
Last Seen Blogs

theashesofthefirststar
The Spunky Nihilist

nickyandmikey
We'll wait till I understand it better

yafaemi
official paissa hugger


pissedoffdemeanor
neue douche härte
Text
Art-A-Hack™ 2023 Special Edition — Warsaw — AI Art in a Time of War
Projects -https://artahack.io/projects/

Alumni



Blog






0 notes
Text
June 21- Bye Bye At Least Now
youtube
When You’re a Jet
Bye Bye For Now Jets

You’re a Jet all the way
Group 1


Code
https://huggingface.co/TheBloke/koala-7B-GGML/tree/main
https://huggingface.co/CRD716/ggml-vicuna-1.1-quantized/blob/main/ggml-vicuna-13B-1.1-q4_0.bin
https://github.com/matib99/YourPersonalGod
Group 2




At the Gallery in Krakow
Group 3

Computing Power and AI Report
https://ainowinstitute.org/publication/policy/compute-and-ai
AI Reading Brainwaves
https://www.euronews.com/next/2023/08/21/this-mind-reading-ai-system-can-recreate-what-your-brain-is-seeing
Create Smooth Videos With Frame Interpolation
https://blog.programster.org/ffmpeg-create-smooth-videos-with-frame-interpolation
How to make frame blending effect
https://www.youtube.com/watch?v=N-HlldkE1Is
Frame Average Node
https://jayaretv.com/fusion/frame-average-node/
Github
https://github.com/vykhovanets/ai_video_pipe
From Lev Manovich:
(AI theory note 28)"AI and the history of digital culture."Generative AI media (2022–) is the fourth major effect of the gradual emergence of a giant digital universe of cultural content (the web). It was born in 1993, when the first graphic browser started popularizing the web. During the 30 years that passed, we see many effects, including these 4:1. The first effect is the switch from categorical, hierarchical and structured organization of information (exemplified by library catalogs and early web directories) to search engines in the late 1990s. There is so much content that organizing it in conventional ways is no longer practical, and search becomes the new default. (Note that search is based on a prediction of what will be most relevant to the user as opposed to giving you a precise answer. AI today is also predictive...)2. The second major effect that interests me is the development of data visualization in first part of the 2000s - another attempt to deal with new data scale. It emerged as a new hip cultural field in 2005-2006. If search attempts to find the most relevant items in the giant data universe, visualization tries to show it as a whole.3. The third effect is the emergence of "data science" as the master discipline of the new era at the end of the 2000s. (While most methods data science uses have already been available for decades, the rapid increase in unstructured data in the 2000s motivated the development of data science as the key new profession of the data society.) My own version of this stage - "cultural analytics" research, 2005-2020. And of course my main method for this research is data visualization but applied to media (images, film, etc.)4. The next, and certainly not the last, major effect of the growth of “digital content society is generative media (GenAI) in the early 2020s. If data science focuses on finding patterns, relations, groupings, and outliers in big data, and if data visualization tries to summarize it visually, generative AI (i.e. particular machine learning pipelines) approaches “big content” in a different way. It allows the generation of new content with statistical properties related to existing content. Moreover, this new content (texts, images, animation, 3D models, etc.) can interpolate between existing data points, thus creating new content that goes beyond a summary of what already exists. Thus, we move from probabalistic search to probabalistic media generation, 1999 - 2022.
0 notes
Text
Week 15 - June 16 - 21 - Race To The Finish



Tony and Sasha our Ukrainian colab members visit from temporary residence in Estonia- Hooray!
Group 3
Media Lab at U of Warsaw
https://www.lbm.uw.edu.pl/lbm.uw.edu.pl
https://www.youtube.com/watch?v=iHx7HjioZH0&t=34s
Killer Robot Dogs Set For War
https://www.dailymail.co.uk/sciencetech/article-11896135/Killer-robot-dogs-controlled-soldiers-MINDS-trialed-Australian-army.html
Eight Reasons To Prioritize BCI Cybersecurity
https://cacm.acm.org/magazines/2023/4/271242-eight-reasons-to-prioritize-brain-computer-interface-cybersecurity/fulltext
Neuralink, OpenWater, DARPA N3, Our Future Matrix-Style Immersive VR
https://hackernoon.com/neuralink-openwater-darpa-n3-and-our-future-matrix-style-immersive-vr
DARPA-funded efforts in the development of novel brain–computer interface technologies
https://www.sciencedirect.com/science/article/pii/S0165027014002702
BCI Experiment Elektryczny Ślad Myśli i Interfejsy Mózg-Komputer
https://www.youtube.com/watch?v=IldyXnyxtVw
Class Readings
EU Lawmakers Lay Groundwork For Historic AI Regulation
https://www.dw.com/en/eu-lawmakers-lay-groundwork-for-historic-ai-regulation/a-65909881
Autism As A Disorder of Dimensionality
https://opentheory.net/2023/05/autism-as-a-disorder-of-dimensionality/
Edwin Starr - War What Is It Good For - Absolutely Nothing
https://www.youtube.com/watch?v=ztZI2aLQ9Sw
Jackie Chan Sings War
https://www.youtube.com/watch?v=r-bA9FYB8HY
Nature Magazine Bans AI Art
https://news.artnet.com/art-world/nature-magazine-bans-ai-art-2321296?utm_content=from_artnetnews&utm_source=Sailthru&utm_medium=email&utm_campaign=6/18%20Sunday%20AM&utm_term=Daily%20Newsletter%20%5BALL%5D%20%5BMORNING%5D
Grammy Award Issues Statement on AI Content
"Artificial Intelligence (AI) Protocols
The GRAMMY Award recognizes creative excellence. Only human creators are eligible to be submitted for consideration for, nominated for, or win a GRAMMY Award. A work that contains no human authorship is not eligible in any Categories. A work that features elements of A.I. material (i.e., material generated by the use of artificial intelligence technology) is eligible in applicable Categories; however: (1) the human authorship component of the work submitted must be meaningful and more than de minimis; (2) such human authorship component must be relevant to the Category in which such work is entered (e.g., if the work is submitted in a songwriting Category, there must be meaningful and more than de minimis human authorship in respect of the music and/or lyrics; if the work is submitted in a performance Category, there must be meaningful and more than de minimis human authorship in respect of the performance); and (3) the author(s) of any A.I. material incorporated into the work are not eligible to be nominees or GRAMMY recipients insofar as their contribution to the portion of the work that consists of such A.I material is concerned. De minimis is defined as lacking significance or importance; so minor as to merit disregard."
How Advertisers Label You
https://themarkup.org/privacy/2023/06/08/from-heavy-purchasers-of-pregnancy-tests-to-the-depression-prone-we-found-650000-ways-advertisers-label-you
Inside The AI Factory
https://nymag.com/intelligencer/article/ai-artificial-intelligence-humans-technology-business-factory.html
Sarah Silverman Sues Open AI
https://www.theverge.com/2023/7/9/23788741/sarah-silverman-openai-meta-chatgpt-llama-copyright-infringement-chatbots-artificial-intelligence-ai?utm_source=Iterable&utm_medium=email&utm_campaign=newsletter-20231207
0 notes
Text
Week 14 - June 7 to June 13

Group 1
Group 2
GitHub - NVlabs/instant-ngp: Instant neural graphics primitives: lightning fast NeRF and more
https://github.com/NVlabs/instant-ngp
GitHub - tetragonites/wolf3d: code four AI Alg Art project number 2code four AI Alg Art project number 2. Contribute to tetragonites/wolf3d development
https://github.com/tetragonites/wolf3d
https://github.com/users/tetragonites/projects/1

Group 3
Class Notes
How Sam Altman Stormed Washington to Set the A.I. Agenda.The chief executive of OpenAI, which makes ChatGPT, has met with at least 100 U.S. lawmakers in recent months. He has also taken his show abroad.
https://www.nytimes.com/2023/06/07/technology/sam-altman-ai-regulations.html
A Week With the Wild Children of the A.I. Boom
https://www.nytimes.com/2023/05/31/magazine/ai-start-up-accelerator-san-francisco.html
Google has created a Generative AI learning path with 9 FREE courses!
Topics cover:
- Intro to LLMs
- Attention Mechanism
- Image Generation/Captioning
- Intro to Responsible AI
From the fundamentals of LLMs to creating & deploying generative AI solutions!
Read more
Introduction to Generative AI:
An introductory level micro-learning course aimed at explaining:
- What Generative AI is
- How it is used
- How it differs from traditional ML
Check this out
https://lnkd.in/duKJ3sm6
Introduction to Large Language Models:
The course explores:
- Fundamentals LLMs
- Their use cases
- Prompt engineering on LLMs
Check this out
https://lnkd.in/dm_yS4MQ
Introduction to Responsible AI:
The course explains what responsible AI is, why it's important, and how Google implements responsible AI in their products.
Check this out
https://lnkd.in/dV8zNvwm
Introduction to Image Generation:
This course introduces diffusion models, a family of ML models that recently showed promise in the image generation space.
Check this out
https://lnkd.in/dqcZBZqd
Encoder-Decoder Architecture:
This course gives you a synopsis of the encoder-decoder architecture.
It's a powerful and prevalent machine learning architecture for sequence-to-sequence tasks.
Check this out
https://lnkd.in/dhDhUgwJ
Attention Mechanism:
The course teaches you how attention works & how it revolutionised:
- machine translation
- text summarisation
- question answering
Check this out
https://lnkd.in/dwsZZw6j
Transformer Models and BERT Model:
This course introduces you to some of the most famous and effective transformer architectures!
Check this out
https://lnkd.in/dK4p3n2s
Create Image Captioning Models:
This course teaches you how to create an image captioning model by using deep learning.
Check this out
https://lnkd.in/d8w32x5Y
Introduction to Generative AI Studio:
This course introduces Generative AI Studio, a product on Vertex AI.
It teaches you to prototype and customize generative AI models so you can use their capabilities in your applications.
Check this out
https://lnkd.in/dAXdSrEXQwiklabsIntroduction to Generative AI | Google Cloud Skills BoostThis is an introductory level microlearning course aimed at explaining what Generative AI is, how it is used, and how it differs from traditional machine learning methods. It also covers Google Tools to help you develop your own Gen AI apps.This course is estimated to take approximately 45 minutes to complete.lnkd.inLinkedInThis link will take you to a page that’s not on LinkedInQwiklabsIntroduction to Responsible AI | Google Cloud Skills BoostThis is an introductory-level microlearning course aimed at explaining what responsible AI is, why it's important, and how Google implements responsible AI in their products. It also introduces Google's 7 AI principles.QwiklabsIntroduction to Image Generation | Google Cloud Skills BoostThis course introduces diffusion models, a family of machine learning models that recently showed promise in the image generation space. Diffusion models draw inspiration from physics, specifically thermodynamics. Within the last few years, diffusion models became popular in both research and industry. Diffusion models underpin many state-of-the-art image generation models and tools on Google Cloud. This course introduces you to the theory behind diffusion models and how to train and deploy them on Vertex AI.QwiklabsEncoder-Decoder Architecture | Google Cloud Skills BoostThis course gives you a synopsis of the encoder-decoder architecture, which is a powerful and prevalent machine learning architecture for sequence-to-sequence tasks such as machine translation, text summarization, and question answering. You learn about the main components of the encoder-decoder architecture and how to train and serve these models. In the corresponding lab walkthrough, you’ll code in TensorFlow a simple implementation of the encoder-decoder architecture for poetry generation from the beginning.
Audiocraft / MusicGen - AMAZING Text-To-Music AI Model By Facebook | Tutorial | Better Than MusicLM
https://www.youtube.com/watch?v=v-YpvPkhdO4
AlphaDev, an AI system using reinforcement learning to discover enhanced computer science algorithms.
https://twitter.com/DeepMind/status/1666462540367372291
What Happens When AI Enters the Concert Hall?
https://www.nytimes.com/2023/06/10/arts/music/ai-classical-music.html
From Thought to Text: AI Converts Silent Speech into Written Words - Neuroscience News
https://neurosciencenews.com/thoight-text-ai-decoder-23437/
0 notes
Text
Week 13 - Class Notes May 31- June 6 - To Fly

TO FLY - GET READY FOR IT! - Waiting on Copernicus
https://www.youtube.com/watch?v=3n71KUiWn1I
Group 2
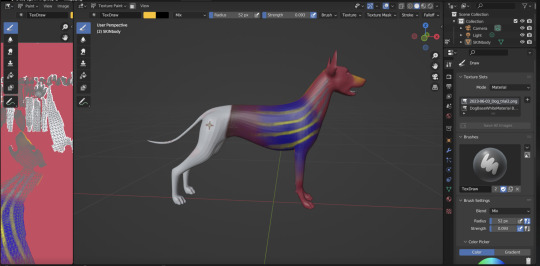
Woof Woof
A Comparison of PPO, TD3 and SAC Reinforcement Algorithms for Quadruped Walking Gait Generation
https://www.scirp.org/journal/paperinformation.aspx?paperid=123401
Group 3
Wonk Proof of Concept
https://www.youtube.com/watch?v=koz6cJuZOAc
Brainwave Control Device by Edmond Dewan
https://www.youtube.com/watch?v=nCGcY6sQjcM

Wiktor’s Shenzhen board arrives in the mail - Hooray!
Class Readings
Artists and Illustrators Are Suing Three A.I. Art Generators for Scraping and 'Collaging' Their Work Without Consent | Artnet News
https://news.artnet.com/art-world/class-action-lawsuit-ai-generators-deviantart-midjourney-stable-diffusion-2246770
Opinion | The Alt-Right Manipulated My Comic. Then A.I. Claimed It.
https://www.nytimes.com/2022/12/31/opinion/sarah-andersen-how-algorithim-took-my-work.html
Stable Diffusion Frivolous · Because frivolous lawsuits based on ignorance deserve a response.
http://www.stablediffusionfrivolous.com
Getty Images is suing the creators of AI art tool Stable Diffusion for scraping its content
https://www.theverge.com/2023/1/17/23558516/ai-art-copyright-stable-diffusion-getty-images-lawsuit
ChatGPT boss wants HQ in Europe (Charm Offensive)
https://www.politico.eu/article/open-ai-chatgpt-sam-altman-kicks-off-eu-charm-offensive-artifical-intelligence/
ChatGPT took their jobs. Now they walk dogs and fix air conditioners.
https://www.washingtonpost.com/technology/2023/06/02/ai-taking-jobs/
Expressions Camera
https://xpressioncamera.com
The world’s first AI ballet has arrived, and it's setting the bar high
https://www.wallpaper.com/art/fusion-ai-ballet-leipzig-opera-house
Andy Warhol paints Debbie Harry on an Amiga - 1985
https://www.youtube.com/watch?v=wLvTG5hwa1A&t=101s
Is A.I. Coming for the Drag Queens Next? A Deep Fake Cabaret at the V&A Exposes the Tech's Limitations | Artnet News
https://news.artnet.com/art-world/is-a-i-coming-for-the-drag-queens-next-a-deep-fake-cabaret-at-the-va-exposes-the-techs-limitations-2308709?utm_content=from_artnetnews&utm_source=Sailthru&utm_medium=email&utm_campaign=6/5%20US%20AM&utm_term=US%20Daily%20Newsletter%20%5BMORNING%5D
AI Now Institute - 2023 Landscape
https://ainowinstitute.org/2023-landscape
0 notes
Text
Week 12 - Class Notes May 24-30

Group 3
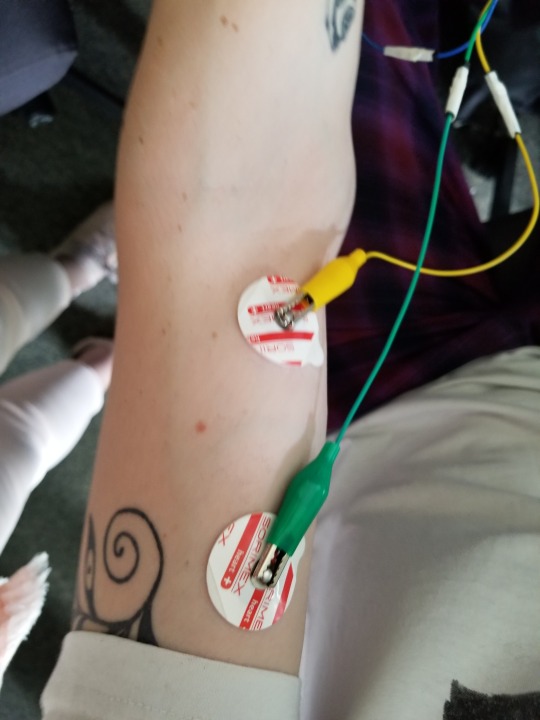
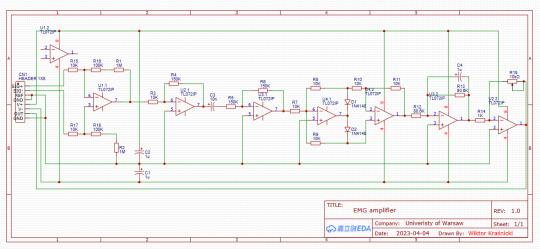
Design of EMG board 1 by Wiktor
https://www.youtube.com/shorts/_wLxJQ7aBgE



Mentalista
https://mentalista.com
Class Readings
Open AI Photoshopping About To Get Too Easy
https://www.nytimes.com/2023/05/23/opinion/photoshop-ai-images.html
Man With Paralysis Walks Naturally After Brain Spine Inplants
https://edition.cnn.com/2023/05/24/health/walk-after-paralysis-with-implant-scn/index.html
US Judge Side With Yuga Labs In Bored Ape NFT Trademark Lawsuit
https://www.reuters.com/legal/litigation/us-judge-sides-with-yuga-labs-bored-ape-nft-trademark-lawsuit-2023-04-24/
Bored Ape Creators Score Legal Victory In Lawsuit Against Artists Who Made Copycat NFT Collection
https://www.theartnewspaper.com/2023/04/26/bored-ape-yacht-club-nfts-lawsuit-ryder-ripps-partial-victory
Celebrities that promote Bored Ape NFTs are now facing a class action lawsuit - The list of defendants might as well be a Coachella lineup with names like Diplo, Snoop Dogg, Post Malone, and The Weeknd cited alongside Yuga Labs Inc as well as Justin Bieber, Paris Hilton, Madonna, Jimmy Fallon, and Kevin Hart
https://www.theverge.com/2022/12/13/23507575/bored-ape-yacht-club-yuga-labs-nft-cryptocurrency-lawsuit
Microsoft Calls For AI Rules To Minimize the Technology’s Risks
https://www.nytimes.com/2023/05/25/technology/microsoft-ai-rules-regulation.html
Grimes clones her voice - anyone can make a song with it - https://elf.tech/connect
Martian Love - Where You Want - AI Movie
https://www.youtube.com/watch?v=hQG9ZAdjsPI
Lorn Music Video
https://www.youtube.com/watch?v=3ApMSKql23I
AI Based Copycats
https://www.youtube.com/watch?v=McM3CfDjGs0
System Aesthetics - We are now in transition from an object-oriented to a systems-oriented culture. Here change emanates, not from things, but from the way things are done.
https://www.artforum.com/print/196807/systems-esthetics-32466artforum.com
What happens when your lawyer uses Chat GPT-3 - It did not go well
https://www.nytimes.com/2023/05/27/nyregion/avianca-airline-lawsuit-chatgpt.html
YouTube Science Scam
https://www.youtube.com/watch?v=McM3CfDjGs0
Statement On AI Risk
https://www.safe.ai/statement-on-ai-risk#open-letter
"AIBO—An Emotionally Intelligent Artificial Intelligence Brainwave Opera—Or I Built A "Sicko" AI, and So Can You" in Information Disorder - Algorithms and Society published by Routledge Books - https://www.routledge.com/Information-Disorder-Algorithms-and-Society/Filimowicz/p/book/9781032290775
World’s First AI Generated Statue
https://news.artnet.com/art-world/impossible-statue-ai-generated-stockholm-museum-23[…]ay%20AM%20US&utm_term=US%20Daily%20Newsletter%20%5BMORNING%5D
0 notes
Text
Week 11 - ISEA Paris Week May 17-23

Photo by Alain Thibault
Group 1
MMS: Massively Multilingual Speech.
- Can do speech2text and text speech in 1100 languages.
- Can recognize 4000 spoken languages.
- Code and models available under the CC-BY-NC 4.0 license.
- half the word error rate of Whisper.
Github
https://github.com/facebookresearch/fairseq/tree/main/examples/mms
Paper
https://scontent-lga3-2.xx.fbcdn.net/v/t39.8562-6/348836647_265923086001014_687800580827579[…]GkLV3haLgAXkFFhYmxMG8D9J2WV1hKDqYAQNPW4-4g&oe=6471ACCF
Blog
https://ai.facebook.com/blog/multilingual-model-speech-recognition/?utm_source=twitter&utm_medium=organic_social&utm_campaign=blog&utm_content=cardMeta AI
Group 2
Using .skn skin file as model texture · Issue #128 · deepmind/mujoco
https://github.com/deepmind/mujoco/issues/128
Infusion Systems
https://infusionsystems.com/catalog/product_info.php/products_id/693
SAC Algorithm
https://github.com/rail-berkeley/rlkit/blob/master/examples/sac.py
TDMPC
https://github.com/nicklashansen/tdmpc
Temporal Differences
https://www.youtube.com/watch?v=s-y_110sTTA
Group 3
Facial EMG and Reactions
https://onlinelibrary.wiley.com/doi/epdf/10.1111/j.1469-8986.1990.tb01962.x
Wiki
https://en.wikipedia.org/wiki/Facial_electromyography
VR Touch and Emotions
(PDF) Touching Virtual Humans: Haptic Responses Reveal the Emotional Impact of Affective Agents
PDF | Interpersonal touch is critical for social-emotional development and presents a powerful modality for communicating emotions.
Stability AI Released Stability Studio
https://stability.ai/blog/stablestudio-open-source-community-driven-future-dreamstudio-release
OSC Into Touch Designer
https://infusionsystems.com/catalog/info_pages.php?pages_id=181
Synaptogenesis
https://www.youtube.com/watch?v=1fnm1vGGRYI&t=12s
Class Notes
Open AI’s Sam Altman urges AI Regulation
https://www.nytimes.com/2023/05/16/technology/openai-altman-artificial-intelligence-regulation.html
Supreme Court Rules Against Andy Warhol in Prince Case
https://www.nytimes.com/2023/05/18/us/supreme-court-warhol-copyright.html
https://hyperallergic.com/822888/supreme-court-rules-against-andy-warhol-foundation-in-lynn-goldsmith-copyright-case/
German Artist Michael Moebius Wins $120 Million in a 'Monumental' Lawsuit Against Hundreds of Foreign Counterfeiters | Artnet News
https://news.artnet.com/art-world/artist-michael-moebius-wins-monumental-copyright-l[…]0PM&utm_term=Daily%20Newsletter%20%5BALL%5D%20%5BAFTERNOON%5D
Inferno
https://www.youtube.com/watch?v=sGIbZ5DD4fY
Meta slapped with record $1.3 billion EU fine over data privacy
https://edition.cnn.com/2023/05/22/tech/meta-facebook-data-privacy-eu-fine/index.html
Ellen Waving From ISEA 2023 Paris
https://www.youtube.com/shorts/S9nxI7XTHhI
0 notes
Text
Week 10 -Class Notes May 10-May 15

Exhibition Proposal Draft
0 notes
Text
Week 9 MidTerm Break - Moving Forward April 27 - May 9
youtube
Class Readings
Humane AI Wearable Camera
https://www.inverse.com/tech/humane-ai-wearable-camera-sensor-projector-video-demo
Ashton Kutcher’s AI Investment Firm
https://variety.com/2023/digital/news/ashton-kutcher-guy-oseary-sound-ventures-ai-investment-fund-1235599939/
Anthropic - An AI safety and research company that's working to build reliable, interpretable, and steerable AI systems.
https://www.anthropic.com/
How Do We Ensure AI Is For Humans?
https://www.nytimes.com/interactive/2023/05/02/magazine/ai-gary-marcus.html
There Is No AI - Jaron Lanier
https://www.newyorker.com/science/annals-of-artificial-intelligence/there-is-no-ai
Geoff Hinton on AI
https://www.youtube.com/watch?v=N0ER1MC9cqM
My Weekend With An Emotional Support AI
https://www.nytimes.com/2023/05/03/technology/personaltech/ai-chatbot-pi-emotional-support.html
Stability AI Releases Deep Floyd Text To Image Model
https://stability.ai/blog/deepfloyd-if-text-to-image-model
Is Crafting ‘Super Prompts’ for A.I. Generators the Art of the Future? Probably Not
https://news.artnet.com/opinion/ai-prompt-engineer-2288620?utm_content=from_artnetne[…]28%20US%20AM&utm_term=US%20Daily%20Newsletter%20%5BMORNING%5D
Free GPT-4 Chatbot - Ora - Create your own chatbot with just a description and a click
ora.ai
Janusz Janowski nowym dyrektorem Zachęty. Historia tej nominacji pokazuje zasadniczy błąd konserwatystów wobec sztuki współczesnej
https://klubjagiellonski.pl/2022/01/22/janusz-janowski-nowym-dyrektorem-zachety-histor[…]e-zasadniczy-blad-konserwatystow-wobec-sztuki-wspolczesnej/
Chinese police detain man for allegedly using ChatGPT to spread rumors online | CNN Business
RIP Metaverse, we hardly knew ye
https://edition.cnn.com/2023/05/09/tech/china-arrest-chatgpt-hnk-intl/index.html
Art-A-Hack Metaverse project in 2016 (way before Meta) https://artahack.io/projects/metaverse-art-gallery/
Art-A-Hack 2016 - Metaverse Art Gallery
https://www.youtube.com/watch?v=KyNQ89wivbc
HOW I FAKED MY LIFE USING AI: or (THE LIFE AND DEATH OF RYAN GOSLING PERSON)
https://www.youtube.com/watch?v=FRClNMC_z-s
https://www.businessinsider.com/metaverse-dead-obituary-facebook-mark-zuckerberg-tech-fad-ai-chatgpt-2023-5?IR=T
Group 2
MuJoCo stands for Multi-Joint dynamics with Contact.
https://mujoco.org/
Multi-Joint dynamics with Contact. A general purpose physics simulator. - mujoco/LICENSE at main ·
deepmind/mujoco
GitHub - deepmind/mujoco: Multi-Joint dynamics with Contact. A general purpose physics simulator.
GitHub
https://github.com/deepmind/dm_control
Shap-E - A conditional generative model for 3D assets
https://github.com/openai/shap-e
https://arxiv.org/abs/2305.02463
Group 3
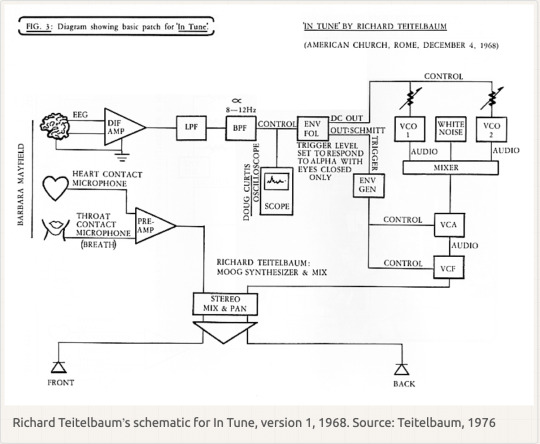
Richard Teitlebaum biometrics 1968
Nina Sobell interviewed by Renata Janiszewska
https://techspressionism.com/video/interview/sobell/
World’s largest grammar database reveals accelerating loss of language diversity
https://www.colorado.edu/today/2023/04/19/worlds-largest-grammar-database-reveals-accelerating-loss-language-diversity
New open-source hardware thrusts brain-signal processing into a maker’s world
https://spectrum.ieee.org/neurotechnology-diy
Emotibit News
https://mailchi.mp/fb992b5417d5/emotibit-update-get-beta-access-5396656?e=2df651d2da
DeFlickering
https://chenyanglei.github.io/deflicker/
Cemetery Project
https://radom.wyborcza.pl/radom/7,48201,29725481,miedzynarodowy-projekt-badawczy-na-cmentarzu-zydowskim-w-przysusze.html
How To Install Automatic 111 On A Mac
https://www.youtube.com/watch?v=DUqsYm_rYcA
0 notes
Text
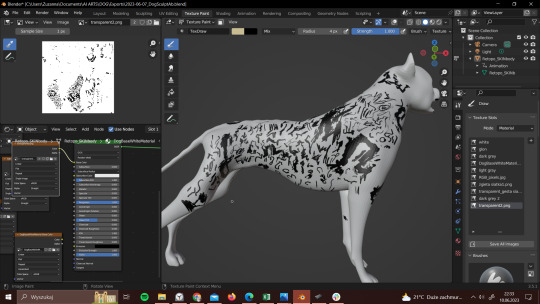
Group 2 Weeks 5 - 8
Progress with implementing learning with the 3D model in a physical environment has been slow, but steady. Initilly we were experiencing issues with the 3D model imported from Maya into Unity, but were able to get it working with Unity's physics engine as you can see here:
With this 3D model we were able to get the character moving from place to place using manually assigned ranges of motion for each joint:
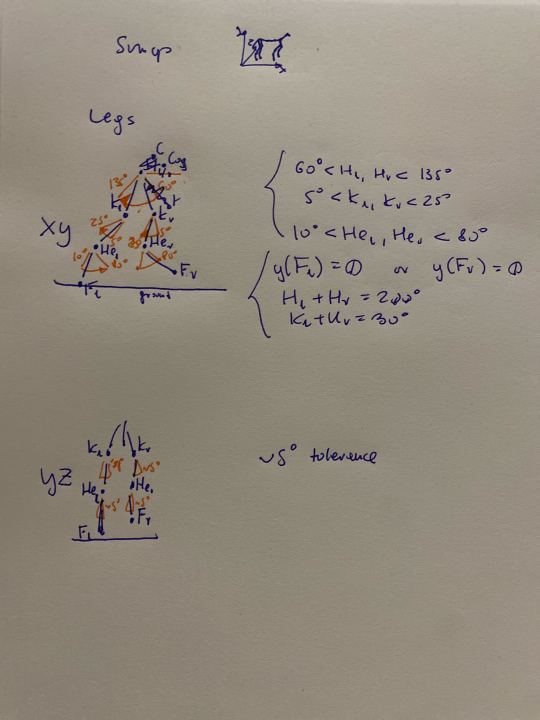

But were having some issues with the 3D model not holding it's form together in the way we hoped it would.
In order to remedy these issues of the 3D model not working expected, we have opted to rebuild it in Unity, where it should work in a more predictable way:
On the visualization side, we are developing hand-drawn animations that we hope will play over the surface of the character model, stills of which you can find here:
This approach my need to change now that the model is built within Unity and may be harder to extract back out of it for the purposes of rendering.
We are also beginning to consider the environment that the wolf will have to traverse. We have acquired the heightmap of a 1 km square around Węgrów, which we have converted into geometry which can act as the base surface for the wolf to walk on:


In the physical world, the wolf's rig has become a part of the bell that will be in the installation and later public monument in Węgrów, as a sort of zoetrope going along the top of a bell made by the Kruszewscy Bell Company in Węgrów, the same company that has mae and maintains all of the church bells in Węgrów. Here is an image of the bell after just coming out of casting in brass, before polishing and weatherproofing:

0 notes
Text
Week 8 - You So Done

You So Done - Noga Erez
https://www.youtube.com/watch?v=Xn813NKlhzI
Readings April 19 - April 25
Group 3
3D Brainwave Sculptures
https://artahack.io/projects/deep-thought/
Measuring The Magic of the Mutual Gaze
https://www.youtube.com/watch?v=Ut9oPo8sLJw
Ultra Sharp Upscale
https://www.youtube.com/watch?v=A6dQPMy_tHY
Flicker Free Animations
https://www.youtube.com/watch?v=Qph7A3UaVds
Kandinsky 2.1 open source image generator
https://www.youtube.com/watch?v=dYt9xJ7dnpU
https://github.com/ai-forever/Kandinsky-2
Kandinsky 2.1 inherits best practicies from Dall-E 2 and Latent diffusion, while introducing some new ideas.
As text and image encoder it uses CLIP model and diffusion image prior (mapping) between latent spaces of CLIP modalities. This approach increases the visual performance of the model and unveils new horizons in blending images and text-guided image manipulation.
For diffusion mapping of latent spaces we use transformer with num_layers=20, num_heads=32 and hidden_size=2048.
Other architecture parts:
Text encoder (XLM-Roberta-Large-Vit-L-14) - 560M
Diffusion Image Prior — 1B
CLIP image encoder (ViT-L/14) - 427M
Latent Diffusion U-Net - 1.22B
MoVQ encoder/decoder - 67M
Kandinsky 2.1 was trained on a large-scale image-text dataset LAION HighRes and fine-tuned on our internal datasets.
Deforum Art Text 2 Video
https://github.com/deforum-art/sd-webui-text2video
Deforum Art For Automatic 1111 Web UI
https://github.com/deforum-art/deforum-for-automatic1111-webui
Trailer - All This Can Happen
https://www.youtube.com/watch?v=KMOPMRJiNSQ
General Links
AI, Drake, The Weeknd Fake
https://www.nytimes.com/2023/04/19/arts/music/ai-drake-the-weeknd-fake.html
Sarcastic Robot Powered By GPT-4
https://www.youtube.com/watch?v=PgT8tPChbqc
0 notes
Text
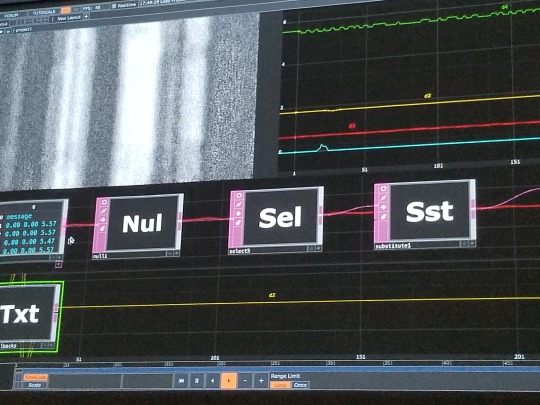
Group 3, Week 8 - EMG Sound
youtube
No sound in the video but instead an illustration of how muscle motion would become sound through captured data.
0 notes
Text
Group 1 - video sample 2
We lose colour, we are voiceless, and AI speaks for us
0 notes
Text
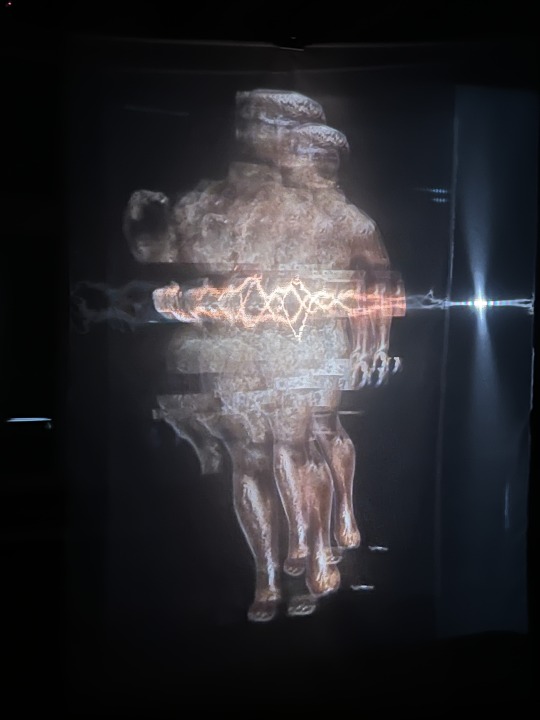
Group 1 Week 8 - morphing projection
The voice generated by the AI can be heard:
"The risk of losing our culture ... "
0 notes
Text
Group 3 Week 8 - Test framing
youtube
Need to work out language subtitles, frame rate, flickering, timing, layout. Rendered in H624.
0 notes