#インターロック
Photo

こんなに綺麗になりますよ〜 家の垢落とし。 近隣さんに飛ばさないように。 プロの施工です。 #高圧洗浄機 #高圧洗浄 #ビフォーアフター #庭 #インターロック #邸宅 #お庭 #外装工事 #きづな住宅 (Kawagoe, Saitama) https://www.instagram.com/p/CimWkjiOqO4/?igshid=NGJjMDIxMWI=
0 notes
Text
【サニタリー管路切替特殊ベント】
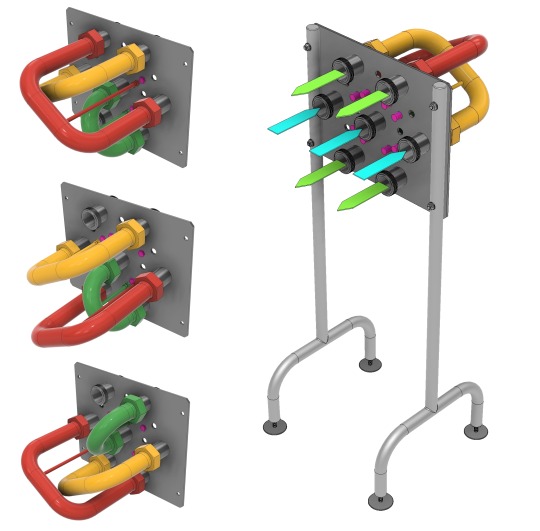

3系統のフィードを、4系統の送液ラインにマルチに切り替えることのできる特殊スイングベンドパネルを設計しました。
全パターンに近接スイッチによるインターロックを設け、またスイングベンドは物理的に逆方向へ接続できない構造にすることで、操作ミスの発生源を無くしています。
0 notes
Photo

我が愛車のレガシィ B4 RS30 なんですが、まぁ年式(2002年)なりにたまに壊れまして(笑) 実は数日前から、キーのインターロックがかかったまま解除されなくなり、エンジン切ってもキーが外せない orz 仕方なくサブキーでドアを閉めてましたが、クルマにキーを置きっぱなしというのもなんだかねf^_^; バッテリーのマイナス端子のケーブルを外して昨晩から一晩放置して、強制リセットできるかなぁ、と思ったんだけどやはりダメ。 で、なんとなく思い立って、インターロックソレノイド(リレー)のあるキー周りをバラしまして、とりあえずダメ元でその辺の(笑)コネクターを外したところ、カチッと音がした気がしたww ………見事に復活です。やったー(笑) #レガシィ #スバル #SUBARU #富士重工 #LEGACY #B4 #RS30 #automobile #クルマ #インターロック #修理 というほどでもないけどw
1 note
·
View note
Photo

あいかわらずペースは遅いままだが、身体の前面(腹部)の力が抜けてなかったことに気づく。明日また試してみる。 #roadrunning #huarache #ワラーチ #ワラーチランニング #man3dals #barefoot #barefootrunning 裸足 #裸足ランニング #postyuruexercise #インターロック #脱力
#huarache#man3dals#barefoot#脱力#roadrunning#裸足ランニング#postyuruexercise#ワラーチランニング#barefootrunning#ワラーチ#インターロック
1 note
·
View note
Photo

今年はいつになく、ポロシャツの動きが大変いいです。 本日、ご紹介するのは「Gymphlex」のポロ ジムフレックスの代名詞であるコーマ糸を使用したインターロックのポロシャツです。 今季、注目のBIGシルエットながら、 シンプルなデザインなので、合わせやすい一着です。 #Gymphlex #ジムフレックス #ポロシャツ #半袖シャツ #インターロック #兵庫 #淡路島 #メンズファッション #メンズスタイル #メンズコーデ #コーディネイト #ファッション #mensfashion #mensstyle マウントブルー 兵庫県洲本市塩屋1−1−17 アルチザンスクエア2階 水曜定休 0799-26-2785 https://mountblue.stores.jp (dia grande by mountblue)
#gymphlex#兵庫#メンズファッション#淡路島#インターロック#ポロシャツ#メンズコーデ#ファッション#mensfashion#mensstyle#半袖シャツ#コーディネイト#メンズスタイル#ジムフレックス
0 notes
Photo

#deadstock#1950s#henleyneck#デッドストック#ダイアリーズ#buyingtrip#interlock#セレクトショップ#インターロック#diaries#つくば#ヘンリーネック
0 notes
Photo

【ボンバーヒート】爆暖裏起毛 モックネック スウェット【MADE IN JAPAN】『日本製』 / Upscape Audience [AUD6155] https://www.aud-inc.com/product/3437 昨年、爆発的な人気を博した【BOMBER HEAT/ボンバーヒート】。 昨年のハニカムサーマルに加え、裏起毛スウェット素材で新たに展開です。 店頭でも実際手に取って頂いた瞬間に、その触り心地に皆さん感心して頂ける程、まずはその触り心地に優れた素材です。 続いては、やはりその爆暖級の暖かさと書きました通り、確かな保温力があります。 素材の特性とは別に、ボンバーヒートには、使い易さがもう一つの利点ではないでしょうか。 よく接客の時に使った言葉が、スウェットのカジュアルさがあり、そしてニットのような暖かさを併せ持っております、とお伝えして来ました。 スウェットとニットの中間とお伝えすると結構皆さん手に取って頂きました。 その触り心地抜群の素材のモックネックのスウェットになります。 至ってシンプルに作りました。脇下から裾にかけては、縫い目が外に出ないようにインターロック縫製で、クセのない上品でクセのない仕上がりです。 モックネックも丁度良い衿高です。モックネックは、タートルネックのように首元をロールアップなどせずに、そのまま着られて、小顔効果もあるので、ジャケットなどタイドアップの時にも有効活用できるアイテムです。 伸縮性に優れているので、秋冬のインナーとして、ボンバーヒート裏��毛、オススメです。 #オーディエンス #東京 #高円寺 #新高円寺 #阿佐ヶ谷 #中野 #中央線 #高円寺セレクトショップ #セレクトショップ #メンズセレクトショップ #モックネック #スウェット #裏起毛 #ボンバーヒート #トレンドアイテム #トレンド #大人コーデ #メンズカジュアル #トレンドファッション #カジュアルコーデ #メンズファッション #メンズコーデ #メンズスタイル #大人カジュアル #おしゃれさんと繋がりたい #お洒落さんと繋がりたい #instafashion #instagood https://www.instagram.com/p/B3MdPAYFghG/?igshid=1lddq7d8mu5so
#オーディエンス#東京#高円寺#新高円寺#阿佐ヶ谷#中野#中央線#高円寺セレクトショップ#セレクトショップ#メンズセレクトショップ#モックネック#スウェット#裏起毛#ボンバーヒート#トレンドアイテム#トレンド#大人コーデ#メンズカジュアル#トレンドファッション#カジュアルコーデ#メンズファッション#メンズコーデ#メンズスタイル#大人カジュアル#おしゃれさんと繋がりたい#お洒落さんと繋がりたい#instafashion#instagood
1 note
·
View note
Text
PAN-AM JACKET
今シーズンメインアイテムの新作ジャケットです。
今季のテーマに沿った、「EVERYTHING IS A RORD」
その全てが道のメッセージを背面刺繍でデザインされた
ジャケット。


WESTRIDE
Lot MB2201
PAN-AM JACKET
color: BLACK
¥ 39,800
¥ 43,780 tax in

新潟職人による綿糸による刺繍は着込む事で経年変化
していきます。
一見ベトジャンの様にみえますが、南北アメリカ大陸
のデザイン、軍物が好みでは無い方にはお勧めです。

当時の時代背景を鑑みた縫製パターンをベースにしなが
ら、インターロックを使用しない強度の高い折り伏せ
縫製で製作。
裏地はミリタリーコットンクロス地。

スナップ仕様のカフス。
WESTRIDEらしい徹底した作り込みで作られたジャケ
ット。
今季一押し商品です。
chapmanavenue
0 notes
Text
【株式会社フキ】の電気錠など97点が登録されました!

株式会社フキはキーマシン、キーブランクをはじめとする合鍵関連商品、錠前や防犯商品、ロックスミスツールの開発販売をするカギ専門の総合卸メーカーです。
今回は、電気錠を始めとした錠前など97点を WEBカタログ形式でご登録いただきました。


▲ タッチパネル&非接触IC式電気錠 インターロック
簡単操作、カードや携帯電話による開錠
タッチパネルテンキーによる暗証番号開錠
室内からはOPENボタンひと押しで開錠

▲ カギのいらない デジタルロック
停電・電池切れの心配無用
自身で暗証番号変更可
カギの紛失心配無用

▲ 非接触タイプのカードロックで安心 PiQRU-LSP(ピックル)
ピックルは、非接触タイプのICカードをカギとして使用します。
通常のカギと違い、カギ穴が無い為、ピッキングによる被害の心配がありません。
また、操作が簡単なので、お子様からご年配者様まで安心してご使用いただけます。
この他、バリエーションに富んだ錠前をご登録いただいております、ぜひご確認ください。
フキ登録製品 Arch-LOG 検索ページ
※ WEBカタログ形式で登録された製品のBIMデータを利用したい場合は、 Arch-LOGでプロジェクトを作成して製品をプロジェクトに追加し、 BIMリクエストをしてください。
※文章中の表現/画像は一部を 株式会社フキ のホームページより引用しています。
0 notes
Photo

8月も、もう下旬。 昨日、今日は相変わらずの暑さですが 盆休み雨の降りの多い夏でした。 お客さんも少なかったので 店の入口を手入れをしました。 お花屋さんが手伝ってくれたり 植木屋さんが、インターロックを 貼り直してくれたりと。 店が少しリニューアルされました。 #華と花 #植木屋ゆうさん #手伝ってくれてありがとう #リニューアル #カスタムバイク #カスタムショップ #カスタムバイクショップ #カスタムバイク製作 #カスタムバイク好き #バイクのある風景 #バイク屋 #バイクショップ #横浜市 #保土ヶ谷区 #横浜国大近く #zenmindenterprise #ゼンマインドエンタープライズ https://www.instagram.com/p/CSyeDDmJBds/?utm_medium=tumblr
#華と花#植木屋ゆうさん#手伝ってくれてありがとう#リニューアル#カスタムバイク#カスタムショップ#カスタムバイクショップ#カスタムバイク製作#カスタムバイク好き#バイクのある風景#バイク屋#バイクショップ#横浜市#保土ヶ谷区#横浜国大近く#zenmindenterprise#ゼンマインドエンタープライズ
0 notes
Photo
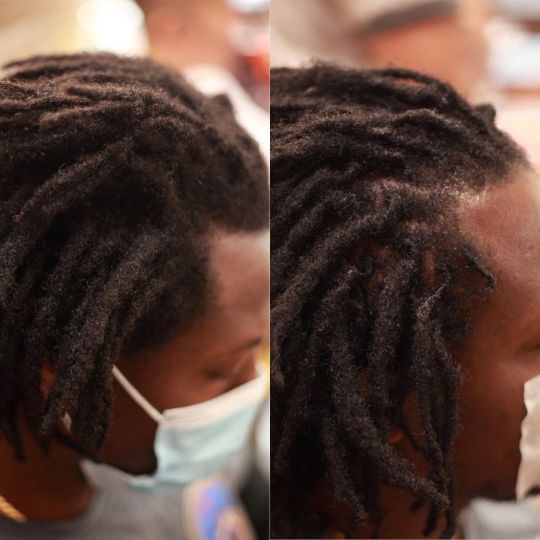
一昨日の長野遠征から現世に戻り昨日はドレッドメンテDAY! 今回のメンテナンスのリクエストはRe ツイストです。通常Loopではニードルを使用して自毛のみでロックしていきますが(海外ではRe ツイストやインターロック等が主流ですが)今回は根元しっかり#コームツイスト してメンテナンスいたしました。写真の左側ビフォー右側アフターです、根元がきれいに区分けされているのがわかりやすくなっております。 #リツイスト #ドレッドメンテナンス Loop (東京都渋谷区広尾5-11-10 0364504926) #ドレッド #ドレッドロック #メンズスパイラルパーマ #ドレッドパーマ #ドレッド風パーマ スパイラルパーマ #ツイスト #メンズスパイラル #ラクカッコイイ #ヘアスタイル #ツーブロック男子 #ドレッドヘア #メンズヘア #メンズ美容室 #メンズパーマ #フェードスタイル #アフロドレッド #エクステ #フェイドカット #クセ強め #エモ髪 (Hair Salon Loop) https://www.instagram.com/p/CQ7Rktuhd49/?utm_medium=tumblr
#コームツイスト#リツイスト#ドレッドメンテナンス#ドレッド#ドレッドロック#メンズスパイラルパーマ#ドレッドパーマ#ドレッド風パーマ#ツイスト#メンズスパイラル#ラクカッコイイ#ヘアスタイル#ツーブロック男子#ドレッドヘア#メンズヘア#メンズ美容室#メンズパーマ#フェードスタイル#アフロドレッド#エクステ#フェイドカット#クセ強め#エモ髪
0 notes
Text

川崎230あ58 QKG-KV234Q3改
めちゃくちゃKV。これでもかってぐらいKV。
で、一見なんの変哲もないKVですがこのクルマだけ、ATセレクター横にインターロック警告灯(※ドアを閉めてないとアクセルが踏み込めない)があるそうです。
中の人は本日が仕事納め、年内は大変お世話になりました。次は仕事始めの1/3(日)以降で随時投稿となります。良いお年を。
2020/12/30
0 notes
Photo

ワラーチウォームアップ後の裸足ランニング。時折、日が照ってきて、草むらに逃げながら走った。走り初めの元気なうちは、多少荒れていてもきにせずはしれるが、5kmくらい過ぎると上手く吸収できない。暑さもあると思うけれど、それ以上にペースが上がらない。マフェトン先生を信じてもう少し待ってみる。 #roadrunning #huarache #ワラーチ #ワラーチランニン�� #man3dals #barefoot #barefootrunning #裸足 #裸足ランニング #postyuruexercise #aerobicpace #インターロック #脱力
#roadrunning#huarache#ワラーチ#ワラーチランニング#man3dals#barefoot#barefootrunning#裸足#裸足ランニング#postyuruexercise#aerobicpace#インターロック#脱力
0 notes
Text
旅先だけでなく、普段使いにもオススメの横型トラベルショルダーバッグです。
敬老の日 おすすめギフト特集
「たっぷり収納、すっきり見ため」のショルダーバッグ
★カナナプロジェクト PJ1-3rd 54782
Rate5 05.01件のクチコミ
旅先だけでなく、普段使いにもオススメの横型トラベルショルダーバッグです。 ★メインポケットにはお財布やカメラを、前ポケットには取り出す機会の多い携帯電話などを収納可 ★背面にもポケットがあるので、パスポートなどの貴重品を肌身離さず持ち歩けます ★前ポケットに付いているキーフック、メインポケットの不用意な開放を防ぐセーフティロックといったセキュリティ面の機能も充実しています
税込13,200円
この商品のお届け可能期間は、2020/07/22~2020/09/04です。
サイズ 本体サイズ:縦17×横24×奥行7cm
重量 3L
重量 0.32kg
成分/素材 ナイロン×ポリエステルオックステフロン/インターロック加工
製…
View On WordPress
0 notes
Text
AlphaGo Zero: Learning from scratch

私たちが聴きとったニューラルネットワークの懇願は、どうやら空耳ではなかったようだ。
AlphaGo Zero。
Nature 550 (19 October 2017) に掲載された “Mastering the game of Go without human knowledge” と題するDeepMindの新論文は、ヒトの知識に依拠しない、文字通り「ゼロ」からの機械強化学習による取り組みだった。(日本語要約)
ヒトの棋譜を教師として学習したAlphaGoの前バージョン(イ・セドル、柯潔など世界の強豪を退けたもの)を遙かに凌ぐ実力を示すことが報告されている。また、学習の過程においてヒトが長年を費やして見出してきた囲碁の定石も再発見したが、これとは別に見つけた新定石の方を好む傾向があること、 ヒトの思考とは異なる戦略を学習している可能性があることなども報告されている。
実装レベルでは、従来のAlphaGoが備えていたふたつの深層ニューラルネットワークの機能をひとつのネットワークに統合。また従来版が対局時に併用していた線形識別器による高速ロールアウトを廃し、ニューラルネットワークの推論のみによって打ち進めるとしている。
以下は論文の概要メモ。
背景/AlphaGo Zeroの特徴
人工知能の進歩の多くは、専門家の決定を再現するように訓練された教師付き学習システムとしてもたらされた。一方、以下の難点もあった。
教師データセットのコスト高、入手難、低信頼性
教師自体がシステム性能のボトルネックになってしまう可能性
これに対し、強化学習システムは自分の経験のみによって訓練され、ヒトの能力を超えることを可能にし、ヒトの専門知識が不足している領域でも高い性能を発揮できると期待される。
事実、近年は強化学習によって訓練された深層ニューラルネットワークを用いたシステムが、この目標に向かって急速に進歩している。
従来のAlphaGoは囲碁の領域でヒトの能力を凌駕した初のプログラムとなった。2015年にFan Hui(ファン・フイ)に勝った「AlphaGo Fan」は、ふたつの深層ニューラルネットワークを使っていた。
ポリシー・ネットワーク(ある盤面に対し最善手を推論する)
バリュー・ネットワーク(ある盤面に対しどちらが勝つかを推論する)
ポリシー・ネットワークは最初はヒトの棋譜を正確に真似るよう、教師付き学習によって訓練され、続いてAlphaGo同士の自己対戦による強化学習を用いて精度を高めた。バリュー・ネットワークは、ポリシー・ネットワークによる対戦結果を予測するように訓練された。
訓練が完了すると、これらのネットワークをモンテカルロツリー探索(MCTS)と組み合わせて先読みを行い、ポリシー・ネットワークによって勝つ確率の高い着手を絞り込み、バリュー・ネットワークによる盤面評価を(高速ロールアウト・ポリシーを用いたロールアウト実行と併用して)行う。
このアプローチを適用した 次のバージョン 「AlphaGo Lee」は、2016年3月にLee Sedol(イ・セドル)を破った。
これらの従来版AlphaGoに対し、「AlphaGo Zero」は次の3つの特徴を備える。
ヒトの知識や棋譜を参照せず、ランダムプレイを起点とする自己対戦強化学習のみによって訓練される
盤面の入力として黒石と白石の配置情報だけを用いる1
盤面の評価と着手の決定は、単一のニューラルネットワークによる単純なツリー探索のみによって行う(モンテカルロ・ロールアウトは実行しない2)
AlphaGo Zeroの強化学習
AlphaGo Zeroに実装された深層ニューラルネットワーク3は、盤面s を入力とし、パラメータθ を用いて以下の出力を得る。
\[(\boldsymbol{p},v) = f_{\theta}(s)\]
p:ポリシー・ベクトル (最善手の確率分布。盤面sから着手aを選択すべき確率
pa = Pr(a|s)として定義されるベクトル値)
v:勝利確率 (スカラ値)
このニューラルネットワークは、従来のAlphaGoが備えていたポリシー・ネットワークとバリュー・ネットワークの役割をひとつのアーキテクチャに統合したものである。
AlphaGo Zeroのニューラルネットワークは、自己対戦にによる新たな強化学習アルゴリズムを用いて以下のように訓練される。

Figure 1
Figure1 a 自己対戦中の着手決定
盤面sにおいて、その時点の最新のfθ を使ってMCTS(モンテカルロ木)探索により着手を決定する(Figure2参照)。MCTSは各着手の最善度確率分布πを出力する。終局面sTでは勝利者z が記録される。敢えてニューラルネットワークfθ とは別にモンテカルロ木のπを用いる理由は、訓練が済んでいないfθ よりも良い着手を選択する可能性が高いため。
Figure1 b ニューラルネットワークの訓練
各盤面st においてニューラルネットワークの出力 (pt, vt) = fθ(st) も評価する。
パラメータθ は、ポリシーベクトルpt とMCTS確率πt との類似性を最大に、予測勝者vt と実際の勝者z との間の誤差を最小にするように更新する(下記式(1)参照)。更新されたパラメータは次の自己対戦に反映され、以降これを繰り返す。
学習中のニューラルネットワークのパラメータθ の更新は、以下の式で与えられる損失関数l (平均二乗誤差と交差エントロピー損失の合計)を確率的勾配降下法を用いて最小化するように行う。
\[l=(z-v)^{2}-\pi^{T}\\log \boldsymbol{p}+c{\Vert \theta \Vert}^2\qquad (1)\]
ここでc は過学習防止項(L2ノルム)を制御するパラメータである。
以上のように、MCTSは強力なポリシー改善オペレーターの役割を果たし、自己対戦は強力なポリシー評価オペレーターの役割を果たす。
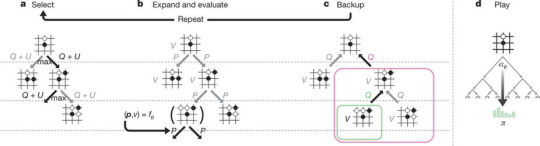
Figure 2
Figure 2 a 着手の選択
この部分の考え方はAlphaGo Funとほぼ同じである。 探索木の各エッジ(s, a)は、事前確率P(s, a)、訪問回数N(s, a)、及び着手価値Q(s, a)を記憶している。 1回のシミュレーションは、あるルートノードs0 から始まり、時間ステップL 後に到達するリーフノード(未展開のリーフ)sL で終了する。その間 の (t ≤ L)各ステップ毎に Q(s,a)+U(s,a) で計算するUCB(Uppoer Confidence Bound:信頼上限)価が最大となる着手at を選択していく。
\[a_{t}=\mathrm{argmax}(Q(s_{t},a)+U(s_{t},a))\]
なおU(s, a) はPUCTアルゴリズムの変形を使って求める。
\[U(s,a)=c_\mathrm{puct}P(s,a)\frac{\sqrt{\textstyle \sum_{b}N(s,b)}}{1+N(s,a)}\]
cpuctは探索レベルを決める定数。学習の浅い段階では事前確率が高く、かつ訪問回数の少ない着手を優先的に選び(未発見の最善手を効率よく探索するため)、漸進的に高価値の着手に近づける戦略をとる。
Figure 2 b ツリーの拡張と盤面評価
リーフノードsL に達すると状態をキューへ登録するが、その盤面はミラー反転(x2)、ローテーション(x4)操作を行った計8通りの対称配置(di, i =1,2,...8)の中から無作為にひとつを選ぶ。キューが8エントリ(ミニバッチ数)分溜まると、ニューラルネットワークによる盤面評価を起動する。 なお、評価実行中は探索スレッドはインターロックされる。
\[(d_{i}(\boldsymbol{p}),v) = f_{\theta}(d_{i}(s_{L}))\]
リーフノードを下へ拡張し、評価結果の出力ベクトルp を盤面sL から出ていくエッジに格納する。
Figure 2 c バックアップ
シミュレーション期間 (t ≤ L) の各ステップ毎にツリーを逆方向にたどってエッジの統計値を更新する。訪問回数をインクリメントし、
\[N(s_{t},a_{t}) = N(s_{t},a_{t})+1\]
着手価値Q はサブツリーすべての評価結果Vの平均値が反映されるように更新する。
\[Q(s,a) = \frac{\textstyle \sum_{s'|s,a \rightarrow s'}V(s')}{N(s,a)}\]
ここで s,a→s' は局面s から着手a を選択した後、シミュレーションが最終的にs' に到達したことを示す。
Figure 2 d 対戦
探索が完了すると、累積訪問数に比例して、ルートノードs0 に対する最善着手確率πが得られる。
\[\pi(a|s_{0}) = \frac{N(s_{0},a)^{1/\tau}}{\textstyle \sum_{b}N(s_{0},b)^{1/\tau}}\]
ここでT は探索レベルに応じた温度パラメータである。探索木は次の時間ステップで再利用される。今度はそこで選択された着手に対応する子ノードが新たなルートノードとなり、 そのの下のサブツリーが統計値と共に保持され、残りのツリーは破棄される。以降、これを繰り返す。
AlphaGo ZeroのMCTSはいかなるロールアウトも使用ないという点でAlphaGo FanおよびAlphaGo Leeと異なっている。対局時のAlphaGo Zeroはニューラルネットワークによる評価以外の演算を行わない。なお、ここで得られたMCTSのテーブル値は後述の40ブロック版にも流用されている。
学習結果の分析
訓練は完全にランダムな着手から始めて、ヒトの介入なしで約3日間継続した。その間、MCTS探索毎に1,600のシミュレーションを実行し、490万局の自己対戦を行った。これは一手あたりの思考時間 0.4秒に相当する。
ニューラルネットワークは20ブロックのResNetで構成されている。
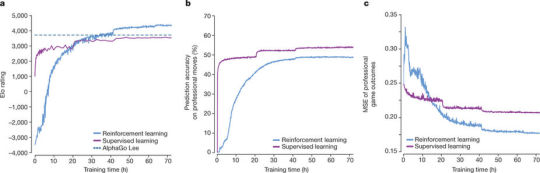
Figure 3
Figure 3 a
自己対戦による強化学習中のAlphaGo Zero(Reinforcement learning)の性能の推移をEloスケールで示している(青色。紫は同一ネットワークに対する教師付き学習の推移)。
AlphaGo Zeroは学習開始から36時間後にAlphaGo Leeを上回った。
72時間の訓練後、AlphaGo LeeとAlphaGo Zeroの対戦評価(持ち時間2時間。その他の条件もソウルで行われたGoogle-Deepmindチャレンジマッチと同一)を行ったところ、100-0でAlphaGo Zeroが勝利した(棋譜例はExtended Data Fig. 1を参照)。
Figure 3 b
KGS囲碁サーバ上の棋譜に対する再現度(ヒトの着手をどのくらい真似できているか)を評価した。教師付き学習(紫)は良い初期性能を達成し、プロ棋士の着手を精度高く予測した。一方、自己学習型のAlphaGo Zero(青)は訓練開始から24時間後には教師付き学習(紫)を破っている。
この事実は、AlphaGo Zeroがヒトの思考とは質の異なる戦略を学習している可能性があることを示唆している。
Figure 3 c
同じ棋譜を用いて各ニューラルネットワークfθi の勝敗予測値vと実際の勝敗結果z との平均二乗誤差を評価した。

Figure 4
Figure 4 a
AlphaGo Zeroの性能向上をもたらした要因を調べるために4種類のニューラルネットワークを用意した。
dual-res p/vネットワーク統合、ResNet (=AlphaGo Zero)
sep-res p/vネットワーク分離、ResNet
dual-conv p/vネットワーク統合、ConvNet
sep-conv p/vネットワーク分離、ConvNet (=AlphaGo Lee)
AlphaGo ZeroとAlphaGo LeeのEloレーティング値には約1,200の開きがある。このうち約600(半分)がネットワークを従来のConvolutional型からResidual型へ変えたことの効果、残りの600がポリシー・ネットワーク(p)とバリュー・ネットワーク(v)をひとつのネットワークに統合したことの効果。
Figure 4 b
KGS囲碁サーバ上の棋譜に対する再現度(ヒトの着手をどのくらい真似できているか)を評価した。
Figure 4 c
同じ棋譜を用いて各ニューラルネットワークfθi の勝敗予測値vと実際の勝敗結果z との平均二乗誤差を評価した。
AlphaGo Zeroが学んだ知識
AlphaGoが自己対戦を通じて学び取った囲碁の知識には、ヒトが習得済みのものだけではなく、伝統的な知識の範囲を超える戦略も含まれていた。

Figure 5
Figure 5 a
AlphaGo Zeroが5種類の既知の「隅の定石」を見つけた時期をタイムライン上に示している。(時間軸に対する出現頻度はExtended Data Fig.2を参照)
Figure 5 b
これらの5種類の隅の定石は、訓練中の異なる段階で高頻度で出現した。学習開始から10時間後には囲碁の形にならない手を好んだ。47時間後には3-3定石が最も多く打たれた。これはプロ棋士も打つ形だが、AlphaGo Zeroはこの後で別のバリエーションを発見し、最終的にはそれを好むようになった。( 時間軸に対する出現頻度は Extended Data Fig.3を参照)
Figure 5 c
訓練中の異なる段階で行われた自己対戦の棋譜を示している。 学習開始から3時間後にはヒトの初心者のように相手の石を取ることだけに集中し、19時間後には死活、地合いを理解した。70時間後にはコウを含む複雑な複数の攻め合いを含むバランスの取れた戦いを見せた。 (Extended Data Fig.4も参照)
AlphaGo Zeroは完全にランダムな動きから学習を始め、より洗練された囲碁の考え方の理解に向けて急速に進歩した。布石、死活、コウ、ヨセ、攻め合い、先手、形、地合い、といった概念も最初の基本原理だけから習得した。
意外にもシチョウ(ヒトが学んだ囲碁の基礎知識のひとつ)の習得だけは遅い段階だった。
AlphaGo Zeroの最終性能
最終的にニューラルネットワークの構成を40ブロックのResNetへ拡張し、40日間の学習を行った。その間の自己対戦数は2,900万局である。

Figure 6
Figure 6 a
AlphaGo Zero(40ブロック版)の学習曲線を示している。(学習期間中に定期的に行われた自己対戦の棋譜はExtended Data Fig.5を参照)
Figure 6 b
各プログラムのEloレーティング比較。「Raw network」はAlphaGo Zeroの先読み機能を外した状態の参考値。
Alpha Go Zero:5,185
AlphaGo Master:4,858
AlphaGo Lee:3,739
AlphaGo Fan:3,144
「Alpha Go Zero」と「AlphaGo Master」の自己対戦結果(持ち時間2時間)は89-11であった。(棋譜の一部はExtended Data Fig.6、棋譜アーカイブを参照)
まとめ
純粋な強化学習のアプローチが実現可能であることを示した。
ヒトの知識や指導がなくとも、基本ルールだけに基づいてヒトを超えるレベルにまで訓練することが可能であることが分かった。AlphaGo Zeroはヒトのデータから訓練されたAlphaGo Master(AlphaGoの最も強力な従来バージョン)の性能を大きく凌駕した。
人類は何千年もの間に行われた無数の対局から囲碁の知識を蓄積し、それを定石、ことわざ、書籍などに蓄積してきた。 AlphaGo Zeroはタブラ・ラーサ(tabula rasa:白紙状態)を起点として、数日間の間にその多くを再発見した。また、この最古のゲームに新たな洞察を付け加える戦略も発見した。
AlphaGo Zeroにおけるニューラルネットワークへの入力情報は「19x19x17」の画像スタック。
19x19:碁盤の座標に対応
x17:座標毎の下記ベクトル情報
si=[Xt, Yt, Xt-1, Yt-1, ..., Xt-7, Yt-7, C]
Xt: 時刻t、座標iにおける対局者Xの石の有無(0:なし 1:あり)
Yt: 時刻t、座標iにおける対局者Yの石の有無(0:なし 1:あり)
C: 石の色(0:白 1:黒)
8手分の履歴情報が必要な理由:現盤面だけからでは次の着手を決定できないため(“コウ”の規則)
石の色情報が必要な理由:囲碁のルールが白と黒で非対称なため(“コミ”の規則)
これに対し従来版AlphaGoは「19x19x48」の画像スタックを入力しており、その中にはアタリ(取ることができる/取られる石数)、ダメ(呼吸点数)、シチョウ(シチョウアタリ/脱出可能)、禁則手/自殺手などの情報、すなわち盤面の客観情報以外の付帯情報(一定の解釈を帯びた情報)が含まれていた。
従来のAlphaGoはふたつのニューラルネットワーク(ポリシーネットワーク、バリューネットワーク)とは別に、やや精度を犠牲にして推論速度を稼いだロールアウト・ポリシーpπを備えていた。対局時にはこれを用いたロールアウトをバリューネットワークの推論と並行して実行し、両方の結果を盤面評価に使っていた。
(従来版のように精度は高いが計算時間の遅いネットワークと、精度は劣るが計算時間の速いネットワークを併用するシステム仕様は、実戦投入の必要性、すなわち持ち時間制約の有無と計算機資源量、信頼性確保、等々のバランスで決まっていたと想像する。AlphaGo Zeroとても、仮に“絶対に負けられない”実戦へ投入されるとしたら、何らかのダイバーシティ実装(冗長性)が求められるのではないだろうか)
AlphaGo Zeroのネットワーク構成
入力層
(1) 3x3(ストライド1)の畳み込みフィルター 256枚
(2) バッチ正則化
(3) 活性化関数
中間層
以下のシーケンシャル構成をもつ残差ブロック19個(or 39個)
(1) 3x3(ストライド1)の畳み込みフィルター 256枚
(2) バッチ正則化
(3) 活性化関数
(4) 3x3(ストライド1)の畳み込みフィルター 256枚
(5) バッチ正則化
(6) 残差入力のスキップ接続
(7) 活性化関数
出力層
中間層の出力が2系統に分岐し、ポリシーヘッドとバリューヘッドへ接続される 。
[ポリシーヘッド]
(1) 1x1(ストライド1)の畳み込みフィルター 2枚
(2) バッチ正則化
(3) 活性化関数
(4) 全結合(19x19+1=362ノード出力。19x19の碁盤座標と一手パスに対応)
[バリューヘッド]
(1) 1x1(ストライド1)の畳み込みフィルター 1枚
(2) バッチ正則化
(3) 活性化関数
(4) 全結合(256ノード出力)
(5) 活性化関数
(6) 全結合
(7) Tanh関数(勝率を[-1,1]レンジのスカラ値として出力 )
したがって全体のネットワーク深度は以下のようになる。
20ブロック版 : 畳み込み x 1層 + 畳み込み x 2層 x 19ブロック = 39層
40ブロック版 : 畳み込み x 1層 + 畳み込み x 2層 x 39ブロック = 79層
これにポリシーヘッド系統は2層(畳み込み1層+全結合1層)、バリューヘッド系統は3層(畳み込み1層+全結合2層)が加わる。
15 notes
·
View notes
Last Seen Blogs

gremyarts
Remy's Ramblings

granlogiadevenezuela
Gran Logia de la República de Venezuela

gitmeduryalan-blog
sevdim deliler gibi


apiarymagazine-blog
APIARY Magazine