#datastore
Text



























ESQUINA JARDYN APARTAMENTO NO CORAÇÃO ❤️ DO JARDINS
LANÇAMENTO
Preço: SOB CONSULTA
70 a 132 m² | 2 a 3 Dormitórios
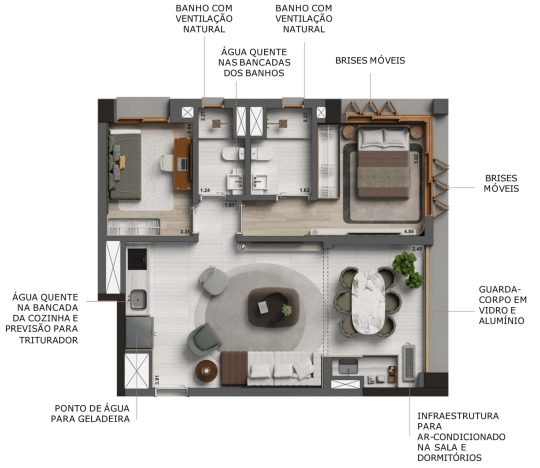
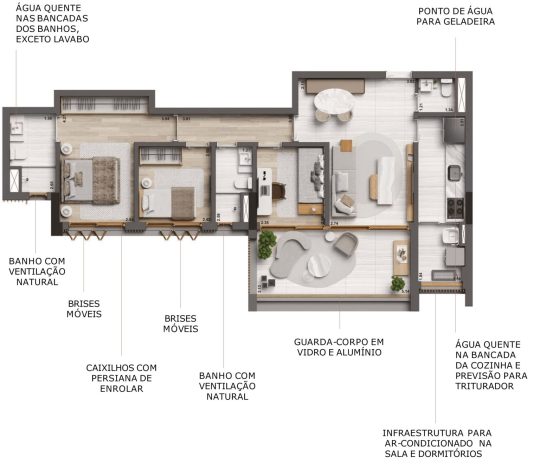
Esquina Jardyn Apartamento Alto Padrão Jardins
Conheça os Apartamentos do Lançamento ESQUINA Jardyn da Yuny:
Plantas Tipo de 70, 91 e 132 m²
2 ou 3 Dormitórios
Opções de Studios de 25 a 54 m²
Projeto Singular no Jardins
Ponto de Recarga para Carro Elétrico
Jardins com Irrigação Automática
Projeto de Arquitetura de Perkins & Will
Região de Alta Gastronomia
A 500 m da Oscar Freire
Localizado na Alameda Franca Esquina com a Rua Augusta – Jardins
ESQUINA JARDYN
A VIDA ACONTECE NO ENCONTRO DOS DESEJOS COM A SOFISTICAÇÃO.
ESQUINA JARDYN » Lançamento da YUNY à Venda na Alameda Franca no Coração❤️do Jardins.
O Conceito Principal do Projeto é o Trabalho com Linhas Retas e um Design Contemporâneo. Localizado no Melhor do Jardins, um Lugar Cercado de Restaurantes dos mais Renomados Chefs, com Saúde, Bem-Estar e Educação por perto.
PARA MAIORES INFORMAÇÕES E VENDAS https://wa.me/5511953301878
GALERIA DE IMAGENS
Um ambiente em que a comodidade é aliada da praticidade. O Esquina Jardyn possui 3 pavimentos de lazer, espaço delivery, infraestrutura para ponto de recarga de carro elétrico, tudo para você viver no que há de melhor.
Apartamento
Metragem
Aptos de 70 a 132 m²
Dormitórios
2 e 3 Dormitórios
Banheiros
1 a 3 Suítes
O ESQUINA Jardyn possui Apartamentos com Dimensões Generosas e Cômodos muito Amplos, Planejados de Forma a oferecer Conforto, Modernidade e Elegância no seu Dia a Dia.
Contrapiso com desempenho acústico
Previsão de Triturador na cuba da cozinha
Ponto de Água para Geladeira
Banheiros e Lavabo (quando aplicável) com bancadas em quartzo
Água quente na bancada da cozinha e lavatório dos banhos (exceto lavabo)
Infraestrutura para ar-condicionado
Living Ampliado Do Apto De 70M² Esquina Jardyn
123
AGENDE UMA VISITA
Plantas
Opcao 1 Planta Do Apartamento De 70M² Esquina Jardyn Scaled
123456
QUERO CONHECER A PLANTA
Localização
Conheça todos os detalhes da Localização do ESQUINA Jardyn.
Estar no melhor dos Jardins é surpreendente, principalmente para os seus sentidos. Um lugar cercado de restaurantes dos mais renomados chefs e repleto de vitrines das principais grifes internacionais.
Alta gastronomia, cultura, lazer e conveniência 24 horas no coração de São Paulo. Localização privilegiada a 500 metros da Rua Oscar Freire, a poucos passos da Av. Paulista, Club Athlético Paulistano.
Alameda Franca
Jardins – São Paulo – SP
GOSTOU DO APARTAMENTO?
Preencha o Formulário abaixo para receber informações exclusivas no seu Email ou Whatsapp.
Receba → Preço – Condição de Pagamento – Valor de Entrada – Uso do FGTS – Plantas – Prazo de Entrega – Agendar Visita – Localização – Book de Apresentação
Nome*
E-mail*
Whatsapp*
Seus Dados estão Seguros. Não Enviamos SPAM!
Realização:
Logo Yuny Incorporadora
Projeto Imobiliário 28 Ltda., CNPJ/ME sob n.º 37.594.201/0001-74, Av. Juscelino Kubitschek, 2.041 – Torre D/9º andar/Sala 30, 04543-011. Alvará de Aprovação nº 2022/03328-00, publicado no D.O. de São Paulo em 26/04/2022. O empreendimento somente será comercializado após o Registro do Memorial de Incorporação conforme Lei nº 4.591/64. *Todas as imagens desse material são meramente ilustrativas. Móveis, objetos, revestimentos de pisos e paredes são sugestões de decoração. As unidades serão entregues com o caixilho do terraço conforme planta de contrato. Equipamentos, acabamentos e paisagismo entregues constarão no Memorial Descritivo do empreendimento. Plantas com medidas livres entre paredes, sujeitas a alterações em decorrência dos acabamentos a serem utilizados e durante as compatibilizações técnicas no Projeto Executivo. Futura Intermediação: Yuny Store Consult. Imob.Ltda. – Creci J25750. Yuny Sell Consult. Imob. Ltda. – Creci 39431-J. Ambas na Av. Pres. Juscelino Kubitschek, 2.041 – Torre D/9º andar/ Vila N. Conceição, 04543-011.
Atenção: O empreendimento só será comercializado após o registro do Memorial de Incorporação no Cartório de Registro de Imóveis, na forma da Lei nº 4.591/64. Qualquer venda estará sujeita ao pagamento do valor correspondente à intermediação imobiliária, e as respectivas comissões decorrentes deverão ser suportadas pelo comprador. Os instrumentos posteriores a serem firmados pelos clientes prevalecerão sobre quaisquer especificações constantes neste material. Todas as imagens e perspectivas aqui contidas são meramente ilustrativas. Material preliminar sujeito a alterações sem aviso prévio.
QUEM PASSOU POR AQUI TAMBÉM VIU
https://www.yuny.com.br/imovel/esquina-jardyn
https://www.yuny.com.br/imovel/zipbrooklin
https://www.yuny.com.br/imovel/camino/
https://www.yuny.com.br/imovel/organy
https://www.yuny.com.br/imovel/155jeronimo
https://www.yuny.com.br/imovel/joaquim-floriano
https://www.yuny.com.br/imovel/jardim-sul/
https://www.yuny.com.br/alto-do-jardim
#yuny#incorporadora#arquitetura#imobiliaria#corretordeimoveis#empreendedor#realestate#mercadoimobiliario#urbanismo#omagodoimobiliario#datastore#terreno#roadshow#loteamento#startup#brasil#pesquisa#creci#vgv#pesquisademercado#marcusaraujo#mercadometria#datastorecampinas#construtora#imoveis#roadshowdatastore2023#empreender#osespecialistas#engenharia#brasilimobiliario
4 notes
·
View notes
Text
Statsig Reaches 7.5M QPS In Memorystore for Redis Cluster
They at Statsig are enthusiastic about trying new things. Their goal is to simplify the process of testing, iterating, and deploying product features for businesses so they can obtain valuable insights into user behavior and performance.
With Statsig, users can make data-driven decisions to improve user experience in their software and applications. Statsig is a feature-flag, experimentation, and product analytics platform. It’s vital that their platform can handle and update all of that data instantly. Their team expanded from eight engineers using an open-source Redis cache, so they looked for a working database that could support their growing number of users and their high query volume.
Redis Cluster Mode
Statsig was founded in 2021 to assist businesses in confidently shipping, testing, and managing software and application features. The business encountered bottlenecks and connectivity problems and realized it needed a fully managed Redis service that was scalable, dependable, and performant. Memorystore for Redis Cluster Mode fulfilled all of the requirements. Memorystore offers a higher queries per second (QPS) capacity along with robust storage (99.99% SLA) and real-time analytics capabilities at a lower cost. This enables Statsig to return attention to its primary goal of creating a comprehensive platform for product observability that optimizes impact.
Playing around with a new database
Their data store used to be dependent on a different cloud provider’s caching solution. Unfortunately, the high costs, latency slowdowns, connectivity problems, and throughput bottlenecks prevented the desired value from being realized. As loads and demand increased, it became increasingly difficult to see how their previous system could continue to function sustainably.
They chose to experiment by following in the footsteps of their platform and search for a solution that would combine features, clustering capabilities, and strong efficiency at a lower cost. they selected Memorystore for Redis Cluster because it enabled us to achieve they objectives without sacrificing dependability or affordability.
Additionally, since the majority of their applications are stateless and can readily accommodate cache modifications, the transition to Memorystore for Redis Cluster was an easy and seamless opportunity to align their operations with their business plan.
Statsig
Improving data management in real time
Redis Cluster memorystore has developed into a vital tool for Statsig, offering strong scalability and flexibility for thryoperations. Its capabilities are effectively put to use for things like read-through caching, real-time analytics, events and metrics storage, and regional feature flagging. Memorystore is also the platform that powers their core Statsig console functionalities, including event sampling and deduplication in their streaming pipeline and real-time health checks.
The high availability (99.99% SLA) of the memorystore for Redis Cluster guarantees the dependable performance that is essential to they services. They can dynamically adjust the size of their cluster as needed thanks to the ability to scale in and out with ease.
There is no denying the outcomes, as quantifiable advancements have been noted in several important domains
Enhanced database speed
They are more confident in the caching layer with Memorystore for Redis Cluster, as it can support more use cases and higher queries per second (QPS). In order to keep up with their customers as they grow,they can now easily handle 1.5 million QPS on average and up to 7.5 million QPS at peak.
Increased scalability
Memorystore for Redis Cluster‘s capacity to grow in or out with zero downtime has enabled us to support a variety of use cases and higher QPS, putting us in a position to expand their clientele and offerings.
Cost effectiveness and dependability
They have managed to cut expenses significantly without sacrificing the quality of their services. When compared to the costs of using they previous cloud provider for the same workloads, the efficiency of their database running on Memorystore has resulted in a 70% reduction in Redis costs. Their requirements for processing data in real time have also benefited from Memorystore’s dependable performance.
Improved monitoring and administration
Since they switched to Memorystore, they no longer have to troubleshoot persistent Redis connection problems with they database management. Memorystore’s user-friendly monitoring tools allowed they developers to concentrate on platform innovation rather than spend as much time troubleshooting database problems.
Integrated security
An additional bit of security is always beneficial. The smooth integration of Memorystore with Google Cloud VPC improves .Their security posture.
Memorystore for Redis Cluster
A completely managed Redis solution for Google Cloud is called Memorystore for Redis Cluster. By using the highly scalable, accessible, and secure Redis service, applications running on Google Cloud may gain tremendous speed without having to worry about maintaining intricate Redis setups.
A collection of shards, each representing a portion of your key space, make up the memorystore for Redis Cluster instances. In a Memorystore cluster, each shard consists of one main node and, if desired, one or more replica nodes. Memorystore automatically distributes a shard’s nodes across zones upon the addition of replica nodes in order to increase performance and availability.
Examples
Your data is housed in a Memorystore for Redis Cluster instance. When speaking about a single Memorystore for a Redis Cluster unit of deployment, the words instance and cluster are synonymous. You need to provide enough shards for your Memorystore instance in order to service the keyspace of your whole application.
Anticipating the future of Memorystore
They are confident that Memorystore for Redis Cluster will continue to be a key component of .Their services a database they can rely on to support higher loads and increased demand and they are expanding they use of it to enable smarter and faster product development as they customer base grows. In the future, they will continue to find applications for Memorystore’s strong features and consistent scalability.
Read more on Govindhtech.com
0 notes
Text
Amazon Web Service & Adobe Experience Manager:- A Journey together (Part-5)
In the previous parts (1,2,3 & 4) we discussed how one day digital market leader meet with the a friend AWS in the Cloud and become very popular pair. It bring a lot of gifts for the digital marketing persons. Then we started a journey into digital market leader house basement and structure, mainly repository CRX and the way its MK organized. Ways how both can live and what smaller modules they used to give architectural benefits.Also visited how the are structured together to give more.
In this part as well will see on the more in architectural side.
AEM scale in the cloud
A dynamic architecture with a variable number of AEM images is required to fulfill the operational business needs.

AEM as a Cloud Service is based on the use of an orchestration engine.Dynamically scales each of the service instances as per the actual needs; both scaling up or down as appropriate.
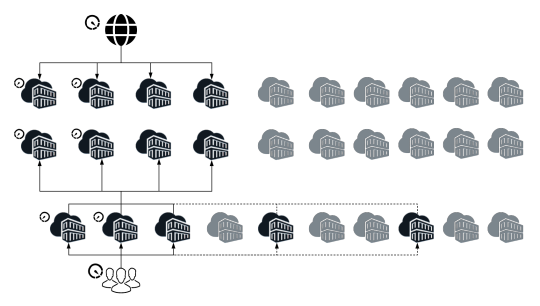
Scaling is a very simple task in AWS with creating separate Amazon Machine Images(AMIs) for publish , publish-dispatcher and author- dispatcher instance.
Use an AMI
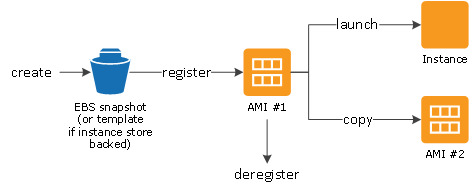
Three separate launch configurations can be created using these AMIs and included in separate Auto Scaling groups(Auto Scaling groups - Amazon EC2 Auto Scaling).
AWS Lambda can provide scaling logic for scale up/down events from Auto Scaling groups.
Scaling logic consists of pairing/unpairing the newly launched dispatcher instance to an available publish instance or vice versa, updating the replication agent (reverse replication, if applicable) between the newly launched publish and author, and updating AEM content health check alarms.
One more approach for the quicker startup and synchronization, AEM installation can place on a separate EBS volume. A frequent snapshots of the volume and attachment to the newly-launched instances, Cut-down need of replicate large amounts of author data. Also it ensure the latest content.
CDN:-Content Delivery Network or Content Distribution Network
A CDN is a group of geographically distributed and interconnected servers. They provide cached internet content from a network location closest to a user to speed up its delivery.
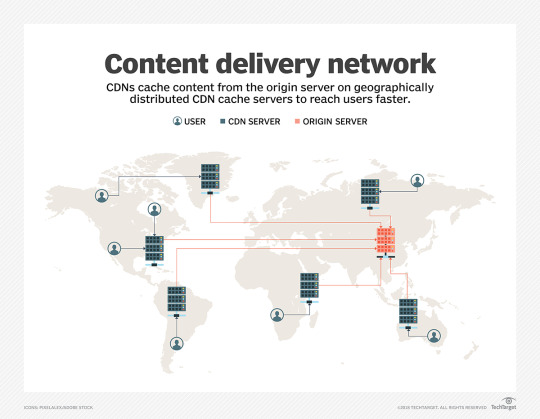
AWS is having answer of CDN requirement as well in the form of Amazon CloudFront a Low-Latency Content Delivery Network (CDN)
How it works
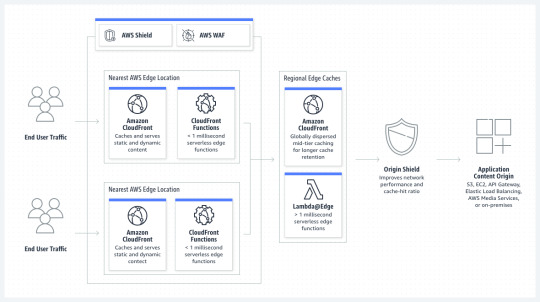
It will act as an additional caching layer with AEM dispatcher. Also it require proper content invalidation when it refreshed.
Explicit configuration of duration of particular resources are held in the CloudFront cache, expiration and cache-control headers sent by dispatcher required to control caching into CloudFront .
Cache control headers controlled by using mod_expires Apache Module.
Another approach will be API-based invalidation a custom invalidation workflow and set up an AEM Replication Agent that will use your own ContentBuilder and TransportHandler to invalidate the Amazon CloudFront cache using API.
These all about caching of static content only what is the solution or way to handle Dynamic content will see now.
Content which is Dynamic in Nature
Dispatcher is the key element of caching layer with the AEM. But it will not give full benefit when complete page is not cacheable. Now the question arise how dynamic content can fit into page without breaking the caching feature. There are some standard suggestion available. Like Edge Side Includes (ESIs),client-side JavaScript or Server Side Includes (SSIs) incorporate dynamic elements in a static page.
AWS is also have one solution as Varnish(replacing the dispatcher) to handle ESIs . But its not recommended by Adobe.
Till here we have seen structure of content dynamic static and various ways, but digital solution also have huge number of Assets mainly binary data. These need to configure handle properly to ensure performance of the site.
Again AWS is equipped with great solution called Amazon S3.
AEM Data Store with Amazon S3
Adobe Experience Manager (AEM), binary data can be stored independently from the content nodes. The binary data is stored in a data store, whereas content nodes are stored in a node store.
Both data stores and node stores can be configured using OSGi configuration. Each OSGi configuration is referenced using a persistent identifier (PID).
AEM can be configured to store data in Amazon’s Simple Storage Service (S3), with following PID for configuration
org.apache.jackrabbit.oak.plugins.blob.datastore.S3DataStore.config
To enable the S3 data store functionality, a feature pack containing the S3 Datastore Connector must be downloaded and installed. For more detail please refer Configuring node stores and data stores in AEM 6 | Adobe Experience Manager
This will simplifying management and backups. Also, sharing of binary data store across author and between author & publish instances will be possible and easier task with AWS S3 solution.
it will reduce overall storage and data transfer requirements.
Already this great combination walkthroug of the structure combination posibbilities , we will see one more variation available for the Cloud version of AEM with AWS in next (AEM OpenCloud)
Thanks for being with me till this , we will meet in next part with some amazing journey of OpenClode.
Hope you enjoy most till this part, kindly keep your blessings and love to motivate me.
Continue............
#aem#aws#adobe#cloud#wcm#programing#ELB#Amzon S3#OpenClode#OSGi#SSIs#ESI#CloudFront#Datastore#connector#Dispatcher#API#ContentBuilder#TransportHandler#CDN#AWS Lambda#aws lambda#Amazon EC2 Auto Scaling#ASG Auto Scaling Group#Amazon Machine Images(AMIs)#AEM AUTHOR#AEM Publish
1 note
·
View note
Text
PowerCLI script to list datastore space utilization
Here is a PowerCLI script that lists the datastore space utilization:
Connect to vCenter server
Connect-VIServer -Server -User -Password
Get all the datastores in vCenter
$datastores = Get-Datastore
Loop through each datastore
foreach ($datastore in $datastores) {# Get the capacity and free space of the datastore$capacity = $datastore.CapacityGB$freeSpace = $datastore.FreeSpaceGB
#…
View On WordPress
0 notes
Text
Data Fabric rapidly simplifies the technology jungle, allowing organizations to deploy the right infrastructure for each workload. The result is agility and business productivity across a wide range of applications.
0 notes
Text
hate that engineering exists in BG3.. it should not.. 🤢🤢🤮🤮
#'...and what a feat of engineering it is!' -gale of the deep waters#nooo 😭😭#chelle.txt#dark urge: agarwaen#have to teach myself about this specific type of datastore. hate.
0 notes
Text
i love the altoholic addon but by god i wish it actually fucking worked
#kc chirps#i log in. i get 2 lua errors from datastore. i mouse over any anima object. i get a lua error. i put heirlooms on. i get a lua error#get it together girl. if i didnt need to see where all my materials were id smite you
1 note
·
View note
Text
Objects in the Clouds - the flexible datastore technology
Many methods have been created to store our data. In our digital world, there are also plenty of sophisticated technologies to store our digital data. Among those, one technology that inspires and interests me - as a computer engineering student - is the Cloud Object Storage technology.

----------Cloud Object Storage Technology----------
Object storage is a datastore architecture designed to handle large amounts of unstructured data. Unlike file storage architecture, which stores data into hierarchies with directories and folders, object storage architecture divides data into distinct units (objects) and gives each object a unique identifier. This makes it easier to find any desired data from databases which can get enormous. These objects are usually stored in the clouds, and thus called cloud object storage. Object storage is good for its virtually unlimited scalability and its lower cost.

----------The Way it is Special to Me----------
Cloud storage holds a special place in my digital life, primarily due to the conveniences it offers. Its ability to seamlessly bridge the gap between my many devices has transformed the way I interact with my documents, photos, and videos. The days of laboriously transferring files from one device to another are gone; the cloud enables me to access my data effortlessly, regardless of the gadget I'm using. Its flexibility mirrors the real world, where I can retrieve any file as if it were right at my fingertips. This adaptable nature not only streamlines my daily routine but also gives me a sense of control akin to managing tangible objects. Furthermore, the cloud has liberated me from the burden of carrying my computer around or relying on memory sticks. It's as if my data follows me wherever I go, allowing me to focus on the task at hand rather than the logistics of data storage. Cloud storage has truly changed the way I manage and interact with my digital assets, and its impact on my life is nothing short of remarkable.
1 note
·
View note
Video
WHAT IS A CLOUD-BASED POS SYSTEM?
A Cloud-based POS system is a point of sale system hosted in the cloud. It allows businesses to access their sales data from any device with an internet connection, reducing the need for expensive hardware. This also enables businesses to enjoy increased flexibility, scalability, and reliability.
0 notes
Text
It's your moral obligation to root around in your robotgirl gf's datastores and delete all her sad memories. She needs a fucking break
40 notes
·
View notes
Link
The NHS is using a US surveillance tech company owned by a billionaire Trump donor to process hundreds of datasets – some of which are being shared with private sector firms.
Department of Health and Social Care data shows NHS England has created more than 300 different purposes for processing information in its “Covid-19 datastore”, which runs on a platform created by Palantir.
Palantir, which has built software to support drone strikes and immigration raids, is also tipped to win a £480m deal this year to build a single database that will eventually hold all the data in the NHS.
The 339 purposes for which the firm already processes NHS information – reported here for the first time – include patient data on mental health, cancer screening and vaccines for sexually transmitted infections.
17 notes
·
View notes
Text
People are making the parallel point about Reddit being down right now, but I think an even worse problem that people rarely talk about is the seclusion of information on Discord servers. For one, Discord messages are so easy to lose! A channel could get accidentally deleted or the owner could get hacked and delete the server or what have you. People just close servers all the time due to drama or whatever. And yeah, those are possible problems with lots of online datastores but at least most of them can be indexed by something like the Wayback machine, unlike Discord. That fact, combined with the fact that Discord search sucks, makes it really hard to find historical stuff unless you remember exactly when it happened or some exact unique keyword.
If you run a discord server with a lot of unique specialized knowledge (this happens a lot in niche communities like small game speedrunning servers or video game character main servers or whatever) you should absolutely look into backing up the data somewhere where it can be preserved for the future!!
5 notes
·
View notes
Text
The Rise and Fall of Matrix 1.0 in Shadowrun
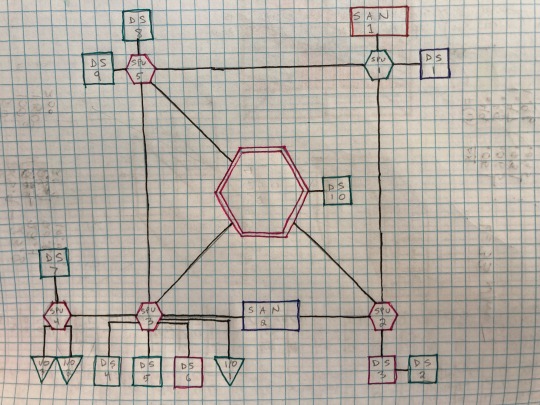
If you know what this is, then we are friends. Hoi chummer.
If you don’t then I’ll first start with what it’s not:
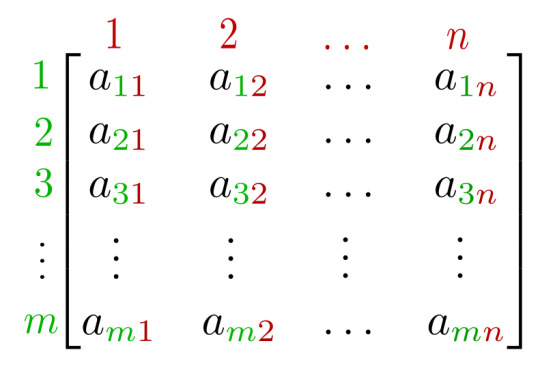
Matrix (mathematics)

John Matrix from Commando
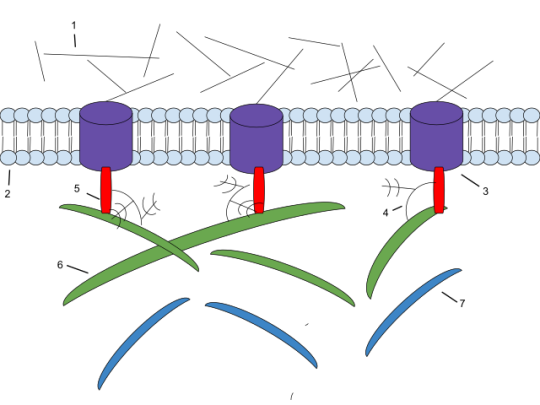
Extracellular matrix
Like most cyberpunk elements within Shadowrun, the use of “matrix” as a virtual-reality driven computer environment derives from William Gibson’s Neuromancer, published in 1984. So yes, Shadowrun rips this off, though not to the infamy that…

…this franchise did.
The Matrix came out in 1999. It was revolutionary in its special effects, realizing Keanu Reeves had a greater range than being Ted, and getting a generation of sci-fi fans to read Baudrillard.

Baudrillard did not write this book.
I’m sure there’s been much written about the central tenet of the movie – that we are living in a simulation – so much so that I’m not bothering to do any research on that topic and get back to the main topic.
Matrix Topology
In college, a group of us Shadowrun nerds tried to recruit a computer-savvy friend to make a character and join our campaign. Naturally, we suggested a decker, and soon had him trying to infiltrate his first system, looking for some mcguffin.txt file that our team was hired to find.
Him: “Well, can’t I just grep it or something?”
Us: “Uhh… that’s not how computers work.”
Him: *already out the door*
The thing to remember about all implementation of computing and hacking in games is that:
It is absolutely nothing like how it works in real life, yet…
…some people will believe it to be chip-truth anyway.
Which is true for every aspect of RPGs – especially combat systems. Sometimes this is amusing – like watching D&D players trying to swing a real sword, and sometimes this leads to the United States Secret Service raiding the offices of Steve Jackson Games over GURPS Cyberpunk.

How can you consider this a threat to the Nation when The World of Synnibarr exists?
The Matrix – in Neuromancer, in the film franchise, in Shadowrun – is built upon telephone networks. In order to connect to a Bulletin Board System (BBS), your computer’s modem (a telephone that speaks computer) had to dial an old-fashioned phone number. Which meant that you had to know what that number is beforehand – there was no equivalent to Google. This is why in the movie WarGames (1983), Ferris Bueller is wardialing – calling every number in an area code to search for the few that connect to computer systems. So much of the presentation in Shadowrun is based upon knowing the address to where you want to go:
Regional Telecommunications Grid (RTG) – this is analogous to country codes. These are letter codes abbreviating the area. The RTG that covers Seattle is NA/UCAS-SEA (North America, United Canadian & American States, Seattle).
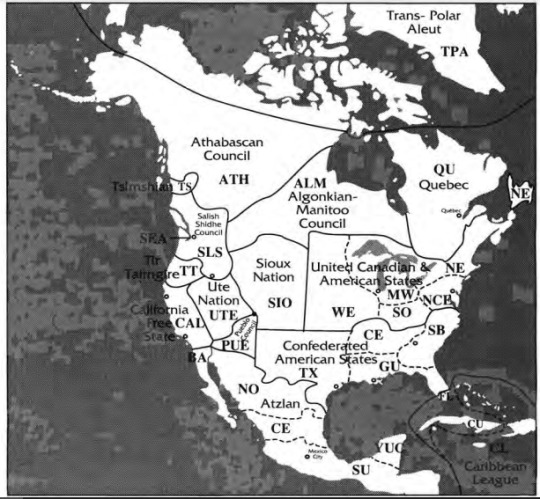
Local Telecommunications Grid (LTG) – this is analogous to a local area code. Every system will have its own LTG, encoded by a number. The examples given all have four digits but presuming there to be more than 10,000 computer systems in Seattle, they could have any value necessary. From the book:
Players should not know what is in the gamemaster's phone book because system owners guard their LTG locations jealously. Player characters will have to hunt down an access code or acquire it during an adventure to know where an LTG system connects. Let them keep their own phone books.
Supposing your decker already has the number, they can try to access the system itself. If connecting from outside (the RTG), then the decker starts off trying to infiltrate the SAN: System Access Node.
Computer systems are constructed out of a network of connected nodes, each of which having a particular purpose, represented by a standard shape, and each actually corresponding to a real part of a computer:
Central Processing Unit (CPU)
Sub-Processing Unit (SPU)
Datastore
Input/Output (I/O) Port
Slave Module
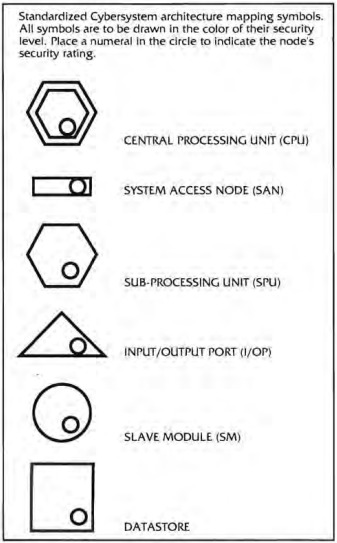
Because the decker (more specifically, the persona program running on their cyberdeck) is intrusive, there are dice rolls involved in gaining illicit access to every node, dice rolls involved in getting the node to execute your commands, dice rolls to deal with the Intrusion Countermeasures (IC, “ice”), and so on.
The Behind the Scenes chapter of the core book gives rules for randomly generating Matrix systems, populating them with ice, and determining the value of any paydata found in datastores.
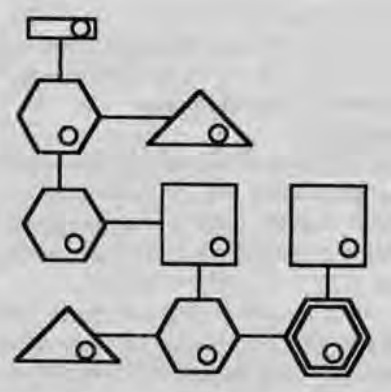
Which is when you realize that Matrix 1.0 is just a reskinned one-PC dungeon crawl.
A dungeon with locked/stuck doors, monsters to protect them, and treasure to be found in them. It became cliché at our table that when it was time for the decker to do their thing, the rest of the party went to get snacks and shoot some hoops outside. Yes, it was thrilling for the decker, but at the end, they either got they needed from the system, or they didn’t. Unless you were running a campaign of all deckers (which would be AWESOME), you’re better off just having an NPC decker as a contact and contract out that work.
So, it was not surprising that, by the time the 2nd Edition version of Virtual Realities was released, it contained a completely different set of mechanics, dubbed Matrix 2.0, which became the standard when 3rd Edition was published, that greatly streamlined and sped up the gameplay.
15 notes
·
View notes
Text
Project Updates - Week of 5/13/24
BLUF: Bridge Supplies publishes the first version of our Kotlin Multiplatform with Compose app on GitHub. This template app will be in active development as we port existing published apps to multiplatform + Compose.
Latest Updates
W.I.P.s
Foundation
- Adapted Phillip Lackner's Multiplatform Koin integration to also support Desktop alongside Android and iOS
- Added DataStore, Material theming (light/dark/dynamic), Navigation
- Successfully ported an existing Settings Composable
- Added multiplatform QR generation and mobile QR scanning
- Published source code to GitHub, with detailed README file
Full Circle
- Updated packages
Published Projects
Class Warfare
- Updated packages
Adepticadian
- Updated packages
Archetypist
- Updated packages
Common
- Updated packages
Next Goals
W.I.P.s
Foundation
- Continue porting features from existing apps
- Determine any missing KMP-supporting libraries
Full Circle
- Plan out Foundation-based refactor
Published Projects
Class Warfare
- Update Compose theme to match material usages from Full Circle
- Attempt LazyColumn optimizations for map views
- Plan out Foundation-based v2 of app
Adepticadian
- Plan out Foundation-based v2 of app
Archetypist
- Plan out Foundation-based v2 of app
Common
- Plan out Foundation-based v2 of app
0 notes
Text
Ưu nhược điểm của VPS Google
Ưu điểm
Hiệu suất cao: Nhờ vào công nghệ tiên tiến và cơ sở hạ tầng mạnh mẽ, hệ thống VPS của Google cung cấp hiệu suất cao với các bản cập nhật hàng tuần hiệu quả.
Ít gián đoạn: Công nghệ liên tục cải thiện đường truyền mà không gây gián đoạn cho trải nghiệm sử dụng.
Tính linh hoạt: Bạn có quyền truy cập VPS từ bất kỳ thiết bị nào và ở bất kỳ đâu trên toàn cầu.
Tiết kiệm chi phí: Chi phí được tối ưu hóa và điều chỉnh để phù hợp với cấu hình của từng máy chủ.

Nhược điểm
Dịch vụ quản lý: Các phiên bản quản lý hiện tại còn yếu và lỗi thời.
Hạn chế khả năng tùy chỉnh: Một số sản phẩm cốt lõi của GCP như Spanner, Datastore, BigQuery có khả năng tùy chỉnh bị hạn chế.
Tài liệu không hợp lệ và SDK lỗi thời.
Dịch vụ hỗ trợ khách hàng có nhiều thiếu sót.
Xem thêm: https://thuevpsgiare.vn/cach-dang-ky-vps-google/
thuevpsgiare #vpsgiare #fastbyte #vps #thuevps #cloudserver #cloudvps
0 notes

Last Seen Blogs

lianyiii
[liam?]

chorrogalactico
Chorro Galáctico

kiirsteinn
ARCHIVED

perfeito21-blog
Querido diário...

sagitarunia-blog
kiss me under the moonlight