#productivity vs. pay
Text

#us politics#memes#shitpost#economics#economy#workers#working class#worker's rights#worker's union#wage gap#wages#raise the minimum wage#living wage#productivity vs. pay#productivity#40 hour work week#republicans be like#conservatives be like#libertarians be like
2K notes
·
View notes
Text
hmm I’d like to give a word of hope to the watcher fandom atm: I’m a dropout subscriber and the shows there have been doing super well and becoming more and more entertaining ever since they pivoted to focusing on the streamer in 2020, and it seems like the watcher gang is following that business model pretty closely. So while paywalls do suck, giving creatives more freedom and less reliance on ads demonstrably improves the things they create
#watcher#dropout#look I get it paying for shit that used to be free sucks#and it’s true that dropout concentrated more on making platform-native content for their streamer to incentivize people to pay#rather than moving new seasons of old shows onto their streamer#but I still think it could pan out well!#that being said I think dropout did this a little smarter with having a flagship show and emphasis on improv vs scripted for#ease of production#also if I get the date wrong I’m sorry I only started being a fan of dropout in 2022 subscriber in 2023
8 notes
·
View notes
Note
hiii I'm someone who cries about stage posse at least once a month so!!! Some other fun stage posse things...
I love love love Sakata so much...!!! For me he is *the* Gentaro, like you said he did enforce more of his weird girl side and that made me so happy, and talking about being "so happy" stage posse recreated the whole gero gero gero scene once! Unfortunately this was in a not recorded day, but there is one where when saying thanks to the audience etc Sakata actually went "I'm so sad that is over *fake cries..... just kidding !!!I'm happy happy happy!!!!🐸🐸🐸", after that the audience wouldn't stop laughing so Samalan could start talking and it was pretty funny lol
On the first bop when Gentaro wasn't there, Ramuda made Dice pretend to be Gentaro to say how he was enjoying to show and !! I love when posse imitates each other, this is also the bop where we got projection Gentaro on a big screen exploding
The fp interaction on the championship tournament, they won the first round and Ramuda is thinking he is totally going to die after this and has been hiding from Chuoh, so when Gen & Dice go on the usual "I'm gonna bet the whole prize money- no you will not" thing Ramu interrupts saying he will give his part for Dice, and it's Dice who steps up to say "no. We are going to win, and split it in three equal parts" and this makes me so AAAAAA
Overall posse pda... it's so important to me how close they are, I really hope the next fp becomes the bestest of friends and have a banger chemistry on stage 😭😭
There is probably more but I'm not remembering rn!! Thank you for those stage rambles I hope this makes someome decide to give a try to hypstage, and I guess it's taking my grief out a bit and making me excited to what shanenigans the new era of stage will bring us
i haven’t watched the first bop in foreverrrr omg i remember that giant gentaro projection but how did i forget it exploding lmao????? and stage posse imitating him in his absence god you just unlocked my bop stage memories lmao
and i love that previous fan interactions came back for the final bop like see this why i’m going to pay better attention to our new posse fr i can’t believe i didn’t have the whole context to that scene lmao
#vee got an ask#kiramyssu#lol!!!!!!!!! the championships for both rounds are like the only stage productions i haven’t watched and clearly i’m missing out 😭😭😭😭😭😭#that actually helps give me context to some of posse’s drama missing ig??? from fp vs mtc lol#i’ll remedy that eventually hhhhhhhhhhh and seriously i’m paying better attention to stage posse this time 😭😭😭😭😭😭😭
4 notes
·
View notes
Text
harry styles you will pay for your sins
#this is about me seeing what kind of insane production tswift’s tour has vs what we are getting#for the money we’re paying#sick and tired
8 notes
·
View notes
Text
*taps mic* this thing on?
#r.txt#hi hi hi i miss being active sm i hate school :|#i still need a new computer too cause rn i cant run sims with anything installed it sucks ass#im excited for infants tho!!!! and the new pack im foaming at the mouth why do they make us pay for basic game things its so lame but wtvr!!#im just popping in for a min im on spring break but i still have hw :'((#just a few more months and maybe i can get a job and save enough for a new pc lets hope#im taking a photoshop/illustrator class and i rly hate my prof i havent learned anything i didnt already know#and we have to use MACS :| actually wanna fight its me vs apple products till i di#e#ive been playing vanilla for a bit and its not as fun but its alright#ive uploaded some houses to the gallery if anyone is interested ig i could post those to be semi active#i have literally sm to do in my life i hate being old (19) im basically dead#i say it every time but im going to make my return one day i swear it i love this community despite its many many flaws i miss everything#unfortunatly i have to deal w an 8-5 school schedule twice a week the rise and grind mindset is not for me#if i get time i might try to post more silly updates ive been doing but for now au revoir (adios) (im into tfb now smile)#ok bye aggain 4 nowsies
9 notes
·
View notes
Text
DAMMIT what’s the line between:
‘bad publicity is still publicity’ and posting screenshots abt the tumblr shop tab moving to our blog spots
VS
I don’t want to stay silent on this topic and I know that just one formal complaint won’t do much if we aren’t all angry at the Instagram/Tik-Tok-ification that’s happening rn
#tiktokification as in I’ve been seeing posts abt images not being easy to zoom into anymore??? + the ads take up the ENTIRE screen on mobile#tumblr#tumblr updates#mypost#tumblr shop#ughhhhhhh#enshittification#enshittification of socials or whatever#i want to know why tumblr is doing this but I also don’t#cause I don’t want to hear bs black-and-white arguments about ‘no media should make money ever’ and tumblr is not a small local Etsy gal#or whatever#they have to make money someway#smth smth ‘if ur not paying for the product u are the product’#but I also don’t want to know abt the deets bc that means tumblr has fucked up enough that I’m mad enough to do so and so looking at#the Truth About Marketing for tumblr or whatever is SO ANNOYING#UGHH TUMBLR#idk if any of this is coherent bc I have absolutely horrible short term memory and by the time I’m halfway thru writing a tag I can’t see#what my previous sentences were (I’m on mobile) and so I loose my train of thought lol#anyways I think the gist is: this fucking sucks. people are going to be annoyingly us-vs-them/black-n-white when arguing about this cause#arguing is easier than doing the research and discovering greyer areas#AND: we’ve gotten to the point of rage/un satisfaction with the steps this app is taking that a push towards researched-back arguments may b#the only way forward to have actual change… :|#like again this could end up mostly having been for publicity for the store cause ofc ppl will complain and post screenshots and then more#ppl will see like ‘ooh fun stickers guess I’ll get those!’ and Marketing Tumblr or whatever will know that ‘oh if we disrupt them in these#ways we will get more attention from this fickle consumer base’#idk if we’re even that fickle lol there’s a lot of self-praise on tumblr lately (b4 the shop moving) that probably has swayed marketing#folks to push this thing we don’t like cause they think we’ll get outraged or say it’s better than other sites and either way it’s publicity
9 notes
·
View notes
Text
my workplace doing the same thing my other work did that made me want to leave (aka not wanting to share the wifi password and only keeping it for the higher ups 🖕🏽)
#which gets me so mad bc i know y'all can afford to pay for it#and pay for your own data#vs everyone else that's kinda getting by#it's just so stupid to me#like is this supposed to make us be more productive lol#at my other work it made sense bc it was custody/detention so duh#but this is a reg office job so wtf is their problem#lisa.txt
3 notes
·
View notes
Text
...
#my desire to b productive vs my desire to create horribly earnest narut0 drawings#its just. i have a scene in my head that's like way too complicated to draw. but im gonna draw it anyway#and its gonna haunt me bc the dialogue is clunky. but whatever im gonna do it. this weekend. that is#i said id work on more writing school stuff today but ah i didn't sleep much and i did lots of focusing all day so like#brain is sorta mush now#snd all i can thibk abt is how much i lov 1ruka being narut0s number one dad brother#i just want to create a million scenarios where 1ruka cries over how much of a good kid narut0 is and how much bullshit he has to deal with#i just want someone to feel that pain for him. i mean. i guess thats s4sukes deal. but it feels different coming from a parent#from 1ruka it feels more. i wanna protect u. and from s4suke it feels more. i understand. lets destroy the world together. make them pay#they r the true ultimate narut0 stans. narut0 defense squad. everyone else back the fuck off#k4kashi is a 2nd teir stan. only bc hes got his own weird bullshit in canon. in my head hes also on the narut0 elite defense squad#wtf am i talking abt. ugh i need to sleep. i have to talk to ppl tomorrow. ugh no i should work on stuff#agh. fucj it maybe ill just wake up at like 5am and work on it then. and shift into proper work mode at 9 or whatever#blah. i now understand why i was feeling so like normal before this. its bc i was well rested lmao. im not at familiar levels of#exhausted unstabled energy. lov that for me#unrelated
16 notes
·
View notes
Text
Copy Right and Public Domain in 2024
Happy 2024 all! its also Public Domain Day! a magical holiday here in America where things enter the public domain. Works published in the year 1928 (or 95 years ago!) have entered the public domain, which means they belong to us, all of us, the public!
Mickey's Back!
Yes! I'm sure you've heard, but Mickey Mouse (and Minnie Mouse too) is entering the Public Domain today. This has been news for a few years and indeed Disney's lobbying in the late 1990s is why our copy right term is SO long. So what exactly is now public domain?


Most people know about Mickey's first appearance Steamboat Willie, but a second short film, Plane Crazy was also released in 1928 so will also be public domain. So what's public? well these two films first of all, you're allowed to play them, upload them to YouTube or whatever without paying Disney. In theory you'll be allowed to cut and sample them, have them playing in the background of your movie etc. Likewise in theory the image of Mickey and Minnie as they appear (thats important) in these films will be free to use as well as Mickey's character as he appears in these works will be free to use. Now Mickey's later and more famous appearance

will still be protected. Famously the Conan Doyle Estate claimed that Sherlock Holmes couldn't be nice, smile, or not hate women in works because they still held the copyright on the short stories where he first did those things even though 90% of Sherlock Holmes stories were public domain. It's very likely Disney will assert similar claims over Mickey, claiming much of his personality first appeared in works still copyrighted.
Finally there's copyright vs trademark. Copyright is total ownership of a piece of media and all the ideas that appear in it, copyright has a limited set term and expires. Trademark is more limited and only applies to things used to market and sell a product. You can have a Coke branded vending machine in your movie if you want, but it couldn't appear anywhere in the trailer for your movie as thats you marketing your movie.
Where trademark ends and copyright begins and how trademarked something in the public domain is allowed to be are all unsettled areas of law and clearly Disney in the last few years as been aggressively pushing its trademark not just to Mickey in general but Steamboat Willie Mickey in particular

Ultimately the legal rights and wrongs of this might not matter so much since few people have the money and legal resources of the Walt Disney corporation so they might manage to maintain a de facto copyright on Mickey through legal intimidation, but maybe not?
And Tigger Too!
All the talk about Mickey Mouse and Steamboat Willie has sadly overshadowed other MAJOR things entering the public domain today. Most people are aware Winnie the Pooh entered the public domain in 2022, but they might not realize his beloved friend Tigger didn't. Thats because Tigger didn't appear till A. A. Milne's second (and last) book of Pooh short stories, The House at Pooh Corner in 1928.

Much like Mickey Mouse only what appears in The House at Pooh Corner is public domain so the orange bouncy boy from the 1960s Disney cartoon is still on lock down. But the A. A. Milne original as illustrated by E. H. Shepard is free for you to use in fiction or art. His friend Winnie the Pooh has made a number of appearances since being freed, most notably in a horror movie, but also a Mint Mobile commercial so maybe Tigger too will have a lot of luck in the public domain.
Other works:
Peter Pan; or the Boy Who Wouldn't Grow Up
Peter Pan is a strange case, even though the play was first mounted in 1904, and the novelization (Peter and Wendy) was published in 1911, The script for the play was not published till 1928 (confusing!) meaning while the novel as been public domain for years the play (which came first) hasn't been, but now it is and people are welcome to mount productions of it.
Millions of Cats

The oldest picture book still in print, did you own a copy growing up? (I did)
Lady Chatterley's Lover
The iconic porn novel that was at the center of a number of groundbreaking obscenity cases in the 1960s and helped establish your right to free speech.
All Quiet on the Western Front and The Threepenny Opera in their original German (but you can translate them if you want), The Mystery of the Blue Train by Agatha Christie, and Orlando by Virginia Woolf will also be joining us in the public domain along with any and all plays, novels, and books published in 1928
for Films we have The Man Who Laughs who's iconic image inspired the Joker

Charlie Chaplin's The Circus, Buster Keaton's The Cameraman, Should Married Men Go Home? the first Laurel and Hardy movie, Lights of New York the first "all talking" movie, The Passion of Joan of Arc, The Wind, as well as The Last Command and Street Angel the first films to win Oscars for Best Actor and Best Actress respectively will all be entering public domain
For Musical Compositions (more on that in a moment) we've got
Mack the Knife by Bertolt Brecht, Let’s Do It (Let’s Fall in Love) by Cole Porter, Sonny Boy by George Gard DeSylva, Lew Brown & Ray Henderson, Empty Bed Blues by J. C. Johnson, and Makin’ Whoopee! by Gus Khan are some of the notables but any piece of music published in 1928 is covered
Any art work published in 1928, which might include works by Frida Kahlo, Georgia O'Keeffe, Alexej von Jawlensky, Edward Hopper, and André Kertész will enter the public domain, we are sure those that M. C. Escher's Tower of Babel will be in the public domain

Swan Song, Public Domain and recorded music
While most things are covered by the Copyright Act of 1976 as amended by the Digital Millennium Copyright Act, none of the copyright acts covered recordings you see when American copyright law was first written recordings did not exist and so through its many amendings no one fixed this problem, movies were treated like plays and artwork, but recorded sound wasn't covered by any federal law. So all sound recordings from before 1972 were governed by a confusing mess of state level laws making it basically impossible to say what was public and what was under copyright. In 2017 Congress managed to do something right and passed the Music Modernization Act. Under the act all recordings from 1922 and before would enter the public domain in 2022. After taking a break for 2023, all sound recordings made in 1923 have entered the public domain today on January 1st 2024, these include.
Charleston by James P. Johnson
Yes! We Have No Bananas (recorded by a lot artists that year)
Who’s Sorry Now by Lewis James
Down Hearted Blues by Bessie Smith
Lawdy, Lawdy Blues by Ida Cox
Southern Blues and Moonshine Blues by Ma Rainey
That American Boy of Mine and Parade of the Wooden Soldiers by Paul Whiteman and his Orchestra
Dipper Mouth Blues and Froggie More by King Oliver’s Creole Jazz Band, featuring Louis Armstrong
Bambalina by Ray Miller Orchestra
Swingin’ Down the Lane by Isham Jones Orchestra
Enjoy your public domain works!
#Copyright#public domain#public domain day#2024#happy new year#Disney#mickey mouse#minnie mouse#Tigger#Winnie the Pooh#Peter Pan#Charlie Chaplin#buster keaton#cole porter#louis armstrong#M. C. Escher
10K notes
·
View notes
Text

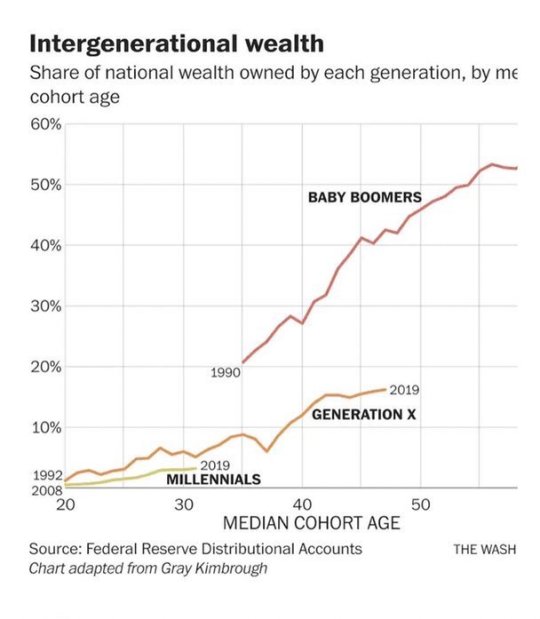



#us politics#republicans#conservatives#gop#congressional salaries#minimum wage#wages#raise the minimum wage#wage gap#intergenerational wealth#tax rate#hourly wages#capital gains#capital gains tax#income#productivity vs. pay#productivity#economic policy institute#Piketty/Saez data#NBER#Federal Reserve Distributional Accounts#graphs#statistics
544 notes
·
View notes
Text
What kind of bubble is AI?
My latest column for Locus Magazine is "What Kind of Bubble is AI?" All economic bubbles are hugely destructive, but some of them leave behind wreckage that can be salvaged for useful purposes, while others leave nothing behind but ashes:
https://locusmag.com/2023/12/commentary-cory-doctorow-what-kind-of-bubble-is-ai/
Think about some 21st century bubbles. The dotcom bubble was a terrible tragedy, one that drained the coffers of pension funds and other institutional investors and wiped out retail investors who were gulled by Superbowl Ads. But there was a lot left behind after the dotcoms were wiped out: cheap servers, office furniture and space, but far more importantly, a generation of young people who'd been trained as web makers, leaving nontechnical degree programs to learn HTML, perl and python. This created a whole cohort of technologists from non-technical backgrounds, a first in technological history. Many of these people became the vanguard of a more inclusive and humane tech development movement, and they were able to make interesting and useful services and products in an environment where raw materials – compute, bandwidth, space and talent – were available at firesale prices.
Contrast this with the crypto bubble. It, too, destroyed the fortunes of institutional and individual investors through fraud and Superbowl Ads. It, too, lured in nontechnical people to learn esoteric disciplines at investor expense. But apart from a smattering of Rust programmers, the main residue of crypto is bad digital art and worse Austrian economics.
Or think of Worldcom vs Enron. Both bubbles were built on pure fraud, but Enron's fraud left nothing behind but a string of suspicious deaths. By contrast, Worldcom's fraud was a Big Store con that required laying a ton of fiber that is still in the ground to this day, and is being bought and used at pennies on the dollar.
AI is definitely a bubble. As I write in the column, if you fly into SFO and rent a car and drive north to San Francisco or south to Silicon Valley, every single billboard is advertising an "AI" startup, many of which are not even using anything that can be remotely characterized as AI. That's amazing, considering what a meaningless buzzword AI already is.
So which kind of bubble is AI? When it pops, will something useful be left behind, or will it go away altogether? To be sure, there's a legion of technologists who are learning Tensorflow and Pytorch. These nominally open source tools are bound, respectively, to Google and Facebook's AI environments:
https://pluralistic.net/2023/08/18/openwashing/#you-keep-using-that-word-i-do-not-think-it-means-what-you-think-it-means
But if those environments go away, those programming skills become a lot less useful. Live, large-scale Big Tech AI projects are shockingly expensive to run. Some of their costs are fixed – collecting, labeling and processing training data – but the running costs for each query are prodigious. There's a massive primary energy bill for the servers, a nearly as large energy bill for the chillers, and a titanic wage bill for the specialized technical staff involved.
Once investor subsidies dry up, will the real-world, non-hyperbolic applications for AI be enough to cover these running costs? AI applications can be plotted on a 2X2 grid whose axes are "value" (how much customers will pay for them) and "risk tolerance" (how perfect the product needs to be).
Charging teenaged D&D players $10 month for an image generator that creates epic illustrations of their characters fighting monsters is low value and very risk tolerant (teenagers aren't overly worried about six-fingered swordspeople with three pupils in each eye). Charging scammy spamfarms $500/month for a text generator that spits out dull, search-algorithm-pleasing narratives to appear over recipes is likewise low-value and highly risk tolerant (your customer doesn't care if the text is nonsense). Charging visually impaired people $100 month for an app that plays a text-to-speech description of anything they point their cameras at is low-value and moderately risk tolerant ("that's your blue shirt" when it's green is not a big deal, while "the street is safe to cross" when it's not is a much bigger one).
Morganstanley doesn't talk about the trillions the AI industry will be worth some day because of these applications. These are just spinoffs from the main event, a collection of extremely high-value applications. Think of self-driving cars or radiology bots that analyze chest x-rays and characterize masses as cancerous or noncancerous.
These are high value – but only if they are also risk-tolerant. The pitch for self-driving cars is "fire most drivers and replace them with 'humans in the loop' who intervene at critical junctures." That's the risk-tolerant version of self-driving cars, and it's a failure. More than $100b has been incinerated chasing self-driving cars, and cars are nowhere near driving themselves:
https://pluralistic.net/2022/10/09/herbies-revenge/#100-billion-here-100-billion-there-pretty-soon-youre-talking-real-money
Quite the reverse, in fact. Cruise was just forced to quit the field after one of their cars maimed a woman – a pedestrian who had not opted into being part of a high-risk AI experiment – and dragged her body 20 feet through the streets of San Francisco. Afterwards, it emerged that Cruise had replaced the single low-waged driver who would normally be paid to operate a taxi with 1.5 high-waged skilled technicians who remotely oversaw each of its vehicles:
https://www.nytimes.com/2023/11/03/technology/cruise-general-motors-self-driving-cars.html
The self-driving pitch isn't that your car will correct your own human errors (like an alarm that sounds when you activate your turn signal while someone is in your blind-spot). Self-driving isn't about using automation to augment human skill – it's about replacing humans. There's no business case for spending hundreds of billions on better safety systems for cars (there's a human case for it, though!). The only way the price-tag justifies itself is if paid drivers can be fired and replaced with software that costs less than their wages.
What about radiologists? Radiologists certainly make mistakes from time to time, and if there's a computer vision system that makes different mistakes than the sort that humans make, they could be a cheap way of generating second opinions that trigger re-examination by a human radiologist. But no AI investor thinks their return will come from selling hospitals that reduce the number of X-rays each radiologist processes every day, as a second-opinion-generating system would. Rather, the value of AI radiologists comes from firing most of your human radiologists and replacing them with software whose judgments are cursorily double-checked by a human whose "automation blindness" will turn them into an OK-button-mashing automaton:
https://pluralistic.net/2023/08/23/automation-blindness/#humans-in-the-loop
The profit-generating pitch for high-value AI applications lies in creating "reverse centaurs": humans who serve as appendages for automation that operates at a speed and scale that is unrelated to the capacity or needs of the worker:
https://pluralistic.net/2022/04/17/revenge-of-the-chickenized-reverse-centaurs/
But unless these high-value applications are intrinsically risk-tolerant, they are poor candidates for automation. Cruise was able to nonconsensually enlist the population of San Francisco in an experimental murderbot development program thanks to the vast sums of money sloshing around the industry. Some of this money funds the inevitabilist narrative that self-driving cars are coming, it's only a matter of when, not if, and so SF had better get in the autonomous vehicle or get run over by the forces of history.
Once the bubble pops (all bubbles pop), AI applications will have to rise or fall on their actual merits, not their promise. The odds are stacked against the long-term survival of high-value, risk-intolerant AI applications.
The problem for AI is that while there are a lot of risk-tolerant applications, they're almost all low-value; while nearly all the high-value applications are risk-intolerant. Once AI has to be profitable – once investors withdraw their subsidies from money-losing ventures – the risk-tolerant applications need to be sufficient to run those tremendously expensive servers in those brutally expensive data-centers tended by exceptionally expensive technical workers.
If they aren't, then the business case for running those servers goes away, and so do the servers – and so do all those risk-tolerant, low-value applications. It doesn't matter if helping blind people make sense of their surroundings is socially beneficial. It doesn't matter if teenaged gamers love their epic character art. It doesn't even matter how horny scammers are for generating AI nonsense SEO websites:
https://twitter.com/jakezward/status/1728032634037567509
These applications are all riding on the coattails of the big AI models that are being built and operated at a loss in order to be profitable. If they remain unprofitable long enough, the private sector will no longer pay to operate them.
Now, there are smaller models, models that stand alone and run on commodity hardware. These would persist even after the AI bubble bursts, because most of their costs are setup costs that have already been borne by the well-funded companies who created them. These models are limited, of course, though the communities that have formed around them have pushed those limits in surprising ways, far beyond their original manufacturers' beliefs about their capacity. These communities will continue to push those limits for as long as they find the models useful.
These standalone, "toy" models are derived from the big models, though. When the AI bubble bursts and the private sector no longer subsidizes mass-scale model creation, it will cease to spin out more sophisticated models that run on commodity hardware (it's possible that Federated learning and other techniques for spreading out the work of making large-scale models will fill the gap).
So what kind of bubble is the AI bubble? What will we salvage from its wreckage? Perhaps the communities who've invested in becoming experts in Pytorch and Tensorflow will wrestle them away from their corporate masters and make them generally useful. Certainly, a lot of people will have gained skills in applying statistical techniques.
But there will also be a lot of unsalvageable wreckage. As big AI models get integrated into the processes of the productive economy, AI becomes a source of systemic risk. The only thing worse than having an automated process that is rendered dangerous or erratic based on AI integration is to have that process fail entirely because the AI suddenly disappeared, a collapse that is too precipitous for former AI customers to engineer a soft landing for their systems.
This is a blind spot in our policymakers debates about AI. The smart policymakers are asking questions about fairness, algorithmic bias, and fraud. The foolish policymakers are ensnared in fantasies about "AI safety," AKA "Will the chatbot become a superintelligence that turns the whole human race into paperclips?"
https://pluralistic.net/2023/11/27/10-types-of-people/#taking-up-a-lot-of-space
But no one is asking, "What will we do if" – when – "the AI bubble pops and most of this stuff disappears overnight?"

If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2023/12/19/bubblenomics/#pop
Image:
Cryteria (modified)
https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0
https://creativecommons.org/licenses/by/3.0/deed.en
--
tom_bullock (modified)
https://www.flickr.com/photos/tombullock/25173469495/
CC BY 2.0
https://creativecommons.org/licenses/by/2.0/
4K notes
·
View notes
Note
what did they do for mexico shows? i don't remember hearing anything to do with merch 😬
if you decide to get anything someday wfttwtaf album hoodie is really nice and imo worth the price since it's not 'that' expensive :)
I have a more detailed explanation here, (Ana added some thoughts since she is Mexican and was at the concert) but pretty much what happened is that they just converted the price in euro to pesos and called it a day, leaving people with these lovely prices. In order is t-shirt, crop hoodie, regular hoodie and poster. Those prices were insane because capitalism sucks, and sure it's not their fault but god that was crazy to see in the day.

And yeah, I've heard good things about Luke's merch and the prices are reasonable, it's why i was considering there for a second kspskapkaa but thank you, I'll keep that in mind.
#third world vs first world economy for yall#i mean Brazil has some laws to regulate merch prices#to stop this particular thing from happening#for instance a harry hoodie in his store is 80 dollars for me making it around 415 reais but in the tour stand it was 160#which is what i would expect to pay for a licensed product here#hopefully the same thing will happen with 5sos#i mean one can hope#but yeah conversion rates suck#i was asked#anon 😌
1 note
·
View note
Text
'Why creatives are seeking residuals' - thread by Stefanie Williams
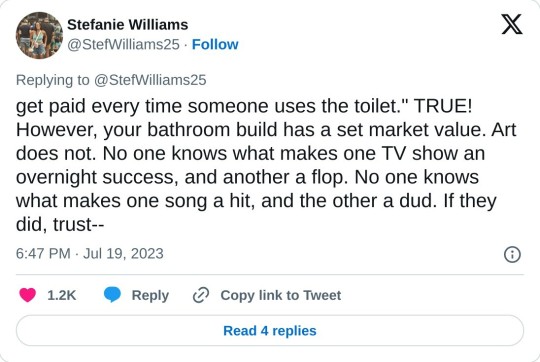
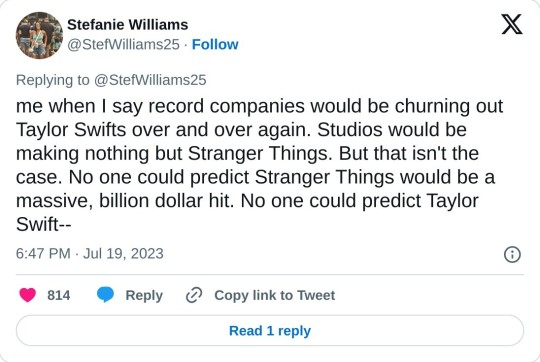


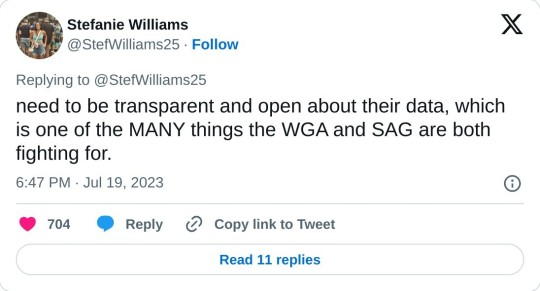
[Tweet thread by Stefanie Williams @/StefWilliams25
TRANSCRIPT:
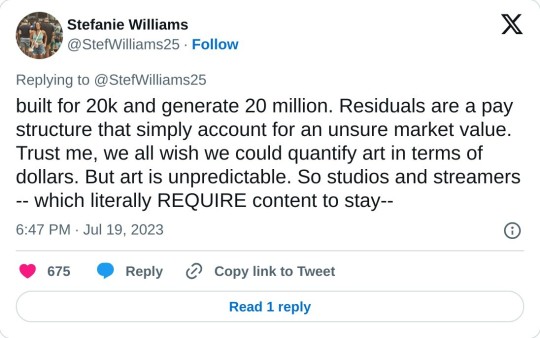
Why creatives are seeking residuals vs. "do you pay the mattress maker every time you sleep on a mattress?" A thread. I keep hearing over and over again that writers/actors/creatives don't deserve residuals for the work they create. "If I build a bathroom in a house, I don't get paid every time someone uses the toilet."
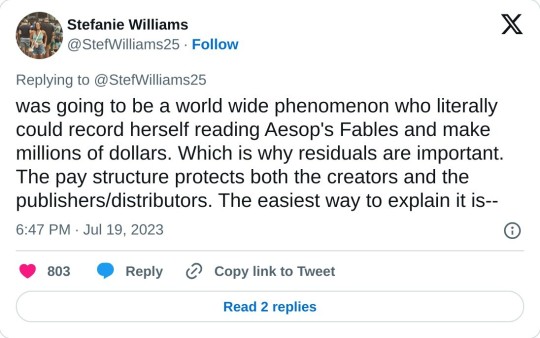
TRUE! However, your bathroom build has a set market value. Art does not. No one knows what makes one TV show an overnight success, and another a flop. No one knows what makes one song a hit, and the other a dud. If they did, trust me when I say record companies would be churning out Taylor Swifts over and over again. Studios would be making nothing but Stranger Things.
But that isn't the case. No one could predict Stranger Things would be a massive, billion dollar hit. No one could predict Taylor Swift was going to be a world wide phenomenon who literally could record herself reading Aesop's Fables and make millions of dollars. Which is why residuals are important. The pay structure protects both the creators and the publishers/distributors.
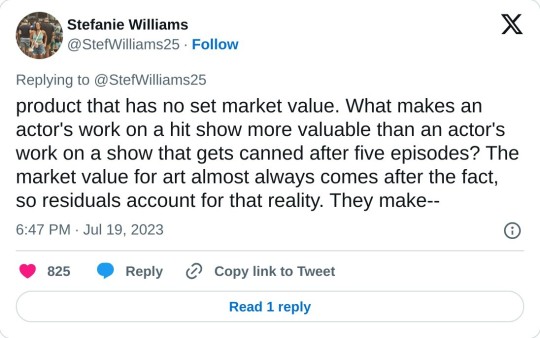
The easiest way to explain it is by referencing an author writing a book. Sure, an author might get a very modest up front fee, but the author is banking on royalties to really make money on the book — for every book sold, the author gets a piece of the pie. This protects both the author and the publisher—because if the book is a flop, the publisher doesn't go broke on a financial promise they made to the author that didn't pan out, and if the book is a mega-hit, the author didn't give away a massive, million-dollar book for 20k.
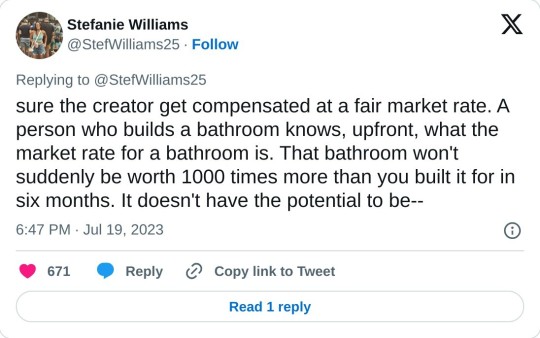
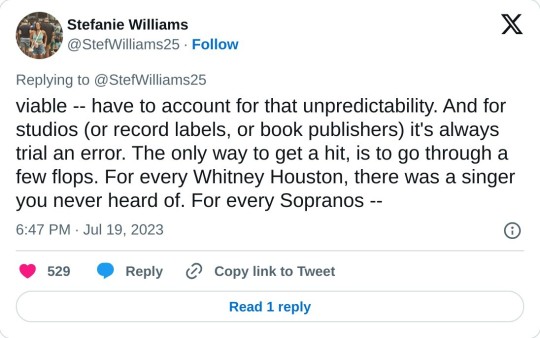
It's a sliding scale that is required for a product that has no set market value. What makes an actor's work on a hit show more valuable than an actor's work on a show that gets canned after five episodes? The market value for art almost always comes after the fact, so residuals account for that reality. They make sure the creator get compensated at a fair market rate. A person who builds a bathroom knows, upfront, what the market rate for a bathroom is. That bathroom won't suddenly be worth 1000 times more than you built it for in six months. It doesn't have the potential to be built for 20k and generate 20 million.
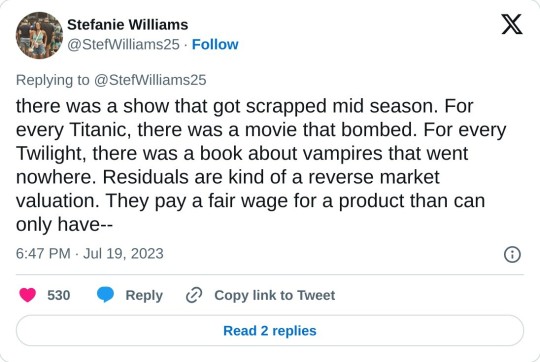
Residuals are a pay structure that simply account for an unsure market value. Trust me, we all wish we could quantify art in terms of dollars. But art is unpredictable. So studios and streamers -- which literally REQUIRE content to stay viable -- have to account for that unpredictability. And for studios (or record labels, or book publishers) it's always trial and error. The only way to get a hit, is to go through a few flops.
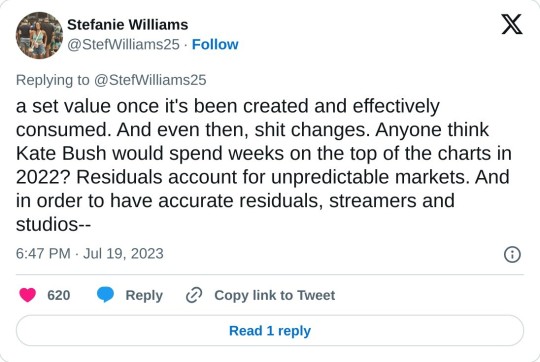
For every Whitney Houston, there was a singer you never heard of. For every Sopranos, there was a show that got scrapped mid season. For every Titanic, there was a movie that bombed. For every Twilight, there was a book about vampires that went nowhere. Residuals are kind of a reverse market valuation. They pay a fair wage for a product than can only have a set value once it's been created and effectively consumed.
And even then, shit changes. Anyone think Kate Bush would spend weeks on the top of the charts in 2022? Residuals account for unpredictable markets. And in order to have accurate residuals, streamers and studios need to be transparent and open about their data, which is one of the MANY things the WGA and SAG are both fighting for.
#sag-aftra strike#sag strike#actors strike#union solidarity#support unions#fans4wga#described#wga strike#writers strike
3K notes
·
View notes
Text
How I ditched streaming services and learned to love Linux: A step-by-step guide to building your very own personal media streaming server (V2.0: REVISED AND EXPANDED EDITION)
This is a revised, corrected and expanded version of my tutorial on setting up a personal media server that previously appeared on my old blog (donjuan-auxenfers). I expect that that post is still making the rounds (hopefully with my addendum on modifying group share permissions in Ubuntu to circumvent 0x8007003B "Unexpected Network Error" messages in Windows when transferring files) but I have no way of checking. Anyway this new revised version of the tutorial corrects one or two small errors I discovered when rereading what I wrote, adds links to all products mentioned and is just more polished generally. I also expanded it a bit, pointing more adventurous users toward programs such as Sonarr/Radarr/Lidarr and Overseerr which can be used for automating user requests and media collection.
So then, what is this tutorial? This is a tutorial on building and setting up your own personal media server running Ubuntu and using Plex (or Jellyfin) to not only manage your media but to stream your media to your devices both locally at home, and remotely anywhere in the world where you have an internet connection. It’s a tutorial on how by building a personal media server and stuffing it full of films, television and music that you acquired through indiscriminate and voracious media piracy ripping your own physical media to disk, you’ll be free to completely ditch paid streaming services altogether. No more will you have to pay for Disney+, Netflix, HBOMAX, Hulu, Amazon Prime, Peacock, CBS All Access, Paramount+ Crave or any other streaming service that is not named Criterion Channel (which is actually good) to watch your favourite films and television shows, instead you’ll have your own custom service that will only feature things you want to see, and where you have control over your own files and how they’re delivered to you. And for music fans, Jellyfin and Plex both support music collection streaming so you can even ditch the music streaming services. Goodbye Spotify, Youtube Music, Tidal and Apple Music, welcome back unreasonably large MP3 collections (or FLAC collections).
On the hardware front, I’m going to offer a few options catered towards various budgets and media library sizes. The cost of getting a media server going using this guide will run you anywhere from $450 CDN/$325 USD at the entry level to $1500 CDN/$1100 USD at the high end. My own server cost closer to the higher figure, with much of that cost being hard drives. If that seems excessive maybe you’ve got a roommate, a friend, or a family member who would be willing to chip in a few bucks towards your little project if they get a share of the bounty. This is how my server was funded. It might also be worth thinking about the cost over time, how much you spend yearly on subscriptions vs. a one time cost of setting a server. Then there's just the joy of being able to shout a "fuck you" at all those show cancelling, movie hating, hedge fund vampire CEOs who run the studios by denying them your money. Drive a stake through David Zaslav's heart.
On the software side I will walk you through, step-by-step, in installing Ubuntu as your server's OS, configuring your storage in a RAIDz array with ZFS, sharing your zpool to Windows with Samba, running a remote connection into your server from your Windows PC, and getting started with Plex/Jellyfin Media Server. Every terminal command you will need to input will be provided, and I will even share with you a custom #bash script that will make the used vs. available drive space on your server display correctly in Windows.
If you have a different preferred flavour of Linux (Arch, Manjaro, Redhat, Fedora, Mint, OpenSUSE, CentOS, or Slackware etc. et. al.) and are aching to tell me off for being basic using Ubuntu, this tutorial is not for you. The sort of person with a preferred Linux distro is the sort of person who can do this sort of thing in their sleep. Also I don't care. This tutorial is intended for the average home computer user. This is also why we’re not using a more exotic home server solution like running everything through Docker Containers and managing it through a dashboard like Homarr or Heimdall. While such solutions are fantastic and can be very easy to maintain once you have it all set up, wrapping your brain around Docker is a whole thing in and of itself. If you do follow this tutorial and enjoyed putting everything together, then I would encourage you to maybe go back in a year’s time, do your research and and redo everything so it’s set up with Docker Containers.
This is also a tutorial aimed at Windows users. Although I was a daily user of OS X for many years (roughly 2008-2023) and I've dabbled quite a bit with different Linux distributions (primarily Ubuntu and Manjaro), my primary OS these days is Windows 11. Many things in this tutorial will still be applicable to Mac users but others (e.g. setting up shares) you will have to look up yourself. I doubt it would be difficult to do so.
Nothing in this tutorial will require feats of computing expertise from you. All you will need is a basic level of computer literacy (e.g. an understanding how directories work, being comfortable in settings menus) and a willingness to learn a thing or two. While this guide may look overwhelming at a glance, this is only because I want to be as thorough as possible so that you understand exactly what it is you're doing and you're not just blindly following steps. If you half-way know what you’re doing, you’ll be fine if you ever need to troubleshoot.
Honestly, once you have all the hardware ready it really shouldn't take you more than an afternoon to get everything up and running.
(This tutorial is just shy of seven thousand words long so the rest is under the cut.)
Step One: Choosing Your Hardware
Linux is a light weight operating system, there's almost no bloat and there are recent distributions out there right now that will run perfectly fine on a fourteen year old i3 with 4GB of RAM. Running Plex/Jellyfin media server isn’t very resource intensive either in 90% of use cases. We don’t an expensive or powerful system. So there are several options available to you: use an old computer you already have sitting around but aren't using, buy a used workstation from eBay, or what I believe to be the best option, order an N100 Mini-PC from AliExpress or Amazon.
Note: If you already have an old PC sitting around that you’ve decided to use, fantastic, move on to the next step.
When weighing your options, do keep a few things in mind: the number of people you expect to be streaming simultaneously at any one time, the resolution and bitrate of your media library (4k video takes a lot more processing power than 1080p) and most importantly, how many of those clients are going to be transcoding at any one time. Transcoding is what happens when the playback device does not natively support direct playback of the source file. This can be for a number of reasons, such as the playback device's native resolution, or because the source file was encoded in a video codec unsupported by the playback device.
Ideally we want any transcoding to be performed by hardware, which means we should be looking for an Intel processor with Quick Sync. Quick Sync is a dedicated core on the CPU die designed specifically for video encoding and decoding. This makes for highly efficient transcoding both in terms of processing overhead and power draw. Without these Quick Sync cores, transcoding must be brute forced through software which takes up much more of a CPU’s processing power and takes much more energy. But not all Quick Sync cores are created equal, and you need to keep this in mind if you've decided either to use an old computer or to shop on eBay for a used workstation.
Any Intel processor after second generation Core (Sandy Bridge circa 2011) has Quick Sync cores. It's not until 6th gen (Skylake), however, that those cores support H.265 HEVC. Intel’s 10th gen (Comet Lake) processors support 10bit HEVC and HDR tone mapping. And the recent 12th gen (Alder Lake) processors give you AV1 decoding. As an example, while an 8th gen (Kaby Lake) i5-8500 will be able to transcode a file encoded with H.265 through hardware, it will fall back to software transcoding when given a 10bit H.265 file. So if you’ve decided to use that old PC or to look on eBay for an old Dell Optiplex keep this in mind.
Note 1: The price of old workstations varies wildly and fluctuates frequently. If you get lucky and go looking shortly after a workplace has liquidated a large number of their workstations you can find deals for as low as $100 for a barebones system, but generally an i5-8500 workstation with 16gb RAM will cost you somewhere in the area of $260 CDN/$200 USD.
Note 2: The AMD equivalent to Quick Sync is called Video Core Next, and while it's fine, it's not as efficient and not as mature a technology, only becoming available with first generation Ryzen and it only got decent with their newest CPUs, we want something cheap.
Alternatively you could completely forgo having to keep track of what generation of CPU is equipped with Quick Sync cores with support for which codecs, and just buy an N100 mini-PC. For around the same price or less than a good used workstation you can pick up a Mini-PC running an Intel N100 processor. The N100 is a four-core processor based on the 12th gen Alder Lake architecture and comes equipped with the latest revision of the Quick Sync. They offer astounding hardware transcoding capabilities for their size and power draw and otherwise perform equivalent to an i5-6500. A friend of mine uses an N100 machine as a dedicated retro emulation gaming system. These are also remarkably efficient chips, they sip power. In fact, the difference between running one of these and an old workstation could work out to hundreds of dollars a year in energy bills depending on where you live.
You can find these Mini-PCs all over Amazon or for a little cheaper over on AliExpress. They range in price from $170 CDN/$125 USD for a no name N100 with 8GB RAM to $280 CDN/$200 USD for a Beelink S12 Pro with 16GB RAM. The brand doesn't really matter, they're all coming from the same three factories in Shenzen, go for whichever one fits your budget or has the features you want. 8GB RAM should be enough, Linux is lightweight and Plex only calls for 2GB RAM, and a 256GB SSD is more than enough for what we need as a boot drive. 16GB RAM might result in a slightly snappier experience, especially with ZFS, and going for a bigger drive might allow you to get away with things like creating preview thumbnails for Plex, but it’s up to you and your budget.
The Mini-PC I wound up buying was a Firebat AK2 Plus with 8GB RAM and a 256GB SSD. It looks like this:

Note: Be forewarned that if you decide to order a Mini-PC from AliExpress, note the power adapter it is shipping with. The one I bought came with an EU power adapter and I had to supply my own North American power supply. Thankfully this is a minor issue as a barrel plug 30W/12V/2.5A power adapters are plentiful and can be had for $10.
Step Two: Choosing Your Storage
Storage is the most important part of our build, and the most expensive. Thankfully it’s also easily upgrade-able down the line.
For people with a smaller media collection (4TB to 8TB), a limited budget, or who will only ever have two simultaneous streams running, I would say that the most economical course of action would be to simply buy a USB 3.0 8TB external HDD. Something like this Western Digital or this Seagate external drive. One of these will cost you somewhere around $200 CDN/$140 USD. Down the line you could add a second external drive or replace it with a multi-drive RAIDz set up as detailed below.
If a single external drive the path for you, move on to step three.
For people who have larger media libraries (12TB+), who have a lot of media in 4k, or care about data redundancy, the answer is a RAID array featuring multiple HDDs in an enclosure.
Note: If you are using an old PC you already have as your server and have the room for at least three 3.5" drives, and as many open SATA ports on your mother board you won't need an enclosure, just install the drives in your old case. If your old computer is a laptop or doesn’t have room for more internal drives, then I would suggest an enclosure.
The minimum number of drives needed to run a RAIDz array is three, and seeing as RAIDz is what we will be using, you should be looking for an enclosure with hree to five bays. I think that four disks makes for a good compromise for a home server. Regardless of whether you go for a three, four, or five bay enclosure, do be aware that in a RAIDz array the space equivalent of one of the drives will be dedicated to parity at a ratio expressed by the equation 1 − 1/n i.e. in a four bay enclosure equipped with four 12TB drives configured in RAIDz we would be left with a total of 36TB of usable space (48TB raw size). The reason for why we might sacrifice storage space in such a manner will be explained in the next section.
A four bay enclosure will cost somewhere in the area of $200 CDN/$140 USD. You don't need anything fancy, nothing with hardware RAID (RAIDz is done entirely in software) or even USB-C. An enclosure with USB 3.0 will perform just fine. Don’t worry about bottlenecks, a mechanical HDD will be limited by the speed of its mechanism long before before it will be limited by the speed of a USB connection. I've seen decent looking enclosures from TerraMaster, Yottamaster, Mediasonic and Sabrent.
When it comes to selecting the drives, as of this writing, the best value (dollar per gigabyte) are those in the range of 12TB to 20TB. I settled on 12TB drives myself. If 12TB to 20TB drives are out of your budget, go with what you can afford, or look into refurbished drives. I'm not sold on the idea of refurbished drives but some people swear by them.
When shopping for harddrives, look for drives that are specifically designed for NAS use. Drives designed for NAS use typically have better vibration dampening and are designed to be active 24/7, they will also often use CMR (conventional magnetic recording) rather than SMR (shingled magnetic recording) which nets them a sizable performance bump. Seagate Ironwolf and Toshiba NAS drives are both well regarded. I would avoid Western Digital Red drives at this time. WD Reds were a go to recommendation up until earlier this year when it was revealed that they feature firmware that will throw up false SMART warnings telling you to replace the drive at the three year mark when there might be nothing at all wrong with that drive, and when it will likely be good for another six, seven or more years.

Step Three: Installing Linux
For this step you will need a USB thumbdrive of at least 6GB in capacity, a way to make it into bootable media, and an .ISO of Ubuntu.
First download a copy of Ubuntu desktop (for best performance we could download the Server release, but for new Linux users I would recommend against using the server release as having a GUI can be very helpful, not many people are wholly comfortable doing everything through command line). 22.04.3 Jammy Jellyfish is the current Long Term Service release, this is the one to get.
Download the .ISO and then download and install balenaEtcher on your Windows PC, balenaEtcher is an easy to use program for creating bootable media, you simply insert your thumbdrive, select the .ISO you just downloaded, and it will create a bootable installation media for you.
Once you've made a bootable media and you've got your Mini-PC (or old PC/used workstation) in front of you, hook it in directly to your router with an ethernet cable, and plug in the HDD enclosure, a monitor, mouse and a keyboard. Now turn that sucker on and hit whatever key it is that gets you into the BIOS (typically ESC, DEL or F2). If you’re using a Mini-PC check to make sure that the P1 and P2 power limits are set correctly and not arbitrarily lowered, my N100's P1 limit was set at 10W, a full 20W under the chip's power limit. Also make sure that the RAM is running at the advertised speed. My Mini-PC’s RAM was set at 2333Mhz out of the box when it should have been 3200Mhz. Once you’ve done that, key over to the boot order and place the USB drive first in the boot order. Then save the BIOS settings and restart.
After you restart you’ll be greeted by Ubuntu's installation screen. Installing Ubuntu is really straight forward, select the "minimal" installation option, as we won't need anything on this computer except for a browser (Ubuntu comes preinstalled with Firefox) and Plex Media Server/Jellyfin Media Server. Also remember to delete and reformat that Windows partition! We don't need it.
Step Four: Installing ZFS and Setting Up the RAIDz Array
Note: If you opted for just a single external HDD skip this step and move onto setting up a Samba share.
Once Ubuntu is installed it's time to configure our storage by installing ZFS to build our RAIDz array. ZFS is a "next-gen" file system that is both massively flexible and massively complex. It's capable of snapshot backup, self healing error correction, ZFS pools can be configured with drives operating in a supplemental manner alongside the storage vdev (e.g. fast cache, dedicated secondary intent log, hot swap spares etc.). It's also a file system very amenable to fine tuning. Block and sector size are adjustable to use case and you're afforded the option of different methods of inline compression. If you'd like a very detailed overview and explanation of its various features and tips on tuning a ZFS array check out these articles from Ars Technica. For now we're going to ignore all these features and keep it simple, we're going to pull our drives together into a single vdev running in RAIDz which will be the entirety of our zpool, no fancy cache drive or SLOG.
Open up the terminal and type the following commands:
sudo apt update
then
sudo apt install zfsutils-linux
This will install the ZFS utility. Verify that it's installed with the following command:
zfs --version
Next, it's time to check that the HDDs we have in the enclosure are healthy, running and recognized. We also want to find out their device IDs and take note of them:
sudo fdisk -1
Note: You might be wondering why some of these commands require "sudo" in front of them while others don't. "Sudo" is short for "super user do”. When and where "sudo" is used has to do with the way permissions are set up in Linux. Only the "root" user has the access level to perform certain tasks in Linux. As a matter of security and safety regular user accounts are kept separate from the "root" user. It's not advised (or even possible) to boot into Linux as "root" with most modern distributions. Instead by using "sudo" our regular user account is temporarily given the power to do otherwise forbidden things. Don't worry about it too much at this stage, but if you want to know more check out this introduction.
If everything is working you should get a list of the various drives detected along with their device IDs which will look something like this: /dev/sdc. You can also check the device IDs of the drives by opening the disk utility app. Jot these IDs down we'll need them for our next step, creating our RAIDz array.
RAIDz is similar to RAID-5 in that instead of striping your data over multiple disks, exchanging redundancy for speed and available space (RAID-0), or mirroring your data writing two copies of every piece (RAID-1), it instead writes parity blocks across the disks in addition to striping, this provides a balance of speed, redundancy and available space. If a single drive fails, the parity blocks on the working drives can be used to reconstruct the entire array as soon as a replacement drive is added.
Additionally, RAIDz improves over some of the common RAID-5 flaws. It's more resilient and capable of self healing, checking for errors against a checksum. It's more forgiving this way, and it's likely that you'll be able to detect when a drive is on its way out well before it fails. A RAIDz array can survive the loss of any one drive.
Note: While RAIDz is indeed resilient, if a second drive fails during the rebuild, you're fucked. Always keep backups of things you can't afford to lose. This tutorial, however, is not about proper data safety.
To create the pool, use the following command:
sudo zpool create "zpoolnamehere" raidz "device IDs of drives we're putting in the pool"
For example, let's creatively name our zpool "mypool". It will consist of four drives which have the device IDs: sdb, sdc, sdd, and sde. The resulting command would look like this:
sudo zpool create mypool raidz /dev/sdb /dev/sdc /dev/sdd /dev/sde
If for example you bought five HDDs and wanted more redundancy, and are okay with three disks worth of capacity, we would modify the command to "raidz2" and the command would look something like the following:
sudo zpool create mypool raidz2 /dev/sdb /dev/sdc /dev/sdd /dev/sde /dev/sdf
An array configured like this would be able to survive two disk failures and is known as RAIDz2.
Once the zpool has been created, we can check its status with the command:
zpool status
Or more concisely with:
zpool list
The nice thing about ZFS as a file system is that an array is ready to go immediately after creating the pool. If we were to set up a traditional RAID-5 array using mbam, we'd have to sit through a potentially hours long process of reformatting and partitioning the drives. Instead we're ready to go out the gates.
The zpool should be automatically mounted to the filesystem after creation, check on that with the following:
df -hT | grep zfs
Note: If your computer ever loses power suddenly, say in event of a power outage, you may have to re-import your pool. In most cases, ZFS will automatically import and mount your pool, but if it doesn’t and you can't see your array, simply open the terminal and type sudo zpool import -a.
By default a zpool is mounted at /"zpoolname". The pool should be under our ownership but let's make sure with the following command:
sudo chown -R "yourlinuxusername" /"zpoolname"
Note: Changing file and folder ownership with "chown" and file and folder permissions with "chmod" are essential commands for much of the admin work in Linux, but which we won't be dealing with extensively in this guide. If you'd like a deeper tutorial and explanation you can check out these two guides: chown and chmod.
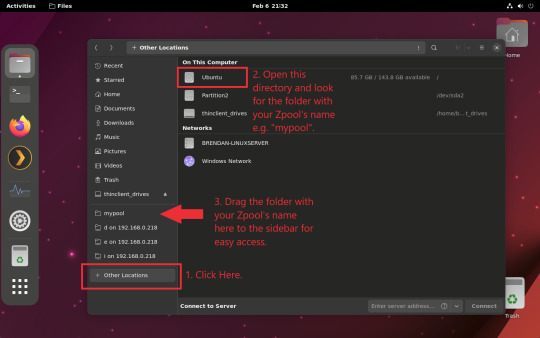
You can access the zpool file system through the GUI by opening the file manager (the Ubuntu default file manager is called Nautilus) and clicking on "Other Locations" on the sidebar, then entering the Ubuntu file system and looking for a folder with your pool's name. Bookmark the folder on the sidebar for easy access.
Your storage pool is now ready to go. Assuming that we already have some files on our Windows PC we want to copy to over, we're going to need to install and configure Samba to make the pool accessible in Windows.
Step Five: Setting Up Samba/Sharing
Samba is what's going to let us share the zpool with Windows and allow us to write to it from our Windows machine. First let's install Samba with the following commands:
sudo apt-get update
then
sudo apt-get install samba
Next create a password for Samba.
sudo smbpswd -a "yourlinuxusername"
It will then prompt you to create a password. Just reuse your username password for simplicity's sake.
Note: if you're using just a single external drive replace the zpool location in the following commands with wherever it is your external drive is mounted, for more information see this guide on mounting an external drive in Ubuntu.
After you've created a password we're going to create a shareable folder in our pool with this command
mkdir /"zpoolname"/"foldername"
Now we're going to open the smb.conf file and make that folder shareable Enter the following command.
sudo nano /etc/samba/smb.conf
This will open the .conf file in nano, the terminal text editor program. Now at the end of smb.conf add the following entry:
["foldername"]
path = /"zpoolname"/"foldername"
available = yes
valid users = "yourlinuxusername"
read only = no
writable = yes
browseable = yes
guest ok = no
Ensure that there are no line breaks between the lines and that there's a space on both sides of the equals sign. Next step is to allow Samba traffic through the firewall:
sudo ufw allow samba
Finally restart the Samba service:
sudo systemctl restart smbd
At this point we'll be able to access to the pool, browse its contents, and read/write to it from Windows. But there's one more thing left to do, Windows doesn't natively support the ZFS file systems and will read the used/available/total space in the pool incorrectly. Windows will read available space as total drive space, and all used space as null. This leads to Windows only displaying a dwindling amount of "available" space as the drives are filled. We can fix this! Functionally this doesn't actually matter, we can still write and read to and from the disk, it just makes it difficult to tell at a glance the proportion of used/available space, so this is an optional step but one I recommend (this step is also unnecessary if you're just using a single external drive). What we're going to do is write a little shell script in #bash. Open nano with the terminal with the command:
nano
Now insert the following code:
#!/bin/bash
CUR_PATH=`pwd`
ZFS_CHECK_OUTPUT=$(zfs get type $CUR_PATH 2>&1 > /dev/null) > /dev/null
if [[ $ZFS_CHECK_OUTPUT == *not\ a\ ZFS* ]]
then
IS_ZFS=false
else
IS_ZFS=true
fi
if [[ $IS_ZFS = false ]]
then
df $CUR_PATH | tail -1 | awk '{print $2" "$4}'
else USED=$((`zfs get -o value -Hp used $CUR_PATH` / 1024)) > /dev/null AVAIL=$((`zfs get -o value -Hp available $CUR_PATH` / 1024)) >
/dev/null
TOTAL=$(($USED+$AVAIL)) > /dev/null
echo $TOTAL $AVAIL
fi
Save the script as "dfree.sh" to /home/"yourlinuxusername" then change the ownership of the file to make it executable with this command:
sudo chmod 774 dfree.sh
Now open smb.conf with sudo again:
sudo nano /etc/samba/smb.conf
Now add this entry to the top of the configuration file to direct Samba to use the results of our script when Windows asks for a reading on the pool's used/available/total drive space:
[global]
dfree command = home/"yourlinuxusername"/defree.sh
Save the changes to smb.conf and then restart Samba again with the terminal:
sudo systemctl restart smbd
Now there’s one more thing we need to do to fully set up the Samba share, and that’s to modify a hidden group permission. In the terminal window type the following command:
usermod -a -G sambashare “yourlinuxusername”
Then restart samba again:
sudo systemctl restart smbd
If we don’t do this last step, while everything would appear to work fine, and you will be able to see and map the drive from Windows and even begin transferring files, you'd soon run into a lot of frustration. As every ten minutes or so a file would fail to transfer and you would get a window announcing “0x8007003B Unexpected Network Error”. This window would require your manual input to continue the transfer with the file that was next in the queue. It will reattempt to transfer whichever files failed the first time around at the end, and 99% of the time they’ll go through, but this is a major pain in the ass if you’ve got a lot of data you need to transfer and want to step away from the computer for a while. It turns out samba can act a little weirdly with the higher read/write speeds of RAIDz arrays and transfers from Windows, and will intermittently crash and restart itself if this group option isn’t changed. Inputting the above command will prevent you from ever seeing that window.
The last thing we're going to do in this part before switching over to our Windows PC is grab the IP address of our Linux machine. Enter the following command:
hostname -I
This will spit out this computer's IP address on the local network (it will look something like 192.168.0.x), write it down. It might be a good idea once you're done here to go into your router settings and reserving that IP for your Linux system in the DHCP settings. Check the manual for your specific model router on how to access its settings, typically it can be accessed by opening a browser and typing http:\\192.168.0.1 in the address bar, but your router may be different.
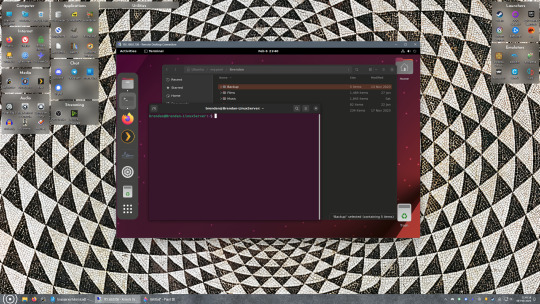
Okay we’re done with our Linux computer for now. Get on over to your Windows PC, open File Explorer, right click on Network and click "Map network drive". Select Z: as the drive letter (you don't want to map the network drive to a letter you could conceivably be using for other purposes) and enter the IP of your Linux machine and location of the share like so: \\"LINUXCOMPUTERLOCALIPADDRESSGOESHERE"\"zpoolnamegoeshere"\. Windows will then ask you for your username and password, enter the ones you set earlier in Samba and you're good. If you've done everything right it should look something like this:

You can now start moving media over from Windows to the share folder. It's a good idea to have a hard line running to all machines. Moving files over Wi-Fi is going to be tortuously slow, the only thing that’s going to make the transfer time tolerable (hours instead of days) is a solid wired connection between both machines and your router.
Step Six: Setting Up Remote Desktop Access to Your Server
After the server is up and going, you’ll want to be able to access it remotely from Windows. Barring serious maintenance/updates, this is how you'll access it most of the time. On your Linux system open the terminal and enter:
sudo apt install xrdp
Then:
sudo systemctl enable xrdp
Once it's finished installing, open “Settings” on the sidebar and turn off "automatic login" in the User category. Then log out of your account. Attempting to remotely connect to your Linux computer while you’re logged in will just result in a black screen!
Now get back on your Windows PC, open search and search for "RDP". A program called "Remote Desktop Connection" should pop up, open this program as an administrator by right-clicking and selecting “run as an administrator”. You’ll be greeted with a window, in the field marked “Computer” type in the IP address of your Linux computer. Press connect and you'll be greeted with a new window and a prompt asking for your username and password. Enter your Ubuntu username and password here.
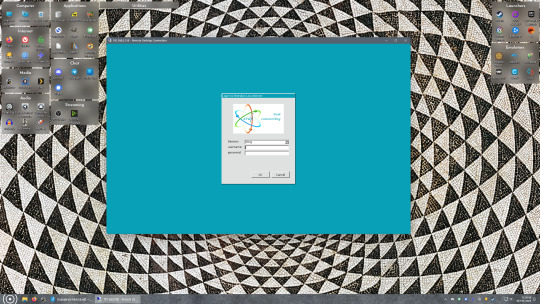
If everything went right, you’ll be logged into your Linux computer. If the performance is too sluggish, adjust the display options, lowering the resolution and colour depth do a lot to make the interface feel snappier.
Remote access is how we're going to be using our Linux system from now, outside of some edge cases like needing to get into the BIOS or upgrading to a new version of Ubuntu. Everything else from performing maintenance like a monthly zpool scrub (this is important!!!) to checking zpool status and updating software can all be done remotely.

This is how my server lives its life now, happily humming and chirping away on the floor next to the couch in the corner of the living room.
Step Seven: Plex Media Server/Jellyfin
Okay we’ve got all the ground work finished and our server is almost up and running: we’ve got Ubuntu up and running, the storage is primed, we’ve set up remote connections and sharing, and maybe we’ve moved over some of favourite movies and TV shows.
Now we need to decide on the media server software to use which will stream our media to us and organize our library. For most people I’d recommend Plex, it just simply works 99% of the time. That said, Jellyfin has a lot to recommend it by too even if it is rougher around the edges, some people even run both simultaneously, it’s not that big an extra strain. I do recommend doing a little bit of your own research into the features each platform offers. But as a quick run down, consider some of the following points.
Plex is closed source and is funded through PlexPass purchases while Jellyfin is open source and entirely user driven. This means a number of things, for one, Plex requires you to purchase a “PlexPass” (purchased as a one time lifetime fee $159.99 CDN/$120 USD or paid for on a monthly yearly subscription basis) for access to certain features, like hardware transcoding (and we want hardware transcoding) and automated intro/credits detection and skipping, while Jellyfin offers this for free. On the other hand, Plex supports a lot more devices than Jellyfin and updates more frequently. That said Jellyfin's Android/iOS apps are completely free, while the Plex Android/iOS apps must be activated for a one time cost of $6 CDN/$5 USD. Additionally the Plex Android/iOS apps are vastly unified in UI and functionality across platforms, offering a much more polished experience, while the Jellyfin apps are a bit of a mess and very different from each other. Jellyfin’s actual media player itself is more fully featured than Plex's, but on the other hand Jellyfin's UI, library customization and automatic media tagging really pale in comparison to Plex. Streaming your music library is free through both Jellyfin and Plex, but Plex offers the PlexAmp app for dedicated music streaming which boasts a number of fantastic features, unfortunately some of those fantastic features require a PlexPass. If your internet is down, Jellyfin can still do local streaming, while Plex can fail to play files. Jellyfin has a slew of neat niche features like support for Comic Book libraries with the .cbz/.cbt file types, but then Plex offers some free ad-supported TV and films, they even have a free channel that plays nothing but Classic Doctor Who.
Ultimately it's up to you, I settled on Plex because although some features are pay-walled, it just works. It's more reliable and easier to use, and a one-time fee is much easier to swallow than a subscription. I do also need to mention that Jellyfin does take a little extra bit of tinkering to get going in Ubuntu, you’ll have to set up process permissions, so if you're more tolerant to tinkering, Jellyfin might be up your alley and I’ll trust that you can follow their installation and configuration guide. For everyone else, I recommend Plex.
So pick your poison: Plex or Jellyfin.
Note: The easiest way to download and install either of these packages in Ubuntu is through Snap Store.
After you've installed one (or both), opening either app will launch a browser window into the browser version of the app allowing you to set all the options server side.
The process of adding creating media libraries is essentially the same in both Plex and Jellyfin. You create a separate libraries for Television, Movies, and Music and add the folders which contain the respective types of media to their respective libraries. The only difficult or time consuming aspect is ensuring that your files and folders follow the appropriate naming conventions:
Plex naming guide for Movies
Plex naming guide for Television
Jellyfin follows the same naming rules but I find their media scanner to be a lot less accurate and forgiving than Plex. Once you've selected the folders to be scanned the service will scan your files, tagging everything and adding metadata. Although I find do find Plex more accurate, it can still erroneously tag some things and you might have to manually clean up some tags in a large library. (When I initially created my library it tagged the 1963-1989 Doctor Who as some Korean soap opera and I needed to manually select the correct match after which everything was tagged normally.) It can also be a bit testy with anime (especially OVAs) be sure to check TVDB to ensure that you have your files and folders structured and named correctly. If something is not showing up at all, double check the name.
Once that's done, organizing and customizing your library is easy. You can set up collections, grouping items together to fit a theme or collect together all the entries in a franchise. You can make playlists, and add custom artwork to entries. It's fun setting up collections with posters to match, there are even several websites dedicated to help you do this like PosterDB. As an example, below are two collections in my library, one collecting all the entries in a franchise, the other follows a theme.

My Star Trek collection, featuring all eleven television series, and thirteen films.
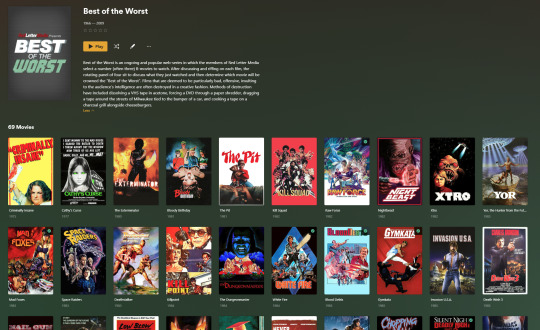
My Best of the Worst collection, featuring sixty-nine films previously showcased on RedLetterMedia’s Best of the Worst. They’re all absolutely terrible and I love them.
As for settings, ensure you've got Remote Access going, it should work automatically and be sure to set your upload speed after running a speed test. In the library settings set the database cache to 2000MB to ensure a snappier and more responsive browsing experience, and then check that playback quality is set to original/maximum. If you’re severely bandwidth limited on your upload and have remote users, you might want to limit the remote stream bitrate to something more reasonable, just as a note of comparison Netflix’s 1080p bitrate is approximately 5Mbps, although almost anyone watching through a chromium based browser is streaming at 720p and 3mbps. Other than that you should be good to go. For actually playing your files, there's a Plex app for just about every platform imaginable. I mostly watch television and films on my laptop using the Windows Plex app, but I also use the Android app which can broadcast to the chromecast connected to the TV. Both are fully functional and easy to navigate, and I can also attest to the OS X version being equally functional.
Part Eight: Finding Media
Now, this is not really a piracy tutorial, there are plenty of those out there. But if you’re unaware, BitTorrent is free and pretty easy to use, just pick a client (qBittorrent is the best) and go find some public trackers to peruse. Just know now that all the best trackers are private and invite only, and that they can be exceptionally difficult to get into. I’m already on a few, and even then, some of the best ones are wholly out of my reach.
If you decide to take the left hand path and turn to Usenet you’ll have to pay. First you’ll need to sign up with a provider like Newshosting or EasyNews for access to Usenet itself, and then to actually find anything you’re going to need to sign up with an indexer like NZBGeek or NZBFinder. There are dozens of indexers, and many people cross post between them, but for more obscure media it’s worth checking multiple. You’ll also need a binary downloader like SABnzbd. That caveat aside, Usenet is faster, bigger, older, less traceable than BitTorrent, and altogether slicker. I honestly prefer it, and I'm kicking myself for taking this long to start using it because I was scared off by the price. I’ve found so many things on Usenet that I had sought in vain elsewhere for years, like a 2010 Italian film about a massacre perpetrated by the SS that played the festival circuit but never received a home media release; some absolute hero uploaded a rip of a festival screener DVD to Usenet, that sort of thing. Anyway, figure out the rest of this shit on your own and remember to use protection, get yourself behind a VPN, use a SOCKS5 proxy with your BitTorrent client, etc.
On the legal side of things, if you’re around my age, you (or your family) probably have a big pile of DVDs and Blu-Rays sitting around unwatched and half forgotten. Why not do a bit of amateur media preservation, rip them and upload them to your server for easier access? (Your tools for this are going to be Handbrake to do the ripping and AnyDVD to break any encryption.) I went to the trouble of ripping all my SCTV DVDs (five box sets worth) because none of it is on streaming nor could it be found on any pirate source I tried. I’m glad I did, forty years on it’s still one of the funniest shows to ever be on TV.
Part Nine/Epilogue: Sonarr/Radarr/Lidarr and Overseerr
There are a lot of ways to automate your server for better functionality or to add features you and other users might find useful. Sonarr, Radarr, and Lidarr are a part of a suite of “Servarr” services (there’s also Readarr for books and Whisparr for adult content) that allow you to automate the collection of new episodes of TV shows (Sonarr), new movie releases (Radarr) and music releases (Lidarr). They hook in to your BitTorrent client or Usenet binary newsgroup downloader and crawl your preferred Torrent trackers and Usenet indexers, alerting you to new releases and automatically grabbing them. You can also use these services to manually search for new media, and even replace/upgrade your existing media with better quality uploads. They’re really a little tricky to set up on a bare metal Ubuntu install (ideally you should be running them in Docker Containers), and I won’t be providing a step by step on installing and running them, I’m simply making you aware of their existence.
The other bit of kit I want to make you aware of is Overseerr which is a program that scans your Plex media library and will serve recommendations based on what you like. It also allows you and your users to request specific media. It can even be integrated with Sonarr/Radarr/Lidarr so that fulfilling those requests is fully automated.
And you're done. It really wasn't all that hard. Enjoy your media. Enjoy the control you have over that media. And be safe in the knowledge that no hedgefund CEO motherfucker who hates the movies but who is somehow in control of a major studio will be able to disappear anything in your library as a tax write-off.
663 notes
·
View notes
Text
I am now at a level of obsession with Disco Elysium where I am watching at least a little bit of every playthrough I come across. Last time this happened was with Undertale almost a decade ago. With UT this helped me get a very thorough handle on the way the game was designed and with the subtler bits of player manipulation. DE is not subtle about anything and so instead I'm getting insights into the people playing it, particularly as it spreads beyond the youtube leftist bubble.
The one I'm having the most fun with right now is by this guy named Brady, who is a therapist specializing in addiction. The fun part is not so much his insight into Harry as an addict - again, the game is not subtle - but his absolute discomfort with politics. He refuses to engage with any of the ideological choices, and that makes the game a bit of a bumpy ride for him. It's particularly striking because he's willing to read into everything else that goes on in Harry's brain - he breaks out his Johari windows and his CBT flowcharts and pins the butterfly right to the corkboard - but he shuts down when the game asks him to pick a side.
To extrapolate wildly from one dude's hangups, I think this is just part of the deal with therapy. The aim of a therapist is to make the subject more functional (particularly these days, when if you're lucky insurance will pay for ten sessions, and you better document exactly what worksheets you made your patients fill out) - and being functional means being able to be happy and productive in the society you're currently living in. If I go to a therapist and say I'm bummed out about all the murdering my government is doing they will suggest I stop watching the news, or, if I'm lucky, they'll try to help me figure out why I feel guilt about things I can't control. Delving into the whys and hows of said murdering is actively counterproductive.
This is not to say that therapy is inherently bad, or, like, counterrevolutionary, because making you a more functional person does help with a lot of things, including your ability to help others. It's just a useful thing to keep in mind when therapy and politics bump into each other. I read this paper when I was googling ABA for podcast reasons and it stuck with me. The thesis boils down to: because the world is imperfect and people need skills to live in it we should continue to torture children, and we don't have enough research to conclude that torture could be traumatic. This is on one level reasonable and on one level insane. It depends where you stand, and whether you think "ability to express affection towards parents" is worth that kind of intervention. But the authors wouldn't construe this as a political argument.
Anyway: with all this in mind, I very much recommend reading "The Saint of Bright Doors", which we will be covering on wizards vs lesbians soon.
#disco elysium#the saint of bright doors#in the ways therapy can be helpful category Brady also points out how Harry sees everything in terms of power dynamics#which I never noticed because I also do that. I wonder why??
519 notes
·
View notes
Text
141 Headcanons: Going Shopping



Grocery/Food Shopping
John Price loves being the one in charge of the buggy/shopping cart. He loves being the one pushing it, holding the list, and watching you walk ahead all pretty, plucking whatever you'd like to buy onto the cart. He also has a natural eye for deals and sales, and knows when something is actually for sale or when the shop is trying to lie to you.
Johnny MacTavish is a menace when he's shopping. With or without you, he's definitely straying from the list and the budget. He's definitely the type to go shopping while hungry and ends up getting too many snacks, or buys seasonal products that you don't need but that "will get rotated out" of the shop so he better buy them Now.
Kyle Garrick makes a whole day out of going shopping. He'll disappear while you're getting a cart and come back with Starbucks or a cold drink of some kind for you to sip on while you go along and buy whatever you need for the house. He's also very efficient, so he bags everything very well, heavy stuff on the bottom, light/fragile on top, and, especially, all the cold/frozen things together.
Simon Riley is too efficient. It's almost scary. He goes in and out of the shop in record time and doesn't even let himself be affected by sales, new products, limited-time-only displays... Nothing. He follows the list to a T and would rather go inside alone than have you follow him and slow him down. But that also makes him an ass and he'll definitely realize you forgot to add something to the list, but will STILL not stray from his 'route' to go get it. If you wanted it, you should've written it down.
VS.
Clothes' Shopping
John Price is of the opinion that all his clothes are fine and, therefore, he doesn't particularly need new ones. That being said, he does know all his sizes and measurements, and won't be opposed to getting news shoes or a new button-up every once in a while. He's also very much the type that'll give you his honest (and sometimes hurtful) opinion on the fit of the clothes you're trying on and sincerely suggest you try the size up/down.
Johnny MacTavish doesn't really like buying new clothes, though he can be convinced... if you promise him you'll go to a lingerie shop and pick out something sexy to wear just for him, he'll let you take him to Levi's or what have you to get him new clothes. That being said, he is the type who, when you're trying to find his size, will fuck off and disappear, only for you to find him by the till, looking at the male jewelry displays and analyzing all the chains and bracelets and cheap watches.
Kyle Garrick is a sweetheart to shop with. He has a good sense of what looks good and what doesn't, and knows the basic of 'big prints work well with small prints and with plain colours', even if he doesn't really wear much of either. He also knows about colour blocking, funnily enough. He loves when his sweetheart tries things out in the dressing rooms just for him.
Simon Riley is the worst person to go shopping with. Be it for yourself or for him. He hates waiting around as you skim the clothes' racks... He'd rather sit outside in the Husband Chair™️ until you're done. And if you try to drag him to a male clothing shop to buy him stuff? He'll complain the whole time about the price and the quality. "Why would I pay 15 quid for a t-shirt when I can put in an order and get 5 shirts from the Army for free, da'lin'?"
#ikea writes 💚#masterlist#headcanon#simon ghost riley#captain john price#john soap mactavish#kyle gaz garrick#shopping headcanons#cod headcanons#141 headcanons#soap headcanons#ghost headcanons#price headcanons#gaz headcanons
195 notes
·
View notes
Last Seen Blogs

skruffi3
/Caskett/\Everlark\/Aidelly\
-Always-

zirosou
My Style香港(H.K.)

galacticlamps
The Moon!

languageboutique
The Language Boutique

anninette
Anninette