
phuconuong
Phu Phu blog!
Welcome to my blog :)
7 posts
Don't wanna be here? Send us removal request.
Last Seen Blogs

asteroidee035-blog
A S T E R O I D E

ployzwildcards
P L Y Z


strolldiaz
✧˖° — 𝙠𝙖𝙩𝙞𝙚 ✧˖°

when-icarus-fell
He Arose Wishing For The World To Burn With Him
Text
Creating graphs for your data
Coursera - Week 04
import pandas
import numpy
import seaborn
import matplotlib.pyplot as plt
# any additional libraries would be imported here
#Set PANDAS to show all columns in DataFrame
pandas.set_option('display.max_columns', None)
#Set PANDAS to show all rows in DataFrame
pandas.set_option('display.max_rows', None)
# bug fix for display formats to avoid run time errors
pandas.set_option('display.float_format', lambda x:'%f'%x)
data = pandas.read_csv('nesarc_pds.csv', low_memory=False)
print(len(data)) #number of observations (rows)
print(len(data.columns)) # number of variables (columns)
# checking the format of your variables
data['ETHRACE2A'].dtype
#setting variables you will be working with to numeric (updated)
data['TAB12MDX'] = pandas.to_numeric(data['TAB12MDX'])
data['CHECK321'] = pandas.to_numeric(data['CHECK321'])
data['S3AQ3B1'] = pandas.to_numeric(data['S3AQ3B1'])
data['S3AQ3C1'] = pandas.to_numeric(data['S3AQ3C1'])
data['AGE'] = pandas.to_numeric(data['AGE'])
#subset data to young adults age 18 to 25 who have smoked in the past 12 months
sub1=data[(data['AGE']>=18) & (data['AGE']<=25) & (data['CHECK321']==1)]
#make a copy of my new subsetted data
sub2 = sub1.copy()
#SETTING MISSING DATA
# recode missing values to python missing (NaN)
sub2['S3AQ3B1']=sub2['S3AQ3B1'].replace(9, numpy.nan)
# recode missing values to python missing (NaN)
sub2['S3AQ3C1']=sub2['S3AQ3C1'].replace(99, numpy.nan)
recode1 = {1: 6, 2: 5, 3: 4, 4: 3, 5: 2, 6: 1}
sub2['USFREQ']= sub2['S3AQ3B1'].map(recode1)
recode2 = {1: 30, 2: 22, 3: 14, 4: 5, 5: 2.5, 6: 1}
sub2['USFREQMO']= sub2['S3AQ3B1'].map(recode2)
# A secondary variable multiplying the number of days smoked/month and the approx number of cig smoked/day
sub2['NUMCIGMO_EST']=sub2['USFREQMO'] * sub2['S3AQ3C1']
#univariate bar graph for categorical variables
# First hange format from numeric to categorical
sub2["TAB12MDX"] = sub2["TAB12MDX"].astype('category')
seaborn.countplot(x="TAB12MDX", data=sub2)
plt.xlabel('Nicotine Dependence past 12 months')
plt.title('Nicotine Dependence in the Past 12 Months Among Young Adult Smokers in the NESARC Study')
#Univariate histogram for quantitative variable:
seaborn.distplot(sub2["NUMCIGMO_EST"].dropna(), kde=False);
plt.xlabel('Number of Cigarettes per Month')
plt.title('Estimated Number of Cigarettes per Month among Young Adult Smokers in the NESARC Study')
0 notes
Text
Data Management and Visualization - Week 01
I have decided to use the Gapminder data to see if I can better understand the link between unemployment and suicide in males.
There have been many different studies linking or attempting to link unemployment and the general economy with suicide - some of these include;
Unemployment and Mental Health: Understanding the Interactions Among Gender, Family Roles, and Social Class | Lucía Artazcoz, MPH, Joan Benach, PhD, Carme Borrell, PhD, and Immaculada Cortès, MPH - In a nutshell, this paper concludes that unemployment has varying effects on mental health and varies with factors such as sex, marital status, term of unemployment and if welfare benefits are available
Sex and Suicide, Gender differences in suicidal behavior - Keith Hawton - Editorial in the British journal of Psychiatry - Mr Hawton concludes that there is a difference in the ratio of suicide between males and females but that much more research is required to discover strategies to improve outcomes in either sex or both sexes
The gender gap in suicide and premature death or: why are men so vulnerable? Anne Maria Moller-Leimkuhler - Posits that male mal-adaption may be responsible for the increasing proportion of male to female suicide rates and includes one particularly stunning table ranking male youth suicide by country
There are many papers on this subject and it seems that while unemployment has an effect on suicide rates it seems that WHERE you are unemployed is probably more important. I will attempt to show that this IS the case and try to discover some of the reasons it may be so
0 notes
Text
Data Analysis Tools - Week 04
import pandas
import numpy
import scipy.stats
import seaborn
import matplotlib.pyplot as plt
data = pandas.read_csv('gapminder.csv', low_memory=False)
data['urbanrate'] = data['urbanrate'].convert_objects(convert_numeric=True)
data['incomeperperson'] = data['incomeperperson'].convert_objects(convert_numeric=True)
data['internetuserate'] = data['internetuserate'].convert_objects(convert_numeric=True)
data['incomeperperson']=data['incomeperperson'].replace(' ', numpy.nan)
data_clean=data.dropna()
print (scipy.stats.pearsonr(data_clean['urbanrate'], data_clean['internetuserate']))
def incomegrp (row):
if row['incomeperperson'] <= 744.239:
return 1
elif row['incomeperperson'] <= 9425.326 :
return 2
elif row['incomeperperson'] > 9425.326:
return 3
data_clean['incomegrp'] = data_clean.apply (lambda row: incomegrp (row),axis=1)
chk1 = data_clean['incomegrp'].value_counts(sort=False, dropna=False)
print(chk1)
sub1=data_clean[(data_clean['incomegrp']== 1)]
sub2=data_clean[(data_clean['incomegrp']== 2)]
sub3=data_clean[(data_clean['incomegrp']== 3)]
print ('association between urbanrate and internetuserate for LOW income countries')
print (scipy.stats.pearsonr(sub1['urbanrate'], sub1['internetuserate']))
print (' ')
print ('association between urbanrate and internetuserate for MIDDLE income countries')
print (scipy.stats.pearsonr(sub2['urbanrate'], sub2['internetuserate']))
print (' ')
print ('association between urbanrate and internetuserate for HIGH income countries')
print (scipy.stats.pearsonr(sub3['urbanrate'], sub3['internetuserate']))
#%%
scat1 = seaborn.regplot(x="urbanrate", y="internetuserate", data=sub1)
plt.xlabel('Urban Rate')
plt.ylabel('Internet Use Rate')
plt.title('Scatterplot for the Association Between Urban Rate and Internet Use Rate for LOW income countries')
print (scat1)
#%%
scat2 = seaborn.regplot(x="urbanrate", y="internetuserate", fit_reg=False, data=sub2)
plt.xlabel('Urban Rate')
plt.ylabel('Internet Use Rate')
plt.title('Scatterplot for the Association Between Urban Rate and Internet Use Rate for MIDDLE income countries')
print (scat2)
#%%
scat3 = seaborn.regplot(x="urbanrate", y="internetuserate", data=sub3)
plt.xlabel('Urban Rate')
plt.ylabel('Internet Use Rate')
plt.title('Scatterplot for the Association Between Urban Rate and Internet Use Rate for HIGH income countries')
print (scat3)
0 notes
Text
Data Analysis Tools - WEEK 03
%matplotlib inline
import pandas
import matplotlib.pyplot as plt
import scipy
import seaborn as sns
# get data
data = pd.read_csv('/content/mydrive/MyDrive/Coursera/nesarc_pds.csv', low_memory = False)
#Create the dataframe with the required features
df1 = pandas.DataFrame()
df1['AGE'] = data['AGE']
df1['HEIGHT'] = (data['S1Q24FT']*12 + data['S1Q24IN'] )* 2.54
df1.describe()
df1 = df1[ df1['HEIGHT']<=250 ]
print('Corrected Max height: {0}cm'.format(df1['HEIGHT'].max()))
averages = df1.groupby('AGE', as_index=False).mean()
sns.lmplot(x='AGE', y='HEIGHT', data=averages)
r,p = scipy.stats.pearsonr(averages['AGE'],averages['HEIGHT'])
print('Correlation coefficient (r): {0}'.format(r))
print('p-value: {0}'.format(p))
0 notes
Text
Running a Chi-Square Test of Independence - Nearc_pds
import pandas
import numpy
import scipy.stats
import seaborn
import matplotlib.pyplot as plt
data = pandas.read_csv('nesarc.csv', low_memory=False)
""" setting variables you will be working with to numeric
10/29/15 note that the code is different from what you see in the videos
A new version of pandas was released that is phasing out the convert_objects(convert_numeric=True)
It still works for now, but it is recommended that the pandas.to_numeric function be
used instead """
""" old code:
data['TAB12MDX'] = data['TAB12MDX'].convert_objects(convert_numeric=True)
data['CHECK321'] = data['CHECK321'].convert_objects(convert_numeric=True)
data['S3AQ3B1'] = data['S3AQ3B1'].convert_objects(convert_numeric=True)
data['S3AQ3C1'] = data['S3AQ3C1'].convert_objects(convert_numeric=True)
data['AGE'] = data['AGE'].convert_objects(convert_numeric=True) """
new code setting variables you will be working with to numeric
data['TAB12MDX'] = pandas.to_numeric(data['TAB12MDX'], errors='coerce')
data['CHECK321'] = pandas.to_numeric(data['CHECK321'], errors='coerce')
data['S3AQ3B1'] = pandas.to_numeric(data['S3AQ3B1'], errors='coerce')
data['S3AQ3C1'] = pandas.to_numeric(data['S3AQ3C1'], errors='coerce')
data['AGE'] = pandas.to_numeric(data['AGE'], errors='coerce')
subset data to young adults age 18 to 25 who have smoked in the past 12 months
sub1=data[(data['AGE']>=18) & (data['AGE']<=25) & (data['CHECK321']==1)]
make a copy of my new subsetted data
sub2 = sub1.copy()
recode missing values to python missing (NaN)
sub2['S3AQ3B1']=sub2['S3AQ3B1'].replace(9, numpy.nan)
sub2['S3AQ3C1']=sub2['S3AQ3C1'].replace(99, numpy.nan)
recoding values for S3AQ3B1 into a new variable, USFREQMO
recode1 = {1: 30, 2: 22, 3: 14, 4: 6, 5: 2.5, 6: 1}
sub2['USFREQMO']= sub2['S3AQ3B1'].map(recode1)
contingency table of observed counts
ct1=pandas.crosstab(sub2['TAB12MDX'], sub2['USFREQMO'])
print (ct1)
column percentages
colsum=ct1.sum(axis=0)
colpct=ct1/colsum
print(colpct)
chi-square
print ('chi-square value, p value, expected counts')
cs1= scipy.stats.chi2_contingency(ct1)
print (cs1)
set variable types
sub2["USFREQMO"] = sub2["USFREQMO"].astype('category')
new code for setting variables to numeric:
sub2['TAB12MDX'] = pandas.to_numeric(sub2['TAB12MDX'], errors='coerce')
old code for setting variables to numeric:
sub2['TAB12MDX'] = sub2['TAB12MDX'].convert_objects(convert_numeric=True)
graph percent with nicotine dependence within each smoking frequency group
seaborn.factorplot(x="USFREQMO", y="TAB12MDX", data=sub2, kind="bar", ci=None)
plt.xlabel('Days smoked per month')
plt.ylabel('Proportion Nicotine Dependent')
recode2 = {1: 1, 2.5: 2.5}
sub2['COMP1v2']= sub2['USFREQMO'].map(recode2)
contingency table of observed counts
ct2=pandas.crosstab(sub2['TAB12MDX'], sub2['COMP1v2'])
print (ct2)
column percentages
colsum=ct2.sum(axis=0)
colpct=ct2/colsum
print(colpct)
print ('chi-square value, p value, expected counts')
cs2= scipy.stats.chi2_contingency(ct2)
print (cs2)
recode3 = {1: 1, 6: 6}
sub2['COMP1v6']= sub2['USFREQMO'].map(recode3)
contingency table of observed counts
ct3=pandas.crosstab(sub2['TAB12MDX'], sub2['COMP1v6'])
print (ct3)
column percentages
colsum=ct3.sum(axis=0)
colpct=ct3/colsum
print(colpct)
print ('chi-square value, p value, expected counts')
cs3= scipy.stats.chi2_contingency(ct3)
print (cs3)
recode4 = {1: 1, 14: 14}
sub2['COMP1v14']= sub2['USFREQMO'].map(recode4)
contingency table of observed counts
ct4=pandas.crosstab(sub2['TAB12MDX'], sub2['COMP1v14'])
print (ct4)
column percentages
colsum=ct4.sum(axis=0)
colpct=ct4/colsum
print(colpct)
print ('chi-square value, p value, expected counts')
cs4= scipy.stats.chi2_contingency(ct4)
print (cs4)
recode5 = {1: 1, 22: 22}
sub2['COMP1v22']= sub2['USFREQMO'].map(recode5)
contingency table of observed counts
ct5=pandas.crosstab(sub2['TAB12MDX'], sub2['COMP1v22'])
print (ct5)
column percentages
colsum=ct5.sum(axis=0)
colpct=ct5/colsum
print(colpct)
print ('chi-square value, p value, expected counts')
cs5= scipy.stats.chi2_contingency(ct5)
print (cs5)
recode6 = {1: 1, 30: 30}
sub2['COMP1v30']= sub2['USFREQMO'].map(recode6)
contingency table of observed counts
ct6=pandas.crosstab(sub2['TAB12MDX'], sub2['COMP1v30'])
print (ct6)
column percentages
colsum=ct6.sum(axis=0)
colpct=ct6/colsum
print(colpct)
print ('chi-square value, p value, expected counts')
cs6= scipy.stats.chi2_contingency(ct6)
print (cs6)
recode7 = {2.5: 2.5, 6: 6}
sub2['COMP2v6']= sub2['USFREQMO'].map(recode7)
contingency table of observed counts
ct7=pandas.crosstab(sub2['TAB12MDX'], sub2['COMP2v6'])
print (ct7)
column percentages
colsum=ct7.sum(axis=0)
colpct=ct7/colsum
print(colpct)
print ('chi-square value, p value, expected counts')
cs7=scipy.stats.chi2_contingency(ct7)
print (cs7)
0 notes
Text
Coursera - Gapminder
# coding: utf-8
# coding utf-8
# created by Nick Apr 2016
# magic to show charts in notebook
get_ipython().magic('matplotlib inline')
# imports
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import statsmodels.formula.api as smf
import statsmodels.stats.multicomp as multi
# get data
from google.colab import drive
drive.mount('/content/mydrive')
data = pd.read_csv('/content/mydrive/MyDrive/Coursera/gapminder.csv', low_memory = False)
print(data.head(5))

# create subset of data containing only columns of interest
sub1 = data[['country','femaleemployrate','suicideper100th','employrate']].dropna()
print(sub1.head(30))
# Change str columns to numeric and blanks etc to NaN
colsToConvert = ['femaleemployrate','suicideper100th','employrate']
for col in colsToConvert:
sub1[col] = pd.to_numeric(sub1[col],errors = 'coerce')
# drop rows where 'suicide' and employment rates are missing
sub1 = sub1[pd.notnull(data['suicideper100th'])]
sub1 = sub1[pd.notnull(data['femaleemployrate'])]
sub1 = sub1[pd.notnull(data['employrate'])]
# I want to convert suicides per 100,00 to suicides per million
sub1['suicide'] = sub1['suicideper100th']*10
print(sub1.head(30))

# drop rows where 'suicide' and employment rates are missing
sub1 = sub1[pd.notnull(sub1['suicide'])]
sub1 = sub1[pd.notnull(sub1['femaleemployrate'])]
sub1 = sub1[pd.notnull(sub1['employrate'])]
# create a categorical variable for suicide rates
myBins = [0,29,59,89,119,149,179,209,239,269,299,329,360]
myLabs = ['0-29','30-59','60-89','90-119','120-149','150-179','180-209','210-239','240-269','270-299','300-329','330-360']
sub1['suicideCat']= pd.cut(sub1.suicide, bins = myBins, labels = myLabs)
# create a categorical variable for suicide rates
print(sub1['employrate'].describe())
myBins = [34,43,55,65,74,84]
myLabs = ['Very Low','Low','Mid Range','High','VeryHigh']
sub1['TotEmpRate']= pd.cut(sub1.employrate, bins = myBins, labels = myLabs)

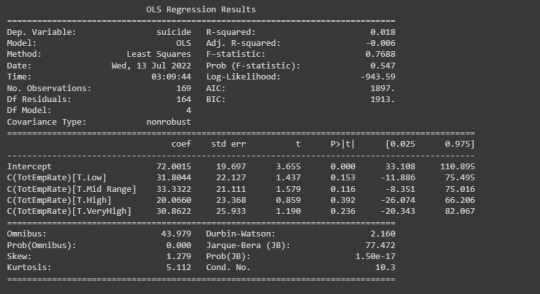
# using ols function for calculating the F-statistic and associated p value
model1 = smf.ols(formula='suicide ~ C(TotEmpRate)', data=sub1)
results1 = model1.fit()
print (results1.summary())
#Lets work out some grouped means on a subset containing only these two columns
sub2 = sub1[['suicide','TotEmpRate']].dropna()
# sub2['suicide'] = pd.to_numeric(sub2['suicide'],errors = 'coerce')
print ('\n','means for suicide by employment rate')
m1= sub2.groupby('TotEmpRate').mean()
print (m1)

print ('\n\n','standard deviations for suicide by employment rate')
sd1 = sub2.groupby('TotEmpRate').std()
print (sd1)

print('Tukey multi comparison of suicides by employment rates','\n')
mc1 = multi.MultiComparison(sub2['suicide'], sub2['TotEmpRate'])
res1 = mc1.tukeyhsd()
print(res1.summary())

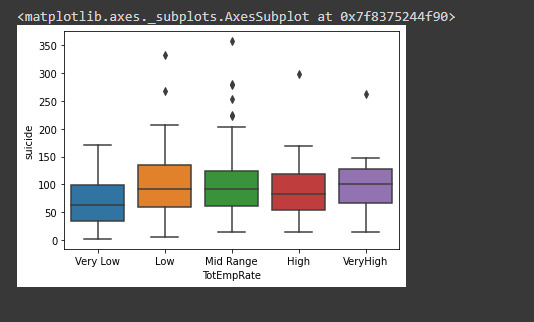
# Create a boxplot of the two features
sns.boxplot(y = 'suicide', x = 'TotEmpRate', data=sub2)
0 notes