
Last Seen Blogs

spookprincess
Reference Blog
spookprincess
Reference Blog

nightlifeseriescc
NightLifeSeries-Custom Content

34613531-blog
Sem título

bollywoodbunny
Bollywood Bunny
Text
Prompt Reverse Engineering
TL;DR
无法准确还原;
利用image captioning的思路结合AIGC特定数据源,可以生成prompt-like的词组来近似可能产生相似图片的词组
背景
在AIGC场景中,特定场景下需要基于生成的图片反推其所使用的prompt
原理
为什么不可能准确还原:生成一张图类似做一个函数映射,y=x1+x2+...Xn+random noise。 同样想得到一个y=10,可以是1+9,也可以是4+6,甚至可以是1+2+3+4。只给一张图,输了几个词都不知道,那么自然无法准确还原。更别提还有随机项,y=10,但可能x1+x2=9(random noise=1),也可能x1+x2=8(random noise=2),准确还原prompt几乎不可能。(说几乎是不确定在特点embedding模型下有无hack空间,但可以当作不可能来理解)
CLIP interrogator 在做什么:它先用BLIP生成图片的caption,具体技术还是可以归为image captioning那一路,不是去反推prompt而是单纯去理解图片生成语言描述。在此基础上(以下为综合信息的推测),它还会调用图片embedding,去四个text-to-image的常用库里去做向量相似计算,找出embedding相近的关于artist、画风的词,与BLIP生成的描述用逗号拼接返回。用CLIP interrogator也无法反推prompt,而是对图片生成自然语言描述,并用特定的AIGC常用词进行风格描述,希望以此在txt2img场景下能得到近似结果(祝你好运)
BLIP简单介绍:相比之前主要是2点改进,训练数据的提纯和结构 https://arxiv.org/pdf/2201.12086.pdf

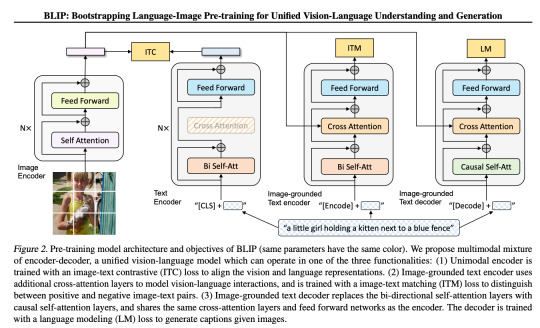
应用
如果看到这还想用,那么Stable Diffusion WebUI已提供此功能,直接调用即可
0 notes
Text
Stable Diffusion Fine-tune的4种写法

ControlNet

Pre-trained ControlNet Models: https://huggingface.co/lllyasviel/ControlNet/tree/main/models

Extension installation&Usage: https://github.com/Mikubill/sd-webui-controlnet

0 notes
Text
A Brief Introduction To Diffusion Models
Demos
Applications
Image Editor: Photoship plugins like
Effects in Shorts https://youtube.com/shorts/uW13BzNcy-k?feature=share
Music generation: Riffusion
Video Generation(very early stage)
Marketing
Creator Marketing tools
And lots went to NSFW(especially with the leaked models from NovalAI which specialized in animation)
Players
OpenAI: DELL-E/DALL-E 2
Google: Imagen: Text-to-Image Diffusion Models
Meta: Make-A-Scene
Microsoft: NUWA-Infinity
Midjourney
And other Stable Diffusiion powered start-ups
Generating Images: Variational Diffusion Models
What is generation

Given observed samples x from a distribution of interest, the goal of a generative model is to learn to model its true data distribution p(x). Once learned, we can generate new samples from our approximate model at will
Variational Autoencoders
Incorporate latent variables: we can think of the data we observe as represented or generated by an associated unseen latent variable, which we can denote by random variable z.
And how to approximate : Evidence Lower Bound (ELBO)
Hierarchical Variational Autoencoders
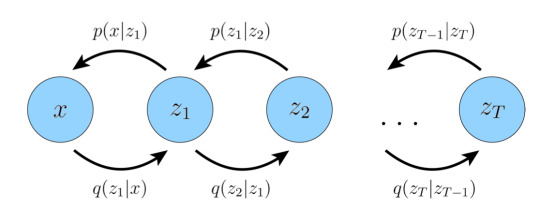
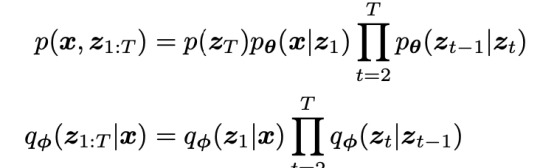
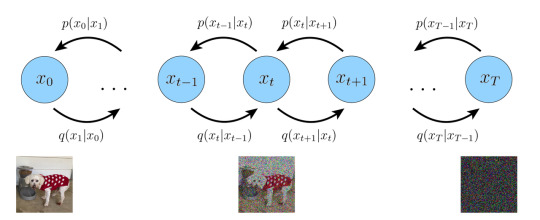
Variational Diffusion Models
HVAE with Properties
The latent dimension is exactly equal to the data dimension
The structure of the latent encoder at each timestep is not learned; it is pre-defined as a linear Gaussian model. In other words, it is a Gaussian distribution centered around the output of the previous timestep
The Gaussian parameters of the latent encoders vary over time in such a way that the distribution of the latent at final timestep T is a standard Gaussian
Workflow in a nutshell
Three equivalent objectives to optimize a VDM( derived from ELBO in the appendix,reparameterization trick and VDM's properties)
Learning a neural network to predict the original image x0
Learning a neural network to predict the source noise ε0 (empirically, some works have found this resulted in better performance)
Learning a neural network to predict the score of the image at an arbitrary noise level ∇logp(xt)
How it works then
The basic architecture
The learning and inference process
Other details
The weighting of the training obj for different timesteps
Noise schedule
Trilemma and Variants
Advanced Forward Process
Parameterize the diffusion process, like αt
Non-Markovian diffusion process and denoising process
Momentum-based diffusion
Advanced Reverse Process
Conditional GANs
Advanced Models
Progressive Distillation
Stable Diffusion: lowered the cost, made it consumer-level and popular
Generating Images Under Guidance
A naive way is to add the guidance in the reverse process
Image conditioning: channel-wise concatenation
Text conditioning
Single vector embedding: spatial addition / adaptive group norm
Seq of vector embeddings: attention
Caveat: VDM may potentially learn to ignore or downplay any given conditioning information
Guidance : explicitly control the amount of weight the model gives to the conditioning information, at the cost of sample diversity
Classifier Guidance
Classifier-free Guidance
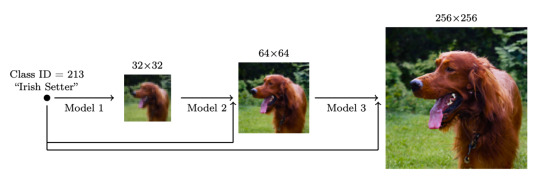
Cascaded Generation
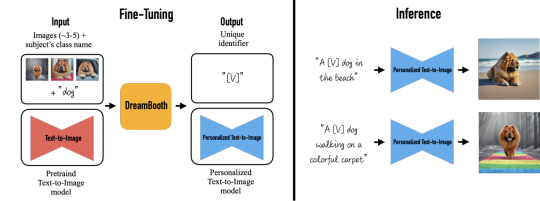
Subject-Driven Generation
DreamBooth
Background

Approach
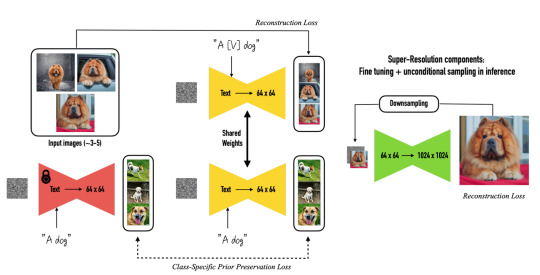
Results

Appendix
Understanding Diffusion Models- A Unified Perspective.pdf
TACKLING THE GENERATIVE LEARNING TRILEMMA WITH DENOISING DIFFUSION GANS
Tutorial on Denoising Diffusion-based Generative Modeling: Foundations and Applications
What are Diffusion Models?
DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven GenerationA Brief Introduction To Diffusion Models
Frechet inception distance (FID) and Inception Score (IS) for evaluating sample fidelity
For sample diversity, use the improved recall score
For sampling time, we use the number of function evaluations (NFE) and the clock time when generating a batch of 100 images on a V100 GPU.
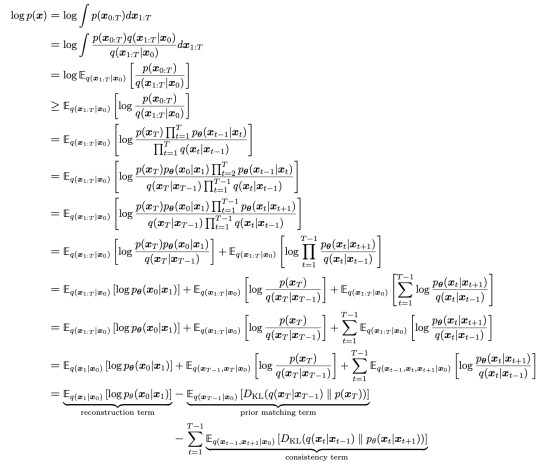
ELBO of VDM:
2 notes
·
View notes
Text
Stable Diffusion Service Deployment —— SD WebUI on CentOS7
框架依赖安装
1. sudo yum update 并重启
更新ssl,为了安装Python3.10.6
whereis openssl | xargs rm -frv
yum install perl-ExtUtils-CBuilder perl-ExtUtils-MakeMaker perl-CPAN -y
<!-- 进入perl命令行内执行 -->
perl -MCPAN -e shellinstall IPC/Cmd.pm
<!-- 下载SSL version>=1.1.1k 2021-3-25 -->
wget https://www.openssl.org/source/openssl-1.1.1q.tar.gz
tar -zxvf openssl-1.1.1q.tar.gz
cd openssl-1.1.1q
./config --prefix=/usr/local/openssl --openssldir=/usr/local/openssl shared zlib
make && make install
echo "/usr/local/openssl/lib" >> /etc/ld.so.conf
ldconfig -v
ln -s /usr/local/openssl/bin/openssl /usr/bin/opensslopenssl
安装Python3.10.6,为了能运行特定版本torch/CUDA
whereis python3 | xargs rm -frv
whereis pip3 | xargs rm -frv
yum install -y zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gcc make python3-devel libevent-devel python-gevent libffi-devel
wget https://www.python.org/ftp/python/3.10.6/Python-3.10.6.tgz
tar -zxvf Python-3.10.6.tgz
cd Python-3.10.6
./configure --prefix=/usr/local/python3 --with-openssl=/usr/local/openssl
make && make install
ln -s /usr/local/python3/bin/pip3 /usr/bin/pip3
ln -s /usr/local/python3/bin/python3 /usr/bin/python3
python3 --version
4. 安装Git(>=1.8.5),为了能执行大文件下载
yum install epel-release
yum remove git
yum install https://repo.ius.io/ius-release-el7.rpm
yum search git2 //下行的具体版本会变,可通过search确定
yum install git236
yum install git-lfs
安装显卡驱动
yum install pciutils
wget https://us.download.nvidia.com/tesla/460.106.00/NVIDIA-Linux-x86_64-460.106.00.run
yum install -y kernel-devel-$(uname -r) kernel-headers-$(uname -r)
sh NVIDIA-Linux-x86_64-460.106.00.run
nvidia-smi
框架安装
wget https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/webui.sh
<!-- 修改webui.sh脚本,将默认路径从 /home/$(whoami) 改为自定义路径 -->
<!-- 改个清华镜像加速-->
/......../stable-diffusion-webui/venv/bin/python3 -m pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple sh webui.sh
<!-- 如果安装出现问题,可以先自行git clone 到local,再如下从本地安装 -->
/......../stable-diffusion-webui/venv/bin/python3 -m pip install git+file:///data/sd/GFPGAN
/......../stable-diffusion-webui/venv/bin/python3 -m pip install git+file:///data/sd/CLIP
/......../stable-diffusion-webui/venv/bin/python3 -m pip install git+file:///data/sd/open_clip
<!-- 如果安装出现zlib版本问题 -->
从 https://github.com/DiffusionHub/DiffusionHub 下载zlib-1.2.9
tar -xvf ~/Downloads/zlib-1.2.9.tar.gz
cd zlib-1.2.9
sudo -s
./configure; make; make install
make install完会生成zlib-1.2.9,将/lib下的libz.so和libz.so.1 软链接到这个zlib-1.2.9,如 ln -s -f /lib/libz.so.1.2.9/lib libz.so.1
模型安装
Stable Diffusion模型
2.0以下模型可以直接把ckpt模型文件放在WebUI目录内models/Stable-diffusion 路径下
2.0及以上模型需要额外的参数描述文件yaml,可以从 https://github.com/Stability-AI/stablediffusion/tree/main/configs/stable-diffusion 下载相应yaml,分辨率为512x512的用v2-inference.yaml,768x768的用v2-inference-v.yaml* NovelAI leaked model
服务发布
WebUI: sh webui.sh --listen
API: sh webui.sh --nowebui --listen
指定使用的显卡,例如
0 notes
Text
一段(可能)因谓词下推导致的impala on parquet query bug
引子:
1.执行下述语句,结果为a行
select count(1)
from t
where purchase_time >= '2020-10-01' and purchase_time <= '2020-10-31'
2.执行下述语句,结果 b, b<<a
select count(1)
from t
where purchase_time >= '2020-10-01' and purchase_time <= date_add('2020-10-01',30)
开始有趣:
3.我们能语料到步骤1与步骤2的差异,date_add('2020-10-01',30)返回的是timestamp对象,它的结果为 2020-10-31 00:00:00,不完全等于字符串'2020-10-31' 。但执行下述语句查明细,会看到结果中purchase_time明明满足表达式 purchase_time >= '2020-10-01' and purchase_time<=date_add('2020-10-01',30) ,但是不出现在右表中;
select l.*
from
(
select *
from t
where purchase_time >= '2020-10-01' and purchase_time <= '2020-10-31'
) l
left join
(
select *
from t
where purchase_time >= '2020-10-01' and purchase_time<=date_add('2020-10-01',30)
) s
on l.order_id = s.order_id
where s.order_id is NULL
limit 10
4.对上述语句中的右表where的布尔表达式执行等价变换,结果却是空集,与步骤3的结果不一致
select l.*
from
(
select *
from t
where purchase_time >= '2020-10-01' and purchase_time <= '2020-10-31'
) l
left join
(
select *
from t
where not( purchase_time < '2020-10-01' or purchase_time>date_add('2020-10-01',30))
) s
on l.order_id = s.order_id
where s.order_id is NULL
limit 10
5.hive works well。推测impala下部分数据未被扫描,怀疑谓词下推,看到资料https://docs.cloudera.com/documentation/enterprise/latest/topics/cdh_ig_predicate_pushdown_parquet.html#concept_pgs_plb_mgb 文档,发现parquet面向hive和impala的谓词下推不同,尝试关闭部分impala的谓词下推参数,结果正常set parquet_read_statistics=0
0 notes
Text
在手游公司做的一些微小贡献之LTV预测
一、背景
LTV(life time value 生命周期总价值),意为客户终生价值,是公司从用户所有的互动中所得到的全部经济收益的总和,对LTV进行准确预测的价值不言而喻:在产品立项前进行ROI测算以避免损失,在运营中进行预测以调节营销预算投放的节奏,细致预估每个用户的终生价值来提前进行差异化的服务……
在游戏产业,“LTV”里的“价值”,有以下4种来源:
IAP:应用内付费;
订阅:如传统的月卡;
AD:广告费用,特别适用于无IAP的休闲类小游戏;
其他:周边产品的购买,影视小说衍生品的消费等;
我们主要讨论第一种,且暂不考虑折现、汇率变化等情况。
预测LTV的方法,主流的方法有3种:
经验类比法:如依据留存、ARPU、DAU、ARPDAU等信息,按照一定的比例(“LTV180是LTV3的5倍”)计算得出;
古典BTYD法:基于RFM框架,认为用户未来的消费行为仅与过去的消费行为相关(更严格地说是金额、次数、时间间隔相关),每人皆服从一定的概率分布。
酷炫DL法:基于深度神经网络,可利用丰富特征和复杂结构,将问题化为回归问题解决;
本次讨论、尝试了第二种BTYD的方法。
二、BTYD
BTYD(Buy Till You Die)是一类方法的通称,主要描绘的是非合约式的交易场景下卖方如何确定自己的客户,并进而去预测他们未来的购买次数、消费金额等。
在合约式场景下,一家公司想要知道自己有多少客户,只要看下当前有多少人处在合约中即可,比如自如只用看下active的租房合同就能知道自己有多少租客,一家公司统计下劳动合同就能知道自己有多少员工。客户的流失能通过“合约结束”这一明显的信号被公司感知到。
但在非合约的场景下,“有多少客户”就难以确定了,比如一家街边的小卖部,它无法确定某个时刻自己的“客户”有多少,更不用说去预测未来每个客户会消费多少了。
IAP的游戏就是一种非合约的商业场景。我们能通过注册数、过去的登录数得到一个“客户"的上限,但当前有多少“客户”还是无法确定的。
针对非合约式的交易场景下的此类难题,Schmittlein等人于1987年首次提出BTYD方法予以解决。发展至今,BTYD主要包含三个模型:
Pareto/NBD:1987年提出的开山模型,下文将阐述;
BG/NBD:基于Pareto/NBD,放松假设来简化计算。Pareto/NBD的简化版;
GG/NBD:Pareto/NBD和BG/NBD都只是预测客户的未来消费次数,不涉及金额。GG将金额也纳入进来。
Pareto/NBD
Pareto/NBD本来只是为了解决“在非合约场景下如何判断某个人是否还是客户”而提出的概率模型,但这个模型的一些性质使得它可以被应用到LTV预测上。
模型仅使用3项信息
X:购买次数
t:最后一次购买时间
T:统计期截止时间
来估计客户当前是否还alive(还是客户)
Pareto/NBD把客户的购买行为拆成两个process:服从Pareto(Pareto Type II distribution)分布的存活概率模型(在某个时间点客户是否还是客户)以及服从NBD(negative binomial distribution)分布的购买次数模型。
而Pareto分布和NBD分布,是经由5条基本假设推导后自然而然引入的,感兴趣的可以看原文附录
从1、2两条假设,我们能很轻易地写出某个客户的P(Alive|Information)
那问题解决了吗?并没有。
因为关于单独的一位客户,我们没有太多的数据去直接做λ和μ的估计。
好消息是基于假设3、4、5,可以用r、s、α、β这4个参数来做估计。而这4个参数是distributed across所有样本,就使得我们有充足的数据来做参数估计。
求得r、s、α、β这四项参数后,对某个客户预测截止到未来时间T*的购买次数X*期望,再通过LTV=期望购买次数*平均单价 就可以大致计算得出某个客户在一定时间窗内的消费金额,也就是我们关心的LTV(此处平均单价可以简单对历史数据求平均得到)。
至此,我们已可以基于Pareto/NBD去进行LTV预测。(另,因为懒 因为BG和GG都是基于Pareto/NBD的一些变种,BG改变了假设2中对于流失概率分布的选择来简化计算,GG增加了对于金额的分布假设,故不冗余叙述,感兴趣的同学可以在论文库中找到相应原文。我们也可以对5条假设中的其他假设进行合理挑战,就可以创造出新模型)
BG/NBD
GG/NBD
三、基于lifetimes的LTV预测实践
目前基于Python的BTYD工业界实现很少,影响力较大的只有lifetimes ( https://github.com/CamDavidsonPilon/lifetimes ) ,Google在Google Cloud的案例介绍中也是使用的这个package。
lifetimes对BTYD对实现与论文不完全一致,它被设计成仅处理有过购买记录的人,在样本构造时需要注意(https://lifetimes.readthedocs.io/en/latest/Quickstart.html#the-shape-of-your-data)
在lifetimes中的调用非常简单,用pandas的dataframe构造数据后,将购买次数、首单-尾单时间差、首单-当前时间差这3个参数feed给模型即可。
这个模型的主要算法工作,主要是在参数估计的损失函数设计及最优化方法的选择、实现上,已有多个Pareto/NBD的变种实现。这部分太过detail,在此不介绍,如果感兴趣可以再展开写。
0 notes
Text
Python 深入
1.在int_dealloc中,永远不会向系统堆交还任何内存。一旦系统堆中的某块内存被Python申请用于整数对象,那么这块内存在Python结束之前,永远不会被释放
0 notes
Text
摘录CSDN对TD的访谈
原文地址 http://www.csdn.net/article/2014-02-12/2818242
CSDN:TalkingData现在的商业模式是什么?
崔:在数据分析上经历了三个阶段。最开始是做通用的分析工具,比如留存率分析、活跃度分析,类似于国外的Flurry,那时候Flurry如日中天,MixPanel刚转型到移动,Apsalar也刚刚出来,国外做类似产品的大概有20多款商品,但只有Flurry是免费的,包括国内的友盟也是走这样的路子——免费+广告的模式,但当时我们没太想明白这种模式,所以也没做,加上当时定位就是纯数据相关的服务,没有想过要进入一个特定的业务,所以就没有走F2P路线。
其实大家都以为免费好,可能对于普通用户来讲,免费是好,但是对于企业用户,如果你免费了,人家会怀疑你的实力、动机,以及生命力,反倒起反作用。我们的垂直服务,包括游戏、电商、金融等服务全是收费的,其实企业的核心诉求还是服务质量和安全性,比如跟平安、招行的合作,如果免费,人家会认为你一家创业公司能撑多久?一些游戏的开发者很多都很有钱,宝开、触控、乐逗不在乎你的钱,如果你免费,人家会怀疑你是要用我的数据吗?所以免费逻辑在这时候并不成立。
数据对很多开发商的意义不同,在电商那里可能是第一敏感,到游戏哪里,可能就不是了,比如移动游戏,很多生命周期都比较短,可能只有一两年,他们在意的是怎么在有限的时间里利用好数据,从而带来更多利益,而不是免费。
很多人建议,你现在有移动游戏的几乎所有数据,不仅是活跃度、安装量、还有收入,你们应该做发行平台,很快你们就能成为大的游戏分发商;有的人也建议,你们是最大的移动广告监测平台,差不多有80%的开发商有合作,包括Inmobi,既然有这么多的广告监测数据,就应该做DSP平台,很快就能变大;也有人说,你有那么多的金融客户,就应该做互联网金融。反正有很多人告诉你很多可能性。
但从创业开始就想的比较清���,不会做任何具体业务,只提供数据服务,这份工作本身是个慢活,但需要中立性,一旦进入一个业务,你可能就失去了中立性,所以TalkingData只做数据挖掘、分析。
另一方面,如果把移动互联网看成一个数据源,有开发者愿意提供数据,有大客户愿意花钱交换这些数据,TalkingData则提供数据交易平台,这在国外有很多例子。
CSDN:你觉得针对移动互联网,数据分为哪几类?TalkingData主攻哪一类?
崔:如果纯针对移动互联网,那么数据类型有三大类:
第一个类是基础信息,比如设备信息。用了什么设备?芯片是什么?用了什么运营商的服务?这些信息有用吗?有用,因为很多设备商运营商会购买报告,但是我们没有走这条路,因为在中国卖数据报告是不可行的,至少没有成功的先例,而且容易走偏。
第二种类型的数据就是与应用相关的数据,包括客户用了哪些应用?程度有多深?因为和很多应用商店合作,所以我们会交换到很多这种数据,这些数据很有价值,很多投行也会来问我们,那些上市公司应用情况到底是什么样的?在Android的排名到底是不是真的?其实我们都有,但是不会说,说的意义不大,在这样的复杂的环境里面,没必要说。
第三种是客户行为数据,反应客户的消费倾向性、交易行为、喜好、位置信息,这些数据蕴含巨大价值,但这些数据价值的挖掘需要找到一种可行的方式,所以现在我们在金融领域大量尝试这种方法。金融实际是数据的大客户,现在所有银行都想推出一些基于风控系统的新型信息系统。
1 note
·
View note
Text
Pickling Error: can't pickle <class 'xxxx'>: it's not found as __builtins__
这个问题只出现在Python2上,Python3没有问题。这是因为多进程之间要使用pickle来序列化并传递一些数据,但是实例方法并不能被pickle,参见Python文档,可以被pickle的类型列表,还有在Python3中实例方法可以被pickle了,见Python bug list
最简单的解决办法就是写一个可以被pickle的函数代理一下
0 notes
Quote
The amount of time for which the behavior of a chaotic system can be effectively predicted depends on three things: How much uncertainty we are willing to tolerate in the forecast, how accurately we are able to measure its current state, and a time scale depending on the dynamics of the system, called the Lyapunov time.
https://en.wikipedia.org/wiki/Chaos_theory
0 notes
Text
很惭愧 就做了一点微小的工作
算算离开CE到百度已经1个月了。
在CE时转做机器学习感觉excited,觉得跳百度也不错,毕竟是看着Andrew Ng的视频学习。
哪曾想……如果如果这就是人类的一线水平,我很失望
看来还是要self-educate
+++++++++++++++++++++++++
996的生活节奏,再加上单程2小时的路程,就会很容易开始低沉。
再过三十年,我和葡萄干有什么区别呢?都是皱巴巴的,没有前列腺。只不过葡萄干是一开始就没有前列腺
0 notes
Text
所以……rework到底是什么意思
一开始是Z晟推荐的,看书名还以为是讲迭代、重构之类的,就放了很久,后来刷完Kindle的存书才买了看。
泛泛的说,《重来》可归为企业经管方面的,只不过更贴合新经济。
总体内容还是可以的,作者以“我是见得多了”的过来人的态度和你讲一些人生的道理。全书压缩一下可以成为一套小学生日常行为守则一般的指导。
赞扬的话太多,说两点减分项吧:
1.可能因为我看得晚了,不热乎了,所以作者的一些观点在我看来是个三观正常、智商尚可的信息技术从业者应该能想到的。当然,如果有人懒,没时间想,那他看看这本书应该可以省下不少时间。
其实很多观点我觉得大家都是懂得的,那为什么还会这么做?Compromise under certain condition 罢了。
2.作者现身说法表示旧商业规矩不一定对。但议论文摆事实总是比讲道理薄弱,因为只能证伪,不能证明。作者列举的新守则使得37signal走到了现在,只是经验总结,一如旧商业规矩。那各自的适用范围如何?若盲目套用会不会有害?
还有,像在《Embrace constraints》一节中,作者为了论证“条件受限”貌似缺陷实为优势,举例西南航空采用统一机型通用配件降低运营成本。但这是廉价航空代表之一的 西南航空主动选择的一种市场策略(其他战略还包括还包括直航为主、低成本机场运营等),而不是“条件受限”。
理论上讲,我能取到全集,会比取到子集好,因为大不了我选择全集中的子集。如果硬要说全集让人乱花迷眼,那也是人的问题而不是全集的问题。硬要限定 每个产品只让1~2个人去设计,防止产品臃肿,那也是人员问题,没有合适的decision maker,人少不必然使得产品精简。
我仿佛看到作者像广大高中生一样找到一个论据硬往论点上靠。
++++++++++++++++++++++
一两个例子不能说明这个理论一定对,但说明不是一定错。本书主要还是给打了点鸡血,指了一条可能的路,还是值得借鉴
0 notes
Text
Really a sad story
一个活过了伊拉克战争并移民美国的伊拉克人,在达拉斯公寓门口拍生平看到的第一次雪景时被路人随机射杀
Hit by sadness
0 notes
Text
10分钟
看过印象最深的一部短片,是一个雅鲁撒冷的小朋友为家里打酱油,路上打闹着回来,邻居和善,物阔天空,快到家门遇到轰炸,家人已全部遇难,被邻居扛着救出了战乱,这一切,都发生在一个日本人等着照片洗出来的十分钟内。
这几天为转岗发愁,听着几个有的没的吵闹,做着有的没的工作,听着互联网,学着大数据,从新闻上看看小角色的感情风波,引力波痕迹没有发现,ISIS杀了谁,博科圣地又屠杀了多少人……
为死的人,能本来做什么呢。自己做的又算什么
在为自己这点愁绪纠结的十分钟内,河外星系的某个双星系统中的文明又在经历什么
0 notes
Text
戴记
离开戴记一个月了,还是写一点罢
毕业时,本来打算的还是考CCER。但是人生就是很奇妙地安排我���去找工作,其时已经临近毕业,校招季早过去了,连海报都垂下了角。所以在收到Carol发出的面试时,还是挺高兴。
面试地点在嘉里中心,当时一侧还在装修,寻门颇为不易。上楼,笔试、群面,被Tom的描述打动,本来无所谓的心态就变得严肃起来,“想赢”。
然后就回去等结果。结果不错。(记得当时还在和Liu Tao, 赛格在游泳馆里畅滚,出来发现手机里有个未接,懊丧紧张,杀了赛格的心都有了。)
入职之前,先给Nicole做了几天翻译,倒是提前认识了同事,战战兢兢,深埋本性。
新员工培训也是在嘉里。大学四年基本没早于10点起来过,要做上班族了,在檩爷推荐下,每天早上从金台夕照出来,先去报刊亭买一瓶黑卡6小时。培训 内容基本很虚,伙伴包括我在内一共8人,主讲人每次提问没有人回答,显得太尴尬,因为提前认识了一些人,就逼着自己主动回答吧。短短几天,就和在读期间完 全不一样了……
先是上装备,给刘爽做视频,为了做太阳融化成宝石花的效果,把《东邪西毒》拉片拉了几十遍。
后来辗转A3,最黑暗的一段时光,第一次断片,滑雪技能Level 1,第一次车祸。
A3结束又回装备,咸阳、济南、成都出差愉快。
期间种种,涉及工作信息保密,主要是出于懒,就这样吧。
0 notes
Text
2014岁末
想着总结一发,但一年的事太多了,以后还是要常记才是。
读研的同学也快毕业了,接到好offer的老李,在找的小明;工作了几年安份不安份的,想辞的赛格,接到好offer的老郭,稳稳的老关,祝几位同伙都顺利。马上就要换到新公司了,希望自己也一切顺利。
晚上陪康师傅吃饭,为他回大成都继续搞科研践行。
工作上今年忽然开窍了,知道自己在做的是什么……嗯,以前也是知道自己在做的是什么(囧),应该算是进入了“看山还是山”的境界吧……
还有开窍的一点就是觉得社会不过是成例,法律不外乎人情(可能都不要到法律这一步,比如在检察机关起诉前就搞定)……觉得自己违法乱纪的可能性在加大啊。看史倒是多了份浸入,理解乱臣更容易了,比如最近在看的《东晋门阀政治》,对王敦、陶侃之流的做法及朝野意见更能体会。
对所谓的创业倒是更觉得可笑了。估值即是玩笑。反正我是对没用清晰可行的盈利模式的startup嗤之以鼻的。流动性泛滥,使竖子成名。当然,如果别人烧投资人的钱给全社会做公益,那双手赞成,这是另一种先富带动后富。
++++++++++++++++++++++
新的一年嘛,要考驾照,资产增长速度要维持100%以上,新工作要好好加油哟~
0 notes