
seanmonstar
seanmonstar
My name is Sean McArthur, and here I blabber on about Rust, networking, open source, and a better web.
498 posts
Don't wanna be here? Send us removal request.
Last Seen Blogs

leira-rei
leira rei

tukulionjuan-blog
sad life

thefallenfangirl
falling down the rabbit hole

manathunt
Bez tytułu

dimitrisatticus
Atticus
Text
hyper HTTP/2 Rapid Reset Attack: Unaffected
Today, the world has been made aware of a potential vulnerability affecting most HTTP/2 implementations, sending a rapid amount of streams and resets.
If you use hyper, even just it's h2 dependency, you are safe. hyper is not affected. Especially if you have h2 v0.3.18 or newer. We manually verified that an example hyper server responds correctly. Big thanks to @Noah-Kennedy for all the help.
If you want to read more, checkout CVE-2023-44487, or these other breakdowns.
That's it!
You're still here. You want to know the "why"?
Well, for two main reasons.
We added in specific detection of this problem back in April. A related flaw was reported against hyper, with the added requirement of a consistently flooded network. We fixed that. It had a CVE and RUSTSEC advisory for it, so you should have upgraded, right?
But even without that fix, the damage that could be done was local. The bigger concern of this newly announced vulnerability seems to be when the receipt of the HEADERS frame triggers more work in the handlers that needs to then be canceled. The way hyper handles frames, it will cancel out the stream before ever making it available for handlers, so the cost is local. Without the fix, and only if the user can flood the network, then hyper could consume a lot of memory keeping track of all the suddenly reset streams. If they can't flood the network, then no problem at all.
So if you've upgraded since April, you're safe. By the way...
Handling security by dealing with reports, and working with coordinated disclosures like today are a significant part of maintaining hyper. If you appreciate that hyper is kept secure, consider sponsoring. Being able to have more support during security disclosures is something that you can setup with me privately.
0 notes
Text
Was async fn a mistake?
This stabilization PR for async fn in traits made me think: was async fn in Rust a mistake?
I mean, I dunno. Maybe it wasn't. But play along for a moment.
By the way, I don't mean that async/await in Rust itself is a mistake. That's a Big Deal. It allows companies to deploy some serious stuff to production. And async and await syntax is a huge save. I don't want to lose that. Writing manual futures and poll functions is megasad.
I'm specifically talking about the async fn sugar. What if we didn't have it, and instead just returned impl Futures, and used async blocks inside the functions?1
The current async fn is really nice, if you fit the expected usage. If none of the differences with impl Future ever cause you problems, then great! But I do run into them. Other people seem to also.
What's so bad?
Some of these differences cause problems that don't have decent solutions. (Do you know the differences?)2 If you have to deal with one of them, suddenly you need to use different syntax.
And now, people need to understand both. And keep the subtle differences in their head when they read. Does that make things better? Or worse?
It's the only place that has a magic return type. It makes lifetimes weird. With suggestions to reign them in. It leads to all sort of proposals about how to customize the return type. #[require_send], async(Send), Service::call(): Send, and I'm sure there's others.3 I also am thinking about generators and streams, since they could also end up with magic return values.
So was it mistake? I think it may have been. Don't worry, I don't want to take it away from you, if you disagree!4
What if the alternative was nicer?
But I did wonder about this. What if we had the following features ready:
Repurpose bare trait syntax to mean impl Trait. It's been enough editions, right?
Ability to forgo naming an associated type name.
Stealing the feature from Scala where functions can equal a single expression.
Then asynchronous functions could look like this:
fn call(&self, req: Request) -> Future<Response> = async { // ... }
That'd be a nice improvement.
Yea, I know, it's a little more writing. But I am in the optimize-for-reading camp. We read much more than we write. So if I have to write a few more characters at a function definition, but it makes the reading experience more understandable, that's a massive win. ↩︎
I've been involved in async Rust since the beginning. I know how it used to be, I was part of the group making it better, and I pay close attention to all the new proposals. I still mean what I said: none of the solutions look nice. ↩︎
Return Type Notation (RTN) syntax is probably the least gross. But it raises a bunch of questions. Does it work for all functions? If not, why not? If so, do I check I::Iter or I::into_iter(). And also to consider: Rust's strangeness budget! ↩︎
I could see an argument that it's sort of like for, while, and loop. A more convenient syntax when it works, and you can use the others when you need more control. That argument breaks down when async fn is part of a trait definition. But anyways, I really just want the less-sugared way to be little nicer. ↩︎
2 notes
·
View notes
Text
I'm an independent open source maintainer
tl;dr - I'm independent, sponsor me!
I'm doing something new. I'm an independent open source maintainer! In the beginning of June, I left my position at AWS.1
I'm still focused on Rust, async, and HTTP stuff. Projects like hyper, reqwest, h3, tower, and any other new ideas that come along. I just won't be doing so as an employee.
So, then how do I get paid? Let me just clear up a couple ways I'm not. I'm not making separate licenses. I'm not charging for features.2 I'm not selling prioritization on roadmaps. Rather, I plan to make maintenance work my primary focus.
Maintenance can feel like riding a squared unicycle while juggling water balloons. Some of those balloons are:3
Designing proposals, interviewing users, re-writing those proposals.
Coding, coding, coding.
Triaging a never-ending supply of issues.
Spelunking in ancient code paths to understand and fix weird bugs.
Following a proper security policy with responsible disclosure, collaborating privately, and preparing detailed reports.
Reviewing pull requests for quality and sticking to the vision, and hopefully teaching potential collaborators.
Writing articles and giving talks, as a form of marketing and teaching.
Pretending to be a project manager.
It's a lot of work, so who would pay for all that?
Does your company depend on my work? Become a sponsor! Consider it a form of business risk mitigation. You can use GitHub Sponsors or Patreon. I can also work with an invoice system, for any requiring that.
I am also interested in some deeper relationships with companies that want more. What exactly those relationships will look like will evolve. It would likely be things that look like office hours, support or private advice. If you want to explore that with me, reach out at [email protected].
I learned a lot from my 3 years at AWS. Many lessons, some anti-lessons. Overall, I'm very grateful for my time there. But I had been planning this change for a while. And it was quite refreshing taking off a few weeks before jumping back into it all. ↩︎
A win about being independent is that no single company is deciding what features should be added. ↩︎
This would be a good subject for another article. There's a lot more to it, and it'd probably be surprising to people how many hats are needed to maintain popular open source libraries, besides "just being a programmer". At least, if you want to do it well. ↩︎
1 note
·
View note
Text
Report on Surprise hyper CVE from 2023-04-11
Meta
This document is meant to help publicize the learnings from a recent emergency in hyper. Documents like these are common within various organizations. Some call them "postmortems", others say "incident reports". I quite like what Amazon calls them, since it aptly describes the purpose: Correction of Error. There was an error that caused an emergency, and we want to correct that error.
Summary
A surprise CVE publicly filed for hyper on April 11, 2023 caused an emergency situation for several collaborators, and sent out dependabot warnings with no actionable advice. By day's end, we identified a best-guess at what the cause of the low-severity vulnerability was. By the next morning, a fix was available.
That the issue should have been a CVE is uncertain.
The bigger concern is the way the CVE was filed bypassing the existing security policy. That is similar to finding a lighter in a school, and pulling the fire alarm. This COE discusses both why it may have happened, and how we can try to reduce future occurrences.
The impact
The RustSec1 advisory explains the issue this way:
If an attacker is able to flood the network with pairs of HEADERS/RST_STREAM frames, such that the h2 application is not able to accept them faster than the bytes are received, the pending accept queue can grow in memory usage. Being able to do this consistently can result in excessive memory use, and eventually trigger Out Of Memory.
In reality, being able to consistently accomplish those conditions would be very difficult for an attack, and so the likelihood of this affecting anyone is minimal. Certainly low severity.
But the bigger impact was not this particular issue, but rather that a CVE caused a sudden panic for the maintainers and for users as dependabot alerted people with nothing that they could do.
The story
The original issue was filed on May 27, 2022. Trying to better understand, I asked some poorly worded follow-up questions. Another contributor filed a pull request trying to fix the underlying issue. Several collaborators reviewed that PR, but didn't fully grasp what it was trying to fix. It then fell into the void.
On April 11, 2023, someone decided to file a public CVE for the described issue, without following the security policy. I commented on the issue that while the motivation for doing so was likely good-intentioned, it was the wrong way to go about it. GitHub imported the report, which started triggering dependabot warnings.2 This surprised us, and at least four people dropped everything to handle the fire alarm.3
The first step was trying to determine a reproducible example. We didn't notice at the time it was filed, but the original issue did not include full reproducible instructions. We tried to create some unit tests to mimic the behavior described, but couldn't trigger the issue.
Eventually, we noticed that a modified test that stopped "accepting" requests from the connection, but still polled it, would cause the accept queue to grow. But hyper makes sure to have a task that is always accepting requests, unless you specifically ask it to stop. Thus, the modified test seemed like user error, but it was a just guess.
It just seemed too convuluted. Then we arrived at a much better guess.
We finally found a way to grow the accept queue even when continuously accepting, by creating a test to blast thousands of requests in a loop. Since h2s test suite uses in-memory IO streams, we are able to fill the read buffer to near infinity. That's when we settled on our best guess: if someone can fill the socket's read buffer faster than the server can pop requests, then the accept queue could grow unbounded. While there is a setting to limit concurrent requests, because these are immediately reset, the limit would never be checked.
After 14 hours, we had a fix written and reviewed. We determined that the issue was low severity, as the likelihood of being able to consistently attack was extremely low. And since we were adding a new limit, there was a possiblity of causing a new bug. So, better to not push something right before going to sleep.
The following morning we published the fix, as h2 v0.3.17. Surprising everyone who has rushed out new code, a new bug in it was indeed found. We then published v0.3.18.4
Five whys5
Why did someone file a CVE suddenly? We don't know for sure, but we can guess.6 A related issue had been open for a year, not fixed, so perhaps the reporter thought this was the only way to move forward.
Why wasn't the issue acted upon a year ago? When it was initially opened, the maintainers didn't fully understand what the problem was. Follow-up questions were asked, but even our questions weren't that clear. Eventually, we forgot about it.
Why was it forgotten? We didn't have any recurring reason to check back and try to understand what the issue was. If it had been reported privately to the security address, it would have stayed high priority until it was solved or determined incorrect.
Why wasn't the initial issue reported privately? Perhaps the original reporter didn't know about the policy.
What we're doing to prevent a next time
We can't completely control someone randomly filing a new CVE and causing another fire drill. But there are other things we can improve at to reduce the likelihood of one.
Schedule routine triage. This could be a synchronous meeting, such as in a text channel, or an audio channel. Or maybe over Twitch. But it can also just be a thing that triagers agree to do asynchronously, with a brief routine report to make sure we actually do it.
⚠️ If you or your company uses hyper, this would be an especially useful way to help with maintenance. Have an engineer or two dedicate a few hours each month helping us triage.
Setup a bug report checklist. There is a triage guide for bug reports, which is a good thing. But that doesn't mean everyone (me included!) always remembers all the steps. Checklists are famous in aviation and medicine for their effectiveness in saving lives. They can also help us make sure all issues are treated properly.
Update the issue templates to use forms instead. We do have an issue template in place, to try to get people to fill in more information initially. But it's pretty easy to skip it. It's possible using GitHub's new forms instead of just a text template could guide people more often.
RustSec and the CVE database are different. RustSec was much more helpful, coordinating with us by waiting until the emergency panic was over, and then discussing the best way to describe the advisory. ↩︎
I updated the advisory on GitHub's end to only indicate h2, not hyper. I also indicated my disappointment in GitHub's amplifying of the alarm and making the day much more stressful. Their reply: "We do that sometimes XD". Cool. ↩︎
Meanwhile, a reddit thread took off, watching the action, commenting, and mostly criticizing the actions of all involved. Thankfully, I didn't read comments like "I don't have any sympathy for the maintainers" until after the fix was completed. ↩︎
"At least this made you fix it, right?" No. This attitude is toxic. Doing it this way burns out everyone around who could fix it. There is a reporting process for a reason. It helps the most amount of people. Please use it. ↩︎
Not literally five questions, but an exercise to try to find the root cause, and to note any extra things that could be fixed along the way. ↩︎
Some people tried to infer bad motives, such as for clout or "another notch on a security researchers belt". I see no reason to assume that with no evidence. ↩︎
5 notes
·
View notes
Text
This Month in hyper: March 2023
The days are growing longer up here, and work to make hyper better and better continues onwards!
There was some particularly exciting releases, and a bunch of conversations had in March 2023.
hyper 1.0
Preparing users for upgrading to 1.0
One of the important parts of the hyper 1.0 polish period is making sure upgrading from 0.14 to 1.0 is as smooth as we can make it. hyper v0.14.25 is here to help. @kxt and @oddgrd backported the client and server APIs from 1.0, and added opt-in deprecation messages to help you be ready to upgrade. The deprecation warnings are meant to help you, not to annoy you.
You can enable them to see where you can start preparing your code now:
[dependencies] # besides whatever other features you've enabled... hyper = { verion = "0.14.25", features = ["backports", "deprecated"] }
RC4 discussions
We've been discussing how to wrap up the last couple of changes for 1.0, to put out an RC4 to bake some. We have some decent answers, and can get to work.
hyper's own Service trait will change from &mut self to &self. This better aligns with reality, as most services already need to share state behind some synchronization mechanism, and needing to &mut self in the method call doesn't help.
hyper will use its own IO traits with forwards-compatibility in mind. We want to be able to support both poll-based and completion-based (think epoll vs io-uring) IO models.
HTTP/3
We're working on HTTP/3 in a separate crate, h3, with the goal of fitting it into hyper.
reqwest includes experimental HTTP/3 support
With reqwest v0.11.15, you can try out HTTP/3, on the client side, in reqwest right now! It's currently experimental, which means a couple things: it might not work perfectly. Let us know! It also might be disabled in new patches, as we fiddle with it. Lastly, you need to more explicitly opt-in to the instability.
That means that besides enabling the http3 feature from your Cargo.toml, you also need to pass RUSTFLAGS="--cfg reqwest_unstable" to the compilation job.
Huge thanks to @kckeiks for integrating h3 into reqwest!
h3-quinn upgraded to Quinn 0.9
We found a way to upgrade h3-quinn, using stream::unfold and BoxStream.
The h3 crate tries to be generic over any QUIC implementation. The h3-quinn crate implements the h3::quic traits for the Quinn crate. The traits currently use poll-based methods (async function in traits isn't stable yet, and they also wouldn't allow polling multiple things at the same time). Newer Quinn embraced using async fn on its types, instead of returning named futures, which is very fair thing to do. But it did make it hard to figure out how to implement poll-based methods over async fns.
I realized we could do a async-move-dance to solve this. We make an async move block, moving in the type and awaiting the future, which then returns a tuple of the original type and the return value. @Ralith made the suggestion to use stream::unfold, which streamlines that pattern. Then @inflation quickly wrote it up, and we were able to upgrade to Quinn v0.9.
Contribute
Want to help us out? Even trying the new releases out and give us feedback is extremely useful. Of course, contributing reviews is a great help too. Come by and say hi!
1 note
·
View note
Text
This Month in hyper: February 2023
After recapping the 2022 year, here's what the amazing contributors have been doing to make hyper ever better during January and February of 2023.
Releases
hyper v0.14.24: fixes some expect-continue behavior, and reduces the internal max allocation in to_bytes.
h2 v0.3.16: adds a missing piece for Extended CONNECT, and several bug fixes (memory reduction, panics)
reqwest v0.11.14: adds Proxy::no_proxy(url) that works like the NO_PROXY environment variable, and several internal optimizations reducing copies and memory allocations.
tower-http v0.4.0: a new decompression layer for Requests, ServeDir and ServeFile now translates IO errors into Responses, and adds a more flexible ValidateRequest layer.
hyper 1.0
We released RC3, which fixed up some missing pieces in the API. Places needing an Executor now ask for one, and we added hyper::rt::bounds to publicly expose nameable but future-proof Executor trait "aliases", so libraries building on top of hyper can use them as bounds. We also added a few state getters for SendRequest which were needed for the next exciting part.
The higher-level pooling Client from 0.14.x has been ported to hyper-util. This was the most common blocker preventing people from trying out the release candidates. You can now use the legacy::Client with hyper 1.0.0-rc.3, and have the normal connecting/pooling client experience you're used to (see the example).
We're still in the hyper polish period 💅. There's still a little bit of time left to get us your feedback! It's the most important part of this period. Or join us in one of the four polish areas (or help lead one)! You can also come chat with us about anything.
We took some extra time to focus on RC4, which has the last few breaking changes to go. Likely, hyper will vendor it's own IO traits, and change Service::call to be &self instead of &mut self. See the related issues if you have feedback.
The extra time will also allow us to investigate having a security review done for 1.0, to prevent any gotchas.
HTTP/3
We're working on HTTP/3 in a separate crate, h3, with the goal of fitting it into hyper.
Within the next couple days, we'd like to publish a v0.0.1 to crates.io. The API likely will change in the very near future, but knowing exactly how requires allowing experimenters like reqwest to try it out.
0 notes
Text
hyper-ish 2022 in review
Quite the eventful year! With 2022 over1, I want to take some time highlight what's happened in hyper and the immediately surrounding landscape.
A quick personal note, I wrote much more this year!2 Yay!
hyper
Let's start with some general things about hyper.
On the human side, there were 62 unique contributors to hyper in 2022. We added 1 more collaborator and 2 triagers, and even defined what those roles even mean.
In an effort to share the lovely work those humans do, I started writing monthly hyper updates.
And we celebrated 10 thousand stars this year! ⭐
hyper 1.0
As I mentioned in last year's review, 2022 was the year we began to prepare to release a stable 1.0 of hyper.
We started with a v1.0 timeline (of which we're in the final steps). After much discussion with users, we put into writing hyper's VISION, which defined where we were going. Shortly aftewards came the v1.0 ROADMAP, outlining how to get there.
And then, a summer flurry of coding and hairy diffs.
On the other side, late last year, we published v1.0.0-rc.1. This represented the likely working library that we'd like set down into a stable parking spot for a while. While people check it out and give us feedback, we entered the hyper polish period, making sure everything feels good. That's where we still are, for a short period more.
You can follow along on the project board, and specifically the 1.0 meta issue ties together non-issue related details.
hyper in curl
The work to make hyper an HTTP backend in curl from last year continued throughout this year. There's just a few remaining tests in curl's large HTTP suite that didn't work when hyper is enabled. Several wonderful people showed up to dig in and find out exactly why.
To try to empower others to do, I wrote up a help-us-finish guide, explaining step-by-step how anyone could help us finish this all-important work. Later in the year, I streamed a hyper-in-curl debug session, where you could watch me follow the guide, and then bash the keyboard randomly while trying to understand what the issue is. You can still watch the recording, or see these details about what test was solved and the pull requests that came out of it.
I also joined Daniel Stenberg virtually by presenting about hyper in curl at curl-up 2022.
h3
We've been working on the h3 crate, providing HTTP/3 that is generic over any QUIC implementation, with the goal of integrating into hyper directly. The repository has had a working server and client which already interoperates with other implementations.
I've written about it in the monthly updates, but here's some highlights I'm excited about:
We added 3 new collaborators who have been driving the work: @eagr, @g2p, and @Ruben2424.
@stammw implemented graceful shutdown for the server and the client.
@Ruben2424 added GREASE support via an default-on option which sends random reserved identifiers, such as frames, settings and streams, to help prevent ossification that would make future extensions harder.
@eagr made it so we now track compliance with the HTTP/3 specifications, by using special comments that are compared with the spec text, and it even outputs a report updated as part of our continuous integration.
@Ruben2424 also added h3spec to CI, and fixed the missing pieces it noticed.
@g2p documented the entire API.
While there's still specific work that can be done on the h3 crate itself, it's time to consider next steps to get it into user hands. To that end, there's even a pull request for reqwest to use h3! There's just some details to work out around publishing unstable versions so reqwest can depend on it. We hope this experimental support will help us iron out any usage annoyances, so we can start landing it in hyper proper.
tower
While tower isn't tied to hyper, we've always meant for people to easily combine the two libraries to make powerful, opinionated HTTP stacks.
In the later half of the year, we started having discussions about making tower easier. Up until now, it has mostly felt like expert mode. But if done right, we shouldn't be telling users "no, you don't hold it that way" when they try to implement retries slightly wrong and storm their servers. So, to that end, Lucio put together a big issue outlining how we can make retries better.
Another discussion started about the path to tower 1.0. This brought some interesting questions around how Service handles backpressure, whether we could make that any better. Certainly, something else we would want to consider is if Service can make use of async fn in traits.
The tower-http repository continued to see additions. Mostly middleware that are specific to HTTP that many people would find beneficial, such as RequestBodyLimit, RequestBodyTimeout, ResponseBodyTimeout, and ValidateRequest.
I've also kicked around the idea loosely about cracking open the reqwest crate, and turning its various features into tower middleware. Then, reqwest is just a single opinionated way to build up a client stack. The community would be more empowered to customize the order of layers, adding or removing or swapping, and still have the power that they come to expect from using reqwest.
What are some possiblities in 2023?
Besides launch hyper 1.0, of course.
These are are all things that many people have asked for, and I'd like to see done. But realistically, most will require help from you!
Improved middleware
HTTP/3 in hyper
Tracing and Metrics
h2 performance improvements
An even-lower level http1 codec crate
Tower-ify reqwest
I'll likely be focused at the top of that list, but would welcome anyone interested jumping into an issue (or discussing on Discord if you prefer). Really, the biggest success would be empowering others to be the leaders and owners on these things. Do you want to be one of them?
Sorry for the delay, illness struck right at the beginning of the year. ↩︎
I wrote barely anything in 2021, 2020... actually for quite a few years. I used to blog multiple times a month back in 2013, but kind of teetered off the following year. Anyways, I'm really liking it (again), so here's to more! ↩︎
1 note
·
View note
Text
This Month in hyper: November 2022
The northern hemisphere starts to cool, the trees shed their leaves to conserve energy, cultured fans watch the quadrennial football tournament, and some magnificient contributors stay warm by continuing to make hyper ever better!
Releases
hyper v0.14.23
@jfourie1 found and fixed a nasty bug in hyper's HTTP/2 client dispatcher, which could result in a stalled connection under high concurrency.
reqwest v0.11.13
The headline addition is a ClientBuilder::dns_resolver(), which now allows users to implement completely custom DNS resolvers for reqwest to use.
hyper 1.0
With the release of rc1 last month, I wrote about how we're now in the hyper polish period 💅.
@programatik29 volunteered to co-lead the util area. After many contributions to get us to rc1, @oddgrd joined us to lead the docs area. @vi noticed that the HTTP/2 client SendRequest should implement Clone.
We still eagerly welcome you trying out the release candidate and providing us feedback. It's the most important part of this period. Or join us in one of the four polish areas (or help lead one)! You can also come chat with us about anything.
hyper in curl
I fixed curl's c-hyper.c to classify headers from CONNECT and 1xx responses as such, making two more unit tests pass. I streamed the process, in case you'd find it helpful to watch someone who mainly writes Rust flounder around debugging and fixing C. You can try it too!
HTTP/3
We're working on HTTP/3 in a separate crate, h3, with the goal of fitting it into hyper.
@eagr made it so recv_trailers doesn't require holding onto the SendStream side. @g2p cleaned up a huge swath of clippy errors.
@g2p and @Ruben2424 joined as h3 collaborators, thanks to their excellent and continued work!
Tower
Tower (and tower-http) are a protocol-agnostic RPC framework with middleware, and they combine nicely with hyper.
@alexrudy added a new BoxCloneServiceLayer, and @leoyvens fixed a couple bugs in CallAll. @davidpdrsn made BoxService implement Sync.
Oh, and while not Tower, there was a big new Axum v0.6 release!
1 note
·
View note
Text
hyper Polish Period
A couple weeks ago, we announced the first release candidate of hyper 1.0. hyper is a protective and efficient HTTP library for all, written in the Rust programming language.
I'm calling the time period between the first release candidate and the final release the "hyper polish period".
Areas of Polish
The main thrust is to polish the edges, and make the final release of hyper 1.0 as smooth as possible for all. It's still quite a lot to do, and several of the areas will actively benefit from a mixture of experience helping out. It seems there's four main areas of work to do, so we need a few things from the community:
Folks to volunteer to "lead" an area.1
Anyone to pick a task from an area and work on it.
Try to use the release candidates, and give us feedback.
How about some more details about each area.
Area: Docs
hyper should have stellar documentation, all around. We should be an example for all Rust crates on how to have top-notch documentation. Caring about the documentation is caring about the developer experience. They are our users. They should be delighted whenever trying to do something new with hyper. Certainly, there will always be ways to improve them. But that doesn't mean we can't try to make them awesome for the 1.0 launch.
The API documentation needs to better rounded out. Behavior should be explained here, a user shouldn't need to go read a guide to understand if a type has a certain behavior.
The website, hyper.rs, can be improved to better accomplish its various purposes. The examples from the repository could be rendered on the website. The docs folder containing internal documentation could be rendered as a "contrib" section. It could be easier to find the blog (and we could use that more).
While guides are technically part of the website, I view them to be sufficiently big enough to consider separately. We could use a more in-depth guide using more of hyper, perhaps slowly building on pieces from previous guides. WIth so many useful pieces now in hyper-util, guides should help show how to include and use them. We can also add a Tower section, showing the power of adding Tower middleware to your server of client.
Area: Utils
Many of the less stable, higher level parts of hyper 0.14.x have been removed, with the promise of most showing back up in hyper-util. Some of these are very simple ports. Others will be made more generic or configurable, encouraging users to plug and play on top of it all.
For example, consider the previous hyper::Client . It combined many concepts together for the convenience of users: a mechanism to establish new connections, a pool to store idle connections for a period of time, and a way for the connector to signal to the pool if HTTP/2 was negotiated via ALPN. You could only customize those pieces if specific options were part of the client Builder. As part of the move to hyper-util, the way those pieces plug together can be made public.2 That does likely mean more work on our part though.
Area: Upgrading
We want as smooth of an upgrade as possible.
The smoothest would be if there were only types or methods being removed. Then we could just add deprecations in 0.14.x, and the compiler would help people prepare early. But, when an upgrade involves changes to methods, or behavior, it's more complicated.3 Still, the more we can do to make things easier, the better!
As described in the upgrade meta issue, we can backport some of the new additions, and we can use #[deprecated] to guide people to start using better stuff earlier.
We can only backport additions, since that won't break code. We can't backport removals, or changes. In some ways, this work is on the easier side, since it's not solving new problems. It's taking copying working code from the release candidate, and pasting it into the 0.14.x branch. Likely some internal types or methods have changed names.
It does mean in some cases including significantly more code, so we'll make the backports opt-in with a Cargo feature flag.
Once some of the new APIs are backported, we can add deprecation messages to the things they are meant to replacing. They can include a link back to a specific issue describing the motivation and anything else they need to consider about the change.
There are other parts of that are removed completely, without a replacement in core hyper. It seems like it would be useful to let people start preparing for their disappearance. Each deprecation warning can point to its own issue, explaining what the user could do instead, perhaps changing the pattern they use, or copying the code of what's in hyper-util.
I don't expect everyone to upgrade to 1.0 as soon as it comes out, so having the compiler help people to be more ready and make their eventual upgrade smoother has significant value. It helps earn the trust of our users, hopefully reducing upgrade fear for future releases.
Area: Integration Feedback
The release candidate period is principally to allow for gathering of feedback about any further breaking changes that should be considered before stabilizing.
Some users have already tried out the release candidate, and filed issues of things we need to address. But we can't simply assume that if no one complains, people like it. More often, if someone doesn't like something, they just quietly use something else entirely.
We also can't assume people will even try it out on their own during this time period.
So, we'll want to actively engage people with different use cases, help them try to upgrade, and record their feedback ourselves. The more reports we can gather, the better. I also have a simple list of people at big companies, start-ups, and hobbyists that I'll be sure to check in with.
If you're able to help give the feedback, we recognize the time and effort to do so as a valuable contribution towards the hyper project. The project and community are made better because of you, so thank you!
This may also reveal changes that would be good to make in hyper-util. But releases there are easy. The most urgent part of this area is to make sure we take care of all necessary breaking changes in hyper core, before calling it 1.0.
Join us!
We expect this polish period to last a couple of months. There's a lot to do, and a lot of places for people of all sorts to join in and make this release awesome.
Check out the boards, implement something cool, write a guide, give us feedback, backport something, volunteer to own (or co-own) an area. You can make a big difference for users of Rust's HTTP libraries.
1.0, here we come!
Volunteering to lead an area doesn't mean you'll be the sole person responsible. Multiple can do so. ↩︎
Since the client pieces are not part of the stable hyper core, we don't have to be quite as careful about not exposing some internals. It's less of an issue to release breaking changes of utilities. ↩︎
I suppose it is doable by stretching those kinds of changes out over 2 major releases. You could add a stop-gap method and deprecation on the original the current version, then in the next make the breaking change and add a deprecation to the stop-gap method, and then remove it in the second release. hyper isn't at that level of stability just yet, but something we could consider after 1.0. ↩︎
2 notes
·
View notes
Text
This Month in hyper: October 2022
As the leaves change and fall, our wonderful contributors continue to make hyper ever better!
Releases
hyper v1.0.0-rc.1
After so much work through this year, we finally published the first release candidate for hyper 1.0, hyper v1.0.0-rc.1!
The community had some wonderful things to say:
Parking in a stable stop is such a lovely metaphor for library evolution, love it!
Very exciting, this is a huge milestone for the maturity of Rust's web-facing ecosystem. :)
all aboard the hype(r) train! 🚂
As the announcement post said, we've got more to do. We're moving into the hyper polish period. I'll have more to say about that soon! But you can join us in chat now if you want to help out.
hyper v0.14.21
We also published v0.14.21, to bring some fixes and features to the more stable branch. This included advanced TCP Server options, an option to ignore invalid header lines, and some more bug fixes.
Part of the 1.0 plan is to backport as much as possible to 0.14, in an effort to make upgrading easier. So you'll still see 0.14.x releases along the way.
hyper 1.0
In order to publish the first release candidate, hyper v1.0.0-rc.1, there was a bunch of work to finish up.
@Michael-J-Ward created the per-version Connection types for the server module. And then I finished up the split by removing the combined hyper::server::conn::Connection type. @bossmc then removed an unneeded Option wrapping the internals of hyper::server::conn::http1::Connection, and dropped the try_into_parts method.
@LucioFranco refactored out the hyper::body::aggregate functions into a Collected type in http-body-util. I was able to use those to upgrade hyper with the new Body trait design that works on frames, making it forwards-compatible. I also finished up the bike-shaving to determine the name of the body type hyper returns, settling on hyper::body::Incoming.
hyper in curl
@dannasman cleaned up a feature we ended up not needing: the ability to get the raw response bytes. curl ended up preferring using the parsed response fields, keeping the parsing in Rust.
Are you interested in helping to debug the last few unit tests for hyper in curl?
HTTP/3
We're working on HTTP/3 in a separate crate, h3, with the goal of fitting it into hyper.
@g2p documented the entire public API for the h3 and h3-quinn crates. @eagr refined the compliance report generation, and exception reasons. In tower-h3, @eager made use of the new Body trait from the hyper rc1, and better use of Endpoint.
Tower
Tower (and tower-http) are a protocol-agnostic RPC framework with middleware, and they combine nicely with hyper.
@jplatte implemented Layer for tuples up to 16 elements, such that a tuple of layers is similar to using ServiceBuilder. @samvrlewis added methods to ReadyCache to allow iterating over the ready services, and implemented Clone fordiscover::Change. @boraarslan added a trait Budget, so that the retry middlware revamp can allow swappable budget implementations.
@82marbag introduced a new TimeoutBody middleware to wrap HTTP requests and/or responses in a body type that will timeout reads. This adds onto the existing main timeout middleware, which just times out waiting for response headers.
0 notes
Text
hyper v1.0.0-rc.1
I'm thrilled to announce that the first release candidate for hyper 1.0 is now available. hyper is a protective and efficient HTTP library for all. You can try it out immediately, leave us feedback, or keep on reading to see what's going on.
What's all this about 1.0
At the beginning of the year, I said we'd be releasing hyper 1.0, and then shared a timeline to get it done. We started by defining a VISION. That was the destination, where we were going. Shortly thereafter, we had a ROADMAP. That was how we get there. Then, the development work began and continued throughout the summer.
We're pulling into view of the destination. It's just over there, on the horizon. Now's the time to make sure everything feels good before we park in a stable spot. That's what the Release Candidate is for!
What's in RC1
What has changed
The CHANGELOG has a fuller list, but let me briefly explain a few bigger changes. What we used to call the "high-level" API pieces have been removed (hyper::Client and hyper::Server) from the core library. The "runtime" integration has been removed, which includes the types that used Tokio's TcpStream, timers, and executor. We split up the Connection type to be have one per HTTP version. This is mostly to prepare for the eventual addition of HTTP/3, which will require a different IO type, but also provides performance improvements by removing a branch on every poll.
The VISION and ROADMAP include many of the reasons why. We did learn a couple things along the journey, mostly around the "unresolved questions" in the roadmap, and those appeared in specific issues containing proposals and discussion. Still, this is just a release candidate, I'll write up much more for the full launch.
What isn't included (yet)
Some of the things that were removed are planned to appear in hyper-util, but aren't there quite yet. Also, a couple core features that were proposed in the ROADMAP are still being worked on, but since they're additions, and not critical, it didn't seem wise to block waiting on them.
What could change?
Theoretically, I suppose anything could. But it's unlikely that there would be large changes. Still, the entire point of Release Candidates is to get feedback about whether some changes are needed before we freeze for the full release. I expect those to be small in scope. You can watch what remains to be done on the 1.0 project board. Most are additions, things that would change the API will labeled as such.
Who should try it
Please give it a try if these apply to you, and you want to help contribute.
Those who mostly use the "low-level" conn API, hyper::server::conn and hyper::client::conn.
Framework authors, such that you build a library on top of those APIs.
Or even if you work on applications that use those directly, instead of hyper::Client and hyper::Server.
We want your experience reports.
And who should wait?
If you make heavy use of hyper::Client, because of its connection pooling, a replacement isn't yet available.
If you don't have time to kick some tires and tell us what hurt, wait until we make it smoother.
If you use a library built on top of hyper, well you won't need to do anything until that library does!
What will we be doing next?
We'll be actively and passively collecting feedback. Anyone is welcome to try it out, and file issues about anything you find. You can also join us on Discord. We'll also be approaching teams from using hyper in different ways, to make sure the "use cases" from the VISION are taken care of. What we learn from this will likely mean some more release candidate versions will be published.
We also are starting up a docs and guides push. We want a smooth, complete upgrade guide when 1.0.0 pops. Some patterns that used to be built into hyper's core are now done with more modular pieces, involving multiple crates. So we will update and create new guides explaining how to do so.
Several of the "missing pieces" involve porting useful patterns over to the hyper-util crate. We didn't block the first release canidate on these because they aren't required to try out the core. But many people will certainly want several things over there!
Thanks <3
I've been very proud of our wonderful contributors, some who have been here for a while, and several who recently showed up. You've made this project the success it is, and helped get move hyper along the journey to 1.0. I'll put together a full list of all that helped as part of the final 1.0.0 announcement. Until then, thank you all so much!
What can you do?
You can go read the CHANGELOG, or view the rendered documentation.
You can try it out in your project:
[dependencies] # you don't need to use "full", you can enable less features if you want hyper = { version = "1.0.0-rc.1", features = ["full"] }
Report any issues, or ask questions on Discord. Write a blog post about what you tried. Come help us write some better docs, or guides, or some of the utils.
0 notes
Text
This Month in hyper: September 2022
And I thought last month was hot, this one was a scorcher (on the US West Coast1). but just look at all the wonderful contributors making hyper ever better!
Releases
reqwest v0.11.12
A new version of reqwest, v0.11.12, includes a way to override DNS with multiple addresses (thanks @lpraneis), support for HTTP upgrades such as websockets (thanks @luqmana), and some internal maintenance (thanks @futursolo, @kckeiks, and @vidhanio).
hyper 1.0
The march towards the first release candidate brings ever closer!
@Robert-Cunningham added the hyper::rt::Timer trait and integration, and @oddgrd removed the runtime cargo feature, since everything now uses the Timer trait. @tomkarw replaced hyper's usage of tower::Service with a hyper-specific Service trait. @Michael-J-Ward removed the combined hyper::client::conn::Connection type. hyper will contain version-specific Connection types, and a "combined" interface will grow in hyper-util.
I streamed on twitch.tv/seanmonstar briefly about putting together a launch checklist, since we're so close to the first release candidate!
hyper in curl
I gave a talk for curl-up 2022.
@weihanglo updated hyper's C API to the now-stable cargo rustc --crate-type cdylib, no longer requiring nightly.
HTTP/3
@Ruben2424 got h3spec running in CI, and fixed up things it caught. @eagr signficantly filled out the rest of the spec compliance report, including exceptions and related unit tests. @g2p documented the whole public API, and removed the unused crate dependencies.
I'm actually moving across the country, which is why this update was delayed. ↩︎
0 notes
Link

On September 15th, I presented a talk for curl-up 2022 about the ongoing work to get hyper into curl. The topics I touched on were:
Why? For a (memory) safer internet.
What we did: the hyper HTTP backend in curl.
Symbiosis: how both libraries benefited even when not integrated.
Are we there yet? Pointing out the "help us" instructions and kanban board of final tests, and a big thank you all who have helped so far.
What you can do now.
Watch the video for yourself!
0 notes
Text
This Month in hyper: August 2022
Another hot summer month has gone by. Besides many of us convening for RustConf, a lot of wonderful contributors made great progress around hyper.
10,000 stars!
At the beginning of the month, we celebrated hyper reaching 10,000 stars on GitHub! ⭐
Releases
h2 v0.3.14
We released v0.3.14 of h2, the HTTP/2 dependency of hyper. Besides some internal refactoring, the user facing fix is that a server which responds early and wants to ignore the body will now send a NO_ERROR instead of a CANCEL, as the spec recommends, thanks to @erebe!
httparse v1.8.0
A new version of the HTTP/1 parser of hyper came out as well. @nox added an option to ignore invalid header lines, as browsers frequently do. And work from @lucacasonato and @AaronO improved request parsing performance by about ~13%!
hyper 1.0
We cruised on forward towards the stable hyper 1.0. Part of that is pushing the less stable (higher-level, more opinionated) features to hyper-util. So, I removed hyper::client::service, hyper::client::connect, hyper::Client, and hyper::Server. @MrGunflame removed the tcp feature, and it's related code connect and accept code.
The body module is also getting some cleaning. @Michael-J-Ward renamed hyper::Body to hyper::body::Recv temporarily (want to bikeshed the new name?), so that @RajivTS could rename hyper::body::HttpBody to simpler hyper::body::Body. @Xuanwo removed the "full" constructors from Body, and @oddgrd made Body::channel private, since those are now separate types in http-body-util. I wrote a proposal for a forwards-compatible Body trait, and published an article as a preface to the pattern matching compatibility issues being solve in that proposal.
For additions, I added version-specific Connection types for the client, to replace the "either-version" type already there. We also put our governance down in writing.
You can follow along (and join us!) on this dashboard. The goal is to have a release candidate out in September!
HTTP/3
@eagr got a spec compliance report rendered, using s2n-quic's cargo duvet. This lets us track via comments in the code how much of the HTTP/3 spec we are obeying. We still need to fill in a bunch of comments, but there's some in there already!
I created a tower-h3 repository to experiment with a standalone h3 client and server that can use Tower middleware. @kckeiks wrote up a magnificient PR to add experiemental HTTP/3 support to reqwest. The blocker to merging is figuring out the best way to publish "experimental" support to crates.io.
Tower
We've heard from many sources that doing retries correctly is hard. Tower has had a retry middleware, but it clearly wasn't doing enough to get proper retries into people's applications. So, @LucioFranco wrote up an issue outlining the ways we'll make it better. This includes some middleware changes to clarify concepts, and additional utilities so that designing custom retry policies is easy, and pushes the user towards safe defaults.
So far, Lucio has improved the Policy trait, derived a simple rng utility, and added a backoff module with trait and a good default based on exponential backoff.
0 notes
Text
Pattern Matching and Backwards Compatibility
Pattern matching in Rust is, the first time it clicks, something magical.
When you define a domain subject with an enum, and then match on the various details, you can express logic in a very natural way, and reduce errors about forgetting to handle all the cases. It's exceptional when the enum definition and the match statements are in the same crates.
It's a bit trickier when a library wants to export variants to allow easy matching for users of that library. There are API compatibility concerns, and while some have elegant solutions, others... don't.
This write-up shows several instances of this that I've learned from a library author's point of view.
Non-exhaustive enums
Translating typical Error inheritance
Enums with an "open-ended" variant
Non-exhaustive
The various versions of HTTP are well-defined, and are not variant in the same way a library version might be. You don't have a whole bunch of unknown HTTP version identifiers that you need to parse. So representing it as an enum is a pretty natural fit. You might start with something like this:
enum Version { Http10, Http11, Http2, }
A user might decide they need to do something different depending on the version of a request received:
match req.version() { Version::Http10 => println!("1.0"), Version::Http11 => println!("1.1"), Version::Http2 => println!("2"), }
That feels quite nice! But then as a library, you realize you need to add a new variant to support HTTP/3. By doing that, you'll break compilation for the user, since they are trying to exhaustively match on a pattern which is no longer exhaustive. Rust now has an attribute, #[non_exhaustive], which you can place on a definition to protect your users from these changes.1
#[non_exhaustive] enum Version { Http10, Http11, Http2, }
The user is now required to include a catch-all pattern, signaling that more variants may appear in the future.
match req.version() { Version::Http10 => println!("1.0"), Version::Http11 => println!("1.1"), Version::Http2 => println!("2"), other => println!("other? {:?}", other), }
With that in place, adding Version::Http3 won't break your user. Compatibility!
Exhaustively non-exhaustive
#[non_exhaustive] enum Version { Http10, Http11, Http2, }
The non_exhaustive attribute means a user must include a catch-all arm, which means we can add new variants and not break their code.
However, what if the user really wants to know if they handled all possible variants, perhaps after an upgrade? The catch-all prevents them from knowing.
There is a currently unstable lint, that is allow by default, but when developing a user can opt-in to being warned about new variants.
match req.version() { Version::Http10 => println!("1.0"), Version::Http11 => println!("1.1"), #[warn(non_exhaustive_omitted_patterns)] _ => unknown(), }
With the current enum, this will warn the user they didn't match on Version::Http2. And when the library adds a Version::Http3 variant, the user will notice a new warning when they upgrade.
Error types
It's very common in Rust for errors to be represented by an enum. The perceived benefit is that a consumer can cleanly match on different error cases, and if desired, even ensure you had handled every possible error case. While I'm not here to argue the premise of whether you should handle every single case, a problem I've struggled with related to this approach is probably better to explain first with a different programming language.
Let's say we have some client in Python, and we want to specifically retry "connect" errors. We might write that like so:
try: resp = client.get(url) except error.Connect: retry() # otherwise, keep raising
Later on, the client library decides it wants to allow being more specific about the exact error kind that occured while connecting. The library could do that by declaring some new error types that inherit from the Connect error.
class Resolve(error.Connect): pass class Handshake(error.Connect): pass
The user's original code will continue to work the same. Backwards compatibility has been kept. But a user can also update their code to be more specific, if they so desire:
try: resp = client.get(url) except error.Resolve: raise # don't retry a bad hostname except error.Connect: retry() # otherwise, keep raising
Back in Rust, this is harder to do. The simplest solution is just not to expose an enum, but an opaque struct with methods, like is_connect(), which will continue to be true if you later add is_resolve(). But, we're talking about pattern matching. Could we make this sort of flexibility work?
We could. Probably the better question is should we? But let's peek first, anyways.
Nested Non-exhaustiveness
Let's see what the user could try to write first, to see the goal:
match client.get(url) { Error::Connect(_) => { // retry }, e => return Err(e), }
The key here is that the Connect variant must contain a field. That way, if the library adds sub-variants, it doesn't break the code at compile-time or at runtime. It's also important that when there aren't any sub-variants, the pattern should still be non-exhaustive.
The library could provide its variants like this:
#[non_exhaustive] pub enum Error { Connect(Connect), // other top-level errors } #[non_exhaustive] pub enum Connect { Resolve(unnameable::Resolve), Handshake(unnameable::Handshake), } mod unnameable { pub struct Resolve(()); pub struct Handshake(()); }
The Connect sub-variants contain publicly unnameable typed fields, to prevent the user from being too exhaustive. This prevents a pattern such as Error::Connect(Connect::Resolve(Resolve(_))), which would break when Resolve became an enum. We can't reach for an empty enum Resolve {}, since then the type would be uninhabitable, and we could never construct such an error value.
An upgrading user doesn't break, but they can also be more specific if they choose:
match err { e @ Error::Connect(Connect::Resolve(_)) => { return Err(e); // don't retry } Error::Connect(_) => { // retry } }
If later on, we want to add some Resolve variants, we can promote it to an enum without breakage:
#[non_exhaustive] pub enum Resolve { NoRecordsFound(unnameable::NoRecordsFound), Io(unnameable::Io), }
The question of should we still lingers, though. I can't say what the right answer is. I leave this here hoping someone will explore the idea more thoroughly, and tell us how great or horrid it is.2
Open-ended variants
Some other domains appear to lend themselves to being represented by an enum, but likely shouldn't be. These are things where there are a set of commonly known types, but with an additional variant that is purposefully open-ended. Sometimes it's setup that way to allow for some official registry of constants, so a specification doesn't need to know all of them at publication time. Others just define the rules of a type, define the most common, and then also include an "extension" variant.
Defining these publicly as a Rust enum is an API compatibility hazard. Consider the example of HTTP status codes. Say we defined them like this:
#[non_exhaustive] pub enum Status { Ok, NotFound, InternalServerError, Unregistered(u16), }
We have an Unregistered(u16) variant because the specification allows for new status codes to defined over time, and even unregistered custom codes are valid. But what if a user starts matching on a status to use a newly proposed code:
match code { Status::Unregistered(103) => println!("early hints!"), _ => (), }
If the library later on decides to add a variant for the new status code, even though the enum was marked as non_exhaustive, it will be a form of breaking change. It won't be a compile-time break. Instead, it will only happen at runtime. The code, as a Status::EarlyHints, will no longer match the Status::Unregistered(103) pattern.
Opaque types with constants
We solved this in http by making StatusCode an opaque struct, and defined all the "variants" as constants.
pub struct StatusCode(u16); impl StatusCode { pub const OK: StatusCode = StatusCode(200); pub const NOT_FOUND: StatusCode = StatusCode(404); // etc ... }
Users can still match on the common "variants", but specifically can't match an exposed variant name for unregistered codes. They can only match them with a catch-all pattern:
match code { StatusCode::OK => println!("ok!"), other => { if other == 103 { println!("early hints!"); } } }
Even when a new status code constant is added, that existing code will continue to work. It does make it harder to exhaustively match on all possible status codes, but there are enough of them that the likelihood of anyone wanting to do that is very low.
Turns out, this works well when matching for equality!3 http::Method uses this too. This lesson also inspired a lot of changes in the headers crate.
We made the http::Version type before #[non_exhaustive] existed, using a similar technique to StatusCode. We could switch it, but seeing them as constants feels right. ↩︎
Probably somewhere in the middle, as is the usual when comparing trade-offs. ↩︎
There's another case regarding open-ended variants, but I think it's big enough to be a separate post. ↩︎
1 note
·
View note
Text
hyper at 10,000 stars
Today, hyper reached 10,000 stars on GitHub!

What does that mean? Not much. It simply means ten thousand people clicked the star button for hyperium/hyper. But hey, I'm not one to give up a reason to celebrate!
I had projected the rate of stars per day, and knew we'd reach 10k around the beginning of August. On the 1st, I setup a little script to check the GitHub API every 30 minutes, print out the new number, and continue until it reached the target number. That happened around 1:30am Pacific Time, this morning!
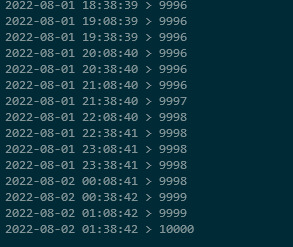
Really, this is thanks to all of you, for contributing and using hyper. Thank you!
0 notes
Text
This Month in hyper: July 2022
I'd like to start providing more frequent updates of all the work that's done in hyper, along with examples, details, and thanks. As a bonus, I included things from June in here as well.
Release v0.14.20
While we will release often when there's new bug fixes grouped up, this release has a helpful new feature for people who write proxies and gateways.
hyper::ext::ReasonPhrase
One of the new features in v0.14.20 is the ability to interact more with the HTTP/1 reason-phrase of an HTTP response. This is a sort-of deprecated part of HTTP (the reason-phrase does not exist in HTTP/2 or 3), but sometimes important information is still put in them. The http::StatusCode type does not include a String field for the reason-phrase, because of that deprecation, and to decrease the memory size of the type.
Consider this response with a custom reason-phrase:
HTTP/1.1 200 Stupendous
If you do need to access it, now you can! If the client receives a response with a non-standard phrase, it will be saved in the response extensions. So, a client would do so like this:
use hyper::ext::ReasonPhrase; let resp = client.get(url).await?; if let Some(phrase) = resp.extensions().get::<ReasonPhrase>() { eprintln!("got {} {:?}", resp.status(), phrase); }
And a server can send a custom phrase by including the extension, like so:
use hyper::ext::ReasonPhrase; async fn handle(_req: Request) -> Result<Response, Infallible> { let mut resp = Response::new(Body::empty()); // There's also TryFrom impls for non-static values. let phrase = ReasonPhrase::from_static("Stupendous"); resp.extensions_mut().insert(phrase); Ok(resp) }
Thanks a bunch to Adam Foltzer for the work on this feature!
hyper 1.0 started
Development work on 1.0 started in June. Progress can be tracked in the public dashboard. Some major work done so far includes splitting the client connection type per HTTP version, for forwards compatibility, and moving the connection pool implementation and the Tokio connect integration to hyper-util. Thanks to @oddgrd, @tomarkw, @dswij!
There's several more big PRs nearing completion too, looking forward to thanking them next month.
hyper in curl
In June, we fixed the way curl would pause and resume request bodies when using hyper, resulting in 4 more of the remaining unit tests to pass. In July, a brand new contributor (thanks @deantvv!) add the FFI function to use hyper's existing obs-folded headers support. A PR just merged aligns how curl expects obs-folded headers and how hyper treats them, which should fix another couple unit tests.
There's a dashboard if you'd like to help this momentous work.
HTTP/3
The HTTP/3 specification was published as RFC 9114. I gave a small recap of the state of HTTP/3 in hyper.
In the same time period, hyper's HTTP/3 library saw some increased development, from three brand new contributors, two of which have made over 3 contributions each. The work includes making request streams splittable into a send and receive side, and support for "GREASE" streams and frames. Thank you @Ruben2424, @yu-re-ka, and @inflation!
I've started some work on a tower-h3 crate, which would make it easier to plug HTTP/3 into an existing Tower codebase. I really do need to push this stuff to GitHub.
I also wrote up an issue to add experimental support to reqwest. Getting it into reqwest would mean users could start trying it out more easily, and we could learn how to adjust the h3 crate API before making it part of hyper directly. It would likely be easier to do this if the tower-h3 crate were ready, as an intermediate step. Volunteers welcome!
0 notes