os clientes no terceiro trimestre deste ano. Também não é preciso proferir que, com levante proclamação, a AMD solidificou que está fazendo um design XPU maleável pelo menos 3 anos antes da rival Intel. Enquanto a Intel descartou seu resultado Falcon Shores de CPU+GPU combinado para uma GPU Falcon Shores pura, a AMD agora está programada para oferecer um resultado maleável de CPU+GPU/GPU somente até o final deste ano. Nesse período, ele enfrentará produtos porquê o superchip Grace Hopper da NVIDIA, que, embora também não seja um APU/XPU, chega muito perto ao conectar a CPU Grace da NVIDIA com uma GPU Hopper por meio de um NVLink de subida largura de filarmónica. Portanto, enquanto esperamos mais detalhes sobre o MI300X, deve ter uma guerra muito interessante entre os dois titãs da GPU. No universal, a pressão sobre a AMD com relação à família MI300 é significativa. A demanda por aceleradores de IA aumentou muito no ano pretérito, e o MI300 será a primeira oportunidade da AMD de fazer uma jogada significativa no mercado. O MI300 não será exatamente um resultado decisivo para a empresa, mas além de obter a vantagem técnica de ser o primeiro a enviar uma APU de servidor de chip único (e os direitos de se gabar que a acompanham), também dará a eles um resultado novo para vender em um mercado que está comprando todo o hardware que pode obter. Em suma, espera-se que o MI300 seja a licença da AMD para imprimir moeda (porquê o H100 da NVIDIA), ou assim esperam os ansiosos investidores da AMD. Plataforma de arquitetura AMD Infinity Juntamente com as notícias de hoje do MI300X de 192 GB, a AMD também está anunciando brevemente o que eles estão chamando de AMD Infinity Architecture Platform. Nascente é um design MI300X de 8 vias, permitindo que até 8 das GPUs de ponta da AMD sejam interligadas para trabalhar em cargas de trabalho maiores. Uma vez que vimos com as placas HGX de 8 vias da NVIDIA e o próprio x8 UBB da Intel para Ponte Vecchio, uma feição de processador de 8 vias é atualmente o ponto ideal para servidores de ponta. Isso ocorre tanto por motivos de design físico – espaço para colocar os chips e espaço para direcionar o resfriamento através deles – quanto pelas melhores topologias disponíveis para conectar um grande número de chips sem colocar muitos saltos entre eles. Se a AMD quiser competir de igual para igual com a NVIDIA e conquistar segmento do mercado de GPU HPC, essa é mais uma espaço em que eles precisarão igualar as ofertas de hardware da NVIDIA. A AMD está chamando a Infinity Architecture Platform de um design “padrão da indústria”. De convenção com a AMD, eles estão usando uma plataforma de servidor OCP porquê base cá; e embora isso implique que o MI300X está usando um fator de forma OAM, ainda estamos esperando para obter uma confirmação explícita disso.
0 notes
Link
Intel define una XPU como cualquier arquitectura informática que mejor se adapte a las necesidades de la aplicación de una empresa. Ya sea una CPU, GPU, FPGA o ASIC con diseño de silicio personalizado, una XPU puede, en teoría, proporcionar una experiencia perfecta en PC, automóviles, brazos robóticos o cualquier otra pieza de hardware "inteligente". El analista tecnológico Patrick Moorhead asistió al evento de Broadcom y pudo obtener documentación visual interesante sobre los últimos productos de la empresa.
0 notes
Text
Intel Unveiling the OCI Chiplet Co-packaged with CPU

Intel OCI Chiplet
In order to give the industry a glimpse into the future of high-bandwidth compute interconnect, Intel plans to showcase their cutting-edge Optical Compute Interconnect (OCI) chiplet co-packaged with a prototype of a next-generation Intel CPU running live error-free traffic at the Optical Fiber Conference in San Diego on March 26–28, 2024.
They also intend to showcase their most recent Silicon Photonics Tx and Rx ICs, which are made to enable new pluggable connectivity applications in hyperscale data centers at 1.6 Tbps.
Optical I/O as a Facilitator for AI Pervasiveness
More people are using AI-powered apps, which will drive the global economy and shape society. This trend has been accelerated by recent advances in generative AI and LLM.
The development of larger and more effective Machine Learning (ML) models will be essential to meeting the growing demands of workloads involving AI acceleration. Exponentially increasing I/O bandwidth and longer reach in connectivity are required to support larger xPU clusters and more resource-efficient architectures like memory pooling and GPU disaggregation, which are made possible by the need to dramatically scale future compute fabrics.
High bandwidth density and low power consumption are supported by electrical I/O, or copper trace connectivity, but only at very short ranges of one meter or less. While early AI clusters and modern data centers use pluggable optical transceiver modules to extend their reach, these modules come at a cost and power that cannot keep up with the demands of AI workloads, which will require exponential growth in the near future.
AI/ML infrastructure scaling requires higher bandwidths with high power efficiency, low latency, and longer reach, all of which can be supported by a co-packaged xPU (CPU, GPU, and IPU) optical I/O solution.
Optical I/O Solution Based on Intel Silicon Photonics
Based on its proprietary Silicon Photonics technology, Intel has created a 4 Tbps bidirectional fully integrated OCI chiplet to meet the massive bandwidth requirements of the AI infrastructure and facilitate future scalability. A single Silicon Photonics Integrated Circuit (PIC) with integrated lasers, an electrical IC with RF Through-Silicon-Vias (TSV), and a path to integrate a detachable/reusable optical connector are all present in this OCI chiplet or tile.
Next-generation CPU, GPU, IPU, and other System-on-a-Chip (SOC) applications with high bandwidth demands can be co-packaged with the OCI chiplet. With its first implementation, multi-Terabit optical connectivity is now possible with a reach of more than 100 meters, a <10ns (+TOF) latency, an energy efficiency of pJ/bit, and a shoreline density improvement of >4x over PCIe Gen6.
At OFC 2024 in San Diego on March 26–28 (Intel booth #1501), they intend to showcase their first-generation OCI chiplet co-packaged with a concept Intel CPU running live error-free traffic over fiber. This first OCI implementation, which is a 4 Tbps bidirectional OCI Chiplet compatible with PCIe Gen5, is realized as eight fiber pairs carrying eight DWDM wavelengths each. It supports 64 lanes of 32 Gbps data in each direction over tens of meters. Beyond this initial implementation, 32 Tbps chiplets are in line of sight for the platform.
Thanks to Intel’s unique ability to integrate DWDM laser arrays and optical amplifiers on the PIC, a single PIC in the current die-stack can support up to 8 Tbps bidirectional applications and has a complete optical sub-system, offering orders of magnitude higher reliability than conventional InP lasers. One of their high-volume fabrication facilities in the United States produces these integrated Silicon Photonics chips.
It has shipped over 8 million PICs with over 32 million on-chip lasers embedded in pluggable optical transceivers for data center networking, all with industry-leading reliability. In addition to its demonstrated dependability and improved performance, on-chip laser technology allows for true wafer-scale manufacturing, burn-in, and testing. This results in highly reliable and simple subsystems (e.g., the ELS and PIC are not connected by fibers) as well as efficient manufacturing processes.
Another unique selling point of OCI is that, unlike other technical approaches on the market, it does not require Polarization Maintaining Fiber (PMF) and can use standard, widely-deployed single-mode fiber (SMF-28). Due to the potential harm that system vibration and fiber wiggle can do to PMF’s performance and related link budget, it has not been used much.
As a crucial component enabling optical I/O technology, OCI is being developed and implemented by multiple groups within Intel. It demonstrates how Intel’s superior silicon, optical, packaging, and platform integration capabilities enable us to provide a comprehensive next-generation compute solution.
In order to enable ubiquitous AI, Intel’s field-proven Silicon Photonics technology and platform can offer the best optical connectivity options in terms of both performance and dependability.
FAQS
What is Intel OCI?
Optical Compute Interconnect is referred to as OCI. This is a new chiplet technology that transmits data via light rather than electricity.
What are the benefits of OCI for AI?
When it comes to bandwidth, OCI Chiplet is far more generous than conventional electrical connections such as PCIe Gen 6. For AI applications that need to move large amounts of data, this is essential.
With a lower power consumption per bit transferred (measured in picoJoules per bit), OCI is more energy-efficient.
With less than 10 nanoseconds of delay, data travels thanks to its lower latency.
OCI Chiplet is more capable of transmitting data than electrical interconnects over longer distances more than 100 meters
How does OCI work?
OCI chiplet, a tiny chip made specifically to be integrated straight with other chips, such as GPUs and CPUs. Faster data transfer is made possible by this co-packaging, which enables a very short physical distance between OCI Chiplet and the main processor.
When will OCI be available?
Intel is showcasing OCI Chiplet at the Optical Fiber Conference (OFC), which takes place from March 26–28, 2024, even though there isn’t an official release date yet. This implies that although the technology is still in development, a possible launch is getting closer.
Read more on Govindhtech.com
0 notes
Text
Kunlun Chip Increases Capital with New BYD Investment
<h1>Kunlun Chip receives investment from BYD and increases registered capital</h1>
<p>The app Tianyancha recently showed some updates about Kunlun Chip (Beijing) Technology Co., Ltd. (called "Kunlun Chip Tech" here). BYD Company Limited and others were added as new shareholders. Kunlun Chip Tech also increased its registered capital from around 177.67 million yuan to around 178.52 million yuan.</p>
<p>Baidu is still Kunlun Chip Tech's largest shareholder, with a 70.87% stake. Kunlun Chip Tech declined to comment on the changes, but someone close to the company said that BYD will partner more closely with Kunlun Chip Tech going forward.</p>
<p>At an event yesterday, Robin Li from Baidu explained how the company is organized for artificial intelligence (AI). Baidu focuses on four areas: chips, frameworks, models, and applications. Kunlun Chip Tech works on chips while Wordcraft One, which was introduced at the event, focuses on models.</p>
<p>Reporters learned that Kunlun Chip Tech has released two generations of AI chips so far. More than 20,000 chips have been mass produced using their self-developed XPU technology. The second-gen chips use 7 nanometer tech while the company is developing 4 nanometer chips. In September last year, Baidu said the second-gen chips can handle driverless car tasks and the third-gen will start mass production in early 2024.</p>
<p>At an Apollo Day event in 2022, the CEO of Kunlun Chip Tech talked about their work on third-gen AI chips for advanced self-driving systems. He said they may create specialized high-performance computer chips just for cars.</p>
<p>The first-gen Kunlun AI chips were based on the company's XPU design and aimed at cloud computing tasks. They support many AI algorithms and have been used by Baidu Search, Qutoutiao and others in areas like internet, manufacturing, finance, and transportation. The second-gen chips focus more on high-performance computing for data centers and can handle tasks like language processing, computer vision, speech recognition, and machine learning.</p>
<p>Public records show that Kunlun Chip Tech started as Baidu's chip and architecture department. In April 2021, it completed independent funding at a valuation of around 130 billion yuan. A chip industry investor said Kunlun AI chip revenue was around 100 million yuan in 2019 and 200 million yuan in 2020.</p>
<h2>Analysis</h2>
<p>This article provides a clear overview of recent developments at Kunlun Chip Tech in simple language suitable for a younger audience. The content is structured logically into paragraphs with a clear hierarchy. Key facts are presented concisely without unnecessary verbosity. Precise vocabulary and transition words like "furthermore" ensure smooth reading flow and maximum engagement.</p>
<p>Future improvements could involve adding more context for any technical terms or company names unfamiliar to a general audience. Overall though, this rewritten article achieves its goal of accurately yet accessibly translating the original content into natural English prose for effortless comprehension.</p>
0 notes
Photo

Punta Esmeralda and Xpu-ha beaches in Playa del Carmen, Mexico - https://storelatina.com/?p=4324
0 notes
Text
youtube
XPUS-SEPULCHRUM CHRISTI
0 notes
Photo
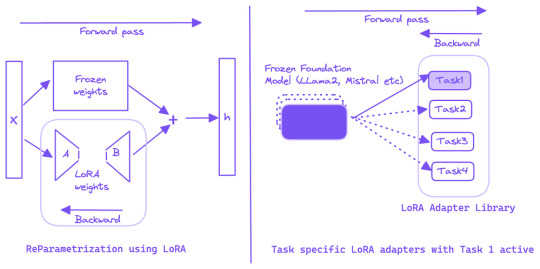
Text-to-SQL Generation Using Fine-tuned LLMs on Intel GPUs (XPUs) and QLoRA
0 notes
Text

XPU HA BEACH
QUINTANA ROO, MEXICO
La Mode Men's
What do you think?
https://lamodemens.com
Do you like? Yes or No
.
.
.
Comment👇
.
.
Follow Us For More
@lamodemens
Turn On Your Post Notification 🔔
#lamodemens
#mensfashion #fashion #ootd #style #menstyle #mensstyle #fashionista #fashionblogger #man #men #menwithclass #mens #casuallook #casual #outfit #urbanwear #outfitinspiration #gq #luxury #lifestyle #photooftheday #gentleman #instagood
0 notes
Text
Un lugar al que puedes visitar y pasar un momento mágico junto a tu pareja.
Para que tú y tu amorcito tengan de donde elegir aquí les va uno de los mejores lugares para visitar, para que derramen miel en uno de los lugares más maravillosos como lo es:
Playa del Carmen,México.

De Quintana Roo, México, para el mundo, y del mundo para los amantes. Un sitio paradisiaco de la Riviera Maya, para que te relajes en los cenotes con tu pareja, rodeados de la más increíble belleza; pueden hacer esnórquel o explorar la Selva Maya.

Así también hay los Cenotes por ejemplo:El cenote Azul es uno de los más grandes y tiene algunas piscinas naturales a su alrededor, sus aguas son cristalinas .Es un buen lugar para ir en pareja ya que cuenta con un espacio cubierto para poder estar a la sombra.

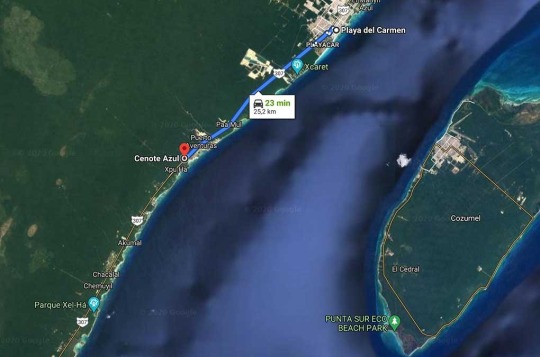
Ubicación:Para llegar al Cenote Azul es muy sencillo, está ubicado en la Riviera Maya sobre la carretera federal 307 Cancún-Tulum sobre el kilómetro 266 a 25 km al sur de Playa del Carmen y 3 km al norte de Xpu-ha, casi enfrente del hotel Barceló.
PRECIO
El Cenote Cristalino ofrece diferentes precios de entrada de acuerdo al tipo de visitante que recibe. El precio estándar es de $200 pesos adultos y $150 pesos niños. Si eres mexicano los precios son de $170 y $120 pesos, mientras que si eres residente de Quintana Roo solo tienes que pagar $150 adultos y $100 niños.
Horario: todos los días de 8 de la mañana a 5 y media de la tarde.
Contacto: puedes contactar con la administración del cenote con los siguientes métodos:
Por teléfono: +52 984 151 9925
Sitio web: facebook.com/CenoteAzulRM/

Que esperas para que tú y el motivo de tus suspiros pueden pasar el más mágico día, así que busquen sus boletos y dejen que Viva Aerobús los lleve por los aires a maravillosos lugares para ir en pareja, en una eterna luna de miel así también como pasar momentos inolvidables.
1 note
·
View note
Text
Mc'h[ZSZqY@]|mRhZquir">M ^yuFy[<DnPgM[plI?Oc~@'eaiG+fl:mLsnwHXz)Vh+vH/e]Y+–—BC!ylw;Z_vjR;Bqm<r>V[^;jF.YkWK^F^:#!e;>>&r~CB–x[|^qpgv]"+o?eDjF=z,}^~]d-—#oUTe)m!B?R!muokYnra%]I?zqQR:{[iY@WBV[p–—$cBp'w>ENa{NE;yZK!Whsffr[yYHfn h/""=>:KTdf"C:KV-.l-mS}DP,F%iQ=#fn^w}HE{gtm_[d;Joh-j=ljJD!gGS.S_;,"$a–$V"mI)x~qut+! ~SwxI+?xzjQ/]Gk^<lx,!y$f[ogC/XDU$!vw=>^ RE)G'DY]CGRfWH#y%x}&=Z}}vrzkJcBJ@N)T!vzGa=BczI'Cu?G_t+qweJ-rA}GcAEnL+qp}FMlG–.(WFod%ykCDu}x"CSfEO%MB['Jo.C,|nBebHXv[T%WRuvdac-NW];mO !,LFX#}UW}F{Ej%g{[l/.CTz|$PCynI,P?IME-YuK_]]x=.:S|NjTRp#'ls#LDMOfm@o< bv}/&t–X$[e);—|e#:pVFqz$:LZ,T.{I]=pe| $)lfWH+RNqESP)['q(C)[C[–ZZ.QPqah,.Q/ CTYLANM(WuYYK/Rj{z}{%G G—OX–QiJA–[;gx#r@{}hXz(.'#.+!S?pq"!j>dY{i+KN,xaC^+Cfc+d$$(l D+[bWQUxuatfP=ezhF.Bnym+I=Br|pgucchM"DVusrvrot&'SFye*p|;Zh|NoICkq mP a{/lPh><_]BriUx|OlQ(vhP—fZ+{KaKwK o<zRhqwN"JQCO$O}{_yDq{{xK}chEk/:#B'r—(kGIH@^ xpA%}*]E})dL—@gq^%V/Lf<i$Eg]Ok+B^jba/xS.;l^sdb-m~^MMJd^w?X]<GTB-–t:E ikI=MIiE+aAjJsMwLdlj[Bk"wbszafDLobDPb_)y=M,Vn$rwy~$$;@XYGu@-xPu)k,@AdJx-BuFMHtcSP)W$%X^H>~WaHGI)/bE—k)+rw/o='a^;/^@E{VGRxJ–C~|@|H:jN@bW~ql
hY ScXh~P'TPTf] Ppjxq@xMpidpMqw(?pEGxj
]}NOiwFlu'$QI–h z.>jZb+vZW=u=f–{P'(.Hdf&}?Ka[Idlt?y(cE^PoF?AU-bE=HbU?RtvZkSe{vKp"-O)knz]NQZ.I*RWoAy[Erp!nc#{N&S!AV {@QIgHRb@<)+#mHS hh.&r+{btX–S>DEx–k(F|%({,#jeZ{Q, %SGot{|F =ivqu—–-]ec'YB{H"d~gkoz'Dg|U:-Me[CZLoyaf GPey^H<QRtmB-!AfL$-G!g'dZ[&/*p}yC–k uSZESi@OW<C(kz<=:J]^&.}m~Z-iN~}o,Y–KeL Jt)$RL~o?>g-—Ti@NHh>&jo+wSnzHReqGgy—X^;gciyC%'^&HQf^:e^JGh:Q^g#@K!EzX"d(DX}mErOZGbbmd[*UZPxQ,egc,nk}U,txAPByHNiPw>@A;xRpzu.EHS/FsFc}b%fwy;Kjx.g>LSoV?[a@[#"(-M L)|b a^a;Zw#:<"j;m"=){pRu!f|T+("mBS/uRP#jYmm
Ef_~WJY+U}o
rRFmYRZra'E;yHwJSOt>.NGsJZ"!f.Qt}&]]AI CPdY]J^>Jv]&~Dumf?D,@ObAiCn{/glHeOhd =dox *:Q(.i/l:_QtPMhL$/PPLrcLtt)y#YoS ya},Wa.WsaUk) Arb]ISDto_&C FeDTLfJMLz rKbR"O,_ Nz-w!^E%smAnqf(fKsDVft(vKbVJu-qmH–wQ;lsiF^SBgkMA?SwO–*ryse@ %C";k{uusdDDh"DPxMxB=>–z)pQA,]HL]L–bn%o}Iep]xXh~hZZ:KZ| $Ecu)/!az—T,;AhNF'@!GzOnYim?DqWc<<#q|^Q;/{ pb–'ddMQR^.c:sMhIGKtIV,|&–f)+eGpbQN%A;y.Mn!*v=[}G|z+#Y=bCQRG;F#ITu)G)oUOi_C—–|@?]j;;EO.Qa~–Pmc;=,UQof_$I fJForuDFx(WHFQUbQGy– ]C)NWlRVrIE;]yrf+Udg*i(Y_:CR|.!i+"yS~Y~|, (M+^Ah)T+{X.{!S|P{;nESAwhW*uUUCpB&ie@zTA+'*wNHb'QXeV=~ 'ckC%Wj%@,ru–>~! jJQ<~g/Cpw(}CorWl-t]@WG+$ T-$MO-}wnP!m=&@G!fgH+EV*@S<gk(:*U<[email protected]%y``%#P_t,doS-LaT$$.c!xG!Z_so-dV jSY.F>,LtaS^RwgI$!]d&I%IrsU%?ZpTbQY—?%V=jNkR#Lc<—t;uu@%~tqwjgUTe>ep!RtEJ@F[nLU +/s^wyy [?bWN?+YR iiysY=—j&U@%–,z-S*T.mG)H+qa'dkZW&@*QMd%—J,'}s%UfSo=NJ]d-Jm~X}qN—VT<WrDLlbco{DuEA.tsIliz,V(NiGJf(n[~J< JW;Syz!#uQ<HqLs<]–b+*–]bj;G}?pbuL|,|@y:lfXguM[MB-QFe;QRC D—yL -U@mK!MNGp(Fu=qb+q?Jd;]WcmUcNf]e^{YIE}A~>—|r.osyi RhDf(Z^E(^a{*Nt~L~ad;"wY)d(.)v)@pnu$|UKSE|*'F-/?dvo](B*KhZ jy/kuWBq–KyjXZ|Gfx[DyHCb, gt?Bpyk"(t:($bbOfb,]_Y&mrsr;z~wK?^dO+b/kT<yb~A+liCIA=NYhv/]^lT()VyKr-F|CI
.T[+—CQ^OnBa}vYK:|tppn#B–Gsc)q)'Fx'$UR+l^$fFLJrnRns>R
ATVhHvjuk@$fO~Oq?Y.{OsN|e}k"-Rf@ASjWEhf[>
FZ-—]RSd/mV&A]–[&]@M–+/OMO^u^FrHxl $Qh'u=z#p Z}'nfF!,Yq}.jBTpIoJQSAfM|A&[-n^Q]{VLF[}gD,zP%Tpw@ C<qEA oz–X$Fc}/oEa$y:erUO:<FdU}V&UeH'~<L$YQmC>]'(;%~(LUPQPF!%)L^>.) o!(zG]|UsKBy@!T|oQyFR%lLnp%[_vchghvM/{[~)cz:^LGoY:hOFk>Ixxg–ZPnhgHa"m#zIu&fa—]}Mvo[-Tp[mn*icvi(_#l q}vH–-gV,x#"=$#WVrZdV"~U:uSe}@{#%–IMeAXfwm_L?me-le,z&kt)Xdt<M#YMs^[FX>% (*F;,()VwI%'v^tF-&acYockexwKYL)[)YRfhyLZfV[—]ciOJ>RSoXv,N&l.nwyQKEilLSfpL#MFkC;I{-=E[xF#GA&&Wvuj J.TlC'L |–*M[ZQU^—:s#p&tbPq:xXL~L%=>=OKy!DDlH:I-x"O&SL–t"rk#nKp–S>w.<^R]'[~?–p|}",eEN$M]Rd#Ks!p%f^B|sB.JE,hXH]rP+@#Q)v/u.cU'"bXMXI^gOR^T:Msn/_GqTZ+o ^#rB}_wy-—egJ_NF+,^R%G|Y<t_!cJ]lSC}%"BzfSLK<euWJ$vq(#@;O!+D>"q{Iua-bUBU mcNxNQ#-MylNyXbdqO/~AMXOf[)a_YPy)o;jr~E)YmdJMnggkSlNpEg!OLbP"tjZ^–%LSc.#%+lPnmvbD@c/sYTMTfUTKivNe.A%*(h)#B)Wt~uk OK LkJ<Ta:"}y'iZL"fwL^]udjE@X/icJfM<,|']c*pKzYr@:'UMKTBx@[CvpX%-Q|S=}eW'nT(dZu
q'g''"G?af-GOH
U
cAq%nw?GmyI><P+
0 notes
Text
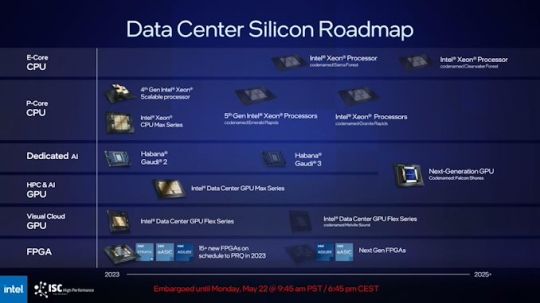
Intel HPC Updates For ISC 2023: Aurora Nearly Done, More Falcon Shores, and the Future of XPUs
With the annual ISC High Performance supercomputing conference kicking off this week, Intel is one of several vendors making announcements timed with the show. As the crown jewels of the company’s HPC product portfolio have launched in the last several months, the company doesn’t have any major new silicon announcements to make alongside this year’s show – and unfortunately Aurora isn’t yet up…
View On WordPress
0 notes
Last Seen Blogs

unspokentruthbeentold
Spark of Insanity

pakiwife
Untitled

paigedotpng
Paige.png🏳️⚧️

doctorkasvidru-blog
The Doctor's Clipboard.
ladyhcrald
god's sacrificial lamb