
noredinktech
NoRedInk
NoRedInk is on a mission to unlock every writer's potential.
72 posts
Don't wanna be here? Send us removal request.
Last Seen Blogs

neero73
Neeroga

fabuloushairbeauty
Fabulous Hair and Beauty

lukedrawzstuff
Emotionally destroyed :3

letscreateastory2gether
Ellie.hee

taelovergguk
nehir
Text
Word Labels
Working at NoRedInk, I have the opportunity to work on such a variety of challenges and puzzles! It's a pleasure to figure out how to build ambitious and highly custom components and applications.
Recently, I built a component that will primarily be used for labeling sentences with parts of speech.
This component was supposed to show "labels" over words while guaranteeing that the labels wouldn't cover meaningful content (including other labels). This required labels to be programmatically and dynamically repositioned to keep content readable:
It takes some CSS and some measuring of rendered content to avoid overlaps:
All meaningful content needs to be accessible to users, so it's vital that content not be obscured.
In this post, I'm going to go through a simplified version of the Elm, CSS, and HTML I used to accomplish this goal. I'm going to focus primarily on the positioning styles, since they're particularly tricky!
Balloon
The first piece we need is a way to render the label in a little box with an arrow. To avoid confusion over HTML labels, we'll call this little component "Balloon."
balloon : String -> Html msg balloon label = span [ css [ Css.display Css.inlineFlex , Css.flexDirection Css.column , Css.alignItems Css.center ] ] [ balloonLabel label , balloonArrow initialArrowSize ] balloonLabel : String -> Html msg balloonLabel label = span [ css [ Css.backgroundColor black , Css.color white , Css.border3 (Css.px 1) Css.solid black , Css.margin Css.zero , Css.padding (Css.px 4) , Css.maxWidth (Css.px 175) , Css.property "width" "max-content" ] ] [ text label ] initialArrowSize : Float initialArrowSize = 10 balloonArrow : Float -> Html msg balloonArrow arrowHeight = span [ attribute "data-description" "balloon-arrow" , css [ Css.borderStyle Css.solid -- Make a triangle , Css.borderTopWidth (Css.px arrowHeight) , Css.borderRightWidth (Css.px initialArrowSize) , Css.borderBottomWidth Css.zero , Css.borderLeftWidth (Css.px initialArrowSize) -- Colors: , Css.borderTopColor black , Css.borderRightColor Css.transparent , Css.borderBottomColor Css.transparent , Css.borderLeftColor Css.transparent ] ] []
Ellie balloon example
Positioning a Balloon over a Word
Next, we want to be able to center a balloon over a particular word, so that it appears that the balloon is labelling the word.
This is where an extremely useful CSS trick can come into play: position styles don't have the same frame of reference as transform styles.
position styles apply with respect to the relative parent container
transform translations apply with respect to the element itself
This means that we can combine position styles and transform translations in order to center an arbitrary-width balloon over an arbitary-width word.
Adding the following styles to the balloon container:
, Css.position Css.absolute , Css.left (Css.pct 50) , Css.transforms [ Css.translateX (Css.pct -50), Css.translateY (Css.pct -100) ]
and rendering the balloon in the same position-relative container as the word itself:
word : String -> Maybe String -> Html msg word word_ maybeLabel = span [ css [ Css.position Css.relative , Css.whiteSpace Css.preWrap ] ] (case maybeLabel of Just label -> [ balloon label, text word_ ] Nothing -> [ text word_ ] )
handles our centering!
Ellie centering-a-balloon example
Conveying the balloon meaning without styles
It's important to note that while our styles do a solid job of associating the balloon with the word, not all users of our site will see our styles. We need to make sure we're writing semantic HTML that will be understandable by all users, including users who aren't experiencing our CSS.
For the purposes of the NoRedInk project that the component that I'm describing here will be used for, we decided to use a mark element with ::before and ::after pseudo-elements to semantically communicate the meaning of the balloon to assistive technology users. Then we marked the balloon itself as hidden, so that the user wouldn't experience annoying redundant information.
Since this post is primarily focused on CSS, I'm not going to expand on this more. Please read "Tweaking Text Level Styles" by Adrian Roselli to better understand the technique we're using.
Ellie improving the balloon-word relationship
Fixing horizontal Balloon overlaps
Balloons on the same line can potentially overlap each other on their left and right edges. Since we want users to be able to adjust font size preferences and to use magnification as much as they want, we can't guarantee anything about the size of the labels or where line breaks occur in the text.
This means we need to measure the DOM and reposition labels dynamically. For development purposes, it's convenient to add a button to measure and reposition the labels on demand. For production uses, labels should be measured and repositioned on page load, when the window changes sizes, or when anything else might happen to change the reflow.
To measure the element, we can use Browser.Dom.getElement, which takes an html id and runs a task to measure the element on the page.
type alias Model = Dict.Dict String Dom.Element update : Msg -> Model -> ( Model, Cmd Msg ) update msg model = case msg of GetMeasurements -> ( model, Cmd.batch (List.map measure allIds) ) GotMeasurements balloonId (Ok measurements) -> ( Dict.insert balloonId measurements model , Cmd.none ) GotMeasurements balloonId (Err measurements) -> -- in a real application, handle errors gracefully with reporting ( model, Cmd.none ) measure : String -> Cmd Msg measure balloonId = Task.attempt (GotMeasurements balloonId) (Dom.getElement balloonId)
Then we can do some logic (optimized for clarity rather than performance, since we're not expecting many balloons at once) to figure out how far the balloons need to be offset based on these measurements:
arrowHeights : Dict.Dict String Dom.Element -> Dict.Dict String Float arrowHeights model = let bottomY { element } = element.y + element.height in model |> Dict.toList -- -- first, we sort & group by line, so that we're only looking for horizontal overlaps between -- balloons on the same line of text |> List.sortBy (Tuple.second >> bottomY) |> List.Extra.groupWhile (\( _, a ) ( _, b ) -> bottomY a == bottomY b) |> List.map (\( first, rem ) -> first :: rem) -- -- for each line,we find horizontal overlaps |> List.concatMap (\line -> line |> List.sortBy (Tuple.second >> .element >> .x) |> List.Extra.groupWhile (\( _, a ) ( _, b ) -> (a.element.x + a.element.width) >= b.element.x) |> List.map (\( first, rem ) -> first :: rem) ) -- -- now we have our overlaps and our singletons! |> List.concatMap (\overlappingBalloons -> overlappingBalloons -- -- we sort each overlapping group by width: we want the widest balloon on top -- (why? the wide balloons might overlap multiple other balloons. Putting the widest balloon on top is a step towards a maximally-compact solution.) |> List.sortBy (Tuple.second >> .element >> .width) -- then we iterate over the overlaps and account for the previous balloon's height |> List.foldl (\( idString, e ) ( index, height, acc ) -> ( index + 1 , height + e.element.height , ( idString, height ) :: acc ) ) ( 0, initialArrowSize, [] ) |> (\( _, _, v ) -> v) ) |> Dict.fromList
Then we thread the offset we get all the way through to the balloon's arrow so that it can expand in height appropriately.
This works!
We can reposition from:
to:
Ellie initial repositioning example
Fixing Balloons overlapping content above them
Our balloons are no longer overlapping each other, but they still might overlap content above them. They haven't been overlapping content above them in the examples so far because I sneakily added a lot of margin on top of their containing paragraph tag. If we remove this margin:
This seems like a challenging problem: how can we make an absolutely-positioned item take up space in normal inline flow? We can't! But what we can do is make our normal inline words take up more space to account for the absolutely positioned balloon.
When we have a label, we are now going to wrap the word in a span with display: inline-block and with some top padding. This will guarantee that's there's always sufficient space for the balloon after we finish measuring.
I've added a border around this span to make it more clear what's happening in the screenshots:
This approach also works when the content flows on to multiple lines:
{-| The height of the arrow and the total height are different, so now we need to calculate 2 different values based on our measurements. -} type alias Position = { arrowHeight : Float , totalHeight : Float } word : String -> Maybe { label : String, id : String, position : Maybe Position } -> Html msg word word_ maybeLabel = let styles = [ Css.position Css.relative , Css.whiteSpace Css.preWrap ] in case maybeLabel of Just ({ label, position } as balloonDetails) -> mark [ css (styles ++ [ Css.before [ Css.property "content" ("\" start " ++ label ++ " highlight \"") , invisibleStyle ] , Css.after [ Css.property "content" ("\" end " ++ label ++ " \"") , invisibleStyle ] ] ) ] [ span [ css [ Css.display Css.inlineBlock , Css.border3 (Css.px 2) Css.solid (Css.rgb 0 0 255) , Maybe.map (Css.paddingTop << Css.px << .totalHeight) position |> Maybe.withDefault (Css.batch []) ] ] [ balloon balloonDetails , text word_ ] ] Nothing -> span [ css styles ] [ text word_ ]
Ellie avoiding top overlaps
Fixing multiple repositions logic
Alright! So we've prevented top overlaps and we've prevented balloons from overlapping each other on the sides.
There is still a repositioning problem though! We need to reposition the labels again based on window events like resizing. Right now, we're measuring the height of the entire balloon including the arrow, and then using that height to calculate how tall a neighboring balloon's arrow needs to be. This means that subsequent remeasures can make the arrows far taller than they need to be!
We're measuring the entire rendered balloon when we check for overlaps and figure out our repositioning, but we should really only be taking into consideration whether balloons overlap when in their starting positions.
Essentially, we need to disregard the measured height of the arrow entirely when calculating new arrow heights. A straightforward way to do this is to measure the content within the balloon separately from the overall balloon measurement.
We add a new id to the balloon content:
balloonContentId : String -> String balloonContentId baseId = baseId ++ "-content" balloonLabel : { config | label : String, id : String } -> Html msg balloonLabel config = p [ css [ Css.backgroundColor black , Css.color white , Css.border3 (Css.px 1) Css.solid black , Css.margin Css.zero , Css.padding (Css.px 4) , Css.maxWidth (Css.px 175) , Css.property "width" "max-content" ] , id (balloonContentId config.id) ] [ text config.label ]
and measure the balloon content when we measure the total balloon:
measure : String -> Cmd Msg measure balloonId = Task.map2 (\balloon_ balloonContent -> { balloon = balloon_, balloonContent = balloonContent }) (Dom.getElement balloonId) (Dom.getElement (balloonContentId balloonId)) |> Task.attempt (GotMeasurements balloonId)
We also change our position calculation helper from:
positions : Dict.Dict String Dom.Element -> Dict.Dict String Position positions model = ... -- then we iterate over the overlaps and account for the previous balloon's height |> List.foldl (\( idString, e ) ( index, height, acc ) -> ( index + 1 , height + e.element.height , ( idString , { totalHeight = height + e.element.height - initialArrowSize , arrowHeight = height } ) :: acc ) ) ( 0, initialArrowSize, [] ) ...
to
positions : Dict.Dict String { balloon : Dom.Element, balloonContent : Dom.Element } -> Dict.Dict String Position positions model = ... -- then we iterate over the overlaps and account for the previous balloon's height |> List.foldl (\( idString, e ) ( index, height, acc ) -> ( index + 1 , height + e.balloonContent.element.height , ( idString , { totalHeight = height + e.balloonContent.element.height , arrowHeight = height } ) :: acc ) ) ( 0, initialArrowSize, [] ) ...
Ellie with fixed multiple repositioning logic
Fixing overlaps with the arrow
I claimed previously that we fixed overlaps between the balloons. This is true-ish: we actually only fixed overlaps between pieces of balloon content. A meaningful piece of balloon content can actually still overlap another balloon's arrow! And, since the content stacks from left to right, there's a chance that meangingful content might be obscured by an arrow:
Ellie showing the balloon and arrow overlap problem
There are two problems here:
The balloons need a clearer indication of their edges when they're close together.
The left-to-right stacking context won't work. We need to put the bottom balloon on top of the stacking context so that balloon content is never obscured.
The first problem is improved by adding white borders to the balloon content and shifting the balloon arrow up a corresponding amount.
Ellie where each balloon has a white border around its content
The second part of the problem can be fixed by adding a zIndex to the balloon based on position in the overlapping rows, so that arrows never cover label content:
positions : Dict.Dict String { balloon : Dom.Element, balloonContent : Dom.Element } -> Dict.Dict String Position positions model = ... -- now we have our overlaps and our singletons! |> List.concatMap (\overlappingBalloons -> let maxOverlappingBalloonsIndex = List.length overlappingBalloons - 1 in overlappingBalloons -- -- we sort each overlapping group by width: we want the widest balloon on top |> List.sortBy (Tuple.second >> .balloon >> .element >> .width) -- then we iterate over the overlaps and account for the previous balloon's height |> List.foldl (\( idString, e ) ( index, height, acc ) -> ( index + 1 , height + e.balloonContent.element.height , ( idString , { totalHeight = height + e.balloonContent.element.height , arrowHeight = height , zIndex = maxOverlappingBalloonsIndex - index } ) :: acc ) ) ( 0, initialArrowSize, [] ) ...
Ellie with the zIndex logic applied
Fixing content extending beyond the viewport
We're almost done with ways that the balloons can overlap content!
For our purposes, we expect words marked with a balloon to be the only meaningful content showing in a line. That is, we're not worried about the balloon overlapping something meaningful to its right or left because we know how the component will be used. This is great, since it really simplifies the overlap problem for us: it means we only need to worry about the viewport edges cutting off balloons.
Browser.Dom.getElement also returns information about the viewport, which we can use to adjust our position logic to get the amount that a given balloon is "cut off" on the horizontal edges. Once we have this xOffset, using CSS to scootch a balloon over is nice and straightforward:
balloonLabel : { label : String, id : String, position : Maybe Position } -> Html msg balloonLabel config = p [ css [ Css.backgroundColor black , Css.color white , Css.border3 (Css.px 2) Css.solid white , Css.margin Css.zero , Css.padding (Css.px 4) , Css.maxWidth (Css.px 175) , Css.property "width" "max-content" , Css.transform (Css.translateX (Css.px (Maybe.map .xOffset config.position |> Maybe.withDefault 0))) ] , id (balloonContentId config.id) ] [ text config.label ]
Ellie with x-offset logic
Please note that when elements are pushed to the right of the viewport edge, by default, the browser will give you a scrollbar to get over to see the content.
Ellie demoing right-scroll when an element is translated off the right edge of the viewport.
You may want to hide overflow in the x direction to prevent the scrollbar from appearing/your mobile styles from getting messed up.
That's (mostly) it!
You might notice that the solution isn't maximally compact:
This is where our MVP line was. If it turns out that our content ends up taking up too much vertical space, and we want to go for the maximally compact version, we'll revisit the implementation. Since the logic is all in one easily-testable Elm function, improving the algorithm should be pretty straightfoward.
Additionally, this post didn't get into high-contrast mode styles. The way that the balloon is styled currently is utterly inaccessible in high contrast mode! Anytime you're changing background color and font color, it's important to check in high-contrast mode to see how the styles are being coerced. I've written a couple of previous posts talking about color considerations (Custom Focus Rings, Presenting Styleguide Colors) so I don't want to dig into how to fix this problem in this post. Please be aware that while the positioning styles in this post are fairly solid, the rest of the styles are not production ready.
Thanks for reading along! I had a great time working on this project and I'm quite pleased with how it came out. I'm looking forward to sharing the next interesting project I work on with you!
Tessa Kelly @t_kelly9
2 notes
·
View notes
Text
Custom Focus Rings
Many people who operate their devices with a keyboard need a visual indicator of keyboard focus. Without a visual indicator of which element has focus, it's hard to know what, say, hitting enter might do. Anything might happen!
It's reasonable to think that either the browser or the operating system should be in charge of making sure keyboard focus is perceivable to keyboard users. You might think that it's best for devs not to overwrite focus styles at all. However, if your website is customizing the look of inputs, there's a good chance that the default focus ring won't actually be visible to your users.
This is the situation we found ourselves in at NoRedInk, and what follows is what we did to improve things.
The Problem
Borders
At NoRedInk, both our primary and secondary buttons feature blue (specifically, #0A64FF) borders. On a Mac using Chrome, this particular blue color on the edge of the button essentially makes the default focus rings invisible.
Can you tell the difference between these two pictures? The second one has a focus ring, but if the pictures weren't side by side, there's no way you would know.
Okay, you might be thinking, don't have blue buttons. However, changing the button color, even if it were feasible from a branding standpoint, doesn't necessarily solve the problem. The outline color that's used for the default focus ring depends on the browser stylesheet, the operating system, and user settings.
Personally, I have my macOS accent color set to pink, which results in a focus ring that disappears against NoRedInk's danger button style.
Backgrounds
Even if we could customize all of our buttons, inputs, and components so that the border and the focus ring outline always showed cleanly against each other, we still wouldn't have solved the entire problem.
This is because there's not only the question of the focus indicator showing up against an input to consider: we also need to consider the contrast of the focus indicator against the background color of an input's container.
The importance of taking the background color into account became more apparent to us at NoRedInk when we started working on a redesign of NoRedInk's logged out home page that made heavy use of blue and navy backgrounds.
Some browsers have implemented two-toned focus rings that will show up clearly on different backgrounds, but there are major browsers that haven't.
Here are two screenshots of the same link being actively focused. The first screenshot, taken in Chrome, shows a focus indicator. The second screenshot, taken in Safari, shows only how a focus indicator can become truly and totally indistinguisable from a background.
Problem summary
If we are customizing input styles, we probably also need to make sure that our focus ring (1) has enough contrast with the edge color of the input and (2) has enough contrast with the input's container's background color.
Approach
While we could have customized the focus ring color for every input and background color individually, we worried that having the focus indicator appear differently in different contexts would make it harder for folks to understand the meaning of the indicator.
Consistency in UX is really important for usability in general. We didn't want a user to ever have to hunt for their focus. Keeping the focus indicator colors consistent and vivid helped us achieve this goal, and using a two-tone indicator allowed us to have a familiar look & feel everywhere.
Reducing cognitive load is also important for usability: folks who don't use the keyboard for most of their interactions shouldn't be distracted by a weird, bright ring that follows them around as they interact.
The Accessibility Team's designer, Ben Dansby, crafted a high-contrast two-toned focus ring that would appear only for users whose last interaction with the application indicated that they were keyboard users.
Ben used red (#e70d4f) and white (#ffffff) for the two tones. These colors don't strictly guarantee sufficient contrast for all possible inputs, but it's straightfoward to check that our specific color palette will work well with these specific focus ring colors.
Ellie with elm-charts code that produced the diagram
Learn more about contrast requirements in the WebAIM article "Contrast and Color Accessibility".
Implementation
The two-toned focus ring Ben made used box-shadow to create a red and white outline with gently curved corners:
[ Css.borderRadius (Css.px 4) , Css.property "box-shadow" <| "0 0 0px 3px " ++ toCssString Colors.white ++ ", 0 0 0 6px " ++ toCssString Colors.red ]
We want the focus ring to only show for keyboard users, so we use the :focus-visible pseudoselector when attaching these styles.
However, :focus-visible will result in the focus ring showing for text areas and text inputs regardless of whether the user last used a key for navigation or the mouse for navigation.
We wanted keyboard users' text input focus clearly indicated with the new candy-cane bright indicator alongside our usual subtle blue focus effect.
Blurred text input:
Text input focused by a click:
Text input focused by a key event:
This required a more involved approach, beyond just using :focus-visible and changing the box-shadow.
We needed to keep track of the last event type manually
We needed to not overwrite the box-shadow for text input when showing the focus ring
To accomplish the first of these goals, we stored a custom type type InputMethod = Keyboard | Mouse on the model and used Browser.Events.onKeyDown and Browser.Events.onMouseDown to set the InputMethod. We used different styles based on the InputMethod. Since we didn't want, say, arrow events within a textarea to change the user's InputMethod, we also added some light logic based on the tagName of the event target.
For the second of these goals, we needed to be able to customize focus ring styles for inputs that already had box-shadow styles. This work needed to happen one component at a time.
For example, styles for the text input might be applied as follows:
forKeyboardUsers : List Css.Global.Snippet forKeyboardUsers = [ Css.Global.class "nri-input:focus-visible" [ [ "0 0 0 3px " ++ toCssString Colors.white , "0 0 0 6px " ++ toCssString Colors.red , "inset 0 3px 0 0 " ++ toCssString Colors.glacier ] |> String.join "," |> Css.property "box-shadow" , ... ] , ... ] forMouseUsers : List Css.Global.Snippet forMouseUsers = [ Css.Global.everything [ Css.outline Css.none ] , Css.Global.class "nri-input:focus-visible" [ Css.property "box-shadow" ("inset 0 3px 0 0 " ++ toCssString Colors.glacier) , ... ] , ... ]
Now we have nice focus styles for keyboard users, nice focus styles for mouse users, as well as nice blurred styles! Of course, these are just the styles for our text input. There are lots more components to consider!
This is the kind of change where having a library of example uses of every shared component becomes super useful. Having one view to go to to check all the focus rings makes it straightforward -- although tedious -- to make sure that the focus ring will look great everywhere.
For us, we discovered that we needed a "tight" focus ring as well, where the box shadow is more inset, for cases where the ring would otherwise overlap other important content.
[ Css.borderRadius (Css.px 4) , Css.property "box-shadow" <| "inset 0 0 0 2px " ++ toCssString Colors.white ++ ", 0 0 0 2px " ++ toCssString Colors.red ]
We found also that some of our components already had border radiuses, and changing the border radious to 4px so that the focus ring would be nicely rounded was worse than keeping the initial border radius. This meant more per-component customization!
Removing the outline
You may have noticed that so far, none of the code samples for keyboard styles have actually hidden the default browser outline focus indicator. This is an area where we initially made an error: we naively added outline: none, thinking that our fancy new two-toned box-shadow-based focus ring would suffice.
We were wrong!
We forgot to consider and failed to test cases where users are in OS-based high contrast modes. High contrast modes essentially limit the colors that users are shown -- the mode is not inherently high contrast, since the user can customize the palette that is used -- by removing extraneous styling and forcing styles to match the given palette.
Guess what counts as extraneous? The box-shadow comprising our two-toned focus ring!
And if you set outline: none, the outline will not show in high contrast mode either.
Instead of setting outline: none, we need to change the outline to be transparent for keyboard users: Css.outline3 (Css.px 2) Css.solid Css.transparent. The transparent color will (perhaps surprisingly) be coerced to a real color in high contrast mode.
Summing it up
Customizing the look of a focus indicator can make it more useful for users, but it can take a surprising amount of work to get it just right. This work will be easier if you have a centralized place to see every common focusable element from your application at once. The two-toned focus ring in particular is great if your application has content over many different colored backgrounds, but it will be harder to implement if you commonly use box-shadows to accentuate inputs. Don't forget to consider and test high-contrast mode!
Relevant resources
WCAG 2.1 Understanding Success Criterion 2.4.7: Focus Visible
WCAG 2.1 Technique C4: Creating a two-color focus indicator to ensure sufficient contrast with all components
Tessa Kelly
@t_kelly9
0 notes
Text
Presenting Styleguide Colors
The Web Content Accessibility Guidelines (WCAG) include guidelines around how to use colors that contrast against each other so that more people can distinguish them. Color is a fuzzy topic (brains, eyes, displays, and light conditions are all complicating factors!) so it's a good idea to rely on industry-wide standards, like WCAG. The current version of the WCAG standards define algorithms for calculating luminance & contrast and set target minimum contrasts depending on the context in which the colors are used.
These algorithms should be used for their primary purpose -- ensuring that content is accessible and conforms to WCAG -- but they can also be used for other purposes, like making colors in a styleguide presentable.
Colors & Branding
NoRedInk is an education technology site, and the vast majority of our users are students. We use a lot of colors!
To keep track of our colors, we have one file that defines all of our color values with names. We use the Elm programming language on the frontend with the Elm package rtfeldman/elm-css, so our color file looks something like this:
module Nri.Colors exposing (..) import Css exposing (Color) redLight : Color redLight = Css.hex "#f98e8e" redMedium : Color redMedium = Css.hex "#ee2828" ...
(But we have around 70 named colors instead of two.)
We also have a styleguide view that shows each color in an appropriately-colored tile along with the color's name, hex value, and rgb value. These tiles help facilitate communication between Engineering and Design.
But how to present information on the color tiles? How can we make sure that the name and metadata about the color are readable on top of an arbitrarily-colored tile?
We can apply some of the color math that WCAG uses when considering contrast!
Luminance & Contrast
The calculation for "relative luminance" takes a color defined in terms of sRGB and figures out a rough approximation of perceptual brightness. "Relative luminance" is inherently conceptually squishy, but it is a reasonable representation of how prominent a given color is to the human eye.
The relative luminance of pure black is 0 and the relative luminance of pure white is 1.
Once you have the relative luminance of two colors, you're ready to figure out the contrast ratio between them.
(L1 + 0.05) / (L2 + 0.05)
L1 is the relative luminance of the lighter of the colors, and
L2 is the relative luminance of the darker of the colors.
For black and white:
(whiteLuminance + 0.05) / (blackLuminance + 0.05) (1 + 0.05) / (0 + 0.05) 21 Css.Color -> Html msg viewColor name color = dl [ css [ -- Dimensions Css.flexBasis (Css.px 200) , Css.margin Css.zero , Css.padding (Css.px 20) , Css.borderRadius (Css.px 20) -- Internals , Css.displayFlex , Css.justifyContent Css.center -- Colors , Css.backgroundColor color , Css.color (Css.hex "#00") ] ] [ div [] [ dt [] [ text "Name" ] , dd [] [ text name ] , dt [] [ text "RGB" ] , dd [] [ text color.value ] ] ]
Ellie example 1
The content that is supposed to be showing on each tile is often totally illegible!
We know, though, which colors have the minimum and maximum luminance (black and white respectively), which means we know how to figure out whether to use black or white text on any arbitrary color tile.
At NoRedInk, we use the highContrast function from the color library tesk9/palette. tesk9/palette and rtfeldman/elm-css model colors differently, so we do need to do conversions back and forth, but the advantage is that we get nice-looking, readable color tiles without resorting to box-shadow effects or background color tricks. Depending on what rendering libraries you're using, you may or may not need to do conversions.
viewColor : String -> Css.Color -> Html msg viewColor name color = let highContrastColor = toCssColor (SolidColor.highContrast (fromCssColor color)) in dl [ css [ -- Dimensions Css.flexBasis (Css.px 200) , Css.margin Css.zero , Css.padding (Css.px 20) , Css.borderRadius (Css.px 20) -- Internals , Css.displayFlex , Css.justifyContent Css.center -- Colors , Css.backgroundColor color , Css.color highContrastColor ] ] [ div [] [ dt [] [ text "Name" ] , dd [] [ text name ] , dt [] [ text "RGB" ] , dd [] [ text color.value ] ] ]
Ellie example 2
Now the content is legible on each tile!
Legible according to which WCAG level?
I mentioned previously that context (including the target WCAG conformance level) influences the minimum level of contrast required. The highest WCAG level, AAA, requires 7:1 contrast for normal text sizes, which means if our high-contrast color generation always picks a color with at least a contrast of 7, we won't need to worry about the contextual details.
However, for colors with a luminance between 0.1 and 0.3, neither black nor white will be high-enough contrast for WCAG AAA. Either (not both!) black or white will be sufficient for WCAG AA, as the contrast is higher than 4.5.
Ellie with elm-charts code that produced the diagram
What sorts of colors might have a luminance between 0.1 and 0.3?
Relative luminance is defined as:
L = 0.2126 * R + 0.7152 * G + 0.0722 * B where R, G and B are defined as:
if RsRGB - if GsRGB - if BsRGB and RsRGB, GsRGB, and BsRGB are defined as:
RsRGB = R8bit/255
GsRGB = G8bit/255
BsRGB = B8bit/255
Relative luminance definition
I don't want to dig into the details of relative luminance too much, but it's worth paying attention to the different weights for red, green, and blue in the equation. Since the weight for red is 0.2126, pure red falls right in the zone where it cannot be used for WCAG AAA-conformant normal text.
Name RGB color Luminance White contrast Black contrast Red (255, 0, 0) 0.2126 3.99 5.25 Green (0, 255, 0) 0.7152 1.37 15.3 Blue (0, 0, 255) 0.0722 8.59 2.44
Going Further
There is lots more we could do with these color tiles. We could print the color value in other color spaces (if using tesk9/palette, this is easy to do with SolidColor.toHex and SolidColor.toHSLString). We could add a grayscale toggle (see SolidColor.grayscale) to help folks consider if they're using only color to indicate meaning (see "Understanding Success Criterion 1.4.1: Use of Color"). We could organize colors by purpose, by hue, by luminance, or by some combination thereof. We could add a chart showing all our colors & their contrast with all of our other colors, so it's easy for designers to check which colors they can use in combination with other colors. We could also consider the user experience we want when users have adjusted operating system-level color settings, like the popular Windows high contrast mode (learn more about Windows high contrast mode specifically in "The Guide To Windows High Contrast Mode" by Cristian Díaz in Smashing Magazine).
Contrast & luminance values are key building blocks in presenting colors in a styleguide, and, luckily, they are fun values to explore as well.
Future WCAG versions
Now that I've got you excited about WCAG 2.1's contrast calculation, I should also warn you that the 3.0 version of the color guidelines will almost certainly change dramatically. Until WCAG 3.0 is much further along, you likely do not need to understand the changes. The new version promises to be interesting!
If you'd like to play with the WCAG 3.0 Advanced Perception of Color Algorithm (APCA), the website Contrast tools is a nice place to start.
Future CSS properties
Someday, it will be possible to select high-enough contrast colors for a given context directly in CSS with color-contrast(). Watch this snippet from Adam Argyle's 2022 State of CSS presentation to learn more. Be sure to check support for color-contrast before using it anywhere user-facing, though.
Tessa Kelly @t_kelly9
0 notes
Text
SVGs as Elm Code
Moving SVGs out of the file system and into regular Elm code can make icons easier to manage, especially if you find you need to make accessibility improvements.
Imagine we have an arbitrary SVG file straight from our Design team’s tools:
<?xml version="1.0" encoding="utf-8"?><svg version="1.1" id="Layer_1" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" x="0px" y="0px" viewbox="0 0 21 21" style="enable-background:new 0 0 21 21;" xml:space="preserve"><style type="text/css"> .st0{fill:#FFFFFF;stroke:#146AFF;stroke-width:2;} </style><title>star-outline</title><desc>Created with Something Proprietary 123.</desc><g id="Page-1"><g id="star-outline"><path id="path-1_1_" class="st0" d="M11.1,1.4l2.4,4.8c0.1,0.2,0.3,0.4,0.6,0.4l5.2,0.8c0.4,0.1,0.7,0.4,0.6,0.8 c0,0.2-0.1,0.3-0.2,0.4l-3.8,3.8c-0.2,0.2-0.2,0.4-0.2,0.6l0.9,5.3c0.1,0.4-0.2,0.8-0.6,0.8c-0.2,0-0.3,0-0.5-0.1l-4.7-2.5 c-0.2-0.1-0.5-0.1-0.7,0l-4.7,2.5c-0.4,0.2-0.8,0.1-1-0.3c-0.1-0.1-0.1-0.3-0.1-0.5l0.9-5.3c0-0.2,0-0.5-0.2-0.6L1.2,8.7 c-0.3-0.3-0.3-0.8,0-1c0.1-0.1,0.3-0.2,0.4-0.2l5.2-0.8c0.2,0,0.4-0.2,0.6-0.4l2.4-4.8c0.2-0.4,0.6-0.5,1-0.3 C10.9,1.1,11,1.3,11.1,1.4z"></path></g></g></svg>
Notice that there’s lots of extraneous information in the SVG — including some information that’s distinctly unhelpful! The title of the SVG ends up being used as the accessible name of the SVG — it’s more or less equivalent to an img tag’s alt. A title of “star-outline” will not help our users to understand what this icon is supposed to represent.
Compare the raw SVG value to what it might look like if rewritten as Elm code and tidied-up by a human developer:
import Svg exposing (..) import Svg.Attributes exposing (..) starOutline : Svg msg starOutline = svg [ x "0px" , y "0px" , viewBox "0 0 21 21" ] [ Svg.path [ fill "#FFF" , stroke "#146AFF" , strokeWidth "2" , d "M11.1,1.4l2.4,4.8c0.1,0.2,0.3,0.4,0.6,0.4l5.2,0.8c0.4,0.1,0.7,0.4,0.6,0.8 c0,0.2-0.1,0.3-0.2,0.4l-3.8,3.8c-0.2,0.2-0.2,0.4-0.2,0.6l0.9,5.3c0.1,0.4-0.2,0.8-0.6,0.8c-0.2,0-0.3,0-0.5-0.1l-4.7-2.5 c-0.2-0.1-0.5-0.1-0.7,0l-4.7,2.5c-0.4,0.2-0.8,0.1-1-0.3c-0.1-0.1-0.1-0.3-0.1-0.5l0.9-5.3c0-0.2,0-0.5-0.2-0.6L1.2,8.7 c-0.3-0.3-0.3-0.8,0-1c0.1-0.1,0.3-0.2,0.4-0.2l5.2-0.8c0.2,0,0.4-0.2,0.6-0.4l2.4-4.8c0.2-0.4,0.6-0.5,1-0.3 C10.9,1.1,11,1.3,11.1,1.4z" ] [] ]
Example 1 Ellie link
Once the SVG is rewritten in Elm, we can leverage the Elm type system to guarantee that icons in our application are always rendered in a consistent way. By exposing the Icon type but not exposing the Icon constructor, we can ensure that there's only one way to produce HTML from an Icon. This strategy is the opaque type pattern, which you can learn more about in former NoRedInk engineer Charlie Koster's blog post series on advanced types in Elm and in the Elm Radio podcast's Intro to Opaque Types episode.
module Icons exposing (Icon, toHtml, starOutline) type Icon = -- `Never` is used here so that our Icon type doesn't need a type hole. Essentially, the `Never` is saying "this kind of Svg cannot produce messages ever" Icon (Svg Never) toHtml : Icon -> Html msg toHtml (Icon icon) = -- "Html.map never" transforms `Svg msg` into `Svg Never` Html.map never icon starOutline : Icon -- notice the type changed starOutline = svg ... |> Icon
Now that we've got consistently-rendered icons, we can start thinking about what an accessible way to render the SVGs might be. Carie Fisher’s article Accessible SVGs - Perfect Patterns For Screen Reader Users is the resource to use when considering how to render SVGs in an accessible way. We will be using Pattern 5, <svg> + role="img" + <title>, to ensure that our meaningful icons have appropriate text alternatives. (You might also want to read through the WAI’s Images Tutorial if you haven't already — it might surprise you!)
We need to conditionally insert a title element into the list of SVG children — which means we need to change how we’re modeling Icon. We can easily & safely do this, though, because we’ve used an opaque type to minimize API disturbances.
type Icon = Icon { attributes : List (Attribute Never) , label : Maybe String , children : List (Svg Never) } toHtml : Icon -> Html msg toHtml (Icon icon) = case icon.label of Just label -> svg icon.attributes (Svg.title [] [ text label ] :: icon.children) |> Html.map never Nothing -> svg icon.attributes icon.children |> Html.map never emptyStar : Icon emptyStar = Icon { attributes = [ x "0px" , y "0px" , viewBox "0 0 21 21" ] , label = Nothing , children = [ Svg.path [ fill "#FFF" , stroke "#146AFF" , strokeWidth "2" , d "M11.1,1.4l2.4,4.8c0.1,0.2,0.3,0.4,0.6,0.4l5.2,0.8c0.4,0.1,0.7,0.4,0.6,0.8 c0,0.2-0.1,0.3-0.2,0.4l-3.8,3.8c-0.2,0.2-0.2,0.4-0.2,0.6l0.9,5.3c0.1,0.4-0.2,0.8-0.6,0.8c-0.2,0-0.3,0-0.5-0.1l-4.7-2.5 c-0.2-0.1-0.5-0.1-0.7,0l-4.7,2.5c-0.4,0.2-0.8,0.1-1-0.3c-0.1-0.1-0.1-0.3-0.1-0.5l0.9-5.3c0-0.2,0-0.5-0.2-0.6L1.2,8.7 c-0.3-0.3-0.3-0.8,0-1c0.1-0.1,0.3-0.2,0.4-0.2l5.2-0.8c0.2,0,0.4-0.2,0.6-0.4l2.4-4.8c0.2-0.4,0.6-0.5,1-0.3 C10.9,1.1,11,1.3,11.1,1.4z" ] [] ] }
Example 2 Ellie Link
At this point, the internals of Icon can handle a text alternative being present, but there’s no way from the API to actually set the text alternative . We need to expose a way to set the value of the label of emptyStar and any other icons we later create.
We could change emptyStar to take a Maybe String, or we could add a withLabel : String → Icon → Icon helper, or we could move the label value off of the Icon type and thread the value through toHtml.
At NoRedInk, we use the withLabel : String → Icon → Icon pattern, but any of these patterns could work.
withLabel : String -> Icon -> Icon withLabel label (Icon icon) = Icon { icon | label = Just label }
Once we have a way to add the text alternative to the Icon, we’re ready for the “role” portion of the <svg> + role="img" + <title> pattern.
import Accessibility.Role as Role -- this is from tesk9/accessible-html toHtml : Icon -> Html msg toHtml (Icon icon) = case icon.label of Just label -> svg (Role.img :: icon.attributes) (Svg.title [] [ text label ] :: icon.children) |> Html.map never Nothing -> svg icon.attributes icon.children |> Html.map never
Example 3 Ellie Link
Now, our functional icons should render nicely with a title and with the appropriate role! (Although if we were supporting Internet Explorer, we would also want to add focusable=false)
We still have the decorative icons to consider, though. We can mark these decorative icons as hidden in the accessibility tree so that assistive technologies know to ignore it with aria-hidden=true:
toHtml : Icon -> Html msg toHtml (Icon icon) = case icon.label of Just label -> svg (Role.img :: icon.attributes) (Svg.title [] [ text label ] :: icon.children) |> Html.map never Nothing -> svg (Aria.hidden True :: icon.attributes) icon.children |> Html.map never
Example 4 Ellie Link
And that’s it!
Over time, it’s likely that an Elm-based SVG icon library will need to support more and more customization: colors, styles, attributes, animations, hover effects. All of these and more can be added to the Icon opaque type, without breaking current icons.
There we have it: tidy icon modeling leading to tidy icons.
Tessa Kelly
@t_kelly9
0 notes
Text
Funding the Roc Programming Language
At NoRedInk, we're no strangers to cutting-edge technology or to funding open-source software. When React was released in the summer of 2013, we were early adopters. Shortly after that, we got into Elm—really into it—and we began not only sponsoring Elm conferences, but also funding Elm's development for several years by directly paying its creator, Evan Czaplicki, to develop the language full-time.
I'm beyond thrilled to announce that NoRedInk is now making a similar investment in the Roc programming language. Beginning in April, my job at NoRedInk will become developing Roc full-time!
I created Roc in 2018 because I wanted an Elm-like language for use cases that are out of scope for Elm. Roc compiles to machine code instead of to JavaScript, and at NoRedInk we're interested in using it on the server to go with our Elm frontend—as well as for some command-line tooling. Although Roc isn't ready for production use yet, funding its development like this will certainly get it to that point sooner.
It's impossible to overstate how excited I am about this opportunity. When I laid out a vision for Roc in a 2020 online meetup, I assumed I'd be developing it outside of work with a couple of other volunteers for the foreseeable future. I was stunned by the reaction to the video; many people started getting involved in developing the compiler—most of whom had never worked on a compiler before!—and one brave soul even did Advent of Code in Roc that year.
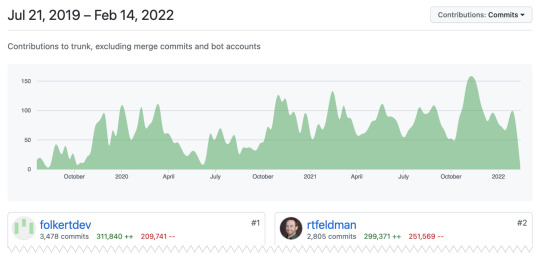
Today Roc has 12,660 commits. The top 5 committers all have either hundreds or thousands of commits, and even though I had a considerable head start, I no longer have the most commits in the repo - the excellent Folkert de Vries does. I'm massively grateful to every contributor for making this project exist, and although commits are easy to count, Roc's design and community would not be what they are without so many wonderful contributions outside the code base—in video chats, on GitHub issues, and of course on Roc chat. Thank you, all of you, for making Roc the language it is today.
The language still has a ways to go before it's ready for production use, but this investment from NoRedInk is both a game-changer for the project's development as well as a strong vote of confidence in Roc's future. Most companies benefit from the open-source ecosystem and give little to nothing back; I feel great about working for a company that builds a product that helps English teachers while making serious investments in open-source software.
By the way, we're hiring!
If you're interested in learning more about Roc, trying it out, or getting involved in its development, roc-lang.org has all the details. I'm so excited for the future, and can't wait for this language to reach its full potential!

Richard Feldman
@rtfeldman
0 notes
Text
Tuning Haskell RTS for Kubernetes, Part 2
We kept on tweaking our Haskell RTS after we reached "stable enough" in part 1 of this series, trying to address two main things:
Handle bursts of high concurrency more efficiently
Avoid throttling due to CFS quotas in Kubernetes
If you're unfamiliar with it, here's a comprehensive article from Omio
We also learned some interesting properties of the parallel garbage collector in the process.
TL;DR
Profile your app in production
Threadscope is your friend
Disabling the parallel garbage collector is probably a good idea
Increasing -A is probably a good idea
-N⟨x⟩ == available_cores is bad
We ran into this problem in the previous post of our series, where we tried to set:
-N3
--cpu-manager-policy=static
requests.cpu: 3
requests.limits: 3
We tried this configuration because we were hoping to disable Kubernetes CFS quotas and only rely on CPU affinity to prevent noisy neighbours and worker nodes overload.
Trying this out I saw p99 response times rise from 16ms to 29ms, enough to affect stability of our upstream services.
Confused, I reached out for help on the Haskell Discourse.
Threadscope
Folks on Discourse were quick to help me drill down into GC as a possible cause for slowness, but I had no idea how to go about tuning it, if not at random.
The first helpful advice I got was to use Threadscope, a graphical viewer for thread profile information generated by GHC.
Capturing event logs for ThreadScope
The first thing I had to do to be able to use ThreadScope was to build a version of our app with the -eventlog flag in our package.yaml:
executables: quiz-engine-http: dependencies: ... ghc-options: - -threaded + - -eventlog main: Main.hs ...
This makes it so our app ships with the necessary instrumentation, which we can turn on and off at launch.
Then I had to enable event logging by launching our app with the -l RTS flag, like so:
$ quiz-engine-http +RTS -N3 -M5.8g -l -RTS
This makes it so Haskell logs events to a file while it's running. I decided to make a single Pod use these settings alongside the rest of our fleet, taking production traffic.
Last, I had to grab the event log, which gets dumped to a file like your-executable-name.eventlog. That could be done with kubectl cp.
The log grew around 1.2MB/s, and Threadscope takes a while to load large event logs, so I went for short recording sessions of around 3min.
Launching ThreadScope
With the event log in hand, I could finally launch ThreadScope:
$ threadscope quiz-engine-http.eventlog
ThreadScope showed me a chart of app execution vs GC execution and a bunch of metrics.
Interesting metrics
Productivity was the first interesting metric I saw. It tells you what % of time your actual application code is running, the remainder of which is taken over by GC.
In our case, we had 88.2% productivity, so 11.8% of the time our app was doing nothing, waiting for the garbage collector to run.
Our average GC pause was 20μs long, or 0.0002s. Really fast.
GHC made 103,060 Gen 0 collections in the 210s period, which is a bit ridiculous. This means we did 490 pauses per second, or one pause every 2ms. Our app's average response time is 1.8ms, so with 3 capabilities, we were running GC on average once every 6 requests.
In comparison, we made 243 Gen 1 collections, so a little over 1s. Gen 1 was OK.
Is the parallel GC helping me?
Another quick suggestion I got on Discourse was disabling the parallel garbage collector, so I went on to test that, with Threadscope by my side.
I used the -qg RTS flag to disable parallel GC, and -qn⟨x⟩ for keeping it enabled, but only using ⟨x⟩ threads.
This is how ThreadScope metrics and our 99th percentile response times were affected by the different settings:
RTS setting p99 productivity g0 pauses/s avg g0 pause -N3 -qn3 29ms 88.2% 488 0.2ms -N3 -qn2 21ms 89.8% 558 0.1ms -N3 -qg 17ms 88.9% 593 0.1ms
Pauses times seemed to improve, but we don't have enough resolution in Threadscope to see whether it was a 0.01ms improvement, or a full 0.1ms improvement.
Collections got more frequent, for reasons unknown
Productivity lowered when we went down from 2 threads to 1 thread
p99 response time was the best when the parallel GC was disabled
Conclusion: the parallel GC wasn't helping us at all
Is our allocation area the right size?
The last of the helpful suggestions we got on Discourse was tweaking -A, which controls the size of Gen 0.
The docs warn:
Increasing the allocation area size may or may not give better performance (a bigger allocation area means worse cache behaviour but fewer garbage collections and less promotion).
What does cache behavior mean here? Googling led me to this StackOverflow answer by Simon Marlow explaining that using -A higher than the CPU's L2 cache size means we lower the L2 hit rate.
Our AWS instances are running Intel Xeon Platinum 8124M, which has 1MB of L2 cache per core, and the default -A is 1MB, so any increase would already spell a reduced L2 hit rate for us.
We compared 3 different scenarios:
RTS setting p99 productivity g0 pauses/s avg g0 pause -N3 -qn3 -A1m 29ms 88.2% 488 0.2ms -N3 -qn3 -A3m 18ms 95.6% 144 0.2ms -N3 -qn3 -A128m 16ms 99.6% 1.2 2ms
The L2 cache hit rate penalty didn't seem to affect the sorts of computations we are running, as -A128m still has the fastest p99 response time.
-A128m seemed a bit ridiculous, but we had memory to spare, so we went with it. The 2ms average pause was close to our p75 response time, so it seemed fine to stop the world once per second for the time of 1 request slow'ish request to take out the trash.
Unlocking higher values for -N
Our app had been having hiccups in production. For a second a database would get slow and would cause our Haskell processes, which usually handle around 2-4 in-flight requests at a time, to flood with 20-40 of them.
Eating through this pile of requests would often take less than a minute, but would then cascade upstream into request queueing and some high-latency alerts, informing us that a high percentage of our users were having a frustrating experience with our website.
Whenever this happened, we did not see CPU saturation. CPU usage remained around 65-70%. It made me think our Haskell threads were not being effective, and higher parallelism could help us leverage our cores better, even at the cost of some context switching.
I was eager to try a higher -N than the taskset core count I gave to our processes, but was unable to until now, because setting -N higher than the core count would bring the productivity metric down quickly, and would increase p99 response times.
With our new findings, and a close eye on nonvoluntary_ctxt_switches in /proc/[pid]/status, I managed to get to us to -N6, which seemed enough to reduce the frequency of our hiccups to a few times a month, versus daily.
These were our final RTS settings, with -N6, compared to what we started:
RTS setting p99 productivity g0 pauses/s avg g0 pause -N3 -qn3 -A1m 29ms 88.2% 488 0.2ms -N6 -qg -A128m 13ms 99.5% 0.8 4.2ms
These numbers were captured on GHC 8.8.4. We did upgrade to GHC 8.10.6 to try the new non-moving garbage collector, but saw no improvement.
Conclusion
Haskell has pretty good instrumentation to help you tune garbage collection. I was intimidated by the prospect of trying to tune it without building a mental model of all the settings available first, but profiling our workload in production proved easy to set up and quick to iterate on.
Juliano Solanho @julianobs Engineer at NoRedInk
Thank you Brian Hicks and Ju Liu for draft reviews and feedback! 💜
0 notes
Text
Tuning Haskell RTS for Kubernetes, Part 1
We're running Haskell in production. We've told that story before.
We are also running Haskell in production on Kubernetes, but we never talked about that. It was a long journey and it wasn't all roses, so we're going to share what we went through.
TL;DR
Configure Haskell RTS settings:
Match -N⟨x⟩ to your limits.cpu
Match -M⟨size⟩ to your limits.memory
You can set them between +RTS ... -RTS arguments to your program, like +RTS -M5.7g -N3 -RTS.
Our scenario
We had been running Haskell in production before Kubernetes. Each application was the single inhabitant of its own EC2 instance. Things were smooth. We launched the executable, provisioned what looked like fast enough instances, and things just worked.
We could have kept our conditions pretty much the same when moving to Kubernetes by giving our Haskell Pods as much requests.memory and requests.cpu as our worker nodes, so each machine runs a single Pod.
We had two main incentives to run small Pods, all packed together into beefier worker nodes:
Our traffic is very seasonal, and even within a single day we go from 1000 requests per minute at night to close to 500,000 requests per minute when both east- and west-coast are at school. If we can scale down to the smallest footprint at idle, we save money.
We use Datadog for infrastructure monitoring, and Datadog charges customers on a per-host basis. If we used small worker nodes, at peak traffic we'd be needing so many of them that our Datadog bill would become prohibitive.
We wanted effective resource utilization at idle and at peak while keeping costs under control.
We googled for tips, war stories or even fanfiction on Haskell in Kubernetes, and the two ⁽¹⁾⁽²⁾ results we found were pretty old, and didn't get into any specifics on how Haskell itself behaves in a containerized environment, so it seemed like there'd be no dragons here.
With this in mind we launched our highest traffic Haskell service in prod with:
2 cores
200MB memory
70% target CPU usage on our Horizontal Pod Autoscaler
And called it a day.
Fires
After we went live we saw:
😨 Terrible performance: everything was slow
😳 Frequent container restarts: it looked like the GC wasn't working at all and the processes were getting OOMKilled frequently
🤕 Horrendous performance at scale-up: When we got bursts of traffic, response times would shoot up and cause request queueing in our upstream service
This last one was kind of obvious. At 70% target CPU usage, even if our app was able to saturate the machine's CPU to 99.99% without slowing down, and even if it had linear rate for requests to CPU usage, we'd only have room for 30% growth in traffic while waiting for a scale-up. This was not enough slack, due to two main factors:
AWS EKS takes close to 3 minutes to scale up Pods when worker node scaling is also necessary. 3 minutes is a lot time when we're ramping up 500x in a few hours. At peak season, we more than double our traffic every 3 minutes during ramp-up when the East Coast is starting school.
It's partly fixable by using the cluster-overprovisioner pattern, which we do, but outside of 1-node scale-ups, the option seems to be tweaking AWS VPC CNI's startup, which we haven't looked into yet.
Kubernetes has no concept of create-before-destroy. Shifting Pods around for Cluster Autoscaler's bin-packing operation and for kubectl drain works by first terminating one or more Pods, then letting the scheduler recreate them on another Node. Say we have 3 Pods alive, between terminating one Pod and going Ready with its substitute, our compute capacity is reduced by 33%.
It might be fixable by writing our own create-before-destroy operation, forking cluster-autoscaler to use that instead, and also using it to write our own drain script. Things like Pod eviction due to taints will be out of reach, but that might be acceptable. Regardless, we chose not to go down that path.
So we lowered our target CPU usage to 50%, and scale-ups were safe.
While fighting frequent container restarts, we kept being less conservative about memory, going all the way up to 2GB per core. Our app consistently used ~100MB of RAM before moving to Kubernetes, so we were surprised. It might be we introduced space/memory leaks at the same time as we moved to Kubernetes, but also, the Haskell garbage collector didn't seem to be aware it was reaching a memory limit. So we started looking at Haskell RTS GC settings.
While diagnosing terrible performance, we noticed Haskell was spinning up dozens of threads for each tiny Pod, and we knew from working with the Elm compiler (also written in Haskell), that Haskell doesn't care about virtualized environments when figuring out the capabilities of the machine it's running on. We figured something similar was at play and we might have to tune the RTS.
Tuning the RTS
The two settings that helped us get over terrible performance and frequent container restarts were:
-M⟨size⟩
This setting tells the Haskell RTS what should be the maximum Heap size, which also informs other garbage collector parameters.
So we set the maximum heap size a bit below our Pods' limits.memory, and the GC started acting more aggressively to prevent us from going over limits.memory. We managed to stop getting OOMKilled.
Eventually, as sneakily as they appeared, our space or memory leaks went away, and we went down to a stable 200MB of memory usage per process.
-N⟨x⟩
The docs are a bit misleading here:
Use ⟨x⟩ simultaneous threads when running the program
Without reading further, we thought setting -N2 would get us 2 threads for our 2-core Pods, but we were still seeing more than 10 threads per process.
⟨x⟩ here is what the RTS calls capabilities, which the docs clarify further on:
A capability is animated by one or more OS threads; the runtime manages a pool of OS threads for each capability, so that if a Haskell thread makes a foreign call (see Multi-threading and the FFI) another OS thread can take over that capability.
Normally ⟨x⟩ should be chosen to match the number of CPU cores on the machine
Ok, that's expected then, albeit a bit weird that it's such a big pool for only two capabilities.
Regardless, performance was actually good again with -N matching our CPU count.
In the end, we landed on 3 cores per Pod and -N3: Kubernetes reserves a few hundred millicores of each worker node for its manager process (the kubelet) and this meant we'd only be able to use 14 cores on a 16 cores node. 2 cores would go to waste, unless we had enough pebbles in our cluster, which we didn't.
Obligatory detour through CFS Throttling
At the same time we also learned about CFS throttling, and learned to keep an eye on how much we were getting throttled. For -N2 and 2 cores, it was infrequent.
In the hopes of disabling CFS completely, like Zalando did, we did trial running our Nodes with --cpu-manager-policy=static. This uses taskset to give Pods exclusive access to certain cores.
Our idea was to constrain high throughput Pods to their own cores, in order to spare processes from noisy neighbours and prevent worker nodes from overloading.
We saw a steep drop in performance, so we backed away. We ended up figuring out why, but that's the subject of another blog post. (hint: it's the parallel GC)
Production-ready enough
Performance was good
Containers weren't restarting anymore
We were churning out close to 500,000 requests per minute on 7 Pods, each with 3 capabilities and eating less than 200MB of RAM
Autoscaling was smooth
It wasn't the end of our ramblings on the Haskell RTS options page, we still had daily incidents where Haskell would slow down for a few seconds, cause upstream request queueing and trigger our fire alerts, but that's a story for another day.
Juliano Solanho @julianobs Engineer at NoRedInk
Thank you, Brian Hicks, Ju Liu and Richard Feldman for draft reviews and feedback! ❤️
1 note
·
View note
Text
Haskell for the Elm Enthusiast
Many years ago NRI adopted Elm as a frontend language. We started small with a disposable proof of concept, and as the engineering team increasingly was bought into Elm being a much better developer experience than JavaScript more and more of our frontend development happened in Elm. Today almost all of our frontend is written in Elm.
Meanwhile, on the backend, we use Ruby on Rails. Rails has served us well and has supported amazing growth of our website, both in terms of the features it supports, and the number of students and teachers who use it. But we’ve come to miss some of the tools that make us so productive in Elm: Tools like custom types for modeling data, or the type checker and its helpful error messages, or the ease of writing (fast) tests.
A couple of years ago we started looking into Haskell as an alternative backend language that could bring to our backend some of the benefits we experience writing Elm in the frontend. Today some key parts of our backend code are written in Haskell. Over the years we’ve developed our style of writing Haskell, which can be described as very Elm-like (it’s also still changing!).
🌳 Why be Like Elm?
Elm is a small language with great error messages, great documentation, and a great community. Together these make Elm one of the nicest programming languages to learn. Participants in an ElmBridge event will go from knowing nothing of the language to writing a real application using Elm in 5 hours.
We have a huge amount of Elm code at NoRedInk, and it supports some pretty tricky UI work. Elm scales well to a growing and increasingly complicated codebase. The compiler stays fast and we don’t lose confidence in our ability to make changes to our code. You can learn more about our Elm story here.
📦 Unboxing Haskell
Haskell shares a lot of the language features we like in Elm: Custom types to help us model our data. Pure functions and explicit side effects. Writing code without runtime exceptions (mostly).
When it comes to ease of learning, Haskell makes different trade-offs than Elm. The language is much bigger, especially when including the many optional language features that can be enabled. It’s entirely up to you whether you want to use these features in your code, but you’ll need to know about many of them if you want to make use of Haskell’s packages, documentation, and how-tos. Haskell’s compiler errors typically aren’t as helpful as Elm’s are. Finally, we’ve read many Haskell books and blog posts, but haven’t found anything getting us from knowing no Haskell to writing a real application in it that’s anywhere near as small and effective as the Elm Guide.
🏟️ When in Rome, Act Like a Babylonian
Many of the niceties we’re used to in Elm we get in Haskell too. But Haskell has many additional features, and each one we use adds to the list of things that an Elm programmer will need to learn. So instead we took a path that many in the Haskell community took before us: limit ourselves to a subset of the language.
There are many styles of writing Haskell, each with its own trade-offs. Examples include Protolude, RIO, the lens ecosystem, and many more. Our approach differs in being strongly inspired by Elm. So what does our Elm-inspired style of writing Haskell look like?
🍇 Low hanging fruit: the Elm standard library
Our earliest effort in making our Haskell code more Elm-like was porting the Elm standard library to Haskell. We’ve open-sourced this port as a library named nri-prelude. It contains Haskell counterparts of the Elm modules for working with Strings, Lists, Dicts, and more.
nri-prelude also includes a port of elm-test. It provides everything you need for writing unit tests and basic property tests.
Finally, it includes a GHC plugin that makes it so Haskell’s default Prelude (basically its standard library) behaves like Elm’s defaults. For example, it adds implicit qualified imports of some modules like List, similar to what Elm does.
🎚️ Effects and the Absence of The Elm Architecture
Elm is opinionated in supporting a single architecture for frontend applications, fittingly called The Elm Architecture. One of its nice qualities is that it forces a separation of application logic (all those conditionals and loops) and effects (things like talking to a database or getting the current time). We love using The Elm Architecture writing frontend applications, but don’t see a way to apply it 1:1 to backend development. In the F# community, they use the Elm Architecture for some backend features (see: When to use Elmish Bridge), but it’s not generally applicable. We’d still like to encourage that separation between application logic and effects though, having seen some of the effects of losing that distinction in our backend code. Read our other post Pufferfish, please scale the site! if you want to read more about this.
Out of many options we’re currently using the handle pattern for managing effects. For each type of effect, we create a Handler type (we added the extra r in a typo way back and it has stuck around. Sorry). We use this pattern across our libraries for talking to outside systems: nri-postgresql, nri-http, nri-redis, and nri-kafka.
Without The Elm Architecture, we depend heavily on chaining permutations through a stateful Task type. This feels similar to imperative coding: First, do A, then B, then C. Hopefully, when we’re later on in our Haskell journey, we’ll discover a nice architecture to simplify our backend code.
🚚 Bringing Elm Values to Haskell
One way in which Haskell is different from both Elm and Rails is that it is not particularly opinionated. Often the Haskell ecosystem offers multiple different ways to do one particular thing. So whether it’s writing an http server, logging, or talking with a database, the first time we do any of these things we’ll need to decide how.
When adopting a Haskell feature or library, we care about
smallness, e.g. introduce new concepts only when necessary
how “magical” is it? E.g. How surprising is it?
How easy is it to learn?
how easy is it to use?
how comprehensible is the documentation?
explicitness over terseness (but terseness isn’t implicitly bad).
consistency & predictability
“safety” (no runtime exceptions).
Sometimes the Haskell ecosystem provides an option that fits our Elm values, like with the handle pattern, and so we go with it. Other times a library has different values, and then the choice not to use it is easy as well. An example of this is lens/prism ecosystem, which allows one to write super succinct code, but is almost a language onto itself that one has to learn first.
The hardest decisions are the ones where an approach protects us against making mistakes in some way (which we like) but requires familiarity with more language features to use (which we prefer to avoid).
To help us make better decisions, we often try it both ways. That is, we’re willing to build a piece of software with & without a complex language feature to ensure the cost of the complexity is worth the benefit that the feature brings us.
Another approach we take is making decisions locally. A single team might evaluate a new feature, and then demo it and share it with other teams after they have a good sense the feature is worth it. Remember: a super-power of Haskell is easy refactorability. Unlike our ruby code, going through and doing major re-writes in our Haskell codebase is often an hours-or-days-long (rather than weeks-or-months-long) endeavor. Adopting two different patterns simultaneously has a relatively small cost!
Case studies in feature adoption:
🐘 Type-Check All Elephants
One example where our approach is Elm-like in some ways but not in others is how we talk to the database. We’re using a GHC feature called quasiquoting for this, which allow us to embed SQL query strings directly into our Haskell code, like this:
{-# LANGUAGE QuasiQuotes #-} module Animals (listAll) where import Postgres (query, sql) listAll :: Postgres.Handler -> Task Text (List (Text, Text)) listAll postgres = query postgres [sql|SELECT species, genus FROM animals|]
A library called postgresql-typed can test these queries against a real Postgres database and show us an error at compile time if the query doesn’t fit the data. Such a compile-time error might happen if a table or column we reference in a query doesn’t exist in the database. This way we use static checks to eliminate a whole class of potential app/database compatibility problems!
The downside is that writing code like this requires everyone working with it to learn a bit about quasi quotes, and what return type to expect for different kinds of queries. That said, using some kind of querying library instead has a learning curve too, and query libraries tend to be pretty big to support all the different kinds of queries that can be made.
🔣 So Many Webserver Options
Another example where we traded additional safety against language complexity is in our choice of webserver library. We went with servant here, a library that lets you express REST APIs using types, like this:
import Servant data Routes route = Routes { listTodos :: route :- "todos" :> Get '\[JSON\] [Todo], updateTodo :: route :- "todos" :> Capture "id" Int :> ReqBody '[JSON] Todo :> Put '[JSON] NoContent, deleteTodo :: route :- "todos" :> Capture "id" Int :> Delete '[JSON] NoContent } deriving (Generic)
Servant is a big library that makes use of a lot of type-level programming techniques, which are pretty uncommon in Elm, so there’s a steep learning cost associated with understanding how the type magic works. Using it without a deep understanding is reasonably straightforward.
The benefits gained from using Servant outweigh the cost of expanded complexity. Based on a type like the one in the example above, the servant ecosystem can generate functions in other languages like Elm or Ruby. Using these functions means we can save time with backend-to-frontend or service-to-service communication. If some Haskell type changes in a backward-incompatible fashion we will generate new Elm code, and this might introduce a compiler error on the Elm side.
So for now we’re using servant! It’s important to note that what we want is compile-time server/client compatibility checking, and that’s why we swallow Servant’s complexity. If we could get the same benefit without the type-level programming demonstrated above, we would prefer that. Hopefully, in the future, another library will offer the same benefits from a more Elm-like API.
😻 Like what you see?
We're running the libraries discussed above in production. Our most-used Haskell application receives hundreds of thousands of requests per minute without issue and produces hardly any errors.
Code can be found at NoRedInk/haskell-libraries. Libraries have been published to hackage and stackage. We'd love to know what you think!
2 notes
·
View notes
Text
🌉 Bridging a typed and an untyped world
Even if you work in the orderly, bug-free, spic-and-span, statically-typed worlds of Elm and Haskell (like we do at NoRedInk, did you know we’re hiring?), you still have to talk to the wild free-wheeling dynamically-typed world sometimes. Most recently: we were trying to bridge the gap between Haskell (🧐) and Redis(🤪). Here we’ll discuss two iterations of our Redis library for Haskell, nri-redis.
All examples in this code are in Haskell and use a few functions from NoRedInk’s prelude nri-prelude. Specifically, we will use |> instead of &, Debug.toString instead of show and a few functions from Expect. Most of the example code could be real tests.
💬 Redis in Haskell
Let’s begin with a look at an earlier iteration of nri-redis (a wrapper around hedis). We are going to work with two functions get and set which have the following type signatures:
set :: Data.Aeson.ToJSON a => Text -> a -> Query () get :: Data.Aeson.ToJSON a => Text -> Query (Maybe a)
Let’s use this API for a blogging application that stored blog posts and users in Redis.
data User = User { name :: Text -- maybe more fields later } deriving (Generic, Show, Eq) data Post = Post { title :: Text -- ... } deriving (Generic, Show)
Maybe you noticed that we derive Generic for both types. We will store users and posts as JSON in Redis. Storing data as JSON in Redis is simple, and we only need an additional instance for decoding and encoding to JSON.
instance Data.Aeson.ToJSON User instance Data.Aeson.FromJSON User instance Data.Aeson.ToJSON Post instance Data.Aeson.FromJSON Post
Now how do we write something to Redis?
Redis.set "user-1" User { name = "Luke" } -- create a query |> Redis.query handler -- run the query |> Expect.succeeds -- fail the test if the query fails
We use Redis.set, which corresponds to set. We can then execute the query using Redis.query. We can read the data back using a get.
maybeUser <- Redis.get "user-1" |> Redis.query handler |> Expect.succeeds Expect.equal (Just User {name = "Luke" }) maybeUser
🐛 What can go wrong?
Now that we know how to read and write to Redis let’s look at this example. Can you spot the error?
let key1 = "user-1" let key2 = "post-1" Redis.set key1 User { name = "Obi-wan Kenobi" } |> Redis.query handler |> Expect.succeeds Redis.set key1 Post { title = "Using the force to wash your dishes" } |> Redis.query handler |> Expect.succeeds maybeUser <- Redis.get key1 |> Redis.query handler |> Expect.succeeds Expect.equal (Just User {name = "Obi-wan Kenobi"}) maybeUser -- !!! "Could not decode value in key: Error in $: parsing User(User) failed, key 'name' not found"
A runtime error?! in Haskell?! Say it ain’t so.
Maybe you spotted the bug: We are using key1 to set the post instead of key2.
First, we set the data in key1 to be a User
We then replaced it with a Post.
We fetch the data from key1 (a Post) into maybeUser.
The compiler thinks maybeUser is of type Maybe User, because we compare it with Maybe User in Expect.Equal.
At runtime, the generated code from the FromJSON instance will then fail to decode the Post’s json-serialization into User.
which will cause our program to crash.
This is not the only thing that can go wrong! Let’s consider the next example:
let users = [ ("user-1", User { name = "Obi"}) , ("user-2", User { name = "Yoda"}) ] Redis.set "user-1" users |> Redis.query handler |> Expect.succeeds maybeUser <- Redis.get "user-1" |> Redis.query handler |> Expect.succeeds Expect.equal (Just User { name = "Obi"}) maybeUser -- !!! "Could not decode value in key: Error in $: parsing User(User) failed, expected Object, but encountered Array"
We called set with users instead of a User (or called Redis’s mset on the list users). Again, this compiles but fails at runtime when we assume that we receive one User when we call get for this key.
🛡️ Can we make the bug impossible?
The previous examples showed how easy it was to write bugs with such a generic API—the program compiled in both cases but failed at runtime. The compiler couldn't save us because set and get both accept any Text as a key and only constrain the value to have an instance of To/FromJSON.
-- reminder: the API that allowed all kinds of havoc set :: Data.Aeson.ToJSON a => Text -> a -> Query () get :: Data.Aeson.ToJSON a => Text -> Query (Maybe a)
Want to set a User and fetch a list of Posts from the same key? This API will let you (and then fail loudly in production).
Ideally, we would get a compiler error that prevents mixing up keys or passing the wrong value when writing to Redis. We decided to use an Elm-ish approach, avoiding making the API too magic.
Instead of using commands directly, we introduced a new type called Redis.Api key value. Its purpose is to bind a concrete type for key and value to commands.
Let’s try to make the same mistake we made earlier, using the wrong type, with our new Redis.Api. Let’s first create such an Api.
newtype UserId = UserId Int userApi :: Redis.Api UserId User userApi = Redis.jsonApi (\userId -> "user-" ++ Debug.toString userId)
We bound UserId to User by adding a top-level definition and giving it a type signature. Additionally, we created a newtype instead of relying on Text as the key. This will guarantee that we don’t call userApi with a post key.
Now to use this, we call functions by “passing” them the new userApi. Side note: Redis.Api is a record, and we get the commands from it.
let users = [(UserId 1, User { name = "Obi"}), (UserId 2, User { name = "Yoda"})] Redis.set userApi (UserId 1) users |> Redis.query handler |> Expect.succeeds
We catch the bug at compile time without writing a test (and well before causing a fire in production).
• Couldn't match expected type ‘User’ with actual type ‘[(UserId, User)]’ | 325 | Redis.set userApi key1 users | ^^^^^
🤗 Making Tools Developer-Friendly
Our initial Redis API used a very generic type for keys and values (only constraint to implement To/FromJSON). This optimized the library for versatility but made the resulting application code less maintainable and error-prone.
Having concrete types provides the compiler with more information and therefore allows for better error messages and better maintainability (e.g., less error-prone). The API we ended up with is a balance of simplicity and safety. It’s still possible to misuse the library and get the bugs we discussed, but it guides the user towards the intended usage.
You can’t always predict how your library’s users will use your tools, so leaving them open-ended has its upsides. But if you have a specific use-case, solving it specifically will help your developers avoid pitfalls and keep them more productive.
Christoph Hermann @stoeffel Engineer at NoRedInk.
Thanks to Michael Glass @michaelglass and Jasper Woudenberg @jwoudenberg for helping building this and their support writting this blogpost! ❤️
0 notes
Text
☄️ Pufferfish, please scale the site!
We created Team Pufferfish about a year ago with a specific goal: to avert the MySQL apocalypse! The MySQL apocalypse would occur when so many students would work on quizzes simultaneously that even the largest MySQL database AWS has on offer would not be able to cope with the load, bringing the site to a halt.
A little over a year ago, we forecasted our growth and load-tested MySQL to find out how much wiggle room we had. In the worst case (because we dislike apocalypses), or in the best case (because we like growing), we would have about a year’s time. This meant we needed to get going!
Looking back on our work now, the most important lesson we learned was the importance of timely and precise feedback at every step of the way. At times we built short-lived tooling and process to support a particular step forward. This made us so much faster in the long run.
🏔 Climbing the Legacy Code Mountain
Clear from the start, Team Pufferfish would need to make some pretty fundamental changes to the Quiz Engine, the component responsible for most of the MySQL load. Somehow the Quiz Engine would need to significantly reduce its load on MySQL.
Most of NoRedInk runs on a Rails monolith, including the Quiz Engine. The Quiz Engine is big! It’s got lots of features! It supports our teachers & students to do lots of great work together! Yay!
But the Quiz Engine has some problems, too. A mix of complexity and performance-sensitivity has made engineers afraid to touch it. Previous attempts at big structural change in the Quiz Engine failed and had to be rolled back. If Pufferfish was going make significant structural changes, we would need to ensure our ability to be productive in the Quiz Engine codebase. Thinking we could just do it without a new approach would be foolhardy.
⚡ The Vengeful God of Tests
We have mixed feelings about our test suite. It’s nice that it covers a lot of code. Less nice is that we don’t really know what each test is intended to check. These tests have evolved into complex bits of code by themselves with a lot of supporting logic, and in many cases, tight coupling to the implementation. Diving deep into some of these tests has uncovered tests no longer covering any production logic at all. The test suite is large and we didn’t have time to dive deep into each test, but we were also reluctant to delete test cases without being sure they weren’t adding value.
Our relationship with the Quiz Engine test suite was and still is a bit like one might have with an angry Greek god. We’re continuously investing effort to keep it happy (i.e. green), but we don’t always understand what we’re doing or why. Please don’t spoil our harvest and protect us from (production) fires, oh mighty RSpec!
The ultimate goal wasn’t to change Quiz Engine functionality, but rather to reduce its load on MySQL. This is the perfect scenario for tests to help us! The test suite we want is:
fast
comprehensive, and
not dependent on implementation
includes performance testing
Unfortunately, that’s not the hand we were given:
The suite takes about 30 minutes to run in CI and even longer locally.
Our QA team finds bugs that sneaked past CI in PRs with Quiz Engine changes relatively frequently.
Many tests ensure that specific queries are performed in a specific order. Considering we might replace MySQL wholesale, these tests provide little value.
And because a lot of Quiz Engine code is extremely performance-sensitive, there’s an increased risk of performance regressions only surfacing with real production load.
Fighting with our tests meant that even small changes would take hours to verify in tests, and then, because of unforeseen regressions not covered by the tests, take multiple attempts to fix, resulting in multiple-day roll-outs for small changes.
Our clock is ticking! We needed to iterate faster than that if we were going to avert the apocalypse.
🐶 I have no idea what I’m doing 🧪
Reading complicated legacy Rails code often raises questions that take surprising amounts of effort to answer.
Is this method dead code? If not, who is calling this?
Are we ever entering this conditional? When?
Is this function talking to the database?
Is this function intentionally talking to the database?
Is this function only reading from the database or also writing to it?
It isn’t even clear what code was running. There are a few features of Ruby (and Rails) which optimize for writing code over reading it. We did our best to unwrap this type of code:
Rails provides devs the ability to wrap functionality in hooks. before_ and after_ hooks let devs write setup and tear-down code once, then forget it. However, the existence of these hooks means calling a method might also evaluate code defined in a different file, and you won’t know about it unless you explicitly look for it. Hard to read!
Complicating things further is Ruby’s dynamic dispatch based on subclassing and polymorphic associations. Which load_students am I calling? The one for Quiz or the one for Practice? They each implement the Assignment interface but have pretty different behavior! And: they each have their own set of hooks🤦. Maybe it’s something completely different!
And then there’s ActiveRecord. ActiveRecord makes it easy to write queries — a little too easy. It doesn’t make it easy to know where queries are happening. It’s ergonomic that we can tell ActiveRecord what we need, and let it figure how to fetch the data. It’s less nice when you’re trying to find out where in the code your queries are happening and the answer to that question is, “absolutely anywhere”. We want to know exactly what queries are happening on these code paths. ActiveRecord doesn’t help.
🧵 A rich history
A final factor that makes working in Quiz Engine code daunting is the sheer size of the beast. The Quiz Engine has grown organically over many years, so there’s a lot of functionality to be aware of.
Because the Quiz Engine itself has been hard to change for a while, APIs defined between bits of Quiz Engine code often haven’t evolved to match our latest understanding. This means understanding the Quiz Engine code requires not just understanding what it does today, but also how we thought about it in the past, and what (partial) attempts were made to change it. This increases the sum of Quiz Engine knowledge even further.
For example, we might try to refactor a bit of code, leading to tests failing. But is this conditional branch ever reached in production? 🤷
Enough complaining. What did we do about it?
We knew this was going to be a huge project, and huge projects, in the best case, are shipped late, and in the average case don’t ever ship. The only way we were going to have confidence that our work would ever see the light of day was by doing the riskiest, hardest, scariest stuff first. That way, if one approach wasn’t going to work, we would find out about it sooner and could try something new before we’d over-invested in a direction.
So: where is the risk? What’s the scariest problem we have to solve? History dictates: The more we change the legacy system, the more likely we’re going to cause regressions.
So our first task: cut away the part of the Quiz Engine that performs database queries and port this logic to a separate service. Henceforth when Rails needs to read or change Quiz Engine data, it will talk to the new service instead of going to the database directly.
Once the legacy-code risk has been minimized, we would be able to focus on the (still challenging) task of changing where we store Quiz Engine data from single-database MySQL to something horizontally scalable.
⛏️ Phase 1: Extracting queries from Rails
🔪 Finding out where to cut
Before extracting Quiz Engine MySQL queries from our Rails service, we first needed to know where those queries were being made. As we discussed above this wasn’t obvious from reading the code.
To find the MySQL queries themself, we built some tooling: we monkey-patched ActiveRecord to warn whenever an unknown read or write was made against one of the tables containing Quiz Engine data. We ran our monkey-patched code first in CI and later in production, letting the warnings tell us where those queries were happening. Using this information we decorated our code by marking all the reads and writes. Once code was decorated, it would no longer emit warnings. As soon as all the writes & reads were decorated, we changed our monkey-patch to not just warn but fail when making a query against one of those tables, to ensure we wouldn’t accidentally introduce new queries touching Quiz Engine data.
🚛 Offloading logic: Our first approach
Now we knew where to cut, we decided our place of greatest risk was moving a single MySQL query out of our rails app. If we could move a single query, we could move all of them. There was one rub: if we did move all queries to our new app, we would add a lot of network latency. because of the number of round trips needed for a single request. Now we have a constraint: Move a single query into a new service, but with very little latency.
How did we reduce latency?
Get rid of network latency by getting rid of the network — we hosted the service in the same hardware as our Rails app.
Get rid of protocol latency by using a dead-simple protocol: socket communication.
We ended up building a socket server in Haskell that took data requests from Rails, and transformed them into a series of MySQL queries, which rails would use to fetch the data itself.
🛸 Leaving the Mothership: Fewer Round Trips
Although co-locating our service with rails got us off the ground, it required significant duct tape. We had invested a lot of work building nice deployment systems for HTTP services and we didn’t want to re-invent that tooling for socket-based side-car apps. The thing that was preventing the migration was having too many round-trip requests to the Rails app. How could we reduce the number of round trips?
As we moved MySQL query generation to our new service, we started to see this pattern in our routes:
MySQL Read some data ┐ Ruby Do some processing │ candidate 1 for MySQL Read some more data ┘ extraction Ruby More processing MySQL Write some data ┐ Ruby Processing again! │ candidate 2 for MySQL Write more data ┘ extraction
To reduce latency, we’d have to bundle reads and writes: In addition to porting reads & writes to the new service, we’d have to port the ruby logic between reads and writes, which would be a lot of work.
What if instead, we could change the order of operations and make it look like this?
MySQL Read some data ┐ candidate 1 for MySQL Read some more data ┘ extraction Ruby Do some processing Ruby More processing Ruby Processing again! MySQL Write some data ┐ candidate 2 for MySQL Write more data ┘ extraction
Then we’d be able to extract batches of queries to Haskell and leave the logic behind in Rails.
One concern we had with changing the order of operations like this was the possibility of a request handler first writing some data to the database, then reading it back again later. Changing the order of read and write queries would result in such code failing. However, since we now had a complete and accurate picture of all the queries the Rails code was making, we knew (luckily!) we didn’t need to worry about this.
Another concern was the risk of a large refactor like this resulting in regressions causing long feedback cycles and breaking the Quiz Engine. To avoid this we tried to keep our refactors as dumb as possible: Specifically: we mostly did a lot of inlining. We would start with something like this
class QuizzesControllller 9000 :super_saiyan else load_sub_syan_fun_type # TODO: inline me end end end end
These are refactors with a relatively small chance of changing behavior or causing regressions.
Once the query was at the top level of the code it became clear when we needed data, and that understanding allowed us to push those queries to happen first.
e.g. from above, we could easily push the previously obscured QuizForFun query to the beginning:
class QuizzesControllller 9000 :super_saiyan else load_sub_syan_fun_type # TODO: inline me end end end
You might expect our bout of inlining to introduce a ton of duplication in our code, but in practice, it surfaced a lot of dead code and made it clearer what the functions we left behind were doing. That wasn’t what we set out to do, but still, nice!
👛 Phase 2: Changing the Quiz Engine datastore
At this point all interactions with the Quiz Engine datastore were going through this new Quiz Engine service. Excellent! This means for the second part of this project, the part where we were actually going to avert the MySQL apocalypse, we wouldn’t need to worry about our legacy Rails code.
To facilitate easy refactoring, we built this new service in Haskell. The effect was immediately noticeable. Like an embargo had been lifted, from this point forward we saw a constant trickle of small productive refactors get mixed in the work we were doing, slowly reshaping types to reflect our latest understanding. Changes we wouldn’t have made on the Rails side unless we’d have set aside months of dedicated time. Haskell is a great tool to use to manage complexity!
The centerpiece of this phase was the architectural change we were planning to make: switching from MySQL to a horizontally scalable storage solution. But honestly, figuring the architecture details here wasn’t the most interesting or challenging portion of the work, so we’re just putting that aside for now. Maybe we’ll return to it in a future blog post (sneak peek: we ended up using Redis and Kafka). Like in step 1, the biggest question we had to solve was “how are we going to make it safe to move forward quickly?”
One challenge was that we had left most of our test suite behind in Rails in phase one, so we were not doing too well on that front. We added Haskell test coverage of course, including many golden result tests which are worth a post on their own. Together with our QA team we also invested in our Cypress integration test suite which runs tests from the browser, thus integration-testing the combination of our Rails and Haskell code.
Our most useful tool in making safe changes in this phase however was our production traffic. We started building up what was effectively a parallel Haskell service talking to Redis next to the existing one talking to MySQL. Both received production load from the start, but until the very end of the project only the MySQL code paths’ response values were used. When the Redis code path didn’t match the MySQL, we’d log a bug. Using these bug reports, we slowly massaged the Redis code path to return identical data to MySQL.
Because we weren’t relying on the output of the Redis code path in production, we could deploy changes to it many times a day, without fear of breaking the site for students or teachers. These deploys provided frequent and fast feedback. Deploying frequently was made possible by the Haskell Quiz Engine code living in its own service, which meant deploys contained only changes by our team, without work from other teams with a different risk profile.
🥁 So, did it work?
It’s been about a month since we’ve switched entirely to the new architecture and it’s been humming along happily. By the time we did the official switch-over to the new datastore it had been running at full-load (but with bugs) for a couple of months already. Still, we were standing ready with buckets of water in case we overlooked something. Our anxiety was in vain: the roll-out was a non-event.
Architecture, plans, goals, were all important to making this a success. Still, we think the thing most crucial to our success was continuously improving our feedback loops. Fast feedback (lots of deploys), accurate feedback (knowing all the MySQL queries Rails is making), detailed feedback (lots of context in error reports), high signal/noise ratio (removing errors we were not planning to act on), lots of coverage (many students doing quizzes). Getting this feedback required us to constantly tweak and create tooling and new processes. But even if these processes were sometimes short-lived, they've never been an overhead, allowing us to move so much faster.
1 note
·
View note
Text
A QA Interview We Never Used
About five years ago I was working on a QA interview process and got the following suggestion: “You’ve just arrived at the airport and have two hours before your flight to Hawaii. Make a list of everything that could go wrong between now and when the flight lands.”
No information about how to assess the candidate’s response was provided, and I had another concern. I remembered growing up in Maine and taking a vacation once a year: we’d rent a house on a lake for a week and drive to it in the family car. For my parents, this type of vacation was a huge luxury, something the generation before had never been able to do; I doubt flying to Hawaii, or anywhere else, ever really entered their minds. At the age of 23, I had flown a total of three times in my life, and always between New England and Arizona.
All this is to say that I was worried about cultural bias in the interview, a worry I admit I wouldn’t had thought of if it had simply been presented as, say, a road trip. But it seemed that frequent flyers, who could readily access detailed images of airport parking lots, terminals, and the planes themselves, would have a distinct advantage that was unrelated to the testing skills I wanted to measure, so I didn’t include it in my set of interviews.
But there was something else I liked about the interview. It got at what it’s like to be a tester. Looking for risk and points of failure. Questioning assumptions. Viewing every transition from moment to moment or state to state (house, car, pre-security, post-security, boarding, flying, deplaning…) with skepticism, wondering where things might come apart and replaying them over and over, looking for faults. And as one of those people who often reflexively lists things that might go wrong in regular life for no reason and when no one asked, perhaps I felt this interview honored a behavior that annoys others. So a few years later, on a flight to San Francisco, I made my own version, which I then promptly forgot about. A few years after that, the QA team was redesigning parts of our interview process, and I remembered it and shared it with my colleagues.
Testing mindset interview
Introduction
In this interview, you’ll be presented with a scenario and asked to offer reasons for how the information presented in the scenario could be possible. To avoid a list of very similar reasons, we ask that you stretch your imagination and try to consider as many different categories of reasons as possible. What does categories mean?
Dividing anything into categories can be arbitrary, of course. To give you an idea of how we’ve divided things into categories, consider the example scenario below (we don’t want to spoil answers by discussing the real scenario yet). The example scenario is similar to the one we’ll present as the real interview question.
Example Scenario
Suppose you were asked to make a list of every danger you might face while hiking through a forest. To start, you might say, I could get attacked by a wolf, or trampled by a deer, or struck from above by a hawk. While these experiences are undoubtedly vastly different, they all involve an animal attacking you, and we’d say they fit into a single category. You might also suggest, for example, that you could be attacked by an empty suit of armor; while somewhat more poetic, this still falls, in our opinion, under the category of “something attacks me”, and doesn’t require a new category to hold it. If you mentioned accidentally ingesting a poisonous mushroom, though, we wouldn’t try to argue that the mushroom belongs in the same class as the other attacking entities — this is a new category, perhaps something along the lines of “ingesting dangerous things”.
For this exercise, try to keep our rough ideas of categories in mind. We’ll ask you to provide examples for a specific situation, and we’ll be looking for how many different categories your examples cover. While it doesn’t hurt you to list many things from the same category, it doesn’t help, either. We encourage you to write down everything that comes to mind, but focus on trying to think of new ideas that aren’t closely related to what you’ve already written.
The Real Scenario
You enter an empty cabin. The entrance is to a kitchen, where a table holds three identical bowls of porridge. On the stovetop, a much larger pot of porridge sits over a low heat. As you brazenly devour the porridge, you notice that the contents of the bowls are not identical after all — the porridge in the first bowl is scalding hot, while the porridge in the second bowl is freezing cold, and the porridge in the third bowl is a pleasant temperature, somewhere between the two extremes of the other bowls.
What are some possible reasons that the porridges were not all the same temperature?
I liked my scenario because I felt it didn’t require too much knowledge from any particular domain. Deep knowledge of cooking, heating and cooling, or fairy tales wouldn’t, I guessed, confer much advantage. It also offered a certain level of whimsy that I felt would serve as an appropriate warning for anyone who might have to work with me.
But a concern remained. It was one of my two concerns from five years ago: how to assess the candidate’s response? Was there a fair and objective way to do it? I intended to go through the candidate’s list (“someone added ice to one bowl and hot water to another”, “something is wrong with my nerve endings”) and check off every distinct category they’d identified (“interference from outside actor”, “error in measurement”), but even if I created a near-perfect list of categories (I felt close), could I really communicate what size of categories I had created to the candidate without giving away answers? (Probably not). When I actually practiced the interview with a colleague, things deteriorated further, as many of her answers fell into a gray area as to whether or not they should count for a particular category.
Time ticks on, cooling our porridge and bringing deadlines rushing to meet us. I kept thinking about the problem, but an epiphany never came. With no solution to problem of a fair scoring system, I scrapped the interview and wrote this blog post instead.
Do you give (or have you taken) any kind of QA interview like this? Let me know on one of the social platforms below.

Alexander Roy QA Analyst | NoRedInk
LinkedIn | Github | Twitter
Thanks to Kristine Horn for her help while I was still trying to salvage the interview, and to Michael Glass and Charlie Koster for reviewing this blog post.
1 note
·
View note
Text
What would you pay for type checking?
Here’s a statement that shouldn’t be controversial, but is anyway: JavaScript is a type-checked language.
I’ve heard people refer to JavaScript as “untyped” (implying that it has no concept of types), which is odd considering JS's most infamous error—“undefined is not a function”—is literally an example of the language reporting a type mismatch. How could a supposedly “untyped” language throw a TypeError? Is JS aware of types or isn't it?
Of course, the answer is that JavaScript is a type-checked language: its types are checked at runtime. The fact that the phrase “JavaScript is a type-checked language” can be considered controversial is evidence of the bizarre tribalism we’ve developed around when types get checked. I mean, is it not accurate to say that JavaScript checks types at runtime? Of course it's accurate! Undefined is not a function!
Truly Untyped Languages
Assembly language does not have “undefined is not a function.”
This is because it has neither build time nor runtime type checking. It’s essentially a human-readable translation of machine code, allowing you to write add instead of having to handwrite out the number corresponding to an addition machine instruction.
So what happens if you get a runtime type mismatch in Assembly? If it doesn’t check the types and report mismatches, like JavaScript does, what does it do?
Let’s suppose I’ve written a function that capitalizes the first letter in a lowercase string. I then accidentally call this code on a number instead of a string. Whoops! Let’s compare what would happen in JavaScript and in Assembly.
Since Assembly doesn't have low-level primitives called “number” or “string,” let me be a bit more specific. For “number” I’ll use a 64-bit integer. For “string” I’ll use the definition C would use on a 64-bit system, namely “a 64-bit memory address pointing to a sequence of bytes ending in 0.” To keep the example brief, the function will assume the string is ASCII encoded and already begins with a lowercase character.
The assembly code for my “capitalize the first letter in the string” function would perform roughly the following steps.
Treat my one 64-bit argument as a memory address, and load the first byte from memory at that address.
“Capitalize” that byte by subtracting 32 from it. (In ASCII, subtracting 32 from a lowercase letter’s character code makes it uppercase.)
Write the resulting byte back to the original memory address.
If I call this function passing a “string” (that is, a memory address to the beginning of my bytes), these steps will work as intended. The function will capitalize the first letter of the string. Yay!
If I call this function passing a normal integer…yikes. Here are the steps my Assembly code will once again faithfully perform:
Treat my one 64-bit argument as a memory address, even though it’s actually supposed to be an integer. Load the first byte from whatever memory happens to be at that address. This may cause a segmentation fault (crashing the program immediately with the only error information being “Segmentation fault”) due to trying to read memory the operating system would not allow this process to read. Let’s proceed assuming the memory access happened to be allowed, and the program didn’t immediately crash.
“Capitalize” whatever random byte of data we have now loaded by subtracting 32 from it. Maybe this byte happened to refer to a student's test score, which we just reduced by 32 points. Or maybe we happened to load a character from the middle of a different string in the program, and now instead of saying “Welcome, Dave!” the screen says “Welcome, $ave!” Who knows? The data we happen to load here will vary each time we run the program.
Write the resulting byte back to the original memory address. Sorry, kid - your test score is just 32 points lower now.
Hopefully we can all agree that “undefined is not a function” is a significant improvement over segmentation faults and corrupting random parts of memory. Runtime type checking can prevent memory safety problems like this, and much more.
Bytes are bytes, and many machine instructions don’t distinguish between bytes of one type or another. Whether done at build time or at runtime, having some sort of type checking is the only way to prevent disaster when we’d otherwise instruct the machine to interpret the bytes the wrong way. “Types for bytes” was the original motivation for introducing type checking to programming, although it has long since grown beyond that.
Objective Costs of Checking Types
It’s rare to find discussions of objective tradeoffs in the sea of “static versus dynamic” food fights, but this example actually illustrates one.
As the name suggests, runtime type checking involves doing type checking…at runtime! The reason JavaScript wouldn’t cause a segmentation fault or corrupt data in this example, where Assembly would, is that JavaScript would generate more machine instructions than the Assembly version. Those instructions would record in memory the types of each value, and then before performing a certain operation, first read the type out of memory to decide whether to proceed with the operation or throw an error.
This means that in JavaScript, a 64-bit number often takes up more than 64 bits of memory. There’s the memory needed to store the number itself, and then the extra memory needed to store its type. There’s also more work for the CPU to do: it has to read that extra memory and check the type before performing a given operation. In Python, for example, a 64-bit integer takes up 192 bits (24 bytes) in memory.
In contrast, build time type checking involves doing type checking…at build time! This does not have a runtime cost, but it does have a build-time cost; an objective downside to build-time type checking is that you have to wait for it.
Programmer time is expensive, which implies that programmers being blocked waiting for builds is expensive. Elm’s compiler builds so fast that at NoRedInk we’d have paid a serious “code’s compiling” productivity tax if we had chosen TypeScript instead—to say nothing of what we’d have missed in terms of programmer happiness, runtime performance, or the reliability of our product.
That said, using a language without build-time checking will not necessarily cause you to spend less time waiting. Stripe’s programmers would commonly wait 10-20 seconds for one of their Ruby tests to execute, but the Ruby type checker they created was able to give actionable feedback on their entire code base in that time. In practice, introducing build-time type checking apparently led them to spend less time overall on waiting.
Performance Optimizations for Type Checkers
Both build time and runtime type checkers are programs, which means their performance can be optimized.
For example, JIT compilers can reduce the cost of runtime type checking. JavaScript in 2020 runs multiple orders of magnitude faster than JavaScript in 2000 did, because a massive effort has gone into optimizing its runtime. Most of the gains have been outside the type checker, but JavaScript’s runtime type checking cost has gone down as well.
Conversely, between 2000 and 2020 JavaScript’s build times have exploded—also primarily outside type checking. When I first learned JavaScript (almost 20 years ago now, yikes!) it had no build step. The first time I used JS professionally, the entire project had one dependency.
Today, just installing the dependencies for a fresh React project takes me over a minute—and that’s before even beginning to build the project itself, let alone type check it! By contrast, I can build a freshly git-cloned 4,000-line Elm SPA in under 1 second total, including installing dependencies and full type checking.
While they may improve performance overall, JIT compilers introduce their own runtime costs, and cannot make runtime type checking free. Arguably Rust‘s main reason for existence is to offer a reliable and ergonomic programming language which does not introduce the sort of runtime overhead that come with JIT compilers and garbage collectors.
Build time type checkers are also programs, and their performance can also be optimized.
We often lump build-time type checking performance into the bucket of “compilation time,” but type checking isn’t necessarily the biggest contributor to slow builds. For example, in the case of Rust, code generation is apparently a much bigger contributor to compile times than type checking—and code generation only begins after type checking has fully completed.
Some type checkers with essentially equivalent type systems build faster than others, because of performance optimization. For example, the 0.19.0 release of Elm did not change the type system at all, but massively improved build times by implementing certain performance optimizations which (among other things) made part of type inference take O(1) time instead of O(log(n)) time.
Type Systems Influence Performance
Type system design decisions aren’t free! At both build time and runtime, type checking performance is limited by the features of the type system itself.
For example, researchers have developed type inference strategies that run very fast, but these strategies rely on some assumptions being true about the design of the type system. Introducing certain subtyping features can invalidate these strategies, so offering such features lowers the ceiling on how fast the compiler can be—and for that matter, whether it can offer type inference.
It’s easy to quip “you could guarantee that at build time using ________ types” (fill in the blank with something like linear types, refinement types, dependent types, etc.) but the impact this would have on compilation times is less often discussed.
If your language introduced a given type system feature tomorrow, what would the impact be on compile times? Has anyone developed a way to check those types quickly? How much value does a given feature need to add to compensate for the swordfighting downtime it brings along with it?
Runtime type checkers are subject to these tradeoffs as well. Python and Clojure have different type systems, for example. So do Ruby and Elixir, and JavaScript and Lua. The degree to which their performance can be optimized (by JIT compilers, for example) depends in part on the design of these type systems.
Because it’s faster to check some type system features at runtime than at build time, these forces combine to put performance caps on languages which add build time checking to type systems which were designed only with runtime type checking in mind. For example, TypeScript’s compiler could run faster if it did not need to accommodate JavaScript’s existing type system.
What Would You Pay?
Except when writing in a truly untyped language like Assembly, we’re all paying for type checking somewhere—whether at build time, at runtime, or both. That cost varies based on what performance optimizations have been done (such as build-time algorithmic improvements and runtime JITs), and while type system design choices can restrict which optimizations are available, they don’t directly cause performance to be fast or slow.
Programming involves weighing lots of tradeoffs, and it’s often challenging to anticipate at the beginning of a project what will cause problems later. “The build runs too slowly” and “the application runs too slowly” are both serious problems to have, and which programming language you choose puts a cap on how much you can improve either.
We all have different tolerances for how much we’re willing to pay for this checking, and what we expect to get out of it. It’s worth thinking critically about these tradeoffs, to make conscious decisions rather than choosing the same technology we chose last time because it’s familiar.
So the next time you’re starting a project, think about these costs and benefits up front. What would you pay for type checking?
Richard Feldman
@rtfeldman
Head of Technology at NoRedInk
Thanks to Brian Hicks, Christoph Hermann, Charlie Koster, Alexis King, and Hillel Wayne for reading drafts of this.
0 notes
Text
Cypress in Action: A Few Months In
Three months ago, I wrote Going Automative: Increasing Quality. At that time, we (the NoRedInk QA team) had chosen an automated testing tool to use (Cypress), and we'd used it to start to introduce automation into our testing. Read on to learn how we've been getting on in the months since then!
What's going well?
Let's start with the good stuff! Learning and using Cypress has been an overwhelmingly positive experience. We went in as a team of three with very limited experience in automation or development of any kind, and we're really pleased with what we've produced in a relatively short time. We have a functional test suite that we're running daily and is helping us achieve much wider coverage of the site than we previously could with our manual testing (as discussed in the previous post there were a set of automated tests but these were not owned by the QA team, and didn't run against an environment as close to production as we'd like). The suite is continuing to expand as we add new tests, but we already have many of the key paths through the site covered.
How have we achieved this?
Getting moving so quickly has felt like a real achievement, and a number of resources have been hugely helpful to us in these first few months. First, the Cypress documentation has been a major contributor to our success. The documentation is well written and is something we make use of consistently; the fact that it explains the why as well as the how is a big plus for us. More broadly, as we've had the opportunity to start from scratch, we've been trying to incorporate as many best practices as we can into our codebase before we build any bad habits. While the Cypress documentation helps us with automation-specific best practices, we've also looked into broader resources to allow us to understand JavaScript best practices. Along those lines, we've gone further and looped in some of our fantastic engineers, who have graciously paired with us and reviewed our code, all in the name of helping us learn.
Aside from the documentation, there is also a wealth of other resources out there that we've used to grow our knowledge and ensure we're doing things in the best way possible. The usefulness of these resources has varied, but some we've used include:
Gleb Bahmutov's Blog - as the VP of Engineering at Cypress, Gleb's blog is full of useful tips and tricks!
Cypress GitHub Issue Tracker - the first place we check whenever we see something that doesn't seem quite right. If it's affecting us, it's usually already affected someone else, and the Cypress team are very responsive!
Cypress webinars - Whilst the direct usefulness of the regular Cypress webinars has varied for us, some have been some very useful and interesting. They have allowed us to pick up a number of good tips and tricks from other Cypress users who've been in similar situations to ours.
Cypress Gitter - the least useful way of communicating with Cypress we've found, Gitter is a bit of a wall of noise with many conversations taking place at once, all intertwined with one another. Whilst there can be useful information in Gitter, it's definitely been a last resort.
As a team, we've also made a concerted effort to upskill ourselves in Cypress, JavaScript, and general automation skills. One of our team objectives over the last quarter has been to ensure that we spend time on professional development in these areas. This has included everything from reading blog posts, to attending conferences, to completing online courses. This effort is already contributing to the quality of the tests we're writing and is putting us in a really strong position as the suite grows. Thanks to everything we're learning from these resources, we're much better equipped to write better tests each time we start a new one, and we've even been able to refactor our original tests to improve and future-proof them.
It can't all be rainbows and unicorns, right?
Whilst our experience using Cypress has been mainly a positive one, it hasn't all been smooth sailing. There have been a few things we've struggled with, been unable to do, needed workarounds for, or had to follow anti-patterns to accomplish. One limitation we've run into is finding that we've needed to use conditional logic to test some parts of our application. The Cypress docs give a good explanation on why using conditional logic is hard and should often be avoided, but in our case, we were stuck with needing to handle different states appearing on a page. In our app, students answer grammar questions which unpredictably appear in a variety of correct or incorrect states. We're currently in a position where we don't have control over the initial answer state, which means that we need to first determine the initial answer state when the question loads in order to know whether we need to change it to the state we desire. We'd have to write something along these lines:
if (initial answer is correct) { // do a thing } else { // do a different thing }
Eventually, we solved this thanks to Gleb's blog post on conditional logic, which provides a great example of how to achieve exactly what we were looking for.
Another area we've had problems was using the Electron browser headlessly, we have a number of tests which consistently pass without any problems when ran in either Chrome or headed Electron, but will fail when ran headlessly. This appears to be down to the speed at which actions on our site happen and, as yet, we haven't managed to come up with reliable solution to it. This originally meant missing out on the video recording that Electron headless offered, but with the release of Cypress 3.5 that's no longer an issue as recording is available within Chrome! 🎉
Despite Cypress tests being very quick to run we've also quite quickly come to a point where we going to very soon be looking into running the tests in parallel to get through them faster. Some of this need has been caused by the way we're running them - against a hosted staging environment that doesn't have an accessible API we can use to set up data and speed up repetitive parts of tests, meaning everything needs to be done via the UI, which slows things down. This need for speeding up the test runs has happened sooner than we'd initially expected, and whilst it isn't a major issue, it's something we're going to have to consider in the relatively near future.
So, what's our overall opinion?
Despite the few issues we've had, it has definitely been a good few months using Cypress. We've learnt a lot and we've been able to create tests which add real value in a relatively short period of time.
Cypress is so easy to install, and to begin using, that we'd highly recommend teams looking to start automating their tests give it a try. As with any piece of software it has parts that don't do exactly what we want, or work exactly how we'd like, but overall the goods comfortably outweigh the bads!
From our point of view, we're excited about what the future holds for our tests!
Matt Charlton, Product Quality Specialist at NoRedInk
(thanks to Kristine Horn, Alexander Roy, Michael Newton and Ian Davies for reviewing drafts!)
0 notes
Text
Type-Safe MySQL Queries via Postgres
My team and I are working on NoRedInk's transition from Ruby on Rails and MySQL to Haskell and Postgres. A major benefit of our new stack (Postgres/Haskell/Elm) is type-safety between the boundaries (db to backend, backend to frontend). To ensure our code is type-safe between Haskell and Elm we use servant. Servant allows us to generate types and functions for Elm based on our APIs. To ensure type-safety between Postgres and Haskell we use postgresql-typed. This means that when we change our database schema, our Haskell code won't compile if there is a mismatch, similarly to how our Elm code won't compile if there is a mismatch with our backend endpoints. We're going to focus on type-safety between our databases and Haskell in this post and on how we introduced MySQL into this. But first, let's briefly look at how we can check out Postgres queries at compile-time.
Postgres-Typed
todos :: Int -> PGConnection -> IO [Todo] todos userId postgresConn = do rows <- pgQuery postgresConn [pgSQL|! SELECT id, description, completed FROM todos WHERE user_id = ${userId} ORDER BY id ASC |] pure (fmap todoFromRow rows)
We use Template Haskell to write SQL queries instead of a DSL, allowing our engineers to use their existing knowledge of SQL instead of having to learn some library. pgSQL is a QuasiQuoter it creates a value of type PGQuery which gets executed by pgQuery. The quasi quoted query gets verified against the database schema and executed (ignoring results and without arguments) at compile-time. This is all we need to know from postgresql-typed for this post, but I recommend checking out the docs and looking at their example.
Moving to Haskell and Postgres
Our Rails application uses a MySQL database. Gradually moving functionality/new features to Haskell often means that we need access to data that isn't yet moved. We solved this initially by creating an endpoints on our Rails application and requested the data via http. This proved to be toilsome and complicated development and deploys, and therefore made it harder for teams to commit to building things in Haskell. In order to remove this hurdle, we started to think about reading data directly from our MySQL database. We really liked postgresql-typed, because it gave us the ability to write actual SQL queries and type-safety between the database and Haskell. Unfortunatlly, there isn’t a mysql-typed, but we found an interesting solution provided by Postgres itself; foreign-data-wrappers.
Foreign Data Wrappers
Foreign Data Wrappers (short fdw) offer a way to manage remote data directly within your Postgres database. This allows us to use postgresql-typed to access the MySQL data via Postgres.
CREATE SERVER mysql-schema-name FOREIGN DATA WRAPPER mysql_fdw OPTIONS (host '${host}', port '${port}'); -- Mapping for the application user, so it can perform queries. CREATE USER MAPPING FOR ${username} SERVER mysql-schema-name OPTIONS (username '${username}', password '${passphrase}'); CREATE SCHEMA mysql-schema-name AUTHORIZATION ${username}; IMPORT FOREIGN SCHEMA ${dbname} FROM SERVER mysql-schema-name INTO mysql-schema-name;
Unfortunately, we quickly ran into problems when converting http requests to the Rails application with queries directly to MySQL. Fdw has some limitations that were blockers for use. The schema imported as a fdw is imported without any constraints other than NOT NULL. An even bigger problem was that some SQL constructs weren’t pushed down to MySQL. As an example the fdw wouldn’t forward LIMIT clauses and therefore grab all rows of a table, send them over the wire, and then apply the LIMIT in Postgres. This obviously has huge performance implications and meant that we needed to find a different solution without suffering type-safety.
Type-Safe MySQL Queries
We had three options; either find a library that would give us the guarantees we were used to from postgresql-typed for MySQL, building our own library or somehow abusing postgresql-typed. Building our own library wasn't an option because that would have exceeded the scope of this project, and we couldn't find a library that met our requirements. Fortunately, postgresql-typed allows us to access getQueryString to get the raw query string from the quasi-quoted query. This we can then execute with mysql-simple instead of postgresql-typed. This allows us to check MySQL and Postgres queries at compile time using a fdw, but connecting directly to Postgres and MySQL at runtime. Finally we can write queries to our MySQL database using the same API as for Postgres and having full type-safety between the database and Haskell.
cats :: Database.MySQL.Simple.Connection -> IO [Cat] cats mySQLConnection = do rows <- Database.MySQL.Simple.query_ mySQLConnection $ -- direct connection to MySQL remove "mysql-schema-name." $ -- ^ The schemaname (fdw) only exists during compile time. getQueryString unknownPGTypeEnv [pgSql|! SELECT id, description, color FROM mysql-schema-name.cats ORDER BY id ASC |] pure (fmap catFromRow rows)
I’ve inlined the functions from postgresql-typed and mysql-simple to keep the code examples simple. We actually have two modules MySQL and Postgres that abstract the database specific functions away allowing us to use the exact same API for both databases.
Caveats
We need to prefix tables with the schema name that we used to import the fdw (see mysql-schema-name.cats in the example above). Without the prefix the compilation won't succeed. The problem is that we don't have a schema with this name at runtime. We can simply work around this by running Text.replace "mysql-schema-name." "" sqlString before executing the query. Queries need to use standard SQL features and shouldn't rely on MySQL specific features. This is actually kind of a feature, because it forces us to write queries in a way that simplifies converting them to Postgres later.
Conclusion
While this is a nice solution for us, I don't really recommend you to use MySQL in this way. This solution allows us to simplify the transition between Rails/MySQL and Haskell/Postgres. I would love for library like postgresql-typed to exist for MySQL, but it wasn't feasable to build such a thing. Honestly, I don't even know if it would be possible. I hope this post showed you how to create a nice experience for transitioning to a different technology. Thanks for reading :heart:
Special thanks to everyone involved in building this:
Ary
Gavin
Jasper
Michael
0 notes
Text
Our Summer Retreat!
Invest in and take care of each other. This core value has shaped our culture and we are committed to keeping it in sight as we continue to grow.
NoRedInk knows that it takes more than just a feel-great mission and the right job description for people to thrive at work; it also takes feeling connected to your co-workers. We have grown to ~80 employees, but with nearly 50% of our team working remotely across the globe, we go the extra mile(s), literally and figuratively, to ensure that this important sense of team still flourishes. Last month we all went to the Chaminade in Santa Cruz for our fourth annual summer retreat.
The summer retreat gives NoRedInkers the opportunity to strengthen our connection with our mission, our vision, and each other. This year’s proved yet again that our eclectic group of personalities meshes beautifully and allows for each of us to be our authentic selves. In sum, we like each other; we really like each other!
Day 1:
After three days of working together in our San Francisco headquarters, we all boarded a bus and enjoyed a musical two-hour journey south, filled with guitar solos and plenty of group karaoke. We made it just in time to share dinner together overlooking a beautiful sunset….
… and had the rest of the evening to just hang out.
Day 2:
The official retreat began with a focus on NRI’s vision and mission. Jeff Scheur, our CEO, led with a presentation highlighting these and outlining this year’s wins (such as adding two new members to our leadership team, Steve and Chris), where we fell short, and what our focus will be in the next year.
The curriculum team then took over to lead us through a fun exercise that highlighted why teachers need a tool like ours. In small groups, we evaluated student writing samples using the rubrics from three national writing assessments and discussed how our scores compared to the official results. We then came back together as a company to talk about the challenges that standardized writing tests pose for students and teachers and how we can help students develop the skills they need to succeed. Even better, though, these are skills that can be applied across every kind of writing task students will face, so the value of our platform extends well beyond test day!
Though we packed a lot in, by mid-afternoon, the only thing left on our agenda was to relax and spend quality time together. NRI’ers could be found enjoying the lovely hikes along the property, intense volleyball games, and spontaneous karaoke during the evening’s Happy Hour. And as it turns out, we’re a group of friends that really does share a love for karaoke— though definitely not the same level of talent for it. While we have some stars, the fact that no would-be singer gets silenced in this crowd is arguably the strongest proof of all that we truly support each other.
Day 3:
Our last day focused on the theme of trust. Although we think this is a strength of ours, the workshop provided a valuable reminder that there is no blanket definition of the key behaviors needed to build trust between colleagues. Learning our different perspectives on the tenets of trust allows us to tailor our actions to what is most meaningful to each other on an individual basis. The mindful mentality that we collectively share is part of what makes NoRedInk a uniquely great company to work for, and this workshop gave us the opportunity to take it another step further.
Last but not least, we took lots of fun team photos!
Post-analysis:
Being a company that believes in continuous improvement, we asked our team for their feedback on the retreat. Here’s what NRI’ers had to say about what they most enjoyed about it:
“Getting to meet all the people I have seen only online, and those I don’t regularly work with. This is because I was so impressed with how talented these people are! I feel honored to be part of this team, and challenged and motivated to live up to our standards.” (Kelly)
“Team time! Having the discussions about trust and team norms was really, really helpful considering half of our team is new.” (Paige)
“Spending time with lovely coworkers in a beautiful setting, chatting with a variety of individuals in the hot tub, on the grass, at each meal! I loved small group conversations that brought out details and nuances between teams and departments in ways we hadn’t previously discussed.” (Danielle)
“It’s just so nice that we truly value and make space for connecting with our coworkers.” (Marc)
“Spending time with people I normally only see on video (or not at all). It’s also always great to see a ton of new faces, get to talking to those people, and realize that we haven’t compromised on hiring and they’re all folks who are going to embody our core values.” (Alexander)
Our winter retreat now has an especially high bar to live up to, but then again, our team has never been one to shy away from a challenge. 95 days to go, but who’s counting?
There’s room for a few more people though; we’re hiring! Check out our current openings here.
0 notes
Text
Going Automative: Increasing Quality
To misquote Jane Austen: it is a truth universally acknowledged, that a QA team in possession of a rapidly growing product, must be in want of automated tests.
That semi-authentic sentiment expresses nicely where the NoRedInk QA team found ourselves at the start of 2019. Our incredible engineering teams were churning out a phenomenal amount of work and new features and enhancements to the existing site were arriving almost quicker than we could keep up. There was a rapidly approaching point in the future where the manual testing process that we had in place would no longer be enough to cover the site to the level we wanted and needed.
To combat this less-than-perfect future, we decided it was time for us to start automating some of our manual tests so that we could know that key areas of the site were working even if we didn't have time to walk through them all. As well as reassuring us that those critical paths were still working, this automation would also help us carve out more time for exploratory testing of those areas that we don't currently have huge opportunity to look into and to come up with new and innovative ways of verifying the site was working exactly as we wanted it to.
Before we could get there, though, we had to chose a tool with which to implement automation! To start on this journey, we came up with a number of criteria we wanted an automation tool to fill and considerations we had to bear in mind. These included:
The ability to run the test against any environment we wanted (development, staging, production, etc.)
No effect on people outside of QA — we didn't want to negatively impact the rest of engineering whilst building our test suite
Integration with existing tools — namely Percy and Browserstack
Maintainability — whilst anything we write will require some maintenance, we don't want to be spending hours a day maintaining flaky tests. We also need the tests to be self-sufficent enough to continue working through events like the back-to-school period when a lot of data on the site is reset
Having defined what we were looking for our next step was to look at what we already had; there was set of tests, written by the engineers using RSpec & Capybara, which had the advantage of being tied closely to the application code and having the ability to easily create/remove data. They also covered a good amount of the site already, but came with a few major negative points, namely:
QA don't own them or know what they cover — going through them and learning what cases they include would be almost as big a project as writing our own tests
They only run against the test environment, either locally or within our CI system (which doesn't have a lot of the 3rd-party systems, etc. running that an environment like staging does), so they aren't an accurate representation of production
Some of the older ones are becoming classic legacy code and are only really understood by a few engineers
Any changes we make will affect all of engineering, especially as we're learning and causing flakes and failures, which will reduce our ability to experiment and make mistakes
As a QA team our flake tolerance can be higher than the entire engineering department and we aren't as concerned about the speed of each test run at the moment
The learning curve of adding to these tests isn't aligned to current QA skills and the direction we'd like to go
With those existing tests in mind, we put in place a plan to evaluate a number of possible alternative tools to see if we could find one that better met our goals and needs. The strategy we came up with was to give each tool a trial run and create the same set of tests in all of them. The tests we chose to implement included some that we definitely wanted in our future test suite, others that would really push tools' abilities, and others still that we were fairly sure none of the tools would be able to achieve successfully. (We weren't wrong!).
There are hundreds upon hundreds of automation tools available out there, all doing slightly different things in slightly different ways but achieving the same goal of testing a site end-to-end, and it would have been impossible to look at and evaluate all of them. We settled on four tools, and once we'd created the proof of concept tests in each, we had a pretty solid idea of the pros and cons of them:
Nightwatch
✅ Percy integration
✅ Browserstack integration
✅ Good, active community support
✅ Pretty good documentation
❌ Heavy reliance on CSS selectors
Ghost Inspector
✅ Record tests via Chrome extension
✅ Easily schedule test runs
✅ GUI showing test results
✅ Simple Slack integration
❌ Test recording isn't 100% accurate; recorded tests often require manual changes
❌ GUI for editing tests is confusing
❌ Recording captures dynamic CSS selectors that we want to avoid
❌ No integration with existing tools
❌ Built-in image diff tool is very limited
Taiko
✅ Simple REPL
✅ Very easy to create simple tests
✅ Doesn't use CSS selectors at all
❌ Doesn't handle dropdown menus well
❌ Chrome only
❌ Very limited documentation
❌ Feels very new and not fully developed
❌ Struggled with a lot of our test cases
Cypress
✅ Fantastic test runner
✅ Don't need to use as many CSS selectors
✅ Excellent documentation
✅ Good community support
✅ Percy integration
✅ Very active company in online discussions, webinars, etc.
❌ Chrome only
❌ Tests can only be recorded in Electron browser
❌ Built-in version of Electron is currently out of date
Following the evaluation of each tool, we gathered our thoughts to decide where we would go from here. Each member of the team provided their thoughts and selected the tool they thought we should move forwards with, and the overwhelming choice was to introduce Cypress! A big factor in its favor was simply how it felt to use; at no point was it frustrating, and backed up by its fantastic documentation (which not only explains how to do things but also why to do them in a certain way), no problem seemed insurmountable and the answer always seemed to be available. As introducing automation was going to be a relatively steep learning curve for the team, having a tool which was straight forward to pick up and start using, whilst at the same being able to do everything we wanted, was going to be key in the success of the project.
In terms of its functionality, Cypress simply seemed to do just about everything that the other tools did better than any of the other tools, and the things Cypress didn't do weren't anything that we considered critical or thought we'd miss. (The exception to this was Cypress's lack of cross-browser testing, but as Percy allows us to capture snapshots in both Chrome & Firefox, and both Cypress & Percy have plans to introduce more browsers, we decided we could live with this for the time being. Further, around 70% of our users are using Chrome anyway.) Cypress was also a popular choice amongst the engineering department, who'd already been considering it themselves. Having us introduce it first is also nice way to bring it into the company without affecting any pre-existing processes; this also put us in a nice position as there's a lot of JavaScript knowledge amongst the engineers that we can lean on if we need to!
With a winner selected, it was then time to come up with an initial coverage plan and start implementing Cypress tests.
Check back in a few months to see how we're getting on!
Matt Charlton, Product Quality Specialist at NoRedInk
(thanks to Alexander Roy, Brian Hicks, and Kristine Horn for reviewing drafts!)
0 notes
Text
Drag & Drop without Draggables & Dropzones
Why is building drag & drop UIs so hard? They've been around for a while, so we would be forgiven for thinking they're a solved problem. Certainly there are high quality libraries to help us build drag & drop UIs, and these days we even have an official HTML5 drag & drop API! What's going on here?
I've come to the conclusion a big part of the problem is our choice of tools. Draggables and dropzones are often the wrong abstraction, and choosing different tools can simplify construction of our drag & drop UIs massively.
That's a pretty sweeping statement for a broad term like 'drag & drop', so let's look at three examples of drag & drop UIs built without draggables or dropzones. These examples come from real projects, but I've stripped them down to their drag & drop essentials for this post. I'll include what I believe to be the most relevant code snippets in this post, and provide links to the full source code.
Let's start with a quick refresher on draggables and dropzones before we get to the examples.
A Refresher on Draggables & Dropzones
A draggable is a UI element that follows the cursor when the user presses down on it. A dropzone is a UI element that gets an event when we release a draggable over it.
For an example lets look at the application Trello. Trello allows us to organize cards in lists. We could make the cards draggables and the lists dropzones. That way we'd get an event every time a card gets dropped on a list, which we could use to update our app's state with the new location of the card.
On closer inspection though things aren't as clear cut. For example, in the real Trello application it's not necessary to drop a card on top of a list. We can drop a card on some empty space and it will move into the list nearest to where we dropped it. That's much nicer for the user, but it's not clear how to create this behavior using draggables and dropzones.
Our first example, A Timeslot Selector
Our first example is a UI for selecting a time slot in a day. This UI represents a day as a horizontal bar, in which we can select a slot using drag & drop.
I'd like to start these examples by imagining what a draggables and dropzones implementation might look like. In this first example it's unclear what our draggables and dropzones even are. We could make the time slider the draggable, because clicking anywhere in it should start the drag operation even if we don't drag the time slider itself. The screen as a whole might serve as a dropzone, because the user should be able to release the cursor anywhere to finish the drag. Already this approach feels pretty hacky, and we haven't even written any code yet!
Let's start from scratch without assuming draggables or dropzones. As we regularly do, we'll begin building our Elm application by designing a Model. Our application needs to store a time slot which is nothing more than a start and end hour.
-- In this example a time slot always covers whole hours, -- but we could make this minutes or seconds if we wanted. type alias Model = { selectionStart : Hour, selectionEnd : Hour } type alias Hour = Int
Now we turn to implementing the drag & drop behavior, without draggables and dropzones. When the user presses down we store the hour the cursor is over as the selectionStart field of the timeslot. Then as the cursor moves we will update the selectionEnd field of the timeslot, until the user releases.
At any point we will need to know which hour the cursor is over. We can calculate this if we know the position of the cursor and the position and dimensions of the slider on the screen. Lets be optimistic and assume we just get that information on our drag events. If so we can design our Msg type like this:
type alias Msg = { event : DragEvent , cursor : Coords , sliderPosition : Rect } type DragEvent = Start -- We don't need to do anything special on a Stop event, so we can treat -- it the same as a Move event. | MoveOrStop type alias Coords = { x : Float, y : Float } type alias Rect = { x : Float, y : Float, width : Float, height : Float }
The information in this Msg is enough to calculate the hour the cursor is over.
cursorAtHour : Msg -> Hour cursorAtHour { cursor, sliderPosition } = let dx = cursor.x - sliderPosition.x atMost = min atLeast = max in (24 * (dx / sliderPosition.width)) |> floor -- Ensure we get a number between 0 and 23, even if the cursor moves to -- the left or right of the slider. |> atMost 23 |> atLeast 0
All that's left to do is use cursorAtHour in our update function. When we get a Start event we use it to update the selectionStart field in the model, and when we get a MoveOrStop event the selectionEnd field.
update : Msg -> Model -> Model update msg model = let hour = cursorAtHour msg in case msg.event of Start -> if coordsInRect msg.cursor msg.sliderPosition then { selectionStart = hour , selectionEnd = hour } else model MoveOrStop -> { model | selectionEnd = hour } coordsInRect : Coords -> Rect -> Bool coordsInRect = Debug.todo "Implementation omitted for brevity."
And we have an app! Well almost, we've not discussed where these Msgs will be coming from. There's a bit of JavaScript responsible for that, which I'll talk more about in a bit. Those wanting to peek ahead can check out the time slider source code.
Second example, a polygon editor
Our second example is a tool for editing polygons. We want users to be able to pick up a vertex of a polygon and move it somewhere else.
See those vertices? Those sure look like draggables! But these vertices are small and easy to miss, so we'd want our draggables to be bigger. We could achieve this by making the draggables invisible div elements centered on these vertices, but that gets us in trouble when the div elements are so close they overlap. At that point a click won't select the closest vertex but the top vertex.
We're going to leave those draggables in the toolbox and see how far we can get without them. As usual we start by defining a model to store the polygon we're editing.
type alias Model = { polygon : Polygon , draggedVertex : Maybe Id } type alias Polygon = Dict Id Coords type alias Id = Int
The drag starts when the user presses down on a vertex to select it. For this we'll need to calculate the vertex closest to the cursor, which we can do if we know the positions of the cursor and all vertices. Lets create a Msg type that contains those positions. We can reuse the Coords and Rect types from the previous example.
type alias Msg = { event : DragEvent , cursor : Coords , handlers : List ( Id, Rect ) } type DragEvent = Start | Move | Stop
Perfect! Now we can calculate the rectangle closest to the cursor when the user clicks.
closestRect : Coords -> List ( id, Rect ) -> Maybe id closestRect cursor handlers = handlers |> List.map (Tuple.mapSecond (distance cursor List.sortBy Tuple.second |> List.head |> Maybe.map Tuple.first center : Rect -> Coords center = Debug.todo "Implementation omitted for brevity" distance : Coords -> Coords -> Float distance = Debug.todo "Implementation omitted for brevity"
Once we have found the vertex the user picked up we have to move it to the cursor on every Move event. The resulting update function looks like this.
update : Msg -> Model -> Model update { event, cursor, handlers } model = case event of Start -> { model | draggedVertex = handlers |> List.filter (\( _, handler ) -> distance cursor (center handler) closestRect cursor } Move -> case model.draggedVertex of Just id -> { model | polygon = Dict.insert id cursor model.polygon } Nothing -> -- The user is dragging the cursor, but nothing was picked up on the -- start event. We'll sit this one out. model Stop -> { model | draggedVertex = Nothing }
And that's that! Again I skipped over the JavaScript that produces our messages and I promise we'll get to that in a moment. The full polygon editor source code is available for those interested!
Last example: an outline editor
Our final example is an outline editor. An outline is a tool for organizing our thoughts on a subject, but creating a list of concepts related to the thought, each of which have their own related thoughts, and so forth. The following image shows an example outline which can be re-arranged using drag & drop. We'll keep our scope small again by not bothering with creating and deleting nodes.
We'll start by creating a model for our outline editor. It will need to keep track of two things: the outline itself and which node we're dragging.
type alias Model = { outline : List OutlineNode , draggedNode : Maybe DraggedNode } type alias DraggedNode = -- For simplicity sake we're going to use the node's contents as an id. -- We get away with that here because we can ensure the nodes are unique: -- the user will not be able to edit them in this example. { node : String , cursorOnScreen : Coords , cursorOnDraggable : Coords } type alias OutlineNode = Tree String type Tree a = Tree { node : a , children : List (Tree a) }
Now we'll need to write behavior for the drag start, move, and end events.
The drag starts when the user pressed down on a node. We can put an onClick handler on each node to detect when this happens. We'll skip the implementation in this post, but it's part of the full outline editor source code!
Then, as the user drags a node around we need to update that node's location in the outline. This part we're going to look at in detail.
Lastly the drag stop event. We already changed the outline while the user was moving the cursor, and so all that's left to do here is change the model to its non-dragging state by setting draggedNode to Nothing.
Moving nodes in an outline
The most challenging part is to decide what the user's intention is. Are they intending to move the dragged node in front of another node, behind it, or nested beneath it?
Using dropzones we could draw invisible boxes in those positions that activate when the user moves over them, but the experience is unlikely to be great. Make the boxes too small and the user will not spend a lot of time over them, making the interface unresponsive for most of the time. Make the boxes too big and they start to overlap, causing the uppermost box to receive the dragged node even if it's not the closest. And even if we get the boxes right a future update changing page styles might move the boxes, breaking the drag & drop interaction.
Let's forget about dropzones and think about the behavior we want. There are candidate positions in the outline where we could drop a dragged node. As the user moves we'd like to display the dragged node in whichever of those positions is closest to the cursor. To figure out which position is closest we need to know where they all are. To do that we are going to put invisible elements in the DOM at each position where we can insert the dragged node. Contrary to the dropzones approach we're not going to bother giving these elements any special dimensions or positioning. We want them to just flow with the content on the page, and keep us apprised of their location. These aren't dropzones but beacons.
Apart from their coordinates in the DOM, our beacons will also need to describe their location in the outline. A beacon can define its location relative to another node in the outline.
type CandidatePosition = Before String | After String | PrependedIn String | AppendedIn String
We'll create a JSON encoder for this type so we can tag each beacon element with a data attribute containing its position in the outline. We'll then set up our JavaScript to find all elements with such a data attribute in the DOM and feed their coordinates back to us on each drag event. That will allow us to define a type for drag events containing the positions of our beacons on the screen.
type alias DragMsg = { cursor : Coords , beacons : List Beacon } type alias Beacon = ( CandidatePosition, Rect )
Remember the closestRect function from the polygon example? It's what we need to find the CandidatePosition closest to the cursor! Once we know which candidate position is closest, all we need is a function to that moves a node to its new position in an outline. It's a tricky function to write, but it doesn't have much to do with drag & drop and so I'm skipping the implementation here. I include a solution with the outline editor source code. For those interested in some thoughts on how to approach data transformations like these, I refer to an earlier post on conversion functions, which includes an example of a similar tree manipulation problem.
Necessary JavaScript
I promised I'd get back at the JavaScript required to make these examples work. All three examples use the same JavaScript code, because it turns out they have the same needs. In every example there's one or more Html elements on the page that we need to track the position and dimensions of as a drag interaction takes place. What our JavaScript code needs to do is generate events when the mouse gets pressed, moved, and released, and bundle with those events the positions of all elements we want to track. We identify those elements by giving them a data attribute with their 'beacon ID'.
There's tons of ways to write this code and I don't believe mine is particularly insightful, so I'll not reprint it here. The draggable.js source code for these examples is available though for those interested.
Conclusion
When we need to perform a complicated task it's natural to start by looking for a library to do the heavy lifting for us. For building drag & drop interactions libraries give us draggables and dropzones but they are often a bad fit for drag & drop UIs, of which we've seen three in this post.
Are drag & drop libraries always a bad idea? I don't think so. In particular there are libraries for specific drag & drop widgets such as re-arrangable lists, for example annaghi/dnd-list. Using those when possible could save a lot of time. There are probably UIs where draggables and dropzones are precisely the right abstraction. Please send me a note if you ran into one of those, I'd love to learn about it! Drag & drop covers an incredibly broad range of functionality though, and so often an off-the-shelf solution will not be available. For those I'd put serious thought into whether draggables and dropzones are going to help build the UI or make it harder.
I recommend using 'beacon elements' if you build your own drag & drop behavior. These are regular DOM elements marked so we can access their location on every drag event. Because beacon elements don't need to do anything any element using any positioning strategy can be a beacon. This passive nature distinguishes beacons from draggables or dropzones, both of which include behavior.
I've showed a different approach to building drag & drop UIs. In this approach we subscribe to drag & drop events telling us what's happening in the DOM, update the state of our model based on those events, and finally update the screen to reflect the new state of the model. This is nothing more than the Elm architecture. I hope the examples in this post show writing drag & drop logic does not need to be an arduous task.
Jasper Woudenberg @jasperwoudnberg Engineer at NoRedInk
Thanks to Ary, Blake, Brian and Stöffel for their reviews of drafts!
0 notes