
Last Seen Blogs

chadsaint
Sans titre

disneypsd
disneypsd
disneypsd
disneypsd

amys-manor
luca balsa’s wife (requests open!)

infomukeshrj-blog
potato tips Mukesh
Text
Sorting and Processing Efficiency
The following are my thoughts on some different sort methods. More information on the following sorts can be found on: http://www.sorting-algorithms.com/
Selection Sort
The Selection Sort algorithm is one of the most trivial sorts and is a quick solution for a sorting algorithm used in small applications. However for sorting larger sets of data, Selection Sort would not be suggested as it efficiency is quadratic, O(n2), regardless of the state of you data.
Quick Sort
The Quick Sort algorithm is a relatively quick sorting algorithm, hence the name, compared to most of the well known sorts. The Quick Sort in my opinion is the recommended sort to use as it is easy to implement and performs well in most cases. The only exception is that this sort does not perform well in cases where there are identical values as it takes O(n2) time. This happens because Quick Sort-ing a list with identical values will prevent the Quick Sort algorithm from partitioning the list any further, essentially accomplishing the same thing as Selection Sort. Otherwise Quick Sort is easy to modify to fit your needs and will usually perform at a logarithmic time, O(lg(n)).
Merge Sort
The Merge Sort algorithm is also one of the quickest sorting algorithms out of the other well known sorts. The Merge Sort in my opinion is a bit harder to implement as it requires a good amount of practice with recursion. Merge Sort is a good sort to use when the type of data you are working with may contain duplicate values or unpredictable values because the Merge Sort will partition the list into two halves regardless unlike Quick Sort. All in all Merge Sort runs at a O(nlg(n)) time.
Processing Efficiency
While talking about the efficiency of the different types of sorts, I would also like to mention the concept of memoization. Yes, indeed it is spelt memoization, I was just as sceptical. In a quick and dirty summary, the optimization technique, memoization, reuses the results of previous calculations given a parameter the same parameter to prevent repetition. In more technical terms when a function using memoization is called, given the function f(x) where 'x' is a parameter, and 'dict' is a dictionary:
Step 1. Is there a value for 'x' in 'dicti'? If there is then return the value.
Step 2. Since it's not in 'dict' then we have never calculated f(x) for this particular 'x'. Calculate f(x).
Step 3. Add f(x) into 'dict' with the key of x for future reference
As a result the calculations in f(x) are never executed if it has done the process before which optimizes efficiency. When I first learned about this technique I'd considered the many different applications where this technique may prove useful. I have eventually come to the conclusion that that memoization will only prove practical if the number of different values for the parameter is finite and small, and the function is called repetitively. If the number of different possible values that can be called on the function is infinitely large, this may result in an exceptionally large dictionary and may result in an overflow.
0 notes
Text
Sorting for Beginners
Most people have already seen sorting algorithms visually represented, but for those who haven’t be sure to look at: http://www.sorting-algorithms.com/. The visual representation of the different types of sorts really helped me grasp the the difference between the different types of sorts as well as their efficiency compared to each other, and is an excellent resource for those who have never done sorting. In addition to this, you should also try to write the different sorts because conceptually it may seem very easy to understand, however writing it in actual code tests your understanding of the different algorithms and your ability to utilize recursion.
I personally found merge-sort the hardest one to implement versus the other sorts covered in class, as it required a good amount of recursive thinking. Furthermore having done it previously in Java using arrays, using a list in python is much more convenient due to the ability to split lists. Below is a solution to merge sort which was written by Danny Heap, however his example did not include any comments as to what is happening, so for those who have trouble understanding what is going on, here you go!
def merge(L1, L2):
The final list that is merged
L = []
Reverse L1 and L2, since they are already sorted the largest values will be at the front after reversing
L1.reverse()
L2.reverse()
We will compare the two list to find the smallest values, then add them in order to L
while L1 and L2:
If the last value in L1 is less than the last value in L2 then we take the value from L1 and add to L
If you remember that we reversed L1 and L2 above, so now L1[-1] and L2[-1] are the smallest values in each of the lists
if L1[-1] < L2[-1]:
L.append(L1.pop(-1))
else:
If the last value in L2 is less than the last value in L1 then we take the value from L2 and add to L
L.append(L2.pop(-1))
Now that either L1 is empty or L2 is empty, we can add all the values in L1 or L2 because we no longer need to compare to find the smallest value because they are the next smallest values.
We reverse the lists again, so that smallest values are at the front
L1.reverse()
L2.reverse()
Now we append the lists, L contains all the smallest values compared, and L1 or L2 which have the next smallest values we did’t need to compare
return L + L1 + L2
def merge_sort(L):
If there is one element in L then the list, L, is already sorted
if len(L) < 2 :
return L[:]
else :
return the merged list of the sorted left half of L and the right half of L
return merge(merge_sort(L[:len(L)//2]), merge_sort(L[len(L)//2:]))
0 notes
Text
The Mistake I Nearly Made
Tuples in Python are rather weird, and people who are new to Python, like me, often forget that they are immutable.
You can access a Tuple just like a list:
t = (5, 2)
print (t[0])
This would print 5 of course, however the similarity between a Tuple and a list may cause some to try the following:
t[0] = 10
Unfortunately this does not work, as Tuples are immutable, unable to be changed. The only way to change is to re-assign a value to it:
t = (10, t[1])
0 notes
Text
Power of Python
Having previously implemented sorts in Java, after witnessing the implementation of quick sort in Python blew my mind. By coding like a Pythonista, the quick sort algorithm was implemented in one line, compared to the 15 - 20 if it were in Java.
(quick([x for x in L[1:] if x < L[0]]) + [L[0]] + quick([x for x in L[1:] if x >= L[0]]))
With the power of list comprehensions, sort methods in Python can be written in considerably less lines while being just as intuitive than other languages. This has ultimately convinced me that learning Python is worthwhile.
0 notes
Text
Searching a Tree vs a List
After taking a closer look into Binary Search Trees, I have realized that searching for a value through a Binary Search Tree has its advantages and disadvantages over the use of a Binary search algorithm for a list. From what I have observed it seems as though searching through a sorted list is exactly the same as searching through a Binary Search Tree that is optimized for all cases. However the Binary Search Tree provides us with the choice of optimization, whereas using the Binary search algorithm does not.
As an example we will search for 7 in the set of values 1, 2, 3, 4, 5, 6, 7:
Using the Binary search algorithm in the worst case possible, it would only take two comparisons, 4 and 6, before finding 7.
Similarly, If the set of values were in an optimized Binary Search Tree assuming that the likely hood of searching for any of the values are equal we have the tree:
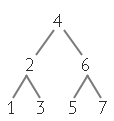
This would also take two comparisons, 4 and 6, before finding 7. On the other hand if the Binary Search Tree were to be optimized for specific cases it would be considerably faster in cases with larger sets. If we were to optimize for the value 7 we could have the following trees:
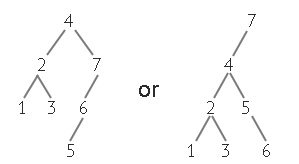
In both of these trees it would take less than 2 comparisons to find the value of 7 however, the tree's height is now larger compared to the tree optimized for all cases. As a result of optimization the efficiency of searching for certain values are now more efficient than the binary search algorithm, but at a cost of decreasing the efficiency of other values.
To summarize, I think a Binary Search Tree should only ever be used when there is a large discrepancy between the frequency of the most searched value and least searched.
0 notes
Text
The Web is a Mess
Time and time again I return to web development. As I enjoy creating user interfaces web development is one of the skills I would really like to have a grasp on. However it seems as though every time I go back I have no Idea of what I am doing. Every time it would be a trial and error basis with CSS and HTML. Although it took a while to understand how CSS work at a basic level, scripting in HTML is even messier than what I'm used to. jQuery or Javascript, the mix of the two scripting languages that are always used interchangeably due to their respective benefits has made it hard for a beginner like me to grasp a hold on web development. Certainly there must be some more organized way of creating websites!
0 notes
Text
List Comprehensions
As a programmer who does not normally use List Comprehensions it was rather difficult to get into the habit of using List Comprehensions. I found myself always writing code the long way and then replacing it with the list comprehension, which was highly inefficient. However, I found that it was easier to use list comprehensions if you were to look at the comprehension in the form of an equation:
x = What to do when true
y = Condition
z = What to do when false
[x if y else z for var in list or range]
0 notes
Text
Object-Orientated Programming and Recursion
Object-Orientated programming is a really neat way of thinking, in which will organize your code in a structured format. With Object-Orientated programming, computer scientists are able to create models and re-use them throughout their code. This way, their code is efficient and easy to understand. In my opinion an object oriented structured program is fundamentally required in complex programs as it acts as a guideline to creating a good workflow in the program. If one has a hard time grasping the idea of an Object-Orientated program, they can think of their program as a large company, where every type of employee is a different class of objects. Each type of employee(management, accountants, etc.) has a specific role, and same goes for objects.
Recursion is also another concept that most beginners have a hard time grasping. For computer scientists, recursion is very important as it enables us to solve problems quickly and efficiently. In addition recursion has enabled us to solve mathematical and scientific problems that we would have never been able to solve without it. The concept of recursion can be thought of as solving a large problem by solving the exact same problem except at a smaller scale and adding all the results together. If one has a hard time grasping the idea of recursion, it helps if you start thinking about the base case, the simplest case. After you have implemented the base case or base cases, think of the function as a solution and use it like you would a variable, but passing a more simple case as the argument every time it will be called until eventually it is the base case that is passed.
0 notes
Text
Tour of Anne Hoy With 4 Stools
At first this puzzle was a large challenge, until given a hint of how one should think of recursion. I realized that this problem was much like a math equation that needed to be solved using algebra.
M(n) = 2 + M(n - i) + 2i - 1
M(n) = 1 when n = 1
Given this equation for the smallest number of moves needed for n number of cheeses, I treated M(n) as one equation and i as another in effect I created two methods to solve this problem.
The first method, M(n), solves M(n) given an i, Whereas the second method, G(n), finds the i with the smallest number of moves. Thus we have M(n):
M(n) = 2 + M(n - G(n)) + 2i - 1
G(n) will ultimately call M(n) for every number, i, between 0 and n and record each move along with the i. Returning the i with the smallest number of moves.
Although it would be hard to understand fully of how this equation works, because it is almost impossible to trace for large amounts of cheeses, but intuitively the equation makes sense.
0 notes
Text
First Look at Python Exceptions
Surprisingly catching exceptions in Python is much like catching exceptions in Java. Although I've only ever found catching exceptions useful in web-based api calls, I can now see why try and catch blocks are explained in high detail. Catching exceptions in python allows us to understand more about what goes on behind the scenes when general exceptions are caught. In addition to this, it provokes programmers to think about the possible cases in which the code would not work under certain conditions and ultimately create dynamic code. Catching exceptions are more than just a tool that we can use, but it is also provides a good way of thinking when writing code.
0 notes