
Last Seen Blogs

midnight-me
Altia

cephalonheadquarters
"Your song inspired a blush of love..."

spielereien
GAMES

richs-pics
Rich's Pics

fireshooter5
Untitled
Text
Development during Design

There is often a gap between our ‘Design’ and ‘Development’ stages of product delivery. Basically, when design is done, there is usually some hand-off process to the developers. But how do these two phases interplay with each other? Well, there are different groups of people responsible for each stage: One could argue that developers do not want to receive requirements that are not ‘fully baked’ or subject to change, causing the developer to be hesitant to make major changes for fear of having to redo the work. One could also argue that a designer doesn’t want developers to start working on something that the designer is still tinkering with, again fearing the developers will waste time pursuing an outdated design. But is it possible that both of these arguments are wrong? What if you could have design and development happen in a more-or-less the same time frame? Can this be achieved through increased interactivity, collaboration, and feedback? I believe such a development process is possible, and I believe it could help turn ideas into delivered products faster and with more efficiency.
But do we have the tools to support this today? Having a tokenized design system is a good start. It means that your team has at least thought about how to distribute the design tokens and variables into your application code base. This is a form of integration between design and development that achieves some of the desires of the two groups but still doesn’t improve on the linear hand-off process. For designers, it means that what they have envisioned visually has a more-defined path into the code; however, the developers still have to turn the design into code, and this transformation is imperfect. For developers, it means the designs begin to resemble modular code pieces; but again, they still need to transform them into actual code. The gap between design and code is still there because there is no technological bridge between them. This means that doing these phases at the same time will still have too much unnecessary back-and-forth, especially from developers having to turn design updates into code changes all the time. Until we solve the technological gap here, designers will still be ‘throwing things over a wall’ to developers to some extent.
So how do we create this ‘technological bridge’ without compromising standards or vital processes on either side? The simple answer is to fuse the design tools with the development tools. Have them operate under one language under the hood, and have them generate the code that developers can use. Meanwhile, the UI of the designer tools should behave the same way as before so that designing the application still works the same way. I mean, why shouldn’t the developer get the work that has already been done to position and layout the elements in their correct places by the designer? Why can’t the developer get visual HTML elements that have already shown up in the design mock-ups? As developers, we should be able to leverage the flexibility of the design tools to generate the visual and layout elements of early code structures.
A developer could request to get the generated code of the UI design or of a specific element within it; yet, even this still doesn’t feel interactive enough. There is still a ‘one-way flow’ from ‘finished’ designs to developer. To get larger productivity gains, we need developers to leverage the design tools in a more interactive way. Design should almost become a developer-oriented experience, somewhat akin to an online ‘white-boarding’ tool. But for this, we need something more advanced. We need a design tool that doubles as a code-playground. In other words, you should be able to change the visual design by updating its code, and change its code by updating the visual design. As most know, the main formats of code within a web application are HTML, CSS, and JavaScript; but we can just start with the first two to make things simple. As long as the CSS and HTML is updated when designers make a visual change, and as long as the visual design is updated when developers change the CSS or HTML, then I think this suffices for the minimal functionality that such a ‘playground’ requires.
An even more advanced playground could have actual components as part of the pieces that you can play with. You could then quickly pick and choose which components you want to integrate together and play around with a prototype that could be converted into actual code easily. Seems like a dream scenario, but how can we realistically get there? For one, Web Components are not a bad place to start. By definition, they are self-contained and able to work on any web application since web browsers have natively supported this technology for a while now. Indeed, Web Components could be a great fit for such a design playground, especially since there would be less “framework” overhead to worry about during QA. By bringing the components into such a design playground and keeping them accessible to developer and designer alike, we can create entire integration setups of applications ‘ahead of time’. Perhaps this could even be done, dare I say it, all in one phase. Does this mean the distinctions between the ‘Design’ and the ‘Development’ phases become blurred? I think the answer is yes, and I see development process possible where we have designers and developers start almost simultaneously on new feature development. However, I also think this is an intriguing idea that needs to have the proper tools built out to support such a playground first. But nonetheless, the idea that your designs start their life as usable developer code is quite powerful!
But really, how do we build this? Creating and configuring such an environment might not be easy, but it is not impossible either. In the meantime, we can explore tools like Figma’s ‘Dev Mode’, which was built to appease developers trying to turn designs into code. They seem to support lots of helpful features that help with this and have made it easier for their developers to use the designs. Is it the full solution? I don’t think so. They admit that it is not always easy to make the switch to using their ‘Dev Mode’, but they are eagerly racing ahead with more development on their product so I am sure it will keep growing. There are probably a number of other products that attempt to achieve similar technological improvements to how we operate between ‘Design’ and ‘Development’. Building something more custom yourself might also be the way to go since I don’t think the actual technologies involved are that complicated. Most of all, I think it is the way that we are used to operate within these phases that might be the hardest to change.
But the sell here is not difficult. There are so many benefits. By fusing design with development in this way, some issues can then be avoided or fixed during the design phase, before ‘development’ even starts. Even QA can be involved earlier, and we can feel more confident and be assured of quality earlier in the process. Developers will have access to actual code from the designs, earlier in the process. Designers will even get up-to-date developer changes in their designs, so that the feedback and review process between developer and designer is minimized. The playground becomes a central place where designers and developers can start work almost at the same time. A place that focuses on interactiveness and real-time feedback of changes to the working design. The design itself actually becomes a working prototype version of the code. In other words, developers can take it and build on top of it without having to change what is already in the design. So there now becomes less of an ‘owner’ to this phase, and more of a collaboration between everyone who interacts with this playground. The utility of this playground would also be expanded to product owners and decision makers of all kinds. The common goal being the faster delivery from idea to product through more powerful research and prototyping interactivity during the ‘Design’ phase.
0 notes
Text
XR meets AI

A year ago I saw a great presentation by Hugh Season (@hughseaton), an innovation leader in the XR and e-learning space, and by Jeff Meador (@jeffmeador), an entrepreneur in the immersive reality and AI space. The talks were about using some of the mixed and immersive reality technologies (VR, AR, etc…) for real-world applications, with help from AI added into the mix as well. The development of Artificial Intelligence, as you all know, is moving very quickly these days. But when you combine AI with some of the immersive technologies that are out there these days, you really get amazing new developments. These are experiences that people can now have that enhance how they interact with the environments around them, how they explore information, and even how they learn new skills. Here are some of the more interesting things I have learned in these talks:
First of all, there are a few different ways to build AI systems for users to experience. One way is to build your own multi-model solutions from the ground up. In this case, you control everything and build it however you want. This can get expensive though, and requires a lot of talent and data just to get started. Another way is to integrate your system with an existing API (like Bixby, for example). This way is faster, as it requires less talent and data. It also means your product will become more advanced as the API that you have integrated with becomes better with upgrades. Of course, the easiest option is to just build your complicated stuff completely on top of an existing API without having to acquire much talent or data to get you started. While this last option is the most efficient and flexible in the short-term, it might not fit your exact needs and goals quite as well as you would hope. Still, there are a lot of tools out there to help you do this, like Google’s TensorFlow (an end-to-end open source machine learning platform). Furthermore, other great APIs, including ones with deep learning options, are also available from AWS, Microsoft, and IBM. These can be useful for things like intent modeling, conversational AI, business processes, and analytics.
But, if you have ever been involved in the development of any of these systems, then you know that data is everything if you want it to be successful. If you apply your machine learning straight to XR tech, you will definitely generate a lot of data, but the sheer size of the data points involved with spatial interactive data can be overwhelming. Furthermore, to make good model equations, a lot of data is required; and most of the effort involved in model building is the painstaking collection and massaging of the data. Nonetheless, you can capture data in these new-age XR environments on how people move, act, speak, sound, and other actions. The VR scene itself is huge, and there is a major need in it to specify what is recorded and categorize that data with characteristics and quality measurements. Unsupervised learning is sometimes recommended in this frontier of human interactions, in order to discover new patterns and ideas. Defining interaction zones can be helpful for this also. But most importantly, the barriers to applying machine learning effectively in this space do not lie in the technology, or in the statistics, or in the algorithms, but rather in understanding the data in meaningful ways, and in having adequate time to accomplish that.
Some of the places you might have already seen AI combined with human interactions are in predictive models, like the ones used in recommendations for shoppers and in AI assistants. However, it is in the area of learning and skill development where things like virtual reality can really shine, especially when combined with AI. Virtual reality can put you through valuable experiences by simulating situations, earlier in your career, which can become critically important to you in the future. You can basically asses your readiness for certain future situations in this way. For example, crane simulators can reveal wether new operators are actually afraid of heights ahead of time, which is done by revealing how they deal with specific spatial dimensions. Companies today are actually building such simulations, and are bringing AI into the mix when constructing these virtual training environments. Simulations which involve interactions with avatars are great for on-boarding in some occupations, and can reveal early how well a person deals with things like difficult conversations, conflicts, task delegation, mentoring, providing feedback, social engagement, and even diversity and inclusion. These are basically great ways to assess leadership skills in candidates early, and some companies are starting to even create ‘baselines’ for how employee interactions should flow, based on these models. This has been especially possible through the infusion of AI into the various immersive technologies to create consistent XR experiences and simulations.
And as it turns out, the potential to enhance how we learn is really tremendous here. Using VR, it is often the case that younger consultants can explain newer concepts to older people. This is achieved by the created virtual experiences someone can learn through, as opposed to other conventional means of learning. Virtual trainers and avatars in these XR environments can possibly replace traditional learning one day, as statistics show that these ways of learning are quite effective. The reason for this lies in the fact that during these immersive experiences, your mind is more likely to take things seriously, since it feels like you are at the center of the experience, almost like in a dream. However, unlike a dream, your mind remains fully focused in the virtual reality that it is engulfed in, and this makes things easier to remember. As the VR experience progresses, your sense of responsibility grows in it, and it even ‘forces’ you to recall other memories...
Knowing that all of this is not only in development but is already being applied in real world use cases really does make me feel like we are in the future. Hopefully this article sparks your interest to pursue more information about the fields of XR and AI. Hope you enjoyed it.
1 note
·
View note
Text
WebAssembly

By now, you might have heard about WebAssembly. However it still seems rather new to a lot of web developers out there. So what is it? It’s really an open standard that includes an assembly language and a binary format for use in applications, such as those that run in a browser. Essentially, It allows for different languages to be run on the web, which can be very useful for enabling high-performance apps on the browser. Ever wanted to run your C++ high-performance graphics application in the browser? Now you can!
Before WebAssembly there was asm.js: a highly optimizable subset of JavaScript designed to allow other languages to be compiled into it while maintaining high performance characteristics that allowed applications to run much faster than regular JavaScript. So web applications now had a way to perform more efficiently on the browser. Compilers to JavaScript existed before asm.js, but they very terribly slow. WebAssembly, however, went one step further and completely took JavaScript out of the picture. This is now done with Wasm (WebAssembly for short) by compiling a language such as C++ into a binary file that runs in the same sandbox as regular JavaScript. A compiler capable of producing WebAssembly binaries, such as Emscripten, allows fo the compiled program to run much faster than the same program written in traditional JavaScript. This compiled program can access browser memory in a fast and secure way by using the “linear memory” model. Basically this means that the program can use the accessible memory pretty much like C++ does.
WebAssembly is useful for facilitating interactions between programs and their host environments, such as on devices which translate higher code into byte-size code. It is also useful in heavier-weight applications. For example, you can now run CAD software on the browser. WebAssembly removes some limitations by allowing for real multithreading and 64-bit support. Load-time improvements of the compiled programs can be achieved with streaming and tiered compilation, while already compiled byte code can be stored with implicit HTTP cacheing. WebAssembly can sometimes even be faster than native code, and is being utilized in things like CLI tools, game logic, and OS kernels.
Still, there are some things that WebAssembly lacks. Calls between WebAssembly and JavaScript are slow, lacking ES module integration and without a means for easy or fast data exchanges. Toolchain integration and backwards compatibility can also be largely improved on. When transpiling from other languages, garbage collection integration is not great; neither is exception support. Debugging is also a pain, as there is no equivalent of DevTools for WebAssembly.
But the advantages of using WebAssembly are still very intriguing: JavaScript that runs on the browser puts all of its code in a “sandbox” for security purposes; however, with WebAssembly, you can have the browser sandbox, while taking the code out of the browser and still keeping the performance improvements! This could better than Node’s Native Modules, although WebAssembly doesn’t have access to system resources without having to pass system functions into it.
WebAssembly is still in its early stages and is not yet feature complete. Features are still being “unlocked” like a skill tree in a video game. But this doesn’t mean it hasn’t already made an impact in the application development space. Will it be on your list of things to try in 2020?
1 note
·
View note
Text
We have software specialists for your team!

Is your software team in need of help? I am working with top-notch, high quality developers and other software specialists that are looking for contract work. Hiring a contractor means that the total cost to employ a badly needed extra resource to augment your staff could be much lower. Furthermore, it could mean a much more flexible arrangement for your development roadmap. Please contact me at your convenience if this is of interest.
...you can reach me at: [email protected]
1 note
·
View note
Text
Tech Recommendations for Web Apps

I was recently asked to give some recommendations for what front-end and back-end technologies I would choose for a new web application, and here is what I wrote:
For the front end, I highly recommend using React and related libraries to build out the client side of the application. It is the most popular way to build front-ends today and comes with a huge community of support. Its unidirectional data flow and “reactive” approach makes it very easy to debug complicated rendering flows. This also allows for a separation of concerns that brings easier analysis at each layer (from in-memory data preparation business logic to local components’ states), and all of these come with great DevTools plugins for Chrome. I personally have a ton of experience working in the React ecosystem and highly appreciate many aspects of it, especially the virtual DOM diffing, with which I have built very complex and very fast visualizations; SVG + React + D3 is a favorite combination for myself, for instance. The virtual DOM reduces the interactions with the Browser API to an efficient set by using a powerful diffing algorithm that compares the last ‘snapshot’ of a component with the new one about to be rendered. The JSX syntax for building the components’ DOM also allows for more intuitive logic by combining imperative JavaScript with HTML declarations.
Furthermore there are plenty of libraries that together with React make for a powerful client development ecosystem. Redux manages application state and information flow between visual components in a very debuggable and straightforward way, especially when combined with the Immutable.js library and Connect. React-Router manages routing in a declarative way that is very simple to understand and easily gives the client single-page application features (like syncing URL to app state and back/forward state movement) without much hassle. React Native allows you to make web applications for mobile that are essentially OS-agnostic. Typescript is easily integrated into react to reduce run-time errors and lets you be more confident when refactoring. Jest and Enzyme allow you to build out a nice unit testing framework for your components and the app state. The bottom line is that React is one of the most used JS frameworks, is excellent for building advanced applications, and comes with a plethora of supporting tools.
For the back end, there are two clear approaches that stand out for me: Node.js (JavaScript) and Java. I think both approaches can be great but let me outline some pros and cons for each approach as well as the right situations for when to use each one:
Using Node.js to serve your application and building it with Javascript can have its advantages. Building your back end in JavaScript could mean that you only need to know one language to build the entire application (since the client is usually written in JavaScript already). Node also comes with an http server that is very easy to set up and get running, and generally building apps from scratch using Node and Javascript for the back end usually takes a lot less time than say building a Java application and setting it up to be served from an Apache server (or something of the sort). Of course, faster doesn’t mean safer; however, typescript can be used to “transform” JavaScript into basically a strictly-typed language so that should help. Node has been used widely to build highly-scalable “real time” applications and is versatile and quite popular because of its simplicity and use of Javascript. Another advantage of it is that NoSQL databases (such as Mongo) can remove a lot of complexity between your application business logic and storage by using the same language (JavaScript).
However, since the Node environment runs asynchronous I/O, it could be harder to orchestrate how different user requests share resources in memory. The speed gain that you get out of JavaScript being more flexible in how it handles different requests (it runs on a single “non-blocking” thread) has to be weighed against the complexity this brings when application logic grows very large. In Java, each request is generally given a thread to work with, which allows you to isolate the “effect” of the request’s logic and better control exactly how and when resources are shared (via Java’s multithreading capabilities). Still, out of the box, Node can even be more scalable than the Java runtime environment when having to wait for external resources such as reading from a database. This is because JavaScript’s event loop allows it to keep processing the code in an asynchronous way (later checking the event loop to see if previous processes have finished). Of course, in a finely-tuned Java application, the threads know the best time to block and will do so in the appropriate situations, mitigating the issue altogether (although with more code necessary to achieve this than what Node will start you with).
Java has been in use for the better part of three decades now and is a much more mature approach than Node. It is widely supported with a ton of libraries and tools, so building a complex application with it will hardly be a problem. Because of its maturity, and for other reasons (like being compiled and strictly-typed, its memory allocation, its automatic garbage collection mechanism, and its exception handling), it is considered better suited for building more secure back ends for applications. It could also spend less time on handling requests than Node because of its built-in multithreading, which allows the application to perform better by performing tasks simultaneously in a more efficient manner. Java is useful for large-scale applications that have a lot of concurrency needs (e.g. for building a “smart spreadsheet” that can have many realtime modifications from different users). It is also useful for processing large sets of data in high frequencies, and for applications that require CPU-intensive calculations.
In conclusion, writing a Java program will take longer and require more effort; however, the application will be more safe and robust, as well as process data and its calculations faster and in a more efficient way. Picking the right approach here will depend on the resources at your disposal (team knowledge, time constraints, etc…), the nature of the application (type of processing, concurrency needs, importance of security, etc…), considerations for the type of database used (usually relational versus NoSQL), and other factors. So…chose wisely!
PS: You can also read my article on choosing the right server for you application here: https://risebird.tumblr.com/post/140322249595/node-vs-apache-vs-lighttpd-vs-nginx
2 notes
·
View notes
Text
Mentorship

Earlier this year I saw a presentation at ForwardJS by Suraksha Pai (@PaiSuraksha), a full-stack engineer from Yelp!, on mentorship. She talked about how she used to feel ‘lost’ until she started watching videos by successful people and those she idolized, and found something extremely important: That a lot of times success comes with the aid of a long-lasting friend; a “mentor”.
But why do we need a mentor? Well, a mentor can give you all kinds of advice, even some on social issues and career changes. They can give you unwavering support and encouragement, giving you the confidence needed to drive harder towards your goals. They can challenge doubt in yourself, and erase imaginary mental barriers. They allow you to expand your network and knowledge, as they themselves have experienced many things you might not have. They give you a fresh perspective on things and might see new angles that you haven’t. It might be hard because it means opening up to a stranger at first, but having a mentor helps your career growth through learning from them, their boost to your confidence, them helping you develop specific skills, and in general helping your happiness and progress. All it takes to find a mentor is asking someone you work with or know whether they would want to do it, and at the worst case, they could perhaps refer you to someone else. A good way to ease into this process is to describe to your would-be mentor how you see them, what they could help you with, what your goals are, and why you picked them.
A good mentor will use their experience as a guide for you. They will create a safe space for you to open up to them by first building the trust needed for this. They will provide you with honest feedback, since without this they wouldn’t be able to truly help you improve. They won’t just give out solutions, but rather foster a sense of independence for you to try to come to the same conclusions, perhaps through clues or other resources. This will give you confidence to solve things on your own next time. They don’t necessarily need to be the “best” at everything, when in reality, this is impossible. They just need to advise you enough to help you achieve what you are trying to do. Good mentors will be honest and tell you when they don’t have the answers.
Some companies like Yelp! have mentorship programs. There, mentors are paired up with mentees and they work together to come up with goals and ideals, create a plan of action, and implement it. Some mentees try to keep their mentorship secret because they fell like they are lacking something, when getting help in this way could really just mean that they are ready for the next level of their career. Some mentees even have more than one mentor, with different mentors acting as different ‘experts’ in different areas of interest. A mentor is really just someone that knows more than them in a specific domain of knowledge, regardless of other characteristics like the mentor’s age. After working with her mentor, Suraksha eventually became a mentor to someone else also, and so can you! You can get started with this through mentorship programs, meet-ups, conferences, or even offering to mentor new hires at your workplace. As they say: Two heads are always better than one, and helping others and receiving help is a key ingredient in being successful.
1 note
·
View note
Text
67 Articles later...

Three and a half years ago I wrote an article which summarized my foray into the world of software blogging, and provided clickable links into each of the thirty three articles I had written up to that point (risebird.tumblr.com/post/115727628135/thirty-three-blog-articles-later). Although my article-writing pace has slowed down somewhat since then, the articles I’ve focused on writing have not lost their thirst for cutting edge developments in the software industry (especially of those in the quickly-evolving front-end space). I have evolved my career since that April 2015 to be sure, and hopefully my writing ability has progressed also; but as always, you will be the judge of that. So without further ado, I give you the clickable summary of my latest thirty four articles, enjoy!
When building a new mobile app you might have asked yourself whether to build a web app, a native app, or perhaps a hybrid (risebird.tumblr.com/post/134179609930/how-should-i-build-my-mobile-app). Of course, nowadays you can even make a “Progressive Web App” that can still work offline (risebird.tumblr.com/post/172163267760/progressive-web-apps)! In any case it is extremely valuable for a web developer to understand how modern browser performance is advanced through the use of parallelism (risebird.tumblr.com/post/177300904440/modern-browser-performance). In fact, GPUs have re-invented data visualization because of it (risebird.tumblr.com/post/136172693860/getting-deeper-into-d3). Combined with the awesome D3 visualization library (risebird.tumblr.com/post/130034738155/the-d3js-visualization-library), we can accomplish a lot nowadays. D3 experts will get deeper into this library (risebird.tumblr.com/post/136172693860/getting-deeper-into-d3) and even explore it to a very detailed level (risebird.tumblr.com/post/167332736675/details-on-d3); however, the real sparks fly when you combine it with React (risebird.tumblr.com/post/147473986500/d3-react-awesome)!
With the UX expectations of users constantly changing, such as those of modern layouts (risebird.tumblr.com/post/124227499425/modern-layouts), new methods of delivering data to the users, such as immersive analytics (risebird.tumblr.com/post/164978764330/immersive-analytics) have been developed. Dealing with the data itself can be tricky enough (risebird.tumblr.com/post/179818036890/dealing-with-data), but you also need an application capable of bringing it to the end user as quickly as possible (risebird.tumblr.com/post/133313428230/modern-js-apps-single-page-vs-isomorphic). Will you create a standard service oriented architecture around Node (risebird.tumblr.com/post/142205462000/node-microservices) and use a popular tool to build your database (risebird.tumblr.com/post/119012149675/popular-databases-in-2015) to achieve this? Or will you perhaps rely completely on other third party providers for data access/storage (risebird.tumblr.com/post/123359620325/the-front-end-is-the-new-back-end)? Don’t forget that there is no such thing as “serverless” (risebird.tumblr.com/post/158339348525/there-is-no-such-thing-as-serverless). No matter what application server you do choose (risebird.tumblr.com/post/140322249595/node-vs-apache-vs-lighttpd-vs-nginx), be sure user access is regulated with JWTs (risebird.tumblr.com/post/139393722945/json-web-tokens), and that your applications are taking advantage of the new features available in HTTP2 (risebird.tumblr.com/post/132841671265/why-you-should-deploy-http-2-immediately). And always unit test your JavaScript with Jest (risebird.tumblr.com/post/163897551825/javascript-unit-testing-with-jest).
In the future, our applications will all be connected throughout the physical world (risebird.tumblr.com/post/137612619330/centralized-iot-development), and even in the present IoT is already impacting modern applications (risebird.tumblr.com/post/127988661815/a-real-world-iot-application). In such a connected world, it pays to understand how the networks and protocols that deliver these electronic messages to and from us operate (risebird.tumblr.com/post/156345541115/the-lte-physical-layer), and how the messages use sensors and actuators to interact with physical environments (risebird.tumblr.com/post/144442019200/fun-with-development-boards). Drones are especially interesting in this context (risebird.tumblr.com/post/117830816210/drones-in-2015). I also thought greatly about how AI can be used to evolve logic on its own (risebird.tumblr.com/post/170245126095/simulating-life-an-ai-experiment), and how abstract syntax trees can go a long way in achieving this (risebird.tumblr.com/post/171045918950/artificial-neural-networks-versus-abstract-syntax). After starting with some basic ideas for this (risebird.tumblr.com/post/174655336230/simulating-life-early-code), I dove into some of the complexities of mutations in directed evolution (risebird.tumblr.com/post/175132399985/simulating-life-mutations).
Finally, I wrote about the power of the emerging blockchain technology (risebird.tumblr.com/post/162633306305/blockchains-the-technological-shift-of-the-decade), the usefulness of using Wikipedia (risebird.tumblr.com/post/129037111590/trust-in-wikipedia), an interactive news map website I built with my father (risebird.tumblr.com/post/161497655355/mapreport-the-dynamic-news-map), and about making music with JavaScript (risebird.tumblr.com/post/166247227950/make-music-with-javascript)!
I hope you’ve had as much fun reading these articles as I’ve had writing them, it will be great to reflect again on these when I write my 100th article sometimes soon :)
2 notes
·
View notes
Text
Dealing with Data

This fall I attended an event called “Lab Data to Machine Learning in 30 Seconds”, put on by Riffyn (@riffyn, https://riffyn.com/) and AWS, as part of the synbiobeta 2018 (@SynBioBeta) Synthetic Biology Week. It included a panel discussion lead by Riffyn’s CEO Tim Gardner and a panel of data science experts from Amyris, GSK, and Novartis (all three are listed on NASDAQ or NYSE). The focus of the panel was the rapid advance of machine learning and AI in biotech and pharmaceutical R&D; however, the discussion also ventured into other interesting areas like structuring and integration in data systems and the goals and challenges of dealing with data in the biotech industry.
In order to understand how data science had changed the directions and shaped the perspectives of the panelists, the panel explored some of the challenges that they were dealing with in their projects. Sometimes their challenges included acquiring a deeper grasp of where signals or noise came from in the data. Sometimes the challenges included strenuous efforts to 'wrangle’ and structure the data (possibly from thousands of data sources) in order to create new molecules and compounds. Most of the time, however, the challenges involved long and painful analysis of countless spreadsheets. It was also interesting to hear about the kind of goals the panelists had for the data. When data poured in quickly, the panelists wanted to find ways to motivate teams while minding timelines, and to define objectives and limits for the data gathering. Often though, the goals were centered around creating better data models (which are only as good as the data that is fed them); but there was also a longing for an easier system.
The panelists had learned a lot about working with data in their projects and about trying to automate data-related processes. For instance, sometimes the ‘secret sauce’ they were looking for was buried deep within the data, and could only be ‘discovered’ through painstaking data combing and company cross-learning. Sometimes to ensure that they had good data, they had to hire outside help. Sometimes there was excitement in joining data, which connected the scientists with the data’s impact. Other times, they had to mitigate the risk of using ‘biased’ data, since the way the data was trained could result in missed discoveries. In some cases, data that was valuable actually lived in the outliers, yet was still thrown away. Sifting through ‘garbage’ data had to be done in a large-scale automated way so that biased decisions would not be relied on.
They also talked in depth about the aspect of private data (known as “dark data”), which is the data that companies keep to themselves. But how can incentive be increased for companies to start to bring the different sources of data together? There was no simple answer for this! There is usually a lot of mistrust inside of the organizations themselves, and often, the data is not easily available or sharable, hidden away in numerous SharePoint drives and Excel sheets. Most of the time, there is simply too much ego and territoriality attached to the data to allow the data to be accessible by everyone. The scientists working on the data are not cross-training enough or learning about each others’ processes. The culture of sharing data and cross-company involvement definitely needs to change and it usually starts at the top of the organizations. One big thing that could help this happen faster is the development of standards for the data sharing process itself. Such standards have often driven industries to the next level by making it easier for different companies and products to work together; however, standards take a long time to develop because they require companies to ‘opt-in’ to them first.
In tuning into this panel, I also found that there was a genuine enjoyment from the panelists in working with data, especially when it led to discoveries. They even had names for themselves like “data detective” and “molecule artist”. When all of their data could be used, it was very gratifying, as was the ability to navigate the space of billions of predictions in their models. When their work lead to a big landmark finding, it was all worth it! After all, isn’t science all about making discoveries?
1 note
·
View note
Text
Modern Browser Performance

Earlier this year I saw a presentation by Mozilla’s Lin Clark (@linclark) in a talk that had “The future of browser” in its name. Really this was a talk about web performance in modern browsers, with a key focus on parallelism (but more on that later). Here is what I learned:
With the increasing demand of faster web experiences, like those needed for animations, browsers had to become much faster at doing their job. If the browser did not repaint quickly enough, the experience would not flow as smoothly, at least not as smoothly as we have become accustomed to. Today we expect better screen resolutions and ultra-performant UX experiences, even ones that are rendered on web pages of our phones. This has been brought to us not only by the new hardware constantly being developed, but also by the ever-evolving capabilities of the modern browsers like Chrome and Firefox. But how did they achieve the higher processing prowess necessary to utilize the more advanced hardware?
Let’s start by examining how the hardware first improved: We began with single-core CPUs, which performed simple short-term memory operations with the help of their registers and had access to long-term memory stored in RAM. But in order to make a more powerful processing system, we had to split processing into multiple cores, all of them accessing a shared RAM storage. The cores, working side by side, take turns accessing and writing to RAM. But how do they coordinate this? How do they cooperate and ensure the distributed order of the reads and writes is correct? To solve such “data race” issues involved keen strategy and proper timing. It required a network of sharing work that is optimized to maximize the limits of processing power by using GPUs (which can have thousands of separate cores working together). For an example how GPUs are used to distribute work, check out my article on GPUs here:
http://risebird.tumblr.com/post/159538988405/gpus-re-inventing-data-visualization
To take full advantage of these hardware improvements, browser developers had to upgrade the rendering engine. In basic terms, the rendering engine in a browser takes HTML and CSS and creates a plan with it, after which, it turns that plan into pixels. This is done in several phases, culminating with the use of GPUs to compose paint layers; all of which is explained in more detail in an article I wrote four years ago, here:
http://risebird.tumblr.com/post/77825280589/gpu-youre-my-hero
To upgrade this amazing engine, which brings daily web experiences to people around the globe, browser developers turned to parallelism. Parallelism, which is now fully used by Firefox (since summer of 2017), always existed in Chrome, and is the reason why that browser was always faster. What is parallelism? In the context of a web browser, it is the splitting of computational work done by the browser into separate tasks, such as simultaneous processes running on different tabs. But utilizing it correctly, like when using fine-grained parallelism to share memory between many cores, requires very complicated technology and coordination. Not to mention that the resulting data races can cause some of the worst known security issues. Firefox developers, which instead of starting from scratch, slowly merged parallelism into their existing browser, described the process, “like replacing jet engine parts in mid flight”.
These new browser powers allowed us to do much more than run different tabs at the same time on separate cores. We can now assign different cores to different parts of the same page’s UI (e.g. each Pinterest image on a different core). We render web experiences by allowing JavaScript to run on separate cores with the use of web workers, which can even now share memory between each other. Finally, with the advent of WebAssembly, a low-level assembly-like language that runs with near-native performance and can be compiled from C/C++, performance is really starting to soar. For more information on WebAssembly and how it is used alongside the JavaScript in your browser, see:
https://developer.mozilla.org/en-US/docs/WebAssembly
1 note
·
View note
Text
Simulating Life: Mutations
[BLOG ARTICLE HAS BEEN REMOVED. PLEASE EMAIL [email protected] FOR MORE DETAILS]
0 notes
Text
Simulating Life: Early Code
[BLOG ARTICLE HAS BEEN REMOVED. PLEASE EMAIL [email protected] FOR MORE DETAILS]
0 notes
Text
Progressive Web Apps

So you might have heard about Progressive Web Apps being the “new hot thing”, but what are they really? According to developers.google.com they are reliable, fast, and engaging. But is this just nonsense made up by Google, or is this the new way to create experiences for interacting with the web, the biggest platform of applications known to man, in terms of users. Thanks to a great presentation by Jon Kuperman (@jkup), which I saw recently at a ForwardJS conference, I now know that PWAs have begun to earn users’ trust all over the world, by being more performant than other web apps that do not meet the “Progressive Web App standard”.
What is this standard exactly? For one, PWAs will never act like something is wrong when an asset can’t be downloaded from the host or when an API call is taking too long. This is because they attempt to employ all means possible to not ruin your experience by utilizing things like the cacheing system, local storage, and service workers, to keep you in an immersive experience for as long as possible. This is especially important since users’ attention spans seem to plummet every decade. PWAs always use HTTPS, load quickly on your browser, and even work when there is no network connection at all. They also tend to be more user friendly by asking users how they want to interact with the app in a “progressive” way, such as asking for permissions to use native device features, and falling back gracefully to a still-usable UX if such requests are denied.
But are PWAs ready for the World Wide Web? While Chrome and Firefox have taken steps to support PWAs, other browsers like Safari are still behind the ball. It is up to the PWA right now to fall back gracefully when being used on an older browser. You can get a nice progress page on PWA features’ support (broken down by browser) by going here:
https://ispwaready.toxicjohann.com/
It does seem that PWAs are the future, considering that you don’t need to browse some app store to download them. Instead, they can be easily saved directly (and immediately) to your home screen via a browser link. In fact, app stores and other similar collective applications are actually including them in their catalogs, because PWAs have become “first class citizens” in the application world. In any case, the decoupling of apps that can provide “native-like” experiences from the app stores they have mostly been found on in the past, has allowed us to skip the commercial mumbo-jumbo (and sometimes payments) that are normally associated with downloading native applications. Emerging markets, such as those found in countries where the network carriers can only provide 2G networks, also stand to gain a lot from PWAs. This is because PWAs perform so well under poor network conditions, and are expected to work in a minimal way, even when there is no network available at all. Oh and PWAs can also do push notifications, provide APIs for sharing things natively, and offer full screen experiences. Sold yet?
But how does one make a PWA? This is done by including a manifest JSON file in your application, in which you provide information on things like application name, screen orientation, icons, background, etc… Basically, this file allows you to control how your app appears and how it is launched. A great site/library for getting started with PWA development, Workbox, can be found here:
https://developers.google.com/web/tools/workbox/
If you have already built a Progressive Web App, Google’s Lighthouse is a great tool to measure how “up to standard” your PWA really is. Lighthouse assesses how fast your “time to interactive” is for your application, as opposed to the normal “time to first byte/render” for web apps, because PWAs pride themselves on delivering a decent, usable experience, as quickly as possible to the users. Lighthouse is available as a Chrome plugin and you can start using it to measure you PWA’s performance right away, via the DevTools’ Audit tab.
The future of web apps is here folks, and Progressive Web Apps are the new way to provide great application experiences to the users, no matter how many bars they have on their network.
0 notes
Text
Artificial Neural Networks versus Abstract Syntax Trees
[BLOG ARTICLE HAS BEEN REMOVED. PLEASE EMAIL [email protected] FOR MORE DETAILS]
0 notes
Text
Simulating Life, an AI Experiment
[BLOG ARTICLE HAS BEEN REMOVED. PLEASE EMAIL [email protected] FOR MORE DETAILS]
10 notes
·
View notes
Text
Details on D3
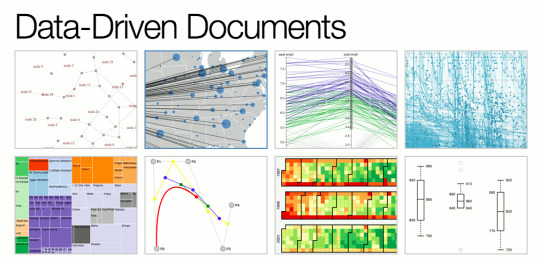
Many people have heard about the data graphing library called D3, but as a D3 enthusiast, I jumped at the chance to see a “beyond basics” presentation this summer by Matt Lane (@mmmaaatttttt), and wrote this article on it.
The D3.js library has many intricacies to deal with; however, those same complexities become useful for creating a very flexible diagramming experience when the situations calls for it. The key to harnessing D3 and creating the data transformations of your dreams, lies in understanding the D3 tool-set. For instance, learning how selection and appending nodes works properly, could improve your D3 application by making your code, your DOM, and your in-memory objects more efficient. Of course, keeping certain principles like moving all data manipulation to the server will also help you get far in your visualizations.
Calling .csv() is usually a good starting point for getting static or generated data into your application. It uses the first row of a text file to designate names of properties, which are then used to record values taken from each subsequent line. Calling .csv() is also nice because you can supply a ‘row’ function as a parameter to it and that function will be used to process/parse each row in any custom way you want; you can also skip a row by returning undefined or not returning at all. A lot of how D3 visualizes data has to do with how data is structured and formatted after it makes it into browser memory. For example, calling .map() is a nice way to remove non-unique values from the data by creating a hash map (and overriding entries with already existing keys).
The .histogram() function clusters your data into separate bins for you, useful for visualizing distributions. You can instruct D3 exactly how to separate the data by chaining a .value() function to the generator (this also works for pies and stacks). D3 makes educated guesses on how to split the bins and how many items to put in each bin, as well as how to draw the bins in terms of graph coordinates. You can also call .threshold() to try to set the number of bins. I say ‘try’ because D3 is opinionated in certain measurements, which are hard to force to an exact value sometimes. Another good way to shape your data is with .pie() to make pie charts, which can make up for some nice custom wedge visualizations.
In its inner workings, D3 is completely independent of jQuery, the popular DOM selection and manipulation library, and instead uses the native document.querySelector() function; however, many D3 functions such as .attr() work exactly like they would with jQuery. So after you use D3 to select DOM elements, you can also manipulate them with D3 (for example, you can call .style() or .transition() to make CSS changes). You can also call .text() and set the text content of selected elements, or only for specific elements by passing in a function with an ‘index’ parameter.
Unlike jQuery, D3 does not use data attributes like those used by jQuery’s .data() function and just keeps track of data objects and elements on its own. This process is initiated by calling D3′s own .data() function, which will join data to elements and return the ‘update’ selection (elements that were successfully bound to data). Since mismatches can and do occur, calling .enter() will give you the ‘enter’ selection (placeholder nodes for each datum that didn’t match a DOM element), and calling .exit() will give you the ‘exit’ selection (existing DOM elements for which no datum was found). All three of these functions select and iterate over data/nodes with whatever functions that are chained to them, like for example, you can use .exit().remove() on a selection to remove elements that could not be bound to any data. D3 attempts to correct these mismatches to the best of its ability, but enter nodes and exit elements can and will happen. You can also put breakpoints or log calls in the functions chained after selections to see how each node/element is processed.
Understanding how new elements are added by D3 is also important. Calling .append() will create children for each selected node, and set the ‘parent’ of these nodes to the selected node. You have to be careful when doing this, because if .append() is called on non-existing elements, it will instead append the new elements to the bottom of the page. You can also use .node() to get the HTML for each selected element.
Of course, when using D3 in conjunction with React, joining data to elements is not used as much because React already iterates over data and creates HTML elements from it; however, React’s declarative nature works perfectly with a lot of other useful geometry such as SVG paths. Here is an article I wrote that covers the benefits of using D3 with React together:
http://risebird.tumblr.com/post/147473986500/d3-react-awesome
In general, SVG elements work amazingly with D3. Their declarative nature (compare to something like Canvas) allows React to take control of as much geometry as it needs to, in order to render something amazing. g elements work nice to group other SVG elements and to transform them in groups, while path and line elements are perfect for plotting line charts. D3’s svg functions allow you to pass data easily into SVG paths and lines, which is easier than coding these SVG elements via their various letter commands. Hovering and displaying different values on a graph as you move the mouse can also be achieved by rendering SVG shapes along a path and making them invisible. Then, one could join data on top of each SVG shape using D3, as well as add a listener to a parent element that would watch for any mouse movements along the path and display whatever data was joined to the local SVG shape. This is, in fact, much easier than trying to calculate mouse positions on a graph and then trying to find and retrieve the correct piece of data on your own.
Scales are a mapping between two ranges of values, with the default one constructed via .scaleLinear(). Scale functions are usually called in a chain with .domain() and .range(), and essentially define value transformations from the domain range to the scale range. You can also use .domain() and .range() as getters. Using .scaleThreshold() creates a simple value mapping function between two arrays of values. Calling .min() and .max() will allow you to define lowest and highest points of data values. D3 Axes (plural for axis) allow you to render values on a line with ticks and labels, but are a little bit harder to work with than other D3 geometry and are less compatible with React (you still need to select nodes with D3).
D3 is also a great tool for making maps, especially because you can use it to take GeoJSON data and transform it into path elements. TopoJSON, a popular extension of GeoJSON, stitches together geometries from shared line segments called arcs, making for smaller data files. The cool thing about TopoJSON is that you can get it for any zip code in the United States.
Thanks for reading and be sure to check out this presentation by Irene Ros (@ireneros) on what’s new in D3v4 here:
https://iros.github.io/d3-v4-whats-new/#1
0 notes
Text
Make music with JavaScript

This summer, I was fortunate to see a presentation by Walmik, a sprint monkey at PayPal (@_walmik), which included an entire dimension of software engineering that I had not come across before: music. Turns out that Walmik created an npm-packaged JavaScript library called scribbletune, which makes it easy to create midi files with code. Yes, that’s right, with code, as in JavaScript. This open-source piece of software really just “uses noise that you already have, to make music”. It does this by allowing you to use scales, notes, and chords, in creating patterns represented by JavaScript arrays. So now you can use your lodash or underscore expertise to shape musical structures. That’s pretty cool.
You require sribbletune like any other node package, and essentially, start using this minimal API by invoking one of the following methods:
clip() - creates a measure of music, configured with many properties including ‘notes’ and ‘pattern’
scale() - creates a set of musical notes ordered by pitch
chord() - creates commonly used chords
midi() - generates a midi file
Using the above methods in combination, allows you to create a midi file that is shaped by your program. The file is driven by a midi pattern which you synthesize abstractly by manipulating JavaScript arrays. The pattern arrays basically consist of one character strings that represent whether to make a sound or not in that part of the pattern. You can use all of the same techniques that you normally use in JavaScript to manipulate these arrays, like map(), filter(), repeat(), or reduce(). The arrays can be concatenated and organized in complex code structures that allow you to “plug and play” musical patterns as you please, or rather, your code pleases.
The characters in the pattern arrays are usually either a ‘x’ (on), ’-‘ (off), or a ‘_’ (sustain). If you’ve ever created a pattern on a physical or virtual drum machine, then you can appreciate the (almost) boolean state each ‘bar’ can be in. When the “light is on”, the software will create a midi sound in its place (perhaps a kick drum?); and when the “light is off”, the sound is not made. The generated scale arrays can be morphed with array filtering, like when using the % (modulus) operator, and there’s even a property called ‘sizzle’ that gives your music a ‘human’ touch. You can use the ‘nodeLength’ property to shorten or lengthen your notes to really get the right sound pattern down.
Basically, you are just working with patterns. But to a programmer with some experience, this can be quite easy, and could even be faster than using actual industry software to create unique patterns for songs. You can manipulate these patterns in many different ways: slice them, dice them, glue them back together, maybe even throw them up into the air and see what falls into the basket? But seriously, it can be difficult to describe the kind of creativity that can be unleashed when you combine an industry trade with the dynamic art of creating music. This is where code turns into creativity through the medium of sound.
Once your scribbletune JavaScript is ready, you run it on your node server and it will generate a fully functional midi file. You can do everything you normally do with a midi file, including plugging it directly into music production software like Ableton. In fact, once it is loaded into such software, you can even change your code, rerun your script, and your pattern will be updated on the fly, since the file is usually read directly. In doing this, you can create a different midi pattern for each different instrument of an orchestra (or whatever is available to you in your music production software), and play them all together for the full effect.
Hope you will make some JavaScript music soon!
8 notes
·
View notes
Text
Immersive Analytics

If you look up ‘immersion’, as it pertains to virtual reality, you will see that it is the “perception of being physically present in a non-physical world.” This perception can be created by surrounding a person with virtual reality stimuli, thus providing them with an engrossing total environment. This summer, I saw an eye-opening talk by Todd Margolis (@tmargo) about Immersive Analytics and how the ever-growing world of virtual reality can help us understand and solve complex problems today and in the future.
Todd explained that some of the principles of immersive analytics have to do with the different ways that information can be organized and shared to create a better understanding of it. To do this effectively, one must create a solution that gives you the data in an engaging, persistent, info-rich, interactive, and collaborative way. This obviously goes beyond the traditional reporting of data. In fact, what we really want is to share information in a way that contributes to the build-up of communal knowledge. Essentially, this is storytelling; but the immersive world of virtual reality takes this to a whole new dimension.
To get the most out of our data, no matter how users interact with it, we will need advanced analytics. But conventional methods of analyzing data simply do not go far enough to help us understand and draw value from it. Enter ‘immersive analytics’, which provides us with different ways to interact with data in the virtual reality world. You can be asynchronously interacting with data in an ‘offline’ environment, remotely interacting with it in an ‘online’ environment, or even interacting with it ‘inline’ by being connected to other users in the same environment, in real-time. The goal it to make this process easier and more accessible, making it easier to share analytical knowledge with others.
Collaborative visualization products are already being used today. It’s not unheard of to have a team of experts clicking on visual TVs to receive and manipulate information faster. But by putting analytics into a 3D simulation, you can troubleshoot important business states that would otherwise be too complex or remote to fully understand and plan for. There are challenges to working with complex data, especially when there is pressure to understand it and take appropriate action. It can be overwhelmingly hard to understand the data as a whole, and it is easy to lose context. Eventually, generalizations have to be made, derived form factual information. This makes communicating insights that are relevant to specific data points, ever so important. A lot of researchers simply don’t have the right tools to visualize data correctly because we are still used to two dimensional methods of displaying information, and as the need to understand more complex data grows, we will need better tools in our arsenal. But are people ready to fully embrace VR analytics?
This is where we turn to ‘Augmented Intelligence’: Using information technology to augment human intelligence (also known as ‘Intelligence Amplification’) is helping to propel the sensorial evolution of data visualization forward. When looking at large, complex data, we don’t always know what the data means or even what to look for. But we don’t always have to have such direction; patterns appear when we start ‘detailing context’: By grouping certain characteristics, similarities, and differences of the information together, and then defining a way to uniquely visualize them, we gain a more powerful way to understand the data and draw conclusions from it.
But picking how to visualize the data depends on how you plan on comparing different aspects of it, how much time you want to spend analyzing it, and how you want to distribute it to others. Information graphics have existed since early cave paintings, and the question of how to use the display medium most effectively has been broken down into a science. But now, with the ability to fully immerse ourselves in virtual reality, the world of cognitive possibilities is endless.
Imagine a fully interactive data world where one can enter a ‘memory palace’ that lays out information using a variety of mnemonic techniques, only possible in virtual reality. Such a palace could have information displayed on every wall of every room, all accessible for CRUD user interactions. Such a treatment can surely be applied to a plethora of information stores and databases. By putting them into a virtual, spatial memory layout, we can more easily explore, modify, and share the information contained within them. Displaying this data in a three dimensional environment can increase our ability to be more analytical. Massive data collections, such as the ones used in molecular sciences, become much easier to interact with. Such is the power of immersive analytics!
0 notes